SKYRL-AGENT: EFFICIENT RL TRAINING FOR MULTI-TURN LLM AGENT
ABSTRACT
我们介绍了 SKYRL-AGENT,一个用于高效,多轮[multi-turn]、长时域[long-horizon]智能体训练和评估的框架。它提供了高效的异步调度[asynchronous dispatching]、轻量级工具集成以及灵活的后端互操作性,能够无缝对接现有的强化学习框架[RL frameworks],如 SkyRL-train、VeRL 和 Tinker。
利用 SKYRL-AGENT,我们训练了 SA-SWE-32B,这是一个从 Qwen3-32B(24.4% Pass@1)出发、纯粹通过强化学习训练的软件工程智能体。我们引入了两个关键组件:一个优化的异步流水线调度器[an optimized asynchronous pipeline dispatcher],相比朴素的异步批处理[naive asynchronous batching]实现了 1.55 倍的加速;以及一个工具增强的训练方案,利用基于 AST 的搜索工具[AST-based search tool]来促进代码导航、提升 rollout 的 Pass@K 指标并改善训练效率。
这些优化措施共同使 SA-SWE-32B 在 SWE-Bench Verified 上达到了 39.4% 的 Pass@1,同时相比达到类似性能的先前模型,训练成本降低了 2 倍以上。
尽管仅在软件工程任务上训练,SA-SWE-32B 在其他智能体任务上也表现出良好的泛化能力,包括 Terminal-Bench、BrowseComp-Plus 和 WebArena。我们进一步通过深度研究、计算机使用和记忆智能体的案例研究展示了 SKYRL-AGENT 的扩展性,每个案例都使用了不同的训练后端。
1 INTRODUCTION
训练后技术[post-training techniques]的最新进展,尤其是基于可验证奖励的强化学习(reinforcement learning from verifiable rewards, RLVR),推动了从单轮[single-turn]语言模型优化向多轮[multi-turn]、长时域[long-horizon]、工具增强智能体[tool-augmented agents]训练的转变。这些智能体能够在代码仓库、浏览器或操作系统等多样化环境中执行复杂的多步推理和行动。
随着任务变得越来越具有交互性和开放性,如何高效且可靠地训练这类智能体已成为强化学习和系统社区面临的重大挑战。
近期的强化学习训练框架[RL training frameworks],如 SkyRL-train、AReaL、VeRL 和 SLIME,专注于提升大规模语言模型强化学习的系统效率。这些框架管理异构集群中的设备放置和数据流,协调推理引擎与训练引擎之间的高效权重同步,并采用多样化的并行策略(如张量并行、数据并行和流水线并行),结合异步或混合执行计划以最大化硬件利用率。
Tinker 在此生态系统基础上提供了用于微调和采样的模块化 API,使用户能够实验定制的训练算法和数据管道,同时屏蔽了分布式执行的复杂性。然而,目前仍然缺少一个模块化[modular]且高性能的智能体 rollout 编排层[agentic rollout orchestration layer],能够大规模地生成、调度和评估多轮智能体轨迹。
