拆解 LazyLLM:10 个你可能忽略的工程黑科技
如果你一路看到这里,说明你大概率已经在真实工程里和大模型打过交道了。后续文章里,我们会继续拆解更底层的东西:为什么要这样设计、当时有哪些取舍、哪些地方其实还在不断演进。如果你对这些工程细节感兴趣,欢迎持续关注。Lazy 的黑科技,等你来一起揭秘~欢迎升级体验 LazyLLM最新版本,请大家去github上点一个免费的star,支持一下~
当大模型真正进入工程系统后,麻烦往往不是一点点。模块越来越多,却越来越难管;配置在不同环境里反复出问题;流程一复杂就不敢动;换个平台几乎等于重来;性能问题总是卡在最不想碰的地方。
这些问题并不新,也不神秘。但它们很难被一次性解决,几乎每个做过 LLM 工程的人都会反复遇到。LazyLLM 正是围绕这些高频、刚性的工程痛点,在真实项目中沉淀了一组“黑科技”。它们不是绕开问题,而是把问题直接收进框架里处理,让工程可以继续往前走。
本文是这个系列的第一篇,我们从工程实践中最常见的10 个问题出发,对应介绍 LazyLLM 中的 10 个工程黑科技,介绍它们分别解决了什么,以及在实际项目中应该怎么用。
如果你已经在这些地方踩过坑,接下来的内容可以帮你卸下一部分工程负担;如果你刚开始做 LLM 工程,希望它能让你少走一些弯路。
目录
-
模块扩展与注册问题
-
中英双语 API 文档问题
-
运行时依赖加载问题
-
配置体系与命名空间问题
-
同一接口的作用域区分
-
数据流与参数绑定问题
-
跨平台部署问题
-
全局与局部上下文管理
-
模型类型自动推断
-
框架层性能瓶颈问题
一、模块扩展与注册问题
(一)问题:模块越多,注册越乱
在 LLM 工程里,模块扩展不是偶发事件,而是日常状态。今天加一个新模型,明天多一种能力类型,后天又冒出一种新的调用方式——系统只会越来越大。
但问题在于:模块不是“写完就能用”。它必须被框架稳定发现、统一管理、正确调用。一旦模块数量上来,注册问题几乎是所有系统都会踩的坑。
通常会同时出现两种混乱:
-
框架内部的混乱:component、module、tool 等能力各自演进,历史包袱一层层叠加,结果往往是——每一类模块都有自己的一套注册方式。短期看还能跑,长期看注册规则分散、语义不一致,维护成本直线上升。
-
对外扩展的尴尬:用户写的外部模块,往往只能当成“独立工具”存在。框架并不真正认识它,更谈不上把它纳入调度、缓存、评测、配置这些体系里。用是能用,但永远是“体系外成员”。
如果系统里每新增一个模块,都要:
-
手写一段注册代码
-
改一个集中注册表
-
甚至改动框架内部逻辑来“接住”它
那模块一多,注册机制几乎一定会失控。其实这两类问题,本质是同一个:模块没有被真正纳入框架体系,扩展能力无法自然生长。
(二)难点:统一且可扩展
注册机制要解决的,不只是“新模块怎么进来”,而是进来之后,老代码还能完全不动。
新模块必须接得快,但注册规则的变化,不能反过来影响已经存在的模块和流程。否则规模一上来,注册逻辑很快就会被条件判断淹没。一旦注册和业务实现发生耦合,后续的重构和扩展,成本都会被成倍放大。
