AI-大语言模型LLM-模型微调4-P-Tuning
P-Tuning和Prompt Tuning在优化方式上的“层数差异”核心在于它们对提示的可训练参数的设计不同。P-Tuning多的一层本质上是一个提示优化器建模提示内部的依赖关系提供更结构化的提示表示提高参数效率和学习稳定性是否值得这额外的复杂度,取决于具体任务、数据量和模型大小。对于复杂任务和小数据场景,P-Tuning的优势更明显;对于简单任务或超大模型,Prompt Tuning可能就足够
·
目的
为避免一学就会、一用就废,这里做下笔记
说明
- 本文内容紧承前文-模型微调1-基础理论、模型微调3-Prompt Tuning,欲渐进,请循序
- 前面学完了Prompt Tuning,这里选择另一种微调方法P Tuning进行学习和实战
P Tuning介绍
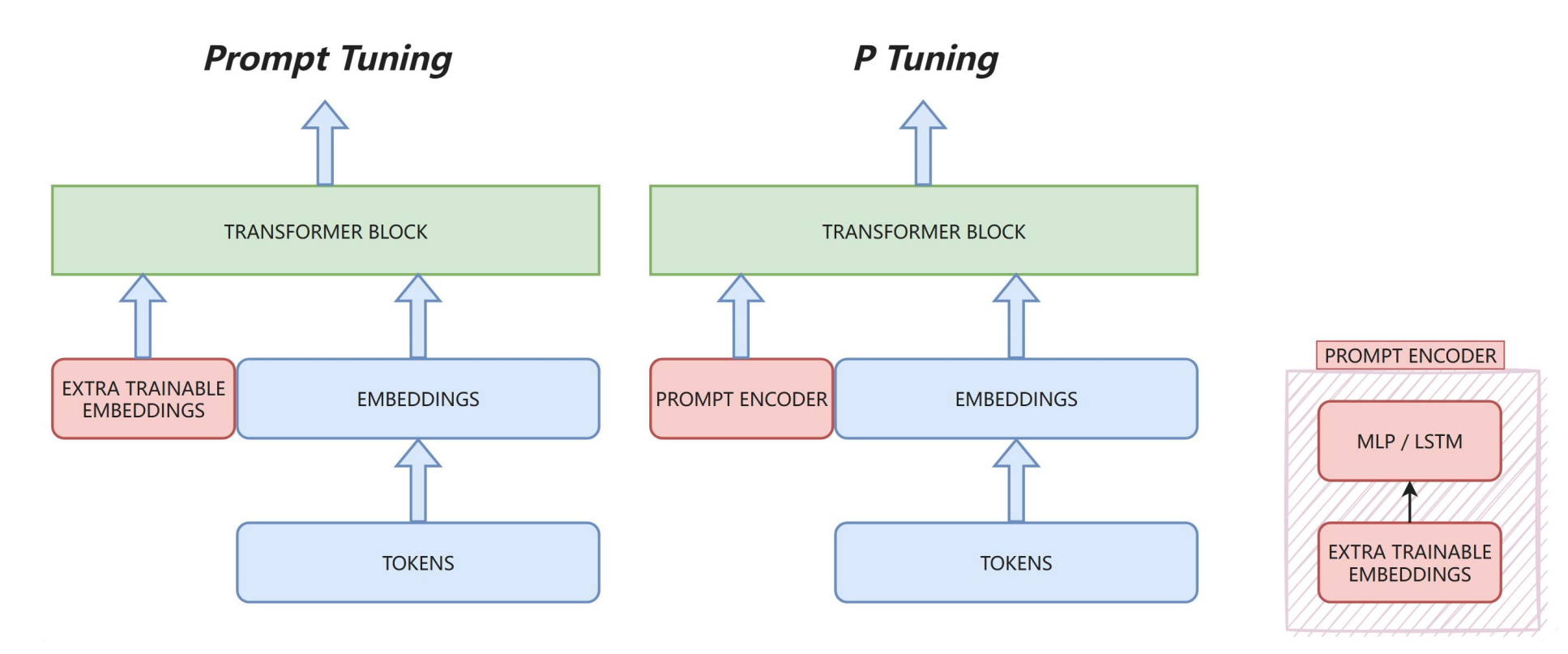
P-Tuning和Prompt Tuning在优化方式上的“层数差异”核心在于它们对提示的可训练参数的设计不同。详细说明如下:
核心差异:可训练参数的架构
Prompt Tuning(简朴版)
- 直接在嵌入层添加可训练token
- 相当于在输入序列前/中插入可训练的“软提示向量”
- 只有单层可训练参数:就是这些提示向量本身
- 结构:
[可训练提示向量] + [原始输入嵌入] → 冻结的LLM
P-Tuning(增强版)
- 引入轻量级神经网络处理提示
- 典型实现:可训练提示向量 → 双向LSTM/MLP → 优化后的提示表示 → LLM
- 多了一层网络:这个轻量级“提示编码器”
- 结构:
[可训练提示向量] → 提示编码器 → [优化提示] + [原始输入] → 冻结的LLM
为什么P-Tuning要多这一层?
