Harnessing Frequency Spectrum Insights for Image Copyright ProtectionAgainst Diffusion Models论文分析
论文介绍
这篇论文揭示了扩散模型生成的图像会继承训练数据的频谱特征这一核心特性 。基于此,作者提出了 CoprGuard 框架,通过在频域植入隐形水印,实现了即使在仅有 1% 的训练数据被标记的情况下,也能准确检测出模型是否侵权(即是否使用了受保护的数据进行训练或微调)。
核心逻辑拆解
背景介绍
随着扩散模型的成功,不可避免的引发了对未经授权的新担忧。因为扩散模型要想效果好,必须海量的依赖数据。但这引发了严重的版权危机,许多数据是未经过授权获取的。
现有痛点
最初的研究主要集中在主动对抗防御(如图像投毒),通过在图像发布前添加肉眼难察的对抗性扰动来诱导模型学习错误的映射。
然而,该方法存在显著局限:
- 缺乏灵活性,对模型架构高度敏感,缺乏跨模型、跨版本的泛化防御能力;
- 在文本到图像任务中,强力的文本引导信号会覆盖图像层面的微小扰动,使模型仍能提取到干净的语义特征。
- 在实际的大规模训练场景下,受保护样本极易被海量无标签数据‘稀释’,导致检测统计量不显著,无法提供具有法律效力的侵权证据
