以医疗行业为例,带大家理解什么是AI偏见测试
AI偏见指人工智能系统对特定群体(如性别、种族等)产生系统性不公平对待的现象。在医疗领域,AI偏见可能导致诊断不公、治疗延误等严重后果。测试重点在于发现不同群体间的性能差异(如诊断准确率差距14%),而非功能错误。调优流程包括:定位偏见根源(数据/算法/部署层面)、选择策略(数据重采样/公平性约束)、验证效果。推荐使用AIF360、Fairlearn等工具进行偏见检测和修正。医疗AI测试工程师需平

一、什么是AI偏见?(从测试视角理解)
官方定义
AI偏见是指人工智能系统在决策过程中,对特定群体(如性别、种族、年龄、地域等)产生系统性不公平对待的现象。如果大家想了解更多关于ai偏见的内容可以参考文章:
https://blog.csdn.net/liwenxiang629/article/details/155532279
关于ai偏见测试的测试报告模板可以参考文章:
https://blog.csdn.net/liwenxiang629/article/details/155532813
测试工程师的理解
- 不是bug,而是数据缺陷的放大器
- 传统测试无法发现(功能正常但结果不公平)
- 可能引发法律风险(违反《算法推荐管理规定》等法规)
AI偏见 ≠ 数据准确度问题
这是很多初学者的误区。
错误理解
"测试数据偏见 = 测试数据是否准确"
正确理解
"测试数据偏见 = 即使数据准确,AI对不同人群是否公平对待"
二、真实医疗业务场景详解
场景1:AI辅助诊断系统
- 功能:输入患者症状,输出疾病概率
- 偏见风险:对女性患者的胸痛症状,AI可能低估心脏病风险(因为训练数据中男性心脏病案例更多)
- 后果:女性患者被漏诊,延误治疗
场景2:智能分诊系统
- 功能:根据患者描述,分配就诊优先级
- 偏见风险:农村患者因表达方式不同,被分配到更低优先级
- 后果:急症患者等待时间过长
场景3:个性化治疗推荐
- 功能:根据患者特征推荐最佳治疗方案
- 偏见风险:老年人被系统性推荐保守治疗(因为训练数据中老年人接受激进治疗的案例少)
- 后果:老年患者失去最佳治疗机会
场景4:药物剂量计算
- 功能:根据体重、年龄等计算药物剂量
- 偏见风险:对少数民族患者剂量计算不准确(因为相关临床试验数据不足)
- 后果:用药过量或不足
三、测试目的:不是找bug,而是找"不公平"
| 测试类型 | 传统软件测试 | AI偏见测试 |
|---|---|---|
| 目标 | 功能是否正确 | 对不同群体是否公平 |
| 输入 | 边界值、异常值 | 不同人群的代表性样本 |
| 预期 | 输出符合规格 | 各群体性能指标差异在可接受范围内 |
| 成功标准 | 无错误 | 公平性指标达标 |
具体测试什么?
以AI诊断系统为例,你要测试:
# 假设这是你的测试结果
诊断准确率 = {
"男性": 92%,
"女性": 78%, # ⚠️ 差距14% - 存在性别偏见!
"城市患者": 90%,
"农村患者": 75% # ⚠️ 差距15% - 存在地域偏见!
}任务:发现这种不公平,并量化差异程度。
四、发现问题后的完整调优流程
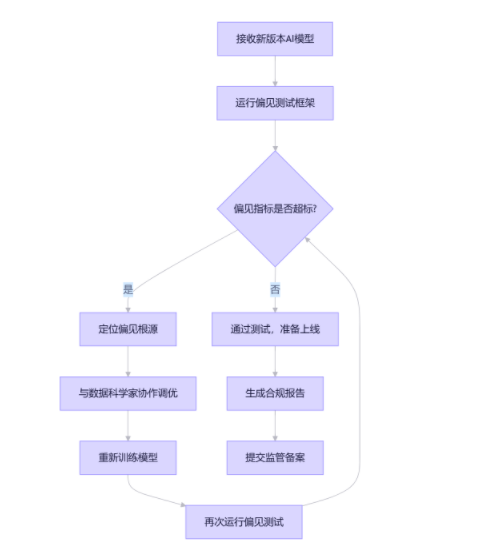
现在重点来了!发现偏见后不能直接修改模型代码,而是要走科学的调优流程:
调优流程图
发现问题 → 定位根源 → 选择策略 → 实施修复 → 验证效果 → 持续监控步骤1:定位偏见根源
偏见通常来自三个层面:
A. 数据层面偏见(最常见,占80%)
- 表现:某些群体样本太少
- 检测方法:
# 检查训练数据分布 print("训练数据中各群体比例:") print(train_data['gender'].value_counts(normalize=True)) print(train_data['region'].value_counts(normalize=True)) # 输出示例: # gender: 男性 75%, 女性 25% ← 严重不平衡! # region: 城市 85%, 农村 15% ← 样本不足!