1. 建模提示token间的依赖关系
- 单纯的Prompt Tuning假设提示向量是独立可训练的
- 但实际上,提示中的不同位置应该有关联
- 双向LSTM/MLP能捕捉提示token间的上下文关系
2. 更好的优化特性
- 直接优化离散的提示向量可能陷入局部最优
- 轻量级网络作为“优化器映射”,能提供更平滑的优化空间
- 相当于给提示优化加了一个可学习的预处理层
实际效果对比
| 维度 | Prompt Tuning | P-Tuning |
|---|---|---|
| 训练稳定性 | 较敏感 | 更稳定 |
| 小样本性能 | 一般 | 更好 |
| 长提示处理 | 直接扩展 | 通过编码器更好地整合信息 |
| 跨任务泛化 | 有限 | 更好(编码器学习到提示的通用结构) |
总结
P-Tuning多的一层本质上是一个提示优化器,它:
- 建模提示内部的依赖关系
- 提供更结构化的提示表示
- 提高参数效率和学习稳定性
是否值得这额外的复杂度,取决于具体任务、数据量和模型大小。对于复杂任务和小数据场景,P-Tuning的优势更明显;对于简单任务或超大模型,Prompt Tuning可能就足够了。
实战代码(Jupyter)
Step1 导包
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
import datasets
datasets.__version__
'4.5.0'
import transformers
transformers.__version__
'4.56.2'
import warnings
warnings.filterwarnings('ignore')
Step2 加载数据集
ds = load_dataset("json", data_dir="./alpaca_data_zh/")
ds = ds['train']
ds
Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 48818
})
ds[:3]
{'instruction': ['保持健康的三个提示。', '三原色是什么?', '描述原子的结构。'],
'input': ['', '', ''],
'output': ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。',
'三原色通常指的是红色、绿色和蓝色(RGB)。它们是通过加色混合原理创建色彩的三种基础颜色。在以发光为基础的显示设备中(如电视、计算机显示器、智能手机和平板电脑显示屏), 三原色可混合产生大量色彩。其中红色和绿色可以混合生成黄色,红色和蓝色可以混合生成品红色,蓝色和绿色可以混合生成青色。当红色、绿色和蓝色按相等比例混合时,可以产生白色或灰色。\n\n此外,在印刷和绘画中,三原色指的是以颜料为基础的红、黄和蓝颜色(RYB)。这三种颜色用以通过减色混合原理来创建色彩。不过,三原色的具体定义并不唯一,不同的颜色系统可能会采用不同的三原色。',
'原子是物质的基本单位,它由三种基本粒子组成:质子、中子和电子。质子和中子形成原子核,位于原子中心,核外的电子围绕着原子核运动。\n\n原子结构具有层次性。原子核中,质子带正电,中子不带电(中性)。原子核非常小且致密,占据了原子总质量的绝大部分。电子带负电,通常围绕核运动,形成若干层次,称为壳层或电子层。电子数量与质子数量相等,使原子呈电中性。\n\n电子在每个壳层中都呈规律分布,并且不同壳层所能容纳的电子数也不同。在最里面的壳层一般只能容纳2个电子,其次一层最多可容纳8个电子,再往外的壳层可容纳的电子数逐层递增。\n\n原子核主要受到两种相互作用力的影响:强力和电磁力。强力的作用范围非常小,主要限制在原子核内,具有极强的吸引作用,使核子(质子和中子)紧密结合在一起。电磁力的作用范围较大,主要通过核外的电子与原子核相互作用,发挥作用。\n\n这就是原子的基本结构。原子内部结构复杂多样,不同元素的原子核中质子、中子数量不同,核外电子排布分布也不同,形成了丰富多彩的化学世界。']}
Step3 数据集预处理
tokenizer = AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")
tokenizer
BloomTokenizerFast(name_or_path='Langboat/bloom-1b4-zh', vocab_size=46145, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=False, added_tokens_decoder={
0: AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
1: AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
3: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
def process_func(example):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: "+ example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
response = tokenizer(example["output"] + tokenizer.eos_token)
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds
Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 48818
})
tokenizer.decode(tokenized_ds[2]["input_ids"])
