论文导读 | LLM4Graph
回顾这些图学习与大模型结合的多种探索,LLM-BP 代表了Enhancer 范式的简洁追求,证明了只要特征足够好,经典的启发依然能打败复杂的微调。GOFA 则代表了Predictor 范式的宏大理想,它用“三明治架构”将 GNN 与 LLM 深度融合,实现了“One-For-All”的零样本推理。而 CROSS 则提醒我们时间维度的重要性,在动态图中,只有捕捉到“语义漂移”,才能避免刻舟求剑。将这
引言:当GNN遇到LLM
现实世界的数据往往兼具“结构”与“语义”双重属性。传统的图神经网络(GNN)擅长处理拓扑结构,但在理解节点背后的丰富文本语义时往往力不从心;而大语言模型(LLM)虽然拥有强大的语义推理与泛化能力,却天生对非欧几里得的图结构水土不服。如何打通这两个模态?目前的学术界主要分化出了两条截然不同的路线:
LLM-as-Enhancer:用 LLM 给 GNN 打辅助。
LLM-as-Predictor:让 LLM 亲自上场做推理。
这两条路,哪条才是通往下一代 Graph AI 的坦途?
1. LLM-as-enhancer
这一范式的核心逻辑是:LLM 负责生成高质量的节点/边文本特征,GNN 负责搞定图结构和下游任务。它的优势在于成本相对较低,且能保留 GNN 对结构的强感知能力。但在实际操作中,这种简单分工往往面临一些棘手问题。
如果我们图省事,直接提取 LLM(如 Llama-3)的隐层特征作为节点表示,效果往往不尽人意。这是因为 LLM 的高维向量空间存在严重的各向异性:绝大多数向量都挤在一个狭窄的圆锥体空间内。这就导致了一个尴尬的现象:任意两个节点的余弦相似度都极高。对于GNN 来说,输入是一堆大差不差的特征,聚合消息之后,最终的节点表示就会发生语义坍缩,根本分不清谁是谁。为了解决特征不好用的问题,经典的思路是微调,要么微调 LLM,要么训练一个庞大的下游GNN。这种做法需要大量的算力和标注数据,难以适应在线应用;并且微调后的模型往往严重过拟合于源域。比如在论文引用网络上训练好的GNN,一旦换到电商网络上,性能就会断崖式下跌。
这就陷入了一个两难困境:直接用效果差,微调又贵又不泛化。下面这篇 ICML 2025 的论文为解决这种问题,提出了一套无需训练且能自适应任务的新范式。
案例论文:Generalization Principles for Inference over Text-Attributed Graphs with Large Language Models (ICML 2025)
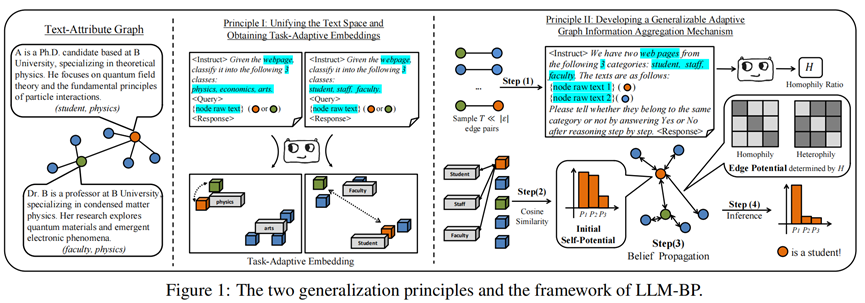
作者首先纠正了我们从 LLM 中提取特征的方式。目前的LLM 本质上是 Decoder-only 架构,采用单向注意力。这意味着前面的 Token 看不到后面的 Token,直接提取的语义表征往往是残缺的。为了修正这一点,LLM-BP 采用了 LLM2Vec 技术。它并不是简单地提取特征,而是开启双向注意力,通过MNTP微调,将 Decoder 改造为 Encoder,使其能够像 BERT 一样处理双向语义,同时保留 LLM 强大的指令遵循能力。
那为什么就不能用传统的Sentence Transformer?作者做了一个非常有趣的对比实验:如果我们在输入中加入 Class Info 的 Prompt,不同的模型会有什么反应?对于传统的小模型来说,性能反而下降了!因为它对长指令的处理天然不好,额外的 Prompt 成了噪声。但是对于大模型 Encoder,则观察到了性能大幅提升。这证明了,只有基于 LLM 的 Encoder 才能真正利用 Task-Adaptive Prompt。实验结果证明,得益于 LLM2Vec 强大的上下文学习能力,作者提出的方法把简单的 SBert 远远甩在身后,证明了选对基座比盲目微调更重要。
