Course 03: 先导知识|大模型&多模态&应用场景
Lesson 1 大模型认知和思维引入
编排原则:把AI当人看
大模型本质:文字→token→embedding
1、函数→神经网络
激活函数 N套 线性函数→非线性函数(神似神经网络) 求出W b
2、计算神经网络的参数
数学言语表达
拟合度:当前函数与真实数据的相差程度
损失函数L:真实数据与预测数据误差的函数
目标:求出让L最小的w b
梯度下降:通过让L不断变小(梯度慢慢下降)的找出一组合适的参数 w b
链式法则:起始变量,经过N轮偏导数后求出终值的原理
控制变换快慢:学习率
3、调教神经网络的方法
过拟合:在样本数据拟合完美,不预测/不适配未知数据(泛化能力)
Robustness鲁棒性plus:避免模型因为输入的小变化对结果产生很大的波动
抑制过拟合--通过加入惩罚项(添加权重)+损失函数→新损失函数
辛顿Dropout:减少关键参数对模型能力的绑定
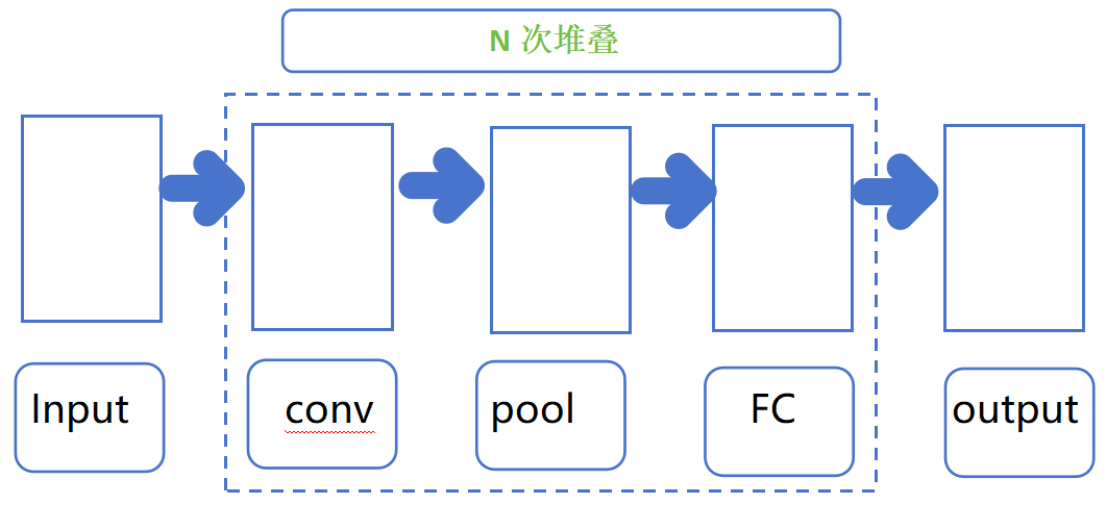
4、矩阵→CNN(卷积神经网络,处理静态数据)
加减乘除 进化→ 矩阵运算→GPU最爱的并行计算特性
图像处理:预设卷积核 原图像矩阵乘积变换
卷积运算代替FC的标准矩阵乘法→大减参数量;提取图像的局部特征
神经网络中的卷积核未知!
