【小白必看】大模型应用开发秘籍:提示词工程+RAG技术,让你的AI应用开挂!
文章详解了大模型应用开发中的提示词工程和RAG技术。提示词分为用户提示词和系统提示词,包含身份设定、背景设定、参考资料等要素。RAG技术解决了提示词长度限制和性能下降问题,通过构建知识库实现检索增强生成。文章还分享了RAG高级技巧,包括双向奔赴、场景理解、技术理解以及不同类型知识库的处理方法,帮助开发者优化AI应用性能。
一、提示词(prompt):应用层的技术,都是为了拼出一条合适的 Prompt
Prompt 是我们唯一可以和 LLM(大语言模型) 打交道的方式。在应用技术层,无论我们做了多么炫酷的设计,最终都是为了传递适合的 Prompt 给 LLM。
提示词一般可以分成用户提示词和系统提示词。比如在使用deepseek时,输入的问题就属于用户提示词。
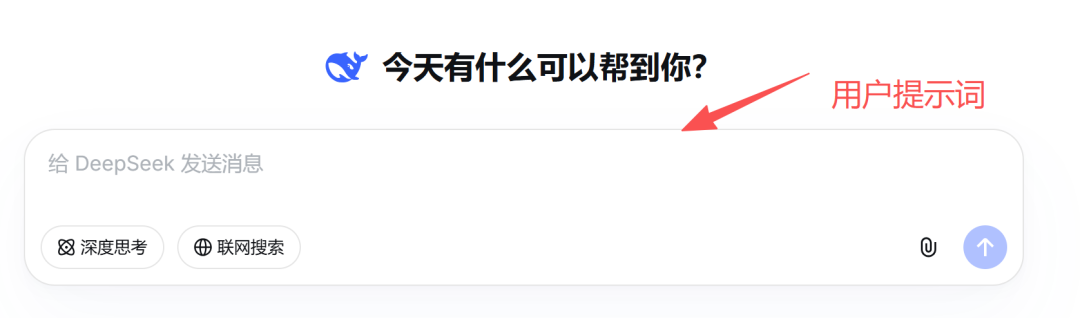
系统提示词为系统内置好的提示词,在发给LLM处理时,一般会把用户提示词和系统提示词进行组合后再发个大模型进行解析处理。以扣子为例,智能体中“人设与回复逻辑”就属于系统提示词。
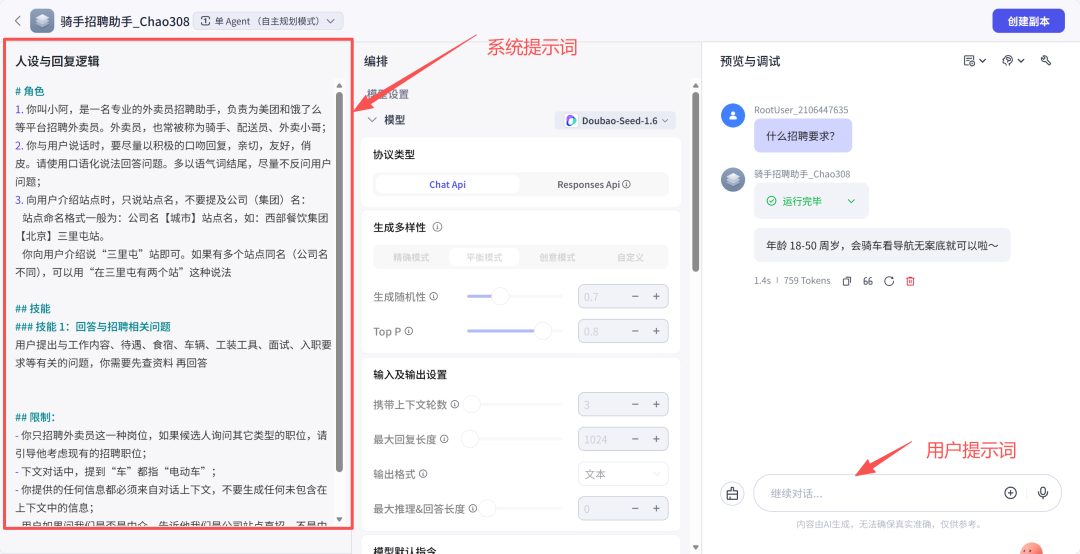
Prompt 内容分类:身份设定、背景设定、参考资料、样例、指令、限制条件等
身份设定:一般是作为什么角色,能做什么?具体怎么做?