(三)解决方法:统一模块入口的工程级架构设计
LazyLLM 对模块接入方式做了一次统一收敛。不管模块是类还是函数,接入路径完全一致,上层调用始终面对稳定、统一的模块入口。
在此之上,LazyLLM 提供了两种对称的接入机制:继承即注册,以及 注册即继承。
A. 继承即注册(类模块)
在 LazyLLM 中,类模块通过继承关系完成接入。只要继承正确的基类,模块在定义阶段就会自动进入系统,并出现在对应的命名空间中。
定义完成后即可直接使用。不需要额外注册,也不需要改动任何框架代码。
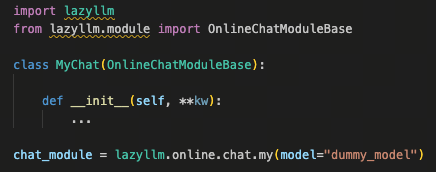
下图展示了LazyLLM的OnlineModule的复杂继承关系,但使用者并不需要理解全部结构——只要继承对了,就会自动注册到对应分组。
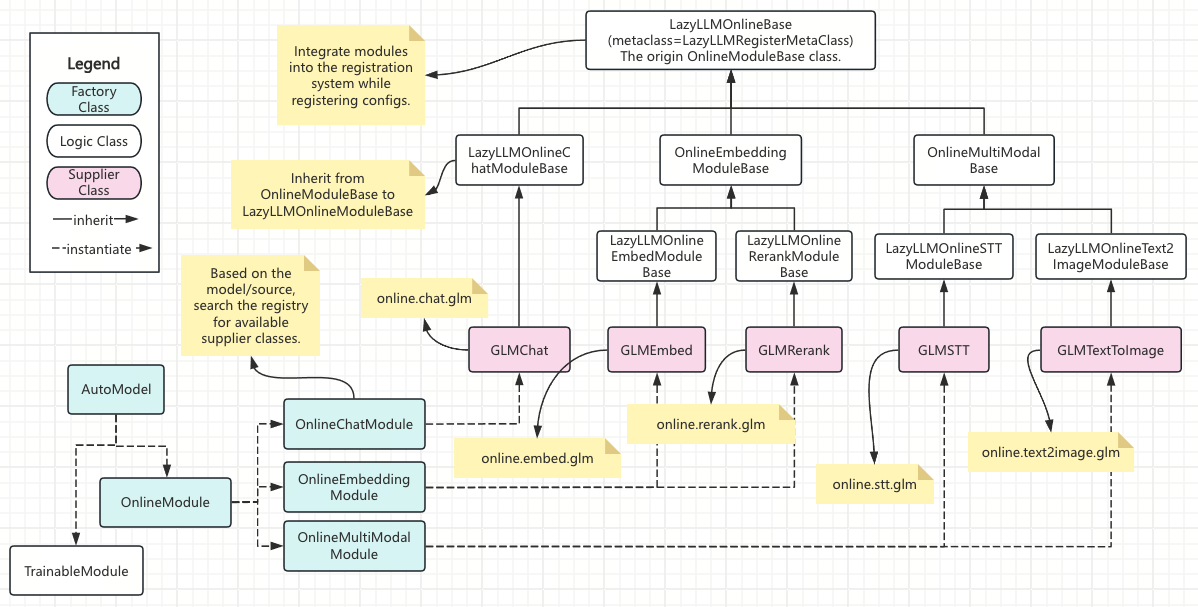
B. 注册即继承(函数模块)
函数在完成注册后,会被自动包装为类,并继承对应的模块基类。
例如,通过 component_register 注册的函数,会自动具备 launcher 的跨节点调度能力;通过 module_register 注册的函数,则会获得 ModuleBase 提供的通用模块能力。
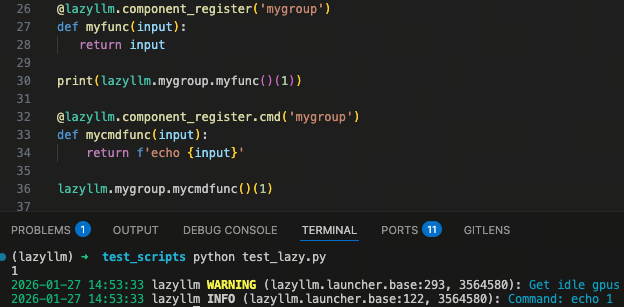
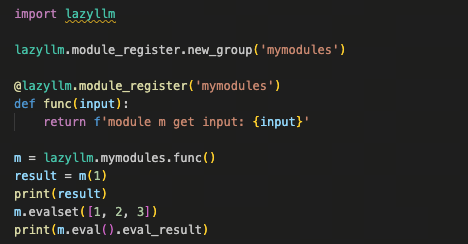
注册完成后,模块才算被框架正式“接纳”。并且,不同的注册类型,会自动对应一整套系统能力:
-
注册为 component
函数不再只是本地可调用的逻辑,而是一个可调度的计算单元。component 会继承 launcher 相关能力,可以直接参与跨节点、跨平台的调度与执行,而不需要在业务代码中处理运行位置和资源分配。
-
注册为 module
函数会被当作标准模块构造和调用,自动支持缓存、评测集、以及通过 config 进行参数透传,适配多进程和跨进程场景。
也就是说,注册不仅是“让框架认得你”,更关键的是,根据注册类型,框架会自动赋予你对应的一整套系统能力,而无需额外封装或适配。
二、中英双语 API 文档问题
(一)问题:API 文档只有英文
在大多数开源框架里,API 文档默认只提供英文版本。中文用户要么依赖翻译工具,要么翻博客、查零散笔记,理解成本高,专有名词还经常被翻错。
更麻烦的是,一旦接口发生变化,这些非官方中文说明很快就会落后。文档和代码不一致,用起来反而更容易踩坑。
(二)难点:双语不能写在代码里
真正的难点不在于“要不要中文文档”,而在于双语 API 文档几乎没法直接写在代码里维护。
在实际工程中,如果同时把中英文 docstring 同时写进注释,生成的文档会中英混杂,语言也无法自由切换。同时 docstring 本身很长,双语并行会让代码逻辑被大量说明文字淹没,影响代码维护与评审。因此,你很难同时做到:
-
