SCI制图——云雨图
“云雨图”(Raincloud Plot)能够巧妙地将核密度曲线、箱线图与原始数据散点图结合在一起,形象地构成了“云在天,雨在下”的视觉效果。这种图表不仅解决了传统统计图掩盖数据分布细节的缺陷,更以其极高的信息密度和优美的视觉形式,成为了近年来《Nature》、《Science》等顶级期刊中的新宠。本文将详细解读云雨图的构成、设计哲学及其在SCI论文中的应用价值。
SCI制图——云雨图简介(一)
在数据可视化领域,追求“信息透明度”与“美学价值”的平衡始终是科研绘图的核心目标。“云雨图”(Raincloud Plot)能够巧妙地将核密度曲线、箱线图与原始数据散点图结合在一起,形象地构成了“云在天,雨在下”的视觉效果。这种图表不仅解决了传统统计图掩盖数据分布细节的缺陷,更以其极高的信息密度和优美的视觉形式,成为了近年来《Nature》、《Science》等顶级期刊中的新宠。本文将详细解读云雨图的构成、设计哲学及其在SCI论文中的应用价值。
一、云雨图的结构
云雨图这一概念最早由 Micah Allen 等人在 2018 年正式提出,其核心设计理念是“原始数据与统计摘要并存”。它并非一种全新的单一图表,而是通过精巧的排布,将三种经典图表有机融合。要绘制一张标准的云雨图,我们需要理解其三个核心组成部分:
1.“云”:即半个小提琴图。通常位于图表的上方或水平布局时的上方。它是基于核密度估计(KDE)绘制的平滑曲线。与传统小提琴图不同,云雨图去除了冗余的镜像对称部分,只保留了一侧的密度曲线。这朵“云”负责展示数据的整体分布形态,告诉读者数据是正态分布、偏态分布还是多峰分布。
2.“雨”:即抖动散点图。位于图表的下方(或“云”的下方)。它展示了每一个原始数据点。为了防止数据点过多导致重叠,我们在绘制时会引入“抖动”算法,给每个点在非数值轴方向上增加微小的随机偏移。这些散落的点如同云层落下的雨滴,直观地反映了样本量的大小(n值)以及数据的具体落点。
3.“伞”:即箱线图或均值区间图。通常隐藏在“云”和“雨”的中间缝隙处,或者叠加在“雨”的上方。它负责提供精确的统计摘要信息,如中位数、四分位数(IQR)或均值与置信区间。它就像一把伞,撑起了数据的统计骨架。
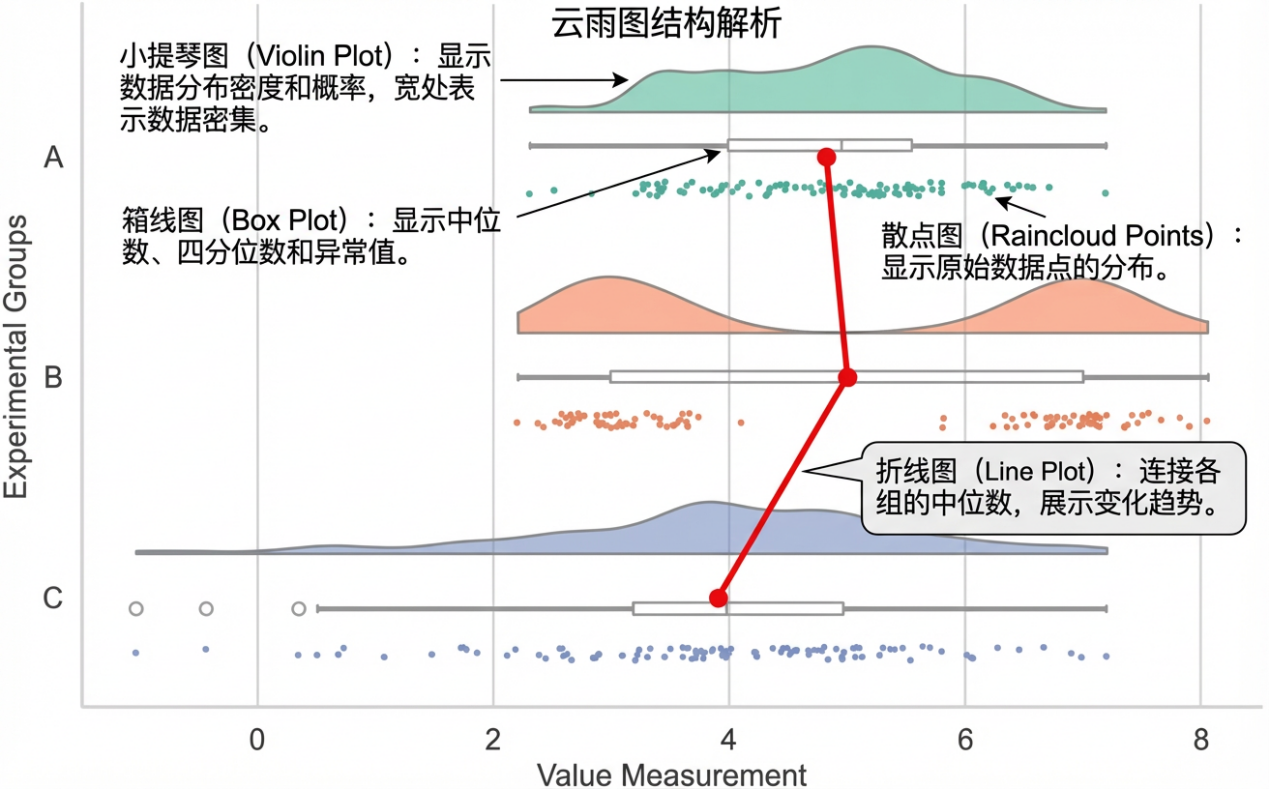
图1 云雨图结构示例
二、云雨图为何优于箱线图与小提琴图
在云雨图出现之前,研究者们往往在箱线图和小提琴图之间纠结。云雨图的出现,主要解决了以下两个核心痛点:
1. 提升空间利用率:传统的小提琴图是左右完全对称的。从信息论的角度来看,左半边和右半边传达的信息是完全重复的。这种对称性虽然美观,但浪费了宝贵的绘图空间。云雨图果断砍掉了一半的“琴身”,腾出的空间正好用来展示原始数据点(雨)。这种非对称的设计使得在同样的画布尺寸下,云雨图能承载双倍的信息量。
2. 揭示“黑箱”数据:箱线图虽然简洁,但它是一个“黑箱”。均值和方差相同的两组数据,其内部结构可能天差地别(例如一组是单峰,另一组是双峰)。小提琴图虽然展示了分布,但它极其依赖带宽参数的选择。如果样本量极少(例如 n=5),算法强行拟合出的平滑曲线会给读者一种“数据量很大且连续”的错觉。
云雨图通过下方的“雨点”,让审稿人一眼就能看穿数据的真相。如果“云”很胖但下面只有稀疏的几个“雨点”,读者立刻就能明白这是小样本拟合的结果,从而保持谨慎。
表1 各类图表功能深度对比
|
图表类型 |
统计摘要 (中位数等) |
分布形态 (多峰/偏态) |
原始数据 (颗粒度) |
样本量 (直观感) |
|
箱线图 |
✅ 优秀 |
❌ 掩盖 |
❌ 无 |
❌ 无法判断 |
|
小提琴图 |
✅ 良好 |
✅ 优秀 |
❌ 通常无 |
❌ 易误导 |
|
抖动散点图 |
❌ 较差 |
❌ 模糊 |
✅ 完美 |
✅ 优秀 |
|
云雨图 |
✅ 优秀 |
✅ 优秀 |
✅ 完美 |
✅ 优秀 |
三、关键应用场景
云雨图在心理学、神经科学、生物医学等领域正变得越来越流行,尤其适用于三种特定的科研场景:
1. 中等样本量与离群值检测:当样本量(n)在 10 到 100 之间时,单纯的散点图会显得杂乱无章,单纯的箱线图又显得过于单薄。云雨图能兼顾整体趋势与个体细节。特别是在检测离群值时,箱线图只能告诉你“有几个点在须之外”,而云雨图能让你看到这些离群值具体偏离了主群多远,有助于判断是测量误差还是具有生物学意义的特殊样本。