为了克服现有技术的缺陷,理想的扩散模型版权保护方案需满足双重标准:
- 感知无损性:保护信号必须在像素层面达到视觉隐形,确保作品的艺术价值不因防护而受损;
- 极低占比下的可检测性:需具备在‘海量数据稀释’(如注入率仅为 1%)的环境下,仍能通过统计学手段稳定提取版权证据的能力。
核心洞察
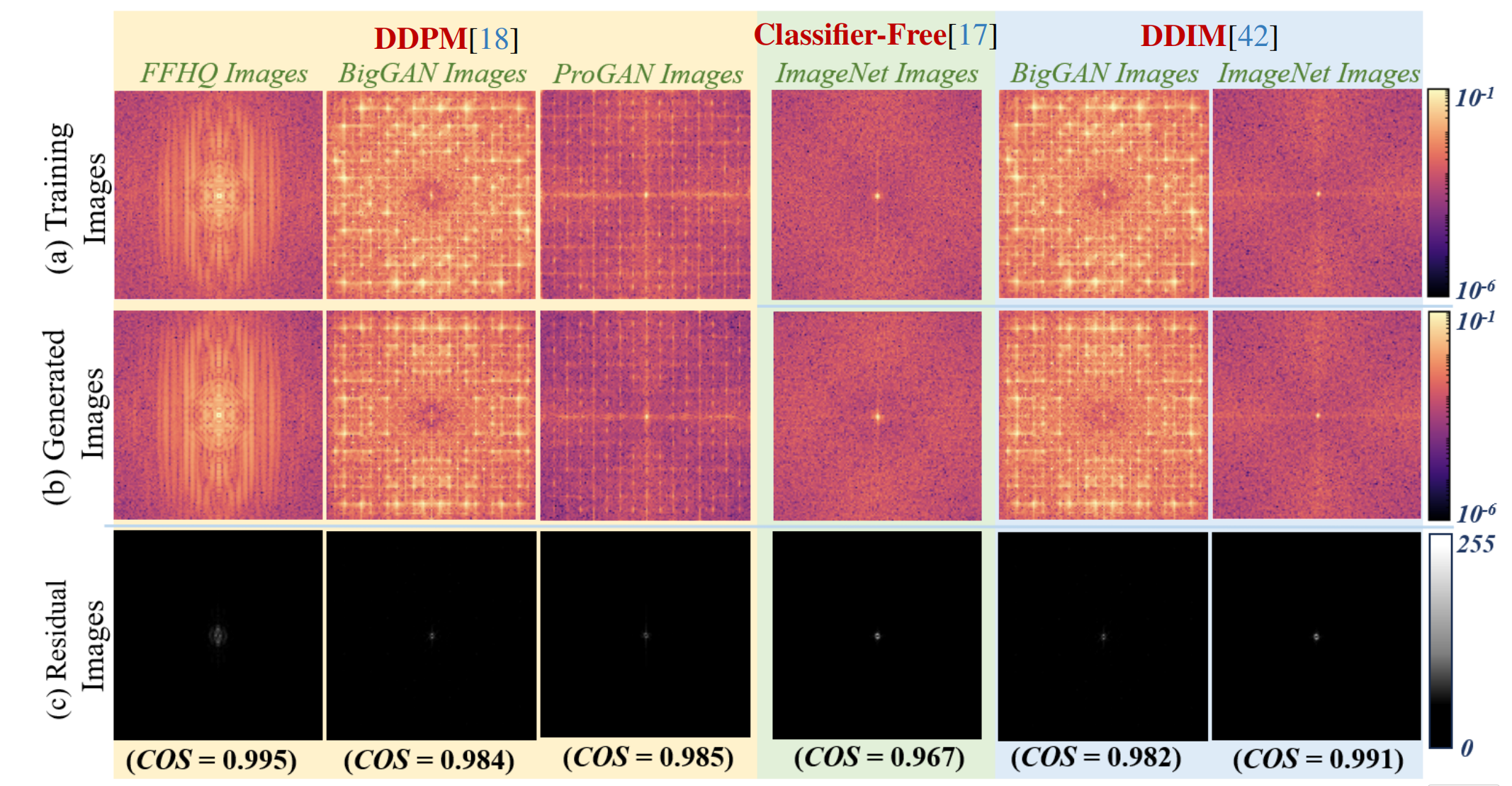
扩散模型是频域的复读机,会保留训练数据的光谱特性。作者发现扩散模型生成的图像,在频谱统计特性(DFT/DWT)上与训练集惊人地相似 。如图可视,作者展示了三种不同的扩散模型在不同数据集上训练后的表现。第一行是训练集原图的频谱,第二行是生成图的频谱,第三行是残差,作者把第一行和第二行相减,得到了这一行全黑的图 。全黑:意味着差异几乎为零。COS 数值: 图片下方标注了余弦相似度,数值越接近 1,代表越相似。基于这个发现,作者就提出了 CoprGuard框架。
方法论
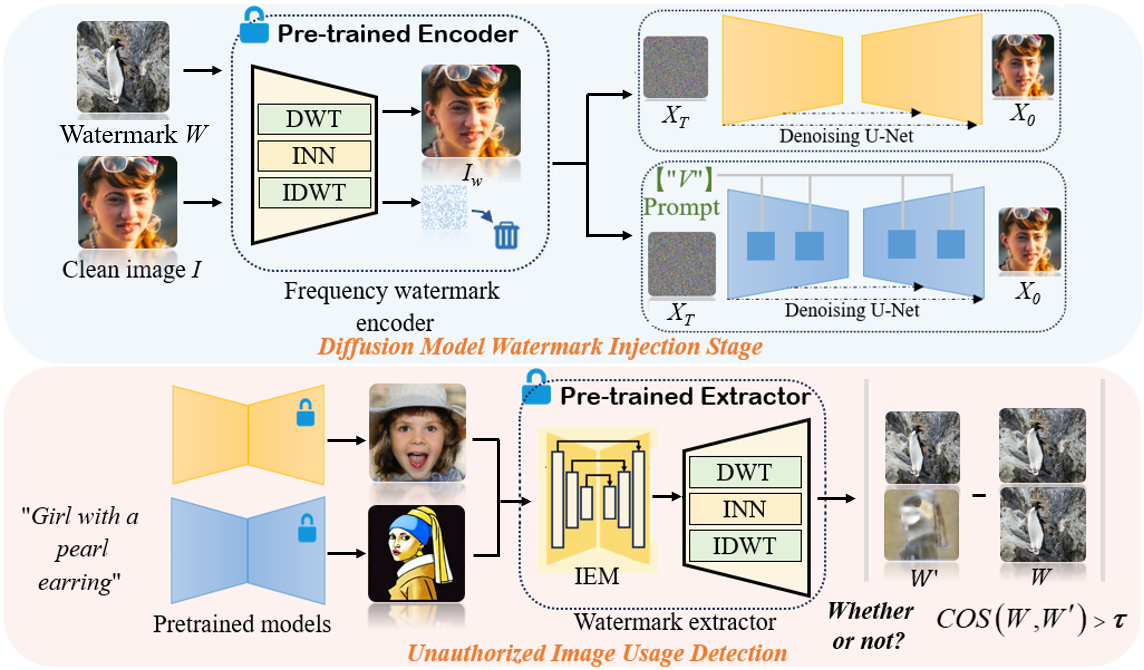
注入阶段:注入阶段的目标是将一个水印图像隐蔽地嵌入到受保护的原始图像 ($I$) 中,生成含水印图像。
- 第一步:频域分解 (DWT 分解)
