覆盖天体物理/地球科学/流变学/声学等19种场景,Polymathic AI构建1.3B模型实现精确连续介质仿真
Polymathic AI 联合研究团队提出了一个以 Transformer 为核心架构、主要面向类流体连续介质动力学的基础模型 Walrus。Walrus 在预训练阶段覆盖了 19 种高度多样化的物理场景,涵盖天体物理、地球科学、流变学、等离子体物理、声学以及经典流体力学等多个领域。结果表明,无论在下游任务的短期预测还是长期预测中,Walrus 均优于此前的基础模型。
在科学计算和工程模拟领域,如何高效、精确地预测复杂物理系统的演化,一直是学术界和工业界的核心难题。传统数值方法虽然在理论上能够求解大部分物理方程,但在处理高维、多物理场景或非均匀边界条件时,计算成本极高,且缺乏对大规模多任务的适应性。与此同时,深度学习在自然语言处理和计算机视觉领域的突破,引发了研究者们探索「基础模型」在物理模拟中的应用可能性。
然而,物理系统往往跨越多个时间尺度和空间尺度演化,而多数学习模型通常仅在短期动力学上进行训练,一旦被用于长时间尺度预测,误差便会在复杂系统中不断累积,导致模型不稳定。此外,不同尺度和系统异质性还意味着,下游任务对建模分辨率、维度以及物理场类型的需求各不相同,这对偏好固定输入形式的现代训练架构构成了巨大挑战。因此,迄今为止用于仿真的基础模型大多仍局限于相对同质的数据场景,例如仅处理二维问题,而非更符合现实的三维情形。
在此背景下,来自 Polymathic AI 协作组的研究团队引入了一系列新方法来应对上述挑战,包括:Patch jittering(补丁抖动)、面向 2D–3D 场景的负载均衡分布式训练策略,以及自适应计算标记化(Adaptive-compute Tokenization)机制等。以此为基础,研究团队提出了一个拥有 13 亿参数、以 Transformer 为核心架构、主要面向类流体连续介质动力学的基础模型 Walrus。Walrus 在预训练阶段覆盖了 19 种高度多样化的物理场景,涵盖天体物理、地球科学、流变学、等离子体物理、声学以及经典流体力学等多个领域。实验结果表明,无论在下游任务的短期预测还是长期预测中,Walrus 均优于此前的基础模型,并且在整个预训练数据分布范围内都展现出更强的泛化性能。
相关研究成果以「Walrus: A Cross-Domain Foundation Model for Continuum Dynamics」为题,已发布预印版于 arXiv。
研究亮点:
* Walrus 的模型参数规模达 1.3B,拥有创新的稳定化技术以及根据问题复杂度自适应计算的能力;
* 解决了当前连续介质动力学基础模型的若干局限性,例如成本自适应、稳定性以及在原生分辨率下对高度异构训练数据的高效训练;
* Walrus 是迄今为止最精确的连续介质仿真基础模型,在来自多个科学领域的 26 个独特连续介质模拟任务的多个时间尺度上,共跟踪的 65 个指标中有 56 个取得最佳结果。

论文地址:
https://arxiv.org/abs/2511.15684
关注公众号,后台回复「介质仿真」获取完整 PDF
更多 AI 前沿论文:
https://hyper.ai/papers
构建异构、多维的高质量数据集
Walrus 的成功离不开多样性和高质量的数据。研究团队采用了来自 Well 和 FlowBench 的混合数据集进行预训练。Well 数据集提供了大量高分辨率、来源于真实科学问题的数据,而 FlowBench 则在标准流体场景中引入几何复杂障碍物,为模型提供复杂流动模式的学习机会。
研究团队总计使用了 19 个数据集,覆盖 63 个状态变量,包含不同方程、边界条件和物理参数化设置。数据维度涵盖二维与三维,确保模型在不同空间维度下的泛化能力。为了验证模型迁移能力,研究团队在预训练完成后,使用了部分保留数据集,包括 Well、FlowBench、PDEBench、PDEArena 和 PDEGym 的数据进行微调。数据切分遵循标准分割策略,或按轨迹划分为训练/验证/测试的 80/10/10 比例。
在训练设置上,Walrus 模型进行了约 40 万步预训练,每个二维数据集约 400 万样本,三维数据集约 200 万样本,使用 AdamW 优化器和学习率调度策略,实现对高维、多任务数据的高效学习。评价指标主要采用 VRMSE(标准化均方根误差)进行比较,可跨数据集、跨任务进行统一评价。
这种高度多样化的训练数据和策略,使 Walrus 能够在预训练阶段捕获丰富的物理特性,并为下游任务的跨领域泛化奠定基础。
基于时空因式分解 Transformer 架构
Walrus 模型采用时空因式分解 Transformer 架构(space-time factorized transformer),在处理时空张量结构数据时,分别沿空间和时间维度执行注意力操作,实现高效建模,流程如下图所示:
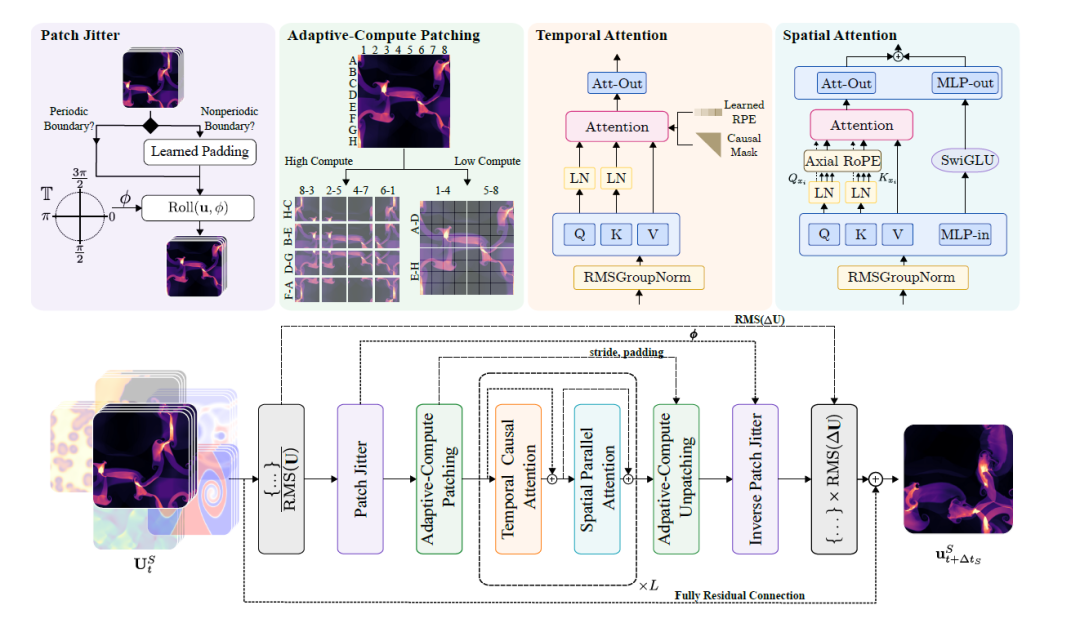
Walrus 流程图
* 空间处理:使用 Wang 提出的并行化注意力,并结合轴向 RoPE(Axial RoPE)进行位置编码。
