Agent架构解析与实战(八)--Episodic + Semantic Memory Stack
🚀 拒绝 AI "金鱼脑"!打造拥有 [情景 + 语义] 双重记忆的超级智能体
参考来源:all-agentic-architectures[1]
目录
- 架构定义
- 宏观工作流
- 应用场景
- 优缺点分析
- Neo4j 配置指南
- 代码实现详解
- 测试与验证
- 总结与核心要点
1. 架构定义
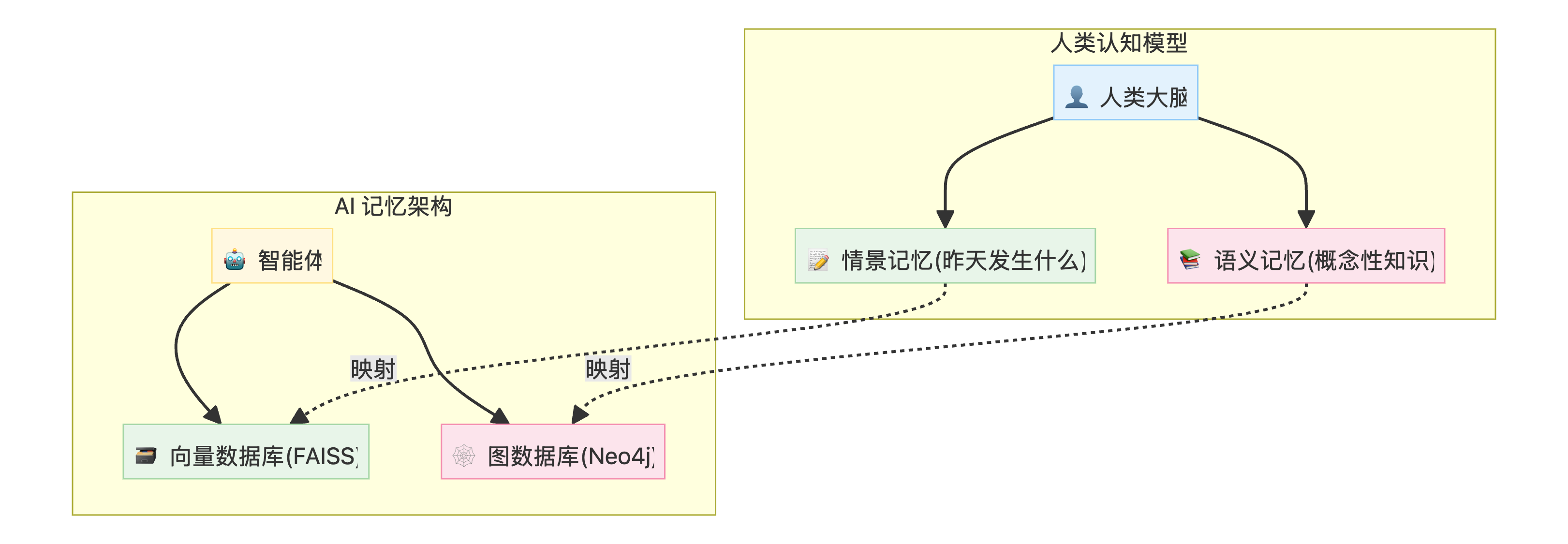
Episodic + Semantic Memory Stack 是一种结合两种长期记忆系统的智能体架构。这种设计模仿了人类认知模型,使 AI 系统能够维护持久的上下文信息,超越单次会话的限制。
两种记忆类型
| 记忆类型 | 描述 | 存储方式 | 回答的问题 |
|---|---|---|---|
| 情景记忆 (Episodic) | 特定事件或过去交互的记忆 | 向量数据库 (FAISS) | "发生了什么?" |
| 语义记忆 (Semantic) | 结构化的事实、概念和关系 | 图数据库 (Neo4j) | "我了解什么?" |
核心理念
[!IMPORTANT]
🎯 核心创新通过结合这两种记忆系统,智能体不仅能回忆过去的对话,还能构建关于用户和世界的丰富、互联的知识库,从而实现深度个性化和上下文感知的交互。
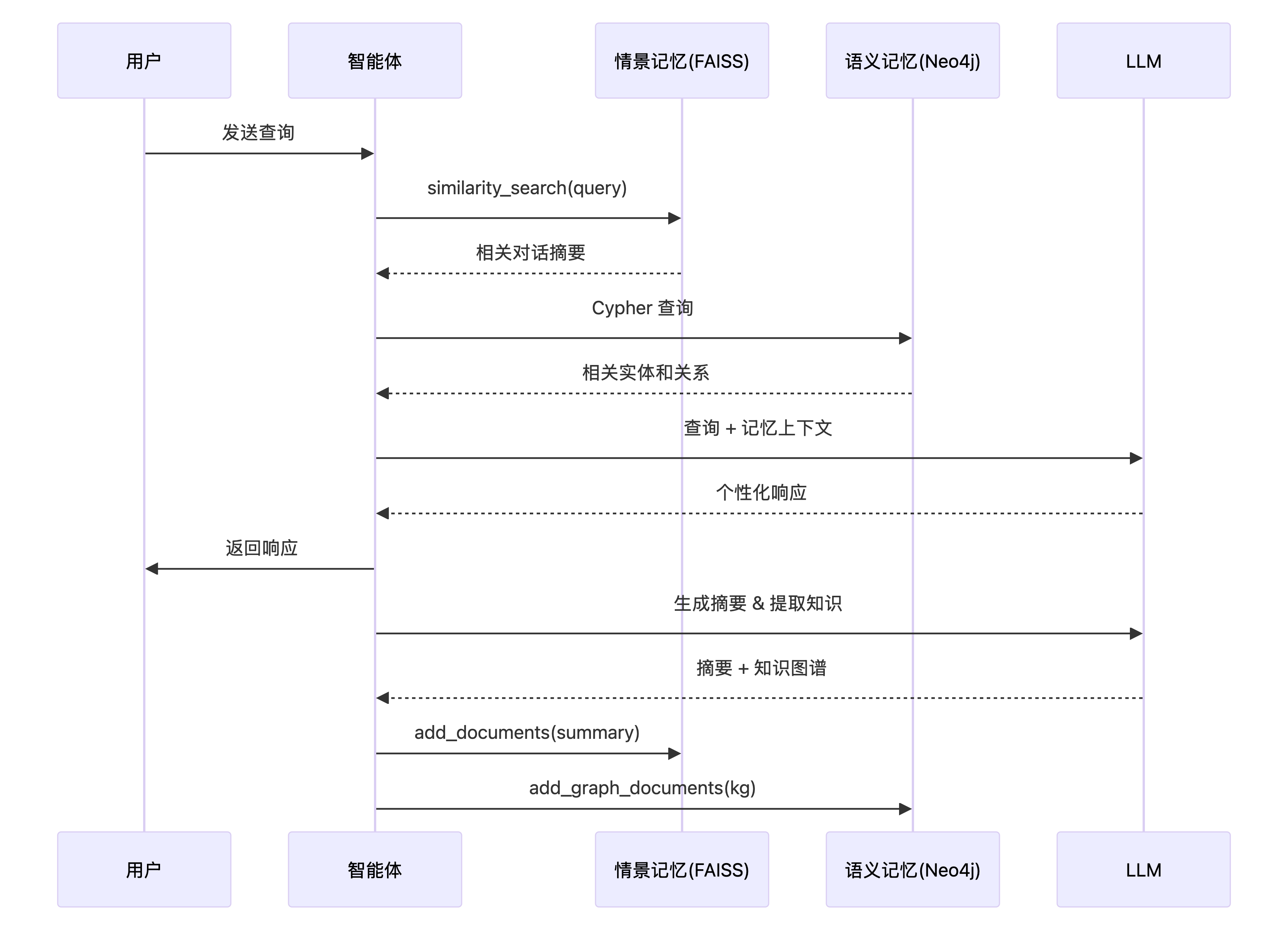
2. 宏观工作流
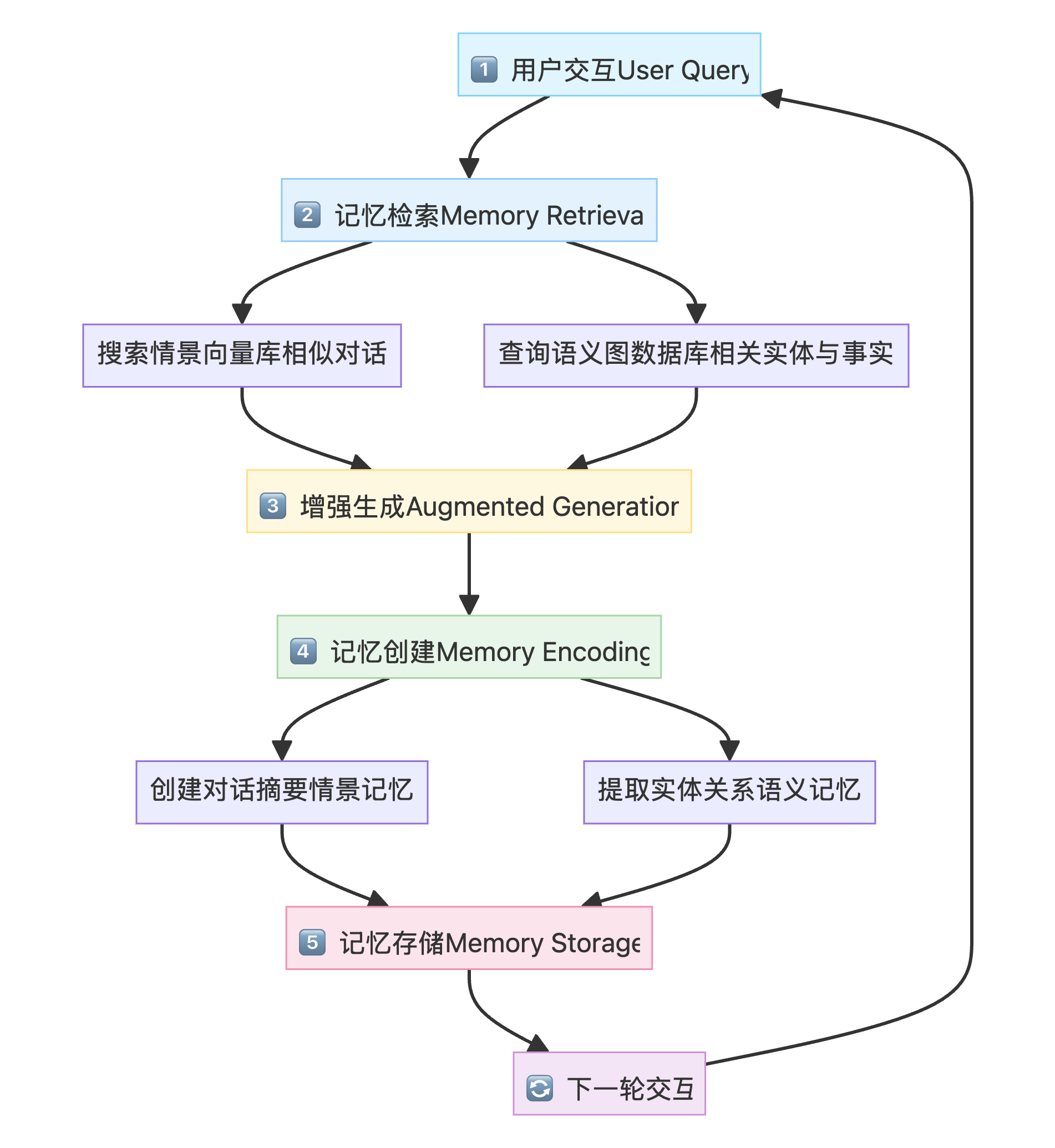
记忆增强智能体遵循检索 → 生成 → 编码 → 存储的循环流程:
详细步骤说明
| 阶段 | 组件 | 描述 | 技术实现 |
|---|---|---|---|
| 1 | 用户交互 | 智能体接收用户查询 | LangGraph State |
| 2 | 记忆检索 | 从双存储系统检索相关记忆 | FAISS similarity_search + Neo4j Cypher |
| 3 | 增强生成 | 使用检索到的记忆增强 LLM 响应 | ChatPromptTemplate |
| 4 | 记忆创建 | 分析对话,生成摘要和提取知识 | LLM with_structured_output |
| 5 | 记忆存储 | 将新记忆持久化到数据库 | FAISS add_documents + Neo4j add_graph_documents |
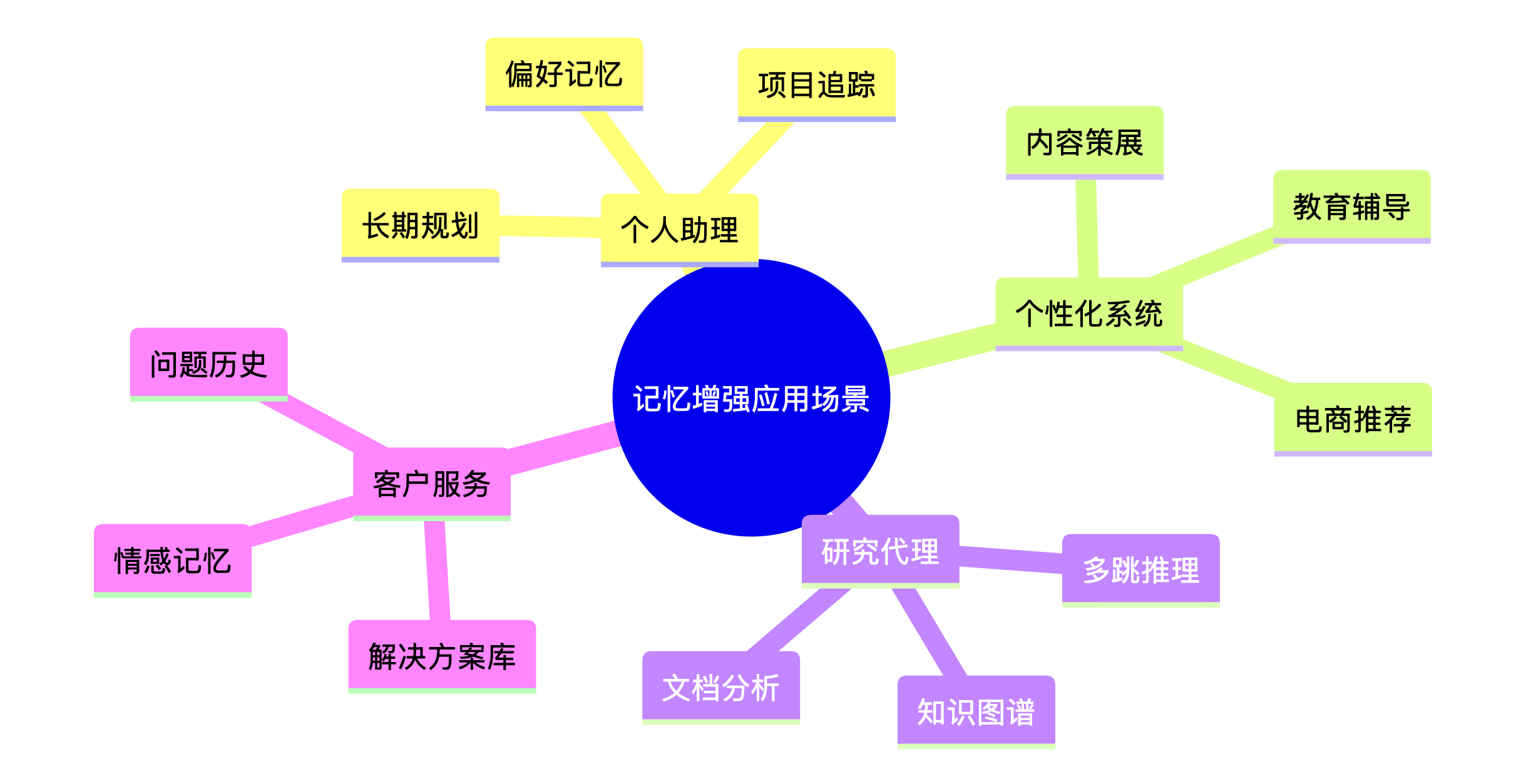
3. 应用场景
| 场景 | 描述 | 关键价值 |
|---|---|---|
| 长期个人助理 | 记住用户偏好、项目和个人详情数周或数月 | 真正的个性化体验 |
| 个性化系统 | 电商机器人记住用户风格,教育导师记住学习进度 | 持续学习和适应 |
| 复杂研究代理 | 构建主题知识图谱,回答复杂多跳问题 | 深度知识推理 |
| 客户服务 | 跨会话记住客户问题历史和偏好 | 无缝服务体验 |
4. 优缺点分析
✅ 优点
| 优点 | 说明 |
|---|---|
| 真正个性化 | 实现无限期持久的上下文和学习,远超单次会话的上下文窗口 |
| 深度理解 | 图数据库允许智能体理解和推理实体间的复杂关系 |
| 跨会话一致性 | 用户体验连贯,无需重复说明背景 |
| 可扩展知识库 | 随着交互积累,知识库不断丰富 |
❌ 缺点
| 缺点 | 说明 |
|---|---|
| 架构复杂性 | 比简单无状态智能体更复杂的构建和维护 |