在代码中同时维护中英文 docstring
-
保持代码整洁、逻辑清晰
-
保证两种语言结构完全一致
-
接口更新时不漏、不乱、不走偏
结果通常只能选一个“主语言”,另一种语言要么机翻,要么失真。如果双语文档不能在同一套维护体系内演进,它迟早会退化成摆设。
(三)解决方法:原生双语,统一管理
LazyLLM 从一开始,就把中英双语 API 文档当成框架的基础能力来设计,而不是事后补丁。在 LazyLLM 中:
-
文档不写在代码里:源码中不堆叠文档级注释,保持实现本身简洁可维护
-
中英文文档统一在 docs 中手写维护:两种语言都由程序员亲自编写和校对,保证语义准确、表达自然
-
同一接口,只维护一套结构:中英文只在语言层面不同,结构、语义始终一致
在文档生成阶段,LazyLLM 会在程序执行时,根据环境变量选择注入中文或英文说明。在发布制品前,再通过 AST 将对应语言的文档结构写入代码对象,确保最终发布的包在 IDE 中也能正确读取。
最终呈现给用户的,是原生、可维护、与代码同步演进的中英双语 API 文档,而不是事后翻译的副本。
下面展示的是同一个 API 在英文与中文文档中的实际效果,结构完全一致,仅语言不同:
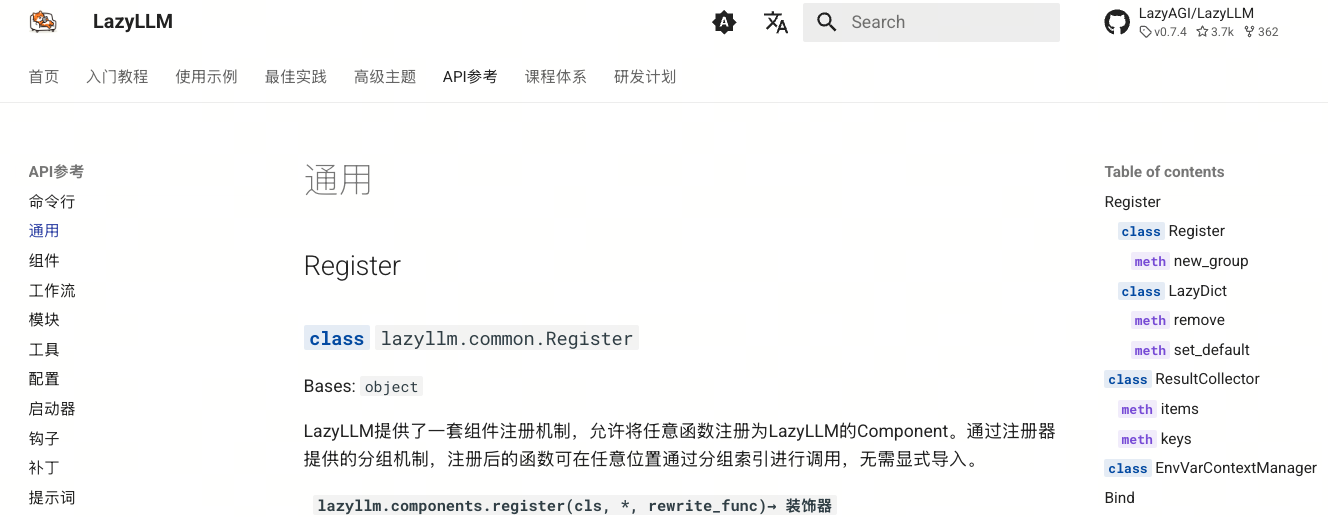
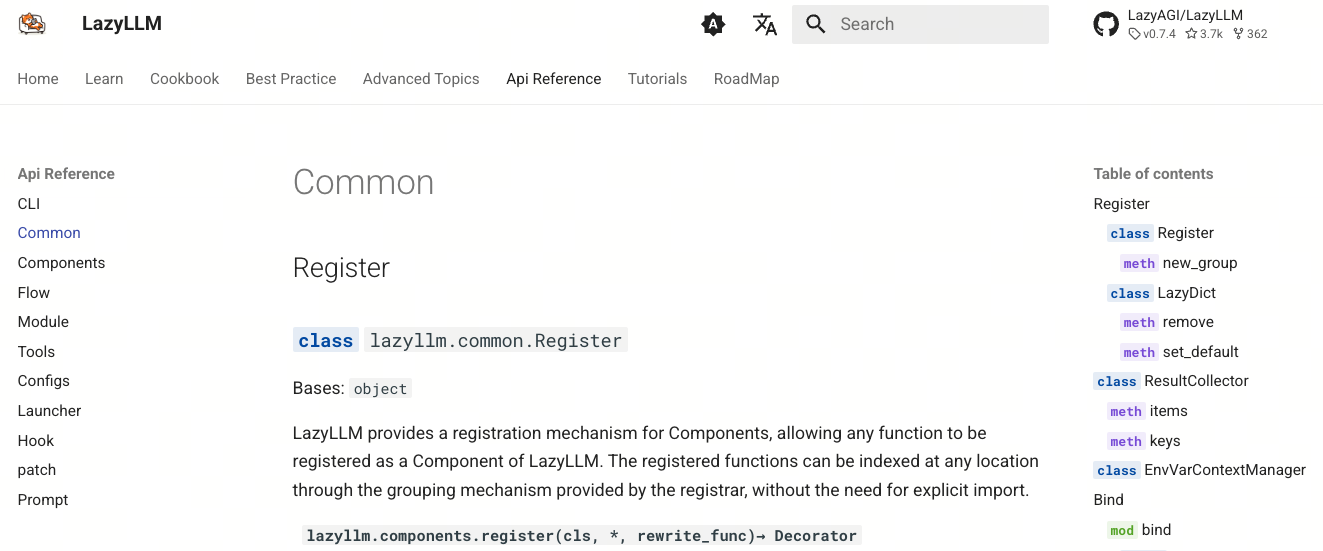
三、运行时依赖加载问题
(一)问题:依赖一多,环境先崩
如果你用过稍微复杂点的 Python 项目,这个场景一定不陌生:代码还没跑起来,环境先炸了。
不同模块依赖的库不一样,一股脑全装,环境立刻变臃肿;不全装,又总是在运行到一半时突然报错。更糟的是,就算框架自己依赖都理顺了,也常常和你本地环境对不上。
这不是你操作有问题,而是 Python 包管理的日常。
(二)难点:提前暴露,清楚报错
依赖管理最头疼的,其实不是 import 写在哪。而是:什么时候告诉你少了依赖,以及怎么告诉你。
理想状态应该是这样:
-
没用到的功能,不强制装一堆包
-
import 统一写在文件顶部,而不是藏进函数里
-
如果缺依赖,最好在任务刚开始、甚至远端执行之前就告诉你
-
一次说清楚:缺什么、装哪个、要什么版本,避免装一个、再报下一个反复折腾
(三)解决方法:按需加载,集中检查
LazyLLM 的做法很直接:不用的功能,不提前装;你一用,立刻统一检查。
下图以 rag 为例,当你第一次调用相关能力时,LazyLLM 会马上:
-
把所有需要的依赖一次性检查完
-
清楚告诉你缺哪些包
-
直接引导你执行:lazyllm install rag
这个安装命令里,连版本号都已经帮你处理好了。你不需要查文档,也不用猜哪个版本能配得上。最终体验只有一句话:不用的不装,用到的一次装全,装完就能跑。

四、配置体系与命名空间问题
(一)问题:配置来源复杂
框架一复杂,配置就开始失控:前端一份,后端一份,算法一套,数据库再来一组。每个模块都悄悄加自己的配置参数,最后没人能说清:现在到底有哪些配置?