有了高质量的 Embedding,还不能直接做推理。在 Zero-shot 场景下,模型得先搞清楚下游类别的含义。作者在这一步使用原型网络的方法,先从图里随机抓一小撮节点,让 GPT-4 盲猜它们的标签。然后,把被归为同一类的节点向量取个平均值,这个平均向量就是该类别的原型。接下来,计算每个节点 Embedding 和这些原型的余弦相似度,就能得到每个节点属于某一类的初始概率。
怎么利用图结构来修正这些信念?LLM-BP 抛弃了会过拟合和过平滑的 GNN,回归了经典的信念传播 (Belief Propagation, BP) 算法。BP 算法说白了就是一种加权的邻居投票:如果我的邻居都觉得它是“计算机类”,那我是“计算机类”的概率也要增加。但这个投票的关键在于:我们该多大程度上相信邻居?(即图的同配率 r)。这时候,LLM 的通用推理能力再次登场。LLM-BP 随机抽取几对相邻节点,问 GPT-4:“你觉得这两个节点属于同一类吗?” 。统计“Yes”的比例,就得到了估算的同配率 r。
论文中还披露了一组极具批判性的实验结果。在 Zero-shot 设置下,作者发现:单纯使用 SBert,没有任何图结构信息的效果,竟然吊打了精心设计的 LLaGA 和 GraphGPT 。这意味着什么?意味着那些试图通过训练一个 Projector 把图特征映射到 LLM 空间的复杂模型,在跨域迁移的场景下,完全过拟合到了源域。相反,像 LLM-BP 这样,回归高质量特征 + 经典传播算法的极简路径,反而在泛化性上取得了巨大优势。
当然,虽然 LLM-BP 刷爆了 Benchmark,但我们必须清醒地看到它背后的代价。无需训练并不代表免费。LLM-BP 其实是将 GNN 的训练成本转移到了 LLM 的推理成本上。为了获取类别原型,它需要调用 GPT-4 对采样节点进行 Zero-shot 标注;为了估算同配率 r,它又要调用 GPT-4 对节点对进行判别。在工业界应用上,这种频繁的 API 调用可能会带来天价的成本。而信念传播算法,尤其是其线性近似版本,本质上是一个线性聚合过程。这意味着它放弃了现代 Deep GNN 中最关键的非线性激活(虽然会过拟合)。虽然文章测试的节点分类任务大多比较直截了当,但当面对那些需要深层学习才能发现的非线性变换关系时,这种方法可能会面临表示能力的天花板。
2. LLM-as-Predictor
LLM-as-Predictor 是一个野心勃勃的流派。这一派试图真正解锁LLM作为基础模型的强大能力,从而构建起真正的 Graph Foundation Model (GFM):不再为节点分类、链路预测分别训练专门的分类头,而是像ChatGPT 一样,一个模型,解决所有图任务。无论是问“这个节点属于哪一类?”还是“这两个人认识吗?”,只需要给 LLM 一个 Prompt,它就能直接生成答案。下面要介绍的这篇 ICLR 2025 的论文,正是这一宏大愿景的杰出代表。它用一种激进的架构,重新定义了GNN与LLM的关系。
案例论文:GOFA: A Generative One-For-All Model for Joint Graph Language Modeling (ICLR 2025)。
