OWL: Optimized Workforce Learning for General Multi-Agent Assistance in Real-World Task Automation翻译
基于大语言模型(LLM)的多智能体系统在自动化现实世界任务方面展现出巨大潜力,但由于其领域特定性,难以跨领域迁移。现有方法面临两大关键缺陷:应用于新领域时,需要对所有组件进行完全的架构重新设计和重新训练。我们提出了 **WORKFORCE**,一个分层多智能体框架,它通过模块化架构将策略规划与专门执行解耦,该架构包含:(i)一个与领域无关的 **Planner**,用于任务分解;(ii)一个 **
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
基于大语言模型(LLM)的多智能体系统在自动化现实世界任务方面展现出巨大潜力,但由于其领域特定性,难以跨领域迁移。现有方法面临两大关键缺陷:应用于新领域时,需要对所有组件进行完全的架构重新设计和重新训练。我们提出了 WORKFORCE,一个分层多智能体框架,它通过模块化架构将策略规划与专门执行解耦,该架构包含:(i)一个与领域无关的 Planner,用于任务分解;(ii)一个 Coordinator,用于子任务管理;以及(iii)具有领域特定工具调用能力的专用 Workers。这种解耦使得 WORKFORCE 在推理和训练阶段均能实现跨领域迁移:在推理阶段,WORKFORCE 通过添加或修改 Workers 无缝适应新领域;为了进行训练,我们引入了OPTIMIZED WORKFORCE LEARNING (OWL),它通过利用来自真实世界的反馈进行强化学习,优化一个与领域无关的 Planner,从而提高跨领域的泛化能力。为了验证我们的方法,我们在 GAIA 基准测试集上评估了 WORKFORCE,该基准测试集涵盖了各种真实的多领域智能体任务。实验结果表明,WORKFORCE达到了开源领域最先进的性能(69.70%),比 OpenAI 的 Deep Research 等商业系统高出2.34%。更值得注意的是,我们用 OWL 训练的 32B 模型达到了 52.73% 的准确率(+16.37%),并且在具有挑战性的任务上展现出了与 GPT-4o 相当的性能。总而言之,通过实现可扩展的泛化和模块化的领域迁移,我们的工作为下一代通用人工智能助手奠定了基础。
1.Introduction
大语言模型(LLM)经历了快速发展时期,从简单的文本预测器演变为能够进行规划、工具使用和多步骤推理的强大自主 Agent。近年来,多 Agent 系统(MAS)已成为处理复杂现实世界任务的一种很有前景的方法,证明将任务分配给专门的 Agent 可以提高性能。
