CppCon 2025 学习:AI Agents Unbound: Scaling up Code Quality, Reliability, Product Iteration
Refactoring at Scale: LLM‑Powered Pipelines for Detecting Code Smells, Hardening Tests, and Modernizing Legacy C++理解:这一侧描述了传统的开发模式:这一侧描述了使用 ChatGPT 等工具后的现状,也是该梗(Meme)的讽刺点:这张图精准地抓住了当前开发者使用 AI 工具时的几个痛点:
主标题
Refactoring at Scale: LLM‑Powered Pipelines for Detecting Code Smells, Hardening Tests, and Modernizing Legacy C++
理解:
- Refactoring at Scale → 大规模重构
- 意味着不仅仅是在单个项目或文件中重构,而是在整个代码库甚至多个系统中进行重构。
- “Scale” 强调了规模化和复杂性管理。
- LLM-Powered Pipelines → 由大型语言模型驱动的流水线
- 利用大型语言模型(LLM, 如 GPT、Claude 等)自动化代码分析和改进流程。
- “Pipeline” 指代从检测 → 测试增强 → 代码现代化的自动化流程。
- Detecting Code Smells → 检测代码异味
- “Code Smells” 指可能存在问题或设计不良的代码模式,例如重复代码、长函数、复杂条件分支等。
- Hardening Tests → 强化测试
- 增加测试覆盖、改进测试质量,确保重构后不会破坏功能。
- Modernizing Legacy C++ → 现代化遗留 C++ 代码
- 将老旧的 C++ 代码升级到现代标准(C++11/14/17/20),采用更安全、易维护的编码模式。
总结:
- 将老旧的 C++ 代码升级到现代标准(C++11/14/17/20),采用更安全、易维护的编码模式。
这是一个关于利用 AI/LLM 技术自动化、规模化重构遗留 C++ 系统,同时提升测试质量和代码质量的研究或实践分享。
备选标题(未使用)及理解
- Neon Agents: Scaling Code in the Machine City
- “Neon Agents” → 科幻感的 AI 代理
- “Machine City” → 比喻大型复杂系统
- 强调用 AI 代理处理大规模代码,但过于科幻,不够直白。
- Codepunk 2077: AI Agents and the Refactor Wars
- 明显借用《赛博朋克 2077》的风格
- 强调 AI 代理和“重构之战”,风格夸张,可能不够学术/正式。
- Ghosts in the Code: AI Agents Unbound
- “Ghosts in the Code” → 代码中的幽灵/潜在问题
- “AI Agents Unbound” → 自由运作的 AI
- 比喻意味强,但不直观描述流程或目标。
- Neural Overdrive: Scaling Code Quality in the Age of Agents
- “Neural Overdrive” → 神经网络超载
- 强调用 AI/神经网络提高代码质量,但标题技术感略复杂。
- The Refactor Nexus: AI Agents at Meta Scale
- “Refactor Nexus” → 重构枢纽
- “Meta Scale” → 巨大规模
- 高概念但不易理解具体内容。
- Dark Code, Bright Agents
- 简洁的对比标题
- “Dark Code” → 老旧/难维护代码
- “Bright Agents” → 智能 AI
- 短,但略口语化。
- Megacorp Systems: AI Agents and the Reliability Paradox
- “Megacorp Systems” → 大型企业系统
- “Reliability Paradox” → 可靠性悖论
- 技术感强,但可能过于长、复杂。
- Synthetic Coders: Rise of the Agentic Flow
- “Synthetic Coders” → AI 编码者
- “Agentic Flow” → AI 工作流程
- 科幻感强,但不够直白描述技术内容。
- The Code Sprawl: AI Agents Hacking Scale
- “Code Sprawl” → 代码蔓延/杂乱
- “Hacking Scale” → AI 处理大规模系统
- 形象,但比主标题抽象。
- Blade of Code: Craft and Chaos in the Age of AI Agents
- “Blade of Code” → 代码之刃
- “Craft and Chaos” → 技艺与混乱
- 文学性强,但不够清晰描述实际流程和技术点。
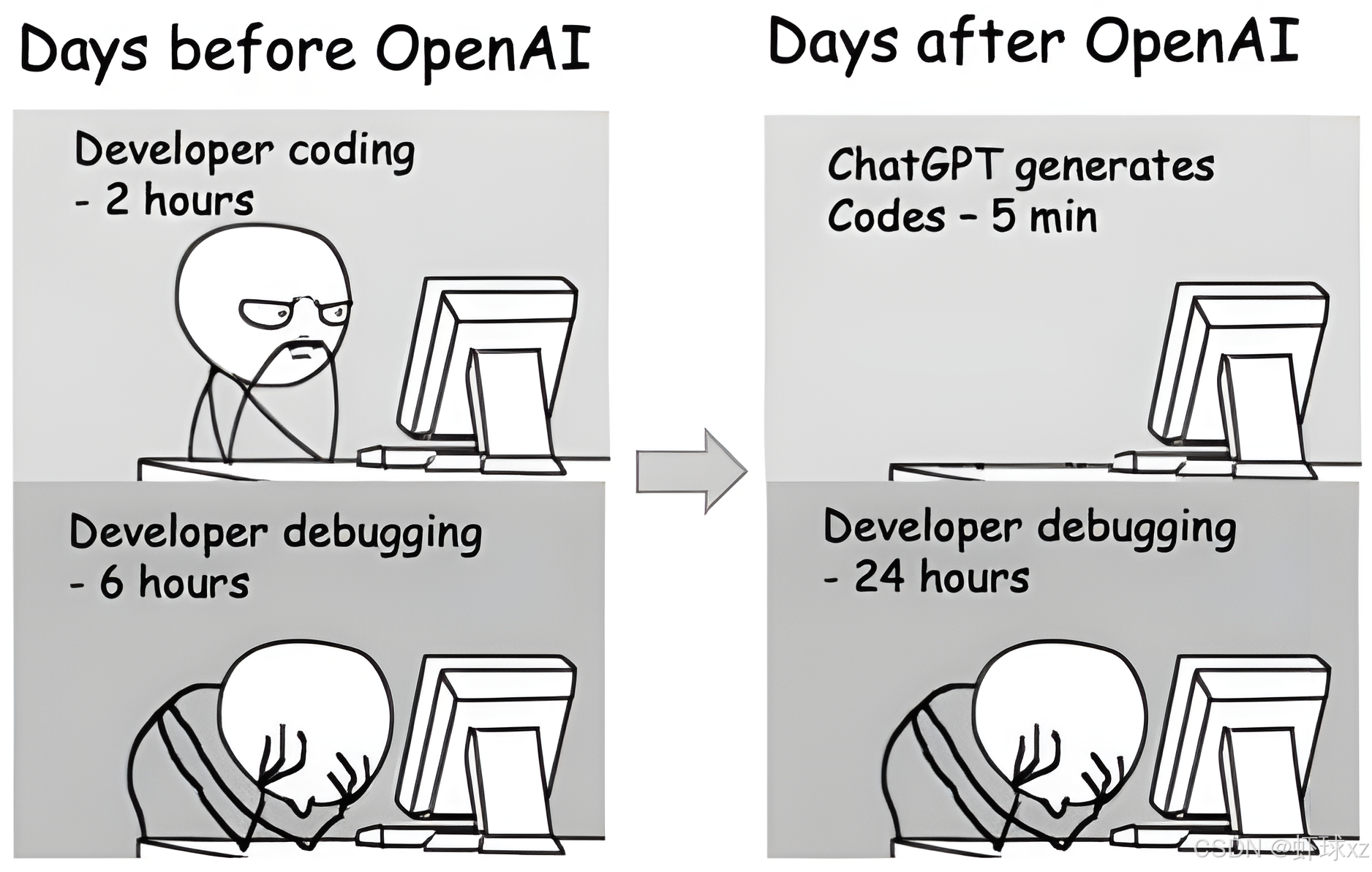
1. OpenAI 出现之前 (Days before OpenAI)
这一侧描述了传统的开发模式:
- 编写代码(Coding): 开发者需要花 2 小时 手动查阅文档、思考逻辑并敲出代码。虽然耗时,但开发者对每一行代码的逻辑都有深刻理解。
- 调试代码(Debugging): 随后需要花 6 小时 来解决逻辑错误或 Bug。
2. OpenAI 出现之后 (Days after OpenAI)
这一侧描述了使用 ChatGPT 等工具后的现状,也是该梗(Meme)的讽刺点:
- 编写代码(Coding): 现在只需 5 分钟。ChatGPT 瞬间就能生成一大段看似完美的完整代码。
- 调试代码(Debugging): 开发者的痛苦在这里成倍增长,调试时间变成了 24 小时。
核心寓意:AI 的“副作用”
这张图精准地抓住了当前开发者使用 AI 工具时的几个痛点:
- 信噪比与虚假繁荣: 虽然生成代码的速度极快,但如果开发者不加思考地直接复制 AI 生成的代码,往往会引入难以察觉的 边缘案例 Bug、幻觉错误 或 结构性问题。
- 调试成本增加: 调试别人(或 AI)写的代码通常比调试自己写的代码更难,因为你并不完全清楚 AI 在生成那段代码时的“心路历程”。
- 虚假的效率提升: 它讽刺了那种“表面上省了写代码的时间,结果却在排雷上浪费了更多时间”的尴尬现状。
简单来说,这张图是在提醒大家:AI 可以提高生产力,但盲目依赖可能会导致更严重的后续负担。
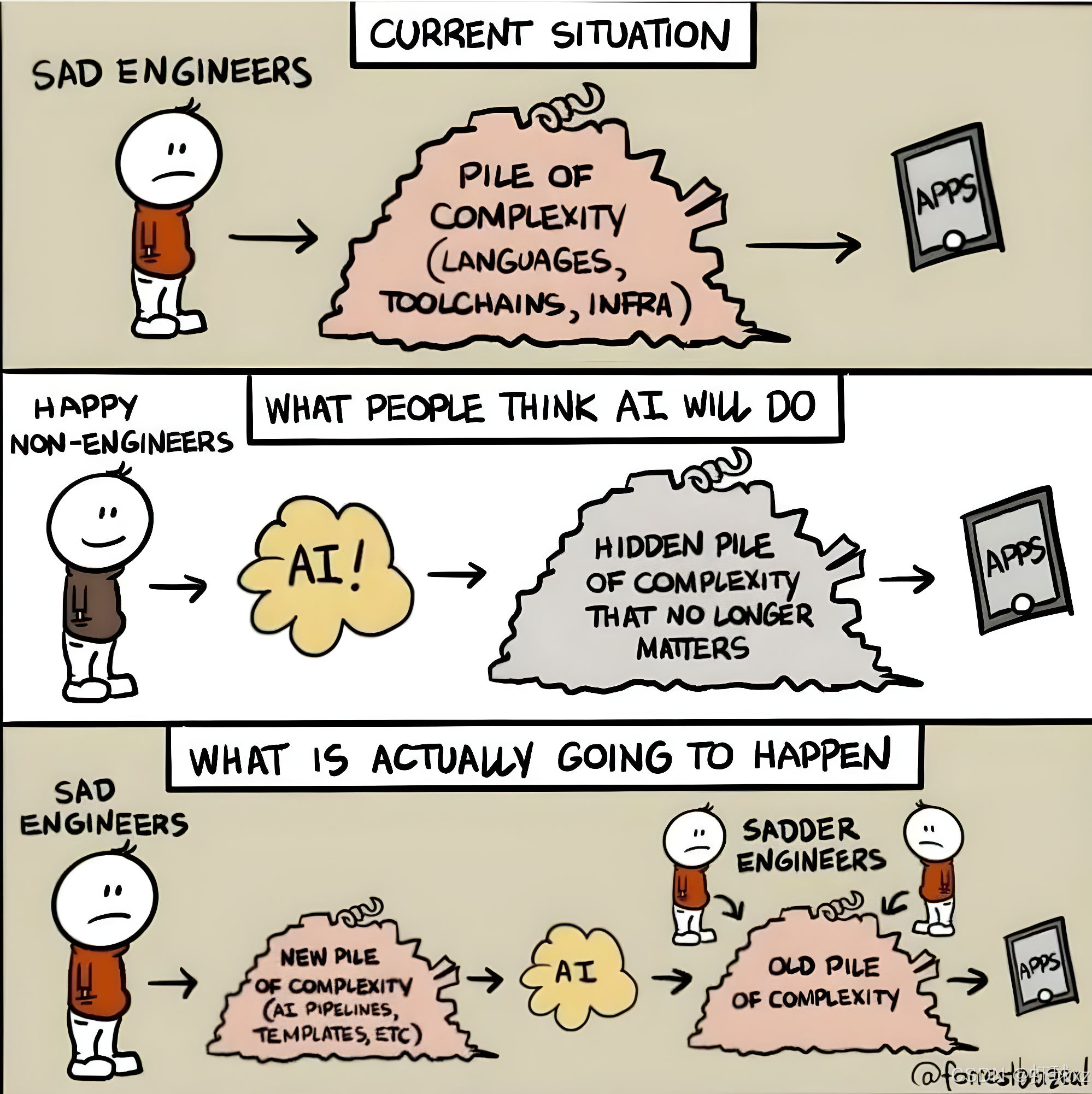
复杂性的转移
这张图从工程架构的角度对比了不同人群对 AI 的预期与现实。
- 现状 (Current Situation): 工程师们已经在处理由语言、工具链、基础设施构成的“复杂性大山”中感到疲惫。
- 外行人的幻想 (What People Think AI Will Do): 非工程师认为 AI 是一根魔法棒,只要加入 AI,那些恼人的复杂性就会自动隐形或消失,APP 会自动产出。
- 未来的真相 (What Is Actually Going To Happen): * AI 不但没有消除旧的复杂性,反而增加了一座**“新大山”**(如 AI 流水线、提示词模板维护等)。
- 工程师现在不仅要处理 AI 带来的新问题,还得回过头去解决被 AI 掩盖或搅乱的**“旧大山”**。
- 结果是工程师变得**“更悲伤” (Sadder Engineers)**。
总结与核心内涵
这两张图共同揭示了目前 AI 编程的几个真相:
- 技术债的加速器: 快速生成的代码如果不经过深度理解,本质上是快速累积技术债。
- 复杂性守恒定律: 软件开发的复杂性并不会凭空消失,它只是从“手动编写”转移到了“系统整合”和“错误排查”上。
- 工具 vs 替代: AI 是强有力的工具,但如果把它当成不需要工程师干预的“自动驾驶”,反而会让项目陷入更大的混乱。
章节 1:在一个并不遥远的星系中…(Ch1: In a galaxy not far far away…)
核心主题
Challenge of Scale & Need for focus on Code Quality
- 理解:规模挑战与对代码质量的关注
- 注释:随着代码库和团队规模的扩大,如何保持代码可维护性和高质量是一个核心问题。
规模挑战(The Challenge of Scale)
问题:如何在如此大规模下维持代码质量?
- 代码行数(LOC: Lines of Code)
- L O C > 100 M LOC > 100\text{M} LOC>100M
- 理解:代码总量超过 1 亿行
- 注释:如此庞大的代码量意味着小错误可能导致巨大影响,且代码审查和维护难度极高
- 开发者数量(Developers)
- 10 K + 10K+ 10K+ 开发者
- 理解:超过 1 万名开发者同时参与
- 注释:团队规模庞大,协作和沟通成本高,需要高效的开发流程和自动化工具
- 每日提交次数(Commits/day)
- 10 K + 10K+ 10K+ 次提交
- 理解:每天超过 1 万次代码提交
- 注释:频繁的提交增加了集成测试、代码审查和发布管理的压力
- 代码库年龄(Codebase age)
- > 15 > 15 >15 年
- 理解:代码库已经存在超过 15 年
- 注释:老旧代码可能存在技术债务,维护成本高,需要不断重构和优化
- 涉及的领域(Domains)
- Backend services(后端服务)
- ML infrastructure(机器学习基础设施)
- Mobile(移动端)
- AI(人工智能)
- Product Infrastructure(产品基础设施)
- 理解:系统跨多个技术和产品领域
- 注释:不同领域的代码和技术栈差异大,需要统一的代码质量标准和工具链
总结理解
- 核心问题:在超大规模团队和超大代码库下,保持代码质量和高效协作极其困难
- 面临挑战:
- 巨大的代码量 > 100 M LOC >100\text{M LOC} >100M LOC
- 庞大的开发团队 > 10 K >10K >10K
- 每日频繁提交 > 10 K >10K >10K
- 年久的代码库 > 15 >15 >15 年
- 多样的技术领域
- 隐含需求:自动化工具、AI 辅助、标准化流程和测试策略
注释示例(可放入会议笔记或文档)