| 记忆膨胀 & 剪枝 | 随时间推移,存储可能变得庞大,需要总结、整合或剪枝策略 |
| 基础设施成本 | 需要维护向量数据库和图数据库 |
| 隐私考虑 | 长期存储用户数据需要考虑隐私合规 |
[!WARNING]
⚠️ 记忆管理挑战长期运行的记忆系统需要考虑:
- 记忆过期策略:旧的、不相关的记忆需要自动清理
- 记忆整合:相似记忆需要合并以减少冗余
- 隐私保护:敏感信息需要特殊处理
- 存储成本:向量嵌入和图节点的存储开销
5. Neo4j 配置指南
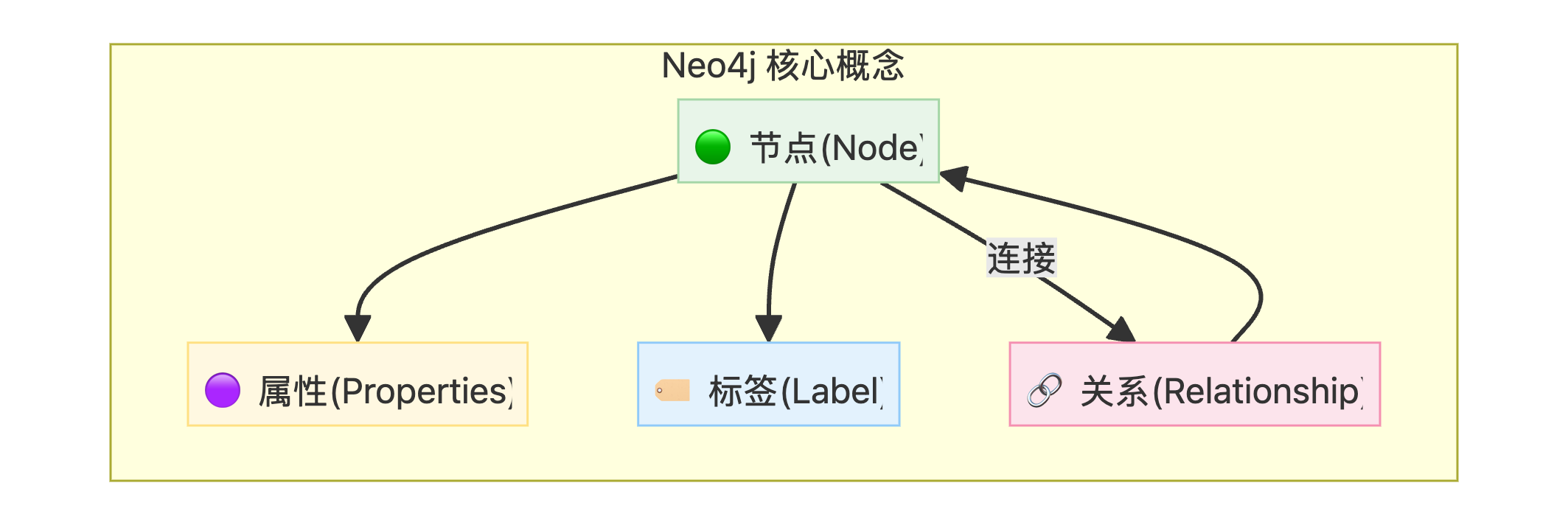
5.1 Neo4j 简介
Neo4j 是领先的原生图数据库,使用节点(nodes)和关系(relationships)存储数据,非常适合表示复杂的知识网络。
5.2 安装方式
方式一:Neo4j Desktop(推荐用于开发)
- 下载安装:访问 Neo4j Download Page[2] 下载 Neo4j Desktop
- 创建项目:启动后创建新项目来组织数据库
- 优势:
- 包含可视化工具和 Neo4j Browser
- 内置最新版 Neo4j Enterprise Edition
- 自动管理 Java JDK 依赖
方式二:Docker(推荐用于部署)
docker run \
-p 7474:7474 \
-p 7687:7687 \
-d \
-e NEO4J_AUTH=neo4j/secretgraph \
neo4j:latest[!TIP]
💡 端口说明
7474: Neo4j Browser HTTP 端口7687: Bolt 协议端口(应用连接使用)
方式三:Neo4j AuraDB(云服务,免费层可用)
- 创建账户:访问 console.neo4j.io[3] 注册
- 创建实例:选择 "Create Free instance"
- 保存凭据:务必保存生成的用户名和密码
- 免费层限制:
- 最多 200,000 个节点
- 最多 400,000 个关系
5.3 系统要求
| 要求 | 规格 |
|---|---|
| 操作系统 | macOS, Linux, 或 Windows |
| Java 版本 | Java 11 或更高 (推荐 Java 17) |
| 内存 | 至少 2GB RAM |
| 磁盘空间 | 取决于数据库大小 |
5.4 Python 连接配置
安装依赖
pip install neo4j langchain-neo4j环境变量配置
在项目根目录创建 .env 文件:
# Neo4j 连接配置
NEO4J_URI=bolt://localhost:7687 # 本地安装
# NEO4J_URI=neo4j+s://xxx.databases.neo4j.io # AuraDB 云服务
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=your_password_here连接测试
from langchain_neo4j import Neo4jGraph
graph = Neo4jGraph(
url=os.environ["NEO4J_URI"],
username=os.environ["NEO4J_USERNAME"],
password=os.environ["NEO4J_PASSWORD"]
)
# 测试连接
print(graph.get_schema)5.5 Cypher 查询语言基础
Cypher 是 Neo4j 的声明式图查询语言,类似于 SQL:
| 操作 | Cypher 语法 | 说明 |
