Flink 内存与资源调优从 Process Memory 到 Fine-Grained Resource Management
本文系统梳理了 Apache Flink 的内存管理机制,重点解析了 1.10+ 版本引入的三层内存模型(进程总内存/Flink内存/JVM开销)。针对不同部署场景(Standalone/K8s/YARN)提供了三种配置路径,详细拆解了 TaskManager 的四大核心内存组件及其调优策略。特别分析了常见 OOM 问题的诊断思路,包括堆内存、元空间、直接内存等不同场景的解决方案。最后介绍了细粒度
1. Flink 的“进程内存账本”到底在算什么
从 Flink 1.10(TaskManager)/1.11(JobManager)开始,Flink 把 JVM 进程的内存拆得更清楚:
- Total Process Memory(进程总内存):你给这个 JVM 进程的“总预算”
- Total Flink Memory(Flink 总内存):Flink 自己可支配的预算(Heap + Off-heap/Native 等)
- 剩下还有 JVM 自己运行需要的开销:Metaspace、JVM Overhead(线程栈、code cache、GC 预留等)
最重要的一句:
本地执行(IDE 跑)是特例;集群/容器部署必须显式配置一套“关键选项子集”,否则启动会失败。
2. 3 种配置思路:选一个就好,别混搭
Flink 给了三条路(除本地执行外至少选一条):
路线 A:只配 Total Flink Memory(更适合 Standalone)
- TaskManager:
taskmanager.memory.flink.size - JobManager:
jobmanager.memory.flink.size
适合你想明确:“Flink 自己能用多少”,至于 JVM overhead 这些不强控(物理机资源为主)。
路线 B:只配 Total Process Memory(更适合容器 Kubernetes/YARN)
- TaskManager:
taskmanager.memory.process.size - JobManager:
jobmanager.memory.process.size
这条路的意义很直接:它基本等价于容器的 memory request/limit 预算。容器环境强烈推荐这么配。
路线 C:直接配关键组件(更细,但更容易冲突)
典型是 TaskManager 显式配:
taskmanager.memory.task.heap.sizetaskmanager.memory.managed.size
然后让其它组件用默认/推导。
注意
不建议同时显式配置 Total Process Memory + Total Flink Memory,很容易配置冲突,导致启动失败(IllegalConfigurationException)。
3. Flink 会自动给 JVM 塞哪些参数(为什么你“明明没配 -Xmx”却变了)
Flink 启动进程时会根据你配置的内存组件,自动推导并设置:
-
-Xmx/-Xms- TaskManager:Framework Heap + Task Heap
- JobManager:JVM Heap
-
-XX:MaxDirectMemorySize- TaskManager:Framework Off-heap + Task Off-heap + Network Memory
- JobManager:默认不一定限制,只有开启
jobmanager.memory.enable-jvm-direct-memory-limit才会加
-
-XX:MaxMetaspaceSize- 对应你配置的 metaspace 选项
这解释了很多“我只调了 Flink 配置,为什么 OOM 报在 JVM 层”的现象。
4. 两类“按比例计算但有上下限”的组件:经常踩坑
Flink 里有些组件不是固定值,而是“比例 + min/max 夹住”的模式:
- JVM Overhead:可按 total process memory 的 fraction 算,但要落在 min/max 之间
- Network Memory(TaskManager 才有):可按 total flink memory 的 fraction 算,同样被 min/max 限制
例子(文档里的思路)
- total process = 1000MB
- overhead fraction = 0.1 → 算出来 100MB
- 如果 min/max 是 64~128MB,则 overhead=100MB 合法
但如果 min 是 128MB,就会被“抬高”到 128MB
结论
看到“配置了 fraction 但结果不是那个值”,先检查 min/max。
5. TaskManager 内存模型:你真正该盯的 4 块