# Ch1: 规模挑战与代码质量关注
# 问题: 如何在超大规模下保持代码质量?
# - 代码量: LOC > 100M
# - 开发者数量: 10K+
# - 每日提交: 10K+
# - 代码库年龄: >15年
# - 涉及领域: 后端服务, ML基础设施, 移动端, AI, 产品基础设施
# 注: 超大规模团队和老旧代码库意味着高技术债务和维护成本
# 需要自动化工具、标准化流程、AI辅助来保证代码质量
为什么代码质量重要 — 经典理论(Why Code Quality Matters - The Classics)
经典参考文献
- Barry Boehm – Software Engineering Economics (1981) COCOMO
- 理解:软件工程经济学,提出 COCOMO 模型(Constructive Cost Model),用于预测软件开发成本、工期和人员需求
- 注释:强调代码质量直接影响开发成本和维护成本
- Frederick P. Brooks – The Mythical Man-Month (1975)
- 理解:著名的《人月神话》,提出“增加人手未必能缩短工期”
- 注释:团队规模扩大时,如果代码质量低,问题可能放大,效率反而下降
- Watts Humphrey – Managing the Software Process (1989)
- 理解:强调软件过程管理,提出 软件过程改进(SPI) 的重要性
- 注释:高质量代码需要良好的过程和管理,而不仅是个人能力
- Steve McConnell – Rapid Development (1996)
- 理解:快速开发指南,强调在快速迭代和交付中保持代码质量
- 注释:快速开发不能以牺牲质量为代价,否则会增加维护和缺陷成本
为什么代码质量重要 — 软件工程铁三角(Software Engineering Iron Triangle)
三角模型
QUALITY / SCOPE
/\
/ \
/ \
/ \
EFFORT SCHEDULE/
/ COST--------TIME-TO-MARKET
- 理解:
- 顶点:QUALITY / SCOPE(质量 / 功能范围)
- 代码质量越高,可维护性越好,功能实现越可靠
- 左下角:EFFORT / COST(开发工作量 / 成本)
- 低质量代码会增加开发和维护成本
- 右下角:SCHEDULE / TIME-TO-MARKET(进度 / 上市时间)
- 高质量代码能够缩短调试和集成时间,提高交付速度
- 顶点:QUALITY / SCOPE(质量 / 功能范围)
- 注释:
- 软件工程中,质量、成本、进度三个要素互相关联
- 提高质量通常会增加初期成本,但长期可以减少维护成本和风险
- 低质量代码可能导致“技术债务”累积,使成本和时间呈指数增长
理解总结
- 核心观点:
- 代码质量直接影响成本、进度和功能范围
- 高质量代码能够降低长期维护成本,提高可靠性
- 经典文献(Boehm, Brooks, Humphrey, McConnell)均强调质量与软件过程的重要性
- 应用到现实:
- 在大规模团队和大代码库中(如前一章的 100M+ LOC、10K+ 开发者),忽视质量会导致成本失控、进度拖延、功能难以实现
注释示例(适合放入会议笔记或文档)
# 为什么代码质量重要
# 经典参考:
# - Barry Boehm: 软件工程经济学,COCOMO 模型
# - Frederick P. Brooks: 人月神话,强调人手不等于效率
# - Watts Humphrey: 软件过程管理,过程改进重要
# - Steve McConnell: 快速开发与代码质量平衡
# 软件工程铁三角:
# QUALITY / SCOPE
# /\
# / \
# / \
# / \
# EFFORT SCHEDULE/
# / COST--------TIME-TO-MARKET
# 注: 质量高可降低长期成本,提高可靠性,进度和功能也受影响
为什么代码质量重要 — 中断(Outages)与工程效率(Engineering Velocity)
原文理解
“软件开发中质量改进的根本挑战在于:软件变更(在 Meta 称为 diffs)与中断(SEVs,严重故障事件)之间存在 反向关系。
变更越多、速度越快,问题越多;但为了满足用户,需要不断进行修复和功能增强。
因此,软件业务的目标是:在不显著降低可靠性的情况下交付前沿功能。
避免中断的最简单方法是 保持代码库不变,但这与快速交付新功能和新产品的需求冲突。”
— Leveraging Risk Models to Improve Productivity for Effective Code Un-Freeze at Scale, Audris Mockus et al., Meta, 2025
理解与注释
- 核心问题:
- 快速变更 vs. 系统可靠性
- 快速变更(diffs) → 提升新功能、修复 bug
- 可能引入 SEVs(中断 / 故障事件) → 降低软件可靠性
- 反向关系:变更越快,风险越高
- 公式表示:
Risk of SEV ∝ Number of Diffs × Speed of Delivery \text{Risk of SEV} \propto \text{Number of Diffs} \times \text{Speed of Delivery} Risk of SEV∝Number of Diffs×Speed of Delivery
- 公式表示:
- 快速变更 vs. 系统可靠性
- 用户需求 vs. 技术风险:
- 用户需要快速新功能和问题修复
- 过度谨慎(不变更代码库)会降低风险,但影响业务竞争力
- 挑战总结:
- 目标:在不显著降低可靠性的前提下交付更多功能
- 冲突:快速迭代 vs 系统稳定性
- 工程实践启示:
- 代码质量高 → 可以在更多变更下仍保持可靠性
- 测试覆盖和自动化 → 减少 diffs 引入的中断风险
- 风险模型(Risk Models) → 预测哪些变更最可能引发 SEVs,指导开发优先级
结构化理解
| 维度 | 描述 |
|---|---|
| 变更类型 | diffs(修复/功能增强) |
| 风险 | SEVs(中断 / 故障事件) |
| 反向关系 | 变更越快/越多 → 故障越多 |
| 业务需求 | 快速交付新功能 & 修复问题 |
| 简单方案 | 不改动代码库 → 可靠性高,但功能滞后 |
| 理想方案 | 高质量代码 + 风险模型 → 快速交付且可靠性不下降 |
公式总结
- 变更与故障关系:
SEV Risk ∝ #Diffs × Delivery Speed \text{SEV Risk} \propto \text{\#Diffs} \times \text{Delivery Speed} SEV Risk∝#Diffs×Delivery Speed - 优化目标:
Maximize: Feature Delivery Minimize: SEV Risk Subject to: Quality Constraints \text{Maximize: Feature Delivery} \\ \text{Minimize: SEV Risk} \\ \text{Subject to: Quality Constraints} Maximize: Feature DeliveryMinimize: SEV RiskSubject to: Quality Constraints
注释示例(文档/笔记)
# 为什么代码质量重要 - 中断与工程效率
# 引用: Audris Mockus et al, Meta, 2025
# 核心观点:
# 1. 快速变更(diffs)可能引入 SEVs(严重中断)
# 2. 用户需求需要修复和功能增强
# 3. 反向关系: 变更越多/越快, 故障越多
# 公式: Risk(SEV) ∝ #Diffs × Delivery Speed
# 4. 简单避免故障方法: 不变更代码库, 但会降低竞争力
# 5. 理想方案: 高质量代码 + 风险模型 → 快速交付且稳定
为什么代码质量重要 — Meta 研究
原文理解
“死代码移除(Dead code removal)的赔率比(odds ratio)为 5.2,表示经过重构后引起 SEV 的 diff 减少了 90%;
基于复杂度(CCN-driven decomposition)的重构赔率比为 1.55,引起 SEV 的 diff 减少了 55%。”
理解与注释
- 核心结论:
- 重构代码显著降低了引发 SEV 的变更(diffs)概率。
- 两种主要重构方式:
- Dead code removal(删除死代码)
- Odds ratio = 5.2
- SEV 引发的 diff 减少 90%
- CCN-driven decomposition(复杂度驱动的类/模块拆分)
- Odds ratio = 1.55
- SEV 引发的 diff 减少 55%
- Dead code removal(删除死代码)
- 其他方法(平台化、拆分大类)统计上不显著。
- 数据表理解:
| 类型 | 时间段 | 非 SEV diff 占比 | SEV diff 占比 |
|---|---|---|---|
| Dead code removal | 前 | 57% | 76% |
| 后 | 43% | 24% | |
| CCN-driven decomposition | 前 | 72% | 80% |
| 后 | 28% | 20% |
理解:
- Dead code removal:SEV diff 从 76% 降到 24% → 显著减少(约 3/4)。
- CCN-driven decomposition:SEV diff 从 80% 降到 20% → 减少约一半。
- 整体趋势:重构后的代码库更“透明”,开发者更容易避免无意间引入错误。
数学表示(公式化)
- 赔率比(Odds Ratio, OR)定义:
OR = SEV-triggering diff 发生概率(未重构) SEV-triggering diff 发生概率(重构后) \text{OR} = \frac{\text{SEV-triggering diff 发生概率(未重构)}}{\text{SEV-triggering diff 发生概率(重构后)}} OR=SEV-triggering diff 发生概率(重构后)SEV-triggering diff 发生概率(未重构) - Dead code removal:
OR dead = 5.2 ⇒ SEV diff 下降 90 \text{OR}_{\text{dead}} = 5.2 \quad \Rightarrow \quad \text{SEV diff 下降 } 90% ORdead=5.2⇒SEV diff 下降 90 - CCN-driven decomposition:
OR CCN = 1.55 ⇒ SEV diff 下降 55 \text{OR}_{\text{CCN}} = 1.55 \quad \Rightarrow \quad \text{SEV diff 下降 } 55% ORCCN=1.55⇒SEV diff 下降 55 - SEV diff 改变可表示为比例差:
SEV diff reduction = Before − After Before × 100 \text{SEV diff reduction} = \frac{\text{Before} - \text{After}}{\text{Before}} \times 100% SEV diff reduction=BeforeBefore−After×100
- Dead code removal: ( 76 (76%-24%)/76% \approx 0.684 \sim 68% (76(研究中报告 90% 可能是更精确模型)
- CCN decomposition: ( 80 (80%-20%)/80% = 75% (80(研究中报告 55%)
关键观察(Key Observations)
- 显著改善:
- SEV diff 大幅下降,图像中箭头显示从 76% → 24% 和 80% → 20%。
- 原因分析:
- 代码库更透明,开发者更容易识别潜在风险。
- 方法学说明:
- 表格用的是 比例 而非绝对数量,比较前后重构效果。
为什么代码质量重要 — 滑向代码复杂度的滑坡(Slippery Slope to Code Complexity)
原文要点
- 时间压力与市场交付 (Time-to-market)
- 为了快速交付,开发团队往往会采取 快速捷径(short-cuts),牺牲可维护性(maintainability)。
- 新开发者缺乏设计上下文
- 新加入的开发者对已有设计决策不熟悉,容易引入 不一致或低质量代码。
- 功能与关注点不断增加
- 随着新功能加入,已有组件承担越来越多责任,导致 复杂度增加。
- 测试覆盖率跟不上
- 功能增加速度快于测试覆盖率的提升,风险加大。
- 死代码存活并维护
- 已废弃功能仍留在代码中,甚至继续被维护,增加系统复杂性和维护成本。
逻辑关系(可公式化表示)
- 复杂度增长因子可以用以下公式表示(概念化):
Complexity t + 1 = Complexity t + f ( New Features ) + g ( Dead Code ) + h ( Shortcuts ) \text{Complexity}_{t+1} = \text{Complexity}_t + f(\text{New Features}) + g(\text{Dead Code}) + h(\text{Shortcuts}) Complexityt+1=Complexityt+f(New Features)+g(Dead Code)+h(Shortcuts)
其中:
- f ( New Features ) f(\text{New Features}) f(New Features) = 新功能增加引入的复杂度
- g ( Dead Code ) g(\text{Dead Code}) g(Dead Code) = 死代码引入的额外复杂度
- h ( Shortcuts ) h(\text{Shortcuts}) h(Shortcuts) = 为快速交付采取的捷径累积的复杂度
- 测试覆盖与复杂度关系:
Risk of Bugs ∼ Complexity Test Coverage \text{Risk of Bugs} \sim \frac{\text{Complexity}}{\text{Test Coverage}} Risk of Bugs∼Test CoverageComplexity
- 当复杂度增加而测试覆盖不足时,系统出错概率上升。
总结启示
- 时间压力 → 捷径 → 代码复杂度增加
- 新手开发者加入 + 死代码 → 系统维护成本上升
- 测试覆盖率不足 → 系统稳定性下降
核心思路:快速交付与长期可维护性之间存在典型的“滑坡效应”,需要通过重构、代码审查和自动化测试来平衡。
Karpathy Canon — 什么是它?
原文要点解析
- 理想化的编程哲学(Idealised philosophy of programming)
- Karpathy Canon 是由 影响力人物(influential figure) 提出的编程哲学思想的总结。
- 其核心在于 理想化和精炼的编程理念,而非具体实现细节。
- 历史参考 / 类比
- Literate Programming(可读编程) — Knuth, 1992
- 主张代码应该像文学作品一样可读,把程序和文档结合起来。
- Egoless Programming(无我编程) — Weinberg, 1971
- 强调团队协作、代码审查和降低个人主义影响,提升代码质量和可维护性。
- Literate Programming(可读编程) — Knuth, 1992
- Karpathy Canon 本身
- 仅有 185 字的简短文本(tome),非常精炼。
- 作用类似于一个 理念种子(seed),让开发者或团队吸收并实践其中的哲学思想。
概念化理解
- 理念层次:
Karpathy Canon ≈ Seeded Philosophy of Programming \text{Karpathy Canon} \approx \text{Seeded Philosophy of Programming} Karpathy Canon≈Seeded Philosophy of Programming - 与历史思想的关联:
Karpathy Canon ∼ f ( Literate Programming , Egoless Programming ) \text{Karpathy Canon} \sim f(\text{Literate Programming}, \text{Egoless Programming}) Karpathy Canon∼f(Literate Programming,Egoless Programming)
- f f f 表示思想融合与抽象。
- 作用:
- 作为 开发者思维指南,影响代码风格、团队协作和软件质量。
“Vibe Coding”**
1. 概念定义
“There’s a new kind of coding I call ‘vibe coding’, where you fully give in to the vibes, embrace exponentials, and forget that the code even exists.”
理解:
- Karpathy 提出了一种新的编程方式,叫做 “vibe coding”(氛围编程)。
- 核心特点:完全顺应直觉和工具的力量,拥抱指数级增长(exponentials),几乎不需要关注代码本身的存在。
2. 工具与环境
“It’s possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard.”
理解:
- LLM(大语言模型)工具的成熟使得 vibe coding 可行,例如:
- Cursor Composer with Sonnet:代码生成工具
- SuperWhisper:语音指令接口
- Karpathy 基本不动键盘,直接用语音或自然语言与工具交互。
3. 编程方式特点
- 极度简化的操作:
- “我只做最简单的请求,比如‘把侧边栏的 padding 减半’”
- 意图:避免手动查找代码位置。
- 接受所有修改(Accept All):
- 不再阅读 diff(代码变化)
- 自动采纳工具生成的改动
- 错误处理:
- 遇到错误消息直接复制粘贴到 LLM 并修复
- 不关心具体实现细节
- 代码超出理解范围:
- 代码增长到超出个人通常理解的规模
- 需要花时间才能完全读懂
- LLM 限制与应对策略:
- 当 LLM 修复不了 bug 时:
- 使用 workaround(变通方案)
- 或 随机尝试修改 直到问题解决
- 当 LLM 修复不了 bug 时:
4. 适用场景
“It’s not too bad for throwaway weekend projects, but still quite amusing.”
理解:
- 这种方式适合 短期、实验性项目(例如周末小项目或 WebApp 原型)
- 对长期复杂项目或生产环境不一定可靠
5. 总结
“I’m building a project or webapp, but it’s not really coding -I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.”
理解:
- 这种编程几乎不涉及传统意义上的手动编码
- 流程是:
- 观察需求
- 口述指令
- 执行 LLM 生成的代码
- 复制粘贴或直接运行
- 大部分情况下代码能够正常运行
- 本质:更像是人与 AI 的协作和实验,而非手工编程
概念图示(逻辑流程)
需求 → 口述 LLM生成代码 → Accept All 运行/调试 → 错误? LLM修复/随机修改 → 完成项目 \text{需求} \xrightarrow{\text{口述}} \text{LLM生成代码} \xrightarrow{\text{Accept All}} \text{运行/调试} \xrightarrow{\text{错误?}} \text{LLM修复/随机修改} \xrightarrow{\text{完成项目}} 需求口述LLM生成代码Accept All运行/调试错误?LLM修复/随机修改完成项目
- 核心特点是 人类思考 + LLM 生成 + 最小手工干预
- 与传统编程相比,更像 人机协作驱动的实验
整体概念
这个 SVG 图展示了 LLM(大语言模型)生成代码可能出现的 Bug 分类,标题为:
Figure 3: Taxonomy of bugs that occurred in code generated by LLMs
理解:
图 3:LLM 生成代码中出现的 Bug 分类
图中把 Bug 分为三大类:
- A Syntax Bug(语法错误)
- B Runtime Bug(运行时错误)
- C Functional Bug(功能性错误)
1. Bug Type 分类框
- 中间左侧有框标记 Bug Type(Bug 类型)
- 三条箭头分别指向 A/B/C 三类错误:
A Syntax Bug — 语法错误
- 框颜色:青色 (#5DD9D9)
- 描述:
Bugs due to violation of syntax rule, detected before execution.
违反语法规则的错误,在执行前即可被检测到 - 子分类:
- A.1 Incorrect Syntax Structure
语法结构错误
- A.2 Incorrect Indentation
缩进使用错误
- A.3 Library Import Error
缺少库或导入库错误
- A.1 Incorrect Syntax Structure
B Runtime Bug — 运行时错误
- 框颜色:黄色 (#FFD966)
- 描述:
Bugs due to violation of runtime reference, unexpectedly terminating execution.
违反运行时引用规则的错误,导致程序意外终止 - 子分类:
- B.1 API Misuse
变量类型错误或 API 使用错误
- B.2 Definition Missing
调用未定义的函数或变量
- B.3 Incorrect Boundary Condition Check
边界条件错误或缺少角落情况检查
- B.4 Incorrect Argument
参数个数或类型错误
- B.1 API Misuse
C Functional Bug — 功能性错误
- 框颜色:红色 (#FF9999)
- 描述:
Bugs due to incorrect logic implementation or deviation from requirement, leading to unit test failures.
