中国海洋大学-2025计算机网络TCP大实验-洪峰
本文详细介绍了TCP协议迭代开发实验的全过程,从基础的Rdt1.0到最终的Reno版本。实验通过逐步增加网络传输中的错误假设(位错、丢包、延迟等),实现了校验和计算、超时重传、滑动窗口、拥塞控制等核心功能。重点解决了Tahoe阶段慢开始重传的实现难题,创新性地在waitAck中补充重传逻辑。实验采用Git进行版本控制,验证了迭代开发在复杂工程中的优势,但也指出了实验文档要求冗余、框架说明不足等问题
前排提醒:本报告仅代表个人的特色做法,可做的做法有很多,仅供参考。
参考及感谢以下文章:
计算机网络-洪锋-中国海洋大学OUC-TCP实验-大作业-实验报告-JAVA
目录
实验目的及要求:
- 结合代码和LOG文件分析针对每个项目举例说明解决效果。(16分)
- 未完全完成的项目,说明完成中遇到的关键困难,以及可能的解决方式。(2分)
- 说明在实验过程中采用迭代开发的优点或问题。(优点或问题合理:1分)
- 总结完成大作业过程中已经解决的主要问题和自己采取的相应解决方法(1分)
- 对于实验系统提出问题或建议(1分)
实验内容:
本次实验要在所给代码框架下,借助git工具实现迭代开发,最终要完成一个拥有拥塞控制的Reno版本的TCP协议。实验框架的UML图如下:
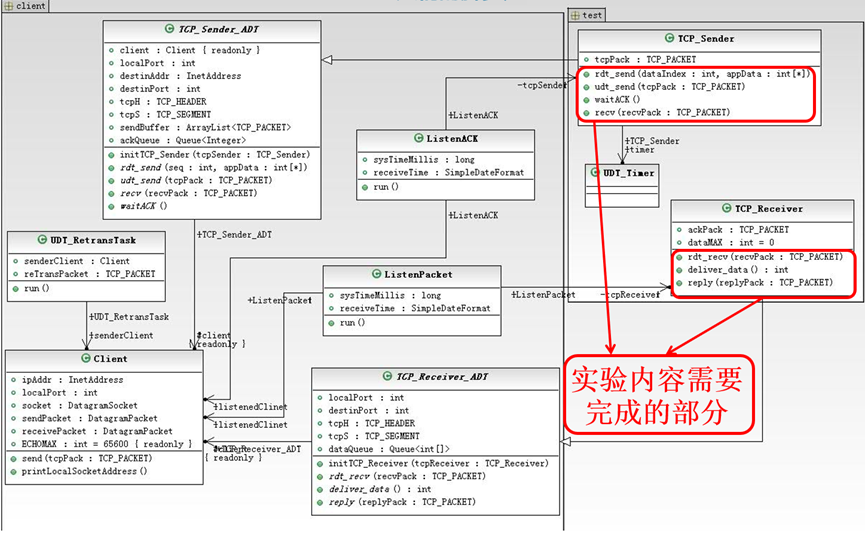
图 1实验框架的UML图
其中实验内容需要修改完成的部分为接收端和发送端。两者的通信模型如下图所示:
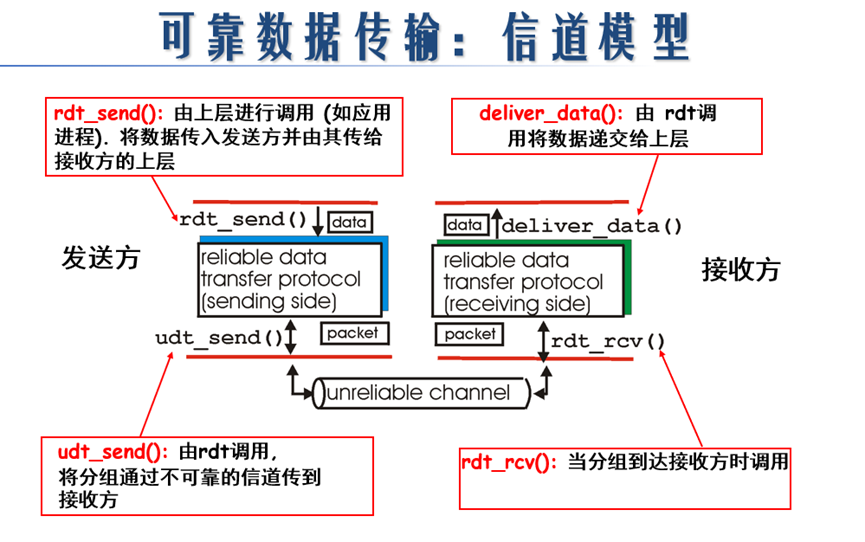
图 2可靠数据传输的通信模型
## 注意
本人在这次实验的所有版本实现中,确认包的序号都是指向当前序号,而非接收方期待收到的序号,序号用字节流号。
