多维创新打造强泛化智能体模型,LongCat-Flash-Thinking-2601技术报告发布
该模型创新性地打造了 “重思考模式” ,通过并行推理与深度总结,实现推理宽度与深度的协同扩展,显著提升复杂交互与多步规划任务中的表现。

当大模型在数学竞赛、代码编写等领域持续突破,甚至超越顶尖人类专家时,大家难免会好奇:这些在基准测试中拿高分的模型,能否真正落地到复杂多变、充满噪声的真实世界任务中?
近期,美团 LongCat 团队交出了一份重磅答卷——开源 LongCat-Flash-Thinking-2601。作为一款拥有 5600 亿参数的 MoE(混合专家) 模型,它不仅在 BrowseComp、VitaBench 等智能体基准测试中登顶开源 SOTA,更通过“环境扩展、多环境RL训练、抗噪训练”等核心创新,解决了智能体“落地难”的问题。同时,该模型创新性地打造了 “重思考模式” ,通过并行推理与深度总结,实现推理宽度与深度的协同扩展,显著提升复杂交互与多步规划任务中的表现。
今天,我们深入解析 LongCat 如何通过多维度的创新打造强泛化的智能体模型。
01 为何智能体在真实世界中总是“水土不服”?
当前,智能体系统依然严重依赖垂直场景的定制化设计——需要工程师精心打磨特定的Prompt、工具链,甚至环境接口。这种模式带来了高昂的适配成本:模型在一个场景下表现优异,一旦换个领域、换套工具,或者环境稍微嘈杂一点(比如工具调用超时、工具报错),它们就会“水土不服”,甚至失效。
根本原因在于:缺乏一个能够在多样化、复杂化、带噪声环境中“身经百战”并稳定泛化的基础模型。 现有的训练往往在高度理想化、规则明确的环境中进行,缺乏对真实世界复杂交互与不确定性的充分覆盖。
为此,美团LongCat团队提出了一套以 “两个扩展+噪声训练” 为核心的通用智能体训练范式:
- 环境扩展:构建覆盖20+领域的规模化训练场
- 强化学习扩展:在万级异构环境中实现高效稳定训练
- 噪声鲁棒训练:系统化注入真实世界扰动,提升模型韧性
通过这套组合拳,模型能够获得高级别的任务执行与跨领域泛化能力,实现模型即智能体,显著降低后续垂直场景的适配负担,让模型能够在真实复杂世界中自如地应对新任务和新挑战。
02 环境扩展:构建高质量“练兵场”
环境扩展是模型获取通用智能体能力的核心基础。要让模型真正掌握实际任务执行能力,就必须脱离纯文本训练的局限,让模型在模拟真实场景的交互环境中落地实操。
