《Linux系统编程之进程环境》【地址空间】
在这里插入图片描述为什么会这样?我们可以从两个关键角度来想: 首先,要是这些 “地址” 直接对应真实内存,意味着:其次,更核心的点在于:简单来说:代码语言:javascriptAI代码解释在这里插入图片描述在这里插入图片描述这就很矛盾了 —— 如果这个地址是真实的物理内存地址,那同一个内存地址里的数据怎么可能同时是两个不同的值?你可别狡辩,遇事不决,量子力学哦! 所以:从这个事实我们可以大胆推断:
我们都被骗了,嘤嘤嘤!

在这里插入图片描述
现在鼠鼠想问问你上面的程序打印的内容是内存吗? 难道不是吗?他还真不是!啊为什么啊?
为什么会这样?我们可以从两个关键角度来想: 首先,要是这些 “地址” 直接对应真实内存,意味着:
- 每个进程的内存都得按 “代码段→数据段→堆→栈” 这种固定、规律的方式排布。
- 可系统里同时运行着成百上千个进程(比如:你的浏览器、终端、后台服务),每个进程需要的内存大小、功能模块都不一样,怎么可能保证所有进程都 “乖乖地” 按同一种规律占用真实内存?
- 一旦两个进程的 “规律排布” 重叠,就会出现内存冲突,轻则程序崩溃,重则整个系统出问题。
其次,更核心的点在于:
- 其实我们上面说的是“程序地址空间”(比如:C/C++ 里学的代码段、数据段划分),其实是个 “语言层的概念”
- 在“系统层的概念”中它又被称为是:进程地址空间(也叫虚拟地址空间),正如其名和真实物理内存完全是两回事
简单来说:
- 操作系统会给每个进程分配一个独立的
“虚拟地址空间”,这个空间里的地址(就是我们代码里打印的&gval、&heap_mem这类值)都是 “假的”,是操作系统给进程画的“内存地图”(切记只是个地图罢了) - 当进程要访问某个虚拟地址时,操作系统会通过
“内存管理单元(MMU)”把虚拟地址翻译成真实的物理内存地址,再去操作真实内存
代码语言:javascript
AI代码解释
#include <stdio.h>
#include <stdlib.h> // 提供malloc等内存分配函数的声明
//1.未初始化的全局变量,会被存放在“BSS段”
int g_unval;
//2.已初始化的全局变量,会被存放在“数据段”
int g_val = 100;
int main(int argc, char* argv[], char* env[])
{
//3.定义一个字符串常量,存储在“只读数据段”
const char* str = "helloworld";
//4.定义静态局部变量,存储在“数据段”(与全局变量同区域)
static int test = 10;
//5.在堆上分配内存,返回的地址属于堆区域
char* heap_mem = (char*)malloc(10);
char* heap_mem1 = (char*)malloc(10);
char* heap_mem2 = (char*)malloc(10);
char* heap_mem3 = (char*)malloc(10);
//6.打印main函数代码的地址(代码段)