* 时间轴处理:使用因果注意力结合 T5 风格的相对位置编。在空间和时间模块中均采用 QK 归一化(QK normalization)以提升训练稳定性。
* 计算自适应压缩(Compute-Adaptive Compression):在编码器和解码器模块中,使用卷积步幅调制(Convolutional Stride Modulation, CSM)来原生处理不同分辨率的数据,通过调整每个编码/解码块中的下采样/上采样水平,实现灵活的分辨率处理。此前用于仿真的基础模型多采用固定压缩编码器,对下游任务中变化的分辨率需求不够灵活。CSM 允许研究人员调整卷积步幅进行下采样,从而选择与任务匹配的空间压缩水平。
* 共享编码器-解码器(Shared Encoder-Decoder):所有同维度物理系统共享单一编码器与解码器,从而学习通用特征。二维与三维数据分别对应两个编码器和解码器,使用轻量级分层 MLP(hMLP)进行编码和解码。
* RMS GroupNorm 和非对称输入输出归一化:在每个 Transformer 块内使用 RMSGroupNorm 进行标准化,提高训练稳定性。输入与输出使用非对称归一化(asymmetric normalization)处理增量预测,保证不同场景的数值稳定性。
* Patch Jittering:通过对输入数据进行随机平移,并在输出端反向处理,减少高频伪影积累,显著提升长期预测稳定性,尤其在 ViT 风格架构中效果明显。
* 高效多任务训练:采用层次化采样和归一化损失函数,确保快速变化场的预测不会被慢速变化场主导,同时结合微批量和自适应 token 化策略,解决高维异构数据训练中的负载不均问题。
* 二维与三维统一表示:通过在二维数据上增加单维并零填充,将其嵌入三维空间,再通过对称性增强(旋转、反射)进行多样化扩增,实现跨维度训练能力。
总体而言,Walrus 架构不仅在空间与时间维度上高效处理张量数据,还通过多样化策略和高效分布式训练应对多任务、多物理场景的挑战。
Walrus 在多个二维和三维下游任务中表现出显著优势
为了验证 Walrus 作为基础模型的性能以及其在下游任务中的表现,研究人员设计了一系列实验:
①下游任务表现
与 MPP-AViT-L、Poseidon-L 和 DPOT-H 等现有基础模型对比,Walrus 在单步预测的平均 VRMSE 上降低约 63.6%,短期轨迹预测降低 56.2%,中期轨迹预测降低 48.3%,如下图:
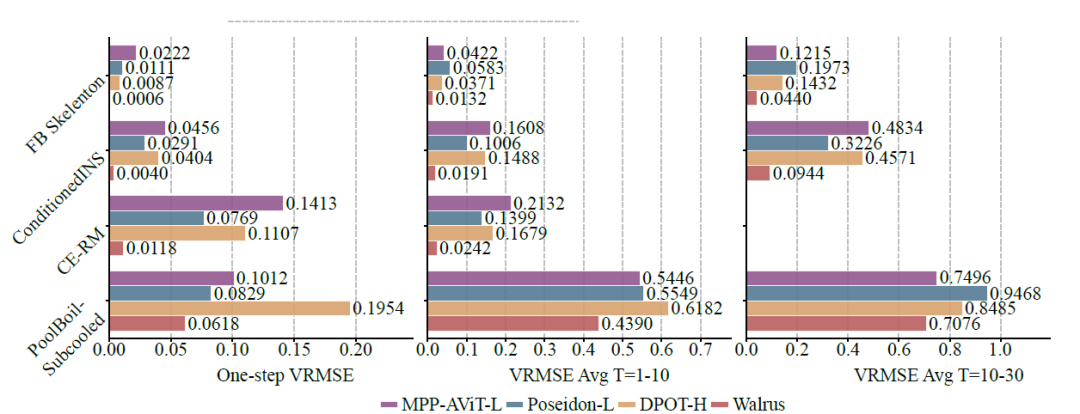