5、Word embedding→RNN(循环神经网络,处理动态数据)
自然语言 编码 成为数字(计算机语言)
词向量本质:自然语言的相关性转换为可以用数学公式计算出来
维度适中:词嵌入→词向量(词之间相关性, 每个位置的数值是训练赋予的)
词向量位置关系:点积 余弦相似度
循环:输入向量拼接一个隐藏状态h,权重矩阵增加Whh
循环比经典神经网络多一个隐藏状态
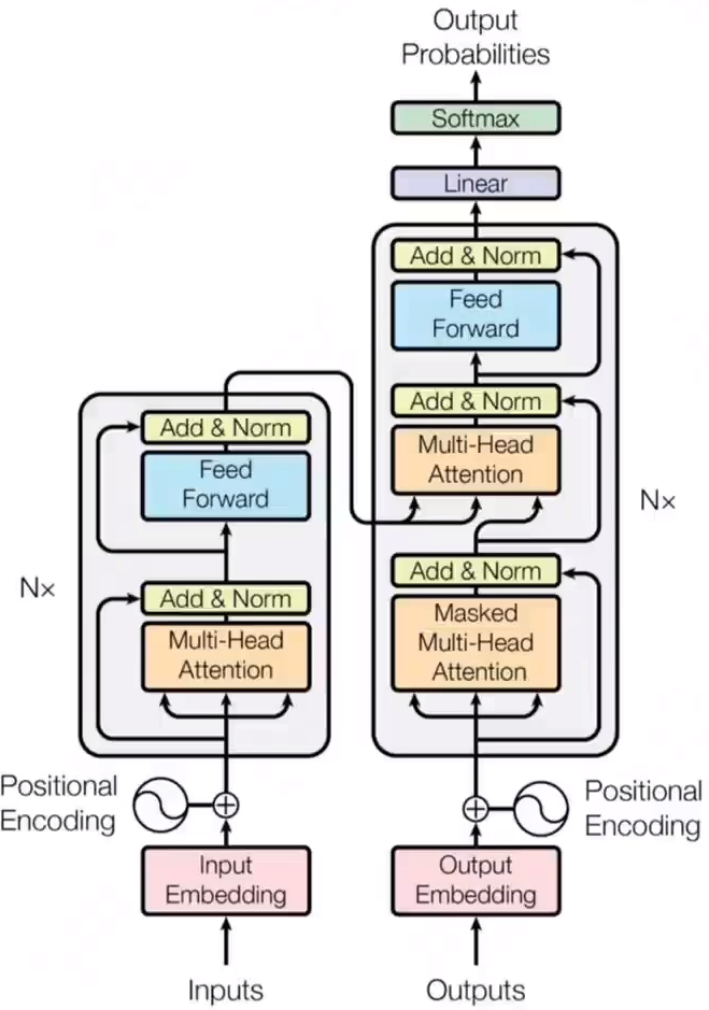
6、简单好用的transformer(Attention is all u need)
Attention:词向量与位置信息的乘积的矩阵(新词向量)包含了位置信息和其他词上下文信息
Muti-head attention:每组QKV进行注意力层运算 增加上下文信息 本质就是矩阵相乘再相加
Add&Norm:残差网络和归一化处理,解决梯度消失和让分布更加稳定
解码器:输出前经过一层线性变换的神经网络,投射到词表向量中,最后用softmax层转化为概率
调整:训练出现偏差时,计算损失函数→反向传播调整transformer结构中的权重矩阵
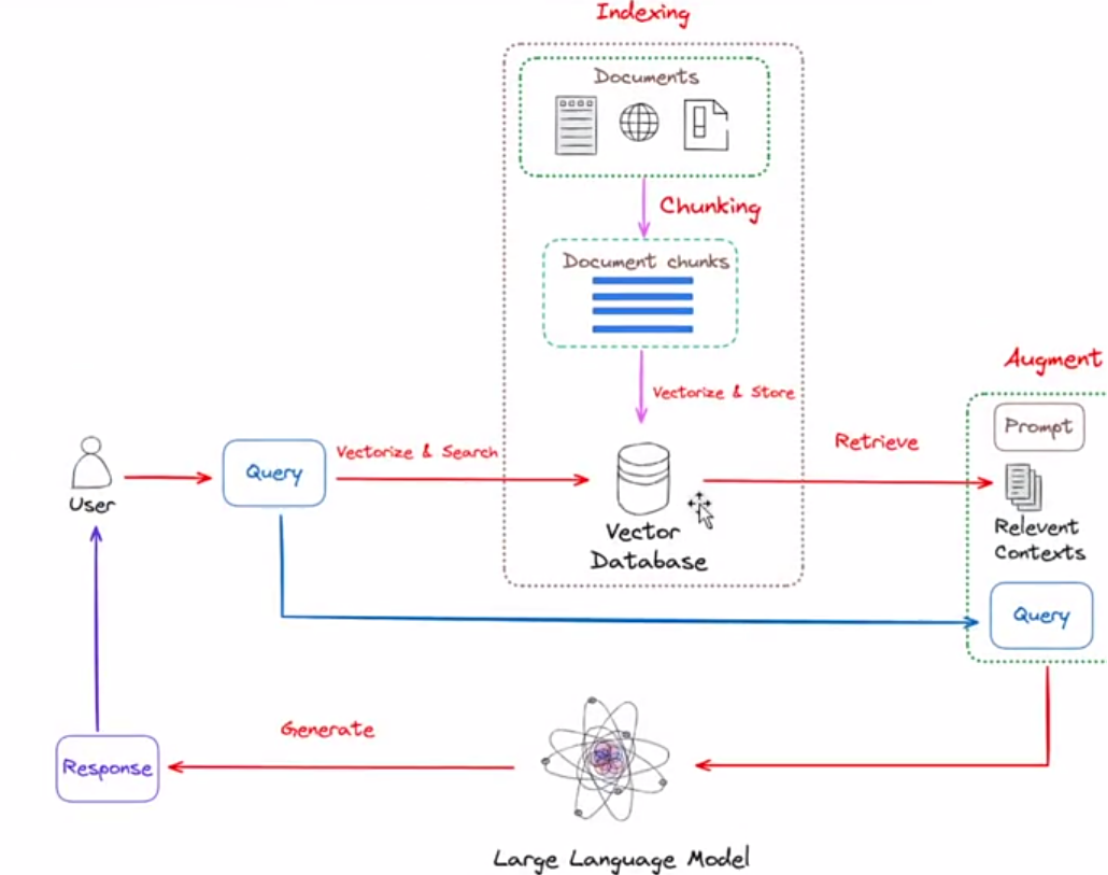
7、langchain搭建数据库
数据输入:企业内部数据库链接
数据清洗:数据分析和处理
算法:
- 文本分类模型
- 情感分析模型
- 主题建模
分析过程与步骤
- 准备阶段
- 选择适合算法
- 微调
分析引擎原理:
few小型算法和模型合作
输出结果
- 图表类