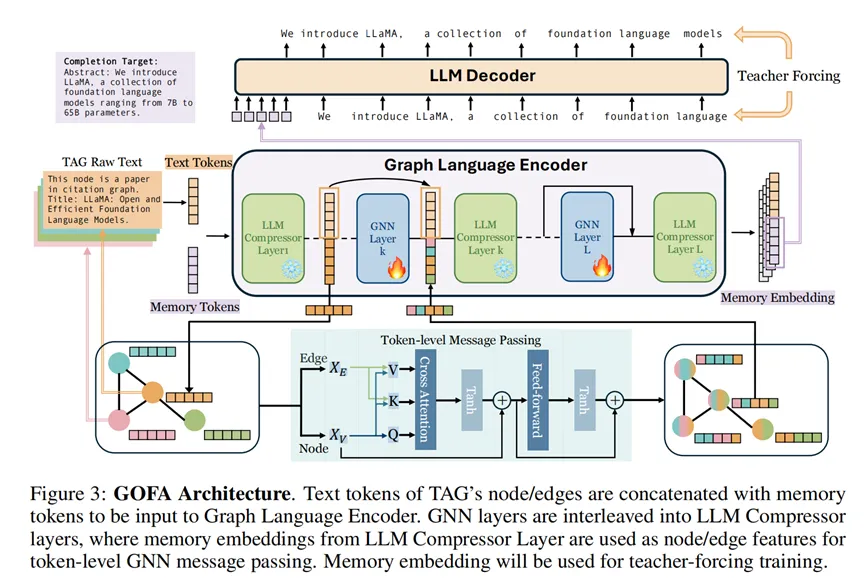 在 GOFA 之前,大家做“图+LLM”通常很偷懒:训练一个简单的 Projector(比如千层MLP),把图特征翻译成 Token 喂给 LLM。这种做法可能会使结构信息在映射过程中大量丢失,LLM 根本看不清图的拓扑细节。 GOFA 彻底重构了这种交互方式,它提出了一种深度交织的架构,让 GNN 和 LLM 真正实现了深度交互。
在 GOFA 之前,大家做“图+LLM”通常很偷懒:训练一个简单的 Projector(比如千层MLP),把图特征翻译成 Token 喂给 LLM。这种做法可能会使结构信息在映射过程中大量丢失,LLM 根本看不清图的拓扑细节。 GOFA 彻底重构了这种交互方式,它提出了一种深度交织的架构,让 GNN 和 LLM 真正实现了深度交互。
首先,图节点的文本往往极长,如果把邻居节点的文本全部拼接起来,Context Window 瞬间就会被撑爆。GOFA 借鉴了 ICAE (In-Context Auto-Encoder) 的思想,利用 LLM 的浅层作为“压缩器”,将每个节点的长文本压缩为 K 个固定的 Memory Tokens 。这种方法既保留了核心语义,又把长度压到了可接受的范围。除此之外,GOFA 使用了一种“三明治架构”,它并没有把 GNN 放在 LLM 外面,而是将其插入到了 LLM 的层与层之间。Layer i (LLM):处理语义,提取 Memory Tokens。Layer i+1 (GNN):在 Memory Tokens 之间交换信息,进行消息传递(Message Passing)。Layer i+2 (LLM):基于交换后的信息继续进行深层语义推理。这种设计让“结构信息”与“语义信息”在模型内部进行了多轮握手。LLM 每思考一层,GNN 就帮它在图结构间传播,从而实现了真正的模态对齐。
GOFA 的效果是震撼的,它在多个任务上实现了 SOTA,并且真的做到了 Zero-shot 泛化。但对于实际应用来说,GOFA 带来的账单也是震撼的。LLM-as-Predictor 模式的死穴就在于随之而来的高额开销。LLM-as-Enhancer 模式:只需推理一次获取 Embedding,后续是毫秒级的 MLP 分类。而GOFA,每生成一个 Token,都要跑一遍巨大的 LLM/GNN 流水线。论文中称,在 FB15k237 任务上,GOFA 处理单个样本的平均耗时高达 3.92 秒。如果你有一个拥有 10 亿用户的社交网络,想用 GOFA 把所有用户跑一遍,哪怕你动用 8 张 A100 显卡,也需要耗时数个世纪才能跑完。
所以,GOFA 代表了学术界对 Graph Foundation Model 的前沿探索,结构精巧、理念先进、效果拔群。但在算力成本呈指数级下降之前,它还不能成为实际应用中的首选。
3. LLM for Dynamic Graphs
动态图是语义图研究的前沿,但这里事情变得更加棘手,在这里,除了“结构”和“语义”,我们必须处理第三模态:时间。在静态图中,一个节点的定义是固定的。但在动态图中,节点不仅连接关系在变,它的含义本身也在变。传统的时序图神经网络 (TGNN) 虽然能捕捉连边的变化,但是并不能捕捉动态的文本语义。下面介绍的这篇NeurIPS 2025的论文,正是试图用 LLM 来修补这个漏洞。
案例论文:Unifying Text Semantics and Graph Structures for Temporal Text-attributed Graphs with Large Language Models (NeurIPS 2025)
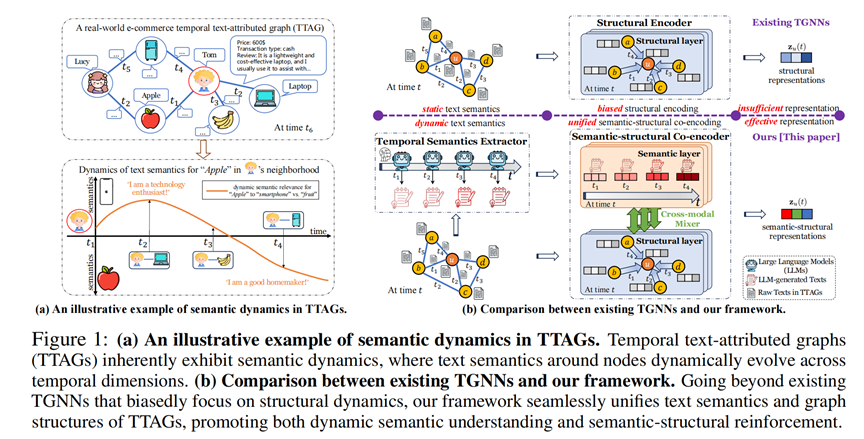