printf("code addr: %p\n", main);
//7.打印已初始化全局变量g_val的地址(数据段)
printf("init global addr: %p\n", &g_val);
//8.打印未初始化全局变量g_unval的地址(BSS段)
printf("uninit global addr: %p\n", &g_unval);
//9.打印堆上分配的内存地址(堆区域)
printf("heap addr: %p\n", heap_mem);
printf("heap addr: %p\n", heap_mem1);
printf("heap addr: %p\n", heap_mem2);
printf("heap addr: %p\n", heap_mem3);
//10.打印静态局部变量test的地址(数据段)
printf("test static addr: %p\n", &test);
//11.打印栈上变量heap_mem的地址(栈区域)
printf("stack addr: %p\n", &heap_mem);
printf("stack addr: %p\n", &heap_mem1);
printf("stack addr: %p\n", &heap_mem2);
printf("stack addr: %p\n", &heap_mem3);
//12.打印字符串常量str的地址(只读数据段)
printf("read only string addr: %p\n", str);
//13.遍历命令行参数数组,打印每个参数的地址
for (int i = 0; i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
//14.遍历环境变量数组,打印每个环境变量的地址(环境变量通常在栈或特定区域)
for (int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
//15.程序正常退出,返回0
return 0;
}
在这里插入图片描述

在这里插入图片描述
什么你说你还是不信,好吧,那鼠鼠就只能用实时说话了! 在之前那段
fork()创建子进程的代码里,有个非常关键的现象:
- 父进程和子进程打印的全局变量
gval的地址完全相同(比如都是0x556b8f7fc010) - 但实际运行时,父进程读取的
gval始终是初始值 100,而子进程的gval却在不断自增(101、102……105)
这就很矛盾了 —— 如果这个地址是真实的物理内存地址,那同一个内存地址里的数据怎么可能同时是两个不同的值?你可别狡辩,遇事不决,量子力学哦! 所以:从这个事实我们可以大胆推断:
- 这些地址绝对不是真实的物理内存地址
- 它们其实是操作系统给每个进程分配的虚拟地址—— 父进程和子进程看到的 “相同地址”,只是虚拟地址空间里的 “表象”,操作系统会通过内存管理单元(MMU)把这两个 “相同的虚拟地址” 映射到物理内存中完全不同的位置
这也意味着:我们在 C/C++ 中用到的所有指针地址,从本质上来说都是虚拟地址。 操作系统通过这种 “虚拟地址 + 映射” 的机制:
- 既保证了每个进程能 “独立” 使用连续的地址空间(方便程序开发)
- 又避免了多进程直接操作物理内存导致的冲突(保证系统稳定)
这种虚拟地址的设计,正是现代操作系统内存管理的核心智慧 —— 让程序以为自己独占内存,实则由系统在背后巧妙地调度和隔离
2. 具体如何实现虚拟地址<->物理地址的映射?
实际上,当你的代码被编译后,程序中的变量名在严格意义上大多已经 “消失” 了 —— 它们要么
被转化为具体的内存地址,要么被编译成特定的寻址方式这意味着:当我们在程序中访问栈上或堆上的数据时,本质上都是通过地址进行操作,这个层面的内存访问属于 “用户空间” 的范畴。
现代操作系统会为 每个进程分配一个独立的虚拟地址空间,这是进程 “看到” 的内存全貌。
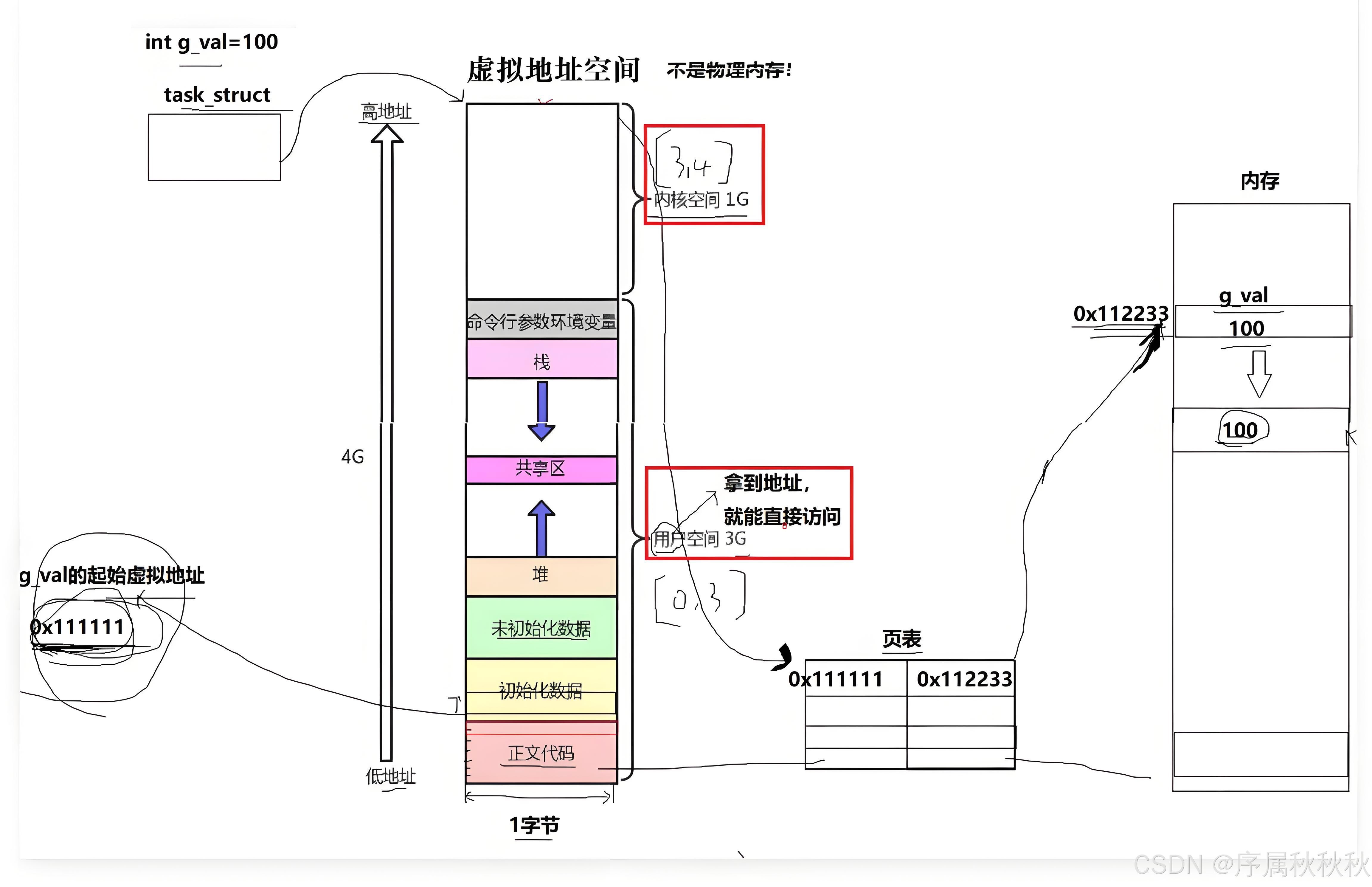
- 举个例子:如果我们定义了一个全局变量
gval并赋值为 100,它在物理内存中必然有一个实际的存储位置(比如:物理地址0x112233) - 同时,在进程的虚拟地址空间里,也会为这个变量预留一块 4 字节的空间,并分配一个虚拟地址(比如:
0x111111)
为了让虚拟地址能对应到真实的物理内存,操作系统会为每个进程维护一个 “页表”
- 这个页表就像一本翻译词典:左侧记录的是进程的虚拟地址(比如:
0x111111),右侧则对应着该虚拟地址映射到的物理地址(比如:0x112233) - 当进程想要访问
gval时,它会先通过虚拟地址0x111111发起请求 - 此时操作系统会自动触发 “地址翻译” 过程:通过查找页表,找到
0x111111对应的物理地址0x112233,然后再去访问物理内存中的数据
整个过程对进程来说是完全透明的 —— 进程只需要操作虚拟地址,无需关心真实的物理内存位置。 所以:页表的核心作用就是实现 “虚拟地址到物理地址的映射”,它是虚拟内存机制的关键组成部分,既让每个进程拥有独立的地址空间(避免冲突),又能高效地管理物理内存的分配与回收。
在这里插入图片描述
思考与探究: 首先我们要明确:虚拟地址空间中,每一个字节都有唯一的地址。无论变量占据多少字节,其包含的每个字节都会经过页表映射到真实的物理内存地址。 这时可能有小伙伴会产生疑问:比如我们定义的
int g_val是整数类型,众所周知 int 类型通常占用 4 个字节,照理说应该对应 4 个地址才对,但为什么我们对g_val取地址时,只得到了一个地址呢?
- 其实我们通过
&g_val拿到的,是这 4 个字节中地址值最小的那个(也就是起始地址) - 而剩下的 3 个字节的地址,会根据变量的类型(这里是 int,占 4 字节)自动计算得出 —— 本质上就是在起始地址的基础上,通过 “偏移量” 来确定后续字节的位置
也就是说:
- 编译器通过 “起始地址 + 类型对应的长度(偏移量)” 的方式,帮我们隐含了对后续字节地址的计算
- 所以虽然变量实际占用多个字节、对应多个地址,但我们只需要通过取地址操作拿到起始地址,再结合变量类型,就能确定该变量所占据的所有字节的地址了
3. 被骗的真相?
