第十二章 智能体性能评估
本文系统介绍了智能体评估体系,重点分析了三大核心评估场景:工具调用能力(BFCL基准)、通用AI助手能力(GAIA基准)和数据生成质量评估(AIME数学题生成)。BFCL采用AST匹配算法评估函数调用准确性,GAIA通过466个真实世界任务测试智能体综合能力,数据生成评估则结合LLM Judge、Win Rate和人工验证三种方法。评估体系采用模块化设计,支持多模态输入,既包含精确的技术指标(如准
我们需要回答以下问题:
智能体是否具备预期的能力?
在不同任务上的表现如何?
与其他智能体相比处于什么水平?
12.1.2 主流评估基准概览
(1)工具调用能力评估
工具调用是智能体的核心能力之一。智能体需要理解用户意图,选择合适的工具,并正确构造函数调用。相关的评估基准包括:
BFCL (Berkeley Function Calling Leaderboard)[1]:UC Berkeley 推出,包含 1120+测试样本,涵盖 simple、multiple、parallel、irrelevance 四个类别,使用 AST 匹配算法评估,数据集规模适中,社区活跃。
ToolBench[2]:清华大学推出,包含 16000+真实 API 调用场景,覆盖真实世界的复杂工具使用场景。
API-Bank[3]:Microsoft Research 推出,包含 53 个常用 API 工具,专注于评估智能体对 API 文档的理解和调用能力。
(2)通用能力评估
评估智能体在真实世界任务中的综合表现,包括多步推理、知识运用、多模态理解等能力:
GAIA (General AI Assistants)[4]:Meta AI 和 Hugging Face 联合推出,包含 466 个真实世界问题,分为 Level 1/2/3 三个难度级别,评估多步推理、工具使用、文件处理、网页浏览等能力,使用准精确匹配(Quasi Exact Match)算法,任务真实且综合性强。
AgentBench[5]:清华大学推出,包含 8 个不同领域的任务,全面评估智能体的通用能力。
WebArena[6]:CMU 推出,评估智能体在真实网页环境中的任务完成能力和网页交互能力。
(3)多智能体协作评估
评估多个智能体协同工作的能力:
ChatEval[7]:评估多智能体对话系统的质量。
SOTOPIA[8]:评估智能体在社交场景中的互动能力。
自定义协作场景:根据具体应用场景设计的评估任务。
(4)常用评估指标
不同基准使用不同的评估指标,常见的包括:
准确性指标:Accuracy(准确率)、Exact Match(精确匹配)、F1 Score(F1 分数),用于衡量答案的正确性。
效率指标:Response Time(响应时间)、Token Usage(Token 使用量),用于衡量执行效率。
鲁棒性指标:Error Rate(错误率)、Failure Recovery(故障恢复),用于衡量容错能力。
协作指标:Communication Efficiency(通信效率)、Task Completion(任务完成度),用于衡量协作效果。
12.1.3 HelloAgents 评估体系设计
考虑到学习曲线和实用性,本章将重点介绍以下评估场景:
BFCL:评估工具调用能力
选择理由:数据集规模适中,评估指标清晰,社区活跃
适用场景:评估智能体的函数调用准确性
GAIA:评估通用 AI 助手能力
选择理由:任务真实,难度分级,综合性强