尽管当前的多 Agent 系统(MAS)已取得令人瞩目的成果,但它们的设计通常具有领域特定性,严重限制了跨领域迁移能力。这一缺陷体现在两个方面:(i)首先,在推理方面,将系统部署到新领域通常需要完全重新设计;例如,MetaGPT 依赖于针对软件工程定制的标准操作程序,这阻碍了其扩展到其他领域。(ii)其次,在训练方面,现有工作通常对每个智能体进行优化。例如,MALT 遵循固定的生成器-验证器-精炼器流程,需要对每个组件进行单独训练。因此,迁移此类系统需要重新训练整个智能体集合,从而显著降低了灵活性。这些缺点凸显了构建通用模块化多智能体架构的必要性,该架构能够以最小的重新训练和重新设计快速适应不同的领域。
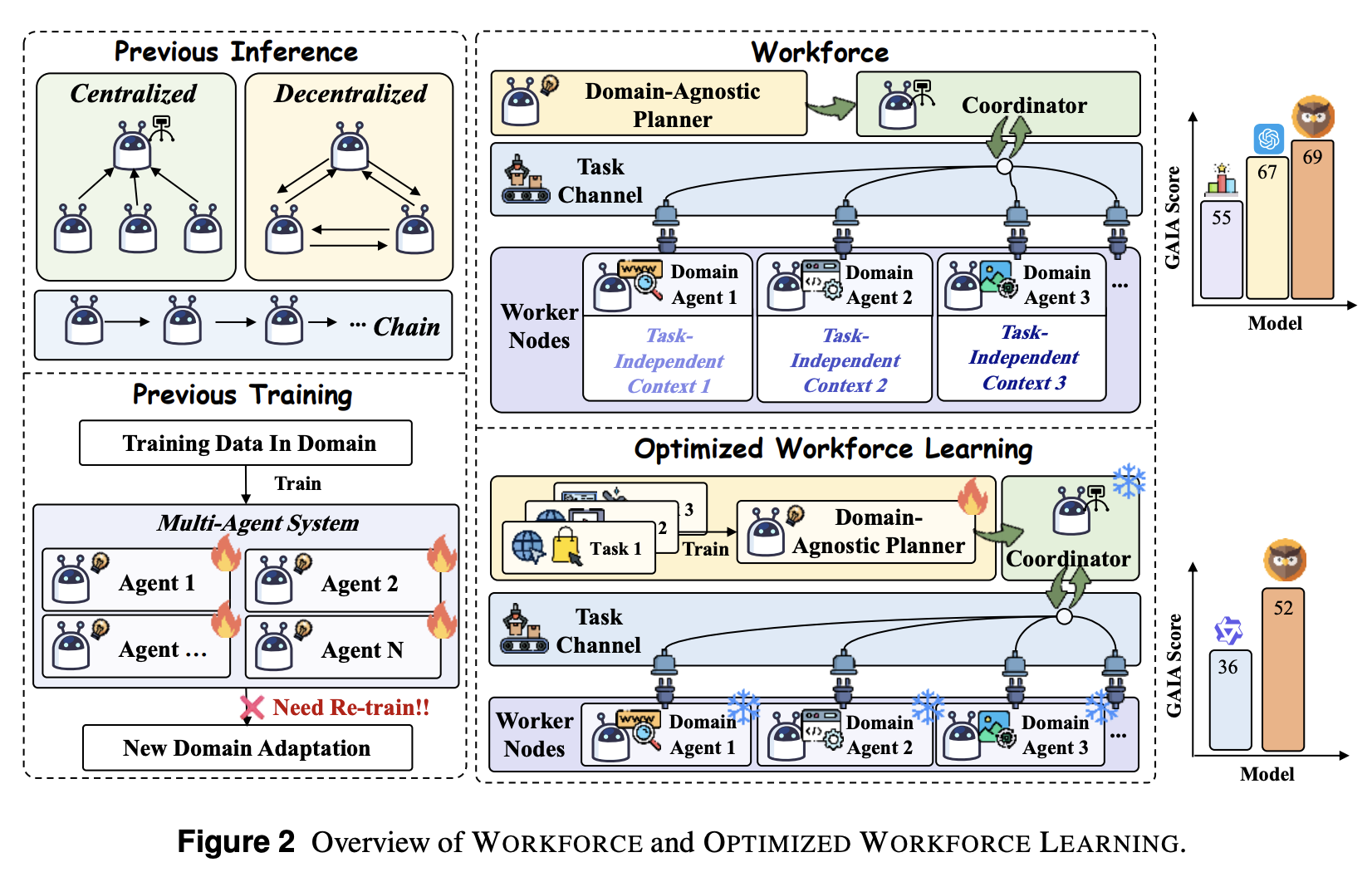
基于以上观察,我们首先引入 WORKFORCE,这是一个分层多智能体推理框架,它将策略规划与特定领域的执行解耦。如图 2 所示,这种模块化设计包含三个核心组件:(i)领域无关 Planner:基于高层目标生成抽象的任务分解。(ii)Coordinator:将子任务分配给合适的智能体。(iii)领域特定智能体 Workers:一组专门的智能体,负责调用工具来完成每个子任务。这些组件的解耦实现了即插即用的可扩展性,使得 WORKFORCE 可以通过简单地替换或添加智能体 Worker 节点无缝适应新的领域。此外,这种模块化架构还支持 OPTIMIZED WORKFORCE LEARNING (OWL),这是一种新型的多智能体训练范式。OWL 专注于通过训练一个可泛化的领域无关 Planner 来增强多智能体系统的跨领域迁移能力。具体来说,我们采用两阶段训练策略:首先使用有监督微调 (SFT) 进行 Planner 初始化,然后使用强化学习进一步增强模型的泛化能力。
我们在 GAIA 基准测试集上评估了我们的方法。GAIA 是一个严格的通用型 AI 助手测试套件,涵盖多个领域,并要求进行多模态推理、代码执行和实时网络搜索。WORKFORCE 的准确率达到了 69.70%,超过了 OpenAI 的 Deep Research (55.15%) 等强大的商业专有基线模型。为了验证 OWL 的有效性,我们进一步使用自定义训练数据集(未使用任何 GAIA 数据)对由 Qwen2.5-32B-Instruct 初始化的策略 Planner 进行了后训练。训练后,该模型的得分达到了 52.73% (+16.37%),优于 GPT-4o-mini (47.27%) 和 Qwen2.5-72B-Instruct 等模型。这些结果证实,我们的模块化训练策略能够跨领域泛化,且只需极少的重新训练。
我们的主要贡献体现在四个方面:
- A New Flexible and Modular Multi-Agent Architecture。我们提出的 WORKFORCE 在推理和训练方面都具有模块化和可扩展性,增强了跨领域迁移能力。
- State-of-the-Art Performance。我们的系统在 GAIA 基准测试中达到了开源领域的最先进水平,甚至超越了 OpenAI 的 Deep Research 等专有系统。