要理解
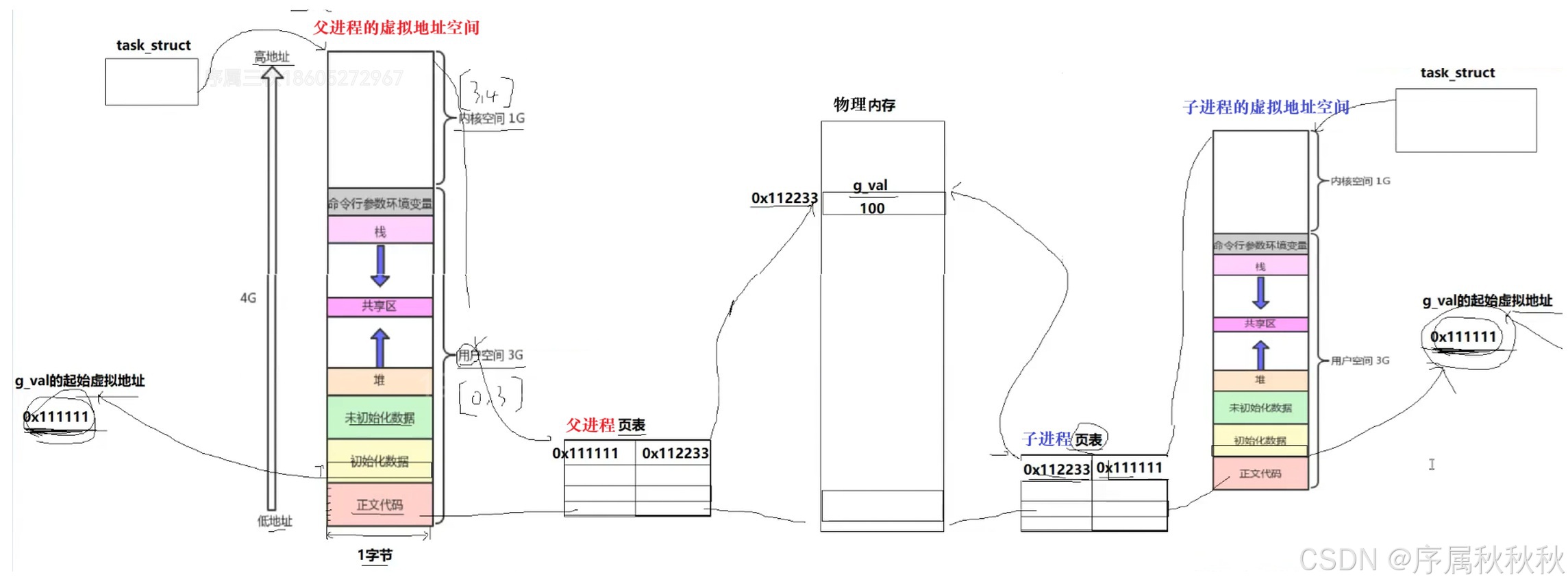
fork()创建子进程后 “地址相同却能独立操作” 的核心逻辑,需要从 “进程资源继承” 的底层机制说起: 首先现代操作系统会为每个进程分配一套独立的 “核心资源”,包括虚拟地址空间和页表
- 父进程有自己的虚拟地址空间和页表,子进程被创建时,这些资源也会完整地从父进程拷贝过来
- 不仅如此,子进程的进程控制块(PCB,记录进程状态的核心数据结构),同样是基于父进程的 PCB 拷贝生成的,目的是让子进程初始状态与父进程保持一致
不过这里的 “拷贝” 有个关键细节:对于虚拟地址空间中的 “地址映射关系”(也就是页表内容),子进程进行的是浅拷贝
- 简单说,子进程页表中记录的 “虚拟地址→物理地址” 映射规则,和父进程完全相同
- 比如说,父进程中全局变量
g_val的虚拟地址是0x111111,映射到物理地址0x112233;子进程的页表也会原样记录 “0x111111→0x112233”
这就解释了为什么父子进程打印的 g_val 虚拟地址完全相同:
- 因为子进程的虚拟地址空间是从父进程拷贝来的,变量的虚拟地址自然和父进程一致
- 而默认情况下,父子进程的
g_val会 “共享同一块物理内存”,也是因为页表的映射关系相同 —— 两者通过相同的虚拟地址,最终都会指向物理内存中0x112233这个位置
更重要的是,这种 “共享” 不仅限于数据(比如:全局变量、局部变量),连程序的代码段也是如此。
- 代码段存储的是可执行指令,这些指令的虚拟地址和物理地址映射关系,同样会通过页表浅拷贝传递给子进程
- 所以从底层看,fork() 刚创建子进程时,父子进程的代码和数据是完全共享物理内存的,只有当子进程尝试修改数据(比如:
g_val++)时,操作系统才会触发“写时拷贝”机制,为子进程分配新的物理内存并更新其页表,让子进程拥有独立的数据副本 —— 这也是操作系统为了节省内存资源设计的高效策略
总结来说:
- 子进程通过拷贝父进程的 PCB、虚拟地址空间和页表,确保了初始状态与父进程一致
- 而页表的浅拷贝既让父子进程的虚拟地址保持相同,又实现了代码和数据的默认共享,这正是
fork()机制中 “继承与共享” 的底层逻辑
在这里插入图片描述
4. 写实拷贝本质是什么?