Rdt1.0
实验代码的初始框架即为Rdt1.0版本。
发送方由上层调用rdt_send,准备好数据包以后通过udt_send进行传输,随后进入等待阶段,用recv进行收包,再在waitACK中进行确认。
接收方由rdt_recv进行接收数据并将数据写入dataQueue中,由deliver_data进行写入数据,由reply来回复ack包。
Rdt1.0版本认为所依赖的信道非常可靠,因此无需各种差错控制,发送方只需要一直发送并等待ack,接收方只要一直等待收包并发送ack。是最基本的传输模型。
基础版本主要是用来熟悉代码框架,了解其中的不同代码接口。(比如设置tcp包序号时要使用setTh_seq等等)
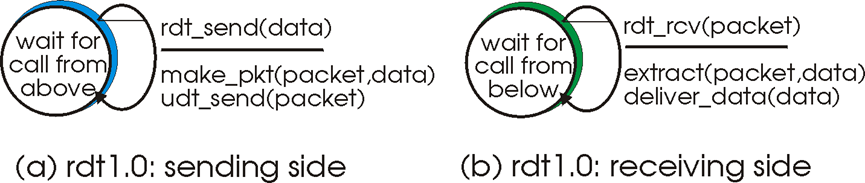
图 3 rdt1.0有限状态机
Rdt2.0
进入rdt2.0版本以后,我们的假设发生了变化,认为底层信道传输过程中,个别数据包的某些字节可能发生位错(此时我们仍然认为接收方发送ack的传输是可靠的),为此需要使用校验和算法检查数据包的正确性(发送前计算/接收后校验),即完成CheckSum类中的computeChkSum()方法。
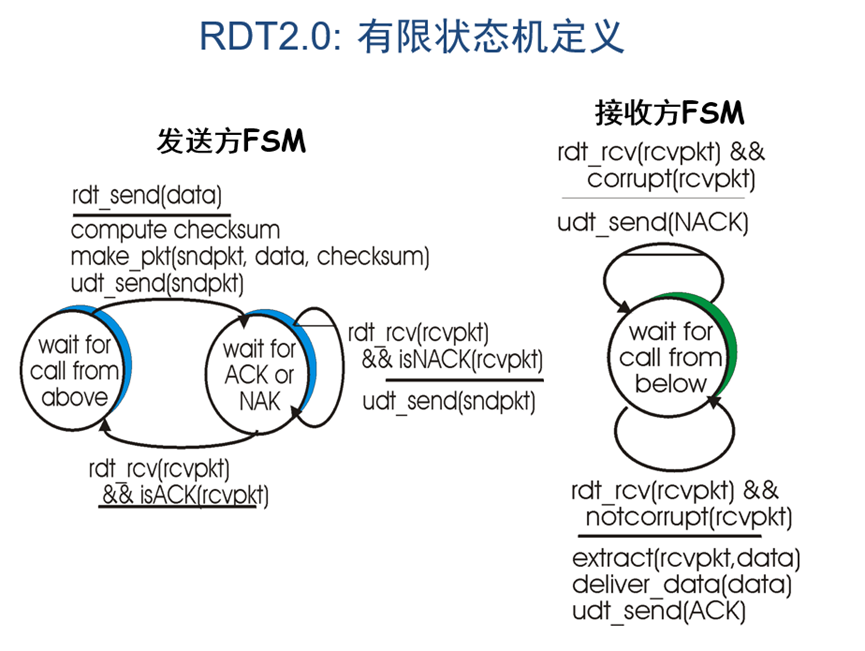
图 4 rdt2.0有限状态机
依据有限状态机所示,我们可以分析得出基本流程如下:
- 发送端在发送数据包前,需要通过computeChkSum计算校验和并填入数据包报头中并发送,随后等待发送方的报文;
- 接收方收到报文以后用同样的方式计算校验和判断是否相等,以此来判断是否损坏(corrupt),若损坏则发送NACK(ack字段为-1),若正确则发送对应的ACK(ack字段为相应包的seq字段)报文;