- Efficient and Effective Training Paradigm。OWL 显著增强了模型能力,同时开销极小,使 Qwen2.5-32B-Instruct 能够实现 16.37% 的性能提升,并在具有挑战性的任务上达到与 GPT-4o 相当的性能。
- Fully Open-Source。我们发布所有代码、模型和数据,以支持开放研究。
2.Preliminary
基于大语言模型(LLM)的智能体是能够在各种环境中感知、推理和行动的自主系统。这些智能体在一个 perception-reasoning-action 循环中运行,它们观察环境,通过语言模型处理信息,确定适当的行动,并执行这些行动以实现目标。
多智能体系统扩展了这一范式,使多个基于大语言模型(LLM)的智能体能够协作完成复杂任务。诸如 CAMEL 和 MetaGPT 等框架已证明,在需要不同专业知识的任务上,协作方法可以优于单智能体系统。然而,现有的多智能体框架通常受限于特定领域的设计,从而限制了其更广泛的适用性。本文旨在通过策略规划和任务执行的解耦,开发可扩展且通用的多智能体框架 WORKFORCE,从而实现跨不同领域的高效协调。(完整的形式化描述见附录 C,更多相关工作见第 6 节。)
通用型人工智能助手最初由 GAIA 提出。这些系统旨在处理跨多个领域和模态的各种复杂任务。作为首个评估通用型人工智能助手的问答基准测试,GAIA 旨在使基于 LLM 的智能体能够在真实世界环境中收集信息,并测试其包括多模态理解、网页浏览、推理和复杂问题解决在内的基本能力。近年来,众多公司发布了通用型人工智能助手产品(例如 OpenAI 的 Deep Research)。虽然开源框架取得了显著进展(例如 Huggingface 的 Open Deep Research),但它们仍然落后于商业解决方案。本文旨在弥合开源和商业专有智能体框架之间的差距。我们提出的 WORKFORCE 的性能比 OpenAI 的 Deep Research 高出 2.34%,而我们的训练方法 OWL 则显著提升了 Qwen2.5-32B-Instruct 的性能,提升幅度达 16.37%。
3.Multi-Agent Inference: WORKFORCE
3.1 WORKFORCE
Motivation。当代多智能体系统受限于领域特定性和架构刚性,每个新的应用领域都需要进行完全的重新设计和训练。我们提出的 WORKFORCE 通过模块化架构解决了这一根本性挑战,特别是将领域无关的规划与领域特定的执行分离。有关 WORKFORCE 的更多详细信息,请参见附录 D。
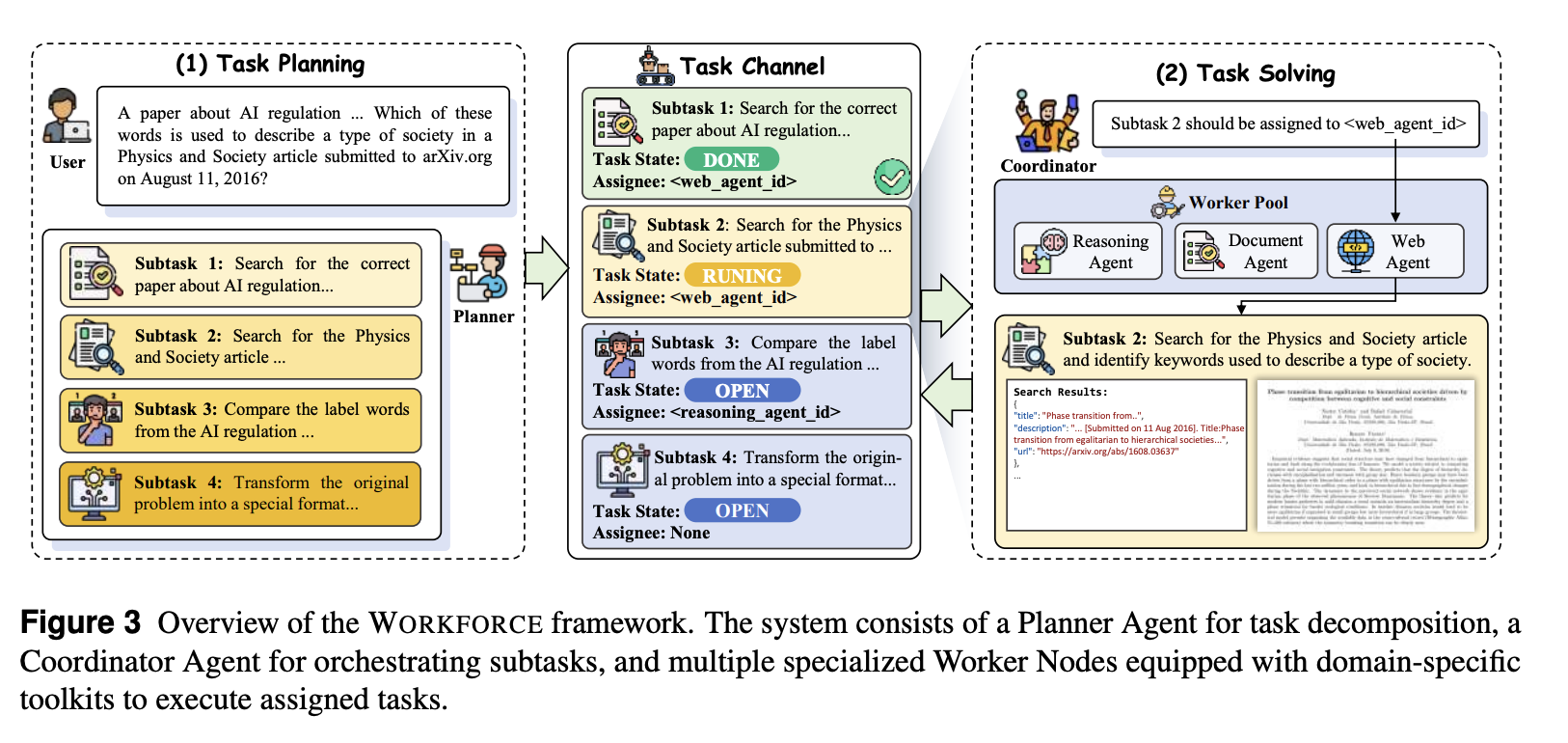
Architecture。如图 3 所示,WORKFORCE 由三个核心组件构成:(i) Planner Agent 分析传入的任务,并根据 worker 能力注册表将其分解为子任务;(ii) Coordinator Agent 作为中央编排机制,管理 worker 分配和任务依赖关系,并整合中间结果;(iii) Worker Nodes 由一个或多个配备特定能力和工具包的专用 Agent 组成,这些 Agent 执行分配的子任务并提交结果。这种模块化架构提供了固有的灵活性,只需修改 Worker 节点,即可在保持其核心规划和协调机制不变的情况下,将该框架部署到各种不同的应用程序中。