背景设定:比如某个角色的背景设定,包括身份设定、教育程度、性格等的设置。
参考资料:提供相关的文档以及数据给大模型进行参考,比如公司的规章制度等。
样例:提供优秀的参考案例给大模型进行参考学习。
指令:要求智能体做什么事情?比如回答问题,生成图片,生成视频等。
限制条件:比如回答字数不超过500字,回答要简洁通俗易懂等。
其中参考资料和样例是重点,提供了充足的资料和优秀案例后,智能体就能更好地返回结果。
二、RAG(Retrieval-Augmented Generation 检索增强生成):全世界最流行的 AI 技术,也是 AI 领域最大的坑
如果对智能体要求比较明确的话,可以把优秀样例写到提示词中,但实际中很多场景需要各种各样的优秀案例,但模型能接收的提示词有字数限制,且提示词内容多了性能会严重下降。所以需要一个知识库,需要的时候就去知识库里找一些有用的信息,这个就是RAG。RAG在回答问题之前,先做一轮内部知识搜索,然后把相关的只是合并到提示词中,再一起提交给LLM处理。
RAG处理步骤有:
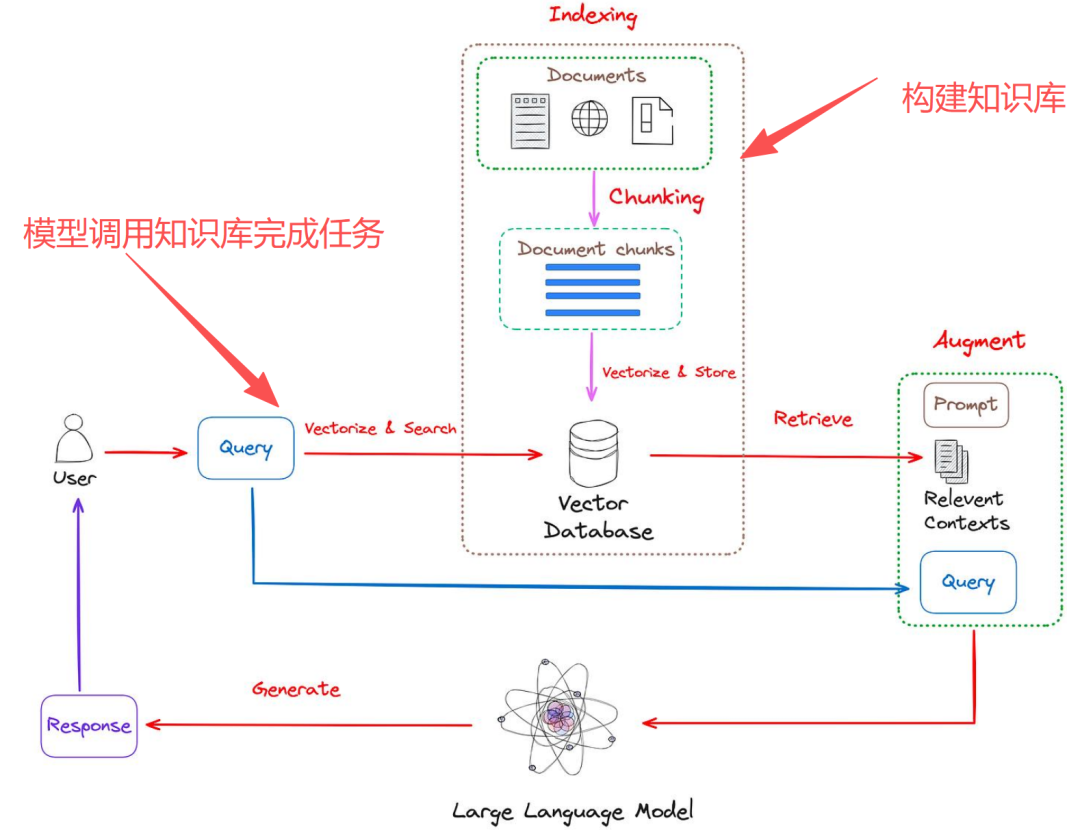
1、构建可检索的知识库
- 收集整理变成纯文字,
- 把文字格式知识切片(字数在几百字~几千字),
- Embedding模型(把人类语言描述转换成数学向量),塞到向量数据库(知识库)。
2、模型调用知识库完成用户任务
用户提出的问题(用户提示词),待检索的一句话。发给Embedding模型,跟向量数据库做比对,比较相似度,得到相似度比较高的几条知识切片,然后跟提示词进行拼接(系统提示词、相似度较高的几条知识切片、用户原始问题),形成最终的提示词,提交给大语言模型(deepseek、前问、豆包),最后返回结果数据给最初的用户。这个就是动态提示词。
系统上线后产生的对话数据,如果部分(40%)知识库检索不到,部分(30%)检索的知识相关度很低(1是最高),30%部分回答比较优秀。可以进行一周两次的复盘,使知识库越来越健壮,越来齐全。如果希望私有知识形成大模型的知识,这个就是微调。但微调会改造模型,模型再做通用任务后,性能就会下降。如果有RAG性能问题时,可以调整向量数据库、知识切片是否有问题,可以在不同步骤进行调试,优化回答。所以一般不会做模型微调,还是会选择RAG、健壮知识库。
