AI学习笔记整理(67)——大模型的Benchmark(基准测试)
以上我们介绍的推理测试,主要还是建立在一类已有的知识学可上的(如数学、物理、生物),要攻克这些题目,模型既要非常博学(掌握大量的学术知识)还得非常聪明(推理能力很强)。那有没有专注于考模型聪不聪明,而不考模型的知识积累的基准呢?就像对于一个人的评价,我们看他聪不聪明,可能从小学能看出来了,不一定要等到他上完大学之后再做评价。对模型的测试也是一样,下面我们讲的对于模型 “抽象推理” 能力的测评,就属
大模型的Benchmark(基准测试)
参考链接:https://zhuanlan.zhihu.com/p/22244946778
大模型的Benchmark(基准测试)是用于评估和比较大型机器学习模型(如GPT、BERT、PaLM等)性能的一系列标准化任务、数据集和评价指标。这些Benchmark为大模型的开发者和使用者提供了一个统一的评估框架,帮助研究人员和开发者衡量模型在不同领域(如语言理解、生成、推理等)的能力,推动技术进步,同时也为用户在选择适合特定任务的大模型时提供参考依据。
评价指标则包括客观指标,主观指标和效率指标等。
- 客观指标:
- 分类/问答:Accuracy、F1、EM(精确匹配)。
- 生成任务:BLEU、ROUGE、BERTScore(语义相似度)。
- 代码任务:Pass@k(生成代码通过单元测试的比例)。
- 主观指标:人工评分(流畅性、逻辑性、实用性)。
- 效率指标:推理速度、显存占用、能耗(尤其边缘设备场景)。
PASS@1是评估模型性能的一个指标,特别是在自然语言处理(NLP)和代码生成任务中常用。它表示模型在测试集中正确预测第一个单词的准确率。具体来说,PASS@1衡量的是模型在给定上下文后,第一次尝试就正确生成或选择正确答案的比例。
Benchmark的评估指标
大模型的Benchmark 评价指标用于量化模型在不同任务中的性能表现,以下是详细的分类和解释:
通用语言任务指标
-
准确率(Accuracy):预测正确的样本占总样本的比例。 适用分类、问答(如选项选择题)等任务。缺点是对类别不平衡的数据不敏感(例如99%的负样本时,模型全预测负也能高准确率)。
-
F1 Score:精确率(Precision)和召回率(Recall)的调和平均数,公式为:
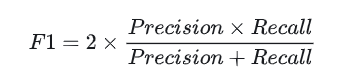
适用二分类或多分类任务(如情感分析、命名实体识别)。平衡了误报(False Positive)和漏报(False Negative)。 -
精确匹配(Exact Match, EM):模型输出与标准答案完全一致的比例(例如“北京”与“北京市”不匹配)。适用封闭式问答(如SQuAD)、代码生成(输出需完全正确)等任务。
文本生成任务指标 -
BLEU(Bilingual Evaluation Understudy):通过比较生成文本与参考文本的n-gram重叠度计算得分(1~4-gram加权)。适用机器翻译、文本摘要等任务。缺点是忽略语义,对同义表达不友好。
-
ROUGE(Recall-Oriented Understudy for Gisting Evaluation):衡量生成文本与参考文本的召回率(ROUGE-N)、最长公共子序列(ROUGE-L)等。适用摘要生成(更关注关键信息覆盖)等任务。常见变体包括ROUGE-N:n-gram重叠率;ROUGE-L:基于最长公共子序列的相似度。
-
BERTScore:利用BERT模型计算生成文本与参考文本的语义相似度(基于词向量余弦相似度)。优点是可以捕捉语义一致性,优于n-gram方法。

-
Perplexity(困惑度,PPL):衡量模型对测试数据的预测不确定性,值越低越好。公式为:
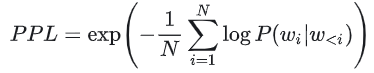
适用语言模型预训练评估等任务。缺点是无法直接反映生成质量(如流畅但无意义的文本可能PPL低)。
代码与推理任务指标 -
Pass@k:生成k个代码样本中至少有一个通过单元测试的比例。适用代码生成(如HumanEval)任务。 常见的Pass@1表示首次生成即正确的概率。
-
数学准确率(Math Accuracy):模型解决数学问题的正确率(需步骤和答案均正确)。适用数学推理(如GSM8K、MATH)等任务。变体包括步骤分等,即部分正确步骤也可得分。
多模态任务指标 -
CIDEr(Consensus-based Image Description Evaluation):通过TF-IDF加权n-gram匹配评估图像描述生成质量。适用图像字幕生成等任务。
-
mAP(mean Average Precision):目标检测中,综合不同IoU阈值下的平均精度。 适用视觉问答(VQA)、物体检测等任务。
