LangChain--AI大模型(一)
介绍LangChain
为什么要用LangChain?
LangChain 通过标准接口(如模型、嵌入、向量存储等)帮助开发者构建由大型语言模型(LLM)驱动的应用程序。
使用 LangChain 用于:
- 实时数据增强。轻松将大型语言模型连接到多样化的数据源和外部/内部系统,利用LangChain庞大的集成库,涵盖模型提供者、工具、向量存储器、检索器等。
- 模型互作性。在工程团队不断试验时,不断更换型号,以找到最适合你应用需求的方案。随着行业前沿的发展,请迅速适应——LangChain的抽象设计让你保持前进且不失去动力。
- 快速原型制作。利用LangChain模块化、基于组件的架构快速构建和迭代LLM应用。无需从头重建即可测试不同方法和工作流,加速开发周期。
- 具备生产准备的功能。通过集成如LangSmith部署可靠应用,支持监控、评估和调试。利用经过实战验证的模式和最佳实践自信地扩展。
- 充满活力的社区和生态系统。利用丰富的集成、模板和社区贡献组件的生态系统。通过活跃的开源社区,享受持续改进并保持对最新AI发展的了解。
- 灵活的抽象层。在适合你需求的抽象层面工作——从快速起步的高级链条到细致控制的低级组件。LangChain 随着应用的复杂性而增长。
LangChain 生态系统
虽然 LangChain 框架可以独立使用,但它也能无缝集成任何 LangChain 产品,为开发者在构建 LLM 应用时提供完整的工具套件。
为了提升你的大型语言模型应用开发,可以将LangChain与以下工具搭配使用:
- 深度代理(新!)——构建能够规划、使用子代理并利用文件系统处理复杂任务的代理
- LangGraph——构建能够可靠处理复杂任务的代理,使用LangGraph,我们的底层代理编排框架。LangGraph提供可定制架构、长期记忆和人机作流,并受到LinkedIn、Uber、Klarna和GitLab等公司的生产信任。
- 集成——LangChain集成列表,包括聊天与嵌入模型、工具包等
- LangSmith——对智能体评估和可观察性很有帮助。调试表现不佳的大型语言模型应用运行,评估智能体轨迹,提高生产环境的可见性,并随着时间提升性能。
- LangSmith 部署——通过专门构建的部署平台轻松部署和扩展代理,支持长期运行的有状态工作流程。发现、重用、配置并在团队间共享代理,并通过 LangSmith Studio 快速迭代视觉原型。
有哪些大模型应用开发框架呢?
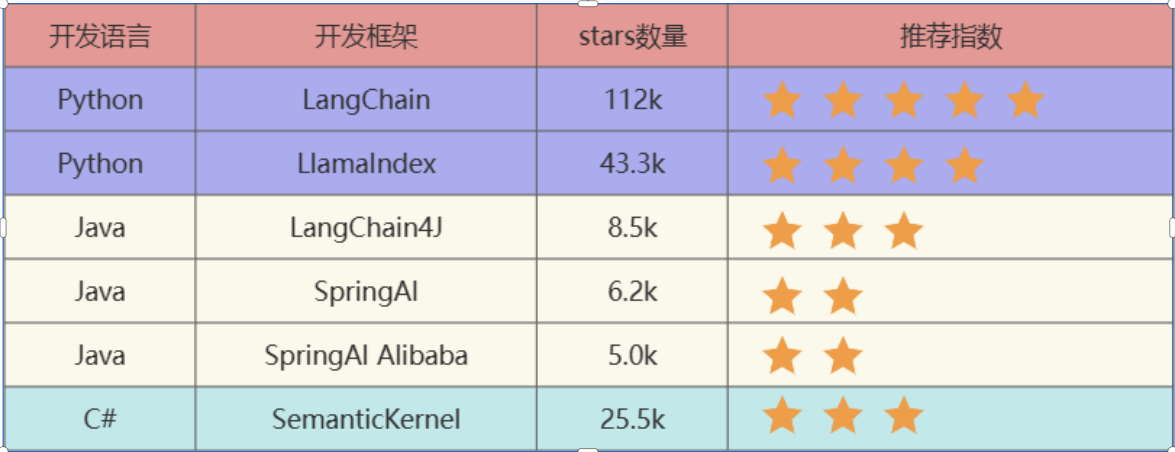
LangChain: 这些工具里出现最早、最成熟的,适合复杂任务分解和单智能体应用.