2. 多峰分布与异质性数据:在生物学实验中,样本往往具有异质性。例如,在药物反应实验中,可能有一部分小鼠反应强烈,而另一部分无反应。这种“双峰分布”在箱线图中会被掩盖成一个宽大的矩形,而在云雨图中,你会看到“云”变成了两个驼峰,下方的“雨”也聚集成两簇。这种发现往往能以此为契机,揭示潜在的亚群机制。
3. 重复测量数据的可视化:这是云雨图最强大的功能扩展之一。在展示同一组样本在不同时间点(如治疗前 vs 治疗后)的变化时,我们可以通过连线将下方的“雨点”一一对应连接起来。这样,读者不仅能看到组间整体分布的变化(云的移动),还能清晰地看到每个个体的变化轨迹(雨的连线)。这种图表被称为“配对云雨图”,在临床研究中极具说服力。
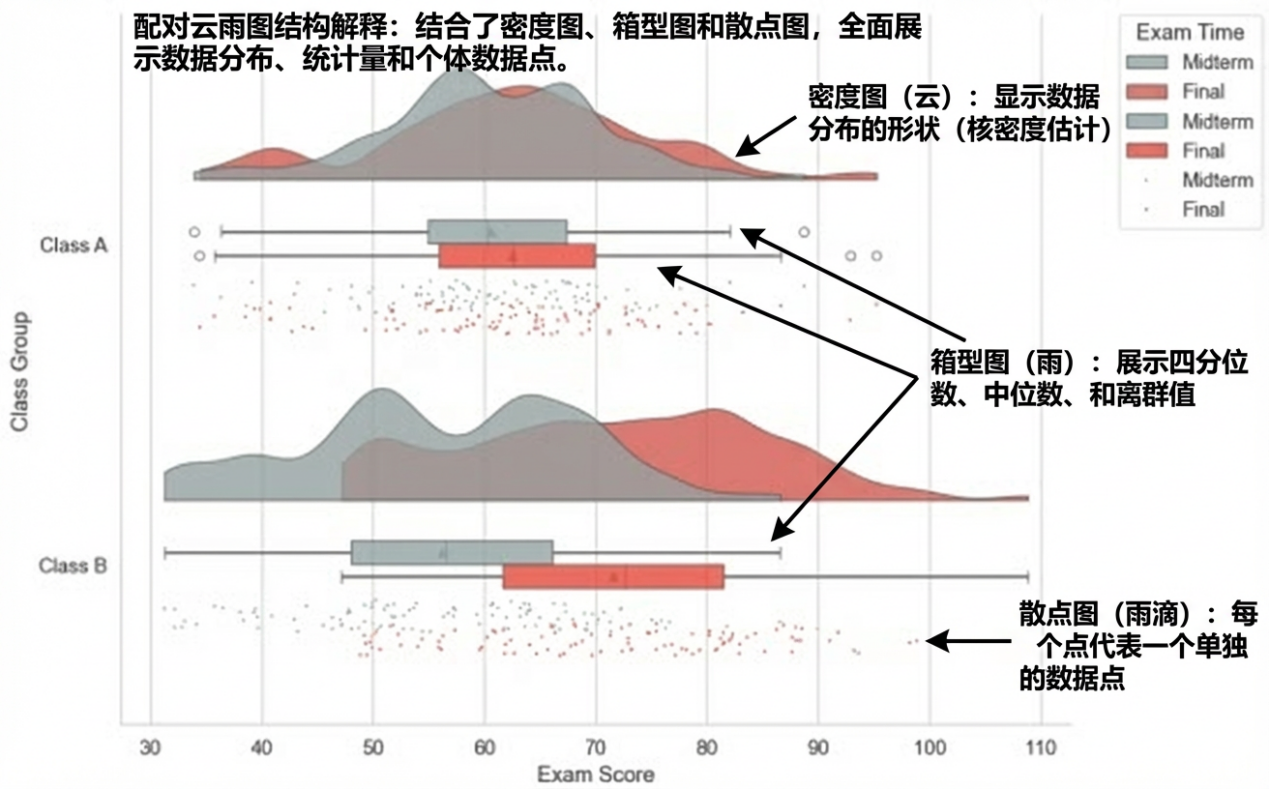
图2 带有连线的配对云雨图(展示治疗前后的个体变化)
四、制图美学与排版建议
一张高质量的云雨图,不仅要数据准确,还要符合 SCI 论文的审美标准。排版过程中,可以按照三个原则进行处理:
1. 推荐水平排布(Horizontal Layout):虽然垂直绘制也可以,但水平排布是云雨图的最佳姿态。首先,水平排布符合从左到右的阅读习惯。其次,分类变量的标签(如“Treatment Group A with long name”)通常较长,水平排布的 Y 轴有足够的空间容纳长文本,避免了文字倾斜或重叠,使图表更加整洁。
2. 配色策略(Color Strategy):为了保持视觉的一致性,建议“云”和“雨”使用同一色系。通常将“云”的透明度(Alpha)设置在 0.5-0.7 之间,使其显得轻盈;而“雨点”的颜色可以稍深,或者保持半透明,以便在数据重叠时能产生加深效果。
3. 抖动幅度的控制:“雨点”的抖动幅度(Jitter width)至关重要。抖动太小,点会连成一条线,无法看清;抖动太大,点会扩散到相邻的组别中,造成混淆。优秀的云雨图,其“雨点”的宽度应严格控制在“云”的投影范围内,保持一种“雨滴落在云影下”的秩序感。
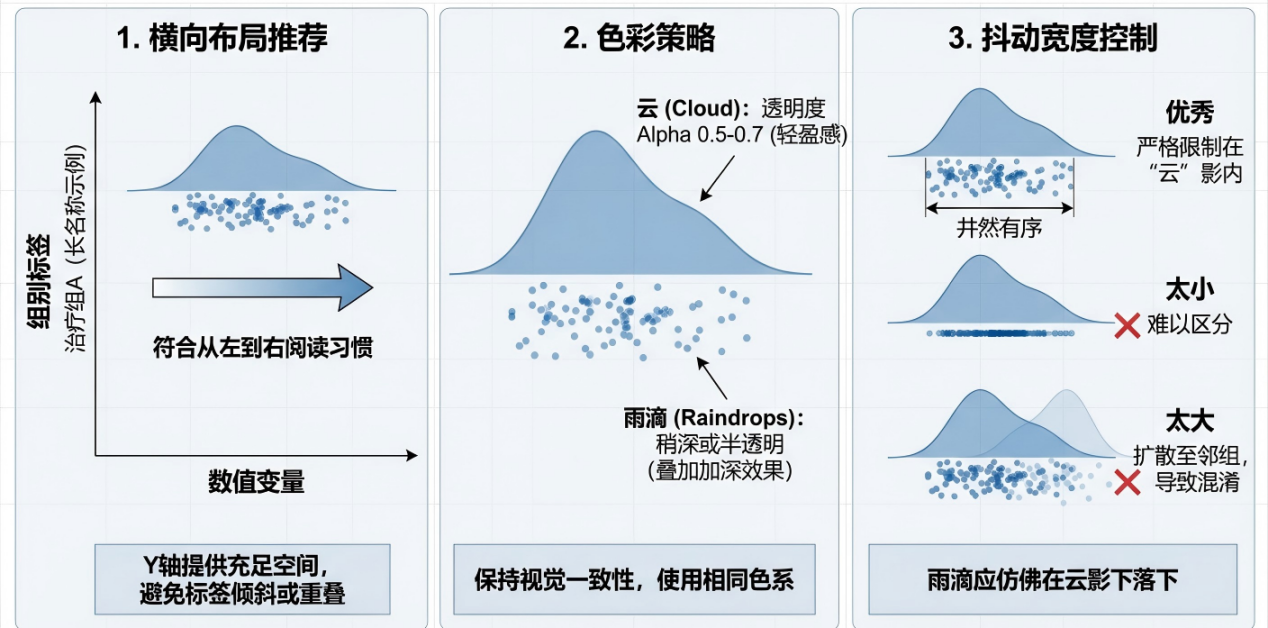
五、总结
随着科学研究对数据再现性要求的不断提高,单纯展示均值和标准差的“条形图时代”正在逐渐远去。云雨图不仅仅是一种图表技术的革新,更代表了一种诚实的科研态度——它敢于展示每一个原始数据点,经得起审稿人最严苛的审视。
SCI绘图——在RStudio中通过ggplot2构建云雨图(二)
在前一章中,我们深入剖析了云雨图的结构与设计哲学。它以极高的信息密度和优美的非对称设计,成为了展示数据分布的神器。然而,对于许多科研工作者而言,理解原理是一回事,将其转化为代码又是另一回事。本篇教程将作为实战续篇,专注于技术实现。我们将使用R语言配合 RStudio ,依托于 ggplot2 图层语法,一步步复现这一顶级期刊偏爱的图表。
R语言环境的安装可以参考《Windows平台R环境下载与安装全指南》这篇教程,按照教程完成环境的安装后,即可进行下一步。
一、准备R语言的内置数据集
1.认识经典数据:植物学家最爱的“鸢尾花(iris)”
我们将要使用的,是数据科学界最著名的“明星”数据集——鸢尾花数据(iris)。这套数据源自1936年,由著名的统计学家罗纳德·费希尔(Ronald Fisher)整理。虽然它年代久远,但至今仍是几乎所有数据分析教程的入门首选。
这个数据集非常直观且贴近科研场景。它记录了150朵鸢尾花的测量数据。这些花分属于三个不同的品种:Setosa(山鸢尾)、Versicolor(变色鸢尾)和Virginica(维吉尼亚鸢尾)。对于每一朵花,植物学家都测量了四个特征:萼片长度(Sepal.Length)、萼片宽度(Sepal.Width)、花瓣长度(Petal.Length)和花瓣宽度(Petal.Width)。你可以把它想象成一份记录了150个样本的实验记录表,非常适合用来练习如何展示组间差异。
2.查看数据的行(样本)与列(变量)
在开始绘图之前,我们需要先看一眼这份数据长什么样。在RStudio中,数据并不像在Excel中那样直接铺开显示,我们需要通过指令来查看。首先打开RStudio,从开始菜单中或桌面快捷方式打开都可以。
