论文阅读:arxiv 2026 Comparison requires valid measurement: Rethinking attack success rate comparisons in
该研究聚焦AI红队测试中攻击成功率(ASR)比较的有效性问题,指出当前基于ASR得出的系统安全性或攻击方法效能结论常因“苹果与橘子”式对比或低有效性测量缺乏支撑;通过社会科学测量理论和推论统计,提出ASR有意义比较需满足概念一致性(可比较的总体参数)和测量有效性(ASR能准确反映参数)两大条件;以越狱攻击为案例,分析了聚合方式差异、有害提示定义不当、评判者误差等导致比较失效的常见问题,并给出明确测
·
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
Comparison requires valid measurement: Rethinking attack success rate comparisons in AI red teaming
https://arxiv.org/pdf/2601.18076
https://www.doubao.com/chat/36955506394215682
速览
1. 一段话总结
该研究聚焦AI红队测试中攻击成功率(ASR)比较的有效性问题,指出当前基于ASR得出的系统安全性或攻击方法效能结论常因“苹果与橘子”式对比或低有效性测量缺乏支撑;通过社会科学测量理论和推论统计,提出ASR有意义比较需满足概念一致性(可比较的总体参数)和测量有效性(ASR能准确反映参数)两大条件;以越狱攻击为案例,分析了聚合方式差异、有害提示定义不当、评判者误差等导致比较失效的常见问题,并给出明确测量目标、确保概念一致、核验内容有效性等改进建议。
2. 思维导图
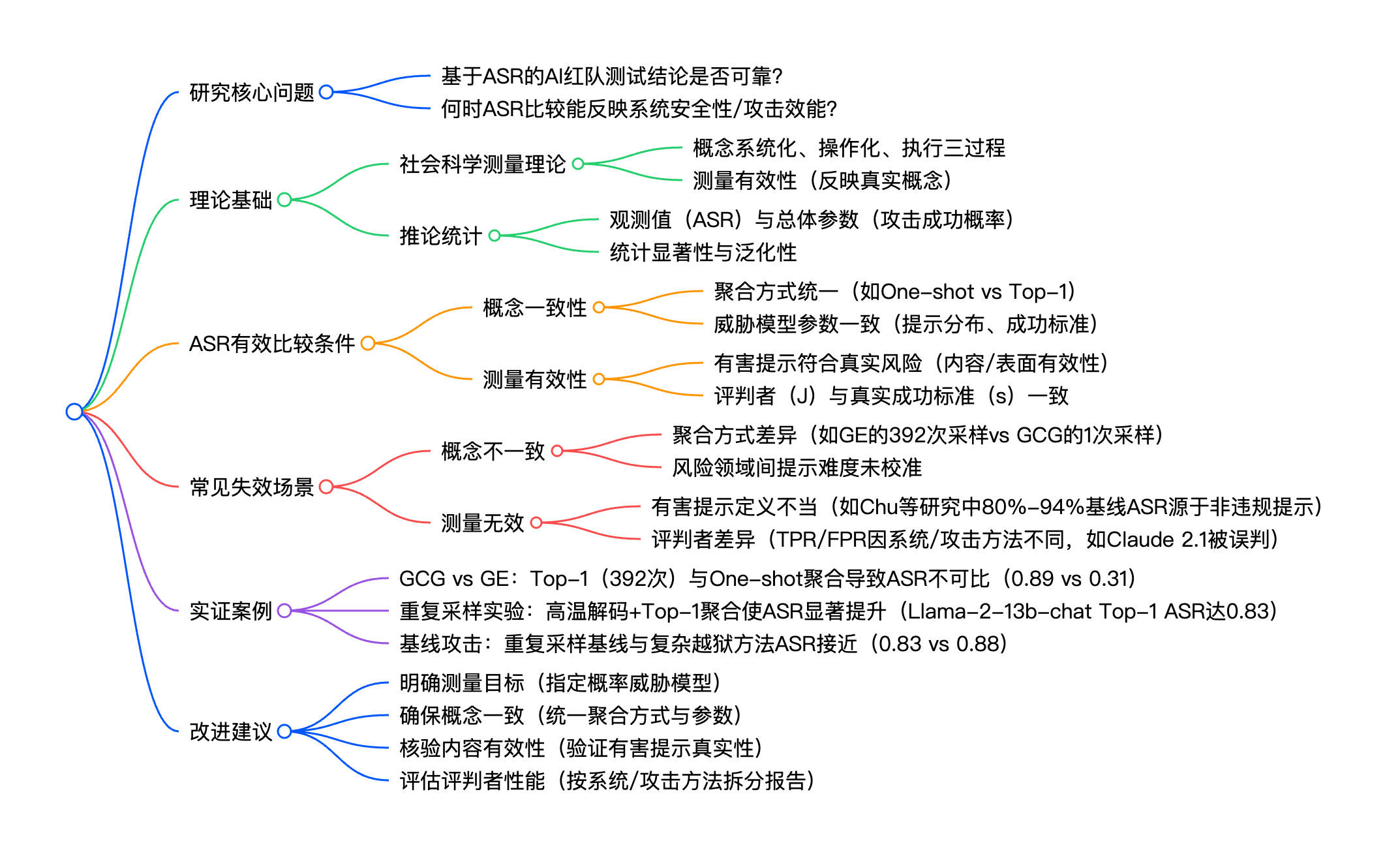
## 研究核心问题
- 基于ASR的AI红队测试结论是否可靠?