- 发送方收到报文以后判断是ack还是nack,若为nack则说明发出去的包出现问题,重传当前的包,若为ack则再次进入发送状态等待上方调用。
分析完基本流程以后就可以开始我们的代码编写了。首先我们需要完成computeChkSum函数实现校验和的计算。实验要求只需考虑seq、ack和数据字段。为了更好地模拟,我并没有用老师帮忙引入的CRC校验包,而是仍然仿照udp风格完成了校验码的设计(即将字段看成若干个16位的字,用二进制反码计算这些16位字的和,再取二进制反码)。
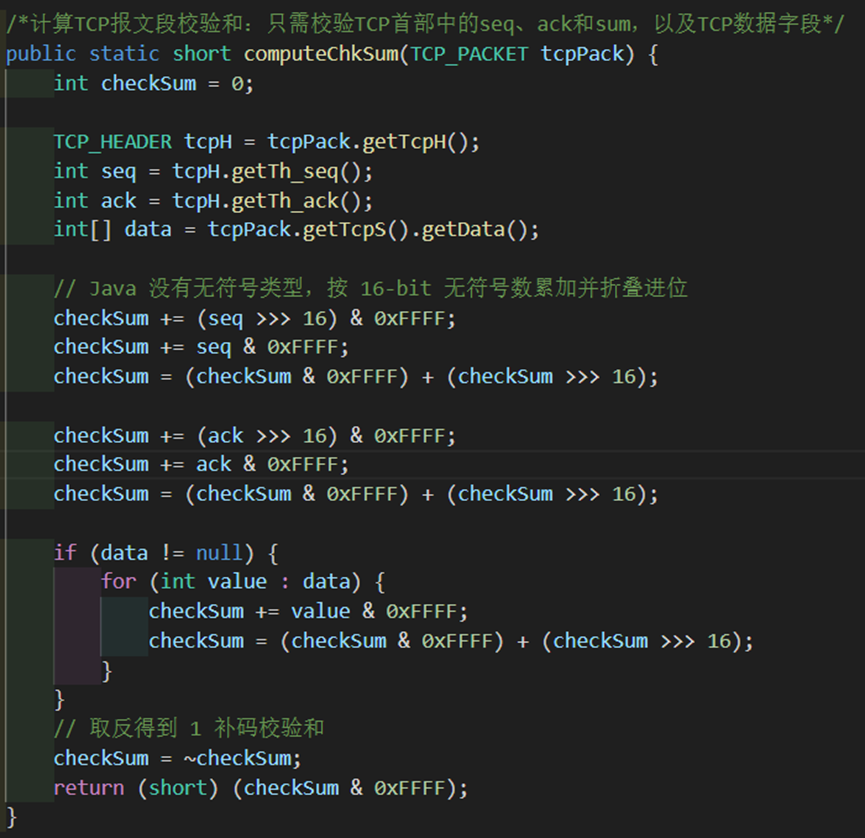
图 5 computeChkSum函数实现
computeChkSum函数的计算比较好实现,也不需要什么特殊说明。接下来我们来根据上述的几点,逐条实现发送方和接收方的具体逻辑,顺带完整过一遍代码框架整个流程。
1.发送端在发送数据包前,需要在tcpH(tcp报文头部)通过computeChkSum计算校验和,并用setTh_sum填入数据包报头中,其余字段如序列号、数据内容也有各自的set函数实现。创建一个TCP包并把包头、数据、目标地址填入,通过udt_send发包,随后利用flag=0进入等待。
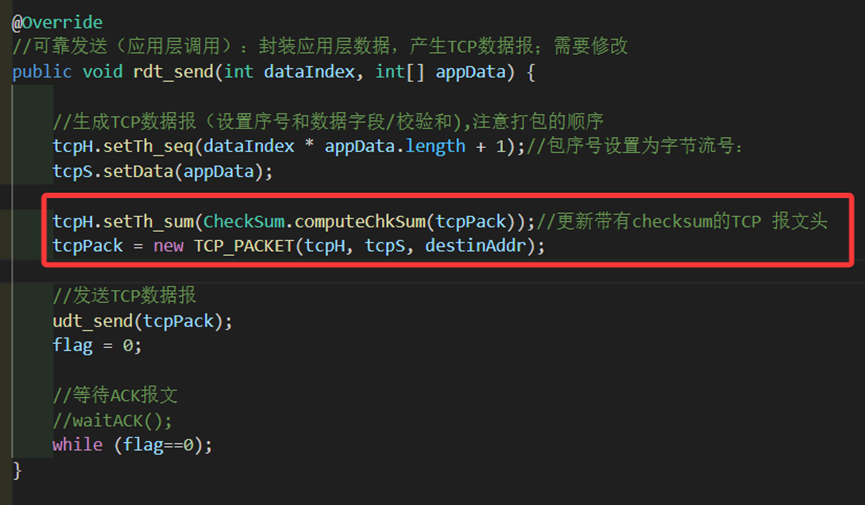
图 6 rdt_send中校验和的实现
2.接收方收到报文以后用同样的方式计算校验和,判断和包内部的sum字段是否相等。
若相等则代表正确,提取recvPack的包头,将提取出来的seq字段填入ack字段代表确认接收,同样也要将自己的校验和填入,随后发送对应的ACK包,将接收到的正确数据存入。