如果没有统一的配置体系,常见的结果只有几种:
-
配置散落在各个模块里,很难列出完整清单
-
调用方为了拿一个默认值,被迫直接 import 上层模块
-
不同环境下到底哪个配置生效,只能靠经验和运气
(二)难点:集中管理,但避免依赖逆置
配置管理真正难的有两点:
一方面,配置必须统一:
-
所有配置项,都要被框架整体感知
-
支持代码覆写 → 环境变量 → 配置文件的清晰优先级
另一方面,配置又不能全挤在一起:
也就是说:配置要统一管理,但配置项必须分散注册。
(三)解决方法:统一配置 + 分散注册
LazyLLM 的做法是,把“管理”和“定义”这两件事彻底拆开。
-
先注册配置项:各个模块在各自位置声明自己的配置名、类型、默认值,以及可选的环境变量映射
-
统一读取配置:所有已注册的配置,统一进入 lazyllm.config,调用方只管 lazyllm.config[“xxx”],不关心配置来自哪
-
覆盖规则清晰:配置优先级从高到低:运行期代码覆写 → 环境变量 → 配置文件
-
修改自动刷新:修改环境变量后,配置会自动刷新,无需重启进程
-
支持临时修改:调试或实验时,用 temp() 临时覆写,作用域结束,配置自动恢复,不污染全局状态
-
自动生成文档:lazyllm 会为当前框架内置的所有 config 自动生成文档,介绍配置名及其描述
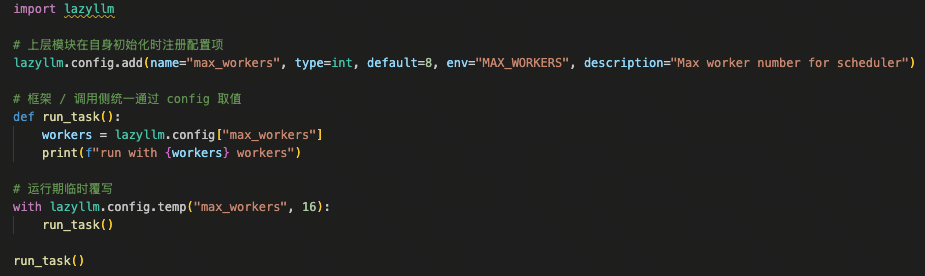
下图展示了注册式配置的效果:
上层结构通过 lazyllm.config.add 定义了配置参数后,调用方不需要再通过 import 去找默认值,而是直接通过 lazyllm.config[“max_workers”] 访问。需要临时改?直接覆写,用完自动恢复,不会污染全局配置。
五、同一接口的作用域区分
(一)问题:同一操作,不同语境
在复杂框架中,同一个操作,往往既可能用于系统级配置或结构变更,也可能只针对某个具体实例生效。换句话说,从设计之初,它就天然存在两种作用范围:
-
类级调用:作用于全局上下文
-
实例调用:只作用于当前对象
之所以一定要把这两种情况分清楚,是因为它们在生命周期、影响边界,以及能不能回滚上,完全不是一回事。全局操作一旦执行,影响面很广,恢复成本也高;而局部操作,本来就应该被严格限制在当前对象内部,不能“溢出”。
如果不加区分,问题就会悄悄出现:本来只是局部的改动,可能被意外放大成全局修改;全局状态,也可能在不经意间被破坏,最后让系统行为变得难以预测。
但如果为了安全起见,干脆把这两种行为拆成两套接口,新的麻烦又马上来了——API 越来越多,名字越来越难记,使用者在调用时也更容易选错作用范围。
(二)难点:统一接口,语义不混
真正的难点在于:只暴露一个方法名,却要让类调用和实例调用在行为上严格区分。
这件事用普通实例方法、@classmethod,或者靠参数约定都很难自然解决。要么接口分裂,要么调用语义变得不直观、调用形式不统一。
(三)解决方法:基于调用上下文的动态绑定
LazyLLM 通过 DynamicDescriptor,为方法引入了“调用者感知”能力。
同一个方法名,在不同访问方式下,会自动绑定到不同的执行对象:
-
从类访问时,方法接收类本身,执行全局逻辑
-
从实例访问时,方法接收实例对象,转发到实例内部实现
这一机制使得:
-
类级与实例级操作共享同一个接口