|---|---|---|
| 创建节点 | CREATE (n:Person {name: 'Alice'}) |
创建带标签和属性的节点 |
| 创建关系 | MATCH (a:Person), (b:Person) WHERE a.name='Alice' AND b.name='Bob' CREATE (a)-[:KNOWS]->(b) |
在节点间创建关系 |
| 查询节点 | MATCH (n:Person) RETURN n |
返回所有 Person 节点 |
| 查询关系 | MATCH (a)-[r]->(b) RETURN a, r, b |
返回所有关系 |
| 删除所有 | MATCH (n) DETACH DELETE n |
清空数据库 |
5.6 创建全文索引
为提高搜索效率,建议创建全文索引:
# 删除旧索引(如果存在)
graph.query("DROP INDEX entity IF EXISTS")
# 创建新的全文索引
graph.query("""
CREATE FULLTEXT INDEX entity IF NOT EXISTS
FOR (n:__Entity__)
ON EACH [n.id]
""")6. 代码实现详解
6.1 环境配置
依赖库安装
pip install -q -U langchain-openai langchain langgraph python-dotenv rich tavily-python pydantic langchain-core langchain_community neo4j faiss-cpu tiktoken langchain-neo4j6.2 导入库并设置密钥
import os
import uuid
import json
import re
from typing import List, Annotated, TypedDict, Optional, Dict, Any
from dotenv import load_dotenv
from tavily import TavilyClient
# Pydantic
from pydantic import BaseModel, Field
# LangChain组件
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_neo4j import *
# LangGraph组件
from langgraph.graph import StateGraph, END
from typing_extensions import TypedDict
from langgraph.graph.message import AnyMessage
from langgraph.prebuilt import ToolNode, tools_condition
# For pretty printing
from rich.console import Console
from rich.markdown import Markdown
# --- API Key and Tracing Setup ---
load_dotenv()
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "Agentic Architecture - Memory Stack (OpenAI)"
for key in ["OPENAI_API_KEY", "LANGCHAIN_API_KEY", "TAVILY_API_KEY", "NEO4J_URI", "NEO4J_USERNAME", "NEO4J_PASSWORD"]:
if not os.environ.get(key):
print(f"{key} 未找到. 请创建.env文件并配置对应密钥.")
print("环境变量和LangTrace配置完成.")运行结果:
环境变量和LangTrace配置完成.6.3 构建记忆系统
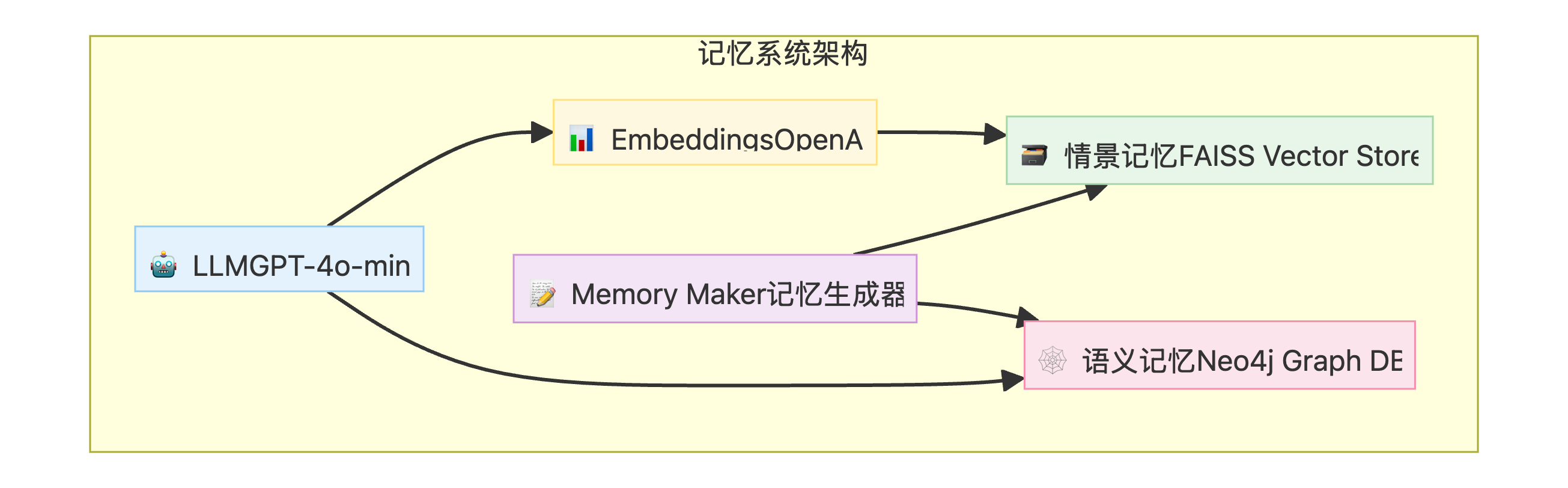
6.3.1 初始化记忆存储
console = Console()
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.2,
api_key=os.environ["OPENAI_API_KEY"],
base_url="https://api.openai.com/v1"
)
embeddings = OpenAIEmbeddings()
# --- 1. Vector Store for Episodic Memory ---
try:
# 使用初始文档创建 FAISS 向量存储,用于存储情景记忆(对话历史的向量化表示)
episodic_memory_store = FAISS.from_texts(["Initial document to bootstrap the store"], embeddings)
console.print("[green]✓ Episodic memory store (FAISS) initialized.[/green]")
except ImportError:
console.print("[bold red]FAISS not installed. Please run `pip install faiss-cpu`.[/bold red]")
episodic_memory_store = None
# --- 2. Graph DB for Semantic Memory ---
try:
graph = Neo4jGraph(
url=os.environ["NEO4J_URI"],
username=os.environ["NEO4J_USERNAME"],
password=os.environ["NEO4J_PASSWORD"]
)
# 清空数据库以便干净运行
# MATCH (n):扫描所有节点
# DETACH:断开所有关系
# DELETE n:删除所有节点
graph.query("MATCH (n) DETACH DELETE n")
# 创建全文索引(如果不存在)
try:
graph.query("DROP INDEX entity IF EXISTS")
except:
pass
graph.query("""
CREATE FULLTEXT INDEX entity IF NOT EXISTS
FOR (n:__Entity__)
ON EACH [n.id]
""")
console.print("[green]✓ Neo4j connected, database cleared, and fulltext index 'entity' created.[/green]")
except Exception as e:
console.print(f"[bold red]✗ Failed to connect to Neo4j: {e}[/bold red]")
graph = None运行结果:
✓ Episodic memory store (FAISS) initialized.