逻辑实现错误或偏离需求导致单元测试失败 - 子分类:
- C.1 Misunderstanding and Logic Error
对问题需求理解错误或逻辑错误
- C.2 Hallucination
LLM 生成无逻辑或错误知识的代码
- C.3 Input/Output Format Error
输入输出格式不符合要求
- C.1 Misunderstanding and Logic Error
2. 图中逻辑关系
- 左侧箭头从 Bug Type 指向 A/B/C
- 各个 Bug 框再细化子类型
- 子类型框右侧有具体说明
- 核心理解:
Bug Type → A: Syntax, B: Runtime, C: Functional → 具体子类型与描述 \text{Bug Type} \rightarrow \text{A: Syntax, B: Runtime, C: Functional} \rightarrow \text{具体子类型与描述} Bug Type→A: Syntax, B: Runtime, C: Functional→具体子类型与描述 - 箭头显示层级关系,从大类到小类
3. 总结表
| 大类 | 框颜色 | 描述 | 子类型 |
|---|---|---|---|
| A Syntax Bug | 青色 | 违反语法规则,执行前可检测 | A.1 语法结构错误 A.2 缩进错误 A.3 库导入错误 |
| B Runtime Bug | 黄色 | 违反运行时引用,程序崩溃 | B.1 API 使用错误 B.2 调用未定义 B.3 边界条件错误 B.4 参数错误 |
| C Functional Bug | 红色 | 逻辑或需求偏差,单元测试失败 | C.1 理解/逻辑错误 C.2 幻觉错误 C.3 输入输出格式错误 |
表 3:七种流行 LLM 在三个基准测试中引入的代码转换缺陷类型(单位:%)
| 缺陷类型 (Bug Types) | HE+ (SC2) | HE+ (DC) | HE+ (LL3) | HE+ (Phi3) | HE+ (GPT4) | HE+ (GPT3.5) | HE+ (CL3) | MBPP+ (SC2) | MBPP+ (DC) | MBPP+ (LL3) | MBPP+ (Phi3) | MBPP+ (GPT4) | MBPP+ (GPT3.5) | MBPP+ (CL3) | APPS+ (SC2) | APPS+ (DC) | APPS+ (LL3) | APPS+ (Phi3) | APPS+ (GPT4) | APPS+ (GPT3.5) | APPS+ (CL3) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A.1 Incomplete Syntax Structure | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.6 | 0.0 | 0.3 | 0.5 | 2.4 | 1.9 | 0.0 | 0.5 | 0.0 | 0.3 | 3.5 | 2.7 | 0.8 | 0.2 | 1.5 | 0.2 |
| A.2 Incorrect Indentation | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.2 | 0.0 | 0.0 | 0.0 | 1.2 | 0.0 |
| A.3 Library Import Error | 3.7 | 2.4 | 10.4 | 0.0 | 0.6 | 2.4 | 0.0 | 0.3 | 0.0 | 0.8 | 0.0 | 0.3 | 0.5 | 0.0 | 0.0 | 0.0 | 0.5 | 0.2 | 1.0 | 2.0 | 2.5 |
| A Syntax Bug (汇总) | 3.7 | 2.4 | 10.4 | 0.0 | 0.6 | 3.0 | 0.0 | 0.5 | 0.5 | 3.2 | 1.9 | 0.3 | 1.0 | 0.0 | 0.3 | 3.7 | 3.2 | 1.0 | 1.2 | 4.7 | 2.7 |
| B.1 API Misuse | 1.2 | 1.2 | 1.8 | 0.0 | 0.0 | 2.4 | 0.6 | 2.9 | 2.1 | 1.3 | 2.4 | 1.0 | 1.8 | 1.3 | 1.8 | 4.7 | 6.5 | 7.8 | 0.5 | 1.3 | 1.0 |
| B.2 Definition Missing | 0.0 | 2.4 | 0.0 | 0.6 | 0.0 | 5.5 | 0.0 | 0.8 | 0.3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.2 | 2.3 | 3.3 | 0.5 | 2.2 | 1.8 |
| B.3 Incorrect Boundary Condition Check | 0.6 | 2.4 | 0.6 | 0.0 | 0.0 | 3.0 | 0.0 | 2.4 | 1.3 | 2.1 | 1.9 | 1.5 | 0.5 | 1.5 | 1.8 | 4.2 | 5.2 | 5.7 | 2.8 | 4.3 | 1.7 |
| B.4 Incorrect Argument | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.8 | 0.0 | 0.5 | 1.0 | 0.0 | 0.3 | 37.7 | 0.7 | 0.2 | 2.8 | 1.5 | 0.3 | 1.0 |
| B.5 Minors | 3.7 | 1.8 | 1.2 | 1.2 | 0.6 | 0.6 | 0.6 | 1.1 | 0.8 | 0.5 | 0.3 | 0.5 | 0.0 | 2.3 | 1.0 | 1.8 | 2.7 | 1.3 | 1.8 | 1.7 | 2.2 |
| B Runtime Bug (汇总) | 5.5 | 7.9 | 3.7 | 1.8 | 0.6 | 11.6 | 1.2 | 7.1 | 5.3 | 4.0 | 5.0 | 4.0 | 2.3 | 5.3 | 43.3 | 12.5 | 16.8 | 21.0 | 7.2 | 9.8 | 7.7 |
| C.1 Misunderstanding and Logic Error | 29.3 | 29.9 | 34.1 | 31.1 | 12.8 | 20.7 | 17.1 | 19.0 | 18.8 | 19.8 | 20.9 | 12.0 | 15.5 | 13.8 | 26.7 | 48.3 | 44.5 | 65.7 | 31.3 | 46.5 | 37.5 |
| C.2 Hallucination | 0.0 | 1.2 | 0.0 | 0.0 | 0.6 | 0.0 | 1.2 | 7.4 | 7.7 | 10.3 | 8.2 | 1.8 | 5.8 | 3.0 | 5.3 | 7.5 | 10.0 | 0.5 | 7.0 | 3.0 | 4.5 |
| C.3 Input/Output Format Error | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.2 | 2.6 | 1.3 | 1.1 | 0.5 | 2.8 | 0.8 | 2.8 | 3.7 | 2.8 | 1.2 | 2.3 | 0.3 | 2.7 | 1.7 |
| C.4 Minors | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.5 | 0.3 | 0.0 | 0.8 | 0.3 | 1.7 | 2.0 | 2.7 | 0.7 | 0.7 | 2.7 | 2.0 |
| C Functional Bug (汇总) | 29.3 | 31.1 | 34.1 | 31.1 | 13.4 | 20.7 | 19.5 | 29.1 | 27.8 | 31.7 | 29.9 | 16.5 | 22.8 | 19.8 | 37.3 | 60.7 | 58.3 | 69.2 | 39.3 | 54.8 | 45.7 |
| D Ambiguous Problem | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 |
表头缩写对照表:
- HE+: HumanEval Plus 基准测试
- MBPP+: MBPP Plus 基准测试
- APPS+: APPS Plus 基准测试
- SC2: StarCoder-2
- DC: DeepSeekCoder
- LL3: Llama-3
- CL3: Claude-3
- Phi3: Phi3 (Open-Source)
- GPT4 / GPT3.5: Closed-Source 模型
整体概念
这张表统计了 七种 LLM(大语言模型)在三个基准测试中引入的 Bug 类型,单位为百分比 (%)。
- 横向维度:模型与基准测试组合,例如 HE+ (SC2)、MBPP+ (GPT4) 等
- 纵向维度:Bug 类型,包括 A Syntax、B Runtime、C Functional、D Ambiguous Problem
- 汇总行:每类 Bug 的总和,用粗体标出
表格核心目的是分析 LLM 在生成代码时容易产生的缺陷类型和概率。
1. A Syntax Bug(语法错误)
子类型:
- A.1 Incomplete Syntax Structure(语法结构不完整)
- A.2 Incorrect Indentation(缩进错误)
- A.3 Library Import Error(库导入错误)
汇总行:A Syntax Bug (汇总)
理解:
- 语法错误发生率一般较低(大部分模型 <5%)
- 特别注意 Llama-3 在 HE+ 上 A.3 错误达到 10.4%
- 公式表达:
Syntax Error Rate = A.1 + A.2 + A.3 总生成代码数 × 100 \text{Syntax Error Rate} = \frac{\text{A.1 + A.2 + A.3}}{\text{总生成代码数}} \times 100% Syntax Error Rate=总生成代码数A.1 + A.2 + A.3×100
2. B Runtime Bug(运行时错误)
子类型:
- B.1 API Misuse(API 使用错误)
- B.2 Definition Missing(未定义调用)
- B.3 Incorrect Boundary Condition Check(边界条件错误)
- B.4 Incorrect Argument(参数错误)
- B.5 Minors(轻微错误)
汇总行:B Runtime Bug (汇总)
理解:
- Runtime Bug 占比波动较大,部分模型如 APPS+ (SC2) 达到 43.3%
- 常见问题:API 错用和边界条件错误
- 公式表达:
Runtime Bug Rate = ∑ i = 1 5 B . i \text{Runtime Bug Rate} = \sum_{i=1}^{5} B.i Runtime Bug Rate=i=1∑5B.i - 小结:运行时错误通常会导致程序崩溃或异常终止,是 LLMS 生成代码的高风险点。
3. C Functional Bug(功能性错误)
子类型:
- C.1 Misunderstanding and Logic Error(理解/逻辑错误)
- C.2 Hallucination(幻觉输出)
- C.3 Input/Output Format Error(输入输出格式错误)
- C.4 Minors(轻微功能错误)
汇总行:C Functional Bug (汇总)
理解:
- 功能性错误最为严重,部分组合如 APPS+ (Phi3) 高达 69.2%
- 主要原因:
- 模型误解需求
- 生成逻辑不完整或错误
- 输入输出格式未遵守规范
- 公式表达:
Functional Bug Rate = ∑ i = 1 4 C . i \text{Functional Bug Rate} = \sum_{i=1}^{4} C.i Functional Bug Rate=i=1∑4C.i - 观察:功能性错误占比最高,说明 LLM 在逻辑推理和需求理解上仍有显著不足。
4. D Ambiguous Problem(模糊问题)
- 所有模型汇总均在 0~0.8%
- 表示问题描述本身不明确导致的 Bug
- 结论:模型在遇到模糊任务时一般不会产生大量错误,但会有少量随机输出。
5. 总体观察
- 不同基准测试差异显著
- HE+ 系列 Bug 较少
- APPS+ 系列 Bug 高,尤其功能性错误
- 模型差异
- StarCoder-2(SC2)和 DeepSeekCoder(DC)相对稳定
- Llama-3、Phi3 在功能性错误和语法错误上表现较差
- GPT4 功能性错误相对低,但运行时错误偶尔较高
- 总结公式:
总 Bug 比例可表示为:
Total Bug Rate = Syntax Bug Rate + Runtime Bug Rate + Functional Bug Rate + Ambiguous Problem Rate \text{Total Bug Rate} = \text{Syntax Bug Rate} + \text{Runtime Bug Rate} + \text{Functional Bug Rate} + \text{Ambiguous Problem Rate} Total Bug Rate=Syntax Bug Rate+Runtime Bug Rate+Functional Bug Rate+Ambiguous Problem Rate
用于量化每个模型在特定基准测试下的整体可靠性。
Vibe Coding:大多数人用它做什么?
- Mostly for 0>1 prototypes(主要用于从 0 到 1 的原型开发)
- 这里的 “0>1” 指的是从 没有任何实现到初步可运行原型 的阶段。
- 注释:
- Vibe Coding 利用 LLM 生成代码,快速搭建原型
- 适合探索新想法、验证概念,而不是正式生产环境
- 公式化理解:
Prototype Stage = 0 → 1 \text{Prototype Stage} = 0 \to 1 Prototype Stage=0→1
表示从“无实现”到“初步可运行实现”。
- Lots of iterative development(大量迭代开发)
- Vibe Coding 适合 快速迭代,模型生成代码 → 人调试/修改 → 再生成
- 注释:
- 这种迭代模式允许开发者快速尝试不同方案
- 与传统“设计完再编码”不同,偏向 实验性开发
- 公式化理解(迭代次数 n n n):
Code n + 1 = LLM ( Code n + Feedback n ) \text{Code}_{n+1} = \text{LLM}(\text{Code}_n + \text{Feedback}_n) Coden+1=LLM(Coden+Feedbackn)
表示每次迭代由 LLM 根据前一次代码和反馈生成新代码。
- Getting a feel for the problem(感受问题本质)
- 开发者通过快速生成和运行代码来 理解问题、探索边界条件
- 注释:
- 不是直接解决最终问题,而是“试水”
- 可以理解为一种 探索式编程
- 概念化:
Understanding ≈ Interact with Code + Observe Outcomes \text{Understanding} \approx \text{Interact with Code} + \text{Observe Outcomes} Understanding≈Interact with Code+Observe Outcomes
表示通过与代码互动和观察结果来建立对问题的直觉理解。
总结
- Vibe Coding 更像是一种 实验性、探索性编程范式,适合:
- 快速原型(0>1)
- 快速迭代
- 理解问题本质
- 不适合生产环境,主要优势在 速度和探索性,劣势在 可维护性和可靠性。
另一种 AI 驱动的软件工程范式:Agentic AI
- Agentic AI–driven development(Agentic AI 驱动开发)
- 定义:Agentic AI 指的是自主或半自主的 LLM 智能体(Agents),可以执行整个开发任务链,而不仅仅是生成代码。
- 注释:
- 自主(Autonomous)意味着无需持续人工干预
- 半自主(Semi-autonomous)意味着在关键决策点仍需要人类反馈
- LLM agents that plan, decompose tasks, call tools … and iteratively ship changes with monitoring/guardrails
- 关键能力:
- Plan → 规划任务
- Decompose tasks → 将复杂目标拆解成子任务
- Call tools → 调用工具(如编译器、测试框架、文件搜索等)
- Iteratively ship changes → 迭代地提交修改
- Monitoring / guardrails → 监控和保护机制(防止错误蔓延)
- 注释:
- 与传统生成工具相比,这些智能体能自主执行整个开发循环
- 迭代性保证了可以根据中间结果动态调整策略
- 公式化表示:
Agentic_AI = f ( Plan , Decompose , ToolCall , Iterate , Monitor ) \text{Agentic\_AI} = f(\text{Plan}, \text{Decompose}, \text{ToolCall}, \text{Iterate}, \text{Monitor}) Agentic_AI=f(Plan,Decompose,ToolCall,Iterate,Monitor)
其中 f f f 表示 LLM Agent 对开发流程的映射与执行能力。
- 关键能力:
- Unlike conventional code generation tools…
- 区别:
- 传统代码生成工具:只做单步代码生成 → $ \text{Code}_{n} = \text{LLM}(\text{Prompt}) $
- Agentic 系统:可以处理多步骤、高层次目标,并根据中间反馈动态调整行为
- 注释:
- 多步骤过程 → $ \text{Goal} \rightarrow {\text{Task}_1, \text{Task}_2, …} $
- 基于反馈的适应性 →
Behavior n + 1 = g ( Behavior n , IntermediateFeedback ) \text{Behavior}_{n+1} = g(\text{Behavior}_n, \text{IntermediateFeedback}) Behaviorn+1=g(Behaviorn,IntermediateFeedback)
表示智能体会根据中间结果调整下一步行为
- 区别:
总结
- Agentic AI 的核心优势:
- 自动化规划和任务拆解
- 可调用多种开发工具
- 迭代提交,带监控和保护
- 根据中间结果动态调整策略
- Agentic AI 与 Vibe Coding 的对比:
| 特性 | Vibe Coding | Agentic AI |
|---|---|---|
| 自动化程度 | 半自动 / 人主导 | 高度自动 / 自主或半自主 |
| 任务分解 | 人类手动 | 智能体自动 |
| 工具调用 | 人类调用 | 智能体调用(编译器、测试、搜索) |
| 迭代与监控 | 人类迭代 | 智能体迭代 + 监控 / 护栏 |
| 目标适应性 | 无 | 基于中间反馈动态调整 |
AI Agents & Their Distinctions(AI 智能体及其区别)
- Autonomy(自主性): Decisions & Actions
- ****:智能体可以自主做决策和采取行动,而不需要人工每一步干预。
- 注释:
# Autonomy Example: Agent.decide_and_act(task) # 决策:选择子任务 # 行动:执行代码生成或调用工具 - 公式化:
Action n = f ( State n , Goal ) \text{Action}_n = f(\text{State}_n, \text{Goal}) Actionn=f(Staten,Goal)
表示智能体根据当前状态和目标自主决定行为。
- Interactive(交互性): tool-calling, memory, other agents
- ****:智能体可以交互式地调用外部工具(编译器、测试框架、文件搜索等)、使用记忆、与其他智能体协作。
- 注释:
Agent.call_tool("unit_test_runner") Agent.remember("parsed_files", file_list) Agent.communicate(other_agent, "share_results") - 公式化:
State n + 1 = g ( State n , ToolOutput , Memory , OtherAgents ) \text{State}_{n+1} = g(\text{State}_n, \text{ToolOutput}, \text{Memory}, \text{OtherAgents}) Staten+1=g(Staten,ToolOutput,Memory,OtherAgents)
- Iterative(迭代性): reflective, feedback from results
- ****:智能体会反思已完成的操作,并基于结果反馈调整后续行动。
- 注释:
for iteration in range(max_iterations): result = Agent.execute(task) feedback = evaluate(result) Agent.update_plan(feedback) - 公式化:
Plan n + 1 = h ( Plan n , Feedback n ) \text{Plan}_{n+1} = h(\text{Plan}_n, \text{Feedback}_n) Plann+1=h(Plann,Feedbackn)
- Goal-oriented(目标导向)
- ****:智能体始终围绕高层目标行动,而不仅仅是完成单个操作。
- 注释:
Goal = "Deliver REST API endpoint with tests & docs" Agent.plan_to_achieve(Goal)
与传统方法的区别(Different than)
| 特性 | Heuristic | Trad-ML | One-shot LLM | Agentic AI |
|---|---|---|---|---|
| 决策方式 | 基于经验规则 | 基于训练模型 | 单次生成 | 自主/半自主,迭代决策 |
| 任务范围 | 局部、单一 | 局部或统计 | 单步 | 高层目标,多任务整合 |
| 反馈使用 | 很少 | 少 | 几乎无 | 迭代,基于中间结果 |
| 工具使用 | 通常无 | 通常无 | 通常无 | 可调用多种工具 |
| 协作性 | 无 | 无 | 无 | 可与其他 agent 协作 |
示例解析
任务:
“Implement a REST API endpoint that returns the top 10 most frequently accessed URLs from a web server log file. Include unit tests and documentation.”
- 要求分析:
- 文件解析(File parsing)
- 频率统计(Frequency analysis)
- Web API 实现(REST endpoint)
- 单元测试(Unit tests)
- 文档编写(Documentation)
- Agentic AI 优势:
- 可以 拆分子任务:
Task → ParseLog , CountFreq , APIImpl , UnitTest , Doc \text{Task} \rightarrow {\text{ParseLog}, \text{CountFreq}, \text{APIImpl}, \text{UnitTest}, \text{Doc}} Task→ParseLog,CountFreq,APIImpl,UnitTest,Doc - 并 迭代执行 + 调整:
State n + 1 = g ( State n , TaskOutput n ) \text{State}_{n+1} = g(\text{State}_n, \text{TaskOutput}_n) Staten+1=g(Staten,TaskOutputn) - 最终 整合完成高层目标。
- 可以 拆分子任务:
AI Agents 与代码质量
原文摘要:
●Amount of code written scales up dramatically
Google — Pichai said “more than 30%” of new code and ~10% productivity gain (Jun 2025 Business Insider).