- 文字报告
- 互动界面
Lesson 2 从提示工程到RAG:构建大模型的知识与交互基础
核心思想
- 提示词:应用层的技术,本质上是为了搭建一条实用的Prompt
- RAG:最流行技术及最大的坑
- RAG的高级思维:双向奔赴
认知如一
Prompt是我们唯一可以和模型交互的方式
Prompt提效:样例,数量分类:zero-shot one-shot few-shot
SAMPLES:
Prompt Sony店员few-shot
RAG企业行政/人事/财务等制度问答
RAG骑手招聘
RAG答疑助手--coze神仙体验
Query AI改写成SQL实现检索普通数据库
query改写(Agentic RAG:规划总结query步骤)
Coze入门体验
CASE 1 :Coze平台操作的学员问题
爬虫抓取页面文字--文档和子集很全面--query和文档都是数据向量,检索相似度不够高--文档整理成(AI根据content生成典型的questions)一一对照--query与questions数据向量相似度检索
CASE 2:微信群问答
学员提问——扩写成10种不同表述(技巧--翻译模型:中文翻译成多种语言再翻回中文)——
CASE 3:视频
文字和语音为主(音频转文字,纯文字文件5万字以上--切片技巧:AI
初步分析:
每个知识点大概多少字讲完,因为选型Embedding字数限制不一样
第一个1000字/chunking--丢给LLM+写好的prompt,判断1000字可以分成几个主题
