LangChain开源框架应对长任务挑战,Deep Agents如何解决上下文管理难题
这是最有技术含量的一个策略,包含两个部分。首先,由另一个 LLM 生成结构化摘要,包括会话意图、已创建的产出物、下一步计划等关键信息,这个摘要保留在上下文中。同时,完整的对话历史被归档到文件系统,以备需要时恢复。这种设计的精妙之处在于:摘要提供了足够的上下文让 Agent 继续工作,而完整历史的归档则确保了关键细节不会真正丢失。
Deep Agents SDK 的完整代码已在 GitHub 开源。随着 AI Agent 承担的任务越来越复杂,上下文管理将成为决定 Agent 能力边界的关键因素。这套方案提供了一个很好的起点。
当 AI Agent 需要处理越来越长的任务时,一个棘手的问题浮出水面:LLM 的上下文窗口是有限的。
任务执行时间越长,积累的对话历史和工具调用结果就越多,最终会撑爆上下文窗口。更糟糕的是,即使没有超出限制,过长的上下文也会导致"上下文腐烂"(context rot)——模型开始遗忘早期的重要信息,甚至偏离最初的目标。
LangChain 团队最近开源了 Deep Agents SDK,专门解决这个问题。这个框架赋予 Agent 规划能力、子 Agent 生成能力,以及文件系统集成,使其能够处理复杂的长时间运行任务。其中最核心的贡献,是三种上下文压缩技术。
三种上下文压缩策略
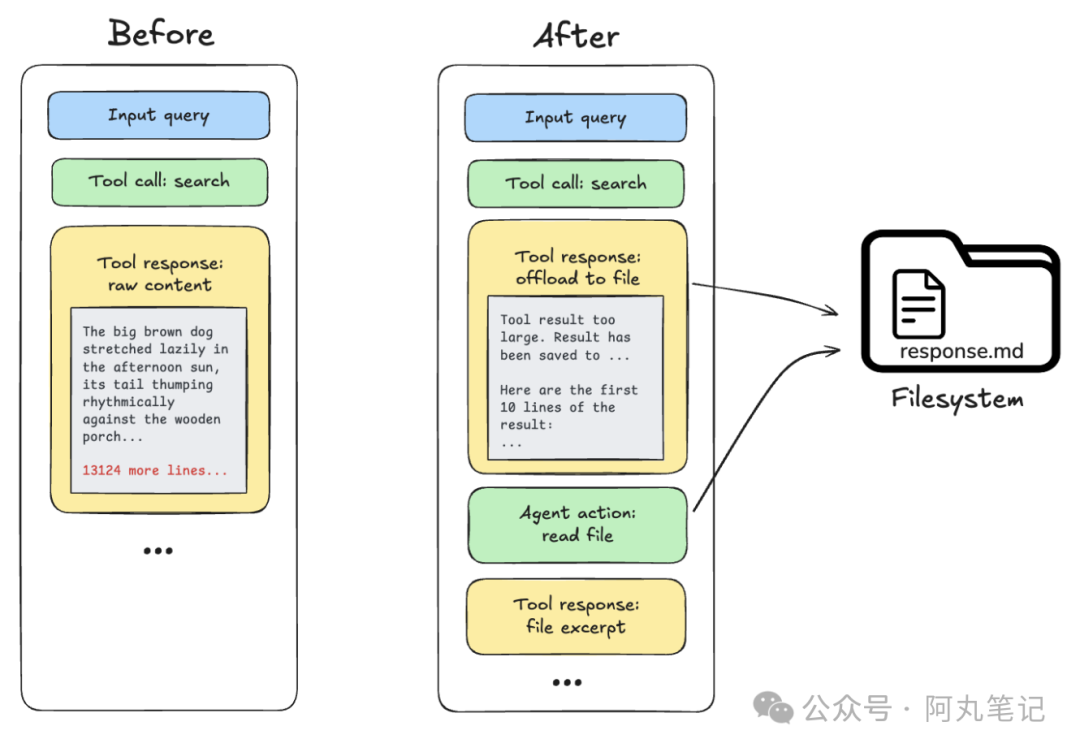
