VSI bench介绍
文章标题:Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces单位:纽约大学团队:李飞飞,Saining Xie文章提出了一个新的任务,就是给定一段视频,需要MLLM对该视频进行空间推理包括:空间中的物体的距离,物体的个数,物体的尺度大小等等文章结论证明显示的文字思维链不能提
文章标题:Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
单位:纽约大学
团队:李飞飞,Saining Xie
文章提出了一个新的任务,就是给定一段视频,需要MLLM对该视频进行空间推理
包括:空间中的物体的距离,物体的个数,物体的尺度大小等等

文章结论证明显示的文字思维链不能提升模型效果,而隐式的cognition map可以增强模型的空间尺度理解能力
Visual-Spatial Intelligence
Visual-Spatial Intelligence -> VSI,基于视觉的空间智能
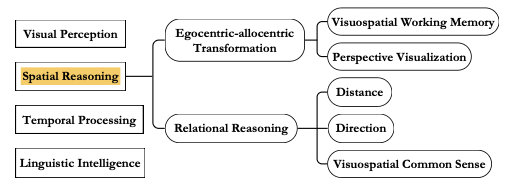
空间推理包括两个部分:第一个是视角变换,第二个是空间关系推理
VSI bench
本文提出的VSI bench 包括了5000个问题对。包含288个真实室内场景(288条video)
数据集来源为Scannet,Scannet++和ARKitScenes
ARKitScenes 150 samples
ScanNet++ 50 samples
ScanNet 88 samples