,假设第683字是第一个主题结束--第一个chunk/content;
第二个1000字:第684-1683,判断1000字可以分成几个主题——第二个chunk)
无声电影:画面,无对话(多模态模型实现每个视频片段撰写文字解说)
Prompt动态提示词:
知识库Embedding(embedding+encode) 800-1000维左右
LLM Embedding 8000-10000维左右
Lesson3 Agent:从可控性到自主反思
Agent认知框架
应用场景:项目管理/多步决策
Plan-and-execute
Self-askz
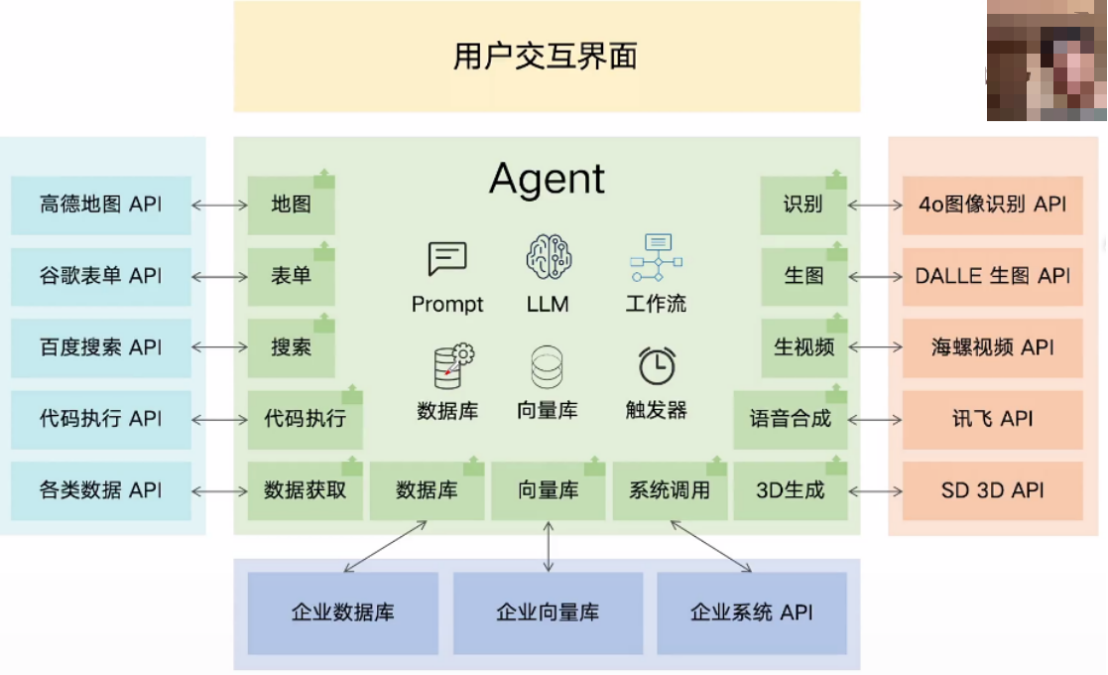
1、Workflow Agent
Q:到底给LLM多大的自由空间?
1、LLM会有幻觉
2、LLM只会说,不会做
3、LLM规划的步骤不靠谱
有些任务就是需要极强的准确度、可控性,怎么办?
A:模型提供智能,Agent保证结果
1、用RAG技术构建私有知识库,提升对话能力
2、用设计者定义好的Workflow完成特定任务
3、过程中使用工具完成LLM无法完成的任务
4、让LLM写代码,完成数据处理、数学计算
2、React Agent
Thought → Action → Observation → Answer
Q:有些任务无法提前设定步骤怎么办?
比如:我有份文件里记录了上个月最终的业务数据,找找是哪份文件比如:检查一下直播系统,我的直播间学员们说很卡,但是网络测速是正常的比如:听说明天台风,我明天从深圳飞北京,能正常起飞么?