适用场景:评估智能体的综合问题解决能力
数据生成质量评估:评估 LLM 生成数据质量
选择理由:通过这个案例可以完整体验如何使用 Agent 创造数据,评估数据的完整演示。
适用场景:评估生成的训练数据、测试数据的质量
评估方法:LLM Judge、Win Rate、人工验证
通过这三个评估场景,我们将构建一个完整的评估体系,如图 12.1 展示了我们的评估系统构建思路。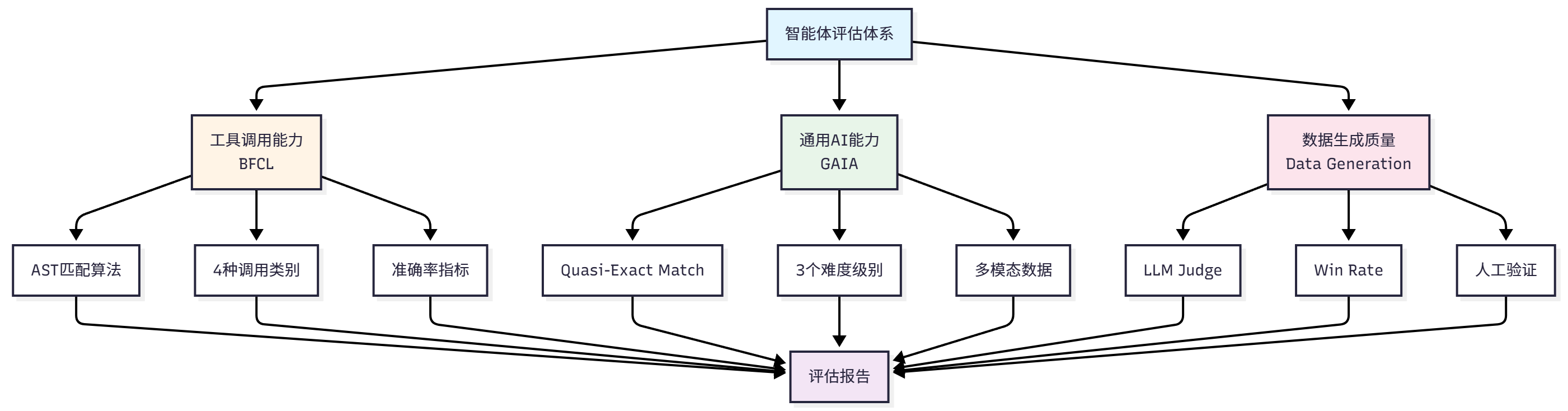
12.2 BFCL:工具调用能力评估
12.2.1 BFCL 基准介绍
BFCL (Berkeley Function Calling Leaderboard) 是由加州大学伯克利分校推出的函数调用能力评估基准[1]。在智能体系统中,工具调用(Tool Calling)是核心能力之一。智能体需要完成以下任务:
理解任务需求:从用户的自然语言描述中提取关键信息
选择合适工具:从可用工具集中选择最适合的工具
构造函数调用:正确填写函数名和参数
处理复杂场景:支持多函数调用、并行调用等高级场景

(2)AST 匹配说明
BFCL 使用AST 匹配(Abstract Syntax Tree Matching)作为核心评估算法,因此下文可以了解一下评估的策略。
BFCL 使用抽象语法树(AST)进行智能匹配,而不是简单的字符串匹配。AST 匹配的核心思想是:将函数调用解析为语法树,然后比较树的结构和节点值。
给定预测的函数调用 P和标准答案 ,AST 匹配函数定义为: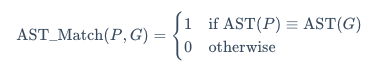

(3)GAIA 评估指标
GAIA 使用以下指标评估智能体性能:
- 精确匹配率 (Exact Match Rate)
精确匹配率是 GAIA 的核心指标,定义为准精确匹配成功的样本比例:


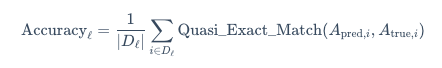




GAIA 的评估使用准精确匹配(Quasi Exact Match)算法,需要特殊的答案归一化和匹配逻辑:
12.4 数据生成质量评估
在 AI 系统开发中,高质量的训练数据是系统性能的基础。本节介绍如何使用 HelloAgents 框架评估生成数据的质量,以 AIME(美国数学邀请赛)[9]风格的数学题目生成为例。
AIME 是美国数学协会(MAA)主办的中等难度数学竞赛,介于 AMC 10/12 和美国数学奥林匹克(USAMO)之间。AIME 题目具有鲜明的特点:每道题的答案都是 0 到 999 之间的整数,题目涵盖代数、几何、数论、组合、概率等多个数学领域,需要多步推理但不涉及高深理论,难度适中(相当于 AIME 第 6-9 题的水平)。这些特点使得 AIME 题目成为评估数学题目生成质量的理想基准:答案格式统一便于自动化评估,题目难度适中适合大规模生成。我们使用 HuggingFace 上的TianHongZXY/aime-1983-2025数据集作为参考,该数据集包含从 1983 年到 2025 年的 900 多道 AIME 真题,为我们的生成和评估提供了丰富的参考样本。
12.4.1 评估方法概述
在数据生成质量评估中,我们采用三种互补的评估方法:LLM Judge、Win Rate 和人工打分。选择这三种方法有两个重要原因。首先,从方法论角度来看,这些是当前智能体领域常用的自动化测评方案,也是许多学术论文中的主流做法,具有广泛的认可度和实践基础。其次,从适用性角度来看,这三种方法天然适合我们的评估场景:LLM Judge 和 Win Rate 用于评估题目生成质量(从正确性、清晰度、难度匹配等维度进行多维度评估),而人工打分用于评估答案生成质量(通过人类专家验证答案的准确性),这种分工非常合理且易于理解。