图1 找到RStudio并打开
打开RStudio后,我们需要在请其中输入以下代码并运行:
# 加载iris数据集(虽然它通常默认已加载,但这行代码是个好习惯)
data(iris)
# 查看数据的前6行
head(iris)运行后,你会在下方看到一张表格。这里有两个核心概念需要理解:
(1)行(Rows):每一行代表一个样本,也就是一朵具体的花。
(2)列(Columns):每一列代表一个变量(属性)。你会看到 Sepal.Length(数值型变量)和 Species(分类变量)等列名。
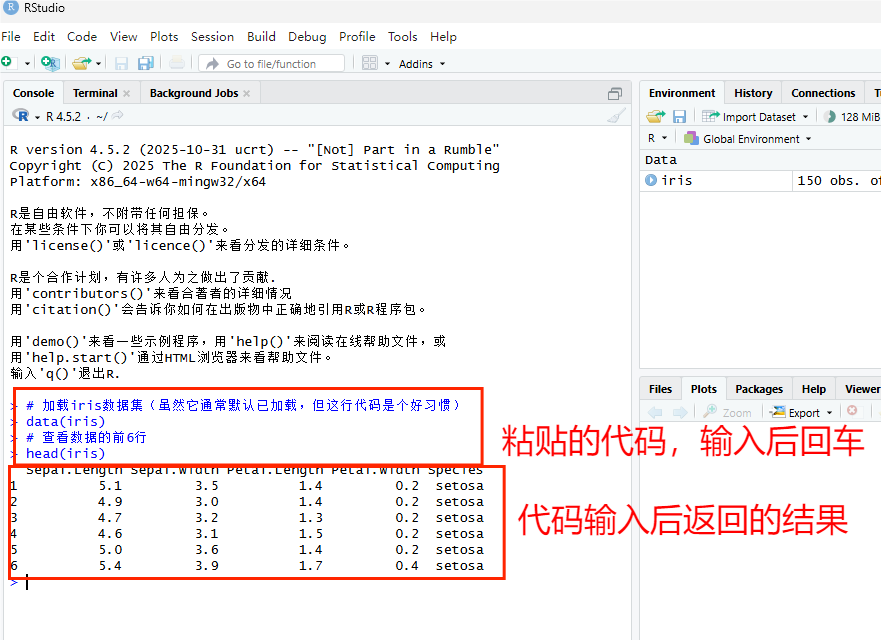
图2 在RStudio中输入代码并获得数据集信息
理解这一点非常重要:ggplot2绘图的核心逻辑,就是将这些“列”映射到图表的图形属性上。
3.明确绘图目标:我们将分析不同品种花朵的萼片长度差异
做科研绘图,切忌“为了画图而画图”,每一张SCI图表背后都应该有一个明确的科学问题。在本教程中,我们的科学假设是:“不同品种的鸢尾花,其萼片长度可能存在显著差异”。
为了验证并展示这一差异,我们便可以利用R语言绘制一个云雨图。在这个图表中:
(1)横轴(X轴):我们将放置 Species(品种)这一列。因为它是分类变量,可以将数据自然地分成三组。
(2)纵轴(Y轴):我们将放置 Sepal.Length(萼片长度)这一列。这是我们要比较的具体数值。
云雨图将能够同时展示这三组数据的分布形态(通过“云”即半小提琴图)、原始数据点(通过“雨”即抖动散点图)以及统计概况(通过“伞”即箱线图)。明确了这一目标后,我们就可以开始构建我们的绘图图层了。
二、理解ggplot2的绘图逻辑
1.什么是ggplot2:图层叠加的绘图思想
ggplot2 中的 “gg” 代表 “Grammar of Graphics”(图形语法)。它认为一张完整的统计图形,并不是一个不可分割的整体,而是由不同的图层叠加而成的。想象一下你在使用Photoshop,或者是在画一幅油画。你不会一次性把所有的东西都画出来,而是分步骤进行:首先铺一张白纸(建立坐标系),然后在上面画出散点(数据层),接着画上趋势线(统计层),最后再给图片加上标题和调整背景颜色(美化层)。
在ggplot2中,我们也需要这样做。我们通过“+”号将不同的代码连接起来,就像把一张张透明的幻灯片叠在一起。这种“图层叠加”的逻辑给了我们极大的自由度——如果你想修改散点的颜色,只需要修改散点那个图层的代码,而不会影响到背景或坐标轴。这就是为什么ggplot2能画出如此复杂且精美图表的原因。
2.核心三要素:数据、映射、几何对象
要构建任何一张ggplot2图表,无论它多么复杂,都离不开三个最基础的要素。你可以把它们看作是烹饪一道菜的三个步骤:
(1)数据:这是我们的“食材”。在上一章中,我们已经准备好了 iris 数据集。ggplot2需要知道它要从哪张表格里读取信息。
(2)映射:这是最关键的概念,通常用 aes() 函数表示。它的作用是建立“数据列”与“图形属性”之间的桥梁。比如,我们需要告诉软件:请把表格里的 Species(品种)这一列数据,对应到图表的 X轴 上;把 Sepal.Length(萼片长度)这一列数据,对应到图表的 Y轴 上。这就叫“映射”。
(3)几何对象:这是数据的“形状”。确定了X轴和Y轴的数据后,你是希望这些数据表现为散点?柱状图?还是箱线图?这些不同的形状在ggplot2中被称为几何对象。
3. 开始建立画布
现在,让我们动手写下第一行绘图代码。在这个阶段,我们先不急着画出具体的图形,而是先要把“画布”搭好,也就是定义好数据和映射。在RStudio中输入以下代码:
# 首先,我们需要安装并加载ggplot2包
install.packages("ggplot2")
library(ggplot2)
# 建立基础画布
# data = iris : 指定使用iris数据集
# aes(...) : 指定映射关系,X轴为品种,Y轴为萼片长度
ggplot(data = iris, aes(x = Species, y = Sepal.Length))运行这段代码后,首先程序会自动完成安装与加载步骤,如图所示:
图3 ggplot2包的安装与加载
然后请观察RStudio右下角的“Plots”窗口。你会看到一个灰色的背景,底部写着 Species,左侧写着 Sepal.Length,但是图里面空空如也,没有任何数据点。
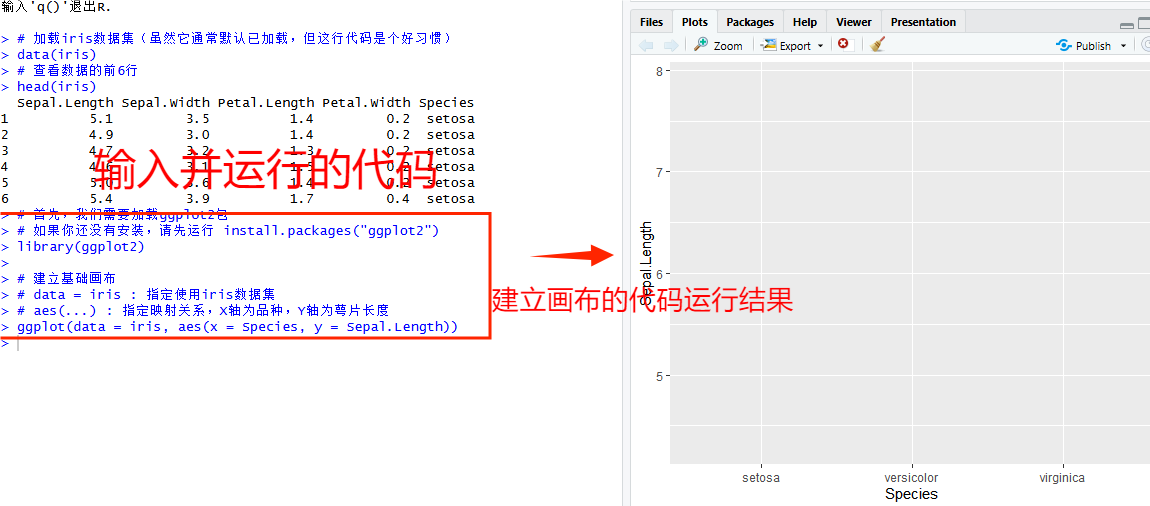
图4 输入画布建立代码并运行的结果
画布内容为空是因为目前位置代码中只指定完成了前两个要素(数据和映射),我们告诉了R语言要用什么数据,以及坐标轴代表什么,但我们还没有告诉它要画什么形状(几何对象)。接下来我们需要通过“+”号,在这个空白的画布上一层层地添加云、雨和伞。
三、实战演练(上)——画出“云”部分
画布已经搭好,现在我们要开始往上面添加内容了。云雨图之所以得名,是因为它由三部分组成:像云一样的密度图、像雨一样的散点图,以及像伞一样的箱线图。我们首先来绘制最上方的“云”,也就是半小提琴图。
1.引入gghalves扩展包
ggplot2 虽然功能强大,但它默认提供的几何对象中只有“全小提琴图”(geom_violin)。在这种情况下,我们需要额外的扩展包 gghalves。请复制并粘贴运行以下代码:
# 安装gghalves包
install.packages("gghalves")
# 加载 gghalves 包
library(gghalves)运行后,效果应如下图所示:
图5 gghalves 包安装与加载结果
2.绘制半小提琴图:展示数据的密度分布
所谓的“云”,在统计学上被称为密度图。它展示了数据在不同数值上的分布密集程度。想象一下,如果把所有的数据点堆在一起,哪里堆得最高,“云”的轮廓就在哪里隆起;哪里数据稀少,“云”就变得扁平。通过观察“云”的胖瘦,我们可以一眼看出哪组数据的分布比较集中,哪组比较分散。为了在画布上增加这层“云”,我们需要使用 geom_half_violin() 函数。
# 基础画布 + 半小提琴图图层
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
geom_half_violin()运行这段代码,你就能看到三个黑白轮廓的“半边小提琴”出现在画面上,如图所示:
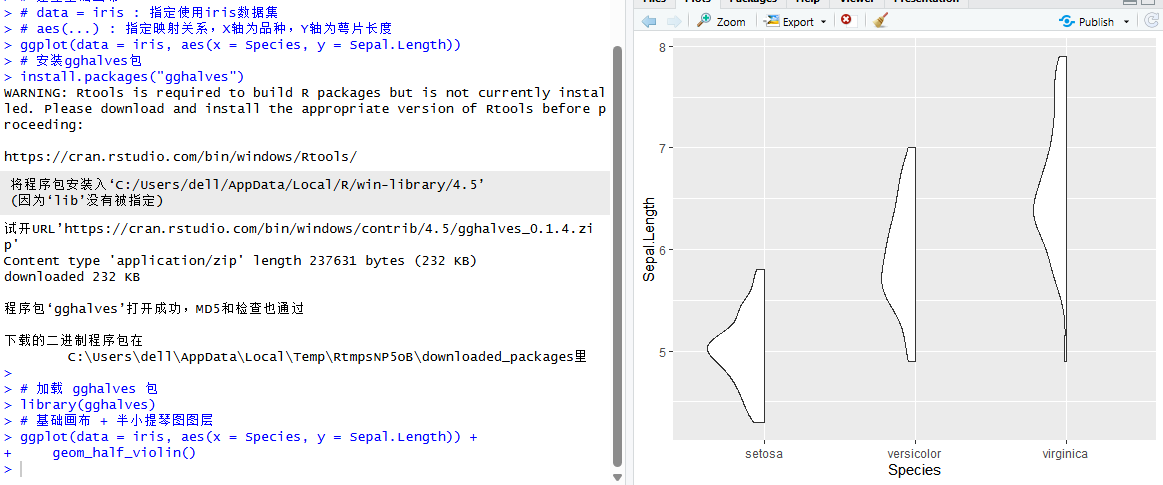
图6 geom_half_violin()函数运行结果
3. 调整“云”的方向与位置
为了给后续的“雨”和“伞”腾出空间,我们需要对“云”做两件事:第一,给它上色,让不同品种的花显示不同的颜色;第二,把它向右推一点,不要挡在正中间。在 ggplot2 中,颜色是通过 aes(fill = Species) 来映射的,这意味着“填充颜色由品种决定”。而位置的调整,我们需要用到 side 参数(决定保留左半边还是右半边)和 position 参数(决定位置的偏移)。
请复制并粘贴运行以下优化后的代码:
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
geom_half_violin(
aes(fill = Species), # 映射:根据品种填充不同的颜色
side = "r", # 细节:只保留右半边(right)
position = position_nudge(x = 0.1) # 细节:向右平移0.1个单位,腾出中间位置
)现在再看你的绘图窗口:三个彩色的“云朵”已经优雅地飘在了每一组数据的右侧。左侧留出的空白区域,正是我们接下来要安排“下雨”的地方。
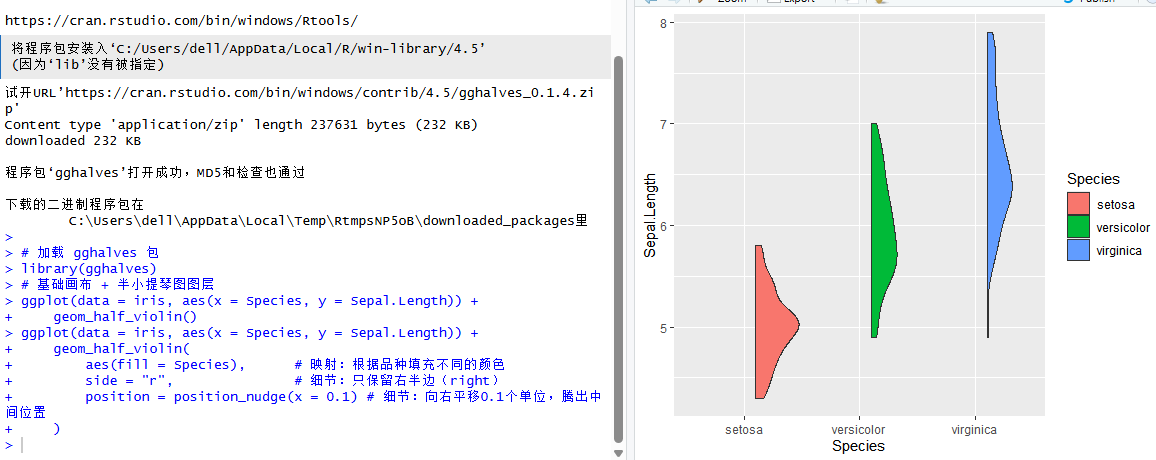
图7 使用aes(fill=Species)映射颜色
四、实战演练(中)——画出“雨”部分
“云”已经飘在了右侧,描绘出了数据的整体轮廓。接下来,我们要画出“雨”。在云雨图中,“雨”代表的是每一个真实的原始数据点。我们将使用散点图来实现这一部分,但不是普通的散点,而是带有抖动效果的散点。
1.绘制抖动散点图:展示每一个原始数据点
如果我们直接把150个数据点画在图上,会遇到一个大问题:很多花朵的萼片长度是一样的(例如都是5.0cm)。如果直接画,这些点会重叠在一起,看起来像只有一个点。