面对真实世界场景复刻成本高、迭代效率低的痛点,LongCat 团队构建了端到端自动化环境生成系统,为模型打造了覆盖 20 余个领域、包含上万种情境的规模化训练环境。该系统具备高效智能化生成能力:输入简洁的 “领域定义” 即可完成全链路环境构建,自动合成包含 60 余个工具、具备复杂依赖关系的可执行环境图谱,并同步生成配套的数据库架构、工具调用接口及验证逻辑。环境类型覆盖文件管理、数据分析、电商零售、电信服务等多元场景,提供与真实世界一致的工具交互体验,支撑模型调用工具、处理数据、接收反馈的全流程训练。
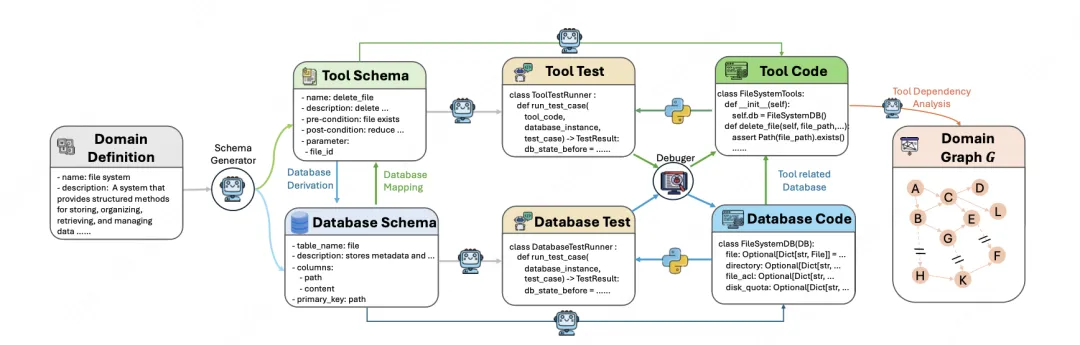
自动化合成的环境越复杂,其背后关联的需要自动合成的数据库越多,越难保持这些自动合成的“数据库一致性” —— 单个环境关联数十个数据库,工具间参数依赖错综复杂,易出现逻辑冲突导致任务 “看似可解实则无解”,向模型传递错误训练信号。为此,LongCat 团队创新了 “可解路径优先” 的环境构建策略:
- 种子采样:随机采样一条长工具调用链作为锚点,并依此自动构建一个采纳该工具调用链作为解法之一的复杂任务,同时对于采样过的工具,降低其采样概率;
- 受控扩展:以该“黄金工具链”为根,通过BFS式扩展,生成一个极大环境子图(保证其前序依赖结点均在已有的工具集内,从而进行可控扩展),严格保证数据库的逻辑一致性;
- 动态环境构建:系统会根据当前环境的复杂度、剩余工具图中找到新有效路径的难度、以及未使用的工具数量,动态决定是否加入新的“黄金工具链”。这样既能扩展环境规模,又能保证任务可解、训练有效;
- 最小规模保证:如果当前环境的工具数量太少(不足20个),系统会直接从全局工具库中随机选一条中等规模的可用工具链加入,并始终保持数据库状态一致,避免环境失效。
这套机制既能扩展环境规模,又能保证任务可解、训练信号有效,彻底摆脱“纸上谈兵”的局限。

03 强化学习扩展:万级异构环境下的高效稳定训练
当我们有了海量训练环境,怎么让模型高效学习?为支持大规模多环境训练,LongCat团队升级了异步训练系统DORA。在训练启动前,团队将预训练/微调模型的目标,从追求基准高分,重新定义成为后续RL提供“冷启动策略”:
- 有真实数据的领域(如数学、编码):通过严格的质量控制与可执行性验证筛选高质量轨迹。
- 缺乏真实数据的领域(如搜索、工具使用):采用双路合成,包括文本驱动合成及环境锚定合成。
这样既保证了数据质量,也为后续强化学习提供了多样化的探索基础。
DORA 系统的核心突破在于全异步流式训练架构,颠覆传统同步训练模式:
- 多版本模型并行探索:不同版本模型生成的训练经验 “随产随收”,直接存入样本队列,训练器无需等待所有任务完成即可启动训练,彻底消除任务间等待时间;训练设备空闲时,系统可弹性扩容生成实例,进一步提升吞吐量;