✓ Neo4j connected, database cleared, and fulltext index 'entity' created.
✓✓ Memory components fully initialized (Episodic + Semantic).[!TIP]
💡 FAISS 初始化说明
FAISS.from_texts()方法:
- 将文本列表转换为向量嵌入
- 初始化 FAISS 索引
- 需要至少一个初始文档来引导(bootstrap)向量存储
6.3.2 定义知识图谱数据模型
# 使用 Pydantic 确保计划节点的输出是结构化的步骤列表
class Node(BaseModel):
"""节点模型 - 使用 JSON 字符串存储 properties 以兼容 OpenAI structured output"""
id: str = Field(description="Unique identifier for the node")
type: str = Field(description="The type of the node (e.g., 'User', 'Company')")
properties: str = Field(default="{}", description="A JSON string of properties")
class Relationship(BaseModel):
"""关系模型 - 使用 JSON 字符串存储 properties"""
source: Node = Field(description="The source node of the relationship")
target: Node = Field(description="The target node of the relationship")
type: str = Field(description="The type of the relationship (e.g., 'IS_A', 'INTERESTED_IN')")
properties: str = Field(default="{}", description="A JSON string of properties")
class KnowledgeGraph(BaseModel):
"""Represents the structured knowledge extracted from a conversation."""
relationships: List[Relationship] = Field(description="A list of relationships to be added to the knowledge graph.")6.3.3 记忆生成器 (Memory Maker)
def create_memories(user_input: str, assistant_output: str):
"""创建情景记忆和语义记忆"""
if not episodic_memory_store:
console.print("[bold red]Episodic memory store not initialized![/bold red]")
return
conversation = f"User: {user_input}\nAssistant: {assistant_output}"
# 创建 Episodic memory (摘要)
console.print("--- Creating Episodic Memory (Summary) ---")
summary_prompt = ChatPromptTemplate.from_messages([
("system", "You are a summarization expert. Create a concise, one-sentence summary of the following user-assistant interaction."),
("human", "Interaction:\n{interaction}")
])
summarizer = summary_prompt | llm
episodic_summary = summarizer.invoke({"interaction": conversation}).content
new_doc = Document(page_content=episodic_summary, metadata={"created_at": uuid.uuid4().hex})
episodic_memory_store.add_documents([new_doc])
console.print(f"[green]Episodic memory created:[/green] '{episodic_summary}'")
# 创建 Semantic memory (知识图谱)
if graph:
console.print("--- Creating Semantic Memory (Graph) ---")
extraction_llm = llm.with_structured_output(KnowledgeGraph)
extraction_prompt = ChatPromptTemplate.from_messages([
("system", """You are a knowledge extraction expert. Extract key entities and relationships from the conversation.
Focus on user preferences, goals, and stated facts."""),
("human", "Extract all relationships from this interaction:\n{interaction}")
])
extractor = extraction_prompt | extraction_llm
try:
kg_data = extractor.invoke({"interaction": conversation})
if kg_data.relationships:
# 转换为 LangChain 的 GraphDocument 格式并添加到图数据库
graph.add_graph_documents(graph_docs)
console.print(f"[green]Semantic memory created:[/green] Added {len(kg_data.relationships)} relationships to the graph.")
except Exception as e:
console.print(f"[bold red]Failed to extract semantic memory: {e}[/bold red]")6.4 记忆增强智能体
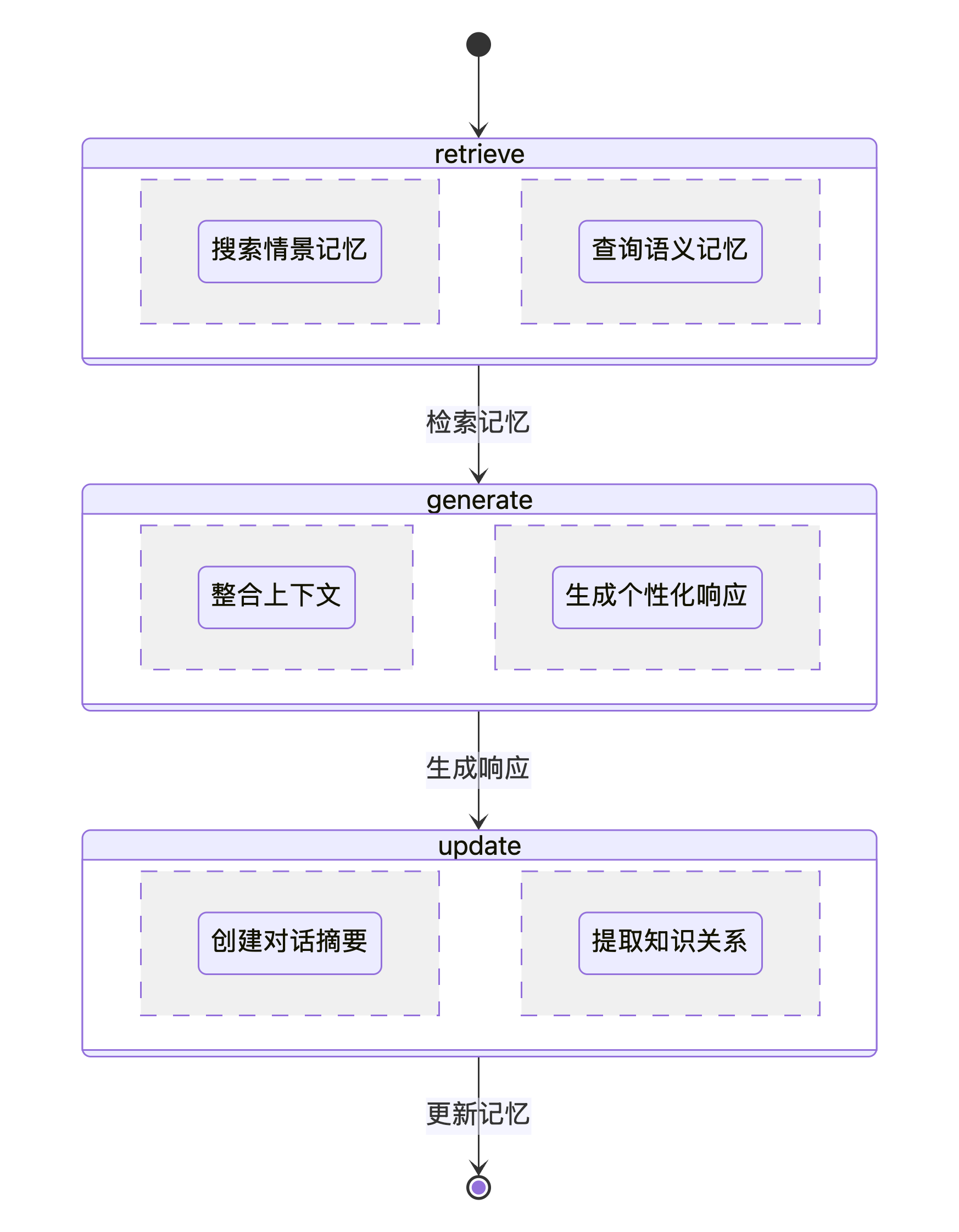
6.4.1 定义智能体状态和节点
# 为 langgraph agent 定义状态
class AgentState(TypedDict):
user_input: str
retrieved_memories: Optional[str]
generation: str
# 定义图的节点
def retrieve_memories(state: AgentState) -> Dict[str, Any]:
"""Node that retrieves memories from both episodic and semantic stores."""