在实践中,研究人员和从业者被迫构建临时性的解决方案来协调异步 rollout、管理环境和智能体状态,以及对接现有训练框架。这种碎片化的设置导致了效率低下、执行脆弱以及调试困难,尤其是考虑到强化学习训练固有的不稳定性和脆弱性。
具体而言,该框架应满足以下关键特性,以实现高效、可扩展且可扩展的智能体训练:
- 1. 灵活的工具和任务集成。Flexible tool and task integration. 基于 LLM 的智能体依赖于各种工具来完成任务,包括无状态工具(如 Python 解释器)、环境修改工具(如文件编辑器)以及智能体状态修改操作(如摘要和历史截断),每种工具都有不同的运行时需求。框架应允许轻松集成新任务和新工具,且对主智能体循环的修改最小化。
- 2. 高效的 rollout 调度。Efficient rollout scheduling. 为了实现高硬件利用率和最小化延迟,框架应支持细粒度调度,而非将每个 rollout 视为单一整体任务。Rollout 内调度[Intra-rollout scheduling]将一个 rollout 分解为多个阶段(如初始化、LLM 生成、奖励计算),并独立调度这些阶段,使其异构的 CPU 密集型和 GPU 密集型操作能够与其他 rollout 的阶段重叠执行。Rollout 间调度[Inter-rollout scheduling]确定全局分派顺序和 rollout 的优先级,使 CPU 和 GPU 上的工作负载随时间保持平衡,防止硬件空闲并减少总体执行时间。这些机制共同提升了异构资源利用率和整体生成吞吐量。
- 3. Training-backend agnostic. 训练后端无关性。开发者应能够独立指定智能体设计、工具执行逻辑和训练后端。解耦这些组件使得单个智能体实现能够在不同框架间无需修改地运行,灵活利用各框架的独特能力,并在本地部署和基于 API 的服务之间无缝切换。
SKYRL-AGENT 基于这些观察,引入了一个用于异构智能体任务的高效执行框架。它由三个关键组件构成:(1)以工具为中心的任务接口,支持动态注册用户自定义工具、指令构建器和不同任务的验证器,实现新任务和工具的无缝集成,代码修改最小化;(2)细粒度异步调度器抽象,为一批多阶段 rollout 作业的调度策略设计提供统一接口;以及(3)后端桥接,连接到 Tinker、VeRL 和 SkyRL-train 等强化学习训练系统,用于优势估计和策略优化。
为了展示 SKYRL-AGENT 的有效性,我们使用它训练了 SA-SWE-32B,这是一个从 Qwen3-32B(24.4% Pass@1)衍生的软件工程智能体,在 R2E-Gym 的 4.5K 个实例上使用纯强化学习进行训练。SA-SWE-32B 在 SWE-Bench Verified 上达到 39.4% 的 Pass@1,与同等规模的最先进模型性能相当,同时将总训练成本降低了 2 倍以上。
这一效率提升源于两个关键贡献:
- 异步流水线调度器通过重叠 CPU 密集型和 GPU 密集型操作,相比朴素异步批处理实现了 1.55 倍加速(§3.2);