使用离散小波变换 (DWT) 将原始图像拆解为四个频率子带:低频平均分量 ($LL$) 和三个高频细节分量(水平、垂直、对角线)。
- 第二步:可逆网络编码 (HiNet Encoding)
利用 HiNet作为核心编码器。HiNet 将水印图像的特征“编织”进原始图像的高频 wavelet 子带中。
- 第三步:逆变换合成 (IDWT 合成)
将包含水印特征的小波分量通过 逆离散小波变换 (IDWT) 重新组合,输出最终的图像。
检测阶段: 从可疑模型生成图片提取水印计算余弦相似度。如果相似度高,说明模型“偷吃”了受保护的数据 。、
第一步:群体采样
检测者让怀疑侵权的 AI 模型随机生成N张图像。
第二步:信息增强模块(IEM)
这是 CoprGuard 区别于传统水印技术的“秘密武器”,专门针对 Stable Diffusion 等模型的 VAE 压缩损耗 设计。扩散模型在训练前会通过 VAE 将图像压缩。VAE 会过滤掉大量高频细节,导致传统的像素级或简单的频域水印在模型生成图像时彻底消失。
第三步:频域分解->HiNet->IDWT 合成
流程:生成图像 → IEM 增强 → DWT 分解 → HiNet 逆向提取 (rev=True) → IWT 还原 → 得到提取水印 W'。