若不相等则代表损坏,则不提取包头也不处理数据,而是直接让ack字段为-1代表NACK,用上述类似的方式构造回复包,随后回复NACK包。
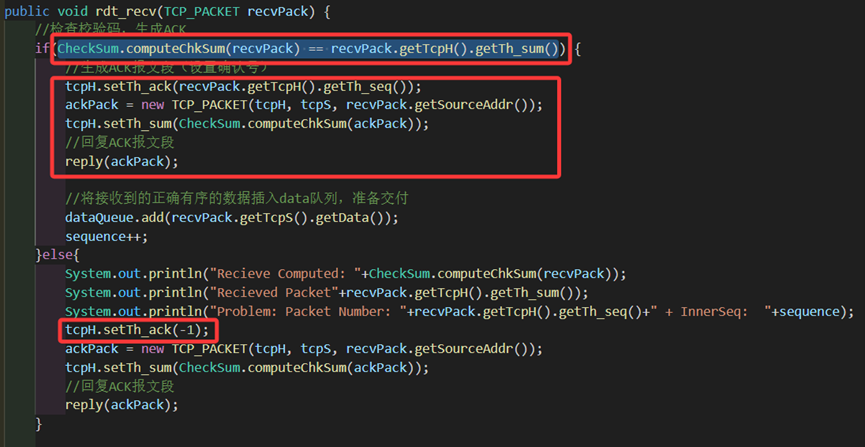
图 7 rdt_recv中校验和的实现和处理,以及如何产生ack和nack的序号
3.发送方收到报文以后判断是ack还是nack,若为nack(nack的ack字段为-1,不可能与当前包的seq序号相等),则说明发出去的包出现问题,重传当前的包。若为ack则利用flag=1再次进入发送状态等待上方调用。
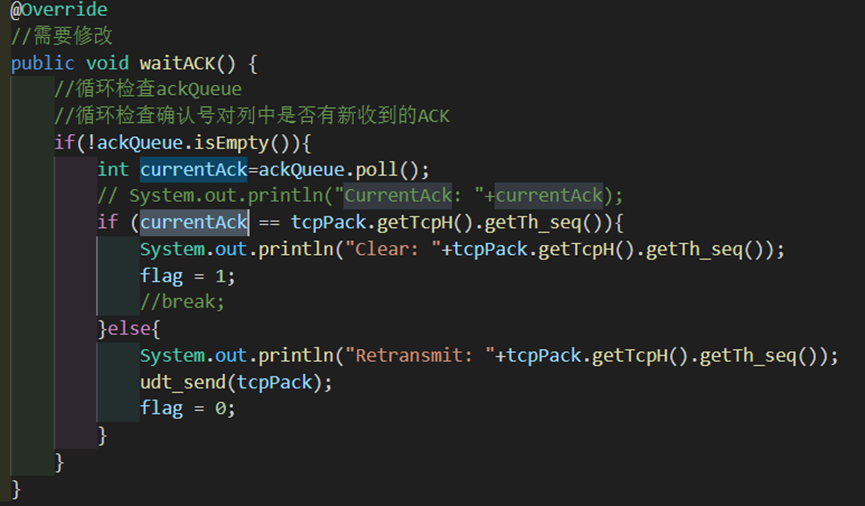
图 8 发送方收到确认后的处理
至此rdt2.0所需要的错误控制以及基本的发包收包的代码流程已经过了一遍。现在将发送方的错误控制标志设为1(只出错)进行发包并查看log结果进行分析。
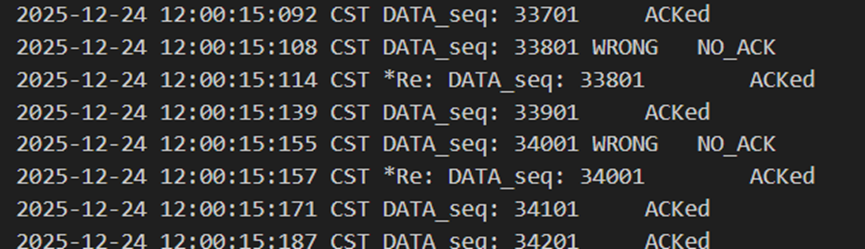
图 9 发送方发包出错和重传
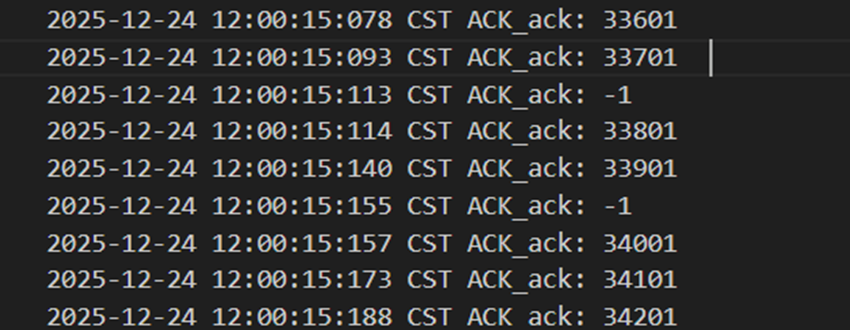
图 10 接受方收到错误包后回NACK
不难发现,当发送方发送正常包的时候,接收方也回复了同样序号的ack代表正确的确认。而当发送方发送错误包(如33801、34001)时,接收方会通过校验和判断收到的包出现了位错,回复序号为-1的NACK代表错误,也因此33801和34001在图9中显示的都是NO_ACK,发送方收到-1以后因为序号不一致,会进行重发(如图9的*Re指示),再次重传的包正确到达接收方以后,接收方会像正常情况一样发送对应序号的ack。
经检查可发现,最终发送方发了1004个包,其中4个错误包,接收方接收到了1000个包,写入数据100000行。证明通过校验和的设计,顺利地实现了在发送方发送的数据有位错的情况下仍能正确传输。