伦理与安全性指标 -
Toxicity Score:使用分类模型(如Perspective API)检测生成文本的毒性比例。适用内容安全评估任务。
-
Bias Score:统计模型输出中涉及性别、种族等敏感属性的偏见程度(如StereoSet数据集)。例如职业关联性测试(“护士”是否总被关联为女性)。
效率指标 -
推理速度(Tokens/sec):每秒生成的token数量,衡量实时性。影响要素包括模型参数量、硬件(GPU/TPU)。
-
显存占用(GPU Memory):推理或训练时的显存使用量(如GB为单位)。可以决定模型能否在边缘设备部署。
人类评估(Human Evaluation)
当自动指标不足时,需人工评估:包括流畅性(Fluency):文本是否通顺;相关性(Relevance):内容是否切题;有用性(Usefulness):是否解决实际问题(如客服对话)等。
指标选择原则
任务匹配性:
- 分类任务 → Accuracy/F1
- 生成任务 → BLEU/ROUGE/BERTScore
- 代码任务 → Pass@k
多维度综合:例如同时评估准确性(EM)和效率(Tokens/sec)。
避免单一指标陷阱:例如BLEU高但语义错误(需结合人工评估)。
大模型的智能体能力、推理能力、coding能力如何评估
参考链接:https://blog.csdn.net/2401_84204207/article/details/156268830
评估大语言模型(LLM)的智能体能力、推理能力和编程(coding)能力,需要结合特定的基准测试、任务设计和量化指标。以下是基于当前公开资料的综合评估方法:
智能体能力(Agent)评估
智能体(Agent)指能自主规划、调用工具并完成多步任务的AI系统,其评估侧重于自主性、协作效率和任务完成质量。
- 自主执行成功率:Agent在无人工干预下,独立完成端到端任务(如重构代码模块、迁移库)的成功率,是核心指标。
- 人机协作比:完成一个任务中,人类下达指令的次数与Agent自动执行步骤的比例。比值越低,表明自动化程度越高。
- 任务完成率与正确率:在标准化任务(如MultiWOZ对话管理、WebShop购物)中,评估Agent能否准确理解目标、调用正确工具并达成预期结果。
- 工具调用准确性:评估Agent选择和使用外部工具(如API、搜索引擎、代码解释器)的精准度和效率。
- 基准案例:
- τ²-bench (逼真的“客服模拟战”):目前 Agent 落地最广泛的场景就是企业的智能客服了,而 τ²-bench(也叫 Tau2-bench)就是模拟了一个真实的 “客服对话智能体” 场景,它专门构建了一个 “用户模拟器” 和一个 “环境数据库”。模型扮演客服(比如电信公司客服),必须在满足刁钻用户需求的同时,严格遵守公司的隐形规定。
- MCP-Atlas(更通用的多工具工作流智能体):Anthropic 推出的模型上下文协议 (MCP) 协议已经成为了 AI 连接外部世界的标准。MCP-Atlas 通过 MCP 评估语言模型处理实际工具使用情况的能力,它直接给模型一张 “工具地图(Atlas)” ,包含 40 多个不同服务器、300 多个工具的复杂环境。模型必须自己发现合适的工具、正确调用,并把多步结果汇总成最终答案。
推理能力(Reasoning)评估
如果说“通用学科知识”是考大模型的“记忆力”(看它背了多少书),那么“推理能力”考的就是它的“脑力”(看它聪不聪明,逻辑转不转得过来)。
推理能力涵盖数学、常识、多步逻辑和因果推断,通常通过结构化基准测试衡量。
- 数学推理:使用GSM8K数据集,评估模型解决小学数学应用题的能力,要求模型生成正确推理链。
- 常识与多跳推理:使用CommonsenseQA、StrategyQA等数据集,测试模型对隐含常识和多步逻辑关系的理解。
- 跨学科知识:MMLU(Massive Multitask Language Understanding)涵盖57个学科的多项选择题,全面检验模型的知识广度与深度。
- 逻辑一致性:通过定制的逻辑谜题或对话场景,评估模型输出是否自洽、无矛盾。
- 基准案例:
- HellaSwag:能不能听懂“人话”的常识测试:简单来说,它考的是 “补全句子” ,但补全的不是古诗词,而是生活常识。它专门设计了一些对人类来说显而易见,但对早期的 AI 来说极容易掉坑里的题目。
- GPQA Diamond:研究生的“噩梦”:GPQA 全称: A Graduate-Level Google-Proof Q&A Benchmark(研究生级别的防 Google 问答测试)。两个关键词:研究生水平 + 防 Google(Google-Proof)。这里面的题目,由生物学、物理学、化学等领域的 博士专家 编写。最变态的是,这些题目被设计成 “即使你把题目复制到 Google 搜索,也搜不到直接答案” 。你必须真正理解这个领域的原理,经过复杂的推导才能做出来。