为了解决这个问题,我们需要给数据点加上一点点随机的“抖动”。ggplot2 提供了一个非常经典的函数 geom_jitter(),它就像是把一把沙子撒在地上,让沙粒自然散开,不再重叠。
请复制并粘贴以下代码:
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
# 云:为了给雨腾出空间,我们将云向右平移的距离增加到 0.2
geom_half_violin(
aes(fill = Species),
side = "r",
position = position_nudge(x = 0.2), # 注意这里改成了 0.2
color = NA # 去掉小提琴图的边框线,让画面更干净
) +
# 雨:使用经典的抖动散点
geom_jitter(aes(color = Species))运行后,你会发现左侧出现了一排排密集的点,这就是我们的“雨”。
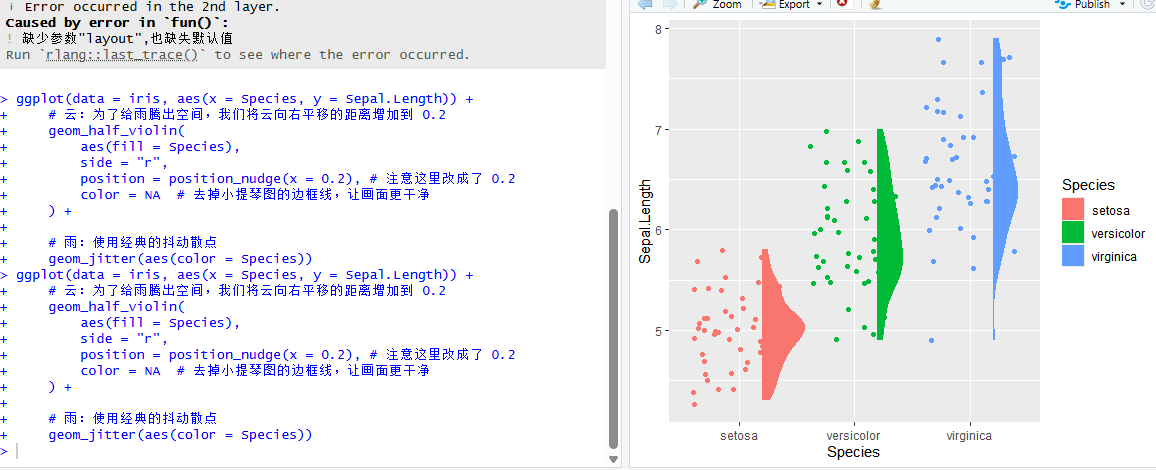
图8 geom_jitter() 函数运行结果
2. 调整“雨”的大小与透明度:避免数据重叠过于拥挤
现在的“雨”可能看起来有点太大了,我们需要对这些点进行调整。这里有两个关键参数:
1.size(大小):控制点的大小。数值越小,点越精细。
2.alpha(透明度):这是一个0到1之间的数值。1代表完全不透明,0代表完全透明。设置透明度的好处是,当多个点重叠时,颜色会变深,这样我们既能看到个体,又能直观感受到哪里数据最密集。
让我们把点变小一点,并加上半透明效果,复制并粘贴运行以下代码:
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
geom_half_violin(aes(fill = Species), side = "r", position = position_nudge(x = 0.2), color = NA) +
geom_jitter(
aes(color = Species),
size = 1.5, # 设置点的大小
alpha = 0.6 # 设置60%的不透明度,让点看起来通透一些
)如图所示,现在这些点已经经过了调整。
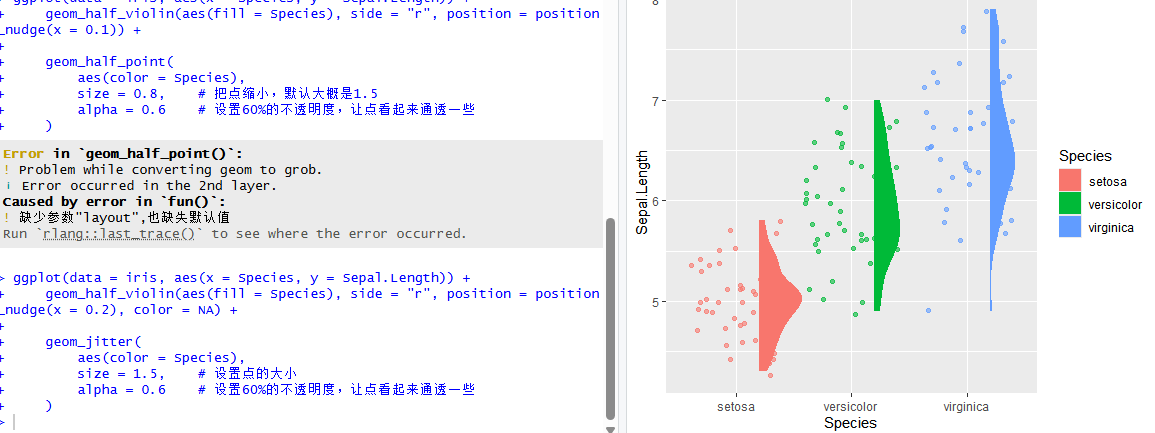
图9 点位调整
3.避免数据重叠过于拥挤
为了视觉上的平衡,我们需要把“雨”(散点图)严格限制在左侧。geom_half_point() 函数非常智能,它也有一个 side 参数。我们只需要把它设为 "l" (left),它就会自动乖乖地待在左边。此外我们可以通过 range_scale 参数来控制雨点“散开”的宽度,避免它们散得太宽撞到旁边的组。
复制并运行以下代码:
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
# 云:飘在右侧 (x + 0.2)
geom_half_violin(
aes(fill = Species),
side = "r",
position = position_nudge(x = 0.2),
color = NA
) +
# 雨:限制在中心附近,宽度控制在 0.15
geom_jitter(
aes(color = Species),
width = 0.15, # 关键:限制抖动宽度,防止撞到云
size = 1.5,
alpha = 0.6
)现在观察绘图窗口,如图所示:左边是细碎的彩色雨点(原始数据),右边是饱满的云朵(密度分布),它们中间留出了一条缝隙,实现了完美呼应。
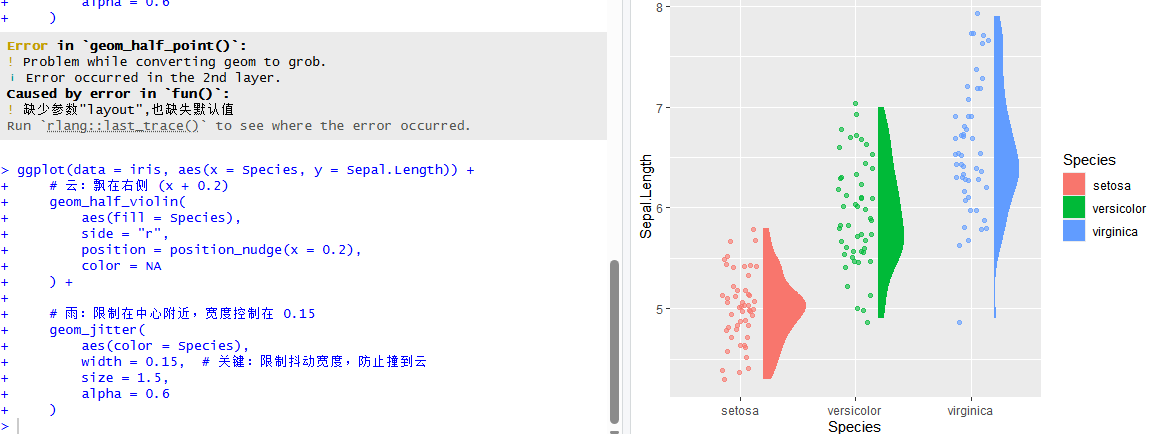
图10 完成调整后的绘图
五、实战演练(下)——画出“伞”部分
云雨图的三大组件,我们已经完成了“云”(密度分布)和“雨”(原始数据)。现在,图表还缺最后一块拼图——“伞”,即箱线图。
1.添加箱线图:展示中位数与四分位数
虽然“云”告诉了我们数据的形状,“雨”展示了每一个点,但科研论文中通常还需要精确的统计指标来进行针对性分析。箱线图能极其高效地传达以下信息:
(1)箱子中间的粗线:代表中位数(50%的数据在这个数值以下)。
(2)箱子的上下边界:代表四分位数(中间50%的数据集中在这个范围内)。
(3)上下的“胡须”:代表数据的延伸范围。