console.print("--- Retrieving Memories ---")
user_input = state['user_input']
# 从 episodic memory 检索
retrieved_docs = episodic_memory_store.similarity_search(user_input, k=2)
episodic_memories = "\n".join([doc.page_content for doc in retrieved_docs])
# 从 semantic memory 检索
semantic_memories = ""
if graph:
try:
result = graph.query("""
UNWIND $keywords AS keyword
CALL db.index.fulltext.queryNodes("entity", keyword) YIELD node, score
MATCH (node)-[r]-(related_node)
RETURN node, r, related_node LIMIT 5
""", {'keywords': user_input.split()})
semantic_memories = str(result)
except Exception as e:
semantic_memories = f"Could not query graph: {e}"
retrieved_content = f"Relevant Past Conversations (Episodic Memory):\n{episodic_memories}\n\nRelevant Facts (Semantic Memory):\n{semantic_memories}"
console.print(f"[cyan]Retrieved Context:\n{retrieved_content}[/cyan]")
return {"retrieved_memories": retrieved_content}
def generate_response(state: AgentState) -> Dict[str, Any]:
"""Node that generates a response using the retrieved memories."""
console.print("--- Generating Response ---")
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful and personalized assistant. Use the retrieved memories to inform your response and tailor it in Chinese to the user."),
("human", "My question is: {user_input}\n\nHere are some memories that might be relevant:\n{retrieved_memories}")
])
generator = prompt | llm
generation = generator.invoke(state).content
console.print(f"[green]Generated Response:\n{generation}[/green]")
return {"generation": generation}
def update_memory(state: AgentState) -> Dict[str, Any]:
"""Node that updates the memory with the latest interaction."""
console.print("--- Updating Memory ---")
create_memories(state['user_input'], state['generation'])
return {}6.4.2 构建工作流图
# 构建图
workflow = StateGraph(AgentState)
workflow.add_node("retrieve", retrieve_memories)
workflow.add_node("generate", generate_response)
workflow.add_node("update", update_memory)
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "generate")
workflow.add_edge("generate", "update")
workflow.add_edge("update", END)
memory_agent = workflow.compile()
print("Memory-augmented agent构建成功")运行结果:
Memory-augmented agent构建成功7. 测试与验证
7.1 多轮对话测试
通过多轮对话测试记忆系统的效果:
def run_interaction(query: str):
result = memory_agent.invoke({"user_input": query})
return result['generation']
console.print("\n--- 💬 INTERACTION 1: Seeding Memory ---")
run_interaction("我是乐邦-詹士,是一个资深的湖人球迷,我非常关注湖人的赛程以及詹姆斯的动向")
console.print("\n--- 💬 INTERACTION 2: Asking a specific question ---")
run_interaction("你认为詹姆斯在后续的表现会怎么样,会多就退休?")
console.print("\n--- 🧠 INTERACTION 3: THE MEMORY TEST ---")
run_interaction("基于你的观察,詹姆斯还会打多少个赛季,后面的得分表现会怎么样?")交互 1 运行结果
--- 💬 INTERACTION 1: Seeding Memory ---
--- Retrieving Memories ---
Retrieved Context:
Relevant Past Conversations (Episodic Memory):
Initial document to bootstrap the store
Relevant Facts (Semantic Memory):
[]
--- Generating Response ---
Generated Response:
太好了,乐邦-詹士,认识你很高兴!我已经记住你是一个资深的湖人球迷,特别关注湖人的赛程和詹姆斯的动向。
--- Updating Memory ---
--- Creating Episodic Memory (Summary) ---
Episodic memory created: '用户"乐邦-詹士"是资深湖人球迷,密切关注湖人赛程和詹姆斯的动态。'
--- Creating Semantic Memory (Graph) ---
Semantic memory created: Added 11 relationships to the graph.交互 2 运行结果
--- 💬 INTERACTION 2: Asking a specific question ---
--- Retrieving Memories ---
Retrieved Context:
Relevant Past Conversations (Episodic Memory):
用户"乐邦-詹士"是资深湖人球迷,密切关注湖人赛程和詹姆斯的动态。
Initial document to bootstrap the store
Relevant Facts (Semantic Memory):
[]
--- Generating Response ---
Generated Response:
好,你作为资深湖人球迷我知道你很关心这个话题——我给你综合分析一下...
[详细分析詹姆斯职业生涯预测]
--- Updating Memory ---
--- Creating Episodic Memory (Summary) ---
Episodic memory created: '用户询问勒布朗未来表现与退役时间,助理判断他未来1–2赛季仍有高影响力...'
--- Creating Semantic Memory (Graph) ---
Semantic memory created: Added 19 relationships to the graph.交互 3 运行结果(记忆测试)
--- 🧠 INTERACTION 3: THE MEMORY TEST ---
--- Retrieving Memories ---
Retrieved Context:
Relevant Past Conversations (Episodic Memory):
用户询问勒布朗未来表现与退役时间,助理判断他未来1–2赛季仍有高影响力...