- HLE:人类最后的防线:HLE 全称: Humanity’s Last Exam(人类最后的考试)。HLE 的设计初衷是:如果我们再不出这套题,AI 可能就要超越人类现有的评估手段了。如果 AI 能在这套题上拿满分,那我们基本可以说人类已经阻挡不住 AI 了。HLE 是一次全球协作:采用了带奖金的征集与审核流程,题目来自近 1000 名各个领域的顶尖专家贡献,覆盖 500+ 机构、50 个国家。公开题库的规模经历过收敛,最终形成 2,500 道题的定稿版本。这些题目通常具有极强的综合性和抽象性。很多题目不再是简单的“问答”,而是给出一张复杂的工程图纸,或者一段模糊的医学影像,结合一段很长的背景描述,问你一个极度细节的推断。
编程能力(coding)评估
编程能力评估关注代码生成、理解、调试和优化的综合水平,尤其在开发者辅助场景中。
- 代码采纳率:开发者接受AI生成代码建议的比例,是反映实用性的关键指标,行业标杆通常在30%-50%之间。
- AI生成占比:最终合入主干代码中,由AI生成的代码行数占总行数的比例,衡量AI贡献度。
- 入库/合入率:AI参与生成的Pull Request(PR)或Merge Request(MR)被成功合并的比例,反映代码的可用性和质量。
- 千行代码Bug率:对比引入AI前后的代码缺陷密度,评估AI辅助对代码质量的提升效果。
- 单元测试覆盖率增量:AI自动生成测试用例的能力,通常在引入后有显著提升。
- 基准测试:使用HumanEval或MBPP(Mostly Basic Python Problems)等数据集,通过函数级代码生成任务,评估模型的编程准确性和逻辑实现能力。
- 基准案例:
- HumanEval:写函数题:HumanEval 可以说是代码评估的 “鼻祖” ,也是很多小模型的入门考试。它由 OpenAI 发布,包含 164 个手写的编程问题。题目很单纯,不依赖外部库,只考基本的 Python 语法和逻辑。它会给你一个函数头和一段注释(Docstring),让你把函数体补全。
- SWE-bench:真实仓库修 Issue:SWE-bench 是大模型从 “做题家” 变成 “工程师” 的分水岭。它不再考孤立的算法题,而是直接从 GitHub 上扒拉下来真实的开源项目(比如 Django、scikit-learn、Flask),拿出用户真实提交过的 Issue(Bug、需求) 和对应的 Pull Request(修复代码),让模型去复现修复过程。数据集中会保留代码库当时的快照(commit hash),整个项目的代码库(可能几十万行),而 Issue 的描述可能非常简单(比如“用户反馈在特定版本下,存在数据泄露问题”)。模型必须自己阅读代码,找到是哪个文件的哪一行出了问题,然后写出修复补丁(Patch),也就是“你要改哪些文件的哪些行”。
- SWE-bench Pro:更真实的工程修复:基础原版的 SWE-bench 主要是 Python 项目,而且随着模型越来越强,原版题库已经被做透了,需要一个更“像真实工作”的新基准。于是 SWE-bench Pro 诞生了,它的数据集格式和基础版的 SWE-bench 保持一致,但是重点解决了下面几个问题:
- [数据污染] 训练时可能见过代码/解法,导致分数虚高,因此引入一部分私有或商业代码,尽量降低“模型背答案”的可能性。
- [任务多样性不足] 只在少数类型仓库上“刷题式”变强,因此新引入了 Java、JavaScript、Go 等多种语言。
- [问题过于干净] 模糊不清或定义不明确的问题一般会从基准测试中移除,但这并不能反映真实开发工作流程,真实工程里很多需求其实是含糊/不完整的。
综上,评估需采用定性与定量结合的方法,例如在真实开发环境中追踪开发者行为(如代码采纳率),同时在标准化基准上进行客观评分(如MMLU、HumanEval)。建议建立效能基线,在引入AI工具前后进行对比分析,以科学衡量其实际价值。评估系统依然会对修复后的代码运行单元测试,而模型写的代码不仅要 通过针对这个 Bug 的新测试,还必须不破坏原有的成百上千个测试(不能修好了一个 Bug,引出了十个新 Bug)。
抽象推理(Abstract reasoning)
以上我们介绍的推理测试,主要还是建立在一类已有的知识学可上的(如数学、物理、生物),要攻克这些题目,模型既要非常博学(掌握大量的学术知识)还得非常聪明(推理能力很强)。
那有没有专注于考模型聪不聪明,而不考模型的知识积累的基准呢?