第四步:余弦相似度计算
计算提取出的W'与原始水印W之间的余弦相似度 (Cosine Similarity)。
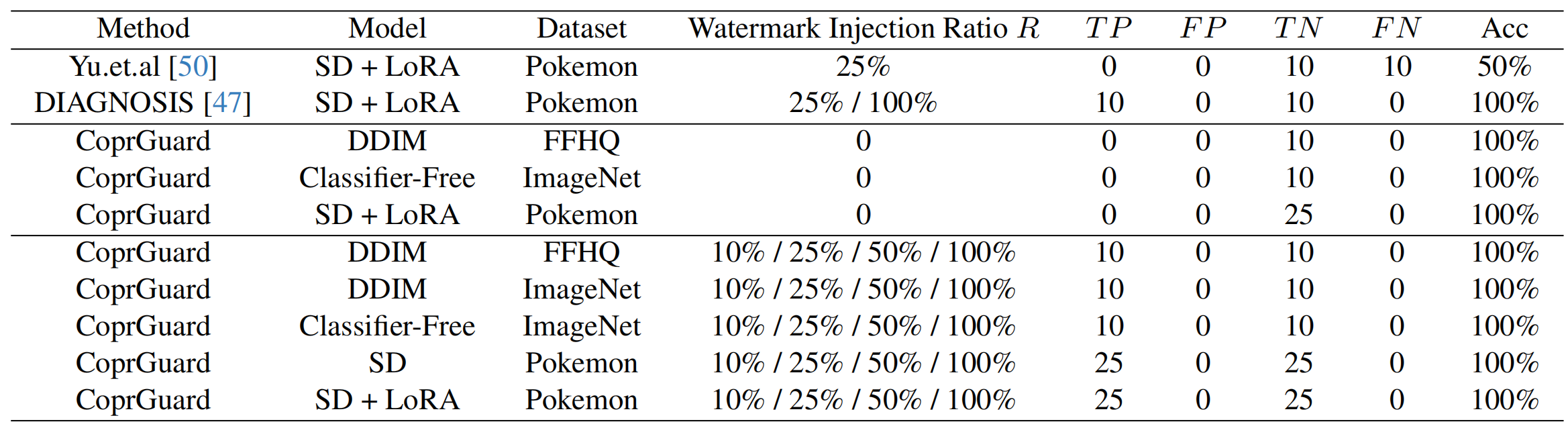
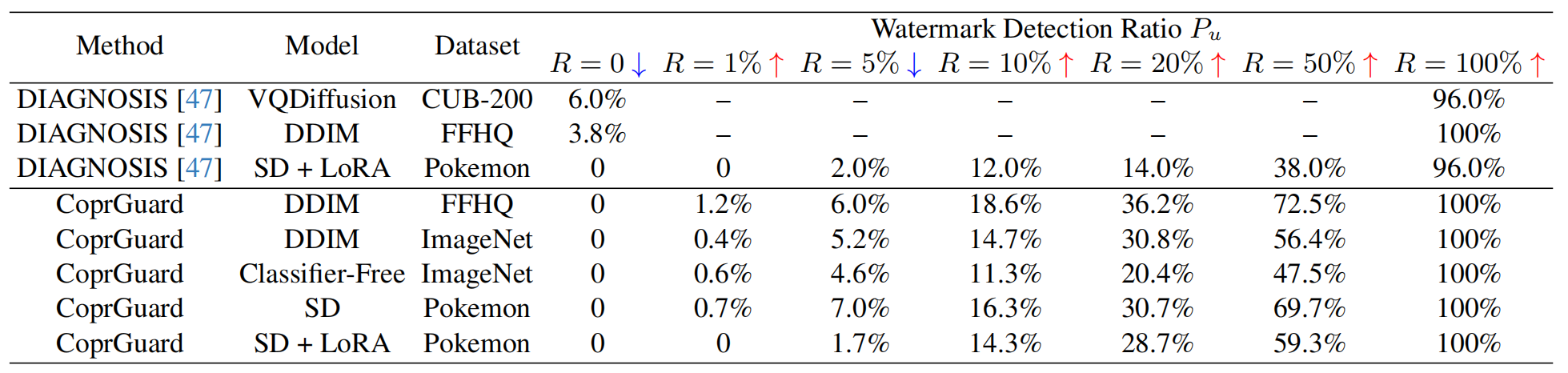
实验效果:
R:数据集中水印注入的比例
P_u:衡量的是在模型生成的所有图片中,有多少比例被成功提取出了水印。检测到水印的生成图数量\总生成图数量。即使注入率只有 1%,只要 P_u显著高于清白模型的误报率P_c,检测就成功了。
本文章的侵权证明重点在于4.2.2节,这部分不进行详细介绍,请自行阅读。
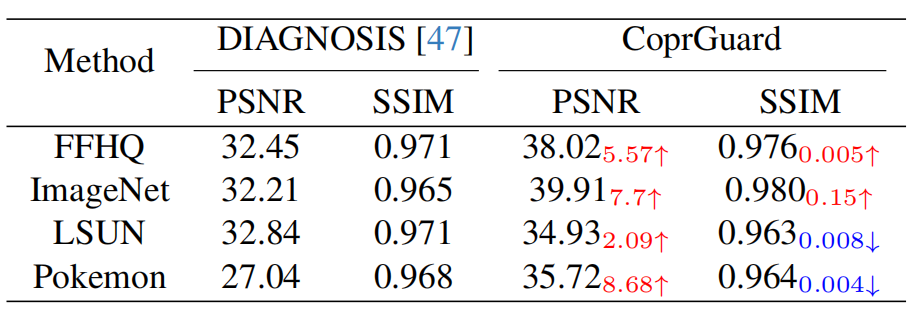
实验显示,当注入率R在 10% 到 100% 之间时,CoprGuard 在所有模型(DDIM, SD, LoRA)上均达到了 100% 的检测准确率,且误报率 (FP) 和漏报率 (FN) 均为 0 。即使受保护图像只占训练集的 1%,CoprGuard 依然能实现显著的检测效果 。对图像质量的影响微乎其微。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)