Communication Mechanism。WORKFORCE 的通信通过一个共享的 task channel 进行,该频道充当中心枢纽。coordinator 将任务和分配发布到此频道。任务完成后,worker 仅将最终结果发布回频道,而工具调用的详细执行上下文则保留在每个子任务的范围内。这为每个 worker 维护了一个清晰的上下文,他们只能访问当前子任务的详细信息和之前子任务的简要结果。这种集中式方法简化了系统管理,并通过消除 Agent 之间的直接消息传递来增强了可扩展性。
Task Flow。WORKFORCE 中的任务处理工作流程遵循结构化的流水线:(i)Planner 分析传入的总体任务,然后根据可用 Worker 的能力和总体任务的复杂性将其分解为一组子任务;(ii)Coordinator 评估可用工作节点的能力,并据此调度子任务;(iii)Worker 节点使用其专用工具执行分配的子任务;(iv)Worker 节点的结果发布到共享任务通道;(v)Coordinator 管理任务依赖关系并整合结果,最终将其转发给 Planner;(vi)Planner 分析每个子任务的结果并综合最终输出。
Replanning Mechanism。在任务执行过程中,Worker 会自行评估所分配的子任务是否失败。当 Worker 判定某个子任务失败时,它会将失败信息发布到任务通道。任务通道随后会检测到此失败,并提示 Planner 根据反馈信息生成新的子任务。这种重规划机制能够通过动态调整其方法以适应日益复杂的任务,从而实现测试时的扩展性,这在第 5 节中得到了验证。
3.2 Generalist Multi-Agent Assistance
为了构建一个能够处理各种现实世界任务的通用型多智能体助手,我们实例化了 WORKFORCE,其中包含三个 worker 智能体,每个智能体都配备了特定领域的工具包:(i)Web Agent,能够执行网络搜索、提取网页内容并模拟浏览器操作;(ii)Document Processing Agent,旨在处理文档和多模态数据,包括文本、图像、音频、视频、电子表格和各种文件格式;以及(iii)Reasoning/Coding Agent,负责处理分析推理和代码执行任务。worker 智能体及其对应工具包的详细信息请参见附录 D.3。
3.3 Experiments