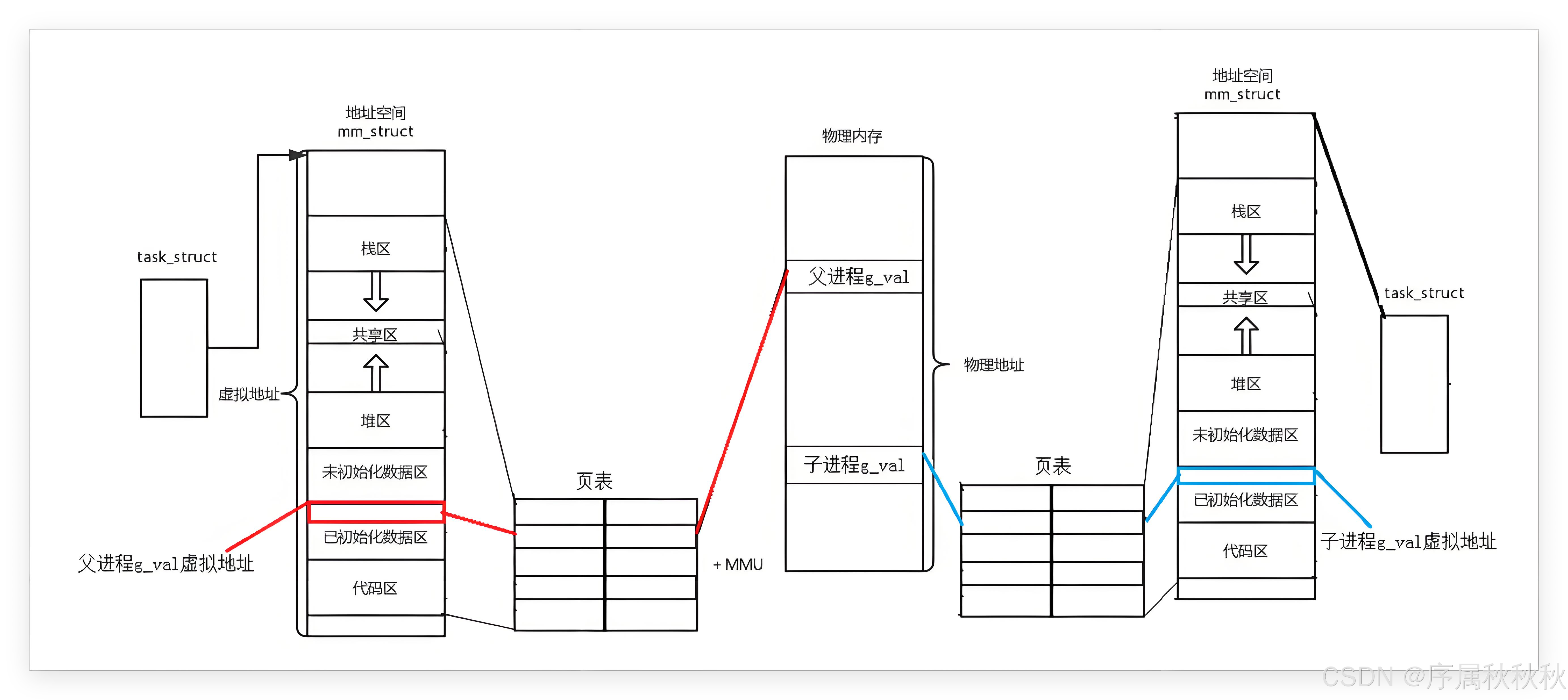
现在我们来聚焦一个关键场景:当子进程要修改变量(比如:对
g_val执行++操作)时,背后会发生什么? 首先要明确一个核心原则:进程具有独立性—— 每个进程的操作不该影响其他进程的运行。
- 如果子进程直接顺着自己的虚拟地址,找到对应的物理地址(比如:之前和父进程共享的
0x112233)并修改 - 那父进程访问
g_val时,看到的值也会被改变,这就破坏了进程的独立性,显然不符合操作系统的设计逻辑
所以:当子进程试图修改 g_val 时,操作系统会立刻介入,触发一种名为 “写时拷贝(Copy-On-Write,简称 COW)” 的机制,具体过程是这样的:
- 检测修改行为:子进程发起
g_val++时,会先通过虚拟地址查找页表,找到对应的物理地址(此时还是和父进程共享的0x112233)。操作系统会检测到 “子进程要修改共享的物理内存数据”,于是暂停子进程的修改操作 - 分配新的物理内存:操作系统会在物理内存中为子进程重新开辟一块新空间(比如:地址为
0x223344),然后把原来物理地址0x112233中g_val的值(比如:初始的 100)完整拷贝到新空间0x223344中。这一步之后,子进程就有了g_val的独立副本 - 更新子进程的页表:接下来,操作系统会修改子进程的页表映射关系 —— 把原来 “虚拟地址
0x111111→ 物理地址0x112233” 的条目,更新为 “虚拟地址0x111111→ 物理地址0x223344”。也就是说,子进程的虚拟地址没有任何变化,还是0x111111,但它对应的物理地址已经换成了新的0x223344 - 恢复子进程修改:完成页表更新后,操作系统会让子进程继续执行
g_val++操作。此时子进程修改的,就是自己独立的物理内存副本(0x223344中的数据),父进程的g_val依然对应原来的物理地址0x112233,数据不会受到任何影响
到这里,我们就能清晰理解写时复制的核心逻辑了:
- 它既保证了进程的独立性(子进程修改数据不影响父进程)
- 又避免了
fork()时直接拷贝所有物理内存(节省了内存资源和创建进程的时间)
只有当真正需要修改数据时,才会为子进程分配独立的物理内存并更新映射。
在这里插入图片描述
5. 进一步探究虚拟地址是什么?
小故事:富豪的私生子