- 分布式调度架构:拆解集中式调度设计,采用 “轻量级 Rollout Manager + 多 Rollout Controller” 的分布式模式,前者负责全局元数据管理,后者各自管理一个虚拟 rollout 组的生命周期,通过数据并行处理环境交互,解决单机器调度瓶颈;
- 灵活环境部署:扩展 PyTorch RPC 框架,支持基于 CPU 空闲状态的远程函数调用与对象实例化,可将海量环境灵活部署到任意空闲机器,实现资源高效利用。
为适配 5600 亿参数 MoE 模型训练需求,DORA 引入两项关键优化:
- Prefill-Decode(PD)解耦,将预填充与解码任务部署在不同设备组,避免长上下文请求的预填充任务干扰解码流程,保障多轮交互中的生成效率;
- KV-cache 交换机制,通过 chunk 级 KV-cache 聚合传输、异步传输与计算重叠降低数据传输开销,配合 CPU 驻留的 KV-cache 动态交换机制,彻底解决设备显存不足导致的重复计算问题。
资源分配上,DORA 实现 “双层平衡”:
- 整体平衡:根据环境难度分配训练任务量,对复杂、低吞吐量领域提高 rollout 配额,避免简单环境训练过度;
- 批内平衡:单批次保证任务域多样性,防止模型仅适应少数环境出现过拟合。
最终,该系统实现 2-4 倍于传统同步训练的效率,支持千步以上稳定训练,支撑模型在万级异构环境中持续学习、稳步提升。
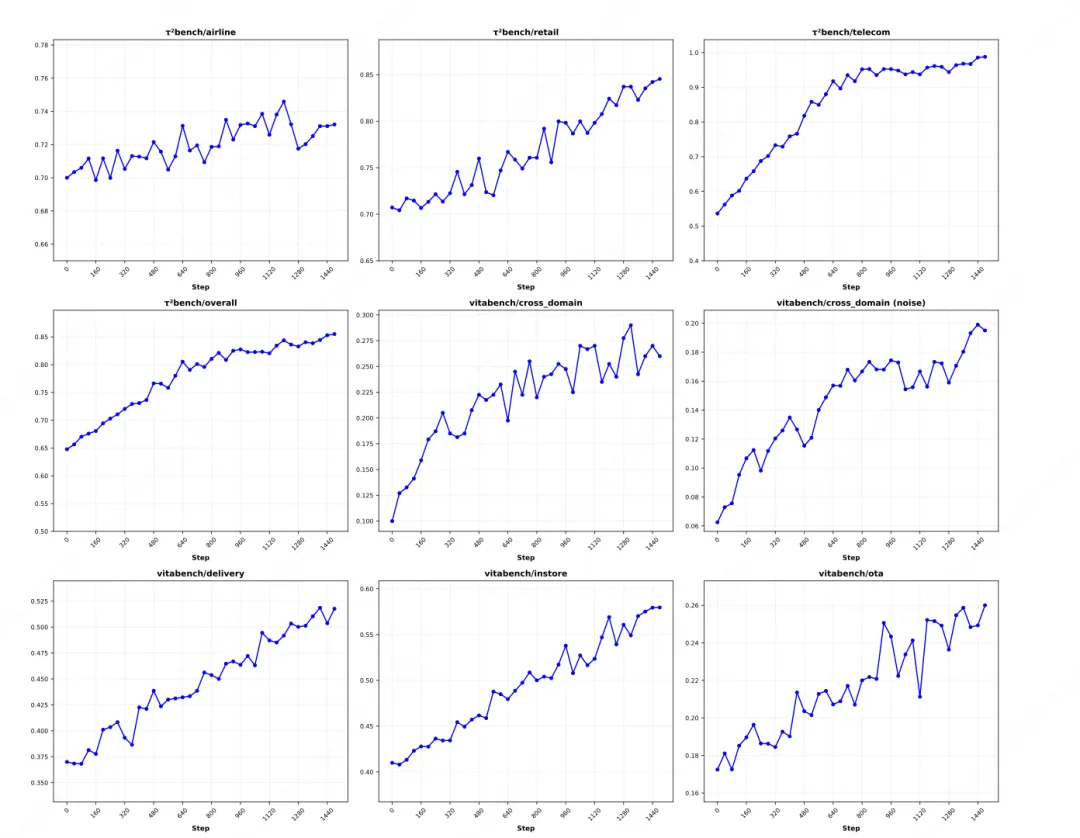
04 噪声环境下的稳健训练:系统化注入真实世界扰动
真实世界环境存在固有不完美性 —— 工具可能因网络问题随机失效、返回残缺结果,用户指令可能存在歧义、表述前后不一致,数据传输过程中还可能出现误差,这些噪声会导致仅在理想化完美环境中训练的模型,部署到真实场景后 “水土不服”,性能大幅下降。为此,LongCat 团队将真实世界的 “不完美” 纳入训练核心,设计系统化鲁棒性训练方案,提升模型在不确定环境中的稳定决策能力。
团队首先对真实世界噪声进行系统拆解与建模,明确两类核心噪声来源:
- 工具噪声:包括工具执行失败(如调用超时、权限不足)、返回结果不完整(如数据字段缺失)、响应格式不一致(如有时返回 JSON 有时返回文本)等场景;
- 指令噪声:涵盖用户表述歧义(如未明确任务目标)、指令信息冗余(如包含无关干扰内容)、需求动态变更(如中途调整任务参数)等情况。
这些噪声均基于真实场景观测总结,最大程度还原真实世界的不确定性。为使模型循序渐进适应噪声,团队采用 “课程学习” 注入策略:训练初期注入轻微扰动(如工具返回结果少部分缺失、指令存在轻微歧义),模型在当前噪声水平下表现出足够稳定性后,再逐步提升噪声复杂度与干扰强度(如工具频繁失效、指令严重模糊),形成稳健决策模式。