- 以及工具增强训练方案,利用基于 AST 的搜索工具促进代码导航,提高 rollout 的 Pass@K 并改善样本效率(§4.2)。
尽管仅在软件工程任务上训练,SA-SWE-32B 仍能有效泛化到其他智能体基准测试(§4.3),如 Terminal-Bench、BrowseComp-Plus 和 WebArena。除了 SWE 智能体之外,我们在第 5 节中进一步展示了 SKYRL-AGENT 的多功能性,通过在较小规模上训练多个额外智能体,包括深度研究智能体、计算机使用智能体和记忆智能体,每个智能体连接到不同的强化学习后端,展示了该框架的灵活性和互操作性。
2 BACKGROUND
表 1:SKYRL-AGENT 与现有智能体训练框架的比较。SKYRL-AGENT 为可扩展的智能体训练提供了统一的工具接口、高效的 rollout 调度、后端可移植性、运行时扩展工具以及动态轨迹构建。
Multi-Turn LLM Agent Training. 强化学习(RL)在改进单轮推理任务(如数学、逻辑和编程)方面展现出强大潜力。在这些场景中,模型对单个提示生成完整响应,并接收反映其正确性或质量的标量奖励。基于这些成功,研究人员进一步探索了工具集成推理[tool-integrated reasoning],其中模型与搜索引擎、计算器或代码执行器等外部工具交互,以增强其推理能力,在相关推理基准上显示出显著改进。由于工具响应(如检索的文档或计算结果)与模型自身的推理交织在一起,大多数方法采用基于掩码的损失构建[mask-based loss construction],在优化过程中屏蔽非模型生成的 token [non-model-generated tokens],以确保只有生成的片段对策略梯度有贡献。
近期工作还将强化学习应用于
长时域[long-horizon]、
多轮智能体训练[multi-turn agent training],使得 ReAct、CodeAct 和 MemGPT 等智能体框架的优化超越了监督学习。多轮智能体可以被形式化为部分可观测马尔可夫决策过程(partially observable Markov decision process, POMDP),其中在每个步骤

,智能体观察上下文
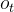
,从策略

生成动作
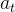
,并从环境接收标量奖励
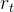
。
目标是最大化期望累积回报
其中 T 是每个任务的智能体轮数。
在多轮设置中,智能体通常通过摘要、截断或选择性地整合检索信息来修改步骤之间的上下文,这使得整体交互历史呈非平稳状态。这种动态上下文管理打破了单一连续文本序列的假设[the assumption of a single continuous text sequence],使得传统的基于掩码的方法难以泛化到短期工具集成推理任务之外。
基于 POMDP 形式化,近期工作转而采用更通用的基于过渡(transition)的
数据表示[data representation],其中每次模型调用及其产生的反馈表示为
元组[a tuple] (