-
调用方式保持直觉一致
-
内部实现路径自动分流,无需额外参数或命名区分
一句话总结:DynamicDescriptor 让 LazyLLM 在不增加 API 数量的前提下,自然表达了同一操作在不同作用域下的不同语义。
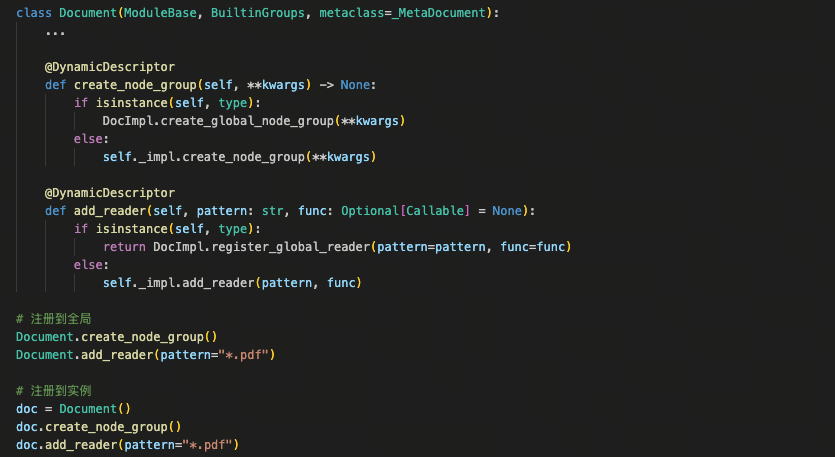
下图展示的是 Document 类的真实代码:create_node_group 和 add_reader 都使用了 @DynamicDescriptor 装饰。调用 Document.create_node_group() 时,node group 会注册到 Document 的全局注册表中,对所有实例可见;而调用 doc.create_node_group() 时,则只会注册到当前 doc 实例内部,不与其他实例共享。同一个方法名,调用方式不变,作用范围由调用上下文自动区分。
六、数据流与参数绑定问题
(一)背景:为什么需要数据流
当系统从单机脚本走向工程化部署,流程本身就不再只是“算完返回结果”这么简单。一旦涉及多服务、多节点或多进程执行,你必须提前知道:
-
这个流程里,到底有哪些计算节点和服务
-
数据是怎么在这些节点之间流动的,谁依赖谁
-
tracing、hook、状态监控,到底该插在哪
如果流程只是靠一串函数调用隐式串起来,这些信息几乎不可能一次性看清。系统层也根本“看不见”流程,只能被动执行。
数据流存在的意义就在这里:把流程从“能跑的代码”,提升为“系统能理解、能管理的结构”。
(二)问题:流程复杂但不可控
在多阶段推理、RAG 和 Agent 场景中,引入流程已经是刚需。但业界主流框架(如 langchain、llamaindex)在工程实践中暴露出明显问题:
-
跨模块数据关系不直观:流程的整体拓扑被拆散在多个对象和回调中,数据如何在各步骤之间流动只能靠顺着代码追,写代码和读代码时都很难一眼看清整体结构。
-
流程一复杂就难以维护:增加或调整一个步骤(比如增加 tracing),往往要改动多处逻辑,可读性和可维护性迅速下降。
(三)解决方法:数据流用flow,参数绑定用bind
LazyLLM 通过 flow 和 bind,将流程提升为系统可感知的执行对象,核心思路很简单:
-
复杂流程可读性高:LazyLLM 提供了一组可以灵活组合的 flow,用来构造串行、并行、嵌套的复杂工作流。结构写出来,就是流程本身,可读性不会随着复杂度上升而崩掉
-
参数可以跨模块传输:通过 bind 机制,参数可以实现跨模块传输,数据流动变得更加灵活可控
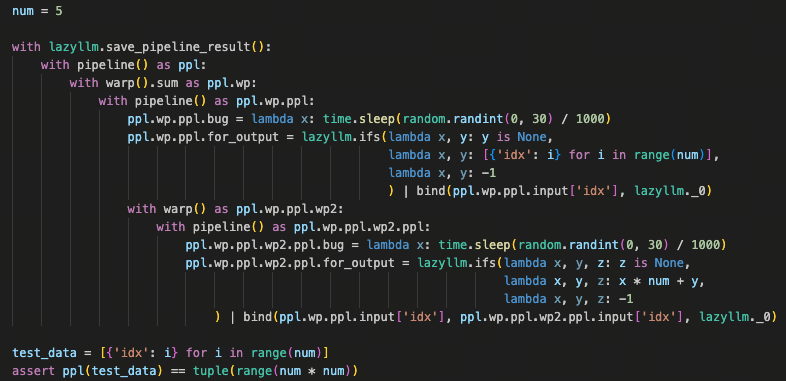
下图展示的是一个多层嵌套的数据流示例:
pipeline 和 warp 多层嵌套,但借助 with 语法,整体拓扑仍然清晰可见。在 warp 多线程并行执行的前提下,bind 可以跨越嵌套层级,把外层 pipeline 的输入准确绑定到内层 warp pipeline 中,同时保证线程之间的数据隔离与一致性。
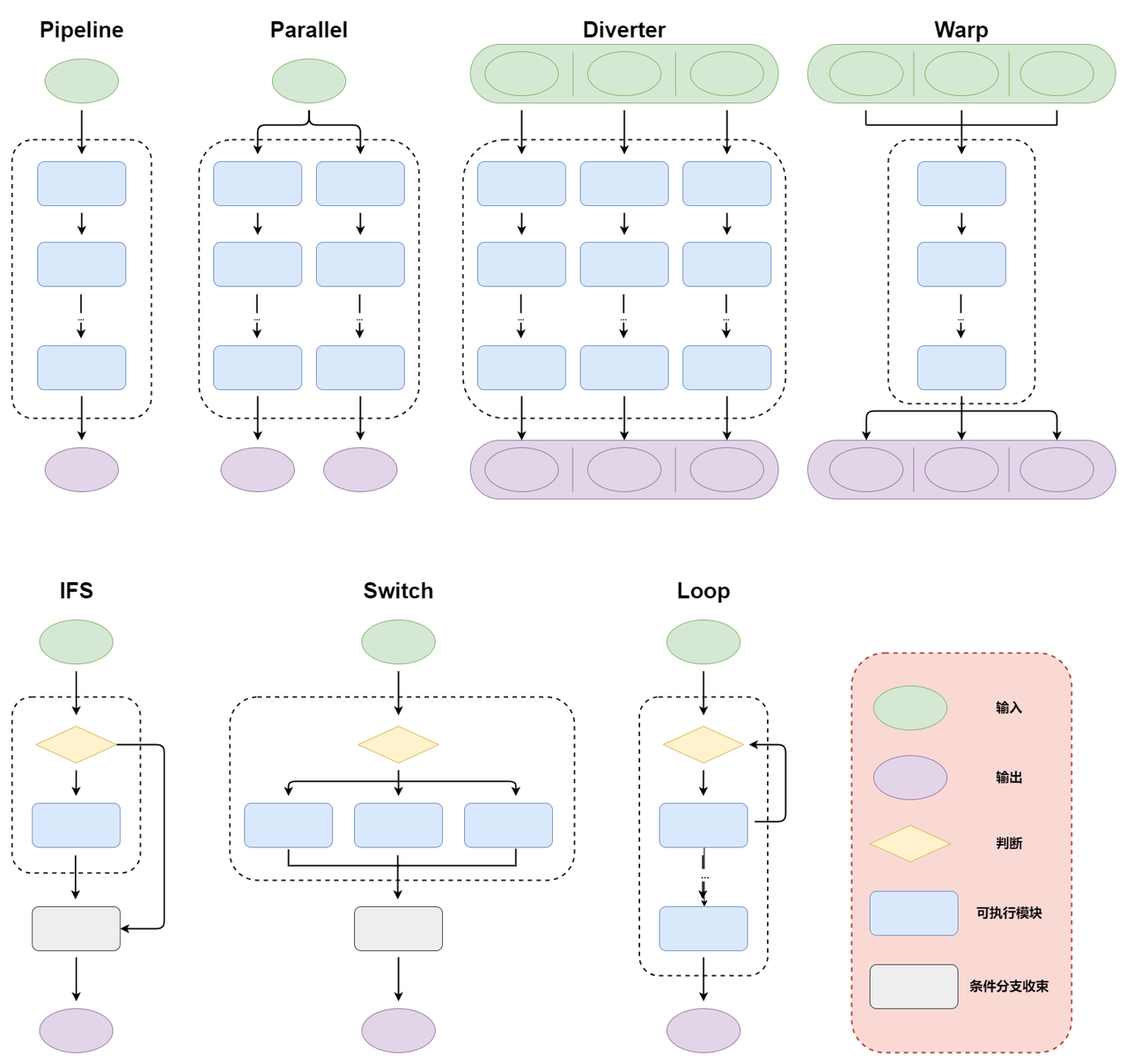
除了用 pipeline 处理线性序列之外,LazyLLM 还支持多种 flow:
-
parallel,用于管理并行流
-
diverter,流分流器,将输入通过不同的模块以并行方式路由
-