训练执行层面,团队将噪声注入与多环境训练深度融合:在20余个领域的上万种环境中,针对性加入不同类型、不同强度的噪声,使模型在学习各领域任务能力的同时,同步适应噪声环境。通过这种渐进式训练,模型最终能够在各种真实世界扰动下仍保持稳健的决策能力。
05 构建 “重思考机制”:让模型“做事”三思而后行
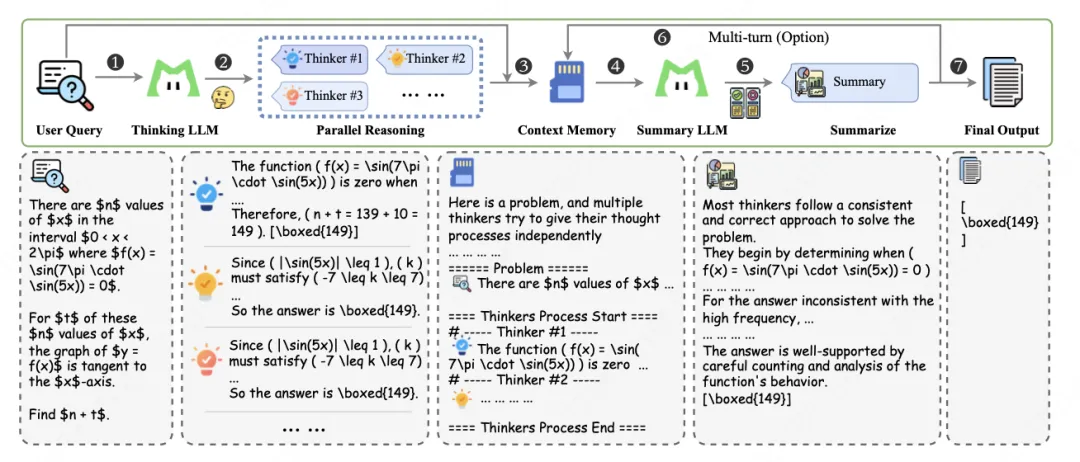
在特别复杂的任务上,模型有时会一根筋——沿着一条思路走到黑,即使那条路可能不对。这很像人类在遇到难题时,需要多想想不同的可能性。“重思考”模式的核心是 “宽度 + 深度” 双扩展:先让模型同时生成多条推理路径,探索不同的解决方案,再用专门的总结模型,对这些路径进行分析、筛选,提炼出最优思路。而且还会通过强化学习,让模型学会整合中间结果,不断完善推理过程。
在实际测试中,不管是长链推理、工具集成推理,还是完全的智能体工具使用场景,“重思考”模式都特别有效。随着测试时计算预算的增加,它的性能优势会越来越明显,比只扩展推理深度或宽度的策略表现好得多。
06 能力验证:不仅会做,而且做得稳、能泛化
在以下基准测试中,LongCat-Flash-Thinking-2601 的表现相当亮眼:在 BrowseComp 、τ²-Bench 、VitaBench 均达到开源模型中的顶尖水平,甚至在部分任务上逼近了闭源顶级模型。
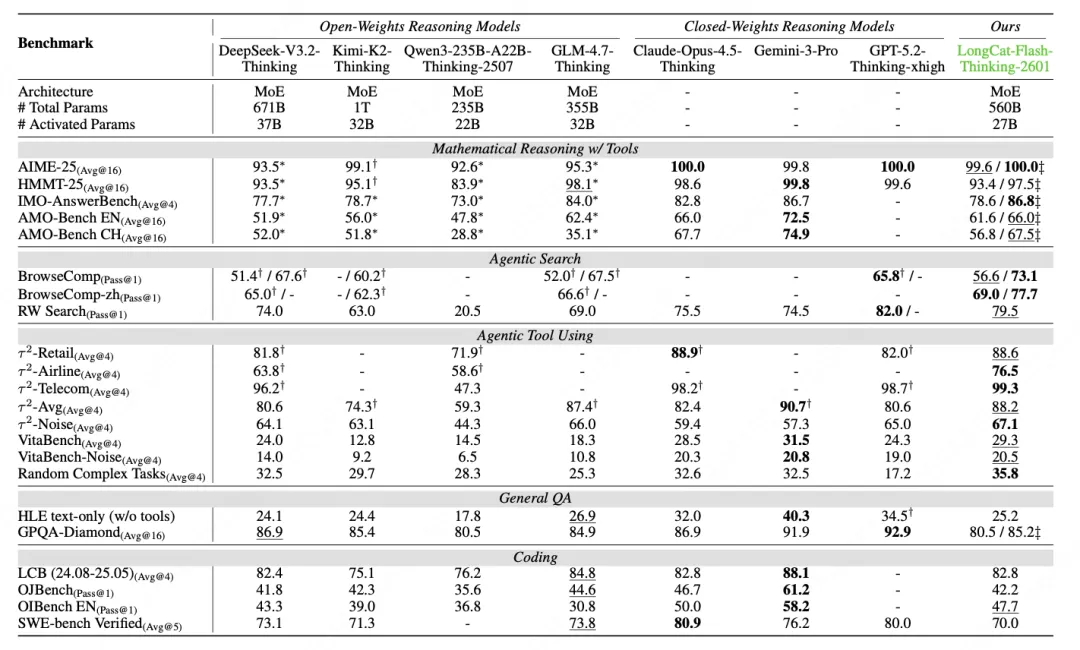
同时,模型展现出强泛化能力,在未见过的随机工具组合与任务中表现出色,掌握 “解决问题的元能力”;在注入真实噪声的测试集上,表现大幅超越其他模型,验证了主动噪声训练的有效性。通过算法与工程的深度协同,自动化环境构建降低适配成本,DORA 系统让训练效率提升 2-4 倍,Heavy Thinking 模式放大复杂任务处理能力,形成高效可扩展的训练体系。
07 One More Thing:Zigzag 注意力机制
传统全注意力机制的二次计算复杂度限制了其对百万级token上下文的支持,而现有稀疏注意力方案往往需要完全重训,成本高昂。
LongCat团队提出的**Zigzag注意力机制(Zigzag Attention)**创新性地结合了两种稀疏注意力模式:MLA(多头潜在注意力) 与 SSA(流式稀疏注意力)。该机制采用分层设计,在不同层中交替使用这两种稀疏注意力变体,避免了传统稀疏注意力中常见的计算不平衡问题,实现了更高的硬件利用率。