'Human: 描述原子的结构。\n\nAssistant: 原子是物质的基本单位,它由三种基本粒子组成:质子、中子和电子。质子和中子形成原子核,位于原子中心,核外的电子围绕着原子核运动。\n\n原子结构具有层次性。原子核中,质子带正电,中子不带电(中性)。原子核非常小且致密,占据了原子总质量的绝大部分。电子带负电,通常围绕核运动,形成若干层次,称为壳层或电子层。电子数量与质子数量相等,使原子呈电中性。\n\n电子在每个壳层中都呈规律分布,并且不同壳层所能容纳的电子数也不同。在最里面的壳层一般只能容纳2个电子,其次一层最多可容纳8个电子,再往外的壳层可容纳的电子数逐层递增。\n\n原子核主要受到两种相互作用力的影响:强力和电磁力。强力的作用范围非常小,主要限制在原子核内,具有极强的吸引作用,使核子(质子和中子)紧密结合在一起。电磁力的作用范围较大,主要通过核外的电子与原子核相互作用,发挥作用。\n\n这就是原子的'
tokenizer.decode(list(filter(lambda x: x!=-100, tokenized_ds[2]["labels"])))
'原子是物质的基本单位,它由三种基本粒子组成:质子、中子和电子。质子和中子形成原子核,位于原子中心,核外的电子围绕着原子核运动。\n\n原子结构具有层次性。原子核中,质子带正电,中子不带电(中性)。原子核非常小且致密,占据了原子总质量的绝大部分。电子带负电,通常围绕核运动,形成若干层次,称为壳层或电子层。电子数量与质子数量相等,使原子呈电中性。\n\n电子在每个壳层中都呈规律分布,并且不同壳层所能容纳的电子数也不同。在最里面的壳层一般只能容纳2个电子,其次一层最多可容纳8个电子,再往外的壳层可容纳的电子数逐层递增。\n\n原子核主要受到两种相互作用力的影响:强力和电磁力。强力的作用范围非常小,主要限制在原子核内,具有极强的吸引作用,使核子(质子和中子)紧密结合在一起。电磁力的作用范围较大,主要通过核外的电子与原子核相互作用,发挥作用。\n\n这就是原子的'
len(tokenized_ds[2]["input_ids"])
256
len(tokenized_ds[2]["labels"])
256
Step4 模型创建
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
model.device
device(type='cpu')
model
BloomForCausalLM(
(transformer): BloomModel(
(word_embeddings): Embedding(46145, 2048)
(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(h): ModuleList(
(0-23): 24 x BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
)
(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=2048, out_features=46145, bias=False)
)
sum(param.numel() for param in model.parameters())
1303111680
P-tuning
PEFT Step1 配置文件
import peft
peft.__version__
'0.18.1'
# conda install peft --channel conda-forge
from peft import PromptEncoderConfig, get_peft_model, TaskType, PromptEncoderReparameterizationType
config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=5,
#encoder_reparameterization_type=PromptEncoderReparameterizationType.LSTM,
#encoder_dropout=0.1, encoder_num_layers=5, encoder_hidden_size=1024
)
config
PromptEncoderConfig(task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, peft_type=<PeftType.P_TUNING: 'P_TUNING'>, auto_mapping=None, peft_version='0.18.1', base_model_name_or_path=None, revision=None, inference_mode=False, num_virtual_tokens=5, token_dim=None, num_transformer_submodules=None, num_attention_heads=None, num_layers=None, modules_to_save=None, encoder_reparameterization_type=<PromptEncoderReparameterizationType.MLP: 'MLP'>, encoder_hidden_size=None, encoder_num_layers=2, encoder_dropout=0.0)
PEFT Step2 创建模型
model = get_peft_model(model, config)
model
PeftModelForCausalLM(
(base_model): PeftModelForCausalLM(
(base_model): BloomForCausalLM(
(transformer): BloomModel(
(word_embeddings): Embedding(46145, 2048)
(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(h): ModuleList(
(0-23): 24 x BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
)
(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=2048, out_features=46145, bias=False)
)
(prompt_encoder): ModuleDict(
(default): PromptEncoder(
(embedding): Embedding(5, 2048)