让我们先试着把箱线图直接加到画布上,这里使用R语言自带的 geom_boxplot() 函数。复制并粘贴运行以下代码:
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
# 云
geom_half_violin(aes(fill = Species), side = "r", position = position_nudge(x = 0.2), color = NA) +
# 雨
geom_jitter(aes(color = Species), width = 0.15, size = 1.5, alpha = 0.6) +
# 伞:直接添加箱线图
geom_boxplot()运行后你会发现一个大问题:默认的箱线图太宽了,像一个巨大的盒子盖住了我们的“雨”和“云”,画面变得非常难看。我们需要给它瘦身。
2.微调箱线图并绘制完整图像
为了让箱线图优雅地融入云雨图,我们需要对它进行三项重要的手术:
(1)瘦身(width):将它的宽度设置得很小,变成一条细长的矩形。
(2)移位(position):它必须和“云”待在一起。既然“云”向右平移了0.2,箱线图也应该向右平移0.2,这样它就会正好位于“云”的平直边缘,像云朵的脊梁骨一样。
(3)隐藏离群点(outlier.shape = NA):这是最关键的一点。因为我们已经画了“雨”(所有原始数据点),箱线图默认会画出的“离群点(黑点)”就属于重复信息。如果不隐藏,图上会有双重的点,这是不严谨的。
另外,在 ggplot2 中,图层的顺序是由代码的先后顺序决定的:后写的代码会盖住先写的代码。为了获得最佳的视觉效果,通常建议顺序是:
(1)最底层:画“云”(半小提琴图),作为背景轮廓。
(2)中间层:画“伞”(箱线图),压在云的边缘,清晰可见。
(3)最顶层:画“雨”(散点图)。虽然它们在左侧,通常不会重叠,但把散点放在代码最后是一个好习惯,确保数据点永远不会被其他图形遮挡。
现在,让我们把所有代码整合在一起,复制并粘贴运行以下调整后的代码:
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
# 1. 画云(半小提琴图)
geom_half_violin(
aes(fill = Species),
side = "r",
position = position_nudge(x = 0.2),
color = NA
) +
# 2. 画伞(箱线图)- 注意这里用 + 号连接了
geom_boxplot(
width = 0.1,
position = position_nudge(x = 0.2),
outlier.shape = NA,
fill = "white",
color = "black"
) +
# 3. 画雨(抖动散点图)
geom_jitter(
aes(color = Species),
width = 0.15,
size = 1.5,
alpha = 0.6
)运行这段代码,你应该能看到一张结构清晰的图表:左侧是缤纷的雨点,右侧是彩色的云朵,云朵的直边上镶嵌着白色的箱线图。这不仅是一张图,更是一份包含了分布、统计和原始数据的完整分析报告。接下来,我们只需要对它进行美化,就能直接用于SCI投稿了。
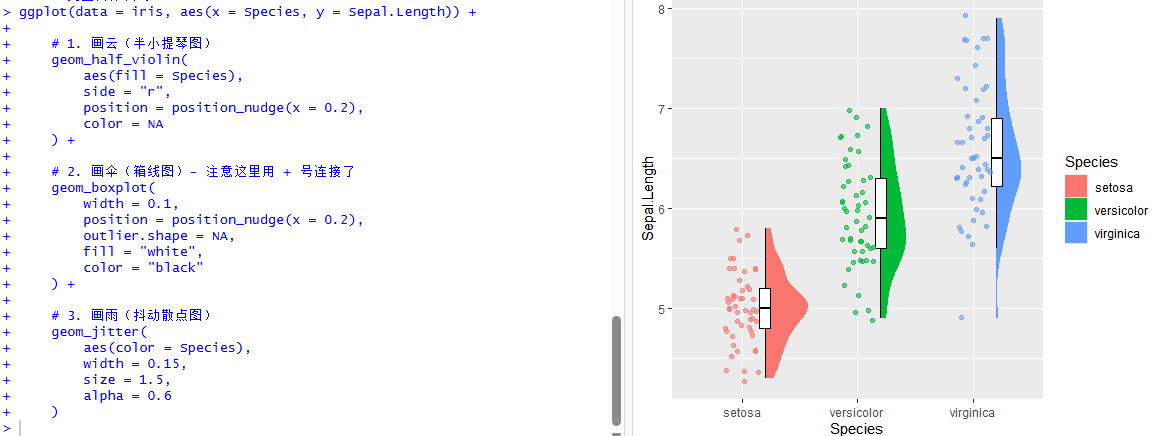
图11 完成绘制的图表
六、美化绘图内容
经过前面的努力,我们已经搭建起了云雨图的基本形态。现在的图表虽然信息完整,但看起来还略显粗糙。为了让它能够登上SCI期刊的版面,我们需要对它进行美化。
1.让云雨图横向展示
你可能注意到了,目前的图表是竖直排列的。虽然这没有错,但在云雨图的惯例中,横向排列往往更受欢迎。横向排列时,品种的名称(X轴标签)是从左往右写的,读者阅读起来更自然,不需要歪着头看;同时,“云朵”横向漂浮看起来更具流动感,视觉上也更平衡。
在 ggplot2 中,实现这一点不需要重写代码,只需要加一个神奇的函数:coord_flip()。它的作用是将X轴和Y轴在视觉上互换。复制并粘贴运行以下代码:
# 在原有代码的基础上加上 coord_flip()
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