在遥远的北美大陆,住着一位身家 50 亿美元的富豪。他有三个私生子,这三个孩子彼此毫不知情 —— 毕竟 “私生子” 的身份。 某天,富豪单独召见了大儿子。看着眼前对经商充满热情的少年,他许诺道:“你既然喜欢做生意,就好好闯。等你做出一番成绩,我的这 50 亿美元家产,就都是你的。” 不久后,他又私下找到了二儿子。得知这个孩子痴迷钢琴,便笑着鼓励:“你弹钢琴很有天赋,好好练,将来成了享誉世界的音乐家,我的那 50 亿美元,就留给你。” 最后见到三女儿时,富豪看着这个成绩优异的小姑娘,同样给出了承诺:“女儿,你学习这么好,继续加油。要是能考上哈佛大学,我的 50 亿美元,就归你了。” 听到这里,大家想必都明白了 —— 这位富豪分明是在给三个孩子 “画大饼” 啊!他之所以敢这么说,核心在于他断定:孩子们当下只会朝着目标努力,绝不会立刻张口就要这 50 亿美元。
而这个有趣的故事,恰好能用来比喻操作系统的虚拟内存机制:
- 故事里的大富豪,就相当于我们的操作系统,掌握着最核心的 “资源分配权”
- 那笔让孩子们向往的50 亿美元,就是计算机里实实在在的物理内存(容量有限,就像富豪的家产总量固定)
- 富豪给每个孩子许下的 “家产承诺”,就是操作系统给每个进程画的 “大饼”——虚拟地址空间
- 那三个彼此隔绝的私生子,则对应着系统中运行的进程(进程间相互独立,就像私生子们互不相识)
就像富豪让每个孩子都以为 “50 亿最终会归自己”,操作系统也会让每个进程都产生一种 “错觉”:
- 自己独占了一整块连续的内存空间(比如:32 位系统下,每个进程都认为自己拥有 4GB 虚拟内存)
- 但实际上,这些虚拟地址空间只是 “纸面承诺”,只有当进程真正需要访问数据时,操作系统才会悄悄将虚拟地址映射到实际的物理内存 —— 就像只有等孩子真的达成目标(虽然故事里是 “大饼”),富豪才需要兑现承诺一样
这个比喻恰好戳中了虚拟内存的精髓:用 “虚拟的地址表象” 让进程方便地管理内存,同时通过操作系统的底层调度,高效且安全地共享有限的物理内存资源。
小故事:我是项目经理
公司里有个爱 “画饼” 的老板:某天他找到小王,拍着肩膀说:“小王啊,好好干,等项目做出成绩,我就让你当项目经理!” 转头见到小李,又换了套说辞:“小李,你技术扎实,好好打磨业务,干好了我给你涨工资!” 接着,小赵、小钱、小孙…… 几乎每个员工都收到了老板量身定制的 “饼”
过了一阵子,老板又来 “画饼” 了。他走到小王面前,张口就说:“小王,最近表现不错,好好干,给你涨工资!” 小王一听就愣了,连忙追问:“老板,您上次明明说让我当项目经理,怎么今天改口了?” 老板瞬间语塞,心里犯起了嘀咕:“哎,员工太多,画的饼记混了……”
这一幕恰好暴露了一个问题:如果老板要给几十上百个员工画饼,每个饼的内容、对象、时间都不一样,要是不专门管理,迟早会乱成一锅粥。怎么解决这个问题?