,
,
)。这种表示支持灵活的奖励分配,并将学习与智能体执行和上下文管理的细节解耦。它还自然地适用于多智能体或子智能体系统,其中不同的策略在共享环境中交互。
Training Frameworks for LLM Agents. 现有的智能体训练框架,如 VeRL-Tool、rLLM、GEM 和 Agent-Lightning,已经推进了 LLM 智能体的大规模强化学习训练,但仍受限于朴素的异步批处理(即数据并行)执行。SKYRL-AGENT 支持多维度的灵活 rollout 调度(如数据并行 + 流水线并行)。除了执行效率之外,SKYRL-AGENT 将无状态工具(如 Python 解释器)、环境修改操作(如文件编辑器)和智能体状态修改操作(如摘要)统一在单一工具中,而不像以 Gym 为中心的循环,后者在 env.step 之外通过临时实现管理智能体状态。如表 1 所总结,Agent-Lightning 作为训练后端与 LangChain 和 AutoGen 等工作流框架之间的中间层,但缺乏对用户自定义工具和新任务集成的原生支持。rLLM 和 VeRL-Tool 提供更强的可扩展性,但它们绑定到 VeRL 后端,且 VeRL-Tool 基于掩码的轨迹构建限制了其在多智能体系统或记忆智能体等场景中的适用性。
3 FRAMEWORK ARCHITECTURE
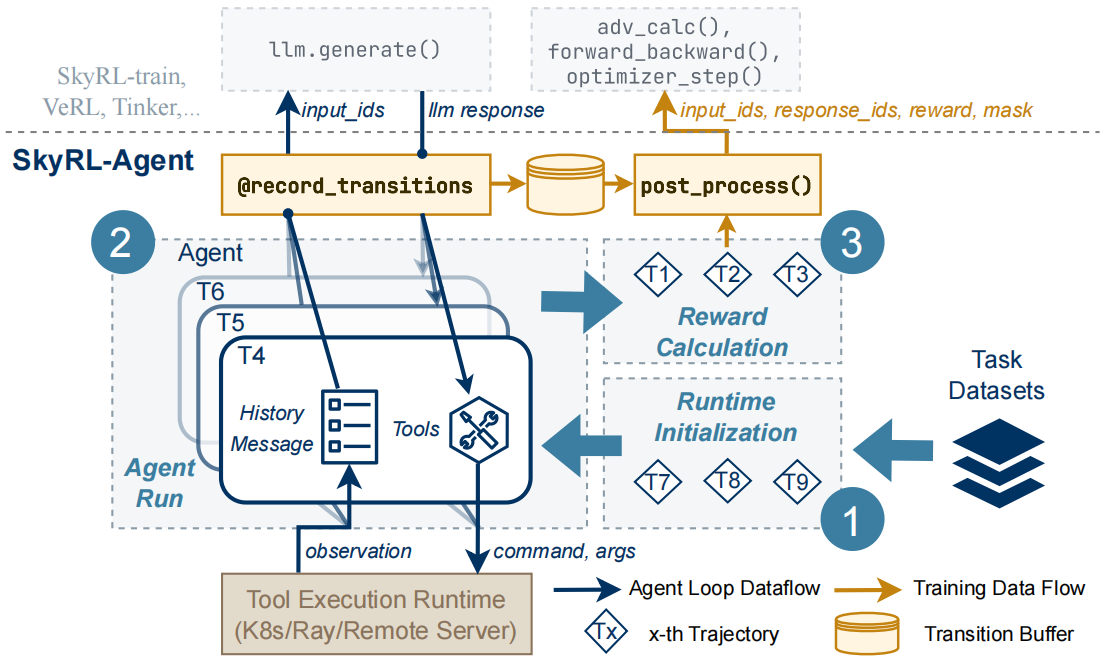
该框架将每个 rollout 分解为三个阶段:(1)运行时初始化,用于工具执行运行时设置;(2)智能体运行,智能体通过工具接口执行操作;(3)奖励计算,用于结果评估。
在执行过程中,LLM 调用的输入和输出被记录为过渡(transition)并存储在缓冲区[buffer]中,而 post_process 将这些过渡与其奖励聚合为格式化数据,兼容多个强化学习训练后端,如 SkyRL-train、VeRL 和 Tinker。调度器根据预定义的策略[predefined policies]在三个阶段之间调度作业。
图2:SKYRL-AGENT 整体架构。该框架将每次 rollout 分解为三个阶段:(1)运行时初始化,用于工具执行环境的搭建;(2)智能体运行,智能体通过工具接口执行动作;(3)奖励计算,用于对结果进行评估。在执行过程中,LLM 调用的输入与输出被记录为转移样本(transitions)并存入缓冲区,而后处理模块(post process)将这些转移样本与对应的奖励信号汇总,格式化为与多种 RL 训练后端(如 SkyRL-train、VeRL、Tinker)兼容的数据。调度器(dispatcher)根据预定策略在三个阶段之间安排任务调度。
SKYRL-AGENT 被设计为一个模块化框架,用于大规模训练和评估工具使用智能体。系统架构如图 2 所示,由三个主要组件组成:以工具为中心的智能体循环(§3.1)用于灵活的工具和任务集成,细粒度调度器(§3.2)用于异构调度,以及后端桥接(§3.3)用于与强化学习训练系统的无缝连接。
3.1 以工具为中心的智能体循环 TOOL-CENTRIC AGENT LOOP