Rdt2.2
我们不难发现,rdt2.0版本的假设依然很理想,因此我们需要引入新的假设来完善,我们先了解一下rdt2.1提出了什么新的假设:
若ACK/NAK报文也会出错,在rdt2.0里发送方将不会知道接收端发生了什么,而且此时如果进行重传,由于接收方没有做包序号的控制,将可能发生数据重复。
为了解决这些问题,我们给发送方给每个分组加上sequence number(也就是seq),如果ACK/NAK出错,发送方则重传当前分组;接收方则要对收到的包进行序号判断是否符合预期,若重复、乱序或错误则要返回NAK,丢弃重复的分组 (不向上递交),若正确则通过序号指明是对哪个数据包的确认,即回复对应ack=seq的ACK包。
而rdt2.2则是在上述的基础上,将NAK改成重复的ACK包,这样子对发送方来说,和收到NACK的效果其实是一样的,发送方将会重发当前数据包。
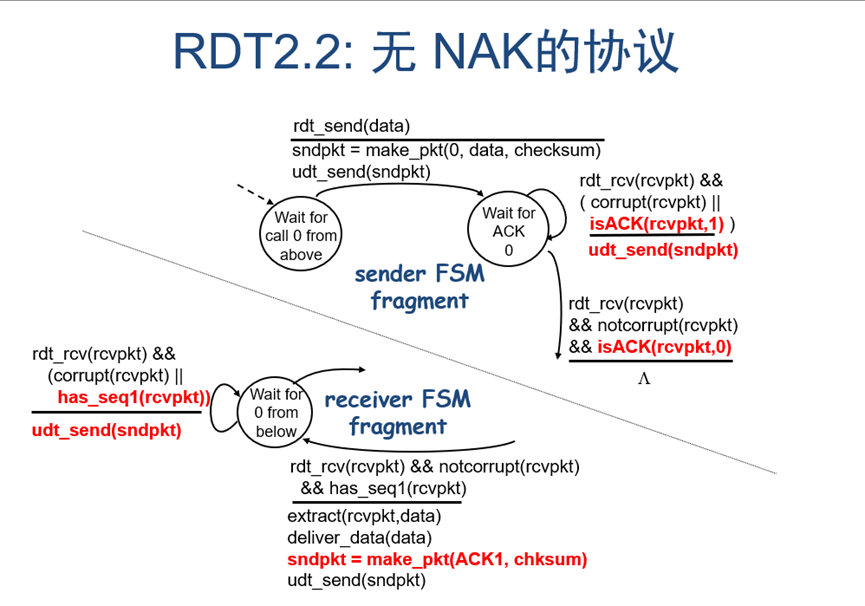
图 11 rdt2.2有限状态机
基于先前完成的代码,需要额外做到的目标主要有以下几点:
- 如果ACK出错,发送方则重传当前分组;
- 接收方则要对收到的包进行序号判断,若重复、乱序或错误则要回复上一次回复的ACK,丢弃重复的分组 (不向上递交);若正确则回复对应ack=seq的ACK包。
我们现在来逐一改进代码。
第一步,我们需要为发送方的接收ack功能增加用校验和判断的功能。
若收到错误的ACK,则直接重传当前的包(也就是刚才发出去的包);否则接收ACK并加入ACK队列,用rdt2.0同样的waitack逻辑进行接收。