Baselines。我们选择了一套全面的基准系统,并将其分为四大类:(i)Proprietary frameworks,用于确定商业性能的上限,包括 OpenAI 的 Deep Research、h2oGPTe Agent 等商业智能系统。(ii)Open-source frameworks,用于展现社区的进步,包括 HuggingFace 的 Open Deep Research、Trase Agent 等强大的基准系统。(iii)采用多步骤工具调用的 Single Agent 基准系统。(iv)Role Playing 系统,由两个智能体(用户智能体和辅助智能体)组成,它们通过结构化对话协作完成任务。需要注意的是,为了控制实验变量,单智能体基准系统和角色扮演系统均使用与 WORKFORCE 相同的工具集。
Implementation Details。在我们的实现中,所有模型均通过 API 访问,无需使用 GPU。为确保结果可复现,我们将 API 推理配置为贪婪解码。默认的重规划阈值设置为 2。在评估方法方面,我们对 GPT-4o 的 WORKFORCE 数据集采用 pass@3 采样,对 Claude-3.7-sonnet 的 WORKFORCE 数据集采用 pass@1 采样。由于部分 GAIA 数据集的 golden 答案已在网上泄露,我们屏蔽了部分网站以确保公平比较。
Main Results。从表1可以得出以下几个结论:
- Workforce 在开源框架中实现了最先进的性能。我们的 Workforce 准确率达到 69.70%,在所有难度级别上均持续优于以往的开源框架。在严格控制的设置下,使用相同的模型和工具包,我们基于 GPT-4o 的 Workforce 准确率达到 60.61%,比单智能体高出 23.03%,比多智能体基线角色扮演高出 6.06%。
- Workforce 的性能与商业专有框架相比毫不逊色,甚至更胜一筹。虽然之前的开源框架与闭源框架相比存在显著的性能差距,但 Workforce 大大缩小了这一差距。据我们所知,Workforce 是首个超越 OpenAI Deep Research 的开源系统,性能提升达 2.34%,并且以 1.89% 的优势超越 Langfun Agent v2.1,创下新的 Level 1 最佳纪录。
4.Multi-Agent Training: OPTIMIZED WORKFORCE LEARNING
4.1 Training Strategy
Motivation。WORKFORCE 架构将与领域无关的规划与特定领域的执行分离,使我们能够通过简单地添加或替换 worker 节点来适应新的领域,同时保持核心规划机制不变。我们引入了 OPTIMIZED WORKFORCE LEARNING (OWL),它专注于增强一个能够处理各种真实世界场景的通用规划 Agent。这种设计显著降低了训练开销,因为只有规划 Agent 需要进行密集优化,而 worker 节点只需进行最小的调整即可利用现有的特定领域工具。这种“稳定核心,可变外围”的方法能够实现跨领域的高效知识迁移,并且无需为新的应用程序重新训练整个系统,从而在保持性能一致性的同时大幅降低计算成本。