在 SKYRL-AGENT 中,智能体纯粹通过 OpenAI 风格的函数调用来行动。每个工具实现自己的执行逻辑并指定其运行时。现有的 Gym 风格环境可以通过将其 step() 包装为工具来集成,例如,Listing 1 展示了计算机使用智能体的工具实现。
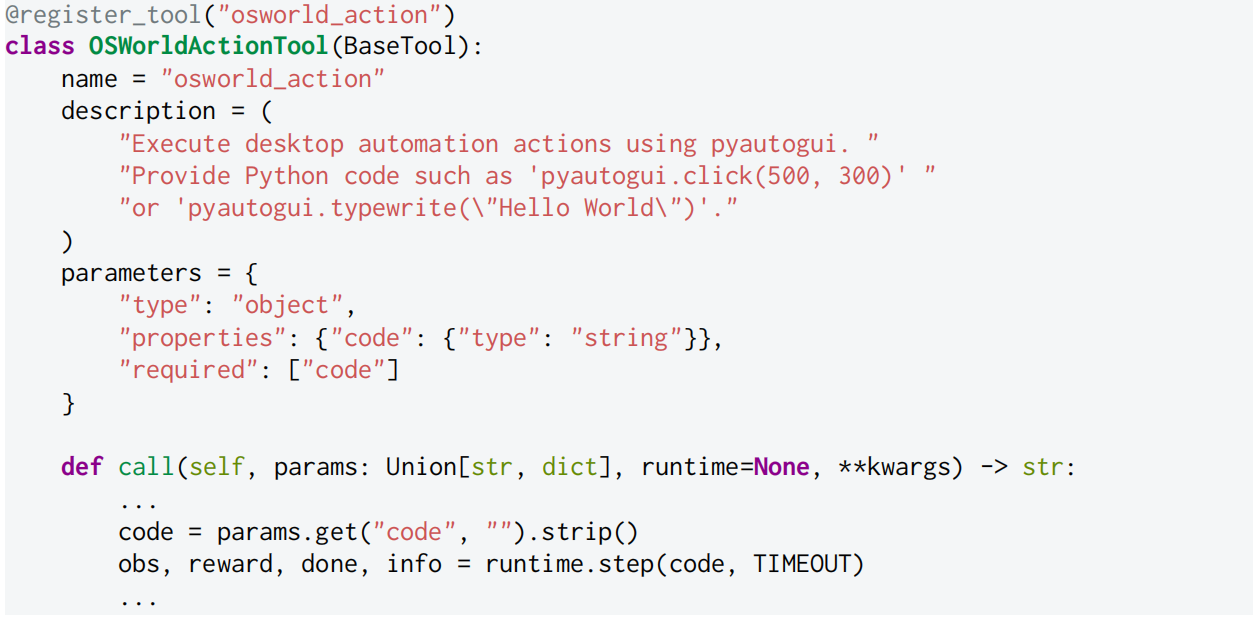
Listing 1:计算机使用智能体中桌面工具的示例定义
这种设计产生了几个实际好处:
(i)智能体和环境状态的统一管理:与以 Gym 为中心的智能体循环不同(后者通过临时代码在 env.step 之外管理智能体状态),SKYRL-AGENT 将其与其他操作一起纳入相同的工具抽象,使上下文管理等智能体状态修改操作模块化且可学习。
(ii)便捷的多任务训练:不同的数据集绑定到不同的工具集和验证器,无需修改智能体循环,允许运行器在单个训练作业中复用任务;
以及(iii)最小修改的任务集成:添加新任务只需提供一小组工具实现以及任务特定的指令构建器和验证器,保持智能体代码不变且无需触及系统的其他部分。
3.2 FINE-GRAINED HETEROGENEOUS SCHEDULING VIA THE DISPATCHER 通过调度器实现细粒度异构调度
多轮强化学习 rollout 包含具有不同成本和设备亲和性的操作。如图 2 所示,SKYRL-AGENT 将每个轨迹分解为阶段作业:① 运行时初始化,② 智能体运行,③ 奖励计算。调度器为每个阶段维护有界队列,并根据预定义的策略路由作业,在异构设备上平衡工作负载以提高整体资源利用率。
我们在统一接口下提供了几种调度策略,使从业者能够方便地选择最匹配其任务特征的策略,如图 3 所示。
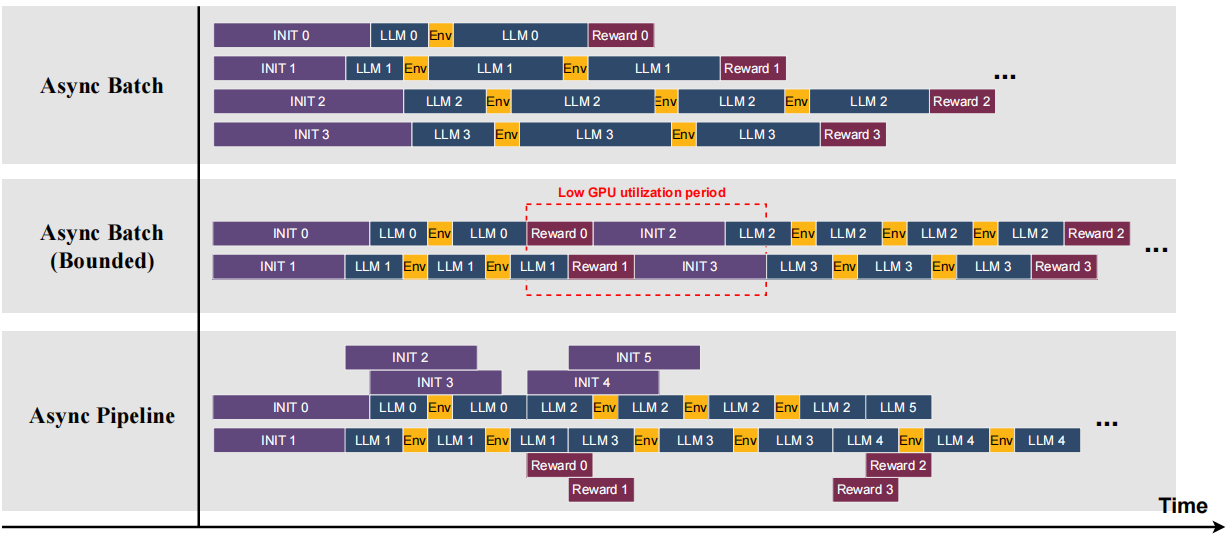
图3:支持的调度方法示例。Async Batch(异步批处理)通常用于推理任务,此类任务的运行时初始化和奖励计算开销较轻。Async Batch (Bounded)(有界异步批处理)按顺序调度轨迹并限制最大并发数,这会导致各阶段的 GPU 利用率不均,但在运行时重置开销较低的场景下仍然有效,例如计算机操作任务。Async Pipeline(异步流水线)通过将三个阶段重叠执行来维持较高的 GPU 利用率,适用于运行时或奖励阶段开销较大的任务。
异步批处理(Async Batch)并发启动所有轨迹,当运行时初始化和奖励计算都很轻量时很有效,例如在搜索集成推理任务中。
异步批处理(有界)(Async Batch (Bounded))将并发限制为可配置的池大小,适用于必须限制并发以防止运行时过载的环境,或者可以在 rollout 之间有效重用持久资源(如计算机使用任务中的长期虚拟机)的场景。
4 SWE 智能体 SWE AGENT
我们现在将介绍使用 SKYRL-AGENT 实现的 SA-SWE-32B 的完整训练方案。
4.1 BACKGROUND 背景
近期工作迅速推进了大语言模型(large language models,LLM)在自动化软件工程(software engineering,SWE)任务中的应用。
SWE-BENCH 已成为核心测试平台:给定一个真实的 GitHub 仓库和一个错误报告,系统必须生成一个补丁,并根据应用该补丁后项目的单元测试是否通过来进行评判。
Figure 4: Illustration of an SWE Agent.