B. 算法层面偏见
- 表现:算法本身对某些特征过度敏感
- 检测方法:特征重要性分析
# 查看哪些特征影响最大 feature_importance = model.feature_importances_ # 如果'gender'特征重要性异常高,说明算法过度依赖性别
C. 部署层面偏见
- 表现:生产环境数据分布与训练数据不同
- 检测方法:数据漂移检测
# 比较训练数据和生产数据分布 from scipy import stats ks_stat, p_value = stats.ks_2samp(train_data['age'], production_data['age']) if p_value < 0.05: print("年龄分布发生显著漂移!")
步骤2:选择调优策略
根据偏见根源选择对应策略:
数据层面偏见 → 数据重采样
方法1:过采样(Oversampling)
from imblearn.over_sampling import SMOTE
# 对少数群体进行过采样
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
# 重新训练模型
model.fit(X_resampled, y_resampled)方法2:欠采样(Undersampling)
from imblearn.under_sampling import RandomUnderSampler
# 对多数群体进行欠采样
undersampler = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = undersampler.fit_resample(X_train, y_train)方法3:合成数据生成
# 使用GAN生成少数群体样本(高级方法)
# 或使用简单的数据增强
def augment_minority_samples(data, minority_group, n_augment):
augmented = []
for _ in range(n_augment):
# 在合理范围内随机扰动特征值
sample = data[data['group'] == minority_group].sample(1)
augmented_sample = sample.copy()
augmented_sample['feature1'] *= np.random.normal(1, 0.1) # ±10%扰动
augmented.append(augmented_sample)
return pd.concat(augmented)算法层面偏见 → 公平性约束
方法1:预处理去偏
from aif360.algorithms.preprocessing import Reweighing
# 重新加权训练样本,使不同群体权重平衡
rw = Reweighing(unprivileged_groups=[{'gender': 0}],
privileged_groups=[{'gender': 1}])
dataset_transformed = rw.fit_transform(dataset_original)方法2:训练时约束
# 使用公平性正则化损失函数
def fair_loss(y_true, y_pred, sensitive_attr):
# 基础损失
base_loss = binary_crossentropy(y_true, y_pred)
# 公平性约束:不同群体的预测分布应相似
fairness_penalty = calculate_demographic_parity(y_pred, sensitive_attr)
return base_loss + 0.1 * fairness_penalty # 0.1是公平性权重
model.compile(loss=fair_loss, optimizer='adam')方法3:后处理校准
from sklearn.calibration import CalibratedClassifierCV
# 对不同群体分别校准预测概率
def group_specific_calibration(model, X_val, y_val, sensitive_attr):
calibrated_models = {}
for group in X_val[sensitive_attr].unique():
group_mask = X_val[sensitive_attr] == group
calibrator = CalibratedClassifierCV(model, method='isotonic', cv=3)
calibrator.fit(X_val[group_mask], y_val[group_mask])
calibrated_models[group] = calibrator
return calibrated_models步骤3:验证调优效果
调优后必须重新测试,确保:
- 偏见确实减少了
- 整体性能没有大幅下降
# 调优前后对比测试
def compare_bias_before_after(original_model, tuned_model, test_data):
tester = MedicalAIBiasTester('config/medical_config.yaml')
# 原始模型测试
original_results = tester.run_comprehensive_test(
original_model, test_data, 'label'