Microsoft CEO says up to 30% of the company’s code was written by AI (Apr 2025 TechCrunch)
- 代码量大幅增加
- 理解:AI 智能体可以在短时间内生成大量代码,这会让公司整体代码量显著增加。
- 注释:
# AI agent writing code new_code_lines = Agent.generate_code(task_list) total_code_lines += new_code_lines - 公式化表示:
Code ∗ total ( t ) = Code ∗ human ( t ) + Code ∗ AI ( t ) \text{Code}*{\text{total}}(t) = \text{Code}*{\text{human}}(t) + \text{Code}*{\text{AI}}(t) Code∗total(t)=Code∗human(t)+Code∗AI(t)
其中 Code ∗ AI ( t ) \text{Code}*{\text{AI}}(t) Code∗AI(t) 随时间快速增长,使得总代码量 Code total ( t ) \text{Code}_{\text{total}}(t) Codetotal(t) 显著增加。
- 生产力提升
- 理解:生成的代码不仅增加数量,还带来一定的生产力提升。例如:
- Google:AI 编写的代码占新增代码的 30%以上,带来约 10% 的生产力提升。
- Microsoft:AI 参与的代码占公司总代码的 30%。
- 注释:
productivity_gain = 0.10 # Google 数据 ai_code_ratio = 0.30 # Microsoft 数据 - 公式化:
Productivity ∗ total = Productivity ∗ human + Δ Productivity ∗ AI \text{Productivity}*{\text{total}} = \text{Productivity}*{\text{human}} + \Delta\text{Productivity}*{\text{AI}} Productivity∗total=Productivity∗human+ΔProductivity∗AI
其中:
Δ Productivity ∗ AI ≈ 10 \Delta\text{Productivity}*{\text{AI}} \approx 10% \times \text{baseline} ΔProductivity∗AI≈10
- 理解:生成的代码不仅增加数量,还带来一定的生产力提升。例如:
- 对代码质量的潜在影响
- 理解:尽管 AI 可以生成大量代码,提高生产力,但如果缺乏代码审查、测试或架构规划,可能会影响代码质量。
- 注释:
# 风险示例 if not Agent.code_review(new_code_lines): code_quality -= 0.05 # 假设下降 5% - 公式化:
Quality ∗ total = Quality ∗ human + Quality ∗ AI − Risk ∗ AI \text{Quality}*{\text{total}} = \text{Quality}*{\text{human}} + \text{Quality}*{\text{AI}} - \text{Risk}*{\text{AI}} Quality∗total=Quality∗human+Quality∗AI−Risk∗AI
其中 Risk AI \text{Risk}_{\text{AI}} RiskAI 代表 AI 自动生成代码带来的潜在缺陷和技术债。
总结
- 优势:AI agents 可以显著提升代码产出和生产力。
- 注意事项:随着代码量增加,需要更多监控、测试和质量控制,以避免技术债积累。
- 公式概念:
Code Productivity ∼ Code Amount × Quality Factor \text{Code Productivity} \sim \text{Code Amount} \times \text{Quality Factor} Code Productivity∼Code Amount×Quality Factor
增加代码量不等于生产力提升,必须配合质量控制。
AI Agents 与代码质量
| Metric (指标) | Resolved Mean (已解决均值) | Unresolved Mean (未解决均值) | Mann-Whitney U Test p-value | Significance (显著性) |
|---|---|---|---|---|
| 1. Problem Statements | ||||
| Flesch_Reading_Ease | 35.63 | 38.91 | 0.2425 | ✘ |
| Flesch_Kincaid_Grade | 11.40 | 10.81 | 0.2219 | ✘ |
| Sentence_Count | 27.46 | 37.22 | 0.0175 | ✓ |
| Word_Count | 178.72 | 209.86 | 0.0015 | ✓ |
| Contains_Code_Snippets | 0.45 | 0.48 | 0.5130 | ✘ |
| Number_of_Code_Blocks | 1.08 | 1.18 | 0.5295 | ✘ |
| Lines_of_Code | 14.44 | 18.56 | 0.47 | ✘ |
| Code_to_Text_Ratio | 0.24 | 0.24 | 0.7960 | ✘ |
| 2. Associated Source Code Files (Gold Patch Based) | ||||
| Code_Files_Count | 1.09 | 1.53 | 3.53e-11 | ✓ |
| Lines_of_Code | 703.13 | 1087.38 | 0.0062 | ✓ |
| Code_Cyclomatic_Complexity | 192.25 | 303.12 | 0.0067 | ✓ |
| 3. Gold Patch Solutions | ||||
| Total_Lines_Change | 9.29 | 24.12 | 1.67e-09 | ✓ |
| Net_Code_Size_Change | 3.22 | 10.08 | 9.18e-06 | ✓ |
原文摘要:
AI agents perform better if code is less complex and or fewer quality issues
理解:
- AI 智能体在处理代码任务时,如果原始代码更简单或者存在的质量问题更少,其表现会更好。
- 换句话说,代码复杂度和质量问题是 AI agent 成功的负向因子(Complexity ↑ 或 Bugs ↑ → AI 成功率 ↓)。
公式化概念:
AI_Performance ∝ 1 Complexity + Quality_Issues \text{AI\_Performance} \propto \frac{1}{\text{Complexity} + \text{Quality\_Issues}} AI_Performance∝Complexity+Quality_Issues1
即复杂度和质量问题越少,AI 性能越高。
表格分析(Metric vs Resolved / Unresolved)
表格描述了不同指标下,AI agent 是否能解决问题(Resolved vs Unresolved)之间的统计差异。
1. 问题陈述 (Problem Statements)
| 指标 | 已解决均值 | 未解决均值 | Mann-Whitney U p-value | 显著性 |
|---|---|---|---|---|
| Flesch_Reading_Ease | 35.63 | 38.91 | 0.2425 | ✘ |
| Flesch_Kincaid_Grade | 11.40 | 10.81 | 0.2219 | ✘ |
| Sentence_Count | 27.46 | 37.22 | 0.0175 | ✓ |
| Word_Count | 178.72 | 209.86 | 0.0015 | ✓ |
| Contains_Code_Snippets | 0.45 | 0.48 | 0.5130 | ✘ |
| Number_of_Code_Blocks | 1.08 | 1.18 | 0.5295 | ✘ |
| Lines_of_Code | 14.44 | 18.56 | 0.47 | ✘ |
| Code_to_Text_Ratio | 0.24 | 0.24 | 0.7960 | ✘ |
解读与注释:
- Sentence_Count / Word_Count 显著影响 AI 成功率(p < 0.05):
- 已解决问题的句子数更少(27 vs 37)、单词数更少(179 vs 210)
- 说明问题描述越简洁,AI agent 越容易理解和解决。
- 其他指标(可读性、代码片段数量、代码比例等)未显示显著影响。
公式化表示:
AI_Success ∼ 1 Sentence_Count + Word_Count \text{AI\_Success} \sim \frac{1}{\text{Sentence\_Count} + \text{Word\_Count}} AI_Success∼Sentence_Count+Word_Count1
2. 关联源码文件 (Associated Source Code Files)
| 指标 | 已解决均值 | 未解决均值 | p-value | 显著性 |
|---|---|---|---|---|
| Code_Files_Count | 1.09 | 1.53 | 3.53e-11 | ✓ |
| Lines_of_Code | 703.13 | 1087.38 | 0.0062 | ✓ |
| Code_Cyclomatic_Complexity | 192.25 | 303.12 | 0.0067 | ✓ |
解读与注释:
- 已解决问题的代码文件数量较少(1.09 vs 1.53),总行数较少(703 vs 1087),圈复杂度较低(192 vs 303)
- 说明 AI agent 在处理小型、简单的代码文件时表现更好。
- 代码复杂度(Cyclomatic Complexity)越高,AI 成功率下降。
公式化:
AI_Success ∼ 1 Code_Files_Count × Lines_of_Code × Cyclomatic_Complexity \text{AI\_Success} \sim \frac{1}{\text{Code\_Files\_Count} \times \text{Lines\_of\_Code} \times \text{Cyclomatic\_Complexity}} AI_Success∼Code_Files_Count×Lines_of_Code×Cyclomatic_Complexity1
3. 金标准修补方案 (Gold Patch Solutions)
| 指标 | 已解决均值 | 未解决均值 | p-value | 显著性 |
|---|---|---|---|---|
| Total_Lines_Change | 9.29 | 24.12 | 1.67e-09 | ✓ |
| Net_Code_Size_Change | 3.22 | 10.08 | 9.18e-06 | ✓ |
解读与注释:
- 已解决问题所需修改的总行数(Total_Lines_Change)更少(9.29 vs 24.12)
- 净代码变更量(Net_Code_Size_Change)也更少(3.22 vs 10.08)
- 说明 AI agent 更容易完成小幅度、低侵入的修复任务,而大型改动则难度更高。
公式化:
AI_Success ∼ 1 Total_Lines_Change + Net_Code_Size_Change \text{AI\_Success} \sim \frac{1}{\text{Total\_Lines\_Change} + \text{Net\_Code\_Size\_Change}} AI_Success∼Total_Lines_Change+Net_Code_Size_Change1
总结
- 关键发现:
- AI agent 对简单、短小、低复杂度、低变更量的代码任务表现最佳。
- 大型、复杂或需要大规模改动的任务,AI agent 成功率明显下降。
- 成功率公式化概念:
AI_Success ∝ 1 Problem_Size + Code_Complexity + Patch_Size \text{AI\_Success} \propto \frac{1}{\text{Problem\_Size} + \text{Code\_Complexity} + \text{Patch\_Size}} AI_Success∝Problem_Size+Code_Complexity+Patch_Size1
其中:
- Problem_Size = Sentence_Count + Word_Count
- Code_Complexity = Cyclomatic_Complexity × Lines_of_Code × Code_Files_Count
- Patch_Size = Total_Lines_Change + Net_Code_Size_Change
- 应用启示:
- 为了让 AI agents 更高效,建议简化问题描述、降低代码复杂度、拆小任务。
- 在大规模、复杂系统中,AI agents 更适合做迭代性小修小补,而非一次性大重构。
Single-Agent Code Generation(单智能体代码生成)**
Planning and Reasoning Techniques规划与推理技术
核心概念:
- 显式规划(Explicit Planning)是提升 LLM 结构化推理能力的关键方法。
- 思路:在生成可执行代码之前,先生成高层次的解决步骤(high-level plan),再逐步实现每一步。
主要方法与贡献:
- Self-Planning
- 首个系统化引入规划阶段的方法。
- 流程:
- 生成高层步骤序列
- 按步骤生成代码
- 优点:复杂问题可分解,降低代码综合难度。
- CodeChain
- 引入聚类与自我修订(self-revision)
- 支持多轮迭代生成可复用模块化代码。
- CodeAct
- 将所有动作统一为可执行 Python 代码(unified action space)
- 集成 Python 解释器,实现即时执行 + 实时反馈 + 动态调整。
- KareCoder
- 将外部知识库注入 LLM 的规划和推理流程。
- WebAgent
- 面向网页自动化任务的三阶段策略:
- 指令分解
- HTML 内容摘要
- 程序合成
- 面向网页自动化任务的三阶段策略:
- CodePlan
- 多阶段控制流 + 自定义控制指令
- 动态选择“生成(generate)”或“修改(modify)”操作
- GIF-MCTS
- 将蒙特卡洛树搜索(MCTS)引入代码生成
- 多路径探索,结合执行反馈进行评分和筛选,提高模型多解任务的稳健性和泛化能力
- PlanSearch
- 将规划形式化为显式搜索任务
- 生成多组候选计划,并行评估找到最优解
- CodeTree / Tree-of-Code
- 从线性结构扩展为树结构规划
- CodeTree:分阶段生成 → 执行反馈 → 启发式剪枝
- Tree-of-Code:多路径宽度优先探索 + 执行信号剪枝
- DARS / VerilogCoder / Guided Search
- DARS:自适应树结构 + 历史轨迹与执行反馈结合
- VerilogCoder:图结构规划 + 波形跟踪,支持 Verilog 硬件建模
- Guided Search:预测候选动作价值,进行单步前瞻与轨迹选择
核心总结:
- 规划技术的发展趋势:
- 单路径 → 多路径探索
- 线性 → 结构化规划(树/图)
- 提升了单智能体生成的效果和灵活性
公式化概念:
Code_Output = f ( Plan , Execution_Feedback , Iteration ) \text{Code\_Output} = f(\text{Plan}, \text{Execution\_Feedback}, \text{Iteration}) Code_Output=f(Plan,Execution_Feedback,Iteration) - Plan:高层解决步骤
- Execution_Feedback:即时执行信号
- Iteration:多轮优化
4.1.2 Tool Integration and Retrieval Enhancement(工具集成与检索增强)
核心概念:
- 单智能体通过集成外部工具或检索机制,可以突破自身生成能力的限制,提高准确性和效率。
主要方法与贡献:
- ToolCoder / ToolGen
- API 查询工具集成
- 自动标注训练数据,减少模型幻觉导致的 API 调用错误
- 解决依赖问题(未定义变量 / 成员错误)
- CodeAgent
- 集成五类工具(网站搜索、文档阅读、符号导航、格式检查、代码解释器)
- 支持信息检索、代码实现、测试
- ROCODE / CodeTool
- ROCODE:闭环机制 + 语法错误检测 + 自适应回溯
- CodeTool:显式建模每一步工具调用,增量调试集成反馈
- RAG(Retrieval-Augmented Generation)方法
- 先从知识库 / 代码仓库检索信息,再生成代码
- 方法示例:RepoHyper(向量检索),CodeNav(自动索引历史仓库),AUTOPATCH(运行时优化结合 CFG)
- 知识图谱增强(Knowledge Graph-Based)提升上下文结构化表达
- cAST:基于 AST 分块,递归合并,提升语法完整性与 Recall / Pass@1
- 领域特化工具
- AnalogCoder:模拟电路任务,封装仿真函数与模型接口
- VerilogCoder:硬件代码生成,跨阶段逻辑验证 + AST 波形跟踪
核心总结:
- 工具集成 + 检索增强显著扩展了模型感知范围与执行能力
- 提高生成准确性、效率与一致性
- 可从通用任务到领域任务迁移
公式化概念:
Code_Output = f ( LLM_Knowledge , External_Tools , Retrieved_Context ) \text{Code\_Output} = f(\text{LLM\_Knowledge}, \text{External\_Tools}, \text{Retrieved\_Context}) Code_Output=f(LLM_Knowledge,External_Tools,Retrieved_Context)
4.1.3 Reflection and Self-Improvement(反思与自我改进)
核心概念:
- 与一次性生成(one-shot generation)不同,反思与自我改进机制使模型能够自我检查、反馈、迭代优化。
主要方法与贡献:
- SelfRefine
- 自然语言自我评估 → 修正生成输出
- 不需额外训练或监督
- Self-Iteration
- 引入软件开发角色(分析员、设计师、开发者、测试者)
- 每轮迭代根据反馈修正模块结构,提高可读性和功能完整性
- Self-Debug / Self-Edit / Self-Repair
- Self-Debug:类似“橡皮鸭调试”,逐行解释代码,自动定位错误
- Self-Edit:结合执行反馈,二次编辑生成代码
- Self-Repair:结合反馈模型进行程序修复
- CodeChain / LeDeX
- CodeChain:模块化自我修订,识别 & 聚类子模块 → 增强后续生成
- LeDeX:闭环自我调试,逐步注释 & 修复错误,并收集训练数据用于模型微调
核心总结:
- 自我反思机制形成完整技术体系:
- 自然语言自我反馈 → 执行结果自动修复 → 模块化优化 & 多解评估
- 提高单智能体生成性能,为推理时计算扩展(test-time scaling)和多智能体协作奠定基础
公式化概念:
Code_Output _ t + 1 = Refine ( Code_Output _ t , Self_Feedback , Execution_Results ) \text{Code\_Output}\_{t+1} = \text{Refine}(\text{Code\_Output}\_t, \text{Self\_Feedback}, \text{Execution\_Results}) Code_Output_t+1=Refine(Code_Output_t,Self_Feedback,Execution_Results) - t t t:迭代轮次
- Self_Feedback:模型内部评估
- Execution_Results:运行反馈
总结
| 子模块 | 核心作用 | 技术趋势 / 方法 |
|---|---|---|
| Planning & Reasoning | 分解复杂问题、提升推理能力 | Self-Planning, GIF-MCTS, CodeTree, DARS |
| Tool Integration | 扩展感知范围与执行能力 | ToolCoder, CodeAgent, ROCODE, RAG, cAST |
| Reflection & Self-Improvement | 自动检测、修正、迭代优化 | SelfRefine, Self-Debug, CodeChain, LeDeX |
总体规律:
- 单智能体生成逐步从线性 → 结构化规划
- 从单路径 → 多路径探索
- 外部工具集成 + 检索增强 → 提升任务覆盖与准确性
- 自我反思与迭代 → 提升代码正确性、模块化和可维护性
图解理解:单智能体代码生成方法
1⃣ 左侧:Single-Agent Code Generation(单智能体代码生成概览)
- Query(输入任务)
- 示例:
Create a quick-sort algorithm in Python. - 对应文本中的单智能体接收自然语言任务阶段。
- 示例:
- LLM-Based Agent(基于 LLM 的智能体)
- 模型核心,负责理解任务、执行规划、调用工具、生成代码。
- 图中三个箭头向下表示三个主要模块:
- Planning(规划)
- Tools(工具)
- Reflection(反思/自我改进)
- Output(输出)
- 初步生成的代码,例如 QuickSort 算法。
公式化:
Initial_Code = Agent ( Query ) \text{Initial\_Code} = \text{Agent}(\text{Query}) Initial_Code=Agent(Query)
- 初步生成的代码,例如 QuickSort 算法。
2⃣ 右上:Planning and Reasoning Techniques(规划与推理)
- Planned Path Generation(生成候选计划路径)
- 将任务分解为高层次步骤 → 避免一次性生成复杂代码。
- Candidate Branch Selection(候选分支选择)
- 类似 GIF-MCTS / PlanSearch 的多路径探索与评分筛选。
- Plan(计划模块)
- 树状或多阶段规划结构(CodeTree / Tree-of-Code)
- 动态执行反馈用于优化选择
公式化:
Optimal_Plan = SelectBest ( Candidate_Plans , Execution_Feedback ) \text{Optimal\_Plan} = \text{SelectBest}(\text{Candidate\_Plans}, \text{Execution\_Feedback}) Optimal_Plan=SelectBest(Candidate_Plans,Execution_Feedback)
3⃣ 中右:Tool Integration & Retrieval Enhancement(工具集成与检索增强)
- External Tool Integration(外部工具集成)
- 编译器(Compiler)、在线搜索(API)、静态分析(Static Analysis)
- 对应文本中 CodeAgent / ToolCoder / ROCODE 等方法。
- RAG(Retrieval Augmented Generation)
- Step 1: 向量数据库检索
- Step 2: Prompt 增强
- Step 3: 基于 LLM 的代码生成
- 对应文本中的 RepoHyper / CodeNav / AUTOPATCH / cAST 方法。
公式化:
Enhanced_Context = Retrieve ( KnowledgeBase , Query ) \text{Enhanced\_Context} = \text{Retrieve}(\text{KnowledgeBase}, \text{Query}) Enhanced_Context=Retrieve(KnowledgeBase,Query)
Generated_Code = Agent ( Query , Enhanced_Context , External_Tools ) \text{Generated\_Code} = \text{Agent}(\text{Query}, \text{Enhanced\_Context}, \text{External\_Tools}) Generated_Code=Agent(Query,Enhanced_Context,External_Tools)
4⃣ 右下:Reflection and Self-Improvement(反思与自我改进)
- Generated Code(生成代码)
- 初次生成的 QuickSort 算法。
- Feedback(反馈 / Failure Diagnosis)
- 例如“Numbers should be sorted in ascending order”
- 对应 SelfRefine / Self-Debug / Self-Repair / CodeChain / LeDeX 方法。
- Autonomous Refinement(自主迭代优化)
- 模型根据反馈修正代码 → 生成最终高质量代码。
公式化:
Final_Code t + 1 = Refine ( Generated_Code t , Feedback ) \text{Final\_Code}_{t+1} = \text{Refine}(\text{Generated\_Code}_t, \text{Feedback}) Final_Codet+1=Refine(Generated_Codet,Feedback)
- 模型根据反馈修正代码 → 生成最终高质量代码。
5⃣ 总体流程概览
- 输入任务 → LLM Agent
- 规划(Planning) → 高层次步骤分解 + 多路径搜索
- 工具调用(Tools) → 编译器、API、静态分析、检索增强
- 代码生成(Generate Code)
- 自我反思与优化(Reflection) → Feedback → Iterative Refinement
- 输出最终代码(Output)
整体公式化:
Final_Code = Agent ( Query , Plan , External_Tools , Self_Reflection ) \text{Final\_Code} = \text{Agent}(\text{Query}, \text{Plan}, \text{External\_Tools}, \text{Self\_Reflection}) Final_Code=Agent(Query,Plan,External_Tools,Self_Reflection)
✓ 图中颜色与含义对应:
- 橙色:整体单智能体流程
- 蓝色:Planning & Reasoning(规划路径)
- 绿色:Tool Integration & RAG(工具与检索增强)
- 紫色:Reflection & Self-Improvement(自我迭代优化)
多智能体代码生成系统理解
多智能体系统的核心思想是:将复杂代码生成任务分解为多个协作智能体,通过不同策略提升效率、准确性和鲁棒性。核心机制包括:流水线分工、层级规划、循环优化、自我演化。
1⃣ Pipeline-based Labor Division(流水线式分工)
- 基本思想:每个智能体负责软件开发的某一阶段,输出交给下一个智能体,典型流程有:
- Requirement Analysis → Coding → Testing
- 代表系统:
- Self-Collaboration [15]:三阶段流水线,独立任务完成 → 顺序执行。
- AgentCoder [71]:三阶段流水线,程序员、测试设计师、测试执行者。
- CodePori [99]:多角色流水线:
- Manager:解析自然语言需求 → 分解任务
- Developer:多智能体并行实现模块代码
- Finalizer:优化代码
- Verifier:集成测试
- MAGIS [100]:模拟 GitHub 项目管理 → Issue 跟踪、任务分配、代码修复。
- HyperAgent [72]:跨语言、跨任务 → Planner + Navigator + Code Editor + Executor,加入自动工具链检索。
优点:
- 流程清晰,责任明确
- 易于调试
缺点: - 任务高度串行,依赖前序结果
- 缺乏全局反馈优化
公式化:
Stage ∗ i + 1 = Agent ∗ i ( Stage i O u t p u t ) \text{Stage}*{i+1} = \text{Agent}*{i}(\text{Stage}_{i_{Output}}) Stage∗i+1=Agent∗i(StageiOutput)
流水线输出是前一阶段智能体生成的代码或中间产物。
2⃣ Hierarchical Planning Execution(层级规划执行)
- 高层智能体负责任务分解,低层智能体执行具体实现。
- 代表系统:
- PairCoder [101]:模拟配对编程:
- Navigator:规划策略 → 选择最优方案
- Driver:执行代码生成、测试、优化
- FlowGen [102]:四层架构,模拟 Waterfall、TDD、Scrum 等流程。
公式化:
LowLevel_Agent_Output = LowAgent ( HighAgent ( Task ) ) \text{LowLevel\_Agent\_Output} = \text{LowAgent}(\text{HighAgent}(\text{Task})) LowLevel_Agent_Output=LowAgent(HighAgent(Task))
- PairCoder [101]:模拟配对编程:
3⃣ Self-Negotiation Circular Optimization(自我协商循环优化)
- 多智能体循环协作:生成 → 评估 → 修复 → 再迭代。
- 代表系统:
- MapCoder [104]:四个智能体循环:
- Recall 相关例子
- 制定方案
- 生成代码
- Debug 修复
- MapCoder [104]:四个智能体循环:
- AutoSafeCoder [105]:Coder + Static Analyzer + Fuzzer → 静态 & 动态安全检测反馈修正。
- QualityFlow [106]:生成单元测试 → LLM质量检查 → 执行测试
- CodeCoR [12]:中间阶段增加“反思”智能体 → 评分和定位问题 → 反馈优化
公式化:
Code t + 1 = Agent ( Code t , Feedback t ) \text{Code}_{t+1} = \text{Agent}(\text{Code}_t, \text{Feedback}_t) Codet+1=Agent(Codet,Feedbackt)
其中 t t t 表示迭代轮次。
4⃣ Self-Evolving Structural Updates(自我演化结构更新)
- 系统可以 动态调整智能体结构和行为策略,不依赖固定流水线。
- 代表系统:
- SEW [108]:根据协作效果和失败反馈,动态重组通信路径与职责分工
- EvoMAC [109]:借鉴神经网络训练 → 将环境反馈转化为“文本反向传播”,自动调整智能体协作结构
公式化:
Agent_Structure t + 1 = Evolve ( Agent_Structure t , Performance_Feedback ) \text{Agent\_Structure}_{t+1} = \text{Evolve}(\text{Agent\_Structure}_t, \text{Performance\_Feedback}) Agent_Structuret+1=Evolve(Agent_Structuret,Performance_Feedback)
5⃣ Role-Playing for Collaboration(角色扮演提升协作效率)
- 给智能体指定特定身份 → 程序员、测试员、项目经理等
- 改善行为一致性与任务执行效果
- 代表系统:
- ChatDev [16]:程序员、审查员、测试员
- MetaGPT [17]:产品经理、架构师、项目经理、工程师 → 模拟完整软件公司组织
机制:
- Prompt 指定智能体角色信息
- 包含任务分工、输入/输出格式、接口调用方式等
公式化:
Agent_Action = Agent ( Task , Role_Prompt ) \text{Agent\_Action} = \text{Agent}(\text{Task}, \text{Role\_Prompt}) Agent_Action=Agent(Task,Role_Prompt)
6⃣ 总结多智能体系统特点
| 特性 | 描述 | 代表系统 |
|---|---|---|
| 流水线分工 | 阶段化、顺序执行 | Self-Collaboration, AgentCoder, CodePori, MAGIS, HyperAgent |
| 层级规划 | 高层规划,低层执行 | PairCoder, FlowGen, MAGE |
| 循环优化 | 生成 → 评估 → 修复迭代 | MapCoder, AutoSafeCoder, QualityFlow, CodeCoR |
| 自我演化 | 动态调整智能体结构 | SEW, EvoMAC |
| 角色扮演 | 提高协作一致性 | ChatDev, MetaGPT |
| 核心公式概览: |
- 流水线分工:
Stage ∗ i + 1 = Agent ∗ i ( Stage i Output ) \text{Stage}*{i+1} = \text{Agent}*{i}(\text{Stage}_{i_\text{Output}}) Stage∗i+1=Agent∗i(StageiOutput) - 层级规划执行:
LowLevel_Agent_Output = LowAgent ( HighAgent ( Task ) ) \text{LowLevel\_Agent\_Output} = \text{LowAgent}(\text{HighAgent}(\text{Task})) LowLevel_Agent_Output=LowAgent(HighAgent(Task)) - 循环优化:
Code t + 1 = Agent ( Code t , Feedback t ) \text{Code}_{t+1} = \text{Agent}(\text{Code}_t, \text{Feedback}_t) Codet+1=Agent(Codet,Feedbackt) - 自我演化:
Agent_Structure t + 1 = Evolve ( Agent_Structure t , Performance_Feedback ) \text{Agent\_Structure}_{t+1} = \text{Evolve}(\text{Agent\_Structure}_t, \text{Performance\_Feedback}) Agent_Structuret+1=Evolve(Agent_Structuret,Performance_Feedback) - 角色扮演:
Agent_Action = Agent ( Task , Role_Prompt ) \text{Agent\_Action} = \text{Agent}(\text{Task}, \text{Role\_Prompt}) Agent_Action=Agent(Task,Role_Prompt)
Fig.4 多智能体代码生成系统总览解析
这个 SVG 图分为 左侧示例输入输出流程 和 右侧多智能体系统工作流与优化机制 两大部分。
1⃣ 左侧:多智能体代码生成流程示例
Query Box(用户请求)
# 用户输入需求
Set up a RESTful API in Flask with a login endpoint and JWT authentication.
- 表示用户提出自然语言需求。
- 箭头向下连接到 Multi-Agent System。
Multi-Agent System(智能体系统)
- 三个智能体(Agent1、Agent2、Agent3)协作生成代码。
- 每个智能体负责不同功能或模块,模拟并行工作。
- 图中小圆圈和表情表示智能体内部状态。
代码示意:
class Agent:
def __init__(self, role):
self.role = role # 角色: planner, coder, tester
def act(self, input_data):
# 根据角色执行任务
if self.role == "coder":
return self.generate_code(input_data)
elif self.role == "tester":
return self.run_tests(input_data)
Workflow / Context / Collaboration Boxes
- Workflow(工作流管理)
- 图标中旋转齿轮表示任务执行流程。
- 智能体依照工作流完成任务。
- 对应流水线分工和层级规划。
- Context Management(上下文管理)
- 图标 RAM 表示存储任务信息、生成历史。
- 便于智能体共享中间结果。
- 可用公式表示:
Context t + 1 = Update ( Context t , AgentOutput t ) \text{Context}_{t+1} = \text{Update}(\text{Context}_t, \text{AgentOutput}_t) Contextt+1=Update(Contextt,AgentOutputt)
- Collaboration(协作机制)
- 图标显示两个人形连接线,表示智能体间通信。
- 多智能体通过共享信息、互评和同步状态完成复杂任务。
Output Box(输出代码示例)
@app.route('/login', methods=['POST'])
def login():
# Validate user credentials
# Return JWT token on success
- 智能体协作生成的最终可执行代码。
- 说明系统支持从自然语言到可执行程序的完整闭环。
2⃣ 右侧:Multi-Agent System Workflows(工作流机制)
Pipeline-Based(流水线分工)
- Planner → Editor → Executor
- 对应 Self-Collaboration、AgentCoder 等系统。
- 公式:
Stage i + 1 = Agent i ( Stage i Output ) \text{Stage}_{i+1} = \text{Agent}_i(\text{Stage}_{i_\text{Output}}) Stagei+1=Agenti(StageiOutput) - 每个智能体只专注自己阶段任务。
Hierarchical(层级规划)
- High-level Task Planning → Low-level Execution
- 对应 PairCoder、FlowGen。
- 公式:
LowLevelOutput = LowAgent ( HighAgent ( Task ) ) \text{LowLevelOutput} = \text{LowAgent}(\text{HighAgent}(\text{Task})) LowLevelOutput=LowAgent(HighAgent(Task))
Self-Negotiation(自我协商循环优化)
- Code Generation ↔ Reflection ↔ Optimization 循环
- 对应 MapCoder、AutoSafeCoder。
- 公式:
Code t + 1 = Agent ( Code t , Feedback t ) \text{Code}_{t+1} = \text{Agent}(\text{Code}_t, \text{Feedback}_t) Codet+1=Agent(Codet,Feedbackt)
Self-Evolving(自我演化)
- Edit → Execute → Self-Evolve 循环
- 系统自动调整智能体结构和策略
- 对应 SEW、EvoMAC。
- 公式:
Agent_Structure t + 1 = Evolve ( Agent_Structure t , PerformanceFeedback ) \text{Agent\_Structure}_{t+1} = \text{Evolve}(\text{Agent\_Structure}_t, \text{PerformanceFeedback}) Agent_Structuret+1=Evolve(Agent_Structuret,PerformanceFeedback)
Context Management & Memory Technologies
- 技术列表:
- Blackboard Model(黑板模型)
- Decoupled Modules(解耦模块)
- Brain-Like Mechanism(类脑机制)
- Dynamic Agent Numbers(智能体动态调整)
- Dual Collaboration(双向协作)
- Declarative Memory Modules(声明式记忆模块)
- 公式化上下文管理:
Context t + 1 = MemoryModule ( AgentOutput t , Context t ) \text{Context}_{t+1} = \text{MemoryModule}(\text{AgentOutput}_t, \text{Context}_t) Contextt+1=MemoryModule(AgentOutputt,Contextt)
Collaborative Optimization(协作优化)
- Multi-Agent Collaboration → Data Collection → Evaluation → Synchronization → Discussion → Optimize Collaboration
- 对应 QualityFlow、CodeCoR。
- 公式:
Collaboration t + 1 = Optimize ( Collaboration t , Feedback ) \text{Collaboration}_{t+1} = \text{Optimize}(\text{Collaboration}_t, \text{Feedback}) Collaborationt+1=Optimize(Collaborationt,Feedback)
总结公式总览
- 流水线:
Stage i + 1 = Agent i ( Stage i Output ) \text{Stage}_{i+1} = \text{Agent}_i(\text{Stage}_{i_\text{Output}}) Stagei+1=Agenti(StageiOutput) - 层级规划:
LowLevelOutput = LowAgent ( HighAgent ( Task ) ) \text{LowLevelOutput} = \text{LowAgent}(\text{HighAgent}(\text{Task})) LowLevelOutput=LowAgent(HighAgent(Task)) - 循环优化:
Code t + 1 = Agent ( Code t , Feedback t ) \text{Code}_{t+1} = \text{Agent}(\text{Code}_t, \text{Feedback}_t) Codet+1=Agent(Codet,Feedbackt) - 自我演化:
Agent_Structure t + 1 = Evolve ( Agent_Structure t , PerformanceFeedback ) \text{Agent\_Structure}_{t+1} = \text{Evolve}(\text{Agent\_Structure}_t, \text{PerformanceFeedback}) Agent_Structuret+1=Evolve(Agent_Structuret,PerformanceFeedback) - 角色扮演 + 协作:
Agent_Action = Agent ( Task , Role_Prompt ) \text{Agent\_Action} = \text{Agent}(\text{Task}, \text{Role\_Prompt}) Agent_Action=Agent(Task,Role_Prompt)
LLM-based Code Generation Agents 应用总览(解析)
- Root(根节点):LLM 智能体在软件开发中的应用总览。
- 作用:说明整棵知识树的顶层主题。
5.1 Automated Code Generation and Implementation(自动化代码生成与实现)
Generation and
Implementation 5.1"] A1 --> A1_1["Function-Level
Code Generation"] A1 --> A1_2["Repository-Level
Code Generation"]
子节点解释:
- Function-Level Code Generation(函数级代码生成)
- 生成单个函数或方法的代码。
- 典型系统:
Self-Planning [10], LATS [115], Lemur [117], CodeChain [11], MapCoder [102], FlowGen [100], PairCoder [99], CodeTree [81], CodeCoR [12], QualityFlow [26], CodeSim [118], DARS [83], SEW [106] - 代码片段示意:
def add(a, b): # LLM智能体生成的函数 return a + b - 公式化表示函数级生成:
f i = Agent ( FunctionSpec i ) f_i = \text{Agent}(\text{FunctionSpec}_i) fi=Agent(FunctionSpeci)
- Repository-Level Code Generation(仓库级代码生成)
- 生成整个代码库的模块化代码。
- 系统示例:
Self-Collaboration[15], ChatDev[16], Webagent[78], MetaGPT[17], CodePlan[79], CodeAgent[28], CodePoRi[13], GameGPT[110], CodeS[119], SoA[27], ToolGen[29], AgileCoder[120], AgileAgent[14] - 公式化表示仓库级生成:
RepoOutput = ∑ i = 1 N Agent i ( ModuleSpec i ) \text{RepoOutput} = \sum_{i=1}^{N} \text{Agent}_i(\text{ModuleSpec}_i) RepoOutput=i=1∑NAgenti(ModuleSpeci)
5.2 Automated Debugging and Program Repair(自动化调试与程序修复)
Debugging and
Program Repair 5.2"]
- 智能体用于自动发现和修复代码中的 bug。
- 系统示例:
Self-Refine[74], Self-Debug[94], Self-Edit[75], Self-Repair[95],
RepairAgent[121], AutoCodeRover[122], SWE-Agent[123], MAGIS[98],
AutoSafeCoder[124], SWE-Search[125], HyperAgent[71], SQLFixAgent[126],
OrcaLoca[127], PatchPilot[128], Thinking-Longer[129], AdverIntentAgent[130],
Nemotron-CORTEXA[131]
- 循环优化公式:
Code t + 1 = Agent ( Code t , BugFeedback t ) \text{Code}_{t+1} = \text{Agent}(\text{Code}_t, \text{BugFeedback}_t) Codet+1=Agent(Codet,BugFeedbackt) - 示意代码:
def fix_bug(code):
# LLM分析代码,自动修复
# 1. 找到错误行
# 2. 生成修复代码
return repaired_code
5.3 Automated Test Code Generation(自动化测试代码生成)
Code Generation 5.3"] A3 --> A3_1["Automated Test
Case Generation"] A3 --> A3_2["Automated
Execution and
Analysis"]
- Automated Test Case Generation
- 生成单元测试或集成测试代码。
- 系统示例:
TestPilot[31], CANDOR[32], XUAT-Copilot[20], LogiAgent[21], SeedMind[35], ACH[36] - 公式:
TestCases = Agent ( CodeSpec , Requirements ) \text{TestCases} = \text{Agent}(\text{CodeSpec}, \text{Requirements}) TestCases=Agent(CodeSpec,Requirements)
- Automated Execution and Analysis
- 自动执行测试,分析结果。
- 系统示例:
AUITestAgent[132], HEPH[133] - 示意代码:
results = run_tests(code, test_cases) evaluate(results)
5.4 Automated Code Refactoring and Optimization(自动化代码重构与优化)
Refactoring and
Optimization 5.4"] A4 --> A4_1["Structural Code
Refactoring"] A4 --> A4_2["Code Performance
Optimization"]
- Structural Code Refactoring
- 改进代码结构、可维护性。
- 系统示例:
DataClump-Pipeline[22], iSMELL[134], EM-assist[135], HaskellAgent[136]
- Code Performance Optimization
- 提升性能(执行效率、内存占用等)。
- 系统示例:
AIDE[137], MARCO[105], LASSI-EE[33], SysLLMatic[34] - 公式化:
OptimizedCode = Agent ( Code , PerformanceMetrics ) \text{OptimizedCode} = \text{Agent}(\text{Code}, \text{PerformanceMetrics}) OptimizedCode=Agent(Code,PerformanceMetrics)
5.5 Automated Requirement Clarification(自动化需求澄清)
Requirement
Clarification 5.5"]
- 智能体与用户交互,理解模糊需求。
- 系统示例:
MARE[116], ClarifyGPT[19], TiCoder[138], SpecFix[139], InterAgent[140], HiLDe[141]
- 交互公式化:
ClarifiedReq = Agent ( UserQuery , Context ) \text{ClarifiedReq} = \text{Agent}(\text{UserQuery}, \text{Context}) ClarifiedReq=Agent(UserQuery,Context) - 示意交互代码:
def clarify_requirement(user_input):
# LLM与用户对话,澄清需求
return clarified_spec
总结与公式概览
- 函数级生成:
f i = Agent ( FunctionSpec i ) f_i = \text{Agent}(\text{FunctionSpec}_i) fi=Agent(FunctionSpeci) - 仓库级生成:
RepoOutput = ∑ i = 1 N Agent i ( ModuleSpec i ) \text{RepoOutput} = \sum_{i=1}^{N} \text{Agent}_i(\text{ModuleSpec}_i) RepoOutput=i=1∑NAgenti(ModuleSpeci) - 自动调试/修复循环:
Code t + 1 = Agent ( Code t , BugFeedback t ) \text{Code}_{t+1} = \text{Agent}(\text{Code}_t, \text{BugFeedback}_t) Codet+1=Agent(Codet,BugFeedbackt) - 测试生成:
TestCases = Agent ( CodeSpec , Requirements ) \text{TestCases} = \text{Agent}(\text{CodeSpec}, \text{Requirements}) TestCases=Agent(CodeSpec,Requirements) - 优化/重构:
OptimizedCode = Agent ( Code , PerformanceMetrics ) \text{OptimizedCode} = \text{Agent}(\text{Code}, \text{PerformanceMetrics}) OptimizedCode=Agent(Code,PerformanceMetrics) - 需求澄清:
ClarifiedReq = Agent ( UserQuery , Context ) \text{ClarifiedReq} = \text{Agent}(\text{UserQuery}, \text{Context}) ClarifiedReq=Agent(UserQuery,Context)
Coding LLMs(代码生成型大语言模型)解析
1. 典型代码生成 LLM
- Codex
- CodeLlama
- DeepSeek-Coder
- Qwen2.5-Coder
这些模型专门针对代码生成进行优化,属于 LLM 在软件开发领域的应用分支。
2. 训练数据来源与学习能力
- 训练数据:
- 大量高质量开源代码库(Open-source code libraries)
- 程序设计文档(Programming documentation)
- 模型能力:
- 学习多种编程语言的语法规则
- 例如 Python、Java、C++ 等
- 代码示意:
# Python语法示例 def add(a, b): return a + b
- 掌握常见的编程范式(Programming paradigms)
- 函数式编程、面向对象编程、命令式编程等
- 代码示意(面向对象):
class Calculator: def add(self, a, b): return a + b
- 理解自然语言描述与代码逻辑的映射关系
- 能将自然语言需求转化为可执行代码
- 示意:
# 用户描述: "创建一个函数,输入两个数字返回它们的和" # LLM生成代码: def sum_two_numbers(a, b): return a + b - 公式化表示映射关系:
Code = LLM ( NaturalLanguageDescription ) \text{Code} = \text{LLM}(\text{NaturalLanguageDescription}) Code=LLM(NaturalLanguageDescription)
- 学习多种编程语言的语法规则
3. 训练目标与数学公式化
LLM 通过最大化给定上下文的代码生成概率进行训练:
θ ∗ = arg max θ ∑ ( x , y ) ∈ D log P θ ( y ∣ x ) \theta^* = \arg\max_\theta \sum_{(x, y) \in D} \log P_\theta(y \mid x) θ∗=argθmax(x,y)∈D∑logPθ(y∣x)
- 其中:
- x x x = 自然语言描述或上下文
- y y y = 对应的代码片段
- D D D = 训练数据集
- P θ ( y ∣ x ) P_\theta(y \mid x) Pθ(y∣x) = LLM 在参数 θ \theta θ 下生成代码 y y y 的概率
解释:模型通过学习大量 ( x , y ) (x, y) (x,y) 对来掌握“自然语言 → 代码”的映射能力。
4. 总结
- 训练数据丰富:涵盖多语言、多范式代码与文档。
- 能力:
- 掌握语法规则
- 学习编程范式
- 理解自然语言到代码的映射
- 公式化:
- 自然语言到代码映射:
Code = LLM ( NL Description ) \text{Code} = \text{LLM}(\text{NL Description}) Code=LLM(NL Description) - 训练目标概率最大化:
θ ∗ = arg max θ ∑ ( x , y ) ∈ D log P θ ( y ∣ x ) \theta^* = \arg\max_\theta \sum_{(x, y) \in D} \log P_\theta(y \mid x) θ∗=argθmax(x,y)∈D∑logPθ(y∣x)
- 自然语言到代码映射:
Top 10 URL 示例任务步骤解析
1. 理解用户提示(Understand prompt)
- 含义:LLM 或多代理系统首先要理解自然语言提示(Prompt),明确任务目标和需求。
- 示意:
prompt = "Generate top 10 URLs from log file based on frequency" # LLM解析任务意图 task = parse_prompt(prompt) print(task) # -> {'action': 'top_urls', 'source': 'log_file', 'top_n': 10}
2. 规划器(Planner)
- 含义:规划器负责拆解任务,确定执行步骤顺序和所需工具。
- 示意:
Planner Steps: 1. Parse log file 2. Count frequency of URLs 3. Sort and select top 10 4. Write test cases 5. Build and execute 6. Generate documentation - 公式化表示任务拆解:
T a s k → Planner [ S t e p 1 , S t e p 2 , . . . , S t e p n ] Task \xrightarrow{\text{Planner}} [Step_1, Step_2, ..., Step_n] TaskPlanner[Step1,Step2,...,Stepn]
3. 编写代码(Write code)
- 子任务:
a. 解析日志文件(Parse Log File)
b. 生成频率字典并分析(Frequency Dictionary & Analysis) - 示意 Python 代码:
# a. 解析日志文件 with open("access.log") as f: lines = f.readlines() # b. 生成频率字典 from collections import Counter url_counter = Counter() for line in lines: url = extract_url(line) # 自定义函数解析 URL url_counter[url] += 1 # 获取前10 URL top_10 = url_counter.most_common(10) print(top_10) - 映射公式:
U R L s = ParseLogFile ( LogData ) URLs = \text{ParseLogFile}(\text{LogData}) URLs=ParseLogFile(LogData)
T o p N = FrequencyAnalysis ( U R L s , n = 10 ) TopN = \text{FrequencyAnalysis}(URLs, n=10) TopN=FrequencyAnalysis(URLs,n=10)
4. 编写测试(Write tests)
- 含义:确保代码正确性。
- 示意 Python 单元测试:
import unittest class TestTopURLs(unittest.TestCase): def test_frequency(self): sample_logs = ["GET /a", "GET /b", "GET /a"] result = frequency_analysis(sample_logs, 2) self.assertEqual(result[0][0], "/a") self.assertEqual(result[0][1], 2) if __name__ == "__main__": unittest.main()
5. 构建和执行(Build and execute)
- 含义:将代码集成、运行,并可能调用外部工具或库。
- 示意:
python top_urls.py # 构建并执行 - 注意:执行过程中可能出现失败,需要迭代修改代码和参数。
6. 文档(Document)
- 含义:记录任务流程、代码使用方法、输入输出格式等。
- 示意 Markdown 文档:
# Top 10 URLs Extraction ## Usage python top_urls.py <log_file> ## Output Top 10 most frequent URLs with count
7. 多工具调用与迭代(Tool Calls & Iteration)
- 说明:
- 许多步骤依赖工具调用(如解析、统计、测试、执行)
- 多数步骤可能失败,需要反复迭代改进
- 区别于一次性 LLM 调用(one-shot):
这里是 多步、多工具、循环迭代的流程
- 迭代公式表示:
S t e p i → Execute R e s u l t i → Check/Feedback S t e p i n e w Step_i \xrightarrow{\text{Execute}} Result_i \xrightarrow{\text{Check/Feedback}} Step_i^{new} StepiExecuteResultiCheck/FeedbackStepinew
Repeat until R e s u l t i meets requirements \text{Repeat until } Result_i \text{ meets requirements} Repeat until Resulti meets requirements
总结
- Top 10 URL 任务是典型多步骤任务:
- 从理解提示 → 规划 → 编码 → 测试 → 执行 → 文档
- 多步骤和工具调用:
- 与“一次性 LLM 调用”不同,需要迭代和错误处理
- 数学/逻辑映射:
- 每步操作可公式化表示,支持自动化执行与反馈循环
MCP(Model Context Protocol)与工具使用详细解析
1. MCP 概述
- 含义:
MCP 是一种 模型上下文协议,允许服务器将外部工具暴露给语言模型(LLM)调用。 - 功能:
- 语言模型可以通过 MCP 调用外部工具完成任务,如:
- 查询数据库(Database Query)
- 调用 API
- 执行计算(Computation)
- 文件发现(File discovery)
- 编译与执行代码(Compiler & Execute)
- 版本控制操作(Version control)
- 语言模型可以通过 MCP 调用外部工具完成任务,如:
- 工具定义:
- 每个工具具有唯一名称(name)
- 包含 元数据(metadata) 描述其 schema 或接口
- 公式表示:
T o o l = n a m e , m e t a d a t a , s c h e m a Tool = {name, metadata, schema} Tool=name,metadata,schema
L L M ↔ MCP invoke T o o l LLM \xleftrightarrow[\text{MCP}]{\text{invoke}} Tool LLMinvoke MCPTool
2. 消息流程(Message Flow)
2.1 工具发现(Discovery)
- 说明:客户端(Client)向服务器(Server)请求当前可用工具列表。
- 示意代码:
# 客户端请求工具列表 tools_list = client.get_tools_list() # tools/list print(tools_list) - 公式表示:
T o o l s a v a i l a b l e = S e r v e r . list_tools ( ) Tools_{available} = Server.\text{list\_tools}() Toolsavailable=Server.list_tools()
2.2 工具选择(Tool Selection)
- 说明:LLM 根据任务选择需要调用的工具。
- 示意代码:
selected_tool = llm.select_tool(tools_list, task) - 公式表示:
T o o l s e l e c t e d = LLM.select ( T o o l s a v a i l a b l e , T a s k ) Tool_{selected} = \text{LLM.select}(Tools_{available}, Task) Toolselected=LLM.select(Toolsavailable,Task)
2.3 工具调用(Invocation)
- 说明:
- 客户端将选择的工具调用请求发送给服务器
- 服务器执行工具逻辑并返回结果
- 示意代码:
# 客户端调用工具 result = client.call_tool(selected_tool, params) # 处理结果 llm.process(result) - 公式表示:
R e s u l t = S e r v e r . call ( T o o l s e l e c t e d , P a r a m s ) Result = Server.\text{call}(Tool_{selected}, Params) Result=Server.call(Toolselected,Params)
L L M ← process R e s u l t LLM \xleftarrow{\text{process}} Result LLMprocessResult
2.4 工具更新(Updates)
- 说明:
- 工具列表可能发生变化(新增、删除、升级)
- 服务器通知客户端
tools/list_changed - 客户端刷新工具列表以保持最新状态
- 示意代码:
# 监听工具更新 if server.tools_list_changed(): tools_list = client.get_tools_list() # 更新工具列表 - 公式表示:
T o o l s a v a i l a b l e n e w = S e r v e r . update_tools ( ) Tools_{available}^{new} = Server.\text{update\_tools}() Toolsavailablenew=Server.update_tools()
3. Mermaid 消息流程图解析
- 流程说明:
- Discovery:客户端请求工具列表,服务器返回可用工具
- Tool Selection:LLM 根据任务选择工具
- Invocation:客户端调用服务器工具并返回结果给 LLM
- Updates:服务器工具列表变化,客户端刷新工具信息
- 重点理解:
- MCP 是 语言模型与工具交互的标准化协议
- 支持 迭代调用与更新
- LLM 不直接执行工具,而是通过 客户端代理 与服务器通信
Copilot Core Tools
| 工具类型 (Tool Type) | 示例 (Examples) |
|---|---|
| Compiler | gcc [1], clang [2], javac [3], tsc [4] |
| Debugger | gdb [5], lldb [7], pdb [8] |
| Test Framework | pytest [9], unittest [10], Jest [11], Mocha [12] |
| Linter | eslint [13], flake8 [14], black [15], prettier [16] |
| Version Control | git [17] |
| Build System | make [18], cmake [19], npm [20], maven [21] |
| Package Manager | pip [24], yarn [25], cargo [26] |
| Language Server | pyright [22], tsserver [23] |
Copilot 核心工具(Core Tools)解析
在 LLM 辅助的代码生成和软件开发场景中,Copilot 依赖一系列核心工具来执行代码编译、调试、测试、格式化、版本控制等操作。下面逐类说明。
1. 编译器(Compiler)
- 功能:将源代码为可执行程序或字节码
- 示例:
gcc[1]:GNU C 编译器clang[2]:LLVM 项目 C/C++/Objective-C 编译器javac[3]:Java 源代码编译器tsc[4]:TypeScript 编译器
- 使用场景:
LLM 生成代码后,需要调用编译器进行 语法验证与可执行生成
# Python 示例:调用 gcc 编译 C 文件
import subprocess
subprocess.run(["gcc", "main.c", "-o", "main"])
- 公式表示:
E x e c u t a b l e = C o m p i l e r ( S o u r c e C o d e , F l a g s ) Executable = Compiler(SourceCode, Flags) Executable=Compiler(SourceCode,Flags)
2. 调试器(Debugger)
- 功能:定位代码运行错误,单步执行,查看变量状态
- 示例:
gdb[5]:GNU 调试器lldb[7]:LLVM 调试器pdb[8]:Python 内置调试器
# Python 调试示例
import pdb
pdb.set_trace() # 代码运行到此处会暂停,进入交互调试
- 公式表示:
D e b u g I n f o = D e b u g g e r ( E x e c u t a b l e , B r e a k p o i n t s ) DebugInfo = Debugger(Executable, Breakpoints) DebugInfo=Debugger(Executable,Breakpoints)
3. 测试框架(Test Framework)
- 功能:自动化单元测试、集成测试,验证代码功能正确性
- 示例:
pytest[9]、unittest[10](Python)Jest[11]、Mocha[12](JavaScript)
# pytest 示例
def test_add():
assert add(2, 3) == 5
- 公式表示:
T e s t R e s u l t = T e s t F r a m e w o r k ( C o d e , T e s t C a s e s ) TestResult = TestFramework(Code, TestCases) TestResult=TestFramework(Code,TestCases)
4. 代码风格检查(Linter)
- 功能:检查代码风格、规范、潜在错误
- 示例:
eslint[13]、prettier[16](JavaScript/TypeScript)flake8[14]、black[15](Python)
# Python 示例
flake8 main.py # 检查 PEP8 规范
- 公式表示:
L i n t R e p o r t = L i n t e r ( S o u r c e C o d e ) LintReport = Linter(SourceCode) LintReport=Linter(SourceCode)
5. 版本控制(Version Control)
- 功能:管理代码版本、分支、合并与协作
- 示例:
git[17]
git commit -m "Add new feature"
git push origin main
- 公式表示:
R e p o S t a t e = V C S . c o m m i t ( C h a n g e s ) RepoState = VCS.commit(Changes) RepoState=VCS.commit(Changes)
6. 构建系统(Build System)
- 功能:自动化构建、依赖管理、打包
- 示例:
make[18]、cmake[19](C/C++ 项目)npm[20]、maven[21](JavaScript/Java 项目)
# make 示例
make all
- 公式表示:
B u i l d O u t p u t = B u i l d S y s t e m ( S o u r c e C o d e , B u i l d R u l e s ) BuildOutput = BuildSystem(SourceCode, BuildRules) BuildOutput=BuildSystem(SourceCode,BuildRules)
7. 包管理器(Package Manager)
- 功能:安装和管理依赖库
- 示例:
pip[24](Python)yarn[25](JavaScript)cargo[26](Rust)
pip install requests
- 公式表示:
D e p e n d e n c i e s = P a c k a g e M a n a g e r . i n s t a l l ( L i b r a r i e s ) Dependencies = PackageManager.install(Libraries) Dependencies=PackageManager.install(Libraries)
8. 语言服务器(Language Server)
- 功能:提供智能补全、类型检查、代码导航
- 示例:
pyright[22](Python)tsserver[23](TypeScript)
# tsserver 配置示例
{
"compilerOptions": {
"target": "ES6",
"module": "commonjs"
}
}
- 公式表示:
L L M a s s i s t = L a n g u a g e S e r v e r ( S o u r c e C o d e ) LLM_{assist} = LanguageServer(SourceCode) LLMassist=LanguageServer(SourceCode)
总结
- Copilot Core Tools 可以看作 LLM 在软件开发中的 执行引擎:
- 编译器 + 调试器 → 代码验证
- 测试框架 + Linter → 质量保证
- 构建系统 + 包管理器 → 项目管理
- 版本控制 → 协作
- 语言服务器 → 智能辅助
- LLM 通过这些工具可以完成 从生成到调试、测试、优化的完整开发闭环
反思与自我改进(Reflection and Self-Improvement)
在代码生成领域,相比 一次性生成(one-shot generation) 方法,反思与自我改进方法允许 LLM 对生成过程中的中间结果进行 自我评估与迭代优化,类似人类写代码的思维过程。
核心思想
- 迭代生成(Iterative Generation)
- 模型不是一次性输出完整代码,而是生成初始版本 → 评估 → 修改 → 再生成。
- 类似人类的 生成 → 评估 → 修正 流程。
- 内部反馈(Internal Feedback)
- 在每次迭代中,模型可以对自己生成的代码进行自然语言或结构化的自我评价。
- 自我评价可能包括:
- 潜在的语法错误
- 逻辑漏洞
- 风格或规范问题
- 逐步优化(Step-wise Refinement)
- 通过多轮迭代,模型的输出质量逐渐提高。
- 最终结果的 正确性、可读性和可维护性 都比一次性生成更高。
流程示意
可以用一个简单的流程表示:
- 解释:
A:生成初始代码B:模型使用自然语言对初始代码进行自我评估C:识别潜在问题D:根据反馈修改代码- 回到
A形成循环,直到满意为止
示例(Python 风格伪代码)
# Step 1: Generate initial code
code = llm.generate(prompt="Parse log file and compute frequency dictionary")
# Step 2: Self-evaluation
feedback = llm.evaluate(code, criteria=["correctness", "efficiency", "style"])
# Step 3: Identify issues
issues = feedback.get("issues")
# Step 4: Refine code
for issue in issues:
code = llm.refine(code, issue)
- 这里
llm.evaluate()模拟自然语言评估过程,llm.refine()根据反馈进行迭代优化。
公式表示
反思与自我改进的核心可以用迭代公式表示:
C o d e t + 1 = R e f i n e ( C o d e t , F e e d b a c k ( C o d e t ) ) Code_{t+1} = Refine(Code_t, Feedback(Code_t)) Codet+1=Refine(Codet,Feedback(Codet))
- C o d e t Code_t Codet:第 t t t 次生成的代码
- F e e d b a c k ( C o d e t ) Feedback(Code_t) Feedback(Codet):模型对 C o d e t Code_t Codet 的自我评价
- R e f i n e Refine Refine:根据反馈修改代码
初始生成:
C o d e 0 = G e n e r a t e ( P r o m p t ) Code_0 = Generate(Prompt) Code0=Generate(Prompt)
迭代直到收敛或达到预设质量标准:
C o d e ∗ = lim t → T C o d e t Code^* = \lim_{t \to T} Code_t Code∗=t→TlimCodet
总结
- 反思与自我改进方法的优势:
- 提高生成代码的正确性
- 提升可读性与规范性
- 能处理复杂任务,需要多步骤推理或逻辑推导
- 核心是通过 自然语言自评 + 迭代修正 模拟人类编码思维。
多智能体架构(Multi-agent Architectures)
多智能体系统(MAS)在代码生成中通常使用多个协作智能体,每个智能体负责特定任务或阶段。主要架构有四种:
1. Pipeline-based Labor Division(流水线式劳动分工)
- 核心思想:
- 系统将任务拆分为 顺序执行的多个阶段,每个智能体负责一个阶段的任务。
- 阶段之间存在明确的 输入输出依赖,类似软件工程中的流水线或瀑布模型(Waterfall)。
- 示意流程:
- 优点:
- 结构清晰,便于系统设计与调试
- 每个阶段职责明确
- 缺点:
- 串行依赖强,处理复杂任务效率低
- 缺少全局反馈机制
- 公式表示:
O u t p u t = A g e n t n ( . . . A g e n t 2 ( A g e n t 1 ( I n p u t ) ) . . . ) Output = Agent_n(...Agent_2(Agent_1(Input))...) Output=Agentn(...Agent2(Agent1(Input))...)