TaskManager 是跑用户算子的地方,最常用、最影响稳定性的核心内存块,通常就这四个:
-
Task Heap(
taskmanager.memory.task.heap.size)
你要保证算子/用户代码有足够 JVM Heap,就盯它。 -
Managed Memory(
taskmanager.memory.managed.size或...managed.fraction)
Flink 管的 off-heap/native 内存,常用于:
- RocksDB state backend(流)
- 排序、哈希表、缓存(批/流)
- Python UDF 进程
并且可以用 taskmanager.memory.managed.consumer-weights 在不同消费者之间分账:STATE_BACKEND:70,PYTHON:30 这种。
-
Network Memory(
taskmanager.memory.network.{min,max,fraction})
网络 buffer,直接关系到 shuffle / 数据交换稳定性。 -
JVM Overhead / Metaspace
容器里最容易被忽略的“native 角落”,经常导致 container memory exceeded。
6. 按场景给“配置方向”,别盲调
6.1 Standalone(物理机/独立集群)
建议优先配 Total Flink Memory:taskmanager.memory.flink.size / jobmanager.memory.flink.size
必要时再调 metaspace。
6.2 容器 Kubernetes/YARN(强烈推荐)
建议优先配 Total Process Memory:taskmanager.memory.process.size / jobmanager.memory.process.size
重要提醒
如果 Flink 或用户代码分配了未被 Flink 计入的 native/off-heap,超过容器预算,会被平台 kill。
6.3 State Backend:HashMap vs RocksDB
- HashMapStateBackend / 基本无状态:managed memory 可设为 0,把预算更多留给 heap
- EmbeddedRocksDBStateBackend:必须给足 managed memory
如果你关掉 RocksDB 默认内存控制,还可能导致容器直接被杀。
6.4 批任务(Batch)
批算子更“吃 managed memory”,managed 足够时能减少反序列化和 JVM 对象开销;不够会优雅落盘(不会无限吃到 OOM)。
7. Troubleshooting:看到这些异常,第一反应应该改哪块
IllegalConfigurationException
大概率是:
- 负数/比例 > 1
- 同时配置了互相冲突的选项(比如 total process + total flink)
做法:沿着异常里提到的组件,回查对应选项。
OutOfMemoryError: Java heap space
Heap 不够:
- 增大 total memory
或直接增大: - TM:
taskmanager.memory.task.heap.size - JM:
jobmanager.memory.heap.size
OutOfMemoryError: Direct buffer memory
direct memory 上限太小或泄漏:
- 检查用户代码/依赖是否大量用 direct buffer
- 通过调 task off-heap / framework off-heap / network memory 间接影响
MaxDirectMemorySize
OutOfMemoryError: Metaspace
调大:
taskmanager.memory.jvm-metaspace.size或jobmanager.memory.jvm-metaspace.size
IOException: Insufficient number of network buffers
网络 buffer 不够:调大
taskmanager.memory.network.min/max/fraction
Container Memory Exceeded(容器被杀)
典型原因:native 没算进来或波动太大
-
JobManager:可考虑开启
jobmanager.memory.enable-jvm-direct-memory-limit排除 direct leak 可能 -
RocksDB:
- 若禁用内存控制:增大 managed memory
- 若 savepoint/full checkpoint 期间 non-heap 飙升:可尝试
MALLOC_ARENA_MAX=1 - 或增大 JVM Overhead(给 native 留更多余量)