(1)LLM Judge 评估
设计动机:在数据生成质量评估中,我们需要对大量生成的题目进行快速、一致的质量评估。传统的人工评估虽然准确,但成本高、效率低,难以应对大规模数据生成的需求。LLM Judge 通过使用大语言模型作为评委,可以自动化地从多个维度评估生成数据的质量,不仅大幅提升评估效率,还能保持评估标准的一致性。更重要的是,LLM Judge 可以提供详细的评分理由和改进建议,帮助我们理解生成数据的优缺点,为后续优化提供方向。
12.5 本章小结
在本章中,我们为 HelloAgents 框架构建了一个完整的性能评估系统。让我们回顾一下学到的核心内容:
(1)评估体系概览
我们建立了一个三层评估体系,全面覆盖智能体的不同能力维度。首先是工具调用能力评估(BFCL),专注于评估智能体的函数调用准确性,包含 simple、multiple、parallel、irrelevance 四个类别,使用 AST 匹配技术进行精确评估。其次是通用能力评估(GAIA),评估智能体的综合问题解决能力,包含三个难度级别共 466 个真实世界问题,关注多步推理、工具使用、文件处理等能力。第三是数据生成质量评估(AIME),评估 LLM 生成数据的质量,使用 LLM Judge 和 Win Rate 两种方法,支持人工验证和综合报告生成,确保生成数据达到参考数据的质量标准。
(2)核心技术要点
在技术实现上,我们采用了六个核心技术要点。首先是模块化设计,评估系统采用三层架构:数据层(Dataset 负责数据加载和管理)、评估层(Evaluator 负责执行评估流程)和指标层(Metrics 负责计算各种评估指标)。其次是工具化封装,所有评估功能都封装成 Tool,可以被智能体直接调用、集成到工作流中或通过统一接口使用。第三是 AST 匹配技术,使用抽象语法树匹配函数调用,比简单字符串匹配更智能,能够忽略参数顺序、识别等价表达式和忽略格式差异。第四是多模态支持,GAIA 评估支持文本问题、附件文件和图片输入等多模态数据。第五是 LLM Judge 评估,使用 LLM 作为评委评估生成数据质量,提供多维度评分(正确性、清晰度、难度匹配、完整性)、自动化评估流程、详细评估报告,并支持自定义评估维度和标准。第六是 Win Rate 对比评估,通过成对对比评估生成质量(生成数据 vs 参考数据),由 LLM 判断哪个更好并计算胜率统计,接近 50%表示质量相当。
(3)扩展方向
基于本章的评估系统,你可以在四个方向上进行扩展。首先是添加新的评估基准,可以参考 BFCL 和 GAIA 的实现模式,实现 Dataset、Evaluator、Metrics 三个组件,并封装成 Tool 供使用。其次是自定义评估指标,在 Metrics 类中添加新的指标计算方法,根据具体应用场景设计指标。第三是集成到 CI/CD 流程,在代码提交时自动运行评估,设置性能阈值防止性能退化,生成评估报告并归档。第四是扩展数据生成评估,支持更多数据类型(代码、对话、文档等),添加更多评估维度(创新性、多样性等),集成更多参考数据集,支持多模型对比评估。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)