A:ReAct: Reasoning + Acting推理、行动、获得反馈
根据反馈再次推理、行动、再次获取反馈
使用了ReAct技术的AI产品:
AutoGPTPerplexity
Manus
Cursor
GenSpark
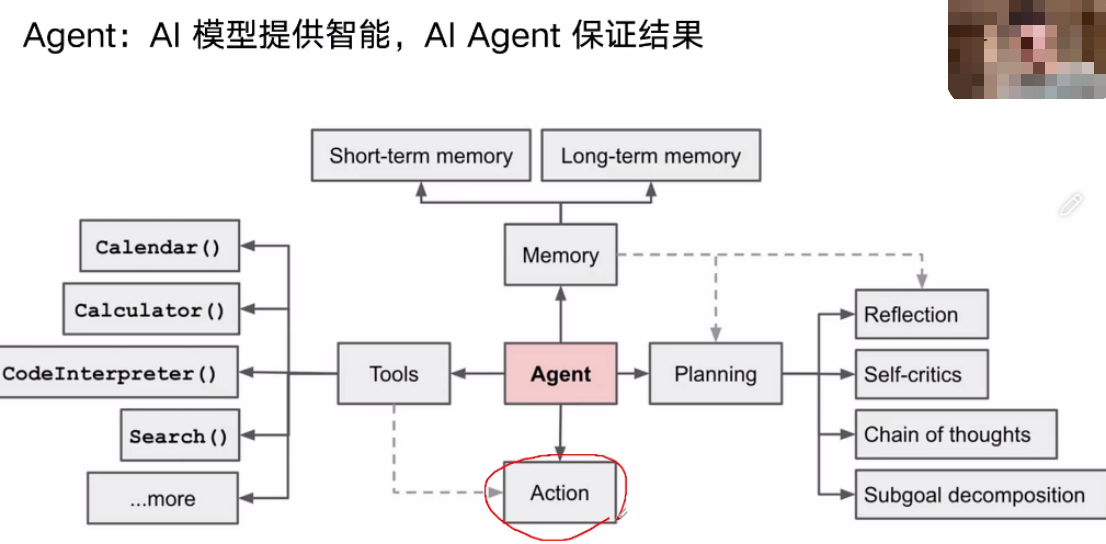
Action\Tools由工程师编码或提供工具
优秀网站
法律工作者:Harvey.ai
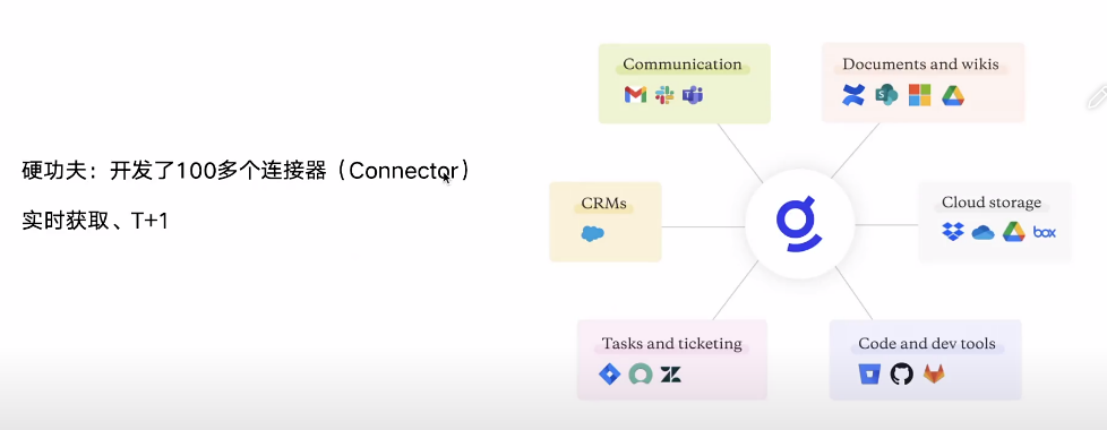
企业知识库:Glean

Lesson4多模态前沿:从Agent构建到视频AIGC
1、视觉和语言的打通
如何打通:一个模型,能同时看懂语言和视觉
图生文:图片存储在只能接受文字的知识库之前,先图转文
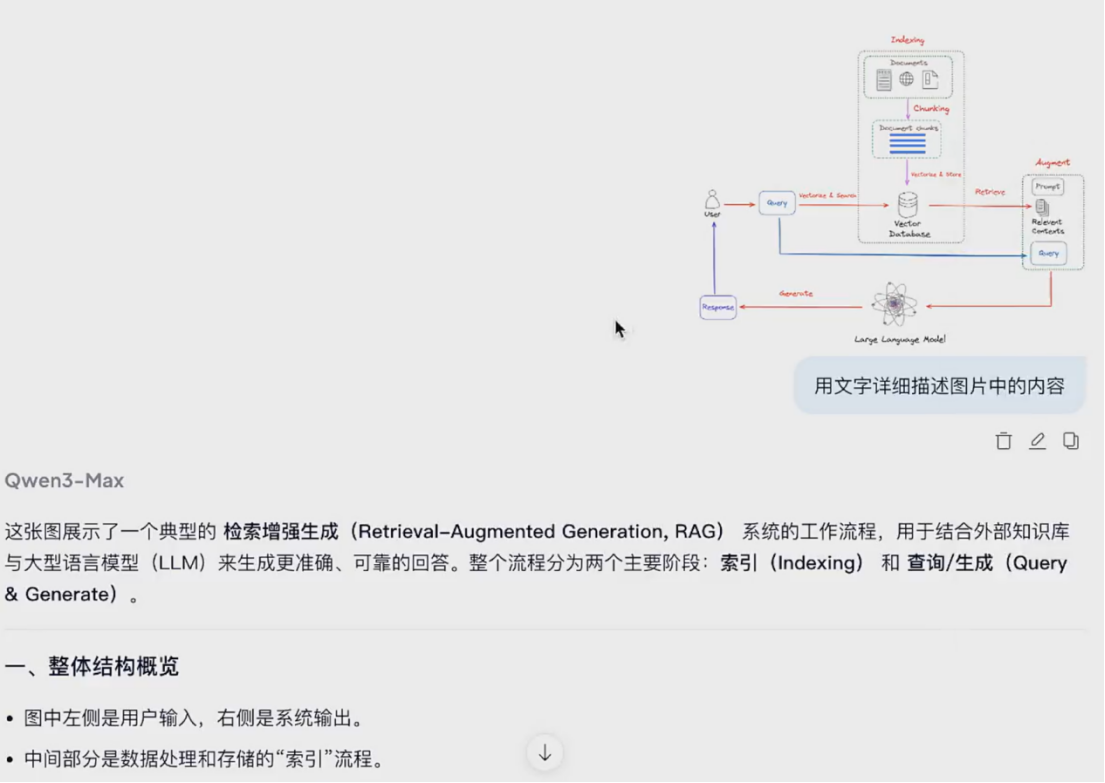
进阶能力:能输出文字,也能输出图片、视频