)
# 调优后模型测试
tuned_results = tester.run_comprehensive_test(
tuned_model, test_data, 'label'
)
# 对比关键指标
print("=== 偏见改善对比 ===")
for attr in ['gender', 'region']:
orig_gap = calculate_accuracy_gap(original_results['group_fairness'][attr])
tuned_gap = calculate_accuracy_gap(tuned_results['group_fairness'][attr])
print(f"{attr} 准确率差距:")
print(f" 调优前: {orig_gap:.2%}")
print(f" 调优后: {tuned_gap:.2%}")
print(f" 改善: {(orig_gap - tuned_gap)/orig_gap:.2%}")
return tuned_results五、实用工具推荐
开源工具包
1. IBM AI Fairness 360 (AIF360)
- 用途:全面的偏见检测和缓解
- 安装:
pip install aif360 - 医疗适用性:⭐⭐⭐⭐⭐
from aif360.datasets import BinaryLabelDataset
from aif360.metrics import ClassificationMetric
# 创建公平性数据集
dataset = BinaryLabelDataset(
favorable_label=1,
unfavorable_label=0,
protected_attribute_names=['gender'],
df=test_data
)
# 计算公平性指标
metric = ClassificationMetric(dataset, dataset_pred,
unprivileged_groups=[{'gender': 0}],
privileged_groups=[{'gender': 1}])
print("统计均等性差异:", metric.statistical_parity_difference())
print("机会均等性差异:", metric.equal_opportunity_difference())2. Google What-If Tool
- 用途:可视化偏见分析
- 特点:无需编码,交互式探索
- 医疗适用性:⭐⭐⭐⭐
3. Microsoft Fairlearn
- 用途:算法层面的公平性约束
- 安装:
pip install fairlearn - 医疗适用性:⭐⭐⭐⭐
from fairlearn.reductions import ExponentiatedGradient
from fairlearn.reductions import DemographicParity
# 在训练时强制满足人口均等性
mitigator = ExponentiatedGradient(
LogisticRegression(),
constraints=DemographicParity()
)
mitigator.fit(X_train, y_train, sensitive_features=sensitive_features)医疗专用工具
1. Healthcare AI Fairness Toolkit
- GitHub开源项目,专为医疗场景设计
- 包含HIPAA合规的数据处理模块
2. Clinical Trial Diversity Analyzer
- 分析临床试验数据的多样性
- 帮助识别训练数据中的群体覆盖不足
六、完整工作流程示例
假设你是某医院AI团队的测试工程师:
日常工作流程
具体操作步骤
-
每周一:运行自动化偏见测试
python scripts/run_weekly_bias_check.py -
发现问题:比如发现"农村患者诊断准确率低15%"
-
分析原因:
- 检查训练数据:农村患者样本只占8%
- 检查特征重要性:地址特征权重过高
-
提出解决方案:
- 建议数据团队收集更多农村患者数据
- 临时方案:对农村患者样本进行过采样
-
验证效果:
- 调优后农村患者准确率提升到85%
- 整体准确率从88%降到86%(可接受)
-
文档记录:
- 更新偏见测试报告
- 记录调优过程供监管审查
七、给初学者的建议
从简单开始
- 先关注数据层面偏见(最容易理解和解决)
- 选择1-2个敏感属性重点测试(如性别、年龄)
- 使用现成工具(AIF360、Fairlearn)
学习路径
第1周:理解偏见概念 + 运行示例代码
第2周:学习AIF360工具包
第3周:在自己的项目中实施简单偏见测试
第4周:尝试数据重采样调优注意事项
- 不要追求绝对公平:完全消除偏见可能损害整体性能
- 业务场景决定阈值:诊断系统比推荐系统的公平性要求更高
- 持续监控很重要:偏见可能随时间重新出现
总结
大家现在应该明白了:
测试目的:确保AI对所有患者群体都公平,而不仅仅是准确
业务场景:诊断、分诊、治疗推荐等医疗核心环节
调优流程:定位→选择策略→实施→验证的科学闭环
实用工具:AIF360、Fairlearn等开源工具包
记住:作为测试工程师,大家不仅是质量守门员,更是患者权益的保护者。医疗AI的公平性直接关系到生命安全!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)