MacBookPro本地搭建大模型:Ollama初使用
Ollama是一个简化本地部署和管理大型语言模型的开源工具。它支持一键安装和运行主流开源模型(如Llama、Mistral、Gemma等),提供类似Docker的命令管理和OpenAI兼容的REST API。核心优势包括极简部署、丰富模型库、完全离线运行和跨平台支持,能在普通PC上运行量化模型。通过简单命令即可下载、运行模型,并支持API调用。Ollama降低了本地AI应用的门槛,是体验和开发隐私
最近因项目开发需要,必须在本地安装一个大模型。Ollama 是一个开源项目,其主要功能是在本地计算机上快速部署、运行和管理大型语言模型。它极大地简化了在个人电脑(从普通笔记本电脑到高性能服务器)上运行诸如热门开源大模型(国内外主流开源大模型均支持)的过程。
一、核心特点与优势
1.1 极简部署
-
通过一条简单的命令行指令(例如
ollama rundeepseek-r1:8b)即可完成模型的下载和运行,无需复杂的配置、环境搭建或依赖处理。 -
内置了模型所需的运行环境,对用户透明。
1.2 丰富的模型库
-
提供官方支持的精选模型列表,涵盖从 Meta 的 Llama, Mistral AI 的 Mistral、Mixtral, Google 的 Gemma, 到众多优秀的社区模型(如 Deepseek、Qwen等)。
-
模型通常经过量化处理,在保持较好性能的同时,显著降低了硬件需求(如可以在仅有 8GB 内存的电脑上运行 7B 参数的模型)。
1.3 类 Docker 的管理方式:
-
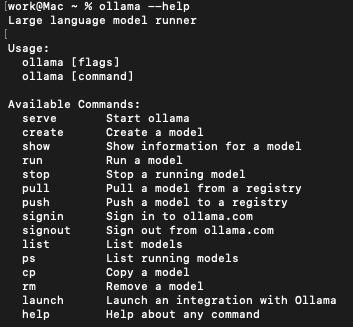
使用类似
pull、run、list、rm的命令来管理模型,对于熟悉 Docker 的开发者来说非常直观。
-
每个模型像是一个独立的“容器”,互不干扰。
1.4 提供 REST API:
-
Ollama 在本地启动一个服务(默认端口 11434),提供标准的 OpenAI 兼容的 API 接口。
-
这使得任何支持 OpenAI API 的应用程序(如聊天客户端、IDE 插件、自动化脚本)都能轻松连接到本地的 Ollama 模型,替代昂贵的云服务。
1.5 完全离线运行:
-
模型下载后,所有计算都在本地进行,无需联网,保证了数据的绝对隐私和安全。
-
没有使用次数限制,无需支付 API 费用。
1.6 跨平台支持:
-
支持 macOS、Linux 和 Windows。
二、基本工作流程
2.1 安装:
从官网下载对应操作系统的安装包,一键安装:https://ollama.com/

2.2 拉取模型:
在终端中执行 ollama pull <模型名>(例如 ollama pull qwen3:30b)。
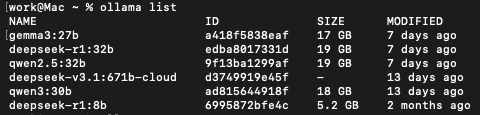
根据硬件选择合适大小的模型,MacbookPro 64G:建议最大32b左右的模型。

2.3 运行与对话:
执行 ollama run <模型名>,即可进入交互式聊天界面。

2.4 通过 API 调用:
启动 Ollama 服务后,可以使用 curl 或任何编程语言的 HTTP 库发送请求:
2.4.1 curl:
# 使用 curl 测试 API
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "Hello world"
}'# 使用聊天接口
curl http://localhost:11434/api/chat -d '{
"model": "llama2",
"messages": [
{
"role": "user",
"content": "你好"
}
]
}'
2.4.2 Java代码:
public JSONObject getAiResult (String prompt, String data ) {
List<JSONObject> messages = new ArrayList<>();
JSONObject system = new JSONObject();
system.put("role", "system");
system.put("content", prompt);
messages.add(system);
JSONObject result = new JSONObject();
MediaType mediaType = MediaType.parse("application/json;charset=utf-8");
JSONObject requestBody = new JSONObject();
requestBody.put("model", "qwen3:30b");
requestBody.put("messages", messages);
requestBody.put("stream", false);
requestBody.putAll(generationConfig);
Request request = new Request.Builder()
.url("http://localhost:11434/api/chat")
.addHeader("Authorization","")
.addHeader("content-type", "application/json;charset=utf-8")
.post(okhttp3.RequestBody.create(mediaType, requestBody.toString()))
.build();
try (Response response = client.newCall(request).execute()) {
if (!response.isSuccessful()) {
result.put("success", false);
result.put("msg","智能助手暂时无应答,请稍后再试!" );
} else {
String responseStr = response.body().string();
JSONObject responseJson = JSONObject.parseObject(responseStr);
JSONObject message = responseJson.getJSONObject("message");
if (message.containsKey("content")){
String content = message.getString("content");
content = content.replaceAll("<think>\\s*.*?\\s*</think>","")
.replace("'", "")
.replace("\n","")
;
result.put("content",content);
result.put("success",true);
} else {
result.put("success",false);
result.put("msg","responseStr:" + responseStr );
}
return result;
}
} catch (Exception e) {
e.printStackTrace();
result.put("success",false);
result.put("msg","智能问数助手暂时无应答,请稍后再试!报错:" + e.getMessage());
}
return result;
}
public static void main(String[] args) {
try {
AiHttpLocal aiHttpService = new AiHttpLocal();
long startTime = System.currentTimeMillis();
String text = "";
String prompt = "你好!" ;
JSONObject result = aiHttpService.getAiResult(prompt, text);
long endTime = System.currentTimeMillis();
System.out.println("耗时:" + (endTime - startTime) + "ms");
System.out.println(result);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
运行结果:
耗时:5780ms
{"success":true,"content":"你好!😊 有什么我可以帮你的吗?无论是问题解答、创意写作、编程帮助,还是其他需求,随时告诉我哦~"}
三、常见问题解决
3.1 端口冲突
# 修改默认端口 export OLLAMA_HOST=0.0.0.0:11435 ollama serve
3.2 内存不足
-
使用较小模型:使用 4-bit 或 8-bit 量化模型节省内存
ollama pull deepseek-r1:8b
-
调整运行参数:
ollama run qwen3:30b
四、总结
Ollama 是当前在个人电脑上运行和管理开源大模型的“事实标准”工具之一。 它以极低的门槛,让普通用户和开发者都能轻松体验和利用前沿的 AI 能力,同时兼顾了隐私、安全和成本控制。无论你是想单纯体验AI对话,还是希望构建一个本地AI应用,Ollama都是一个绝佳的起点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)