LifeTrace,日常/工作必备工具!
LifeTrace:智能工作轨迹记录与检索系统 LifeTrace是一款本地化部署的工作轨迹管理系统,通过结构化记录电脑操作(窗口/应用/行为),结合向量检索技术实现高效回溯。核心功能包括:工作日志检索、AI助手背景自动补充、与FreeTodo任务管理联动。系统采用Python+FastAPI后端和Next.js前端架构,支持SQLite+ChromaDB存储。部署需配置Python 3.12、N
LifeTrace 更像个人工作轨迹 + 可检索上下文的底座,比如把你电脑上的活动(窗口、应用、操作痕迹等)落地成结构化记录,并配合向量检索,让你之后能搜得到、对得上、可以随时复盘。再往上就是接任务面板(FreeTodo)以及智能体,这些就可以把你正在做什么、刚做过什么全部自动喂给你的专属助手,而不是每次都需要手动复制背景。
本次教程以 雨云RainYun 服务器为主。
点击享受一杯奶茶钱购买 雨云 海外云服务器进行部署
点击查看详细的服务器开通教程
点击查看详细的宝塔面板安装教程
更多优质文章请前往 Flow Ciotter 论坛
常见的用法:
- LifeLog / 工作回溯:你可以按时间、应用、关键词去找,比如当时在干嘛,那段资料从哪来的,我为什么做了这个决定。
- 上下文自动化(给 AI 喂背景):让助手基于你的轨迹来理解当前任务,少问废话,不会总是让你补充背景。很多AI 助理不好用其实就是上下文断裂造成的,LifeTrace 特点就是可以把上下文补齐。