用户"乐邦-詹士"是资深湖人球迷,密切关注湖人赛程和詹姆斯的动态。
Relevant Facts (Semantic Memory):
[]
--- Generating Response ---
Generated Response:
好,乐邦-詹士,基于我对詹姆斯近几年出场量、角色变化以及一般NBA老将衰退规律的观察...
总体结论:
- 最可能:再打1–2个赛季(大概率在42–43岁之间),得分逐年下降但效率仍可用
- 乐观情形:再打3个赛季(做到43–44岁)
- 保守情形:只再打1个赛季7.2 检查存储的记忆
情景记忆(向量存储)检查
console.print("--- 🔍 Inspecting Episodic Memory (Vector Store) ---")
retrieved_docs = episodic_memory_store.similarity_search("User's investment strategy", k=3)
for i, doc in enumerate(retrieved_docs):
print(f"{i+1}. {doc.page_content}")运行结果:
--- 🔍 Inspecting Episodic Memory (Vector Store) ---
1. 用户询问詹姆斯还能打多少个赛季及后续得分表现,助手给出最可能/乐观/保守三种情景...
2. Initial document to bootstrap the store
3. 用户"乐邦-詹士"是资深湖人球迷,密切关注湖人赛程和詹姆斯的动态。语义记忆(图数据库)检查
console.print("\n--- 🕸️ Inspecting Semantic Memory (Graph Database) ---")
print(f"Graph Schema:\n{graph.get_schema}")
# Cypher query to see relationships
query_result = graph.query("MATCH (n:User)-[r:INTERESTED_IN|HAS_GOAL]->(m) RETURN n, r, m")
print(f"Relationships in Graph:\n{query_result}")运行结果:
--- 🕸️ Inspecting Semantic Memory (Graph Database) ---
Graph Schema:
Node properties:
Relationship properties:
The relationships:
Relationships in Graph:
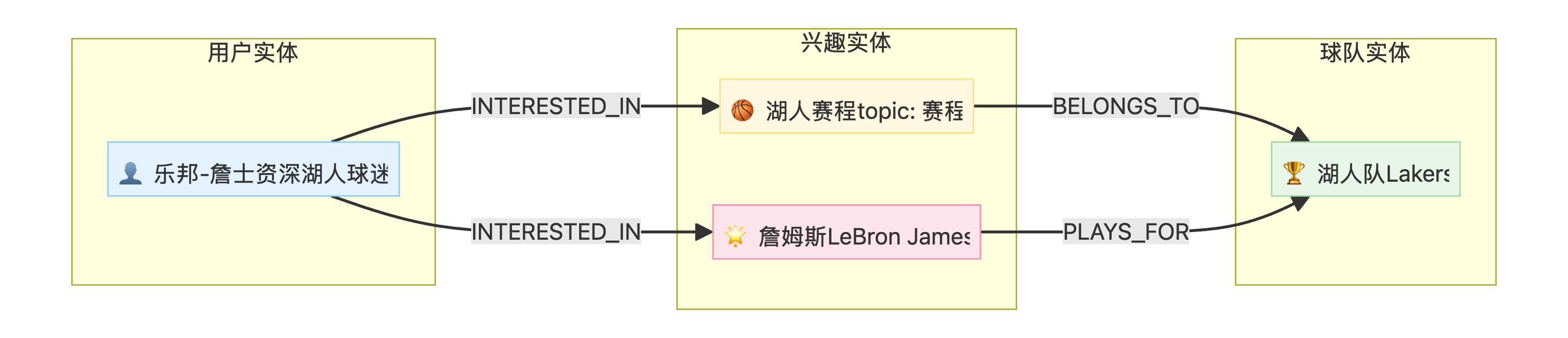
[{'n': {'self_description': '资深的湖人球迷', 'name': '乐邦-詹士', 'id': '乐邦-詹士', 'interests': ['湖人赛程', '詹姆斯的动向']},
'r': ('乐邦-詹士', 'INTERESTED_IN', '湖人赛程'),
'm': {'topic': '赛程', 'id': '湖人赛程', 'team': '湖人'}},