文生图:这是一只安哥拉猫,背上是安静的马耳他蓝,从喉咙到足尖的胸腹部是一片纯净、光滑如貂的白色皮毛,精致的脑袋有贵族气质,神情透出智慧,动作优雅像一只年轻的豹子。

实际用处:视觉转译、融合推理、视觉编辑
融合推理:读懂文、图==>推导答案
- 视觉识别与视觉推理
传统视觉识别模型vs多模态模型
传统视觉识别模型:Yolo、UNet
Yolo:目标物体的识别
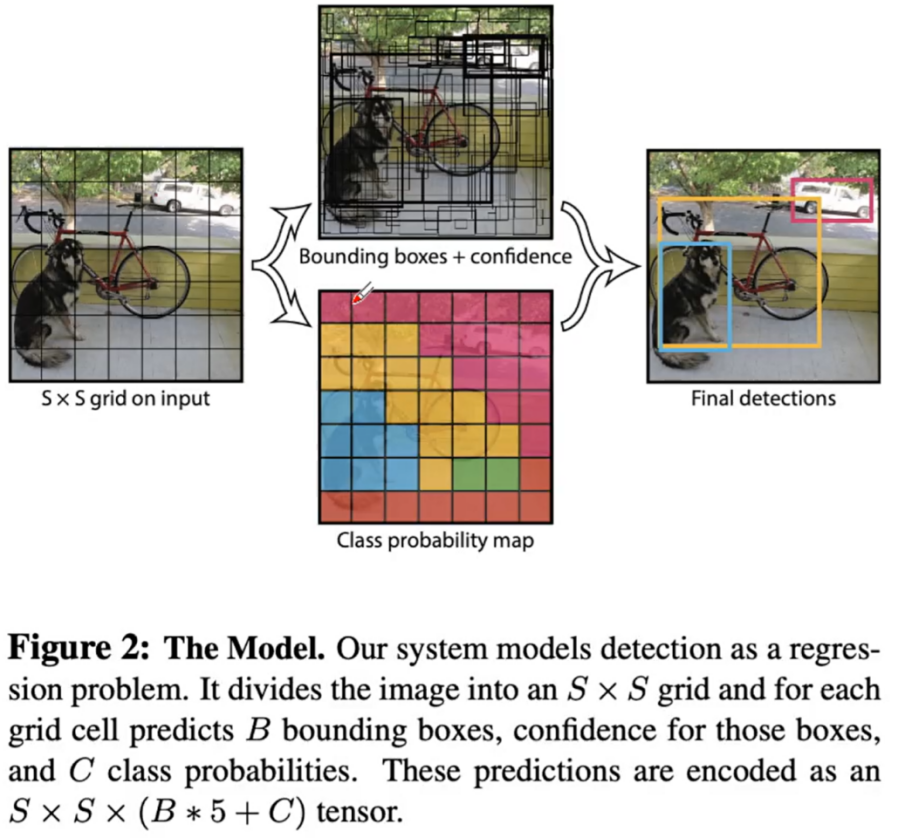
视觉识别:分出员工与顾问
动作分析:每个员工做出多少杯咖啡,必须借助多模态

UNet:具体区域的分割
像素识别:1024✖768

左例子,右测评

总结:
Yolo、UNet
应用硬伤,泛化性太低:训练模型采用的图库之外新图片识别精度骤降
优势:模型小、部署和使用成本低、识别精度高
劣势:需要单独标注数据、训练模型
多模态模型
Gemini、 GPT、Qwen VL、豆包 Seed
优势:无需标注、无需训练、直接使用、有推理能力