- 任务管理联动(比如 FreeTodo):前端是任务/事项 UI,后端提供 API,本地库+向量库支撑检索与智能能力,你可以把它理解成ui负责管理,LifeTrace负责记住以及查询。
注:(隐私提示):这类工具本质就是在采集活动信息,自然也会碰到密码、聊天或者工作机密,如果真的要投入正式环境使用,推荐优先选择本地部署,数据目录、保留周期以及过滤规则都必须先定好,再开启记录功能。
怎么部署(本地自托管:后端 + 前端)
项目是典型的前后端分离架构:
后端:Python / FastAPI(lifetrace/)
前端:Next.js(free-todo-frontend/)
数据:SQLite + ChromaDB(向量检索)
首先打开终端
如果是纯净环境则打开雨云-我的云服务器-(选择你的云服务器)- Xtermjs 模式链接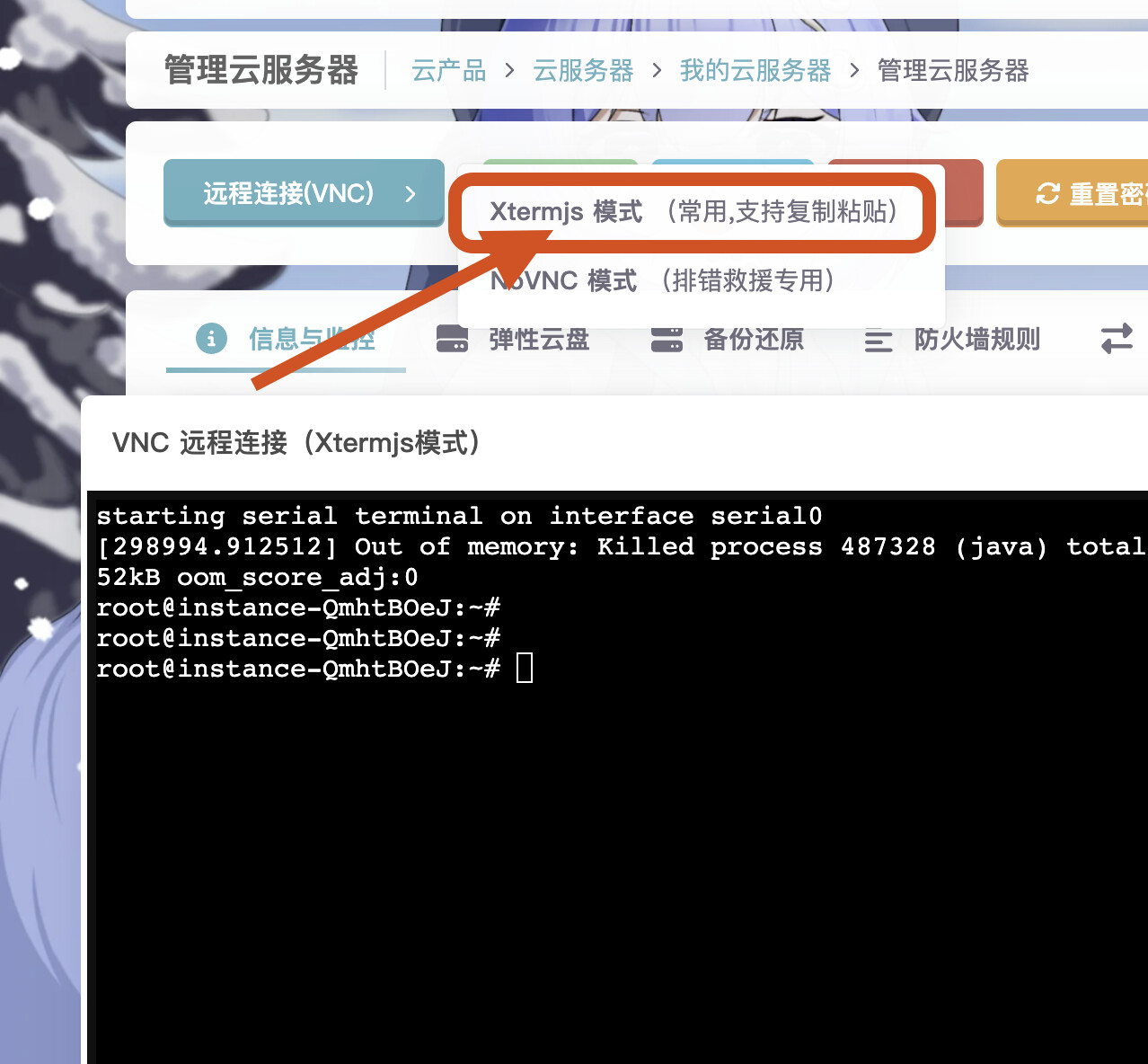
如果安装了宝塔面板,则以宝塔面板为主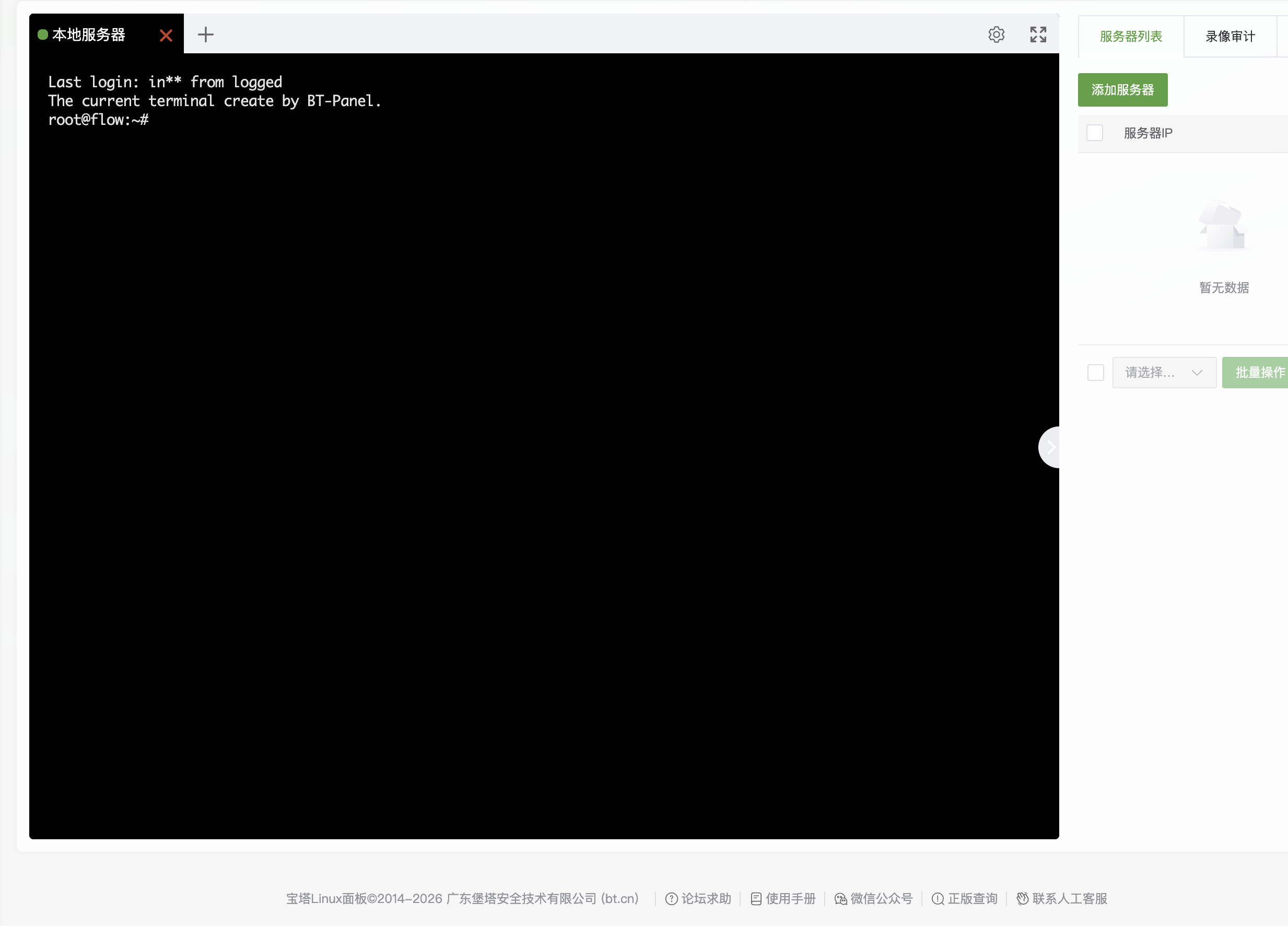
1)环境准备
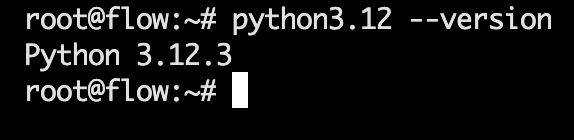
Python 3.12
执行以下指令后验证:python3.12 --version
sudo apt update
sudo apt install -y software-properties-common