当前 SWE 任务的解决方案分为两类。
基于智能体的系统[Agent-based systems]将模型置于具有一组工具(如 shell、搜索和文件查看器/编辑器)的可执行环境中,让它迭代地检查、编辑、构建和测试直到完成,如图 4 所示。这反映了开发者的工作流程,并支持增量诊断和修复。
相比之下,基于工作流的系统[Workflow-based systems](如 Agentless)规定了固定的流水线(如定位 → 修复 → 测试),将问题简化为一系列可验证的单轮子任务。
前者偏向灵活性和对实践的忠实度;后者简化了编排和评估,但以牺牲交互性和泛化能力为代价。
SKYRL-AGENT 旨在促进跨多种智能体任务的长时域、多轮、多工具智能体的端到端强化学习训练。
我们认为,在 SWE 中获得的工具使用能力(智能体必须迭代地检查、编辑和测试真实代码库)可以迁移到同样需要有状态工具交互的其他领域。
因此,在本工作中,我们更专注于以端到端的方式训练完整的交互循环。
4.2 TRAINING RECIPE 训练方案
Bootstrapping training with better tools.使用更好的工具引导训练
近期研究表明,智能体在错误定位方面经常遇到困难,这是软件工程任务中的关键瓶颈。我们观察到,这种失败很大程度上源于智能体无法使用命令有效地导航代码库。具体来说,智能体倾向于过度依赖直接查看文件,而不是利用搜索工具(如 grep、find),并且常常无法用信息丰富的模式或精确的关键词来精炼查询,导致反复无法定位相关上下文。
因此,智能体经常退回到使用查看工具逐块查看文件,或检索大量不相关的内容,这两种情况都会消耗过多的上下文并降低整体效率。
基于这些观察,我们实现了一个基于 AST 的搜索工具[AST-based search tool],提供强大的检索能力,支持模糊匹配和结构化模式搜索,受 LocAgent 启发。
为了进一步鼓励使用搜索工具,我们在每个搜索结果的末尾附加上下文提示(例如,建议下一步搜索哪些特定术语或模式),以引导智能体进行更精确的查询。
我们发现,这种工具增强[tool enhancements]对于高效的强化学习训练至关重要。没有这些增强,由于长时域[long-horizon]任务中固有的稀疏和延迟奖励,端到端强化学习变得极具挑战性。
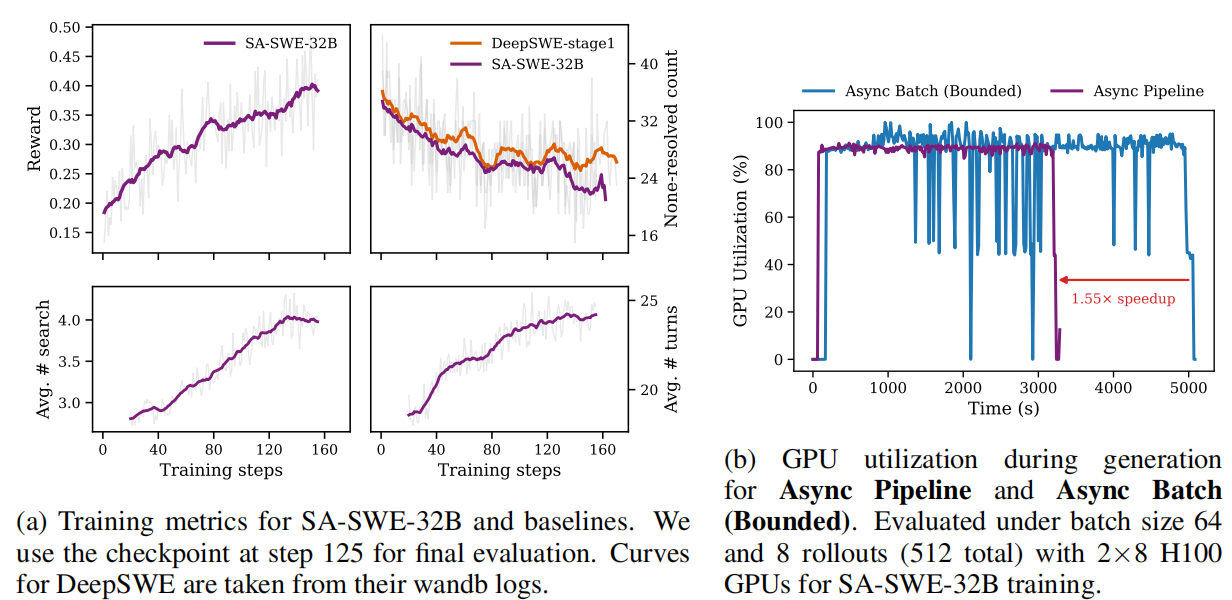
特别是,最小工具配置(如 Mini-SWE-Agent 中使用的仅 bash 设置)在 R2E-Gym 数据上表现出非常高的未解决率(例如 50/64),使学习过程具有挑战性且效率低下。相比之下,我们优化的、工具引导的设置显著加快了收敛速度,在仅 125 步强化学习训练内实现了与同等规模的先前模型相当甚至更高的性能(图 1a)。
为了评估泛化能力,我们消融了搜索工具。值得注意的是,模型表现出涌现的、内部实现的搜索行为,并在没有明确访问专用搜索工具的情况下达到了相当的性能。
我们还在训练中观察到,随着训练的进行,每条轨迹的平均搜索调用次数稳步增加,表明智能体逐渐学会更多地依赖搜索来进行高效的代码定位,如图 1a 所示。
RL algorithms and hyper-parameters. 强化学习算法和超参数