2. Hierarchical Planning × Execution(分层规划与执行)
- 核心思想:
- 高层智能体负责 任务规划和分解
- 低层智能体负责 具体执行和实现
- 模拟“管理者-执行者”模式,可处理更复杂任务
- 示意流程:
- 优点:
- 能处理复杂和分布式任务
- 高层规划保证全局目标一致性
- 公式表示:
C o d e f i n a l = ∑ i = 1 n E x e c u t e i ( P l a n i ( T a s k ) ) Code_{final} = \sum_{i=1}^{n} Execute_i(Plan_i(Task)) Codefinal=i=1∑nExecutei(Plani(Task))
3. Self-Negotiation(自我协商循环优化)
- 核心思想:
- 智能体通过 协商、反思和反馈 循环优化生成结果
- 多轮迭代中,智能体评估、修复和改进代码
- 示意流程:
- 优点:
- 提高代码质量和鲁棒性
- 能处理多步骤复杂任务
- 公式表示:
C o d e t + 1 = O p t i m i z e ( C o d e t , F e e d b a c k ( C o d e t ) ) Code_{t+1} = Optimize(Code_t, Feedback(Code_t)) Codet+1=Optimize(Codet,Feedback(Codet))
4. Self-Evolving Structural Updates(自我进化结构更新)
- 核心思想:
- 系统可根据任务复杂度、失败反馈和协作效果 动态调整智能体结构和策略
- 不再依赖固定的手动设定流程
- 示意流程:
- 优点:
- 自适应性强,可在运行时学习和重组
- 系统更健壮,适应不同任务场景
- 公式表示:
S t r u c t u r e t + 1 , S t r a t e g y t + 1 = E v o l v e ( S t r u c t u r e t , S t r a t e g y t , F e e d b a c k t ) Structure_{t+1}, Strategy_{t+1} = Evolve(Structure_t, Strategy_t, Feedback_t) Structuret+1,Strategyt+1=Evolve(Structuret,Strategyt,Feedbackt)
总结
| 架构类型 | 核心特点 | 优缺点 |
|---|---|---|
| Pipeline-based | 串行分工,每阶段独立 | 结构清晰,但缺全局反馈 |
| Hierarchical | 高层规划 + 低层执行 | 可处理复杂任务,但需良好任务分解 |
| Self-Negotiation | 循环优化,多轮反馈 | 提升代码质量,但迭代成本高 |
| Self-Evolving | 动态结构调整,策略自适应 | 高鲁棒性,适应不同场景,系统复杂 |
多智能体架构(Multi-agent Architectures)详细解析
1. Pipeline-based Labor Division(流水线式劳动分工)
- 核心思想:
- 任务被拆分为 一系列顺序阶段,每个智能体完成特定任务后将结果传递给下一个智能体。
- 模拟传统瀑布模型,任务线性执行。
- 具体示例流程:
Data-Analyzer → PRD Brainstormer → Coder → Tester → Public Experiment Manager → Data Analyzer
- 说明:
- Data-Analyzer:分析数据,发现机会或问题点
- PRD Brainstormer:生成产品需求文档(PRD),策划功能
- Coder:根据PRD编写代码
- Tester:对代码进行单元和集成测试
- Public Experiment Manager:管理实验发布和用户反馈
- Data Analyzer:循环回到数据分析阶段,形成闭环
- 公式表示:
O u t p u t = A g e n t 6 ( . . . A g e n t 2 ( A g e n t 1 ( D a t a ) ) . . . ) Output = Agent_6(...Agent_2(Agent_1(Data))...) Output=Agent6(...Agent2(Agent1(Data))...) - 特点:
- 串行执行,流程清晰
- 优点:便于任务分工与管理
- 缺点:处理复杂或迭代任务效率低,依赖前序阶段成功
2. Hierarchical Planning × Execution(分层规划与执行)
- 核心思想:
- 系统分为 战略层(高层规划) 与 战术层(具体执行)
- 高层智能体负责任务分解、策略决策
- 低层智能体负责任务执行和实现
- 示例智能体对:
Navigator <> Driver
Coder <> Deep-researcher
- 说明:
- Navigator:高层规划,提供策略、选择路径
- Driver:低层执行,根据Navigator提供的策略实现具体代码
- Coder:编写代码
- Deep-researcher:深度研究、提供参考资料或算法优化
- 任务拆分模式:
- 战略智能体(Strategic agents):处理高层规划,宏观决策
- 战术智能体(Tactical agents):执行具体操作,微观实现
- 公式表示:
C o d e f i n a l = ∑ i = 1 n E x e c u t e i ( P l a n i ( T a s k ) ) Code_{final} = \sum_{i=1}^{n} Execute_i(Plan_i(Task)) Codefinal=i=1∑nExecutei(Plani(Task)) - 特点:
- 可处理复杂任务,规划与执行分离
- 高层智能体确保全局一致性
- 可扩展性强,可增加多层智能体
3. Self-Negotiation(自我协商循环优化)
- 核心思想:
- 每个智能体或阶段生成的输出经过 反思/评分
- 形成内部反馈循环,使智能体可以不断 迭代优化
- 流程示意:
Stage Output → Reflection Agents → Feedback → Stage Re-execution → Updated Output
- 说明:
- Reflection agents(反思智能体):对每个阶段输出进行评分和评估
- 反馈机制:为前序智能体提供改进建议
- 多轮迭代直到输出满足质量要求
- 公式表示:
C o d e t + 1 = O p t i m i z e ( C o d e t , F e e d b a c k ( C o d e t ) ) Code_{t+1} = Optimize(Code_t, Feedback(Code_t)) Codet+1=Optimize(Codet,Feedback(Codet)) - 特点:
- 模拟人类写作-评估-修改过程
- 提高代码正确性和质量
- 适用于多阶段复杂任务和高要求输出
小结表格
| 架构类型 | 核心智能体/阶段 | 核心逻辑 | 优缺点 |
|---|---|---|---|
| Pipeline-based | Data-Analyzer → PRD Brainstormer → Coder → Tester → Public Experiment Manager | 串行分工,阶段依赖 | 结构清晰,便于管理;迭代效率低 |
| Hierarchical | Navigator <> Driver, Coder <> Deep-researcher | 高层规划 + 低层执行 | 可处理复杂任务;需良好任务分解 |
| Self-Negotiation | Reflection agents + 各阶段智能体 | 生成-评估-反馈循环 | 输出质量高,适应复杂任务;迭代成本高 |
上下文管理与记忆技术(Context Management & Memory Technologies)
1. 消息传递机制(Message Passing)
- 核心思想:
- 多智能体系统通过 消息传递 进行通信与信息共享
- 每个智能体可以发送消息(信息、请求、反馈)给其他智能体
- 特点:
- 弱耦合:智能体之间无需直接共享内部状态
- 异步或同步通信
- 支持 任务协调、状态更新、上下文维护
- 示意公式:
- 假设智能体 A i A_i Ai 和 A j A_j Aj 进行消息传递
M e s s a g e A i → A j = f ( C o n t e x t A i , T a s k I n f o ) Message_{A_i \to A_j} = f(Context_{A_i}, TaskInfo) MessageAi→Aj=f(ContextAi,TaskInfo)
- 假设智能体 A i A_i Ai 和 A j A_j Aj 进行消息传递
- 解释:
- C o n t e x t A i Context_{A_i} ContextAi:发送者当前上下文信息
- T a s k I n f o TaskInfo TaskInfo:任务相关信息
- f f f:消息编码或处理函数
2. Blackboard Method(黑板方法)
- 核心思想:
- 多智能体系统共享一个 公共“黑板”
- 所有智能体可以向黑板写入信息,也可以读取已有信息
- 类似团队协作中的共享笔记板
- 特点:
- 支持 解耦协作
- 每个智能体只需关注 自己感兴趣的部分
- 适合复杂任务分解与知识整合
- 示意公式:
B l a c k b o a r d ( t + 1 ) = B l a c k b o a r d ( t ) ∪ ⋃ i = 1 n C o n t r i b u t i o n A i ( t ) Blackboard(t+1) = Blackboard(t) \cup \bigcup_{i=1}^{n} Contribution_{A_i}(t) Blackboard(t+1)=Blackboard(t)∪i=1⋃nContributionAi(t) - 解释:
- B l a c k b o a r d ( t ) Blackboard(t) Blackboard(t):时间 t t t 的黑板状态
- C o n t r i b u t i o n A i ( t ) Contribution_{A_i}(t) ContributionAi(t):智能体 A i A_i Ai 在时间 t t t 的贡献信息
- 通过多轮迭代,黑板不断累积全局知识
3. von Neumann Model(冯·诺依曼模型)
- 核心思想:
- 传统计算机体系结构模型,提供 指令执行与存储机制
- 主要组件:
- Instruction Register(指令寄存器):存储当前执行的指令
- Data Storage(数据存储):存储程序数据和上下文
- 特点:
- 为上下文管理提供基础硬件支持
- 可与 LLM/多智能体系统结合,用作 短期或长期记忆
- 支持 顺序执行 + 数据访问
- 示意公式:
E x e c u t i o n C y c l e : I R → D e c o d e A L U → C o m p u t e D a t a S t o r a g e ExecutionCycle: IR \xrightarrow{Decode} ALU \xrightarrow{Compute} DataStorage ExecutionCycle:IRDecodeALUComputeDataStorage - 解释:
- I R IR IR:当前指令寄存器中的指令
- A L U ALU ALU:算术逻辑单元,用于执行指令
- D a t a S t o r a g e DataStorage DataStorage:读/写数据,维护上下文状态
小结
| 技术/方法 | 功能 | 特点 | 数学/流程表示 |
|---|---|---|---|
| Message Passing | 智能体之间通信 | 弱耦合,可异步 | M e s s a g e A i → A j = f ( C o n t e x t A i , T a s k I n f o ) Message_{A_i \to A_j} = f(Context_{A_i}, TaskInfo) MessageAi→Aj=f(ContextAi,TaskInfo) |
| Blackboard Method | 多智能体共享信息 | 支持协作与知识整合 | B l a c k b o a r d ( t + 1 ) = B l a c k b o a r d ( t ) ∪ ∑ C o n t r i b u t i o n A i ( t ) Blackboard(t+1) = Blackboard(t) \cup \sum Contribution_{A_i}(t) Blackboard(t+1)=Blackboard(t)∪∑ContributionAi(t) |
| von Neumann Model | 程序指令执行与数据存储 | 提供上下文硬件支持 | I R → D e c o d e A L U → C o m p u t e D a t a S t o r a g e IR \xrightarrow{Decode} ALU \xrightarrow{Compute} DataStorage IRDecodeALUComputeDataStorage |
AI Agents 面临的主要挑战
1. 任务评估与基准测试(Evals & Benchmarks for Your Tasks)
- 问题:
- AI 智能体需要在具体任务中证明其性能
- 缺乏统一的评估标准或基准数据集可能导致结果不可比较
- 解决思路:
- 定制化任务评估标准(Task-specific evals)
- 对比 自动化指标 + 人工评审
- 示意公式:
- 假设智能体输出为 O O O,期望输出为 G G G,评估函数为 E v a l ( ⋅ ) Eval(\cdot) Eval(⋅)
S c o r e = E v a l ( O , G ) Score = Eval(O, G) Score=Eval(O,G)
- 假设智能体输出为 O O O,期望输出为 G G G,评估函数为 E v a l ( ⋅ ) Eval(\cdot) Eval(⋅)
- 解释:
- S c o r e Score Score 越高表示输出质量越接近目标
- E v a l Eval Eval 可以是准确率、功能覆盖率或代码质量指标
2. 领域知识(Domain-specific Knowledge)
- 问题:
- LLM 或 AI 智能体可能对通用代码生成很强,但对特定领域(如金融、嵌入式系统)知识不足
- 缺乏领域规则和约束可能导致错误或不安全的代码
- 解决思路:
- 通过 微调(Fine-tuning) 或 插件/工具调用 提供领域知识
- 将领域规则形式化为上下文约束
- 示意公式:
- L L M LLM LLM 输出 O O O 需满足领域约束 D D D
O ∈ V a l i d ( D ) O \in Valid(D) O∈Valid(D)
- L L M LLM LLM 输出 O O O 需满足领域约束 D D D
3. 上下文窗口与记忆扩展(Context Window & Memory Scaling)
- 问题:
- LLM 有最大上下文长度限制,处理大规模代码或长任务时容易丢失上下文
- 对多轮迭代、长文档或大型项目支持不足
- 解决思路:
- 分块处理(Chunking) + 记忆管理(Memory Management)
- 结合 Blackboard 或 RAM 模型 保持长期上下文
- 示意公式:
- 上下文窗口 C m a x C_{max} Cmax
if ∣ C o n t e x t ∣ > C m a x ⇒ C o n t e x t → M e m o r y S t o r a g e \text{if } |Context| > C_{max} \Rightarrow Context \rightarrow MemoryStorage if ∣Context∣>Cmax⇒Context→MemoryStorage
- 上下文窗口 C m a x C_{max} Cmax
- 解释:
- 超出上下文长度的内容转入记忆存储以便后续访问
4. 成本(Costs)
- 问题:
- 运行大模型(如 Codex、CodeLlama)和多智能体系统需要 大量计算资源
- GPU/TPU 使用、API 调用成本高
- 解决思路:
- 层级调度(Hierarchical scheduling)
- 模型压缩(Model pruning / quantization)
- 异步或按需调用(On-demand inference)
- 示意公式:
- 成本 C o s t Cost Cost 估计
C o s t ∝ M o d e l S i z e × N u m T o k e n s × N u m A g e n t s Cost \propto ModelSize \times NumTokens \times NumAgents Cost∝ModelSize×NumTokens×NumAgents
- 成本 C o s t Cost Cost 估计
- 解释:
- M o d e l S i z e ModelSize ModelSize:模型参数量
- N u m T o k e n s NumTokens NumTokens:处理文本或代码长度
- N u m A g e n t s NumAgents NumAgents:并行智能体数量
5. 大规模代码库处理(Handling Large Code-bases)
- 问题:
- 单个智能体难以理解、生成和维护大型代码库
- 依赖模块关系、跨文件调用和版本控制
- 解决思路:
- 分层分析(Hierarchical Analysis):模块级、函数级、语句级
- 智能体协作(Multi-Agent Collaboration):分工处理不同模块
- 利用 静态分析工具 + Linter + 测试框架
- 示意公式:
- 将大型代码库 C o d e B a s e CodeBase CodeBase 拆分为模块 M i M_i Mi
C o d e B a s e = ⋃ i = 1 n M i , A g e n t i 负责 M i CodeBase = \bigcup_{i=1}^{n} M_i, \quad Agent_i \text{负责} M_i CodeBase=i=1⋃nMi,Agenti负责Mi
- 将大型代码库 C o d e B a s e CodeBase CodeBase 拆分为模块 M i M_i Mi
- 解释:
- 每个智能体专注于一部分,最后通过黑板或协作机制整合输出
总结表
| 挑战 | 描述 | 对策 | 数学/公式表示 | ||
|---|---|---|---|---|---|
| 评估与基准 | 缺乏统一评测标准 | 定制化 Eval 函数 | S c o r e = E v a l ( O , G ) Score = Eval(O, G) Score=Eval(O,G) | ||
| 领域知识 | 特定领域知识缺失 | 微调 / 插件 / 规则约束 | O ∈ V a l i d ( D ) O \in Valid(D) O∈Valid(D) | ||
| 上下文 & 记忆 | 上下文窗口有限 | 分块 + 长期记忆 | $ | Context | >C_{max}\Rightarrow MemoryStorage$ | ||
| 成本 | 计算资源消耗大 | 模型压缩 + 异步调度 | C o s t ∝ M o d e l S i z e × N u m T o k e n s × N u m A g e n t s Cost \propto ModelSize \times NumTokens \times NumAgents Cost∝ModelSize×NumTokens×NumAgents | ||
| 大型代码库 | 难以理解与生成 | 分层分析 + 多智能体协作 | C o d e B a s e = ⋃ i = 1 n M i CodeBase = \bigcup_{i=1}^{n} M_i CodeBase=⋃i=1nMi |
Evals & Benchmarks(评估与基准测试)
AI 智能体在软件开发任务中,需要可靠的评估方法来衡量其性能和实用性。
1. 从组织内的任务集合中设置示例任务
- 问题:
- 单纯使用公开数据集可能无法反映组织内部真实需求
- 做法:
- 从组织内部不同部门、项目中挑选任务
- 手动筛选(Manual curation),确保任务具有代表性
- 示意公式:
- 假设组织内部任务集合为 T o r g T_{org} Torg,经过人工筛选得到示例任务集合 T s a m p l e T_{sample} Tsample
T s a m p l e ⊆ T o r g , ∣ T s a m p l e ∣ ≪ ∣ T o r g ∣ T_{sample} \subseteq T_{org}, \quad |T_{sample}| \ll |T_{org}| Tsample⊆Torg,∣Tsample∣≪∣Torg∣
- 假设组织内部任务集合为 T o r g T_{org} Torg,经过人工筛选得到示例任务集合 T s a m p l e T_{sample} Tsample
- 解释:
- T s a m p l e T_{sample} Tsample 是一个精心挑选的子集,用于测试智能体能力
2. 收集用户的隐式和显式信号
- 问题:
- 用户使用行为可以提供智能体性能的真实反馈
- 做法:
- 显式信号(Explicit signal):用户评分、评论、选择正确方案
- 隐式信号(Implicit signal):用户点击、修改、跳过或复用代码的行为
- 示意公式:
- 评分 S S S 可由显式信号 E E E 和隐式信号 I I I 组合得到
S = f ( E , I ) S = f(E, I) S=f(E,I)
- 评分 S S S 可由显式信号 E E E 和隐式信号 I I I 组合得到
- 解释:
- f ( ⋅ ) f(\cdot) f(⋅) 可以是加权平均或自定义评价函数
- 反映智能体生成的代码是否符合用户需求
3. 保证任务多样性
- 问题:
- 任务单一会导致智能体过拟合,无法推广到真实项目
- 做法:
- 涵盖不同领域(Domain)、编程语言(Language)、难度等级(Difficulty)
- 使用 多维度任务分布,确保评估全面
- 示意公式:
- 任务集合 T T T 需满足
T = t i ∣ Domain ( t i ) ∈ D , Language ( t i ) ∈ L , Difficulty ( t i ) ∈ F T = {t_i \mid \text{Domain}(t_i) \in D, \ \text{Language}(t_i) \in L, \ \text{Difficulty}(t_i) \in F } T=ti∣Domain(ti)∈D, Language(ti)∈L, Difficulty(ti)∈F
- 任务集合 T T T 需满足
- 解释:
- D D D、 L L L、 F F F 分别表示领域、语言和难度集合
- 每个任务 t i t_i ti 都属于这些维度中的某个值
总结表
| 评估要点 | 描述 | 方法 | 公式 |
|---|---|---|---|
| 示例任务 | 从组织内任务集合中挑选代表性任务 | 手动筛选 | T s a m p l e ⊆ T o r g T_{sample} \subseteq T_{org} Tsample⊆Torg |
| 用户信号 | 收集显式/隐式反馈 | 评分、点击、修改 | S = f ( E , I ) S = f(E, I) S=f(E,I) |
| 任务多样性 | 避免过拟合,提高泛化能力 | 多领域、多语言、多难度 | T = t i ∣ Domain ( t i ) ∈ D , Language ( t i ) ∈ L , Difficulty ( t i ) ∈ F T = {t_i \mid \text{Domain}(t_i) \in D, \text{Language}(t_i) \in L, \text{Difficulty}(t_i) \in F } T=ti∣Domain(ti)∈D,Language(ti)∈L,Difficulty(ti)∈F |
LargeLSFT: Scaling SFT with Human + AI Labeling