warp,流形变器,将单个模块并行应用于多个输入
-
ifs,实现If-Else功能,用于根据给定条件的评估有条件地执行两个提供的路径之一
-
switch,条件选择并执行流的控制流机制
-
loop,初始化一个循环流结构,该结构将一系列函数重复应用于输入,直到满足停止条件或达到指定的迭代次数
-
graph,一个基于有向无环图(DAG)的复杂流控制结构
上述数据流的结构示意图如下:
七、跨平台部署问题
(一)背景:算力平台高度异构
在真实工程环境里,算力平台几乎从来不是单一、稳定的。
公司内部,可能同时维护着多套集群;不同团队用着不同的调度系统;业务一调整,平台就升级、迁移,甚至整体更换。而一旦对外部署或交付给客户,运行环境的不确定性只会更高。不同平台之间,往往在这些地方差异明显:
-
作业提交方式不同
-
资源申请参数不一致
-
调度系统和作业生命周期,各有一套规则
(二)问题:部署逻辑侵入业务代码
当平台差异直接反映在代码层时,问题会迅速放大。常见情况是:
-
为不同平台各写一套启动脚本
-
业务代码里混进调度参数和平台判断
-
一换环境,就得整体重改部署逻辑
结果是:平台一变,业务跟着改;部署本身比功能还复杂。
(三)解决方法:用 Launcher 隔离运行平台差异
LazyLLM 在 lazyllm/launcher 中引入了独立的Launcher 体系,将运行平台差异从业务逻辑中彻底剥离。在 LazyLLM 中,职责分工非常清楚:
-
模型与流程只描述要执行的计算逻辑
-
Launcher 负责运行平台、资源调度和作业生命周期
这种设计带来三个直接效果:
-
已支持的平台,只需要通过配置选择对应的 launcher
-
新平台或小众平台,只需继承Launcher基类实现调度逻辑
-
不改框架主体,也不动业务代码
目前,LazyLLM 已内置多种 launcher,用于覆盖常见运行环境:本地执行、Kubernetes 集群、Slurm 调度集群以及云平台部署。这些 launcher 共享统一的作业生命周期抽象,上层模块始终用同一种方式被管理和调度。
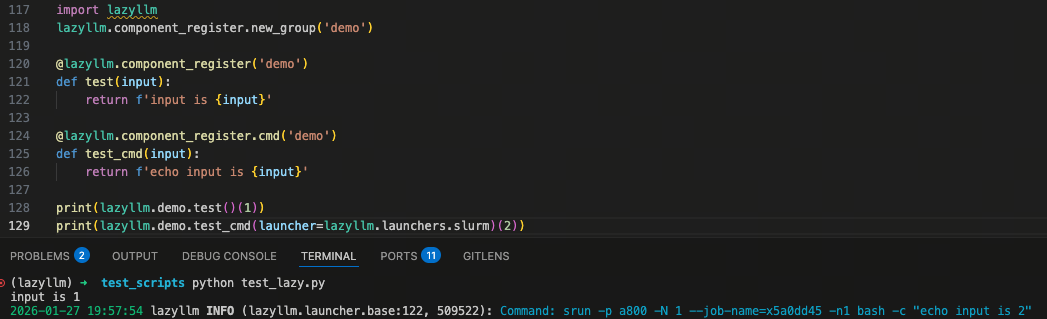
如图所示:同一个 component,既可以在本地直接运行,也可以通过指定 launcher 提交到 Slurm 集群执行。业务代码不变,运行位置由 launcher 动态决定。
八、全局与局部上下文管理
(一)背景:状态不只是配置
在真实系统里,“状态”远不只是启动时写死的配置项。
随着流程跑起来,系统会不断产生新的状态:用户临时设置、中间计算结果、会话上下文、甚至短期记忆。如果这些状态和配置混在一起管,很快就会出问题。生命周期不清、作用范围不明,既影响系统稳定性,也让排查问题变得异常痛苦。
(二)问题:全局状态与临时上下文难以区分
在复杂流程和多线程场景下,常见问题包括:
-
本该是临时的中间结果,被错误地长期保留
-
多线程同时读写状态,互相干扰,行为不可预测
一旦状态缺乏明确的作用域划分,系统规模越大,问题越难控制。
(三)解决方法:Globals / Locals 统一上下文体系
LazyLLM 在配置体系之上,引入了Globals / Locals两级上下文,用来把“该共享的”和“该隔离的”彻底分开。
-
Globals:会话级共享状态