劣势:部署和使用成本较高,精度中等
- 视觉生成
停留在使用层面/模型能力不足:
只是写提示词给模型,生成的视频无法满足需求
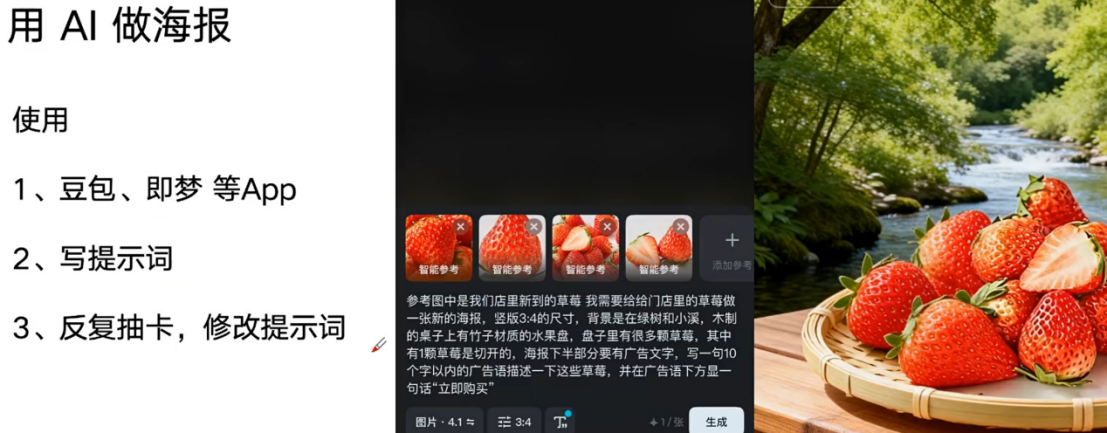
1、海报生成
2、漫剧视频
3、电商视频

从Agent构建到视频AIGC
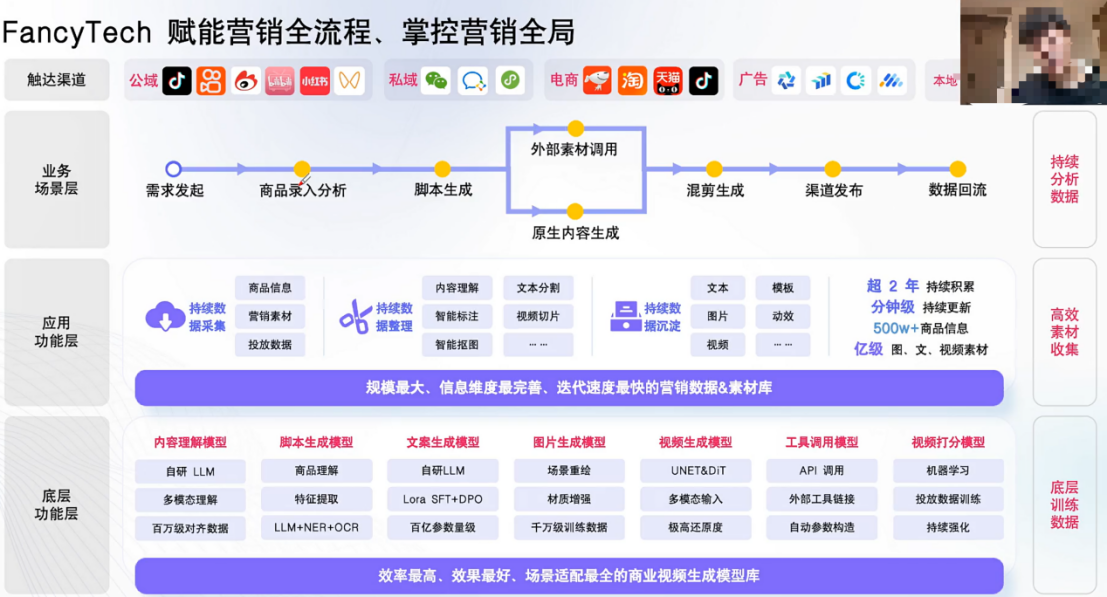
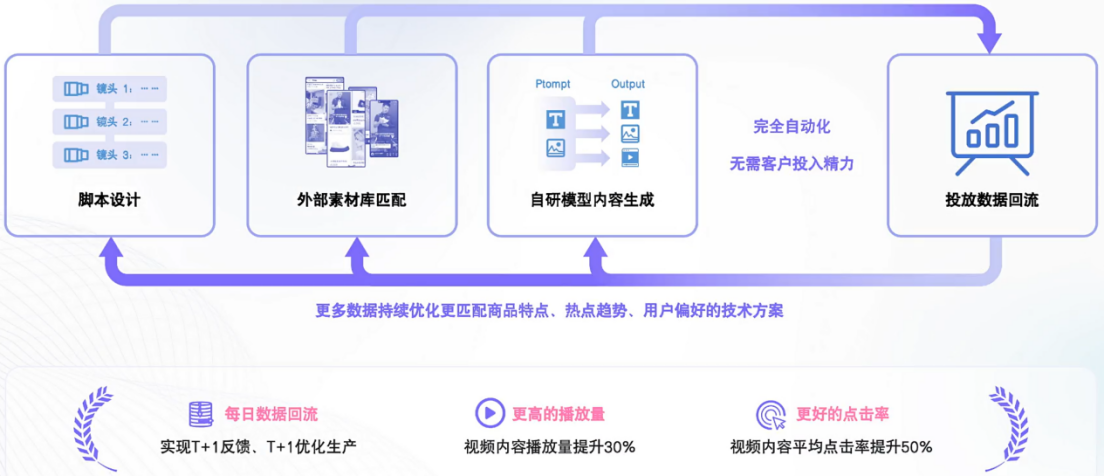
多模态Agent:品牌视频切片、产品展示切片、模特展示切片、直播切片,根据片库推理 重组新视频,必须用到LLM
操作流程:多模态每个步骤的成果材料转为文字==>LLM学习和创新生成==>新素材
1、Al+人工切片,1-10秒视频
2、通过代码或工具,将视频中的音频分离
3、从音频中提取文字
4、通过多模态模型对画面进行文字描述
5、人工补充修改文字描述
6、整理成结构化信息

商业实际情况:
大量商家95%以上的商品没有拍过模特展示视频
1、文生视频,可控性普遍还不够
2、图生视频,生成几秒钟的展示视频,效果是可用的
N种大小颗粒度差别的模板,保障商品图真实感:
梳理和标注所有的商品图,模特图
1、上衣内容类别:连衣裙、T恤、衬衫、外套、针织衫、风衣、西服、卫衣、马夹、大衣、皮衣、皮草、毛衣、羽绒服等等
2、上衣款式:贴身款、修身款、合身款、宽松款、超宽松款
3、上衣长度:超短款、短款、常规款、中长款、长款、超长款
4、上衣袖子:长袖、半袖、短袖、无袖
5、下衣内容类别:连衣裙、半身裙、休闲裤、牛仔裤、短裤、直筒裤、工装裤、西裤、运动裤等等6、下衣款式:紧身款、修身款、合身款、宽松款、超宽松款
7、下衣长度:拖地、长、7分、膝盖、短、超短
商业案例:Fancy Tech千人千面内容制作内容精准触达

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)