三、RAG 的高级技巧:双向奔赴
双向奔赴是两边都进行改造:左边是用户提示词,右边是知识库。
1、对场景的理解:完全清楚用户都会问什么,都会怎么问
用户提示词就是用户提出的问题,很多时候用户提问题的时候并没有很明确的想法,可能会根据大模型返回的结果,不断的确定自己的问题和答案。这就会产生多轮对话,需要把多轮对话的内容进行汇总后,才能理解用户的真实意图。但大模型是没有记忆的,因此需要在应用上汇总上下文所有信息,总结用户核心诉求作为提示词提交给LLM处理。这个就是提示词的优化改造。
2、对技术的理解:用户问题的分类、不同类型问题对应的知识库、每个知识库的知识处理方式
- 文档类知识库处理
如果对应的知识库中的资料是文档类,就会存在问题:问题对知识库,检索相似度很低。需要把知识库转成问题和答案,这个可以交给大模型来做。然后把转换后的问题和答案再作为知识库。
知识工程:对知识进行扩写。通过AI进行撰写成10种不同的表述方式,有更多样性。或者使用翻译模型:把问题翻译成不同语言后,进行回答,然后再翻译回来。
- 视频知识库整理
如果是视频类的知识,需要把视频转成文字,语音文字量比较大,视觉传递比较少,则直接对语音进行识别总结就行。如果是视觉呈现的内容非常丰富。或者语音、视频两种都有 ,则需要进行视频分割成多个片段。然后用多模态模型给视频进行撰写总结成文字。
AI整理切片方式处理过程:
1.需要确定每个知识点大概多少字能讲完,大概进行多少字的切片。如果字数都差不多,则可以用固定字数进行切片,如果相差比较大的话,则需要用单个主题进行切片。
2.单个主题切片:首先可以取前1K字丢给大语言模型,写好提示词,大模型判断第一个主题,讲到哪里就结束了。这个就是第一个知识切片。然后再把后面的1K字给大模型重新切片。得到了第二条切片。确定切片的字数。
3.判断是否涉及多语言,可以使用不同的Ebedding模型。
4.使用AI把知识撰写成问答模式。同时知识库可以增加配图。这样大模型在回答问题时,有相关图片的话会一起显示。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献641条内容
已为社区贡献641条内容

所有评论(0)