用于存储同一个 session 内需要共享的信息。例如模型选择、全局参数、来自前端的配置等。
在同一 session 中,Globals 对所有线程和协程可见。根据使用场景,可以基于内存实现,也可以切换为 Redis 等持久化后端,保证更高的稳定性。
-
Locals:执行级临时上下文
用于保存单次执行路径中的临时状态。比如中间结果、临时配置或执行期记忆。这些状态只在当前线程或协程中生效,不会跨线程传播,也不会被持久化。
如图所示,每次请求都会通过 session id 建立独立的会话上下文。在同一个 session 内,Globals 提供稳定一致的共享状态;而 Locals 则确保不同执行路径互不干扰,使并发场景下的行为始终可预测。
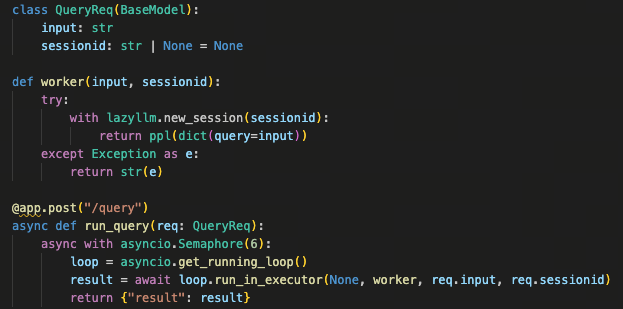
九、模型类型自动推断
(一)背景:模型入口不统一
在多模型工程里,最先让人头疼的,往往不是模型效果,而是入口不统一。
明明都是“用一个模型”,却要先想清楚:这是在线的还是本地的?是 chat、embedding、tts,还是多模态?不同能力,对应不同的类和参数。
更现实的是,同一个模型在不同阶段,常常要在在线和本地之间来回切换。模型没变,逻辑没变,但因为入口不同,却不得不改类名、调参数,甚至动业务代码。
(二)问题:调用逻辑被迫前置
当模型入口不统一,这些判断就会被迫写进调用代码里:
-
这是在线模型还是本地模型
-
在线模型属于哪个供应商,用哪套 API Key
-
当前模型是 chat、embedding、tts 还是其他能力
一旦这些分支进了业务代码,后果很直接:
-
调用接口变得冗长且脆弱
-
同一个模型换运行方式,就得改代码
-
模型或供应商一变,业务跟着动
结果是,模型越多,分支越多;入口层越复杂,系统整体越难维护。
(三)解决方法:两层自动推断,统一入口
LazyLLM 在模型入口层引入模型类型自动推断机制,并拆成两层,把这些判断全部收敛到框架内部。
对用户来说,只需要一件事:给出模型名称,其余交给框架。
整体结构如下:
AutoModel
├─ OnlineModule
└─ TrainableModule
AutoModel —— 运行路径判定
入口首先由 AutoModel 决定模型的运行路径,是在线调用,还是本地模型。判断不是靠临时 if-else,而是稳定、可预测的顺序:
-
配置中包含 framework、deploy_config,或显式指定 source=local → 本地模型
-
存在在线模型配置 → 在线模型
-
两类配置都不存在 → 先尝试在线,失败后回退至本地
调用侧只需要传模型名。如果你想明确指定来源,也可以补一个 source,但接口本身不变。

OnlineModule ——在线模型的供应商与能力判定
当被判定为在线模型后,OnlineModule 会进一步确定其供应商实现和能力类型。能力类型通过内部映射自动完成,例如:
-
embed / rerank / cross_modal_embed → 向量类模型
-
stt / tts / sd / image_editing → 多模态模型
-
其他模型 → 对话模型(默认)
示例如下:

TrainableModule —— 本地模型的类型推断
当模型走本地路径时,LazyLLM 会自动推断模型的类别与目录结构,用于后续的下载、缓存、加载、训练或部署。模型类型推断遵循分级规则:
-
精确匹配:针对已知模型名称的固定映射
-
关键词匹配:根据模型名中包含的关键特征进行判断
-
正则匹配:覆盖更宽泛的模型命名模式
-
最终兜底:未命中时默认归为通用模型类型
通过这一整套自动推断机制,LazyLLM 把“模型名称”变成唯一入口,而把运行方式、能力类型和模型类别的判断全部收敛到框架内部。
对调用方来说,不管模型来自哪里、以什么形式存在,用法始终一致,切换成本几乎为零。
十、框架层性能瓶颈问题
(一)背景:Python 的系统性性能上限
在以 Python 为主的工程体系里,性能上限其实是写在语言里的:
-
解释执行,速度很难贴近原生指令
-
存在 GIL 机制,多线程并行执行 Python 字节码天然受限
-
动态类型和 GC,对象检查和内存管理都有额外成本
这些问题在小脚本里不明显,但一旦进入高频、规模化、长链路的工程场景,就会被不断放大,变成系统的客观上限。
(二)问题:性能瓶颈转移到框架层
在大模型工程里,一个很常见的变化是:系统复杂度上来之后,性能瓶颈会逐渐从模型推理转移到框架层。
瓶颈往往集中在这些地方:
-
大量结构化数据与中间对象的构建与遍历
-
节点、状态和上下文的高频创建与销毁
-
本地并行计算、批处理与调度逻辑
这些操作会出现得非常频繁,一旦规模上来,Python 的解释执行、GIL 限制和对象管理开销就会被无限放大。这时候再去“微调某个函数”,效果其实很有限。因此,真正的问题在于:这些核心路径本身,就不适合长期放在 Python 层来承载。
也就是说,瓶颈不在模型,而在于框架有没有能力把该下沉的东西,下沉到更合适的层级。
(三)解决方法:框架级 C++扩展
LazyLLM 在设计之初,就把 C++ 扩展作为框架能力的一部分,而不是等性能问题暴露后再打补丁。在 LazyLLM 中,高性能逻辑通过统一的 C++ 扩展机制实现,以 lazyllm.cpp 模块的形式随框架一起构建、安装和使用。内部的职责划分非常清晰:
-
C++ 核心层:用于处理计算密集、调用频繁、并行需求明显的通用逻辑
-
绑定层(pybind11):负责接口暴露、类型转换和异常传递
-
Python 层:负责模块组织、流程控制和对外接口
这种设计保证了 C++ 实现能够自然地融入框架结构中,而不是形成一套独立的接口或调用方式。
当某些通用路径逐渐成为性能瓶颈时,LazyLLM 可以在不改变 Python 接口的前提下,把具体实现平滑迁移到 C++ 层。对使用者来说,用法不变;对框架来说,性能优化可以持续推进,而不会破坏整体结构。
通过这种方式,LazyLLM 把 C++ 扩展纳入统一管理,使框架在更大规模、更高并发的场景下,依然具备稳定的性能表现和足够的演进空间。
写在最后
如果你一路看到这里,说明你大概率已经在真实工程里和大模型打过交道了。后续文章里,我们会继续拆解更底层的东西:为什么要这样设计、当时有哪些取舍、哪些地方其实还在不断演进。
如果你对这些工程细节感兴趣,欢迎持续关注。Lazy 的黑科技,等你来一起揭秘~
欢迎升级体验 LazyLLM最新版本,请大家去github上点一个免费的star,支持一下~
LazyLLM项目仓库链接🔗:
更多技术内容,欢迎移步 “LazyLLM” 讨论!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)