这篇论文依然沿用了 LLM-as-Enhancer 的思路,不过事先使用LLM,根据时序和结构做语义增强。它不相信静态的节点描述,而是相信交互定义语义。本方法取若干个时间窗口,对于每一个时间窗口的节点,调用LLM把它的 1-hop 历史交互记录打包成一段动态摘要。这个摘要通过 Embedding 后,就成了该节点在当前时间窗口内的动态语义特征。
拿到动态的文本特征后,CROSS 并没有简单地拼接,而是设计了一个双流架构,让“时序语义”和“拓扑结构”并行处理,最后通过门控机制融合。这确保了模型既不会因为关注语义而丢失结构信息,也不会因为拟合结构而掩盖了语义的变化。在那些节点特征本身质量较差、但具有语义演化的数据集(如 DTGB)上,该方法带来的提升是巨大的。这直接证明了:传统的 TGNN 确实未能有效建模动态变化的语义信息。
不过话说回来,该方法最大的一个弱点,仍然在于效率方面。想要使用这种方法,我们需要对全图节点进行持续的滚动更新。每过一个时间窗口,就要调用 LLM 对所有活跃节点的历史记录进行一次推理,这无疑是非常昂贵的。
另一方面,和静态图一样,动态图也出现了一系列LLM-as-predictor的早期尝试。目前的方法还比较初步,主要还停留在 Prompt Engineering 的截断。如简单粗暴的“截断历史”,把一个节点过去一段时间的交互记录直接转换成文本序列,喂给 LLM 让它猜下一个。但 Context Window 是有限的,所以通常只能保留最近的k条记录。这种做法不仅丢失了长期依赖,而且极易受近期的交互噪声误导。但我们相信,随着研究的进一步深入,更加精巧有效的方法会逐步出现。
总结
回顾这些图学习与大模型结合的多种探索,LLM-BP 代表了Enhancer 范式的简洁追求,证明了只要特征足够好,经典的启发依然能打败复杂的微调。GOFA 则代表了Predictor 范式的宏大理想,它用“三明治架构”将 GNN 与 LLM 深度融合,实现了“One-For-All”的零样本推理。而 CROSS 则提醒我们时间维度的重要性,在动态图中,只有捕捉到“语义漂移”,才能避免刻舟求剑。
将这三者放在一起审视,我们能清晰地看到横亘在整个领域面前的性能-效率悖论。Training-free的策略凭借只推理一次 Embedding,实现了工业级的可用性,但牺牲了对复杂模式的把握;而处于顶层的 Generative Predictor 虽然描绘了GFM的宏大愿景,推理成本却指数级爆炸。这迫使我们反思:在追求benchmark上的最高分时,我们是否牺牲了太多的现实可行性?
另一点是泛化性的悖论。我们往往认为训练得越多,效果越好,但在图与 LLM 的结合中,事实却常常相反。微调虽然能让模型在源域上表现优异,却容易让 LLM 过拟合于特定的结构模式,导致在跨域迁移时出现负迁移。相反,像 LLM-BP 这样完全不训练 GNN、仅依靠 LLM 通用推理能力的策略,反而保留了最强的跨域适应性。我们距离一个兼顾泛化性和强大能力的图基础模型,可能还有很长的路要走。
最后,回到Enhancer与Predictor的较量。Enhancer 只是把 LLM 当作昂贵的特征提取器,而 Predictor 试图让 LLM 强行处理每一条请求,这两种极端都有各自的突出问题。利用语义的最优模式,尚待后续研究继续探索。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 36
36 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)