其实思路和操作系统管理进程的逻辑如出一辙 ——“先描述,再组织”
所谓 “先描述”,就是给每个 “饼” 建立一份 “档案”
老板可以专门定义一个 “饼” 的结构体(比如:用代码里的 struct 表示),把关键信息都记下来:
代码语言:javascript
AI代码解释
struct Cake
{
char *employee; // 给谁画的饼(比如:“小王”“小李”)
char *time; // 什么时间画的(比如:“2025年9月16日”)
char *place; // 在哪里画的(比如:“办公室茶水间”)
char *content; // 画的什么饼(比如:“当项目经理”“涨工资”)
struct Cake *next; // 指针,用来连接下一个“饼”的档案
};每个员工的 “饼” 都对应一个这样的结构体实例,把 “给谁画、何时画、画了啥” 都描述清楚,就不会再记混细节。
然而 “再组织”,就是把这些零散的 “饼档案” 串起来管理 利用结构体里的 next 指针,把所有 struct Cake 实例连成一个链表 —— 这样老板想查哪个员工的饼,只要从链表头开始遍历,顺着指针就能找到对应的档案;想新增、修改或删除某个饼,直接操作链表节点就行,管理起来既清晰又高效。
其实,老板管理 “饼” 的逻辑,和操作系统管理虚拟地址空间的逻辑完全一致:
- 操作系统里的 “饼”,就是每个进程的虚拟地址空间(让进程以为自己独占内存的 “假象”)
- 用来描述虚拟地址空间的 “结构体档案”,在 Linux 系统中叫做 mm_struct(全称 “memory descriptor”,内存描述符)
- 这个结构体里记录了虚拟地址空间的所有关键信息:
代码段、数据段、堆、栈的起止地址、页表的指针、内存使用状态等,就像 “饼档案” 里记满了细节一样