LlamaIndex: 专注于高效的索引和检索,适合 RAG 场景。(注意不是Meta开发的)
LangChain4J: LangChain还出了Java,Javascript两个语言的版本.
SpringAI/SpringAI Alibaba: 有待进一步成熟,此外只是简单的对于一些接口进行了封装.
SemanticKernel: 也称为sk,微软推出的,对于C#同学来说,那就是5颗星.
LangChain的使用场景
学完LangChain,如下类型的项目,大家都可以实现:
| 项目名称 | 技术点 | 难度 |
| 文档回答助手 |
Prompt + Embedding + RetrievalQA |
⭐⭐ |
|
智能日程规划助手 |
Agent + Tool + Memory |
⭐⭐⭐ |
|
LLM+数据库问答 |
SQLDatabaseToolkit + Agent |
⭐⭐⭐⭐ |
|
多模型路由对话系统 |
RouterChain + 多 LLM |
⭐⭐⭐⭐ |
|
互联网智能客服 |
ConversationChain + RAG +Agent |
⭐⭐⭐⭐⭐ |
|
企业知识库助手(RAG + 本地模型) |
VectorDB + LLM + Streamlit |
⭐⭐⭐⭐⭐ |
LangChain资料介绍
官网地址:https://www.langchain.com/langchain
官网文档:https://python.langchain.com/docs/introduction/
API文档:https://python.langchain.com/api_reference/
github地址:https://github.com/langchain-ai/langchain
模型调用的分类
模型调用的主要方法及参数
相关方法及属性:
OpenAI(...) / ChatOpenAI(...) :创建一个模型对象(非对话类/对话类)
model.invoke(xxx) :执行调用,将用户输入发送给模型
.content :提取模型返回的实际文本内容
必须设置的参数:
base_url :大模型 API 服务的根地址
api_key :用于身份验证的密钥,由大模型服务商(如 OpenAI、百度千帆)提供
model/model_name :指定要调用的具体大模型名称(如 gpt-4-turbo 、 ERNIE-3.5-8K 等)
其它参数:
temperature :温度,控制生成文本的“随机性”,取值范围为0~1。
值越低 → 输出越确定、保守(适合事实回答)
值越高 → 输出越多样、有创意(适合创意写作)
通常,根据需要设置如下:
精确模式(0.5或更低):生成的文本更加安全可靠,但可能缺乏创意和多样性。
平衡模式(通常是0.8):生成的文本通常既有一定的多样性,又能保持较好的连贯性和准确
性。
创意模式(通常是1):生成的文本更有创意,但也更容易出现语法错误或不合逻辑的内容。
max_tokens :限制生成文本的最大长度,防止输出过长。
Token是什么?
基本单位 : 大模型处理文本的最小单位是token(相当于自然语言中的词或字),输出时逐个token
依次生成。
收费依据 :大语言模型(LLM)通常也是以token的数量作为其计量(或收费)的依据。
1个Token≈1-1.8个汉字,1个Token≈3-4个英文字母
Token与字符转化的可视化工具:
OpenAI提供:https://platform.openai.com/tokenizer
百度智能云提供:https://console.bce.baidu.com/support/#/tokenizer
max_tokens设置建议:
客服短回复:128-256。比如:生成一句客服回复(如“订单已发货,预计明天送达”)
常规对话、多轮对话:512-1024
长内容生成:1024-4096。比如:生成一篇产品说明书(包含功能、使用方法等结构)
模型调用推荐平台:closeai
这里推荐使用的平台:
考虑到OpenAI等模型在国内访问及充值的不便,大家可以使用CloseAI网站注册和充值, 具体费用自理 。
https://www.closeai-asia.com
模型调用的三种方式
硬编码方式
调用对话模型
import os
import dotenv
from langchain_openai import ChatOpenAI
# 调用对话模型
chat_model = ChatOpenAI(
# 必须要设置的三个参数
model_name='gpt-4o-mini', # 默认使用的是gpt-3.5-turbo模型
base_url='https://api.openai-proxy.org/v1',
api_key='sk-8d××××××××××××××××××××××××××××××××××××',
)
# 调用模型
response = chat_model.invoke("什么是langchain?")