就像对于一个人的评价,我们看他聪不聪明,可能从小学能看出来了,不一定要等到他上完大学之后再做评价。
对模型的测试也是一样,下面我们讲的对于模型 “抽象推理” 能力的测评,就属于这一类。
严格来说,“抽象推理” 的测评也属于推理能力测评的一种,但这类测评往往不需要模型具备太多专业的学术知识,最典型的就是 ARC-AGI ,我们看到 Gemini 3 和 GPT 5.2 也都出现了这两项测试,并且得分都不是很高。
- ARC-AGI-1
在 ARC-AGI 的测试中,模型你拿到的不是文字题干,不和某个领域的知识相关,也不是某个生活常识,而是几张 “前后对照图”(输入网格 → 输出网格)。模型先从要从这些对照图里猜出隐藏规则,再把规则用到一张新图上,画出它的“正确变换结果”。它要考察的也不再是领域知识的深度,而是:能不能用很少的例子快速学会新规则,并正确迁移。你可以把它简单理解成我们小学时代做的那种看图找规律的题,需要从多个角度找到规律 - ARC-AGI-2
ARC-AGI-2 是 ARC Prize 团队在 2025 年发布的下一代版本,它的题目形式与 ARC-AGI-1 一致,但是难度更高。
智谱、DeepSeek、Claude 和 Gemini
智谱、DeepSeek、Claude 和 Gemini 是当前全球大模型竞争格局中的代表性力量,分别来自中国和西方技术生态。综合来看,智谱GLM-4.7在编程与智能体能力上表现突出,DeepSeek以高性价比和开源优势赢得开发者青睐,Claude在复杂推理与企业级应用中保持领先,而Gemini则依托谷歌生态在多模态和大规模上下文处理上具备优势。
-
智谱(GLM系列)
- 优势领域:编程能力、智能体任务执行、长上下文处理。
- 在2025年发布的GLM-4.6已超越同期DeepSeek-V3.2-Exp,在AIME 25、SWE-Bench Verified等权威编程评测中表现优异,实测性能接近Claude Sonnet 4,但成本仅为七分之一。
- GLM-4.7进一步提升,与Claude Opus 4.5在智能体能力(Agentic Index)上仅差4分,位列全球前列。
- 模型支持多语言,尤其在中文语境下理解精准,适合教育、科研和企业开发场景。
- 已发布完全基于华为芯片训练的GLM-Image模型,体现国产软硬协同突破。
-
DeepSeek
- 优势领域:成本效率、开源开放、中文优化。
- DeepSeek-R1凭借混合专家架构(MoE),以较低资源消耗实现接近GPT-4o和Claude 3.5 Sonnet的性能。
- DeepSeek-V3.2在总榜排名第10,编程能力第10,智能体能力第6,整体稳居国产第一梯队。
- 模型权重公开,支持本地部署与微调,深受中小企业和开发者欢迎。
- 2025年4月月活达9688万,日活超2200万,用户主要集中在18–24岁群体,市场聚焦中国、印度和东南亚。
-
Claude(Anthropic)
- 优势领域:逻辑推理、内容安全、复杂任务编排。
- Claude Opus 4.5在Agentic Index智能体能力榜单中排名第一(67分),擅长处理多步骤、高复杂度任务。
- 采用“宪法AI”训练方法,强调安全性与伦理对齐,适合金融、法律、教育等高可信场景。
- 支持高达20万token上下文,在长文档分析、合同审查等任务中表现稳定。
- 被广泛用于企业知识管理、内容审核和自动化工作流构建。
-
Gemini(Google)
- 优势领域:多模态融合、搜索集成、大规模推理。
- Gemini 3 Pro与GPT-5.2并列总榜第一(73分),在编程能力上也并列榜首(62分)。
- 原生集成Google Search、YouTube、Workspace,适合产品调研、价格比较、内容创作等日常任务。
- 支持128K以上上下文,谷歌宣称其Gemini Diffusion模型生成速度可达1479 tokens/秒,远超GPT-4o的约150 tokens/秒。
- 多模态能力突出,可直接生成图文内容,适用于营销、设计辅助等创意场景。
适用场景建议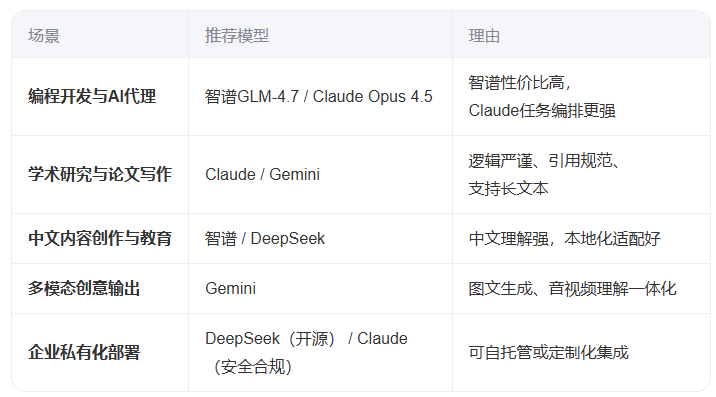

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)