geom_half_violin(aes(fill = Species), side = "r", position = position_nudge(x = 0.2), color = NA) +
geom_boxplot(width = 0.1, position = position_nudge(x = 0.2), outlier.shape = NA, fill = "white") +
geom_jitter(aes(color = Species), width = 0.15, size = 1.5, alpha = 0.6) +
# 翻转坐标轴
coord_flip()运行后的效果如图所示,可以看到图像已经得到了横向展示:
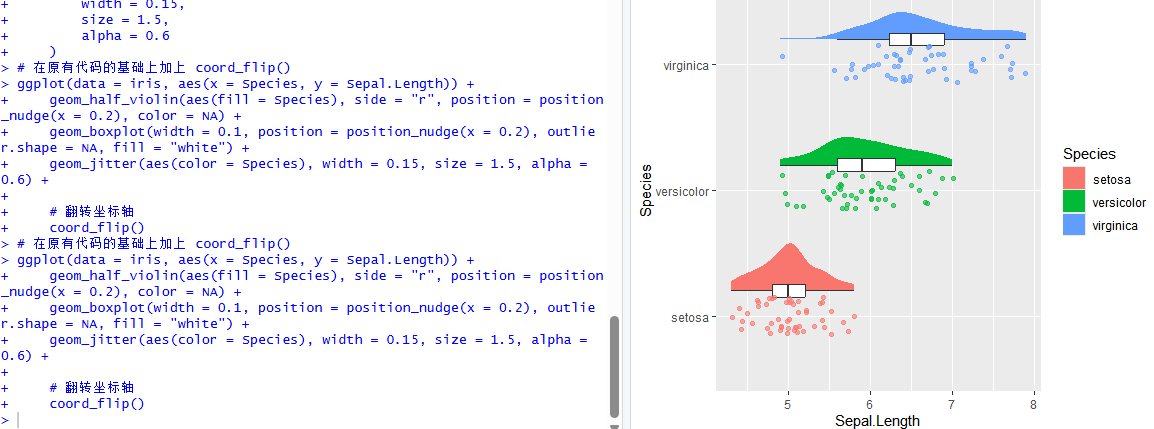
图12 横向调整展示效果
2.使用经典的SCI配色方案
默认的红绿蓝配色虽然区分度高,但缺乏高级感。顶级期刊(如Nature, Science, JCO等)都有自己独特的配色偏好。这里我们需要引入一个新的扩展包 ggsci。它预设了许多著名期刊的配色方案。比如,我们可以使用 scale_fill_jco() 和 scale_color_jco() 来应用《临床肿瘤学杂志》(JCO)的经典配色,这种配色稳重且专业。复制并粘贴运行以下代码:
install.packages(c("ggsci", "ggpubr"))
library(ggsci)
library(ggpubr)
# 在代码中添加配色层
# 注意:我们需要同时设置填充色(fill)和线条色(color)
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
geom_half_violin(aes(fill = Species), side = "r", position = position_nudge(x = 0.2), color = NA) +
geom_boxplot(width = 0.1, position = position_nudge(x = 0.2), outlier.shape = NA, fill = "white") +
geom_jitter(aes(color = Species), width = 0.15, size = 1.5, alpha = 0.6) +
# 翻转坐标轴
coord_flip()
scale_fill_jco() + # 改变云的填充色
scale_color_jco() # 改变雨点的颜色完成后,即可达到调整配色的效果,如图所示:
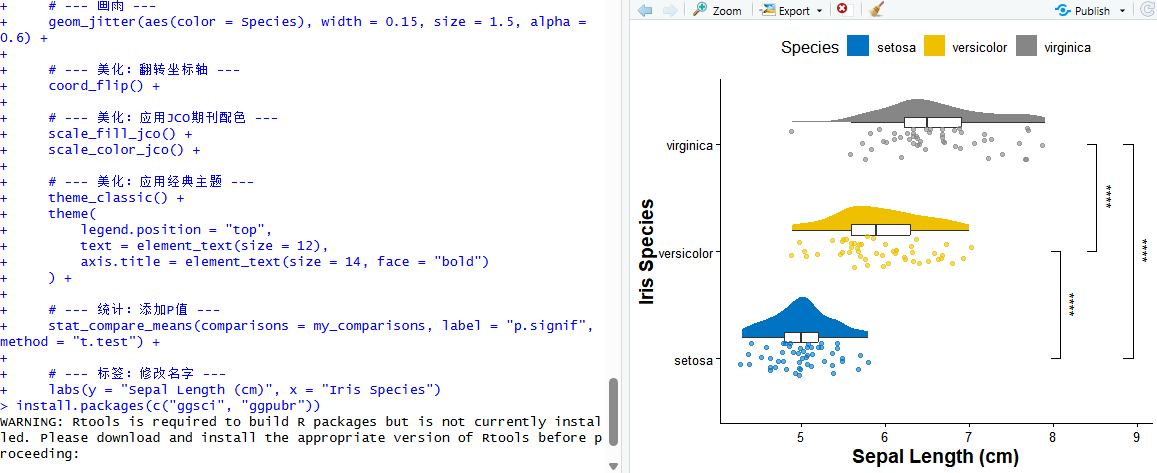
图13 配色方案调整效果
3. 调整背景、网格线与坐标轴字体
ggplot2 默认的灰色背景和白色网格线被称为灰底风格,这在屏幕上显示还不错,但打印在论文里往往显得不够干净。SCI绘图推崇“高数据墨水比”,即尽量减少与数据无关的墨水。
因此我们可以使用 theme_classic() 主题,它会去除背景和网格线,只保留坐标轴线。此外还需要调整字体大小,确保图片缩小后文字依然清晰可见。复制并执行以下代码:
# 1. 检查并安装必要的包
if (!requireNamespace("gghalves", quietly = TRUE)) {
install.packages("gghalves")
}
# 2. 加载包
library(ggplot2)
library(gghalves) # 必须加载这个包才能使用 geom_half_violin
# 3. 绘图
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
# --- 几何对象层 ---
# 半小提琴图 (使用 fill 映射)
# side = "r" 表示画在右侧
geom_half_violin(aes(fill = Species), side = "r", position = position_nudge(x = 0.2), color = NA) +