- 这个结构体里记录了虚拟地址空间的所有关键信息:
- 而我们之前学过的 task_struct(进程控制块 PCB),则是描述进程本身的 “档案”—— 每个
task_struct里都会包含一个指向mm_struct的指针,就像 “员工档案” 里会关联他的 “饼档案” 一样😄
最终:操作系统通过 mm_struct 描述每个进程的虚拟地址空间,再通过链表等数据结构将这些 mm_struct 组织起来,实现了对所有进程虚拟内存的高效管理 —— 这和老板用 “结构体 + 链表” 管理 “画的饼”,本质上是同一个 “先描述,再组织” 的智慧。
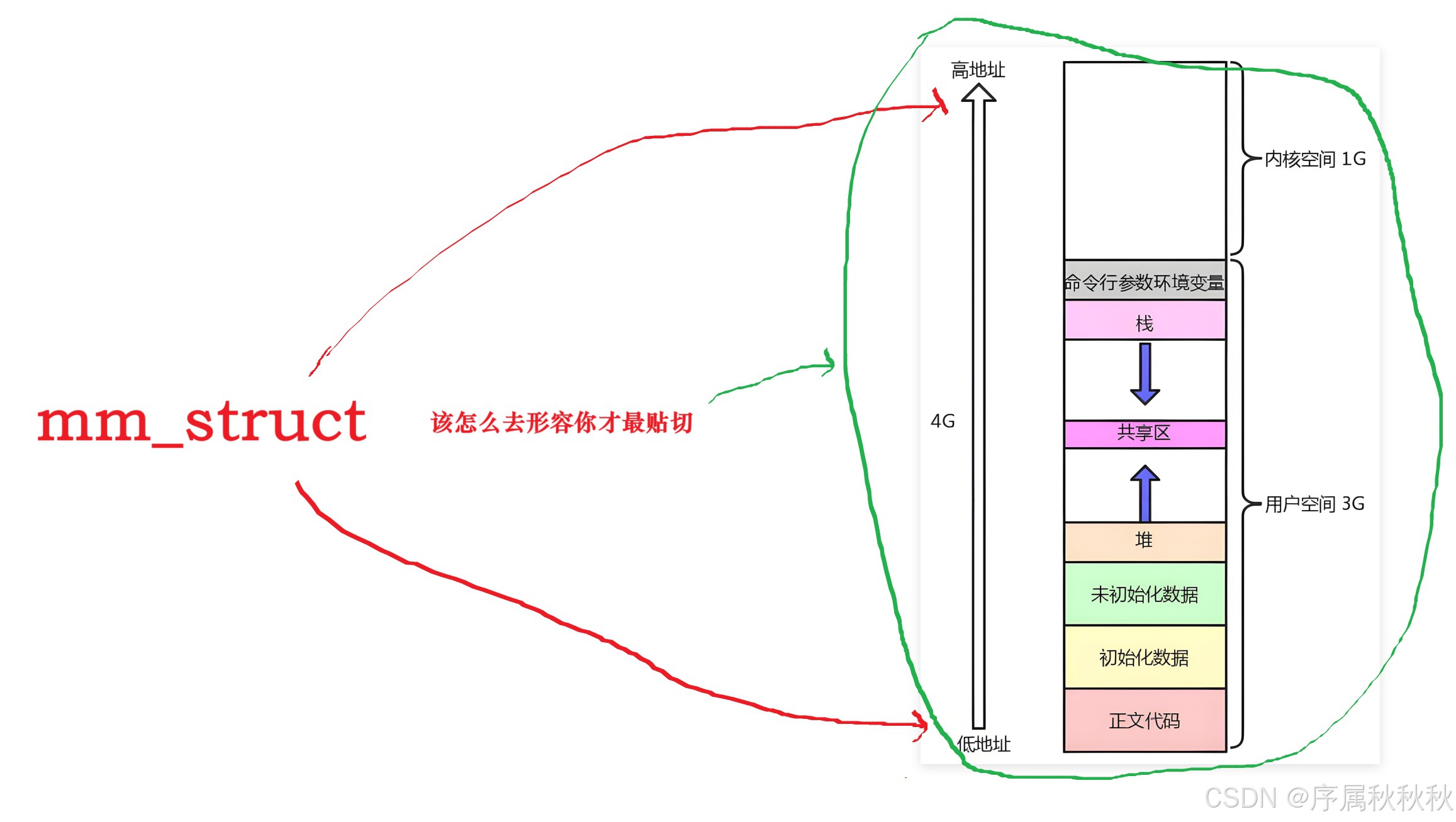
在 Linux 系统里,
mm_struct(内存描述符)这个结构体负责描述进程地址空间的所有信息
- 每个进程都仅有一个
mm_struct结构,并且在每个进程的task_struct(进程控制块)结构里,存在一个指针,该指针指向对应进程的mm_struct结构体 - 正因为如此,每个进程才能拥有各自独立的地址空间,从而做到相互之间不产生干扰
6. mm_struct到底长什么样?
在这里插入图片描述
小故事:桌上的三八线
假如你正在上幼儿园,平时总爱流鼻涕、不讲卫生,是个小邋遢鬼。但幸运的是,你和班里的班花小美分到了同一张课桌 —— 这张课桌长 100 厘米,本是两人共用的空间。可小美特别嫌弃你,一坐下就掏出铅笔,在课桌正中间画了一条清清楚楚的 “三八线”,还叉着腰警告你:“不许越过这条线,你的东西只能放你那边!”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献97条内容
已为社区贡献97条内容

所有评论(0)