企业级RAG教程 | langchain+AWS Bedrock+Zilliz,适合80%企业
本文将基于AWS Bedrock+Nova模型+Titan Embeddings+Zilliz Cloud+LangChain,为大家带来一套可以快速上手并落地的企业级RAG教程。
放眼当下,RAG已经成了90%企业落地大模型的技术首选。但问题是,从LLM到embedding到框架,再到向量数据库,基础组件已经多到不胜枚举。
于是一个尴尬的情况出现了:教程和组件都很好,但就是和企业的已有资源不搭。
比如,许多企业业务都跑在AWS这样的云平台上,因此,如何基于现有云平台构建一整套可落地的RAG系统变得尤为关键。
本文将基于AWS Bedrock+Nova模型+Titan Embeddings+Zilliz Cloud+LangChain,为大家带来一套可以快速上手并落地的企业级RAG教程。
01 架构设计思路
传统的大语言模型(LLM)在企业级应用中存在两大局限性:其一,知识时效性停止于模型训练阶段、无法获取最新数据与私有数据;其二,幻觉高、可解释性差。
在此背景下,RAG(检索增强生成)应运而生,通过结合外部知识检索与生成,RAG可以在不重新训练大模型的情况下就能获取最新的**动态知识、企业私有知识,并保证知识来源可追溯、更透明、更准确,**准确率提升25-40%,幻觉率降低了60%以上。
架构上,企业级RAG系统采用标准的MVC(Model-View-Controller)架构模式**,其中:**
- Model层负责数据处理和业务逻辑,包括文档模型、嵌入模型、向量存储模型和LLM模型;
- View层处理用户界面和数据展示,包含Web前端和API响应格式化器;
- Controller层管理请求处理和流程控制,涵盖RAG控制器、文档控制器和Lambda处理器。
这个架构的优势在于关注点分离,组件间的耦合度更低,系统能够灵活应对不同的前端需求和业务变化。
本次的RAG构建,核心组件一共有五部分:
- 查询处理引擎:负责用户输入的预处理与优化(查询扩展、意图识别、分解处理)。
- 向量检索引擎:使用Zilliz Cloud进行高效的语义搜索,支持混合检索和近似最近邻算法。
- 重排序模块:对检索结果进行排序,结合相关性得分和业务规则进行优化。
- 生成引擎:基于AWS Bedrock Nova模型,将上下文与用户查询结合,生成准确的回答。
- 事件驱动架构:使用Amazon EventBridge解耦组件间通信,确保系统响应性和可靠性。
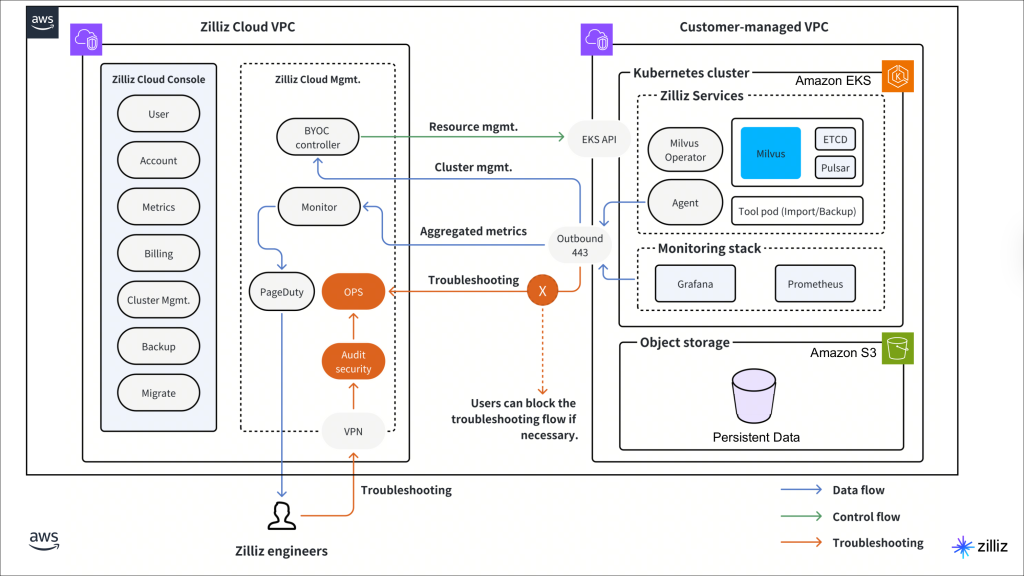
02 选型思路
基础设施层面,我们选择AWS Lambda作为核心计算服务,提供按需执行和自动扩缩容能力。系统中的每个功能组件(文档处理、向量化、检索、生成)都被设计为独立的Lambda函数,这种设计带来了低耦合,弹性伸缩的优势。
在此基础上,RAG的核心模块选型上,我们采用的是AWS****Bedrock+Nova模型+Titan Embeddings+Zilliz cloud,决策原因如下:
AWS****Bedrock优势:多模型支持。
AWS Bedrock平台支持来自Amazon、Anthropic、Met供应商超过50种Serverless模型和122种Marketplace模型。此外,在AWS Bedrock,开发者可以在不修改应用代码的情况下切换模型,便于A/B测试和性能比较。
Nova模型技术优势:性能与性价比兼顾。
- Nova Micro:文本专用,适用于低延迟和成本的任务(如文本摘要、翻译)。
- Nova Lite:支持多模态处理,处理图像、视频和文本输入。
- Nova Pro:高性能多模态模型,支持300K tokens的长上下文,适合复杂推理任务和大型文档处理。
Titan Embeddings优势:多模态、多语言
Titan Embeddings可以提供文本、图像等多种数据类型的高质量向量表示,并支持200多种语言,针对RAG场景优化。
Zilliz Cloud优势:基于开源产品打造、全托管开箱即用、无索引学习困扰
Zilliz Cloud基于开源Milvus构建的全托管向量数据库产品。很多向量数据库小白用户刚上手的时候,对于如何选择索引会有些摸不着头脑,Zilliz Cloud的AutoIndex可以根据数据特征和系统状态自动帮助用户动态调整索引策略。此外,Zilliz Cloud的Cardinal搜索引擎实现了10倍于传统向量数据库的检索速度,同时支持亿级向量规模的实时检索。