各基础模型微调后在 2D 下游任务上的损失(中位数 VRMSE)
在非混沌系统中,Patch Jittering 带来的低伪影生成,使模型长期预测表现稳定;在更随机的系统(如 BubbleML 的 Pool-BoilSubcool)中,Walrus 虽然初期领先,但由于短期历史信息无法充分反映材料和燃烧器特性,长期滚动预测优势有所减弱。
三维任务尤其重要,因为大部分实际物理仿真场景为三维系统。Walrus 在 PNS(中子星合并后)和 RSG(红超巨星对流层)数据集上表现优异,即便这些数据集生成成本高达数百万核小时,如下图:
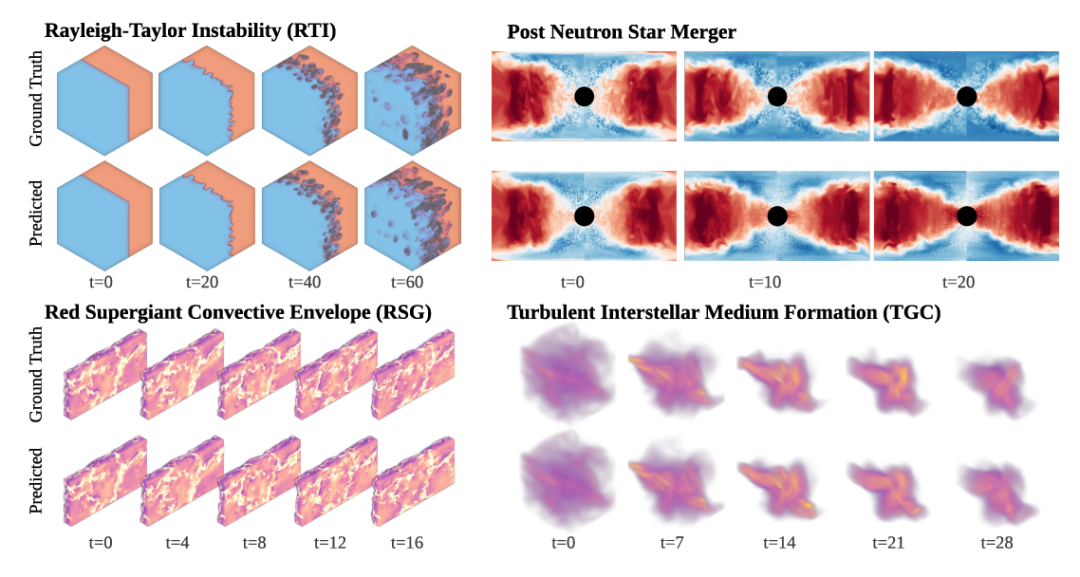
可视化微调后的 Walrus 在 3D 前沿科研级别模拟中的预测结果
②跨领域能力
Walrus 的跨领域能力也得到验证,与最优基线相比,Walrus 在单步预测上平均损失降低 52.2%。在对 19 个预训练数据集进行微调后,Walrus 在 18/19 个任务上取得最低单步损失,并在 20 步和 20-60 步的中期滚动预测中分别取得 30.5% 和 6.3% 的平均优势,如下表:
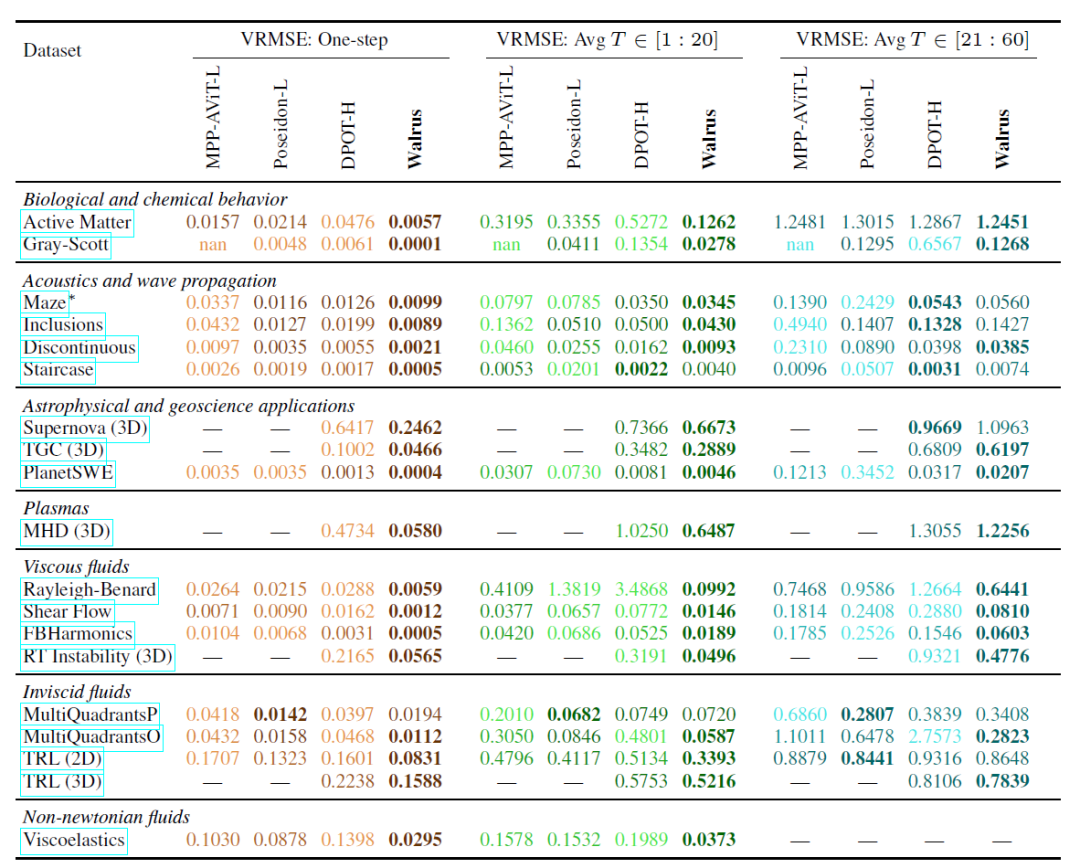
在不同时间范围内的损失(中位数 VRMSE)平均值
相比之下,DPOT 在声学和线性波传播任务中表现接近 Walrus,Poseidon 在无粘流任务中表现优异,但 Walrus 通过广泛预训练和通用架构,在大多数任务上都取得了竞争力甚至更优的结果。
③预训练策略影响
消融实验显示,Walrus 的多样化预训练策略对下游性能至关重要。即使在仅使用二维数据的半尺寸模型(HalfWalrus)上,经过全面空间与时间增强的预训练策略,在完全未见的新任务上仍明显优于从零训练或简单二维预训练策略的模型。
在三维 CNS 任务上,HalfWalrus 即使未见过三维数据,也能在极小数据量下取得小幅提升,而完整 Walrus 模型通过包含三维数据的预训练,取得了明显优势,强调了多维度、多样化数据的重要性。
Polymathic AI 加速跨学科人工智能应用的落地
在科学计算与工程建模领域,基础模型的潜力正在引发新一轮范式转变。Polymathic AI 是一个值得关注的开源研究项目,其核心目标是构建面向科学数据的通用基础模型,以加速跨学科人工智能应用的落地。
与面向自然语言或视觉任务的通用大模型不同,Polymathic AI 聚焦于连续动力学系统、物理场模拟、工程系统建模等典型科学计算问题。其核心思想是:通过大规模、多物理场、多尺度数据训练统一模型,使其具备跨领域迁移能力,从而减少每个科学问题从零构建模型的成本——这种「跨领域泛化能力」被视为科学 AI 的关键突破点。