策略一:卸载大型工具输出
当工具返回的结果超过 20,000 tokens 时,系统会自动将完整内容存储到文件系统中,只在活跃上下文中保留一个引用指针和前 10 行的预览。
这样 Agent 知道数据在哪里,需要时可以随时读取,但不会让这些大块数据占用宝贵的上下文空间。
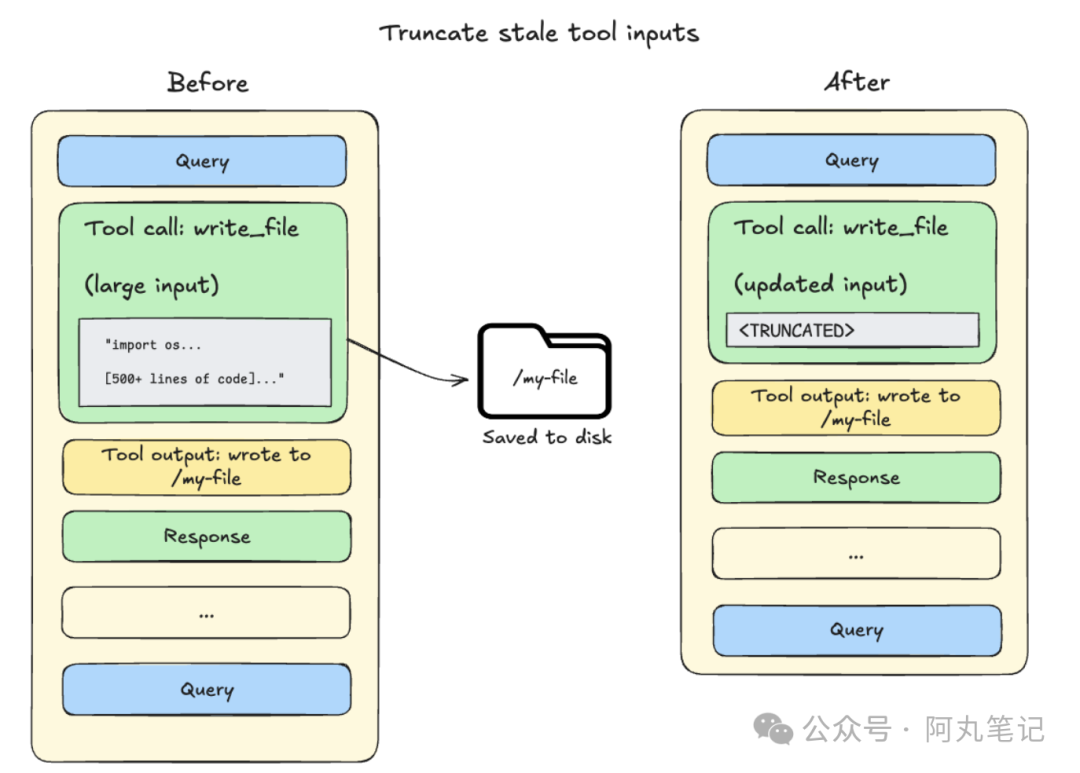
策略二:卸载大型工具输入
当上下文使用量达到 85% 容量时,系统会对历史记录中较早的文件写入和编辑操作进行截断,用文件系统指针替代完整内容。
这是一种渐进式压缩——越老的操作越可能被压缩,而最近的操作保持完整。
策略三:对话摘要
这是最有技术含量的一个策略,包含两个部分。
首先,由另一个 LLM 生成结构化摘要,包括会话意图、已创建的产出物、下一步计划等关键信息,这个摘要保留在上下文中。
同时,完整的对话历史被归档到文件系统,以备需要时恢复。
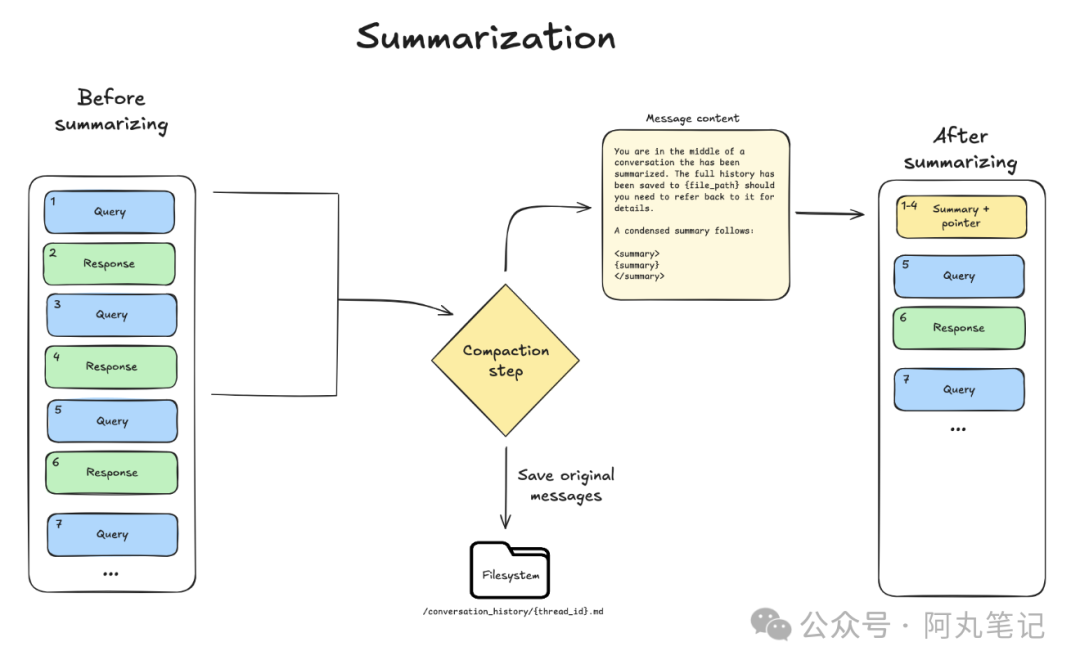
这种设计的精妙之处在于:摘要提供了足够的上下文让 Agent 继续工作,而完整历史的归档则确保了关键细节不会真正丢失。
如何验证压缩效果
上下文压缩最大的风险是信息丢失。LangChain 团队为此设计了专门的评估策略。
他们使用"大海捞针"测试来验证信息恢复能力——在压缩后的上下文中,Agent 是否仍然能找到早期对话中的关键信息?