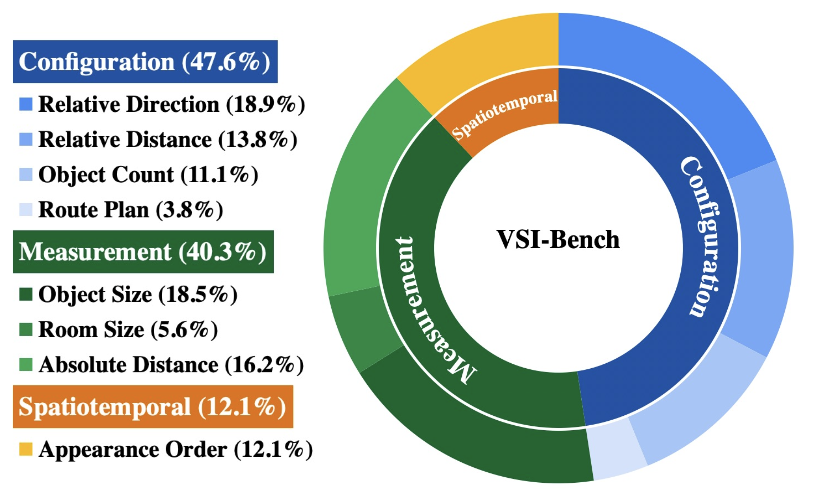
数据集被划分为了3个不同的任务种类,包括了8种不同的任务
1,空间布局:包括相对方向,相对距离,物体计数,路径规划
2,空间测量:物体的大小,房间的大小,绝对距离
3,时空理解: 需要知道物体出现的相对顺序
8种问题的模板:
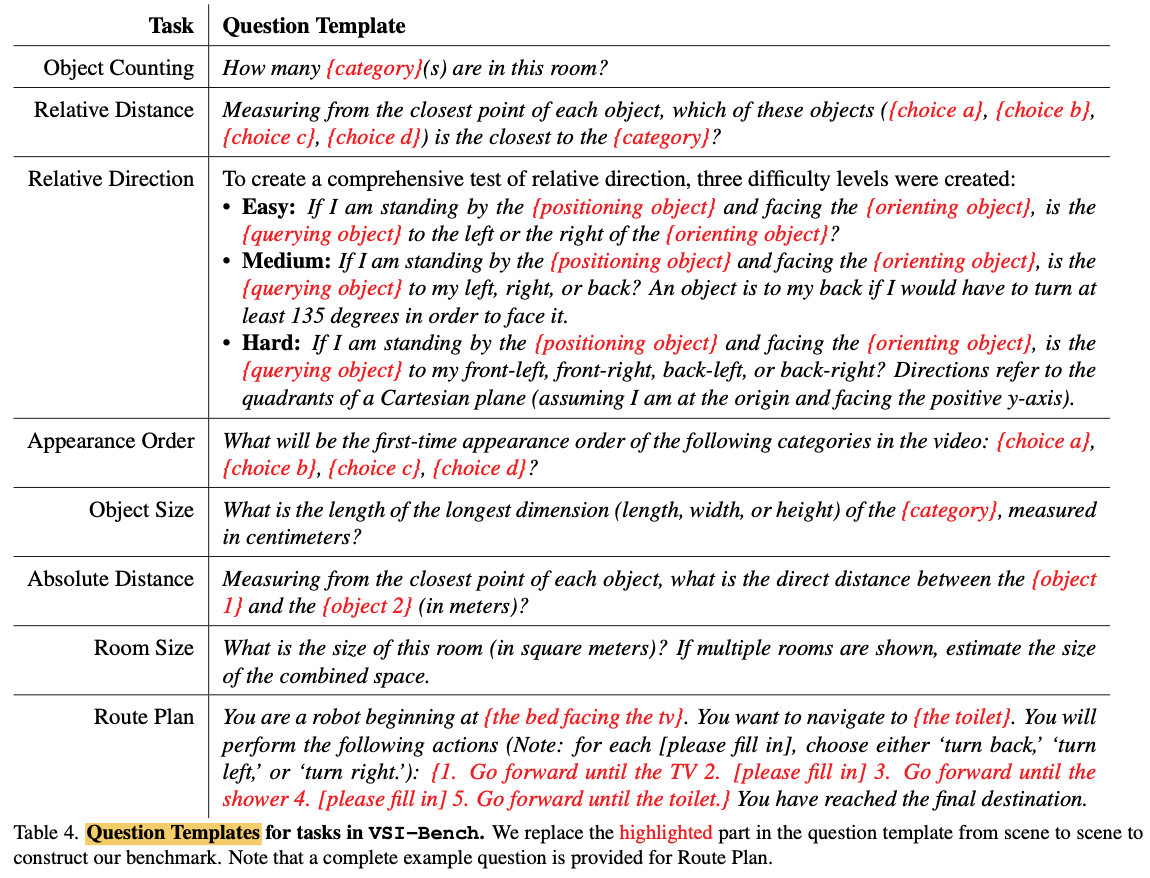
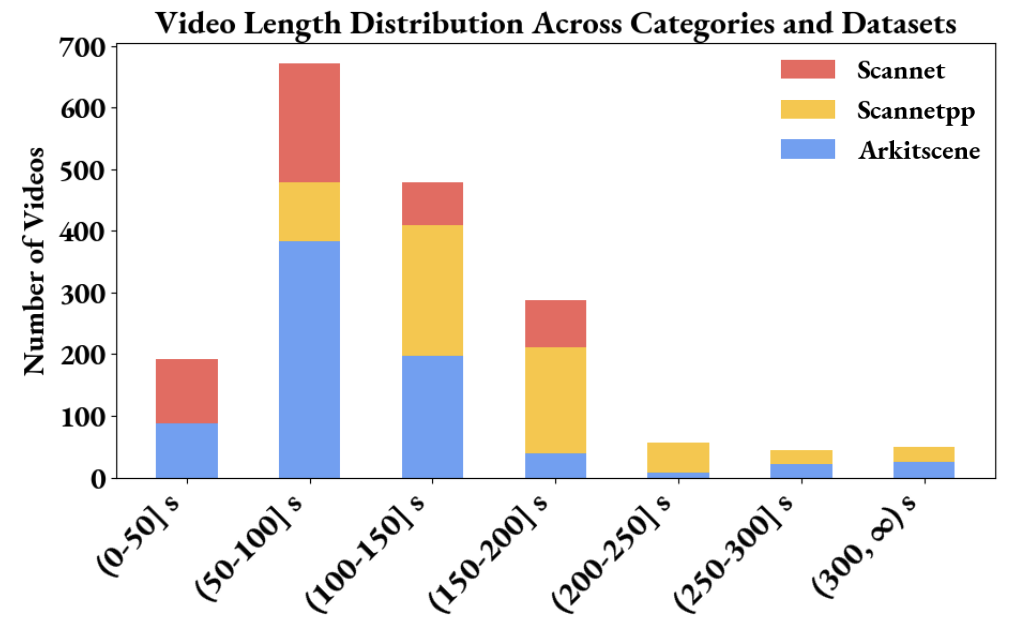
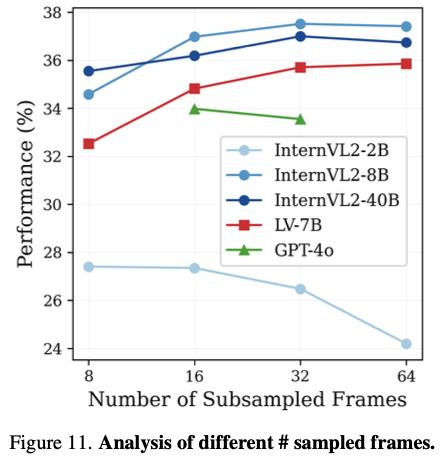
数据集视频的时间在1分钟到5分钟不等,但对于大部分方法实际上只会使用抽取其中的32帧
评估方式
在VSI bench数据集中,问题的回答只有两种:选择题或者数字填空题:Multiple-Choice Answer (MCA) or Numerical Answer (NA) format
对于数字的回答,使用Mean Relative Accuracy (MRA)
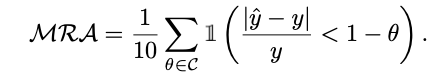
VSI bench还有一个tiny的版本
a subset of 400 questions (50 per task)
benchmark:
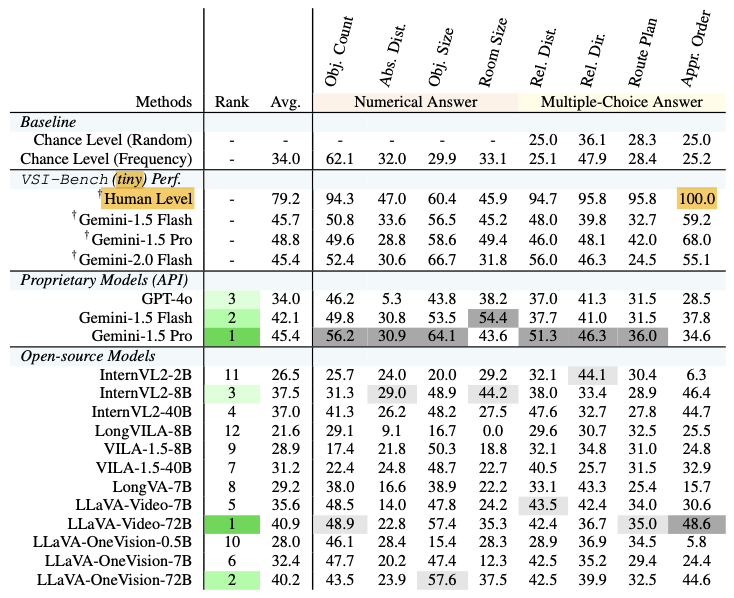
实验
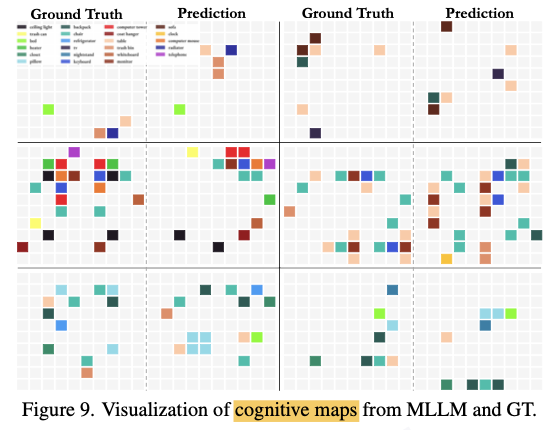