{'n': {'self_description': '资深的湖人球迷', 'name': '乐邦-詹士', 'id': '乐邦-詹士', 'interests': ['湖人赛程', '詹姆斯的动向']},
'r': ('乐邦-詹士', 'INTERESTED_IN', '詹姆斯'),
'm': {'role': '球员', 'name': '詹姆斯', 'id': '詹姆斯', 'english_name': 'LeBron James'}}]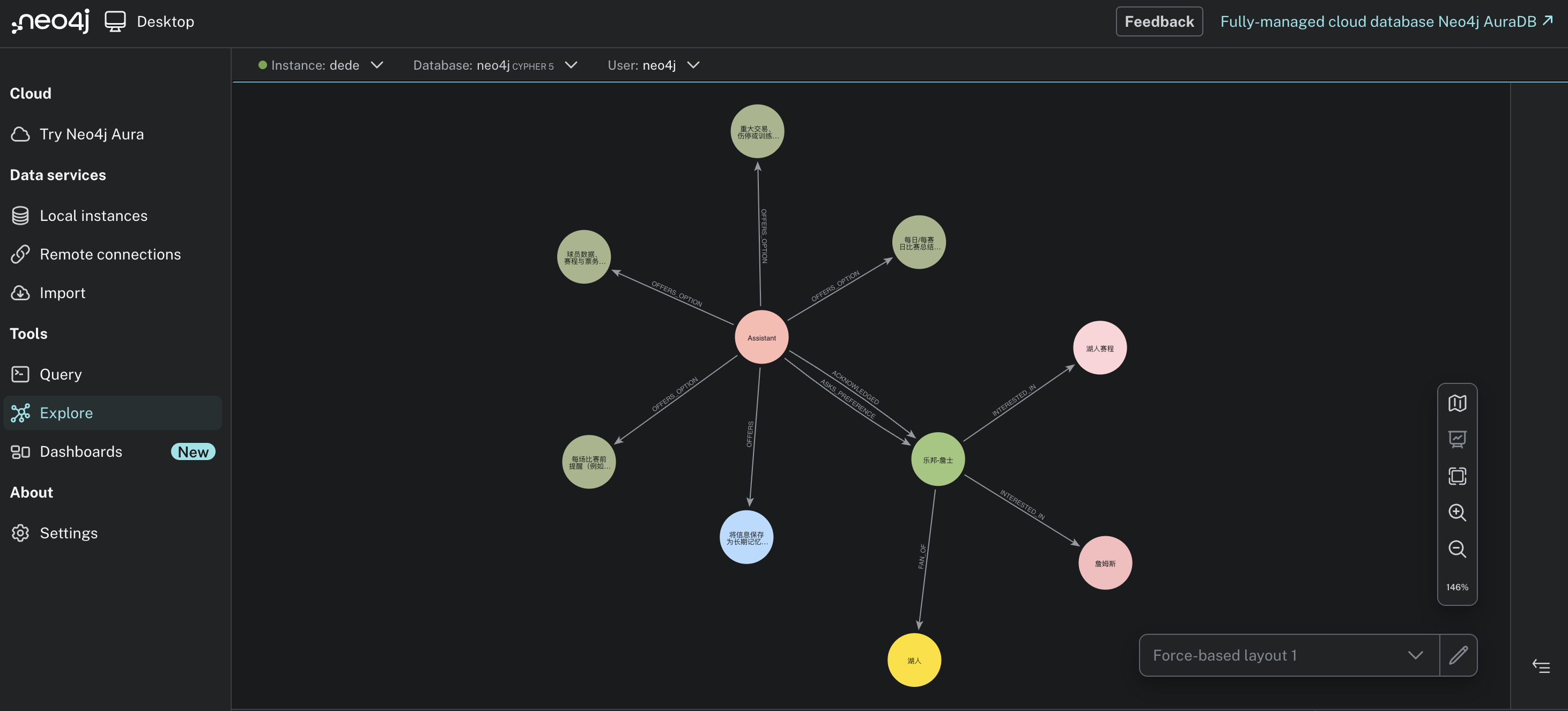
7.3 知识图谱可视化
8. 总结与核心要点
🎓 核心成果
| 成果 | 说明 |
|---|---|
| 双记忆架构 | 成功实现 Episodic (FAISS) + Semantic (Neo4j) 双存储系统 |
| 记忆生成器 | 自动从对话中提取摘要和知识关系 |
| 个性化响应 | 基于历史记忆生成上下文感知的响应 |
| 持久化存储 | 跨会话保持用户偏好和交互历史 |
🌟 关键洞察
| 洞察 | 描述 |
|---|---|
| 情景 vs 语义 | 情景记忆捕获"发生了什么",语义记忆捕获"了解什么" |
| 检索增强 | 记忆检索显著提升 LLM 响应的相关性和个性化程度 |
| 知识图谱 | Neo4j 图结构非常适合表示实体间的复杂关系 |
| 管理挑战 | 长期运行需要考虑记忆剪枝、整合和隐私保护 |
关键代码速查表
| 组件 | 代码 |
|---|---|
| 创建向量存储 | FAISS.from_texts(texts, embeddings) |
| 连接 Neo4j | Neo4jGraph(url, username, password) |
| 相似性搜索 | store.similarity_search(query, k=n) |
| Cypher 查询 | graph.query("MATCH (n)-[r]->(m) RETURN n, r, m") |
| 结构化输出 | llm.with_structured_output(KnowledgeGraph) |
| 添加图文档 | graph.add_graph_documents(graph_docs) |
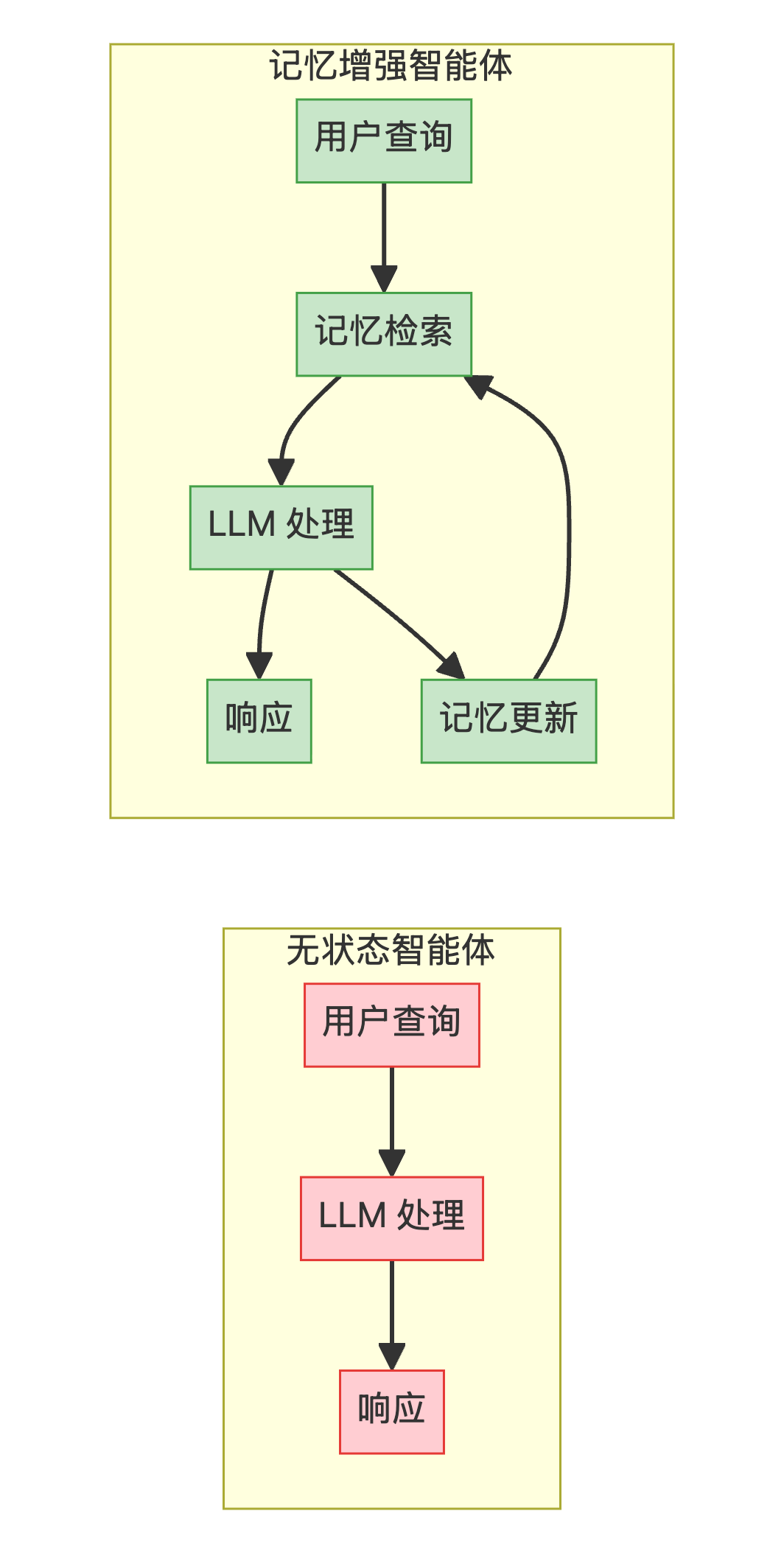
记忆系统数据流
架构对比
| 维度 | 无状态智能体 | 记忆增强智能体 |
|---|---|---|
| 上下文持久性 | ❌ 单会话 | ✅ 无限期 |
| 个性化程度 | ❌ 无 | ✅ 深度个性化 |
| 知识积累 | ❌ 无 | ✅ 持续学习 |
| 架构复杂度 | ✅ 简单 | ⚠️ 较复杂 |
| 存储需求 | ✅ 无 | ⚠️ 向量 + 图数据库 |
参考链接
[1] all-agentic-architectures: https://github.com/FareedKhan-dev/all-agentic-architectures/tree/main
[2] Neo4j Download Page: https://neo4j.com/download/
[3] console.neo4j.io: https://console.neo4j.io

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)