8. Fine-Grained Resource Management:为什么你“slots 配得再漂亮”也可能浪费
传统的资源管理是“粗粒度”:
TaskManager 预先切成固定数量、规格一致的 slot,调参时你常常只能围绕 taskmanager.numberOfTaskSlots 做文章。
细粒度资源管理的核心变化是:
slot request 里带着明确的 resource profile(CPU、heap、off-heap、managed、GPU 等),Flink 会从 TaskManager 剩余资源里“切一块刚好匹配的 slot”。
这张图就是粗粒度 vs 细粒度的直观差异(建议放在这一节开头):
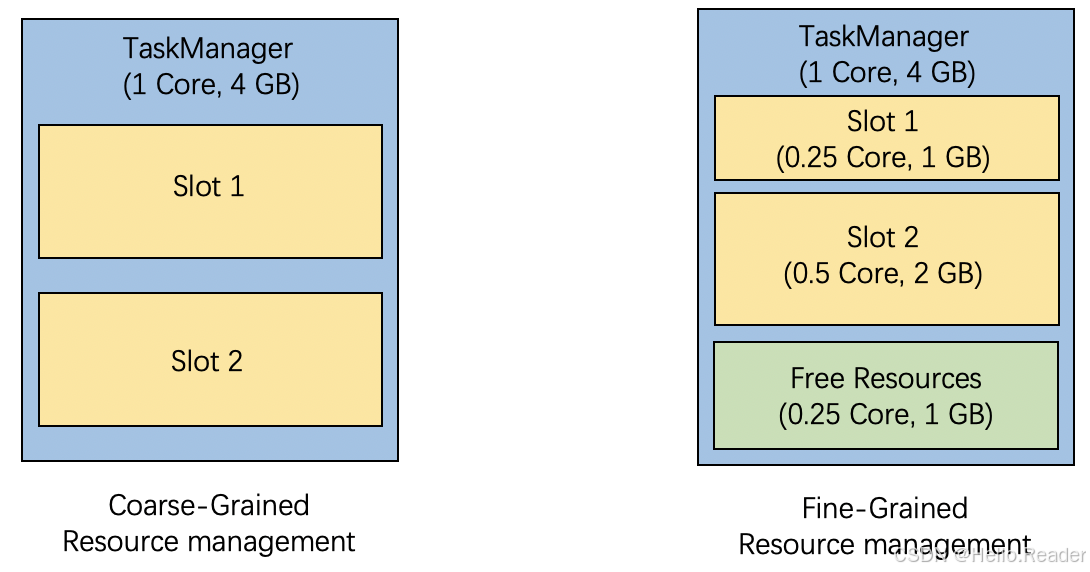
你会发现:细粒度模式下,slot 不再“生来一样”,剩余资源还能继续被切分利用。
9. 怎么用:用 SlotSharingGroup 给算子分“资源套餐”
细粒度资源需求定义在 SlotSharingGroup(SSG) 上:
- 先把算子归组(同组“可以”放同一 slot,不是强制)
- 再给这个组指定资源:CPU cores、Task Heap(必填且必须为正)、以及可选的 off-heap/managed/GPU 等
Java 示例(你贴的文档思路原样落地):
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SlotSharingGroup ssgA = SlotSharingGroup.newBuilder("a")
.setCpuCores(1.0)
.setTaskHeapMemoryMB(100)
.build();
SlotSharingGroup ssgB = SlotSharingGroup.newBuilder("b")
.setCpuCores(0.5)
.setTaskHeapMemoryMB(100)
.build();
someStream
.filter(...).slotSharingGroup("a")
.map(...).slotSharingGroup(ssgB);
env.registerSlotSharingGroup(ssgA);
也可以直接构造带完整资源的 SSG(含 GPU):
SlotSharingGroup ssgWithResource =
SlotSharingGroup.newBuilder("ssg")
.setCpuCores(1.0) // required
.setTaskHeapMemoryMB(100) // required
.setTaskOffHeapMemoryMB(50)
.setManagedMemory(MemorySize.ofMebiBytes(200))
.setExternalResource("gpu", 1.0)
.build();
注意
同名 SSG 只能绑定一套资源规格,有冲突会在 job 编译阶段失败。
10. 这张“切 slot 的过程图”,最适合放在“How it works”小节
当 slot request 依次到来,TaskManager 里的 free resources 会被不断切分;slot 释放后资源回收,再可用于后续分配。把这张图插在这里会非常顺:
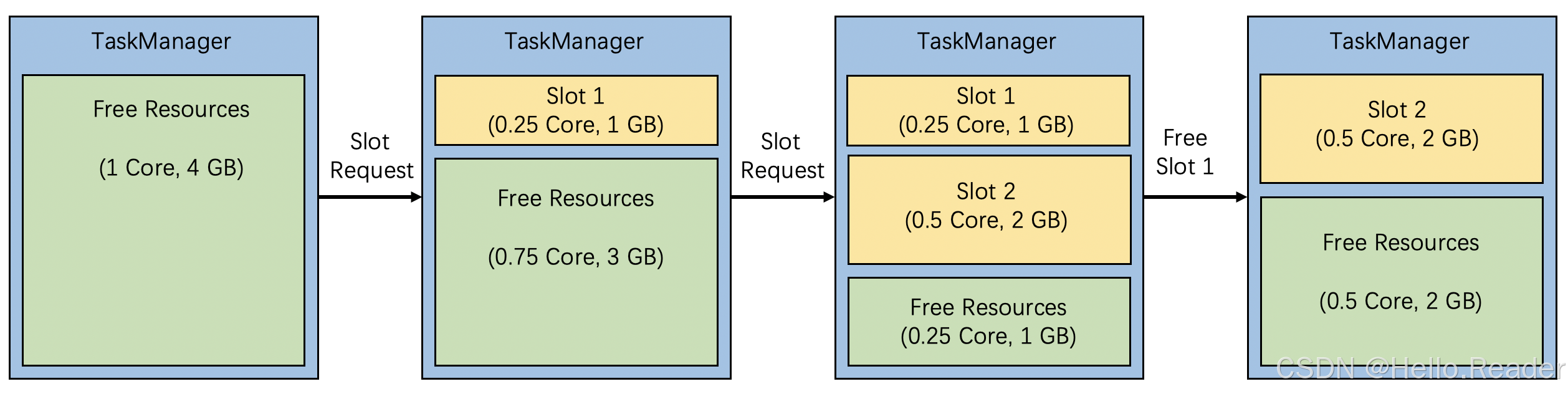
你也可以顺手在图下补一句解释:
“TaskManager 不再预分固定 slots,而是按请求动态切割;释放即归还资源池。”
11. 限制与坑:别在不合适的场景硬上
文档里提到的限制,建议你在博客里用一个“上线前检查清单”的口吻写出来:
- 目前是 MVP,只支持 DataStream API
- 暂不支持 Elastic Scaling(带资源 profile 的 slot request 还不行)
- Web UI 展示不完整(只显示 slot 数量,细节不足)
- 批任务需要
fine-grained.shuffle-mode.all-blocking=true才好用,但可能影响性能 - 不推荐“混合要求”(一部分指定资源,一部分不指定),可能导致执行间不一致甚至失败
- 资源分配是多维装箱问题(NP-hard),默认策略不保证最优,可能产生碎片或分配失败
- 拆分 SSG 可能打断 chain,性能会变(这点一定要提醒)
12. 什么时候值得用细粒度资源管理
你可以用一句很落地的判断标准收尾:
- 并行度差异巨大(source/sink/lookup 被外部系统约束)
- 整条 pipeline 放不进单 slot/单 TM(需要拆成多个 SSG)
- 批任务阶段资源差异明显(不同 stage 对 CPU/内存/外设需求不同)
- 有昂贵外部资源(GPU),粗粒度的“统一大 slot”浪费太明显

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)