# 查看响应的文本
print(response.content)调用非对话模型
import os
import dotenv
from langchain_openai import OpenAI
# 调用非对话模型
chat_model = OpenAI(
# 必须要设置的三个参数
model_name='gpt-4o-mini', # 默认使用的是gpt-3.5-turbo模型
base_url='https://api.openai-proxy.org/v1',
api_key='sk-8d××××××××××××××××××××××××××××××××××××',
)
# 调用模型
response = chat_model.invoke("什么是langchain?")
# 查看响应的文本
print(response)环境变量方式(推荐)
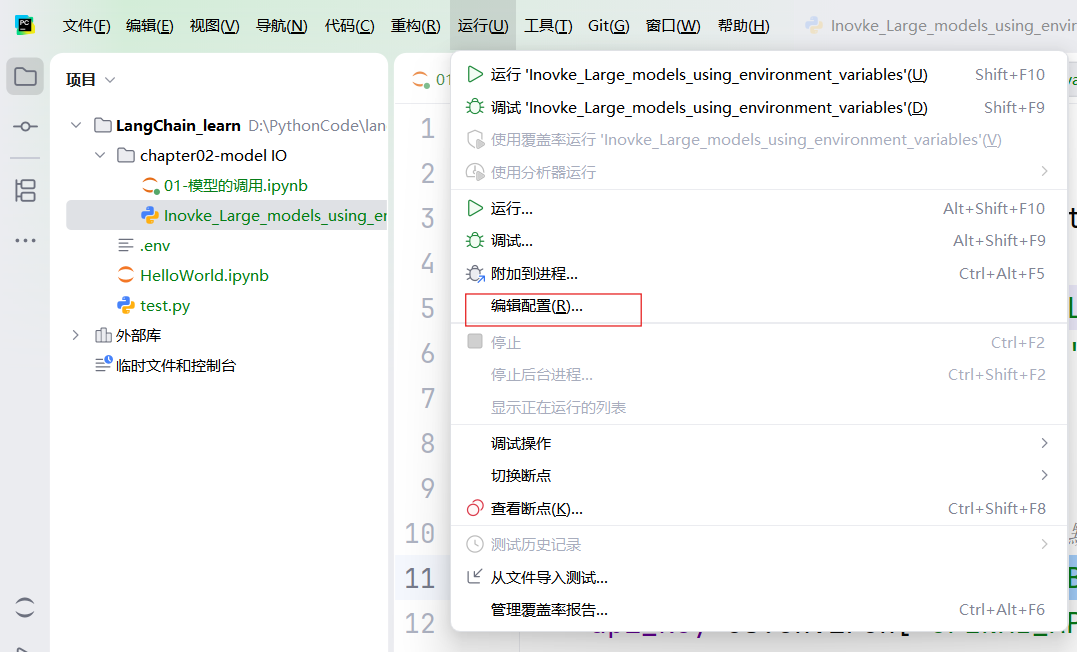
第一步:
在运行中找到编辑配置:
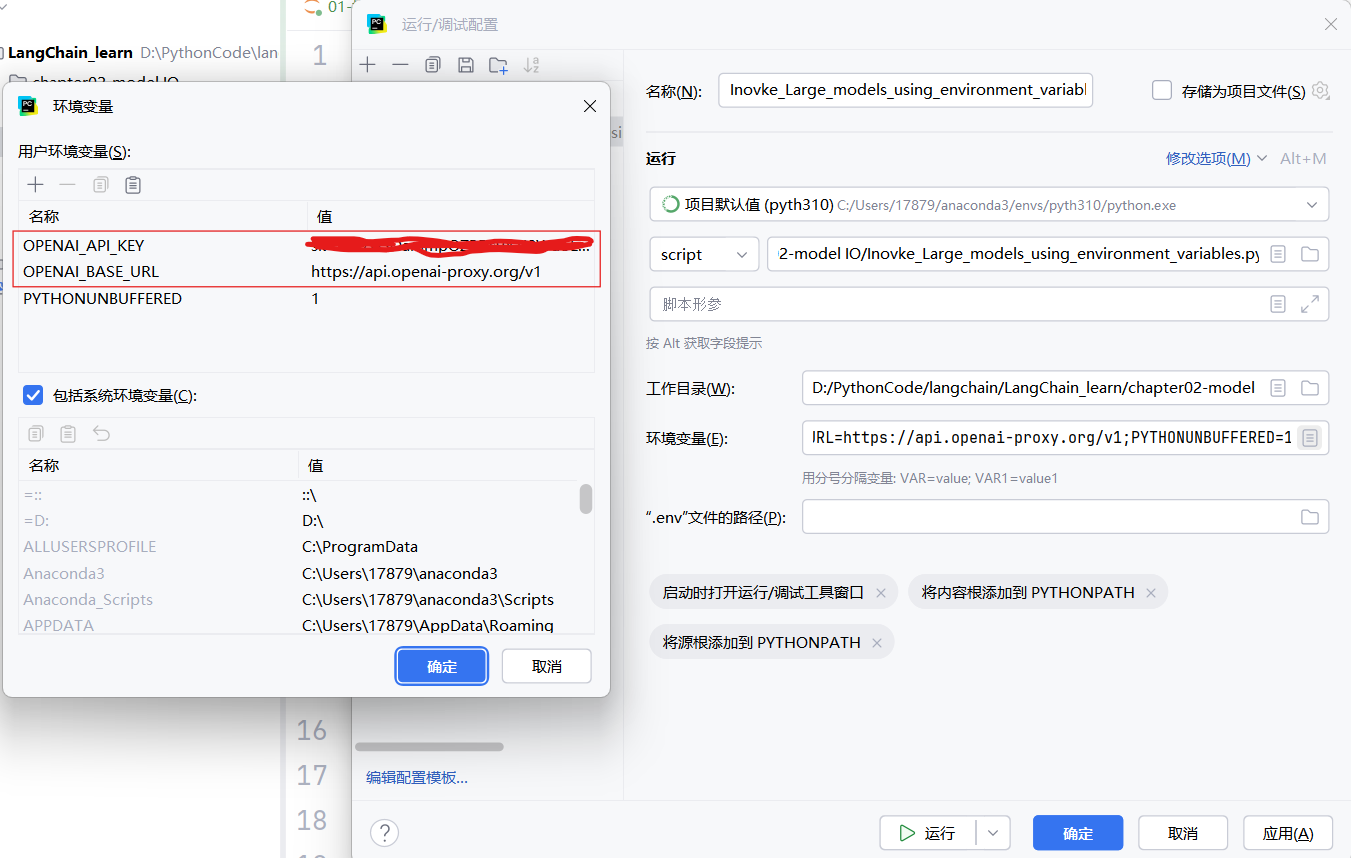
第二步:
添加OPEN_API_KEY和OPEN_BASE_URL两个环境变量:
运行代码:
import os
import dotenv
from langchain_openai import ChatOpenAI
print(os.environ['OPENAI_BASE_URL'])
print(os.environ['OPENAI_API_KEY'])
# 调用对话模型
chat_model = ChatOpenAI(
# 必须要设置的三个参数
model_name='gpt-4o-mini', # 默 认使用的是gpt-3.5-turbo模型
base_url=os.environ['OPENAI_BASE_URL'],
api_key=os.environ['OPENAI_API_KEY'],
)
# 调用模型
response = chat_model.invoke("什么是langchain?")