需要注意的是,如果出现了重复的确认(比如发送包错误导致接收方传来了同样的ack时),这正是我们rdt2.2所要求用重复ACK代替NACK的情况,此时只需要和之前逻辑一样进行重传就行。而由于重复ACK和NACK在发送方看来都可以用“和当前发的包序号不一致”来判断,因此waitack中的逻辑不需要更改。
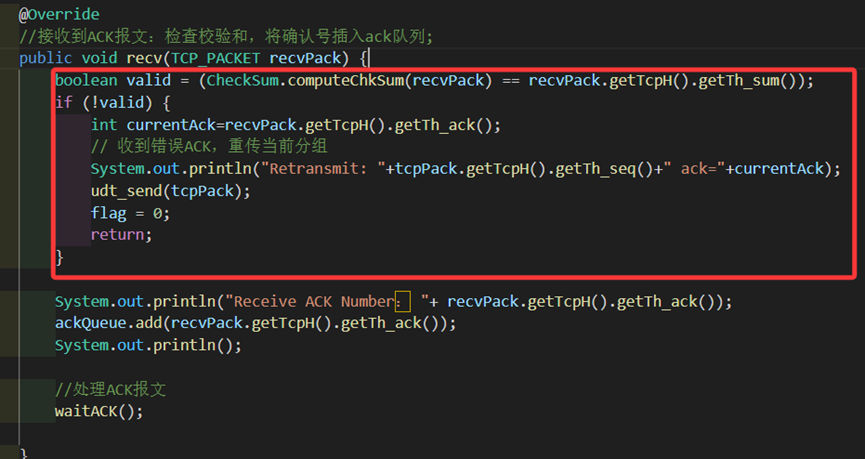
图 12 发送方recv中检验ACK是否错误
第二步,我们要为接收方新增seq序号判断的功能。
初始需要定义我们期望接收的包号,和上一次确认的包号,以方便我们进行设计,初始定义如下:
int expectedSeq = 1; //期望接收的报文序号
int lastAck = 0; //已正确接收的最大序号判定条件除了判断是否是错包以外,还要判断是否是期望收到的序号。
若正确且符合期望,则正常地收包,让ack字段为当前包的seq代表确认,调用reply回复ACK。这里需要注意更新expectedSeq和lastAck,使得lastAck等于刚刚用来确认的期望序号,expectedSeq将自身加上当前收到的包的数据长度data.length来前移至下一个字节流号。
若包重复、乱序(不符合expectedSeq)或错误(校验和错误),则要回复上一次回复的ACK来当做否认的信号,也就是将ack字段设置为lastAck并重发,丢弃重复的分组。
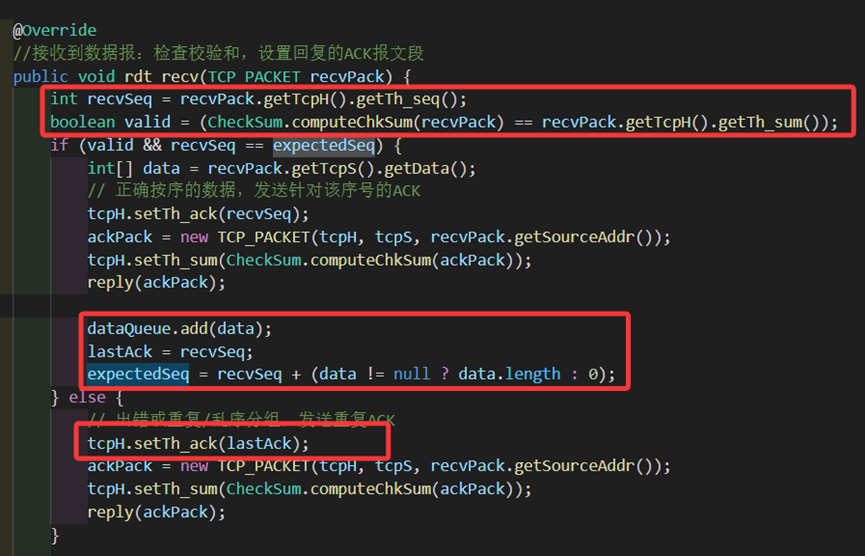
图 13 接收方rdt_recv中对seq的检查
接下来我们将两边的错误标志位都设为1(只出错),启动test后观察Log文件。分为两个情况:发送方报文出错,以及接收方ack出错。