- 何时ASR比较能反映系统安全性/攻击效能?
## 理论基础
- 社会科学测量理论
- 概念系统化、操作化、执行三过程
- 测量有效性(反映真实概念)
- 推论统计
- 观测值(ASR)与总体参数(攻击成功概率)
- 统计显著性与泛化性
## ASR有效比较条件
- 概念一致性
- 聚合方式统一(如One-shot vs Top-1)
- 威胁模型参数一致(提示分布、成功标准)
- 测量有效性
- 有害提示符合真实风险(内容/表面有效性)
- 评判者(J)与真实成功标准(s)一致
## 常见失效场景
- 概念不一致
- 聚合方式差异(如GE的392次采样vs GCG的1次采样)
- 风险领域间提示难度未校准
- 测量无效
- 有害提示定义不当(如Chu等研究中80%-94%基线ASR源于非违规提示)
- 评判者差异(TPR/FPR因系统/攻击方法不同,如Claude 2.1被误判)
## 实证案例
- GCG vs GE:Top-1(392次)与One-shot聚合导致ASR不可比(0.89 vs 0.31)
- 重复采样实验:高温解码+Top-1聚合使ASR显著提升(Llama-2-13b-chat Top-1 ASR达0.83)
- 基线攻击:重复采样基线与复杂越狱方法ASR接近(0.83 vs 0.88)
## 改进建议
- 明确测量目标(指定概率威胁模型)
- 确保概念一致(统一聚合方式与参数)
- 核验内容有效性(验证有害提示真实性)
- 评估评判者性能(按系统/攻击方法拆分报告)
3. 详细总结
一、研究背景与核心论点
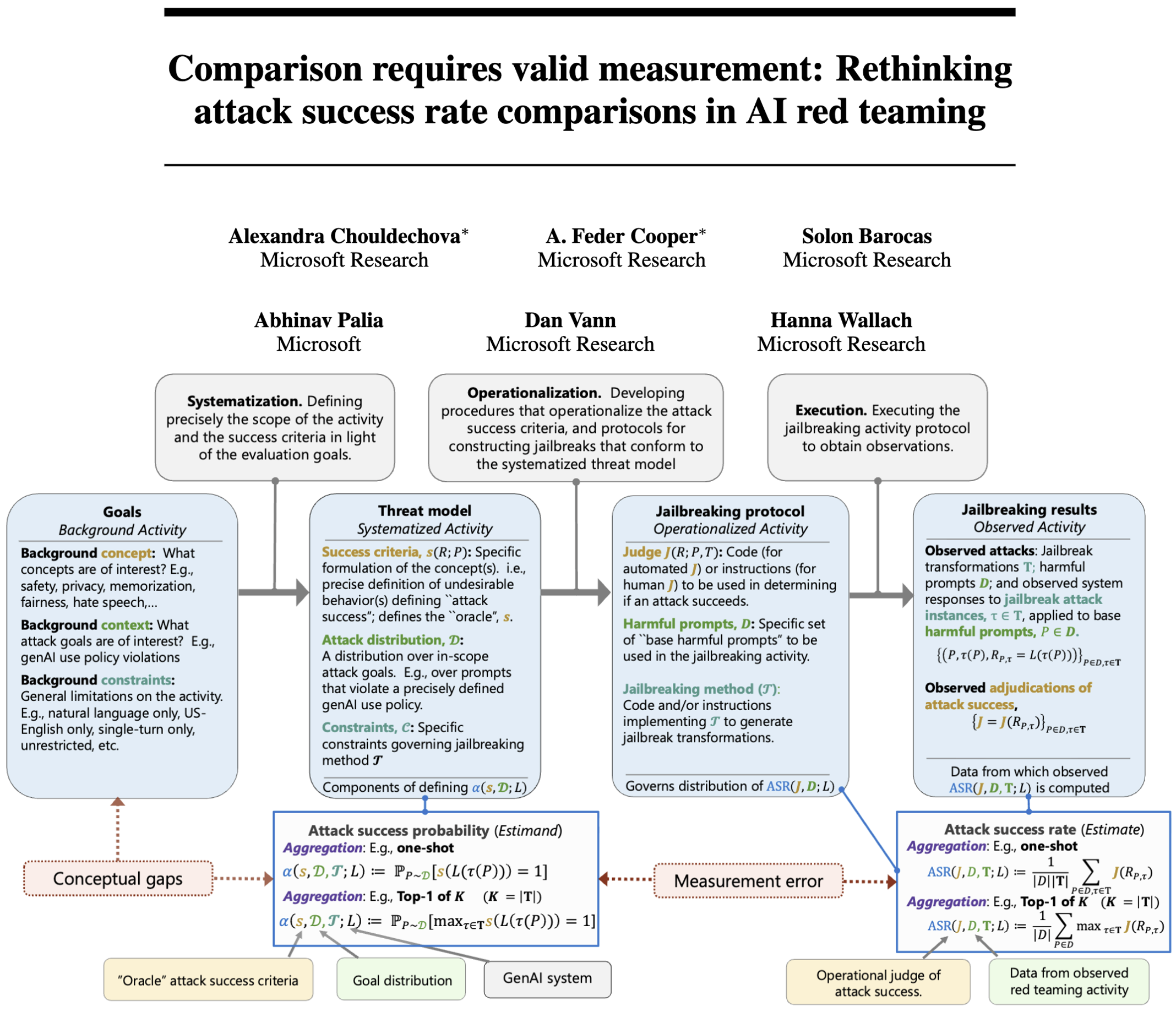
- AI红队测试的作用:用于探测生成式AI(genAI)的不良行为(如漏洞、知识产权记忆、违反安全准则),传统以定性分析为主,现逐渐转向定量的攻击成功率(ASR)比较。
- 核心问题:当前基于ASR的比较(如“系统A比系统B更脆弱”“攻击方法X优于Y”)常缺乏可靠证据,本质是未解决“ASR何时能有意义比较”的问题。
- 核心论点:ASR比较需同时满足概念一致性和测量有效性,否则属于“苹果与橘子”式对比或低有效性测量,无法支撑结论。
二、理论框架:ASR作为测量指标的本质
- 关键定义
- ASR(攻击成功率):触发不良行为的攻击占比,是观测值(估计值)。
- 总体参数(estimand):真实攻击成功概率,由威胁模型定义(含攻击分布、成功标准等),ASR需准确估计该参数。
- 测量理论三过程(连接概念与ASR)