Implementation。更具体地说,我们采用两阶段训练范式:(i)在第一阶段,我们使用有监督微调(SFT)初始化 Planner Agent,使其具备从专家数据中提取的基本任务分解技能。(ii)随后,我们利用强化学习进一步优化经 SFT 初始化的 Planner Agent。我们选择直接偏好优化(DPO)作为优化算法,因为该阶段能够提升分解策略的质量,使其超越简单的模仿演示,从而使 Planner Agent 发展出更复杂的决策能力。
4.2 Task Curriculum
Motivation。WORKFORCE 的核心创新在于其架构上将领域无关的规划与领域特定的执行分离。为了使这种设计有效,Planner Agent 必须具备跨不同问题领域的强大泛化能力。这就带来了一个根本性的矛盾:Planner Agent 必须同时保持对不同领域的深刻理解,并避免过度拟合特定的任务模式或领域。为了应对这一挑战,我们开发了一套策略性平衡的任务课程,该课程有意涵盖通用智能所需的多个能力维度。我们的课程设计遵循两个关键原则:(i)能力覆盖:使 Planner Agent 接触不同的推理模式和问题结构。(ii)迁移学习:优先培养能够跨领域迁移的互补认知技能,而非领域特定知识。
Implementation。更具体地说,如表2所示,我们精心挑选了四个数据集,每个数据集都针对不同的智能体认知能力维度:(i)HotpotQA:该数据集要求基于在线信息进行多跳推理,挑战 Planner 协调复杂的信息检索行为。(ii)WikiTableQuestions:该数据集要求 Planner 制定策略来导航、筛选和处理表格信息。(iii)Math-related Problems:这是一个精心策划的数学问题集,需要通过推理或编程来解决,涵盖各种数学领域。这些问题有助于 Planner 培养逻辑推理和计算问题解决能力。(iv)Infinity-MM:作为一个多模态数据集,Infinity-MM 挑战 Planner 协调多模态信息处理,包括视觉、文本和结构化数据。
4.3 Trajectory Synthesis
Supervised Fine-tuning。我们采用 WORKFORCE 方法(§3.1)结合 GPT-4o-mini 来合成专家轨迹,这些轨迹由 Planner 生成的子任务和 worker 生成的执行轨迹组成。为了过滤掉低质量数据,我们对不同的数据集应用了不同的评估指标:对于 HotpotQA 和 WikiTableQuestions,我们使用了准确率指标;对于 Infinity-MM,我们使用了文本余弦相似度,并将真实答案与生成答案之间的阈值设为 0.7;对于数学相关问题,我们实现了 LLM 作为评判器,以比较真实答案和 worker 生成的解决方案。最终,如表 2 和表 6 所示,我们获得了 1599 条经过过滤的轨迹用于有监督微调,每条轨迹平均包含 3.41 个子任务。