(mlp_head): Sequential(
(0): Linear(in_features=2048, out_features=2048, bias=True)
(1): ReLU()
(2): Linear(in_features=2048, out_features=2048, bias=True)
(3): ReLU()
(4): Linear(in_features=2048, out_features=2048, bias=True)
)
)
)
(word_embeddings): Embedding(46145, 2048)
)
(word_embeddings): Embedding(46145, 2048)
)
config
PromptEncoderConfig(task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, peft_type=<PeftType.P_TUNING: 'P_TUNING'>, auto_mapping=None, peft_version='0.18.1', base_model_name_or_path=None, revision=None, inference_mode=False, num_virtual_tokens=5, token_dim=2048, num_transformer_submodules=1, num_attention_heads=16, num_layers=24, modules_to_save=None, encoder_reparameterization_type=<PromptEncoderReparameterizationType.MLP: 'MLP'>, encoder_hidden_size=2048, encoder_num_layers=2, encoder_dropout=0.0)
model.print_trainable_parameters()
trainable params: 12,599,296 || all params: 1,315,710,976 || trainable%: 0.9576
Step5 配置训练参数
args = TrainingArguments(
output_dir="./chatbot", # 输出文件夹存储模型的预测结果和模型文件checkpoints
per_device_train_batch_size=1, # 默认8, 对于训练的时候每个 GPU核或者CPU 上面对应的一个批次的样本数
gradient_accumulation_steps=8, # 默认1, 在执行反向传播/更新参数之前, 对应梯度计算累积了多少次
logging_steps=10, # 每隔10迭代落地一次日志
num_train_epochs=1 # 整体上数据集让模型学习多少遍
)
Step6 创建训练器
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
# 构建一个个批次数据所需要的
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True)
)
Step7 模型训练
trainer.train()
Step8 模型推理
加载训练好的 PEFT 模型
from peft import PeftModel
# 这里需要特别注意,传入的model参数对应的是原始的base模型,所以需要先重新加载一下原始模型
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh", low_cpu_mem_usage=True)
peft_model = PeftModel.from_pretrained(model=model, model_id="./checkpoint-500/")
peft_model.device
device(type='cpu')
# peft_model = peft_model.cuda()
准备输入数据
ipt = tokenizer("Human: {}\n{}".format("如何提高学习效率?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(model.device)
ipt
# 把model输出的response结果再次转为文本
# print(tokenizer.decode(peft_model.generate(**ipt, max_length=256, do_sample=True)[0], skip_special_tokens=True))
{'input_ids': tensor([[26283, 29, 28683, 5706, 7189, 12230, 1518, 189, 189, 4340,
17245, 29, 210]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
执行推理
# 把model输出的response结果再次转为文本
output = peft_model.generate(
input_ids=ipt["input_ids"],
attention_mask=ipt["attention_mask"],
max_length=256,
do_sample=True,
pad_token_id=tokenizer.pad_token_id # 显式指定 pad_token_id
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Human: 如何提高学习效率?
Assistant: 3.3、10K、20K后不 过,可以提高输出输出电阻值, 从而提高电路的 效率。 电子器件一般采用 桥型或 场效应管 构成的稳压二极管,它的稳压原理是输出电流经 结 饱和,而电路中的高负载不 稳定,由于输出电流不 稳、 极性偏转而使其 电源电压稳定输出。 其它稳压二极管 电阻值过低则 电流不够稳定而损坏,电阻值过 高等原因,会使稳压环 路的 阻抗 变化而使噪声增大。一般稳压 环 路的 阻抗 是10dB 以降左右

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)