据悉,Polymathic AI 汇集了一支由纯机器学习研究人员,以及领域科学家组成的团队,接受世界领先专家组成的科学咨询小组的指导,并由图灵奖得主、Meta 首席科学家 Yann LeCun 担任顾问,受到包括剑桥大学 AI+天文/物理助理教授 Miles Cranmer 在内的多位学术大咖的支持,以期集中精力开发科学数据的基础模型,利用跨学科的共享概念解决 AI for Science 行业难题。
2025 年,Polymathic AI 合作组成员展示了两款使用真实科学数据集训练的新人工智能模型,旨在解决天文学和类流体系统中的问题。其中一款为前文介绍的 Walrus,另一款则是首个面向天文学的大规模多模态基础模型家族 AION-1(天文全模态网络,AstronomIcal Omni-modal Network)。AION-1 通过统一的早期融合骨干网络,将图像、光谱和星表数据等异质观测信息进行集成建模,不仅在零样本场景下表现优异,其线性探测准确率也可媲美针对特定任务专门训练的模型,在广泛的科学任务中表现优异。即便仅通过简单的前向探测,其性能即可达到 SOTA 水平,在低数据量场景下更是显著优于有监督基线
论文标题:AION-1: Omnimodal Foundation Model for Astronomical Sciences
论文地址:https://arxiv.org/abs/2510.17960
总体而言,Polymathic AI 代表了「科学 AI 基础模型」这一新兴技术范式的前沿探索,其长期意义不仅在于性能提升,更在于构建跨学科知识迁移的通用计算底座,为「AI for Science」从工具级应用走向基础设施级能力奠定基础。
参考文献:
1.https://arxiv.org/abs/2511.15684
2.https://www.thepaper.cn/newsDetail_forward_32173693
3.https://polymathic-ai.org
4.https://arxiv.org/abs/2510.17960
5.https://www.163.com/dy/article/KGMRMMQM055676SU.html

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献144条内容
已为社区贡献144条内容

所有评论(0)