作者让Gemini-1.5 Pro通过文字的方式输出cognitive maps,来判断模型的mental representation。但这只是让模型显式的输出这个cognitive map,其实模型在推理时应该是在内部具备这个建模能力的。(思考:是否可以先显式的训练这部分的建模能力,然后再变成隐式的推理?)

实验证明通过prompt Gemini-1.5 Pro在回答问题之前先generate cognitive map可以提升模型的性能
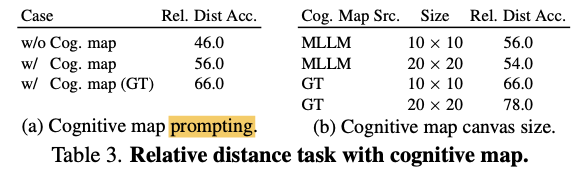
然而,如下表所示,在7B的模型上加入了cognitive map反而会掉点

虽然论文说的是输入video,但实际上处理时还是截取的其中的32帧(或者其他数量的帧数)
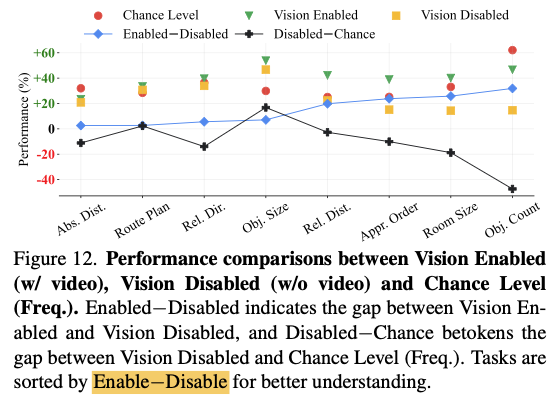
对于某些任务,输入vision和不输入vision基本上没有区别,说明数据集存在一定的局限性

把问题放到视频的前面会掉点。
在问题后面再次加入一次video会涨点,这说明模型还是需要推理能力的,而不是把视频看完一遍就直接输出答案
This finding suggests that, despite its remarkable capabilities, a powerful MLLM like Gemini still has suboptimal reasoning processes for Video QA.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)