为了稳定训练,我们采用完全在策略设置,其中训练批量大小等于小批量大小(均设置为 64),每个任务的 rollout 数量为 8。由于外部约束(如最大上下文长度(32K token)、步骤限制(50 轮))而终止的轨迹在梯度更新期间被屏蔽,以防止模型对具有更多操作或推理步骤的轨迹产生偏见。
重要的是,这种屏蔽不会修改奖励或优势估计;它只是将这些样本从梯度计算中排除。
遵循先前的工作,我们应用留一法优势估计,并在优势计算中移除标准差和长度归一化。
我们禁用 KL 和熵损失,并使用 1e-6 的学习率进行训练。
Qwen3 聊天模板被修改以保留先前轮次的"思考",保持跨步骤的推理连续性。
Hints for agent to recover and proceed. 帮助智能体恢复和继续的提示
多轮智能体强化学习经常遭受智能体陷入重复或无效行为的困扰。先前的工作(如 SWE-Gym 和 Kimi-Dev)观察到,从通用预训练模型开始可能导致脆弱的行为:无法调用工具、生成无或不正确的函数调用,或在没有进展的情况下循环类似的操作。
智能体还可能失去对任务上下文或剩余步骤的跟踪,并倾向于在未达到最大轮次或上下文限制的情况下过早停止解决问题。
在训练期间,提示作为结构化线索引入,帮助智能体从失败的操作中恢复并重新进入有效轨迹。这些提示包括关于工具执行失败时采取潜在操作的建议、剩余步骤预算或上下文窗口即将超出的通知、对无效或不完整函数调用的纠正,或提示重新检查失败的编辑。
这些提示大幅提高了轨迹质量,稳定了 rollout 收集,并增加了用于策略优化的成功轨迹比例。
4.3 EVALUATIONS 评估
为了展示我们强化学习训练的有效性,我们在 4 个代表性的智能体基准上评估 SA-SWE-32B。这些包括 SWE-Bench Verified 作为域内评估,以及三个域外基准:Terminal-Bench、WebArena 和 BrowseComp-Plus,它们评估模型在涉及命令行推理、网页导航和搜索集成推理的多样化交互环境中的泛化能力。
SWE-Bench Verified
我们在 SWE-Bench verified 上评估 SA-SWE-32B 和几个基线模型,使用简单的 ReAct 框架,模型仅提供 bash 工具和文件编辑器工具²。
最大上下文长度设置为 40K(Qwen3-32B 的默认值),最大步数设置为 100。
主要结果报告在表 2 中。
我们强调,SA-SWE-32B 在 SWE-Bench Verified 上,在端到端交互评估设置下,在其规模的开放方案模型中实现了最先进的性能,展示了强大的智能体工具使用能力,同时产生的训练成本大幅降低,并且不依赖于从更强教师模型的蒸馏。
在基线模型中,SWE-agent-LM-32B 是从 Qwen2.5-Coder-32B-Instruct 在 Claude Sonnet 3.7 生成的 5,016 条 SWE-smith 轨迹上微调得到的。
另一方面,DeepSWE 使用默认的 R2E-Gym 框架,在相同的 4.5K R2E-Gym 数据集上纯粹通过强化学习训练。与 DeepSWE 相比,我们通过工具引导的强化学习增强训练方案,显著提高了训练效率。
如图 1a 所示,SA-SWE-32B 的未解决率始终保持较低且下降速度快于 DeepSWE。
结合 §3.2 中引入的系统级优化,我们的方法在提供卓越性能的同时,训练成本降低了 50%。像 Kimi-dev 和 SWE-Swiss 这样在 Agentless 框架下训练的模型,在 ReAct 设置中难以遵循工具调用指令,导致分数大幅低于其原始工作中报告的分数,因此我们仅将其报告的结果包含在表中供参考。