03 开发实践与LangChain集成
3.1 环境搭建与配置
AWS CDK基础设施示例代码
企业级RAG系统 采用基础设施即代码(IaC)方法进行部署和管理,AWS CDK(Cloud Development Kit)提供了强大的基础设施定义能力。系统的CDK配置包含了Lambda函数、API Gateway、S3存储、CloudFront分发等核心组件的定义。
# 核心Lambda函数配置
lambda_function = lambda_.Function(
self,
"RAGQueryFunction"
,
runtime=lambda_.Runtime.PYTHON_3_9,
memory_size=
3008
,
# 优化内存配置
timeout=Duration.seconds(
30
),
reserved_concurrency=
100
,
# 并发控制
environment={
"ZILLIZ_ENDPOINT"
: self.zilliz_endpoint,
"BEDROCK_MODEL_ID"
:
"amazon.nova-pro-v1:0"
}
)
CDK Bootstrap过程是系统部署的关键步骤,创建了必要的AWS资源,包括S3存储桶、IAM角色和SSM参数。项目采用了多环境支持,通过CDK的堆栈管理实现开发、测试和生产环境的隔离部署。
Zilliz Cloud环境配置
Zilliz Cloud的配置涉及集合创建、索引优化和连接管理三个核心环节。系统采用1024维向量空间,选择HNSW索引以平衡检索精度和性能。
# Zilliz连接配置
connections.connect(
alias
=
"default"
,
uri=ZILLIZ_ENDPOINT,
token=ZILLIZ_TOKEN,
timeout
=30
)
# 创建优化的collection
collection = Collection(
"rag_collection"
)
index_params = {
"metric_type"
:
"IP"
,
"index_type"
:
"HNSW"
,
"params"
: {
"M"
: 16,
"efConstruction"
: 128}
}
分区策略根据文档类型和业务域进行数据分割,提高检索效率。系统还配置了副本机制,确保高可用性和负载分担。
开发环境标准化
项目采用Makefile统一管理所有开发操作,提供一致的命令接口。开发环境包含了完整的CI/CD流水线,支持代码质量检查、类型检查和自动化测试。
# 标准化开发流程
install:
# 安装依赖
test
:
# 运行测试
lint:
# 代码检查
deploy:
# 部署应用
clean:
# 清理环境
3.2 核心功能实现
文档处理管道设计
文档处理管道采用分布式处理架构,支持多种文档格式的并行处理。管道包含文档解析、内容清洗、分块处理和元数据提取四个核心阶段。
class
DocumentProcessor
:
def
process
(
self
, document
):
# 文档解析
parsed_content =
self
.parse_document(document)
# 内容清洗和预处理
cleaned_text =
self
.clean_content(parsed_content)
# 智能分块
chunks =
self
.chunk_text(cleaned_text,
chunk_size=
1000
,
overlap=
100
)
# 元数据提取
metadata =
self
.extract_metadata(document)
return
processed_chunks
分块策略采用语义感知的分割方法,考虑段落边界和语义连贯性。系统支持自适应分块大小,根据文档类型调整最优参数。
向量化与存储优化
向量化过程使用AWS Bedrock的Titan Embeddings模型,支持批量处理以提高效率。系统实现了向量缓存机制,避免重复计算相同内容的向量表示。
class
VectorProcessor