核心设计:对每个查询token,注意力被限制在以下两部分:
- 局部窗口:最近的W个token,捕捉短期依赖
- 全局锚点:序列开头的B个token,保留长期记忆
这一设计显著降低了计算和内存复杂度,同时保持了模型对短长期上下文的感知能力。
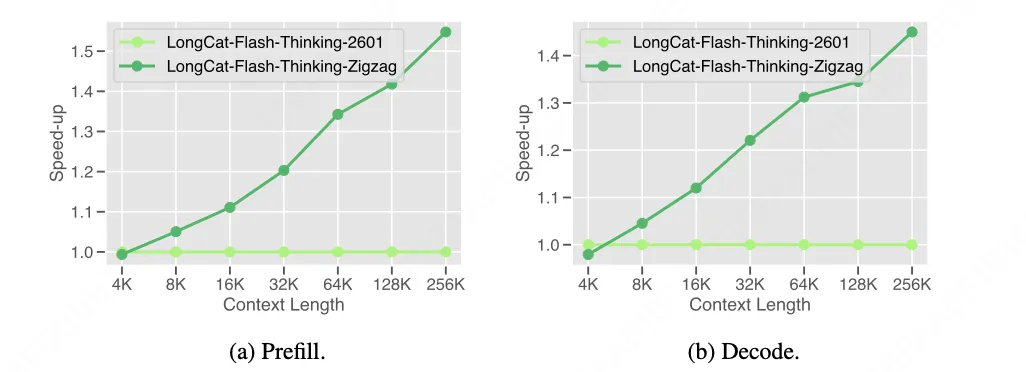
实施方式:Zigzag注意力在中期训练阶段引入,通过结构化稀疏化流程将原始全注意力模型高效转换为稀疏变体,转换开销极低。经过优化后的模型支持最长100万token的上下文长度,为超长序列处理提供了可行解决方案。
团队同步开源适配该机制的模型 LongCat-Flash-Thinking-ZigZag ,完整继承LongCat-Flash-Thinking-2601的核心能力,同时具备超长上下文处理优势,为开发者提供即拿即用的长序列解决方案。
08 总结
LongCat-Flash-Thinking-2601 通过环境扩展与噪声训练,显著降低了智能体对垂直场景的依赖,为开源模型在真实世界任务中的泛化能力设立了新的参考标准。我们相信,真正通用的智能体,不应是温室里的盆景,而应是能在真实世界风雨中扎根的大树。
LongCat-Flash-Thinking-2601 的发布,是我们向这个目标迈出的坚实一步。开源是我们播下的一颗种子,我们期待与整个社区一起,在这片名为“智能体”的星辰大海中,共同驶向辽阔的未来。
开源平台
- GitHub:https://github.com/meituan-longcat/LongCat-Flash-Thinking-2601
- Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking-2601
- ModelScope:https://www.modelscope.cn/models/meituan-longcat/LongCat-Flash-Thinking-2601
在线体验与调用
欢迎开发者下载、部署并体验 LongCat-Flash-Thinking-2601,同时也欢迎您在LongCat API 开放平台申请免费调用额度。如果您在智能体开发、大模型推理优化等领域有合作想法或反馈,我们期待与您交流。
| 关注「美团技术团队」微信公众号,阅读更多技术干货!
| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明“内容转载自美团技术团队”。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)