如图14和图15,当发送方报文18101出错时,接收方回复的ack序号是18001(也就是上一个接收的序号),以此来代表否定。发送方收到18001时知道自己出了问题,于是重发18101,再次重发的包被接收方正确接收并回复18101。
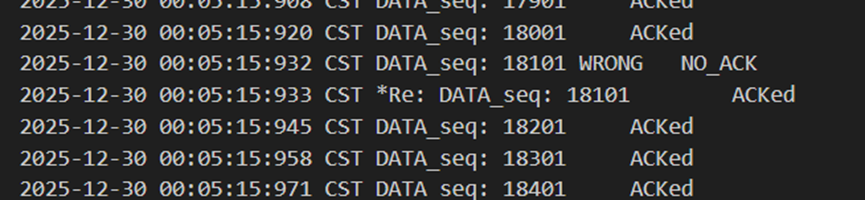
图 14 发送方发包出错和重传
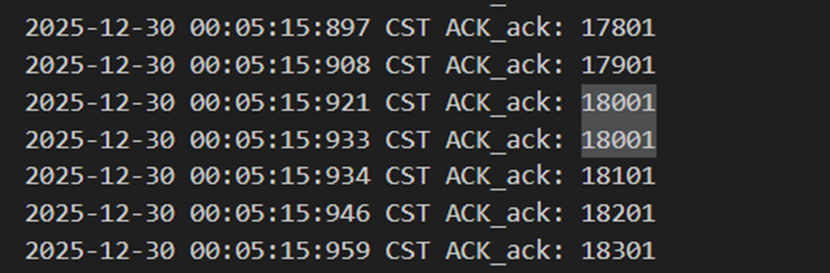
图 15 接收方收到错包后进行重复确认
如图16和图17,接收方收到24301以后想回复Ack但是出错了,此时发送方收到出错的包并进行重传,接收方收到重复的24301以后,和预期收到的包号不符,因此回复laskAck(也就是24301),发送方再次收到ack包后知道是对24301的确认,从而继续发下一个包。
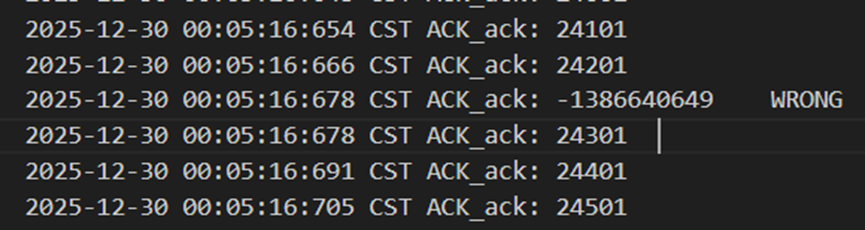
图 16 接收方ack出错
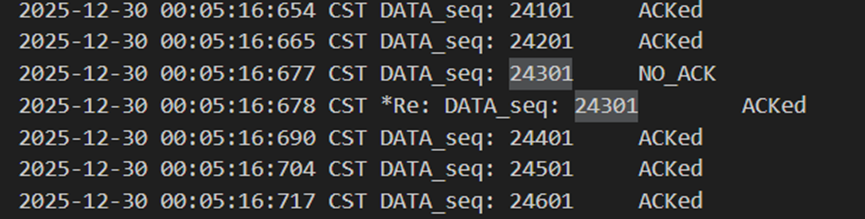
图 17 发送方重发包
在这个阶段我们让发送方也有了错误处理的能力,同时增加了变量用来记录期望的包序号和上一次确认的包号,实现了接收方收到不符合预期的包的时候,能正确回复上一条ACK,用来代替原先的NACK实现了否定。而且接收方也能够根据包序号来阻拦重复的包,避免数据包的重复交付。
Rdt3.0
之前我们已经通过检测序列号、校验和的手段解决了包出错的情况,并用适当的重传机制保证了数据的交付,此后我们可以不用再关心出现位错的情况了。
但现在Rdt3.0又提出了新的假设。通道上不仅可能出错,还可能丢失数据(延迟、丢包)。比如发送方发出去的包根本没到达或者很晚才到接收方,在这期间两者都不会做任何事,整个程序都会停住陷入死锁状态。接收方发的Ack丢失了同理。