这是针对 代码审查补丁生成(code-review patching)的 大规模监督微调(SFT, Supervised Fine-Tuning) 方法,通过 人类 + AI 标注 来快速扩展训练数据。
1. 人类构建 SFT 数据集
- 描述:
- 人类标注者 (annotators) 对补丁和审查意见进行配对
- 平均 7 名标注者,历时 14 周完成
- 数据量:
- 构建了 18k ⟨review_comment, patch⟩ 对
- 公式表示:
D human = ( c i , p i ) i = 1 18 k , c i = review comment , p i = patch D_\text{human} = {(c_i, p_i)}_{i=1}^{18k}, \quad c_i = \text{review comment}, \ p_i = \text{patch} Dhuman=(ci,pi)i=118k,ci=review comment, pi=patch - 解释:
- D human D_\text{human} Dhuman 表示完全由人工标注的数据集
2. AI 分类器扩展数据
- 训练:
- 使用 Llama 8B 模型在 7.5k 人类标注数据 上训练分类器
- 目标:预测 patch 是否“good vs bad”
- 验证质量(700 held-out):
Precision = 0.88 , Recall = 0.75 , Accuracy = 0.79 \text{Precision} = 0.88, \quad \text{Recall} = 0.75, \quad \text{Accuracy} = 0.79 Precision=0.88,Recall=0.75,Accuracy=0.79 - 解释:
- 分类器性能良好,能在保证一定质量的前提下快速生成更多训练数据
3. 快速扩展
- 生成额外数据:
- AI 分类器生成了 +46k ⟨review_comment, patch⟩ 对
- 仅用 <1 天 完成扩展
- 相比人工 14 周从 2.5k 扩展到 18k,人力成本大幅下降
- 公式表示:
D AI = ( c i , p i ) ∗ i = 1 46 k , D ∗ total = D human ∪ D AI = 64 k D_\text{AI} = {(c_i, p_i)}*{i=1}^{46k}, \quad D*\text{total} = D_\text{human} \cup D_\text{AI} = 64k DAI=(ci,pi)∗i=146k,D∗total=Dhuman∪DAI=64k - 解释:
- 数据总量 D total D_\text{total} Dtotal = 人类标注 18k + AI 分类器生成 46k
4. 模型与上下文
- 模型:Llama-70B → Fine-tune 得到 Llama-LargeLSFT
- 上下文长度:128k(相比 SmallLSFT 的 16k)
- 设计理念(Rationale):
- 利用大规模 SFT 数据容忍少量质量下降,以提升模型在大规模任务上的性能
- 公式表示:
Performance ∼ f ( ∣ D total ∣ , Context Length ) \text{Performance} \sim f(|D_\text{total}|, \text{Context Length}) Performance∼f(∣Dtotal∣,Context Length) - 解释:
- 数据量越大 + 上下文越长 → 模型整体性能提升
5. 总结表
| 阶段 | 描述 | 数据量 | 时间/成本 |
|---|---|---|---|
| 人类 SFT 构建 | 人工标注 ⟨review_comment, patch⟩ 对 | 18k | 14 周 |
| AI 扩展 | 使用 Llama 8B 分类器生成数据 | 46k | <1 天 |
| 总数据集 | 人工 + AI 分类器 | 64k | – |
| 模型 & 上下文 | Llama-70B → Llama-LargeLSFT | 128k context | – |
| 设计理念 | 大规模 SFT 容忍质量略降,提升整体性能 | – | – |
示意流程图(文字版):
Human SFT (18k pairs)
│
▼
Train Classifier (Llama 8B)
│
▼
AI-generated data (+46k pairs)
│
▼
Total SFT Corpus (64k pairs)
│
▼
Fine-tune Llama-70B
│
▼
LargeLSFT Model (128k context)
Domain Specific Knowledge(领域特定知识)
在代码生成与多智能体系统中,模型在特定领域的能力通常依赖于 领域知识(Domain Knowledge),主要涉及工具调用和运行手册等。
1. MCP Tool Calls
- 描述:
- MCP(Model Context Protocol)允许模型调用外部工具
- 对于 定制框架(custom frameworks) 或 领域特定语言(DSL, Domain Specific Language) 特别有用
- 模型可以通过工具访问外部系统的功能,而不是完全依赖自身生成逻辑
- 公式化表示:
ToolCall : LLM → MCP External Framework / DSL \text{ToolCall}: \text{LLM} \xrightarrow{\text{MCP}} \text{External Framework / DSL} ToolCall:LLMMCPExternal Framework / DSL - 解释:
- 模型 L L M LLM LLM 通过 MCP 协议调用工具
- 可以访问自定义库、DSL 函数或特殊 API,而不是仅依赖内置知识
- 示例注释:
# LLM 调用自定义 DSL 工具解析业务逻辑
result = MCP.call("CustomDSLTool", input="parse workflow steps")
2. Runbook .md Files
- 描述:
- Runbook 文件(通常为 .md 格式)提供操作步骤、配方、工作手册
- 对代码生成代理(agent)很重要,因为它让模型 遵循规则而非自行发挥
- 作用:
- 避免模型在特定任务中“自由发挥”,保证遵循团队标准和业务规范
- 可用于 操作指令、部署脚本、调试步骤、自动化流水线
- 公式化表示:
AgentBehavior = f ( Runbook Instructions ) \text{AgentBehavior} = f(\text{Runbook Instructions}) AgentBehavior=f(Runbook Instructions) - 解释:
- 模型生成的行为依赖于 Runbook 指令集
- 公式表示:行为函数 f f f 输入 Runbook 内容,输出执行动作
- 示例注释:
# 从 runbook.md 读取操作步骤
with open("runbook.md", "r") as f:
instructions = f.read()
# 模型遵循步骤生成代码或执行任务
agent_output = LLM.generate_code(instructions)
总结
| 类别 | 描述 | 功能 |
|---|---|---|
| MCP Tool Calls | 调用外部工具、定制框架、DSL | 提供模型访问外部系统能力 |
| Runbook .md 文件 | 工作手册、操作步骤、配方 | 约束模型行为,保证任务遵循规则 |
核心理念:
- 对领域特定任务,工具调用 + 文档指导 可以显著提升 LLM 的准确性和可靠性
- 避免模型自由发挥导致的错误,同时扩展其对专业框架的理解
MCP 工具示例:DEADCODE_SCAVENGER
这是一个面向代码库扫描的 MCP 工具示例,用于检测、统计或修复死代码。
1. 工具说明
- 工具名称:
DEADCODE_SCAVENGER - 功能:
- list:列出代码库中发现的死代码
- stats:统计死代码信息
- patch:自动生成修复补丁
- 调用参数 schema:
"type": "object",
"properties": {
"root": {
"type": "string",
"description": "Repo root to scan",
"default": "."
},
"action": {
"type": "string",
"enum": ["list","stats","patch"],
"default": "stats"
},
"include_ext": {
"type": "array",
"items": {"type": "string"},
"description": "File extensions to include (no dot). Empty means all.",
"default": ["py","js","java"]
}
}
2. 理解
- root:
- 指定代码库根目录
- 默认为当前目录
"."
- action:
- 指定工具执行的操作类型
- 可选值:
"list"→ 列出所有死代码"stats"→ 统计死代码数量、占比等信息"patch"→ 自动生成删除或修复死代码的补丁
- include_ext:
- 指定扫描的文件类型扩展名
- 空数组表示扫描所有类型
- 默认包含 Python (
py)、JavaScript (js) 和 Java (java) 文件
3. MCP 调用示例
# MCP 调用 DEADCODE_SCAVENGER 统计当前 repo 的死代码
result = MCP.call(
tool_name="DEADCODE_SCAVENGER",
parameters={
"root": ".",
"action": "stats",
"include_ext": ["py","js"]
}
)
print(result)
4. 公式化表示
用符号表示 MCP 工具调用过程:
Result = MCP.call ( ToolName , Parameters ) \text{Result} = \text{MCP.call}(\text{ToolName}, \text{Parameters}) Result=MCP.call(ToolName,Parameters)
- 对应本例:
Result = MCP.call ( " D E A D C O D E _ S C A V E N G E R " , root = " . " , action = " s t a t s " , include_ext = [ " p y " , " j s " ] ) \text{Result} = \text{MCP.call}( "DEADCODE\_SCAVENGER",\\ {\text{root}=".", \\ \text{action}="stats", \\ \text{include\_ext}=["py","js"]} ) Result=MCP.call("DEADCODE_SCAVENGER",root=".",action="stats",include_ext=["py","js"]) - 说明:
- 模型通过 MCP 调用工具,对指定目录扫描特定类型文件
- 输出结果包含死代码统计信息或列表
5. 核心作用
- 提供 领域知识的外部工具访问
- 让 LLM 在代码审查、重构、优化任务中:
- 自动发现死代码
- 生成统计信息
- 辅助修复
总结:结合 MCP 调用,模型不再仅依赖自身推理,而是可通过工具访问真实代码库,提高任务准确性和可靠性。
上下文窗口与内存管理问题
在大型 LLM 或多代理系统中,处理大规模代码库和长会话时,上下文窗口(context window)和内存容量是关键瓶颈,需要特别的管理策略。
1. 总结代码库
- 方法:将整个代码库摘要为
.md文件,并用 Mermaid 图表表示:- 类图(Class Diagrams)
- 交互图(Interaction Diagrams)
- 模块依赖图(Module Dependency Diagrams)等
理解:
通过摘要和图示,模型可以在有限上下文窗口内“理解”整个代码库结构,避免一次性加载全部源代码。
示例(Mermaid 类图):
2. 会话追踪与检查点(Session Trace & Checkpointing)
- 作用:保存模型的会话状态,允许断点恢复或分阶段迭代。
- 命令示例:
/checkpoint [optional-name]→ 保存当前会话状态/list-checkpoints→ 显示所有可用检查点及对应 session ID
理解:
- 检查点类似 快照,可以保存模型对代码库理解的中间状态
- 支持长会话或多步骤生成任务
- 避免重复计算,节省上下文窗口和内存
3. 外部文件与资源
llms.txt(https://llmstxt.org/)- 提供代码、文档和知识片段,作为模型外部内存资源
- 可用于辅助理解和补充上下文
4. 内存管理技术
为解决上下文窗口与内存问题,可采用以下方法:
- Memory Compression(内存压缩)
- 对上下文进行压缩编码,只保留关键语义信息
- 减少 token 数量占用
- Caching(缓存)
- 将中间计算结果缓存
- 避免重复解析大型代码文件或中间生成结果
- Offloading(卸载)
- 将部分上下文或状态保存到外部存储(硬盘或云端)
- 按需加载,节省内存
5. 公式化表示
假设代码库 C C C 被摘要为 M M M 个 Markdown 文件,每个文件包含 d i d_i di 个图表(diagram)和 t i t_i ti 个文本片段:
C → Summarize M D 1 , M D 2 , … , M D M , M D i = d i , t i C \xrightarrow{\text{Summarize}} {MD_1, MD_2, \dots, MD_M}, \quad MD_i = {d_i, t_i} CSummarizeMD1,MD2,…,MDM,MDi=di,ti
- 会话检查点函数 c h e c k p o i n t checkpoint checkpoint 将模型状态 S S S 保存为:
S s a v e d = c h e c k p o i n t ( S , n a m e ) S_{saved} = checkpoint(S, name) Ssaved=checkpoint(S,name) - 内存压缩可以表示为函数 c o m p r e s s compress compress:
S c o m p r e s s e d = c o m p r e s s ( S ) S_{compressed} = compress(S) Scompressed=compress(S) - 缓存和卸载可形式化为:
S a c t i v e = c a c h e ( S c o m p r e s s e d ) or S a c t i v e = l o a d ( S o f f l o a d ) S_{active} = cache(S_{compressed}) \quad \text{or} \quad S_{active} = load(S_{offload}) Sactive=cache(Scompressed)orSactive=load(Soffload)
总结
- 摘要 + Mermaid 图 → 提高代码库可读性,节省上下文窗口
- 检查点机制 → 支持长会话和中断恢复
- Memory Compression / Caching / Offloading → 高效管理大规模内存和上下文
- 外部文件
llms.txt→ 补充知识,提升多步骤代码任务效率
降低成本策略 (Reducing Costs)
在使用 LLM 或多代理系统进行代码生成时,成本包括计算资源消耗、API 调用费用、训练与推理成本等。为了降低成本,可以采取以下措施:
1. 会话检查点与复用 (Session Checkpoints and Reuse)
- 方法:在关键步骤或阶段保存会话状态(checkpoint),之后可直接复用,而无需重新生成整个会话。
- 效果:
- 节省重复计算的成本
- 缩短生成时间
- 减少上下文窗口占用
示例:
/checkpoint stage1
...
/restore stage1 # 复用之前的会话状态
公式化表示:
若模型会话状态为 S S S, 保存检查点后:
S s a v e d = c h e c k p o i n t ( S , n a m e ) S_{saved} = checkpoint(S, name) Ssaved=checkpoint(S,name)
复用检查点:
S a c t i v e = r e s t o r e ( S s a v e d ) S_{active} = restore(S_{saved}) Sactive=restore(Ssaved)
2. 代码与会话摘要 (.md 文件)
- 方法:将生成的代码或会话步骤摘要成 Markdown 文件,并可附带图示(如 Mermaid 图表)
- 效果:
- 避免重复解析完整代码库
- 节省 token 消耗和计算时间
- 提高代码可理解性
公式化表示:
C → Summarize M D ( C ) C \xrightarrow{\text{Summarize}} MD(C) CSummarizeMD(C)
其中 C C C 为代码/会话, M D ( C ) MD(C) MD(C) 为 Markdown 摘要表示。
3. 降低代码复杂度 (Reduce Code Complexity)
- 方法:尽量生成结构清晰、模块化、低耦合的代码
- 效果:
- 更高的成功率(成功编译和执行)
- 减少调试、测试和迭代步骤
- 降低计算成本
示例:
- 避免单函数过长
- 拆分大功能模块为小函数
- 使用清晰命名和注释
数学表示:
假设复杂度函数为 C o m p l e x i t y ( C ) Complexity(C) Complexity(C),成功率为 P ( s u c c e s s ) P(success) P(success),成本 C o s t Cost Cost 与步骤数 N N N 成正比:
C o s t ∝ N ∝ C o m p l e x i t y ( C ) Cost \propto N \propto Complexity(C) Cost∝N∝Complexity(C)
降低复杂度 ⇒ \Rightarrow ⇒ 降低步骤数 ⇒ \Rightarrow ⇒ 降低成本:
C o m p l e x i t y ( C ) ↓ ⟹ N ↓ ⟹ C o s t ↓ Complexity(C) \downarrow \implies N \downarrow \implies Cost \downarrow Complexity(C)↓⟹N↓⟹Cost↓
4. 工具使用与确定性代码生成 (Tools & Deterministic Code Writing)
- 方法:
- 使用外部工具(如编译器、测试框架、静态分析工具)完成子任务
- 尽量生成确定性代码(相同输入可生成相同输出)
- 效果:
- 减少模型迭代次数
- 提高任务成功率
- 降低不必要的计算和成本
示例:
- 使用
pytest自动生成测试,而不是模型手动生成测试代码 - 使用
git diff或lint工具验证代码修改
公式化表示:
假设任务分解为 T = t 1 , t 2 , . . . , t n T = {t_1, t_2, ..., t_n} T=t1,t2,...,tn,工具执行成功率为 P ( t o o l ) P(tool) P(tool):
C o s t ( T ) = ∑ i = 1 n C o s t L L M ( t i ) P ( t o o l i ) Cost(T) = \sum_{i=1}^n \frac{Cost_{LLM}(t_i)}{P(tool_i)} Cost(T)=i=1∑nP(tooli)CostLLM(ti)
工具辅助可提高 P ( t o o l i ) P(tool_i) P(tooli),从而降低总成本。
总结
降低成本的核心思路是:
- 复用检查点 → 避免重复生成
- 代码与会话摘要 → 节省 token 和上下文窗口
- 降低代码复杂度 → 减少迭代与失败率
- 工具辅助 + 确定性生成 → 提高效率,减少计算消耗
关键公式:
C o m p l e x i t y ( C ) ↓ ⟹ N ↓ ⟹ C o s t ↓ Complexity(C) \downarrow \implies N \downarrow \implies Cost \downarrow Complexity(C)↓⟹N↓⟹Cost↓
C o s t ( T ) = ∑ i = 1 n C o s t L L M ( t i ) P ( t o o l i ) Cost(T) = \sum_{i=1}^n \frac{Cost_{LLM}(t_i)}{P(tool_i)} Cost(T)=i=1∑nP(tooli)CostLLM(ti)
代码质量评分 (Code Quality Score)
LLM 驱动的 代码质量评分系统用于评估生成代码的规范性和质量,帮助工程师更高效地完成代码审核和改进。
1. 系统架构
- Powered by two Llama3 models(由两个 Llama3 模型驱动)
- 模型1:检测常见代码质量问题
- 关注 编码最佳实践 (coding best practices)
- 示例问题:
- 命名不规范
- 代码重复 (code duplication)
- 潜在逻辑错误
- 缺少注释或文档
- 模型2:提供高质量的 “评论/建议 (critiques)”
- 对 LLM 生成的代码进行审查
- 给出具体改进建议,辅助开发者优化代码
公式化表示:
- 模型1:检测常见代码质量问题
- 假设代码片段为 C C C,模型1检测问题:
I s s u e s = M o d e l 1 ( C ) Issues = Model_1(C) Issues=Model1(C) - 模型2生成改进建议:
C r i t i q u e s = M o d e l 2 ( C ) Critiques = Model_2(C) Critiques=Model2(C) - 最终生成 代码质量评分 (QualityScore):
Q u a l i t y S c o r e = f ( I s s u e s , C r i t i q u e s ) QualityScore = f(Issues, Critiques) QualityScore=f(Issues,Critiques)
其中 f f f 可以是加权评分函数,例如:
Q u a l i t y S c o r e = 1 − w 1 ⋅ ∣ I s s u e s ∣ T o t a l C h e c k s + w 2 ⋅ I m p r o v e m e n t S c o r e QualityScore = 1 - w_1 \cdot \frac{|Issues|}{TotalChecks} + w_2 \cdot ImprovementScore QualityScore=1−w1⋅TotalChecks∣Issues∣+w2⋅ImprovementScore
2. 用户反馈与应用
- 使用人数:约 5000 名工程师
- 满意度:超过 60% 的用户对评分和建议表示认可
- 用途:
- 自动化代码审查
- 提升团队代码质量
- 指导 LLM 生成更规范的代码
3. 系统价值
- 减少人工审核成本:自动检测常见问题
- 提升代码可维护性:通过明确的改进建议
- 迭代优化 LLM 输出:结合模型反馈,改进生成策略
总结
Code Quality Score 的核心是:
- 检测问题:模型1扫描代码质量问题
- 提出建议:模型2生成针对性的改进意见
- 生成评分:结合问题数量和改进潜力计算综合质量分
关键公式:
Q u a l i t y S c o r e = f ( M o d e l 1 ( C ) , M o d e l 2 ( C ) ) QualityScore = f(Model_1(C), Model_2(C)) QualityScore=f(Model1(C),Model2(C))

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)