# 箱线图 (设置 fill="white" 使其在中间突出)
geom_boxplot(width = 0.1, position = position_nudge(x = 0.2), outlier.shape = NA, fill = "white") +
# 抖动散点图 (使用 color 映射)
# 注意:这里放在左侧,因为小提琴图被nudge到了右侧
geom_jitter(aes(color = Species), width = 0.15, size = 1.5, alpha = 0.6) +
# --- 配色层 ---
# 设置填充色 (对应 geom_half_violin)
scale_fill_manual(values = c("setosa" = "#00AFBB", "versicolor" = "#E7B800", "virginica" = "#FC4E07")) +
# 设置线条/点颜色 (对应 geom_jitter)
# 保持与填充色一致,视觉效果最好
scale_color_manual(values = c("setosa" = "#00AFBB", "versicolor" = "#E7B800", "virginica" = "#FC4E07")) +
# --- 坐标轴与主题 ---
# 翻转坐标轴
coord_flip() +
# 使用简洁主题
theme_minimal() +
# 去掉图例
theme(legend.position = "none")效果如图所示,背景、网格线、坐标轴的字体都得到了调整:
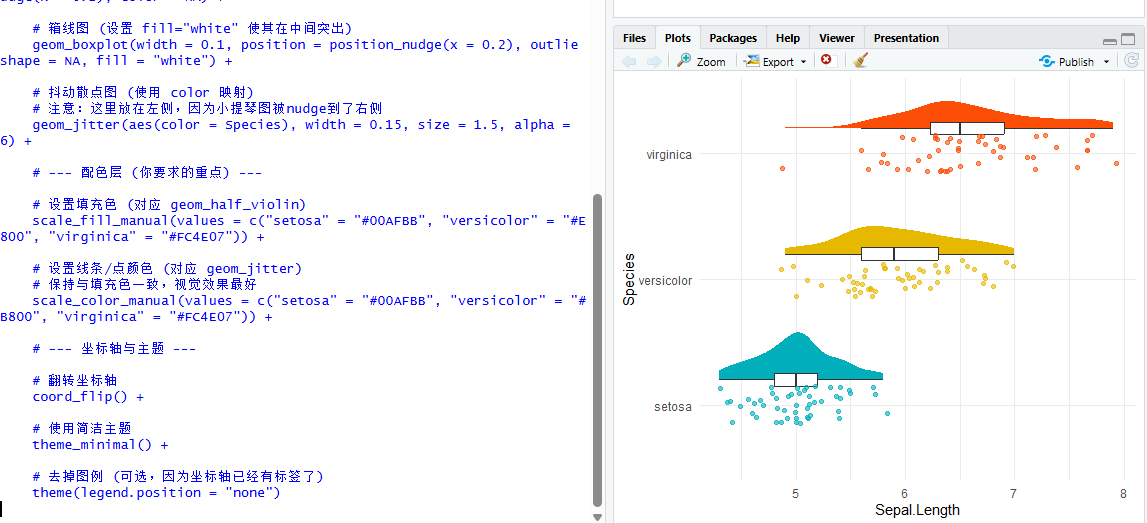
图14 背景、网格线与坐标轴字体调整效果
4. 添加显著性标记
最后,作为一张统计图表,如果没有P值(显著性标记),它的灵魂就少了一半。我们需要告诉读者:这些品种之间的差异在统计学上是有意义的吗?我们可以使用 ggpubr 包中的 stat_compare_means() 函数来自动计算并标注P值。这比我们自己算完再用PS加上去要准确和方便得多。
library(ggplot2)
library(gghalves)
library(ggsci)
library(ggpubr)
# 准备比较组
my_comparisons <- list( c("setosa", "versicolor"), c("versicolor", "virginica"), c("setosa", "virginica") )
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
# 1. 云
geom_half_violin(aes(fill = Species), side = "r", position = position_nudge(x = 0.2), color = NA) +
# 2. 伞
geom_boxplot(width = 0.1, position = position_nudge(x = 0.2), outlier.shape = NA, fill = "white") +
# 3. 雨
geom_jitter(aes(color = Species), width = 0.15, size = 1.5, alpha = 0.6) +
# 4. 美化:翻转
coord_flip() +
# 5. 美化:配色
scale_fill_jco() +
scale_color_jco() +
# 6. 美化:主题
theme_classic() +
theme(legend.position = "top") +
# 7. 统计:添加P值
stat_compare_means(comparisons = my_comparisons, label = "p.signif", method = "t.test") +
# 8. 标签:修改坐标轴名字
labs(y = "Sepal Length (cm)", x = "Iris Species")现在,运行这段代码,你将得到一张配色专业、布局合理、带有统计显著性标记的完美云雨图。它已经完全准备好被插入你的Word文档中了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)