:
def
__init__
(
self
):
self
.embedding_model =
TitanEmbeddings
()
self
.batch_size =
32
def
vectorize_batch
(
self
, texts
):
# 批量向量化
embeddings =
self
.embedding_model.embed_documents(texts)
# 向量标准化
normalized_embeddings =
self
.normalize_vectors(embeddings)
return
normalized_embeddings
存储优化策略包括向量压缩、索引预构建和分层存储。热点数据存储在高速访问层,冷数据归档至成本优化的存储层。
检索增强策略
检索策略采用混合检索方法,结合向量检索和关键词检索的优势。系统实现了多阶段检索流程:初检、精排和后处理。
class
HybridRetriever
:
def
retrieve
(
self
, query, top_k=
10
):
# 向量检索
vector_results =
self
.vector_search(query, top_k*
2
)
# 关键词检索
keyword_results =
self
.keyword_search(query, top_k*
2
)
# 结果融合
merged_results =
self
.merge_results(
vector_results, keyword_results
)
# 重排序
reranked_results =
self
.rerank(query, merged_results)
return
reranked_results[
:top_k
]
重排序机制使用Cross-Encoder模型对候选结果进行精细化排序。系统还支持上下文窗口优化,动态调整检索结果的上下文范围。
LangChain框架集成
from
langchain.chains
import
RetrievalQA
from
langchain.retrievers
import
VectorStoreRetriever
# 构建RAG链
qa_chain = RetrievalQA.from_chain_type(
llm=BedrockLLM(model_id=
"amazon.nova-pro-v1:0"
),
chain_type=
"stuff"
,
retriever=ZillizRetriever(
collection=collection,
search_params={
"top_k"
:
5
}
),
return_source_documents=
True
)
# 执行查询
result = qa_chain.invoke({
"query"
: user_question})
提示工程优化是LangChain集成的关键环节,系统使用LangChain Hub中的经过优化的RAG提示模板。记忆管理机制确保多轮对话的上下文连贯性。
系统还实现了流式处理能力,支持实时响应流和增量结果展示。错误处理和重试机制确保了系统的鲁棒性,能够处理各种异常情况。
04 生产部署与系统优化
4.1 无服务器架构部署
Lambda函数设计
企业级RAG系统的Lambda函数应该采用单一职责原则进行设计,每个函数专注于特定的业务逻辑。核心函数包括文档处理函数、向量化函数、检索函数和生成函数,各自独立部署和扩展。
# 查询处理Lambda函数
def
lambda_handler
(
event, context
):
try
:
# 初始化连接(在handler外部)
query = event[
'query'
]
# 向量检索
retriever = ZillizRetriever()
relevant_docs = retriever.search(query, top_k=
5
)
# LLM生成
llm = BedrockLLM()
response = llm.generate(query, relevant_docs)
return
{
'statusCode'
:
200
,
'body'
: json.dumps(response)
}
except
Exception
as
e:
logger.error(
f"Error:
{
str
(e)}
"
)
return
error_response(e)
内存配置优化根据函数职责进行差异化设置:查询函数配置1GB内存,文档处理函数配置2GB内存,确保最佳性价比。超时设置针对不同场景进行调优:查询函数30秒,文档处理函数300秒。
保留并发设置避免了冷启动对关键路径的影响,查询函数设置100个保留实例,确保用户请求的快速响应。
API Gateway配置
API Gateway作为系统的统一入口,提供RESTful API接口和请求路由功能。配置包括速率限制、身份验证和CORS设置,确保API的安全性和稳定性。
# API Gateway配置
endpoints:
- path: /query
method: POST
integration: lambda
rate_limit: 1000/min
auth: IAM
- path: /documents
method: POST
integration: lambda
rate_limit: 100/min
auth: IAM
缓存策略在API Gateway层实现,对相同查询的结果进行短期缓存,减少后端调用。请求验证确保输入参数的合法性,避免无效请求对后端系统的冲击。
CloudFront CDN优化
CloudFront配置实现了全球内容分发和静态资源缓存,显著提升了用户访问速度。CDN策略包括动静分离、智能路由和边缘缓存。
# CloudFront缓存配置
cache_behaviors
= [
{
'path_pattern'
:
'/api/*'
,
'ttl'
:
300
,
# API响应短期缓存
'headers'
: [
'Authorization'
]
},
{
'path_pattern'
:
'/static/*'
,
'ttl'
:
86400
,
# 静态资源长期缓存
'compress'
:
True
}
]
边缘位置优化确保全球用户都能获得低延迟访问,平均响应时间降至100毫秒以下。
4.2 性能优化
冷启动优化策略
冷启动是无服务器架构的核心挑战,系统采用多层优化策略进行应对。预热机制使用CloudWatch Events定期调用关键函数,保持执行环境的热度。
# 预热Lambda配置
def
warm_up_handler
(
event
, context
):
if
event
.
get
(
'source'
) ==
'aws.events'
:
return
{
'statusCode'
:
200
,
'body'
:
'warmed up'
}
# 正常业务逻辑
return
business_logic(
event
, context)
依赖优化通过减少包大小和选择轻量级库来缩短冷启动时间。连接池复用在全局作用域初始化数据库连接,避免重复连接开销。
Provisioned Concurrency为关键函数配置预配置并发,消除冷启动延迟。根据业务模式动态调整预配置实例数量,平衡性能和成本。
并发处理设计
系统采用分层并发控制策略,不同函数根据资源需求设置不同的并发限制。Lambda并发设置基于函数的资源密集程度:轻量级查询函数支持高并发,重计算文档处理函数限制并发以避免资源竞争
# 并发配置示例
functions_config = {
'query_function'
: {
'reserved_concurrency'
: 100,
'memory'
: 1024
},
'document_processing'
: {
'reserved_concurrency'
: 10,
'memory'
: 2048
}
}
异步处理机制使用SQS和SNS实现任务解耦,避免同步调用的级联失败。批处理优化将相似任务聚合处理,提高资源利用效率。
缓存机制实现
多层缓存架构包括L1内存缓存、L2 Redis缓存和L3 S3缓存。每层缓存针对不同的访问模式进行优化:
- L1缓存:Lambda函数内存中,TTL 5分钟,容量100MB
- L2缓存:Redis集群,TTL 1小时,容量1GB
- L3缓存:S3存储,TTL 1天,容量无限制
class
CacheManager
:
def
get
(
self
, key
):
# L1缓存查询
if
key
in
self
.