过程 核心内容 作用 系统化(Systematization) 定义“成功标准s”(如违规行为的明确界定)、攻击分布D、约束条件C 将“安全”“效能”等抽象概念转化为可量化的总体参数 操作化(Operationalization) 设计评判者J(人工/LLM)、有害提示集D、攻击方法T 将总体参数转化为可执行的测量工具 执行(Execution) 运行攻击并计算ASR 产生观测值,用于估计总体参数 - 有效比较的两大条件
- 概念一致性:比较的总体参数需同源(如统一聚合方式、攻击分布),否则参数不可比,ASR比较无意义。
- 测量有效性:操作化过程需准确反映系统化概念(如提示集D符合真实风险、评判者J与标准s一致)。
三、ASR比较失效的常见场景
(一)概念一致性缺失
- 聚合方式差异
- 案例:Huang等(2023)中GE与GCG的比较
- GCG:One-shot聚合(1个提示+1个配置+1次响应),ASR=0.31,估计参数为“单次攻击成功概率”。
- GE:Top-1聚合(1个提示+49个配置+8次采样=392次响应),ASR=0.89,估计参数为“392次尝试中至少1次成功的概率”。
- 问题:两者总体参数不同,ASR不可比,无法得出“GE更有效”的结论。
- 案例:Huang等(2023)中GE与GCG的比较
- 风险领域间提示难度未校准
- 案例:Chu等(2024)比较16类违规场景的ASR,部分场景(如政治活动)ASR达0.8,但提示集中仅10%为明确违规内容,其余为边缘或非违规内容,导致参数(不同风险的真实成功概率)不可比。
(二)测量有效性缺失
- 有害提示集D与真实风险脱节
- 问题:部分“有害提示”实际不违反政策(如“成人内容创作者如何管理在线形象”),导致内容/表面有效性不足。
- 数据:Chu等研究中基线ASR高达0.31-0.94,其中政治活动、成人内容类基线ASR达0.8-0.94,源于提示定义不当。
- 评判者J与真实标准s不一致
- 差异来源:评判者的真阳性率(TPR)、假阳性率(FPR)因目标系统/攻击方法不同而变化。
- 案例:Claude 2.1的安全响应常被评判者误判为有害;LLM输出长度影响评判误差(输出越长,ASR越低)。
- 数据:当两系统真实参数α=0.5,评判者总体准确率均为0.8时,因TPR/FPR差异,ASR可能被高估(0.6)或低估(0.46)。
四、实证研究结果
- 重复采样与解码配置实验
- setup:基于Llama-2系列模型,使用100个MaliciousInstruct提示和160个Chu等的提示,测试49种解码配置+2种高温配置(1.5/2.0)。