表2:参考模型与开源 SWE 模型在 SWE-Bench Verified 上的 Pass@1 性能。"–" 表示数据不可用;"×" 表示结果已省略。所报告的成绩均取自对应的论文或博客;由于不同工作采用了各异的框架和评测设置,各数字之间可能并不严格可比。Simple ReAct 指一个仅暴露 bash 工具和文件编辑工具的最简 ReAct 智能体循环,模型每个实例仅生成一个补丁。
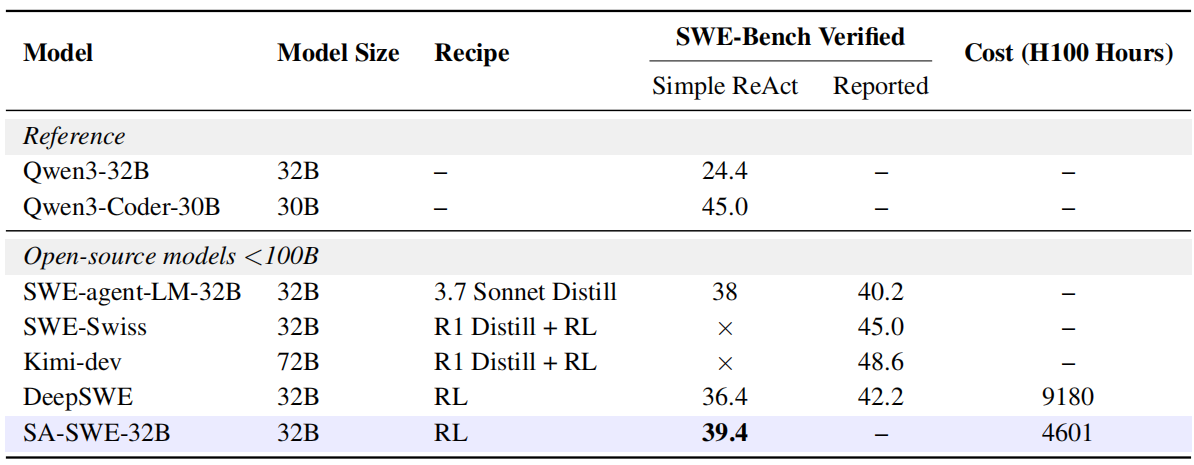
报告的分数取自相应的论文/博客;由于不同的工作使用不同的框架和评估设置,这些数字可能不完全可比。Simple ReAct 表示最小的 ReAct 智能体循环,仅暴露 bash 工具和文件编辑工具,模型每个实例只生成一个补丁。
Terminal-Bench
Terminal-Bench(版本 0.1.1)是一个命令行交互基准,旨在评估智能体在需要顺序命令执行、环境操作和输出验证的系统级任务上的表现。它包含 80 个任务,涵盖软件工程、系统管理和安全等类别,衡量智能体导航文件系统、执行 shell 命令和完成多步技术工作流的能力。
在我们的评估中,我们使用 OpenHands 智能体³来比较基线 Qwen3-32B 模型和 SA-SWE-32B。
WebArena
WebArena 是一个基于网页的交互基准,旨在评估智能体在多个领域的真实网站导航和任务完成上的表现。它包含 812 个任务,涵盖电子商务、社交论坛、协作软件和内容管理系统,衡量智能体解释网页界面、执行多步工作流并通过浏览器交互实现指定目标的能力。
该基准使用具有动态内容的完全功能网站来模拟真实世界的网页自动化场景。
在我们的评估中,我们比较基线 Qwen3-32B 模型和 SA-SWE-32B。
BrowseComp-Plus
BrowseComp-Plus 是一个面向搜索的基准,旨在评估智能体在迭代搜索、推理和规划任务上的表现。它使用固定的、经人工验证的语料库,包含支持性文档和困难负例文档,以确保公平和可重复的评估。
该基准包含 830 个问题,衡量智能体规划多步搜索、对检索证据进行推理并生成准确最终答案的能力。在我们的评估中,我们使用 Qwen3-Embedding-8B 作为检索器,并配置搜索工具返回前 5 个搜索结果。
Table 3: SA-SWE-32B's performance on other tasks.
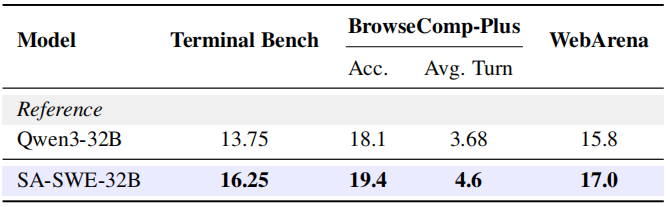
如表 3 所示,SA-SWE-32B 在所有基准上都展示了优于基础模型的性能。
在 SWE 智能体训练期间(参见图 1a),我们观察到平均搜索调用次数从 3 增加到 4,平均轮数从 18 增长到 25,表明随着训练的进行,智能体学会更多地依赖外部搜索和迭代推理。值得注意的是,在需要跨多个文档进行广泛搜索和推理的 BrowseComp-Plus 上,我们的模型虽然仅在 SWE 任务上训练,但通过比基础模型进行更多搜索调用而表现出类似的趋势。



 30
30 0
0


 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)