Reinforcement Learning。我们使用 SFT 初始化的模型为 DPO 生成成对轨迹。具体来说,对于我们收集的数据集中的每个问题,我们生成 n=4n=4n=4 条不同的轨迹。这些生成轨迹的评估方法与SFT阶段相同。然后,我们基于评估结果,从每个问题生成的 nnn 条轨迹中构建偏好对。对于数学、HotpotQA和WikiTableQuestions任务,正确的轨迹被标记为“chosen”,错误的答案被标记为“rejected”。对于Infinity-MM 数据集,最终文本余弦相似度得分超过与SFT阶段相同阈值(0.7)的轨迹被标记为“chosen”,低于该阈值的轨迹被标记为“rejected”。如表2所示,我们收集了 1009 对经过筛选的轨迹。
4.4 Experiments
Baselines。我们将我们的方法与多个专有和开源模型作为基准进行比较,包括 GPT-4o 系列、Claude-3.7-Sonnet 和 Qwen2.5 系列。这些模型代表了不同规模和架构下语言模型能力的当前最先进水平。
Implementation Details。我们的模型训练在配备 8 个 NVIDIA H100 GPU 的计算集群上进行。我们使用 LlamaFactory 框架来管理和执行训练过程。具体来说,对于我们训练的所有模型,输入序列的最大长度被截断为 32,768 个 token,学习率设置为 10−510^{-5}10−5。所有模型均训练了两个 epoch。为了优化内存使用和训练效率,我们使用了 bfloat16 混合精度训练。有效 batch-size 为 12,这是通过每个设备 1 个 batch size 并结合 12 个梯度累积步骤实现的。
Main Results。表3揭示了多项重要发现:
- OWL 显著提升了 Planner 的性能,使开源模型能够超越专有模型。经过 OWL 训练的 Qwen2.5-32B-Instruct 模型表现出色,性能提升高达16.37%。OWL使开源模型的性能达到 52.73%,超越了专有模型 GPT-4o-mini(47.27%)和规模更大的 Qwen2.5-72B-Instruct(49.09%)。虽然 GPT-4o(60.61%)仍然保持优势,但我们的 OWL 训练模型在更具挑战性的3级任务上达到了与GPT-4o(26.92%)相当的性能。
- 强化学习显著提升了 Planner 的泛化能力。虽然单独使用有监督微调(SFT)可以提高简单任务(1级和2级)的性能,但在最复杂的任务(3级)上却出现了性能下降,下降幅度达3.85%。然而,当与 DPO 结合使用时,我们的方法不仅恢复了性能,而且在所有难度级别上都显著优于基础模型,在3级任务上的性能提升高达7.69%。
Ablation Study。我们评估了轨迹过滤对模型性能的影响。
如图 3a 所示,基于过滤轨迹训练的模型始终优于基于未过滤数据训练的模型,这表明对于有效的 Planner 训练而言,数据质量比数据数量更为重要。
5.Analysis
6.Related Work

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)