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt update
sudo apt install -y python3.12 python3.12-venv python3.12-dev
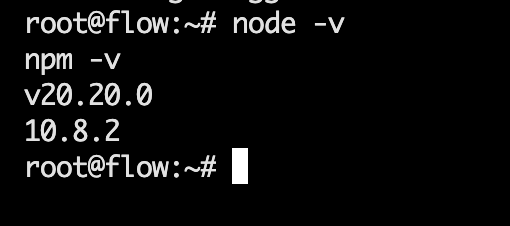
Node.js 20+
执行以下指令后验证:
node -v
npm -v
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt install -y nodejs
pnpm
执行以下命令后验证:pnpm -v
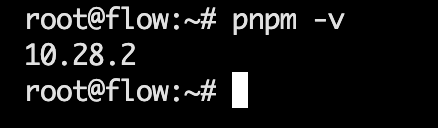
corepack enable
corepack prepare pnpm@latest --activate
推荐用 uv 管 Python 依赖(项目的 quick start 就按这个来的)
执行以下命令后验证:source ~/.bashrc
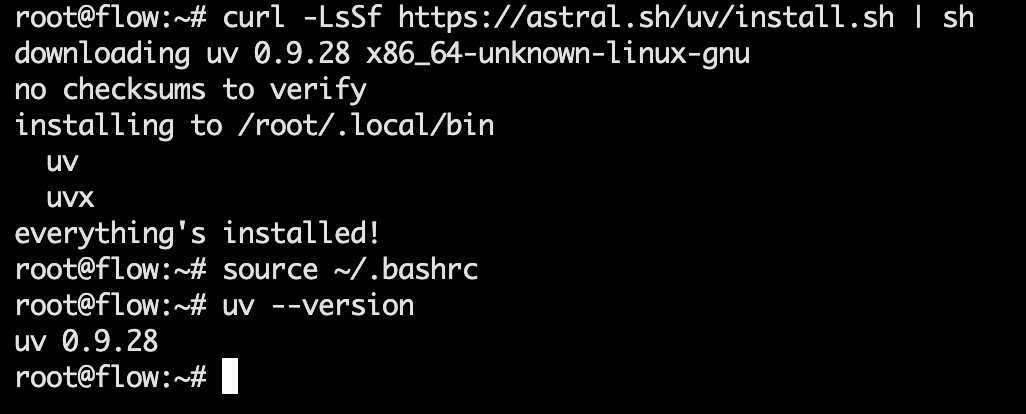
curl -LsSf https://astral.sh/uv/install.sh | sh
2)克隆项目
git clone https://github.com/FreeU-group/LifeTrace.git
cd LifeTrace
粘贴指令后回车,等待跑完即可。
跑完后回到命令行:
3)安装 uv + 安装后端依赖
macOS/Linux(我们执行这一条,大概几秒钟就好):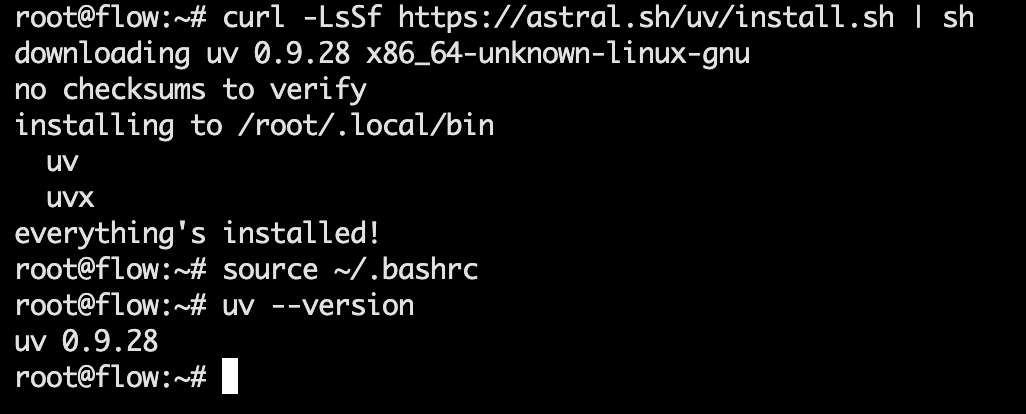
curl -LsSf https://astral.sh/uv/install.sh | sh
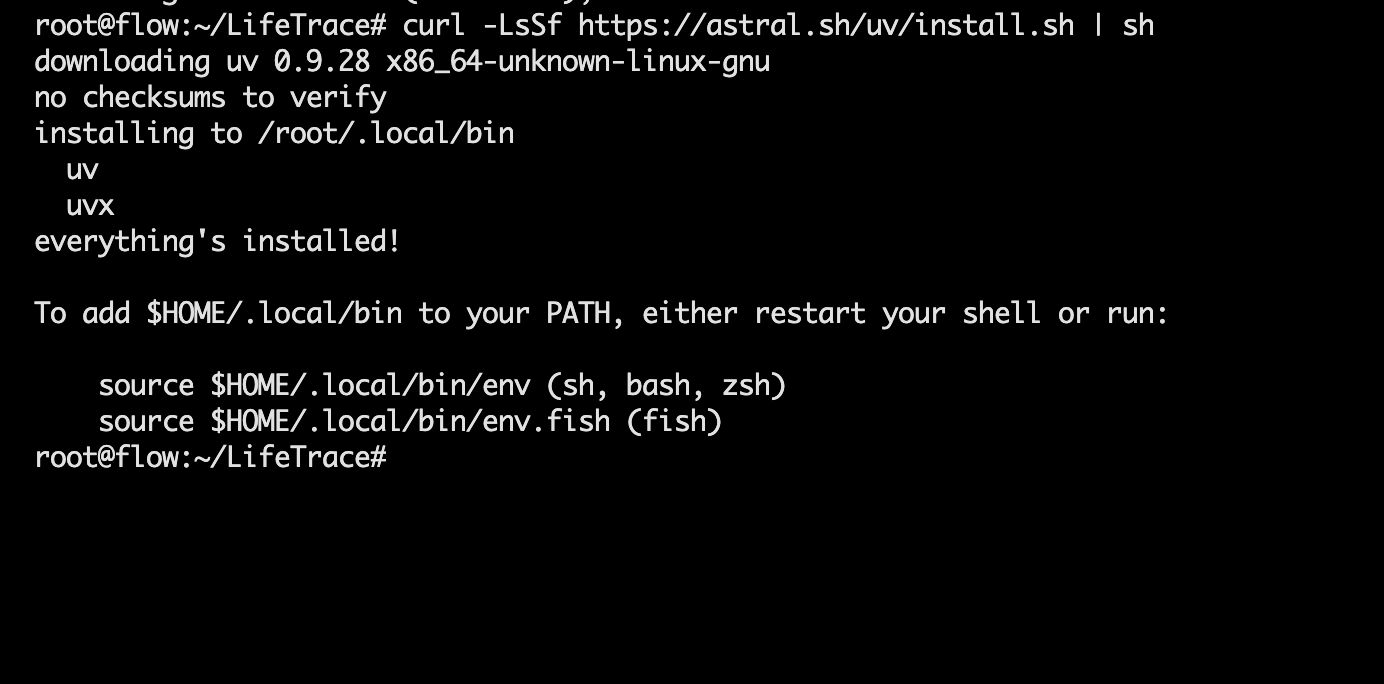
Windows(PowerShell):
irm https://astral.sh/uv/install.ps1 | iex
接下来在项目根目录装依赖并进虚拟环境:
# 对应示例第一步
uv sync
# 对应示例第二部:macOS/Linux
source .venv/bin/activate
# Windows
# .venv\Scripts\activate
示例第一步,等待 172 项跑完即可(无需分布执行,这里只是为了方便大家了解每个步骤的详细过程):
跑完后是这样:
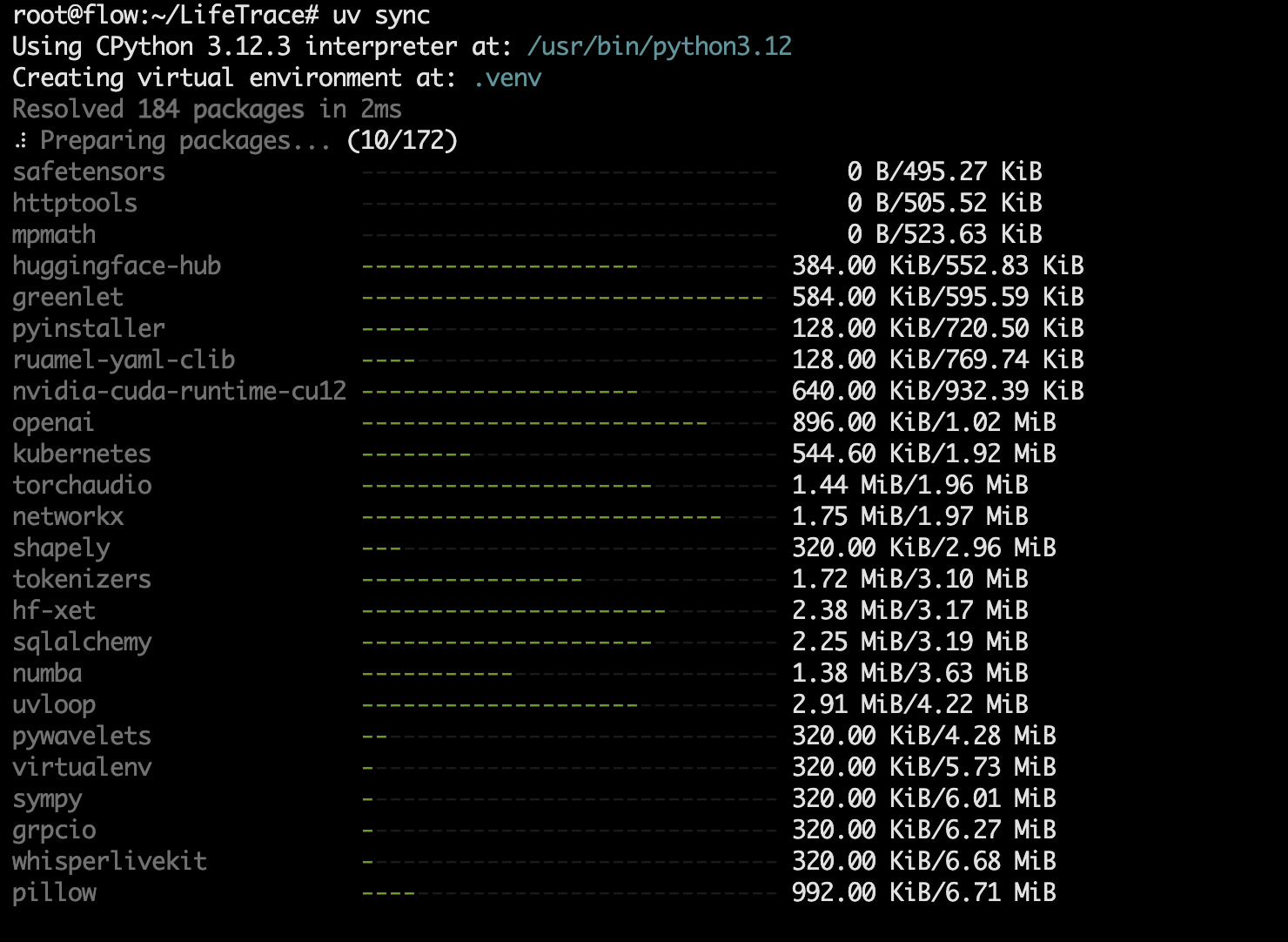
示例第二步,把当前 Shell 切换到项目专用的 Python 虚拟环境里。

最后在虚拟环境执行python -m pip install rapidocr-onnxruntime安装 RapidOCR。
注:如果该条命令报ERROR,就开始执行修复:
在宿主机装 libGL.so.1 所在包即可:
> sudo apt update
> sudo apt install -y libgl1