memory_cache:
return
self
.memory_cache[key]
# L2缓存查询
value =
self
.redis_client.get(key)
if
value:
self
.memory_cache[key] = value
return
value
# L3缓存查询
return
self
.s3_cache.get(key)
缓存预热策略基于历史查询模式,预先加载高频访问的数据。缓存失效机制确保数据一致性,支持主动更新和被动过期两种模式。
成本控制方案
按需计费优化通过精细化的资源配置实现成本控制。系统实现了动态资源调整,根据负载模式自动调整Lambda内存和超时设置。
Reserved Instance和Savings Plans用于稳定工作负载,可节省高达72%的计算成本。Spot Instance用于非关键的批处理任务,进一步降低成本。
# 成本优化配置
cost_optimization = {
'lambda_memory_optimization'
:
True
,
'auto_scaling'
:
True
,
'reserved_capacity'
: {
'query_functions'
:
50
,
'processing_functions'
:
5
}
}
4.3 监控与运维体系
关键指标监控
系统监控采用CloudWatch集成方案,收集完整的性能指标。核心监控指标包括:
- API响应时间:P50 < 1s,P95 < 3s,P99 < 5s
- 成功率:> 99.9%
- 并发用户数:实时监控
- 向量检索性能:< 200ms
- LLM生成时间:< 2s
# 自定义指标发送
def
send_metrics
(
metric_name, value, unit=
'Count'
):
cloudwatch = boto3.client(
'cloudwatch'
)
cloudwatch.put_metric_data(
Namespace=
'RAG/System'
,
MetricData=[{
'MetricName'
: metric_name,
'Value'
: value,
'Unit'
: unit,
'Timestamp'
: datetime.utcnow()
}]
)
日志分析系统
结构化日志记录可以考虑使用JSON格式,便于查询和分析。日志包含请求ID、时间戳、用户信息、性能指标和错误信息等关键字段。
故障排查机制
分布式追踪可以考虑使用AWS X-Ray实现端到端的请求跟踪,快速定位性能瓶颈。自动化告警基于关键指标设置阈值,支持多渠道通知。
# 告警规则配置
alerts
= [
{
'metric'
:
'ResponseTime'
,
'threshold'
:
3000
,
# 3秒
'comparison'
:
'GreaterThanThreshold'
,
'action'
:
'sns_notification'
},
{
'metric'
:
'ErrorRate'
,
'threshold'
:
1
,
# 1%
'comparison'
:
'GreaterThanThreshold'
,
'action'
:
'auto_scaling'
}
]
自愈能力可以考虑通过Lambda的自动重试和DLQ(死信队列)机制实现故障自动恢复。容量规划基于历史数据和增长趋势,提前进行资源扩容。
尾声
企业级RAG系统,原理很简单,但是具体的构建是一个涉及多个技术栈深度整合的复杂工程。做选型和落地,应当注重技术选型的前瞻性,但也要重点关注架构设计的可扩展性以及运维体系的完善性
这套AWS Bedrock+Zilliz cloud+langchain教程,适用80%de企业级RAG落地场景。
关于这套教程,大家有更多疑问,欢迎评论区留言交流。
附:完整代码如下
https://github.com/yincma/AWS-zilliz-RAG/tree/main
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2026 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2026 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献631条内容
已为社区贡献631条内容

所有评论(0)