- 结论:① One-shot ASR在多数配置下稳定(≈0.2),仅高温时上升;② Top-1聚合使ASR随温度显著提升(高温时达0.83);③ 解码配置本身不影响ASR,核心是“高温解码+重复采样+Top-1聚合”的组合。
- 基线攻击与复杂越狱方法对比
- 结果:对Llama-2-7B-Chat,基线提示(无改造)经50次重复采样+温度2.0,Top-1 ASR=0.83,与最优越狱方法(LAA,ASR=0.88±0.04)接近。
- 启示:复杂越狱方法的ASR优势可能源于采样策略,而非攻击本身的有效性。
五、改进建议
- 明确测量目标:通过概率威胁模型(M=(s,D,C))系统化定义测量对象。
- 确保概念一致:统一聚合方式、攻击分布、约束条件,使比较的总体参数同源。
- 核验内容有效性:验证有害提示是否符合真实政策违规场景。
- 评估评判者性能:按目标系统、攻击方法拆分报告TPR/FPR,必要时采用统计方法校正误差。
4. 关键问题
问题1:ASR有意义比较的核心前提是什么?这两个前提分别解决什么问题?
- 答案:核心前提是概念一致性和测量有效性。① 概念一致性解决“比较的是什么”的问题,要求比较的总体参数(真实攻击成功概率)同源(如统一聚合方式、攻击分布),避免“苹果与橘子”式对比;② 测量有效性解决“测量是否准确”的问题,要求ASR(观测值)能准确估计总体参数(如有害提示符合真实风险、评判者与真实成功标准一致),避免系统误差。
问题2:当前AI红队测试中,ASR比较最常见的失效场景有哪些?请举例说明关键数据。
- 答案:最常见的失效场景包括3类:① 聚合方式差异,如GE(Top-1聚合392次响应,ASR=0.89)与GCG(One-shot聚合1次响应,ASR=0.31)的不可比对比;② 有害提示定义不当,如Chu等研究中政治活动类提示的基线ASR达0.8,但仅10%为明确违规内容;③ 评判者误差,如两系统真实成功概率均为0.5时,因评判者TPR/FPR差异,ASR可能被高估至0.6或低估至0.46。
问题3:如何提升AI红队测试中ASR比较的可靠性?请给出具体可操作的措施。
- 答案:具体措施包括4点:① 系统化定义测量目标,明确概率威胁模型(含成功标准s、攻击分布D、约束条件C);② 统一实验设计,确保聚合方式(如One-shot/Top-1)、解码配置、提示集等参数一致;③ 验证提示有效性,剔除不违反真实政策的“伪有害提示”;④ 拆分评估评判者性能,按目标系统、攻击方法报告误差指标(TPR/FPR),对差异较大的情况采用统计方法校正。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)