>
为了避免后面又缺别的 OpenCV 依赖(常见还会缺 libglib2.0-0),我建议一次装齐:
>
sudo apt update
sudo apt install -y libgl1 libglib2.0-0
>
装完后,先验证 import:
>
source /root/LifeTrace/.venv/bin/activate
python -c "import cv2; print('cv2 OK', cv2.__version__)"
>
python -c "import rapidocr_onnxruntime; print('rapidocr_onnxruntime OK')"
4)启动后端(lifetrace 服务)
python -m lifetrace.server
最后,你需要知道的只有这三点:
- 首次运行会生成配置:如果没有 lifetrace/config/config.yaml,会从 default_config.yaml 复制出一份。你真正要改的基本都在这个 config.yaml 里(模型、存储路径、采集策略、过滤规则等)。
- 端口不是死的:默认从 8001 起找可用端口,占用就自动往上跳,一般不需要你手动配置,控制台也会打印最终端口,通常就是:
- API:http://localhost:8001
- 文档:http://localhost:8001/docs(以日志为准)
- 先把后端跑稳后,后面前端会探测它,就会省很多事情。
5)启动前端(Web UI)
cd free-todo-frontend
pnpm install
pnpm dev
说明:
- dev 端口通常从 3001 起跳(同样会自动找可用端口)
- 前端会用 /health 去探测后端端口并做代理,所以后端先开更顺。
浏览器打开控制台给你的地址(一般为 http://localhost:3001)。
常见坑(特别注意,极大可能会出现)
- 端口冲突 后端/前端都会自动换端口,如果要做反代或写死地址时,别拿默认端口作为实际端口,必须按照日志输出的端口信息来配置。
- config.yaml 如果不改就可能卡住 重点就看着 lifetrace/config/config.yaml的模型提供商、API Key、embedding、数据目录、采集频率以及过滤规则,如果这些没有配置好,轻则功能缺一半,重则直接启动报错(通常会在启动后端时报错,如果存在其他报错则可查询官方文档或直接询问deepseek)。
- 资源占用上来很快,比如高频记录 + 向量化 + 本地模型,很容易就会把 CPU/RAM 拉满,常用的降压手段就是降低采样频率以及加过滤规则,同时也要换轻量 embedding 并减少入库字段。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 36
36 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)