# 查看响应的文本
print(response.content)配置文件的方式
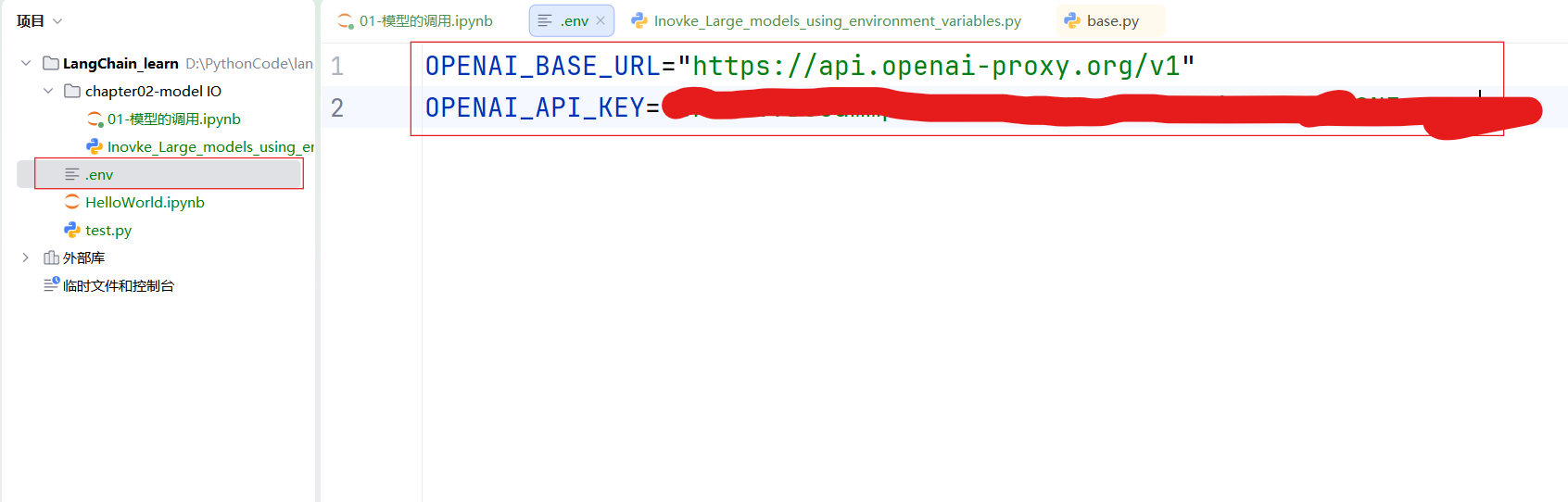
创建一个.env的文件,添加OPEN_API_KEY和OPEN_BASE_URL两个环境变量,然后通过编译器调用该文件:
运行代码:
import os
import dotenv
from langchain_openai import ChatOpenAI
# 调用对话模型
chat_model = ChatOpenAI(
# 必须要设置的三个参数
model_name='gpt-4o-mini', # 默认使用的是gpt-3.5-turbo模型
base_url=os.environ['OPENAI_BASE_URL'],
api_key=os.environ['OPENAI_API_KEY'],
)
# 调用模型
response = chat_model.invoke("什么是langchain?")
# 查看响应的文本
print(response.content)小结
| 方式 | 安全性 | 持久性 | 适用场景 |
| 硬编码 |
⚠ 低 |
❌ 临时 |
本地快速测试 |
|
环境变量 |
✅ 中 |
⚠ 会话级 |
短期开发调试 |
|
.env 配置文件 |
✅✅ 高 |
✅ 永久 |
生产环境、团队协作 |
使用各个平台的API调用大模型
OpenAI的方式
调用非对话模型
from openai import OpenAI
# 从环境变量读取API密钥(推荐安全存储)
client = OpenAI(api_key="sk-×××××××××××××××××××××××××××××××××",
#填写自己的api-key
base_url="https://api.openai-proxy.org/v1") #通过代码示例获取
# 调用Completion接口
response = client.completions.create(
model="gpt-3.5-turbo-instruct", # 非对话模型
prompt="请将以下英文翻译成中文:\n'Artificial intelligence will reshape the future.'",
max_tokens=100, # 生成文本最大长度
temperature=0.7, # 控制随机性
)
# 提取结果
print(response.choices[0].text.strip())调用对话模型(推荐)
from openai import OpenAI
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "我是一位乐于助人的AI智能小助手"},
{"role": "user", "content": "你好,请你介绍一下你自己。"}
]
)
print(response.choices[0])百度千帆平台
链接:https://cloud.baidu.com/doc/qianfan-docs/s/Mm8r1mejk
使用OpenAI的方式
from openai import OpenAI
import os
import dotenv
dotenv.load_dotenv()
# 初始化OpenAI客户端
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
messages = [{"role": "user", "content": "你是谁"}]
completion = client.chat.completions.create(
model="deepseek-v3.2",
messages=messages,
# 通过 extra_body 设置 enable_thinking 开启思考模式
extra_body={"enable_thinking": True},
stream=True,
stream_options={
"include_usage": True
},
)
reasoning_content = "" # 完整思考过程
answer_content = "" # 完整回复
is_answering = False # 是否进入回复阶段
print("\n" + "=" * 20 + "思考过程" + "=" * 20 + "\n")
for chunk in completion:
if not chunk.choices:
print("\n" + "=" * 20 + "Token 消耗" + "=" * 20 + "\n")
print(chunk.usage)
continue
delta = chunk.choices[0].delta
# 只收集思考内容
if hasattr(delta, "reasoning_content") and delta.reasoning_content is not None:
if not is_answering:
print(delta.reasoning_content, end="", flush=True)
reasoning_content += delta.reasoning_content
# 收到content,开始进行回复
if hasattr(delta, "content") and delta.content:
if not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")
is_answering = True
print(delta.content, end="", flush=True)