为了放大测试信号,他们会故意将压缩阈值从 85% 调低到 10-20%,让压缩更频繁地触发,从而暴露潜在问题。
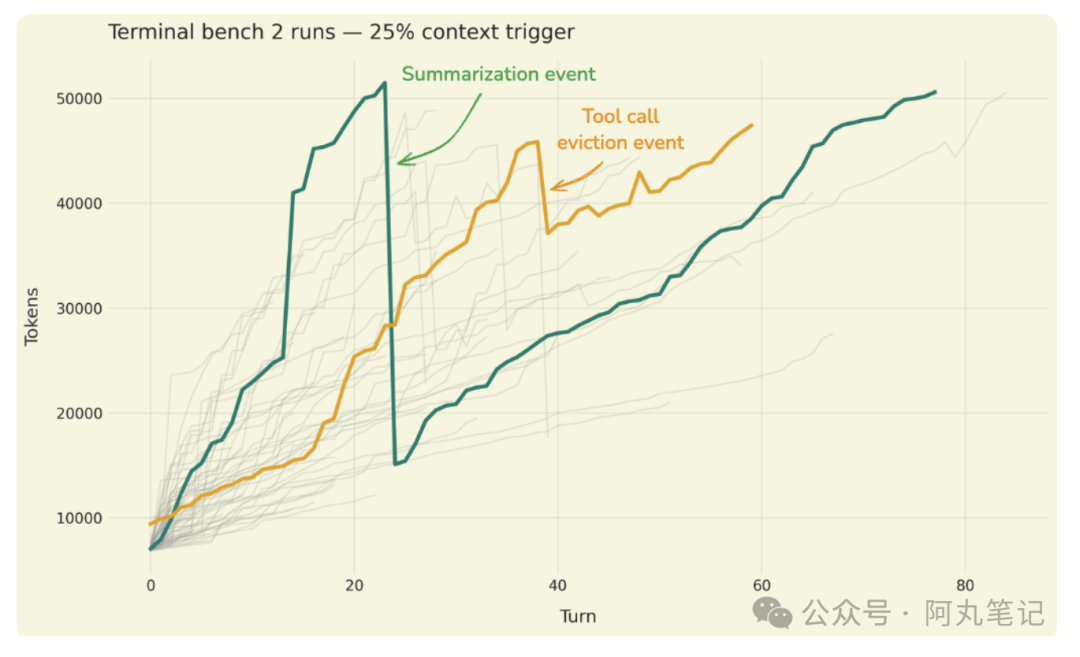
另一个重点测试是摘要完整性检查。摘要是否准确捕捉了会话的核心要素?是否遗漏了影响后续决策的关键信息?
最隐蔽的失败模式:目标漂移
LangChain 团队特别警告了一种失败模式:目标漂移(goal drift)。
这是上下文压缩最隐蔽的副作用——Agent 在压缩后仍然能正常工作,但逐渐偏离了用户最初的意图。表面上看一切正常,实际上 Agent 已经在解决一个略有不同的问题。
这也是为什么结构化摘要如此重要。摘要中明确包含"会话意图"这一字段,就是为了在压缩后帮助 Agent 保持方向感。
实践建议
LangChain 团队给出了三条实践建议:
• 先建立基线 - 在真实任务上测试 Agent 的基准表现,再去压力测试单个功能
• 验证信息恢复 - 确保 Agent 在压缩后仍能访问关键信息
• 监控目标漂移 - 定期检查 Agent 是否仍在解决最初的问题
Deep Agents SDK 的完整代码已在 GitHub 开源。随着 AI Agent 承担的任务越来越复杂,上下文管理将成为决定 Agent 能力边界的关键因素。这套方案提供了一个很好的起点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献264条内容
已为社区贡献264条内容

所有评论(0)