answer_content += delta.content使用dashscope
import os
from dashscope import Generation
# 初始化请求参数
messages = [{"role": "user", "content": "你是谁?"}]
completion = Generation.call(
# 如果没有配置环境变量,请用阿里云百炼API Key替换:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="deepseek-v3.2",
messages=messages,
result_format="message", # 设置结果格式为 message
enable_thinking=True,
stream=True, # 开启流式输出
incremental_output=True, # 开启增量输出
)
reasoning_content = "" # 完整思考过程
answer_content = "" # 完整回复
is_answering = False # 是否进入回复阶段
print("\n" + "=" * 20 + "思考过程" + "=" * 20 + "\n")
for chunk in completion:
message = chunk.output.choices[0].message
# 只收集思考内容
if "reasoning_content" in message:
if not is_answering:
print(message.reasoning_content, end="", flush=True)
reasoning_content += message.reasoning_content
# 收到 content,开始进行回复
if message.content:
if not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")
is_answering = True
print(message.content, end="", flush=True)
answer_content += message.content
print("\n" + "=" * 20 + "Token 消耗" + "=" * 20 + "\n")
print(chunk.usage)智谱的GLM
链接:https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys
使用OpenAI的方式
from openai import OpenAI
client = OpenAI(
api_key="8d××××××××××××××××××××××××××××××××××××",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
completion = client.chat.completions.create(
model="glm-4.7",
messages=[
{"role": "system", "content": "你是一个聪明且富有创造力的小说作家"},
{"role": "user", "content": "请你作为童话故事大王,写一篇短篇童话故事"}
],
top_p=0.7,
temperature=0.9
)
print(completion.choices[0].message.content)使用langchain的方式
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage # 修改这里
# 创建 LLM 实例
llm = ChatOpenAI(
temperature=0.7,
model="glm-4.7",
openai_api_key="8d××××××××××××××××××××××××××××××××××××",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 创建消息
messages = [
SystemMessage(content="你是一个有用的 AI 助手"),
HumanMessage(content="请介绍一下人工智能的发展历程")
]
# 调用模型
response = llm.invoke(messages) # 注意:使用 invoke 方法
print(response.content)硅基流动平台
链接:https://www.siliconflow.cn/
OpenAI方式
from openai import OpenAI
client = OpenAI(api_key="8d××××××××××××××××××××××××××××××××××××",
base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
# model='Pro/deepseek-ai/DeepSeek-R1',
model="Qwen/Qwen2.5-72B-Instruct",
messages=[
{'role': 'user',
'content': "推理模型会给市场带来哪些新的机会"}
],
stream=True
)
for chunk in response:
if not chunk.choices:
continue
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)