而解决方法很简单: 发送方等待ACK一段“适当的”时间,如果在这段时间里没有收到ACK,则进行超时重传。如果分组(或ACK)仅仅被延迟了(没有丢失)时,虽然重传会导致重复, 但使用我们在rdt2.2里实现的seq判断就可以进行控制。在本阶段中发送方需要1个计时器进行倒计时实现重传。
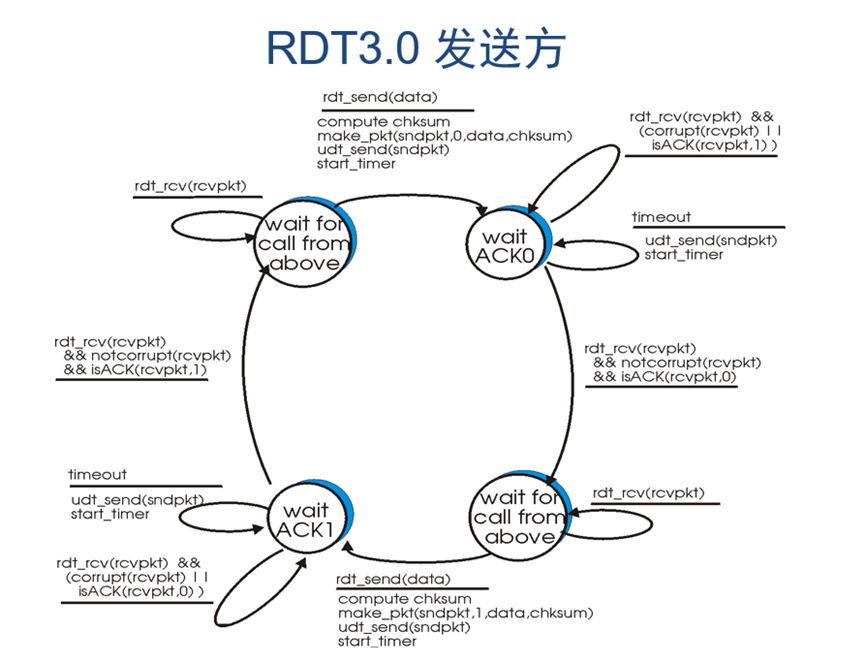
图 18 rdt3.0发送方有限状态机
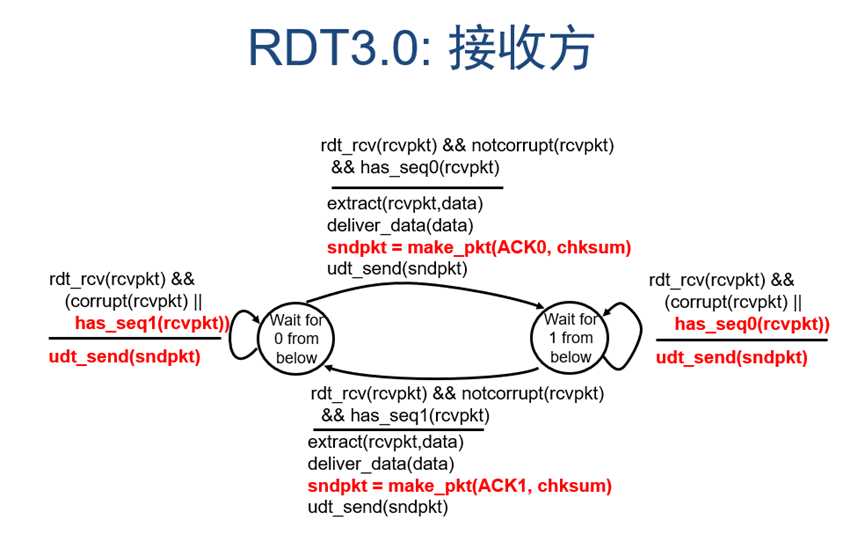
图 19 rdt3.0接收方有限状态机
通过分析可知,rdt3.0中接收方和rdt2.2的其实完全一样,不需要做出任何改变。发送方则相比之前版本需要在发送包以后启动计时器用来检测是否超时,若超时则重发之前发出去的包。其余条件和rdt2.2一样。
老师已经为我们导入了一个UDT_Timer包(继承自java的Timer类)和UDT_RetransTask
包(继承自java的TimerTask类),我们的目的就是为发送方引入这个超时的设计。在此我们需要定义以下变量:
private static final int TIMEOUT_MS = 3000; //超时时间
private UDT_Timer timer; //定时器(用于周期性重传)
private UDT_RetransTask retransTask; //重传任务根据逻辑,我们需要在发包以后重设计时器,计时器的任务是等待3秒以后重传当前的包,并且之后每隔3秒都要进行一次。因此我们在发包前用cancel等代码确保之前的计时器停止了,再设立一个计时器。其中retransTask是调用接口重传发包的任务,timer是计时器,用来在3秒之后每隔3秒执行一次retransTask。
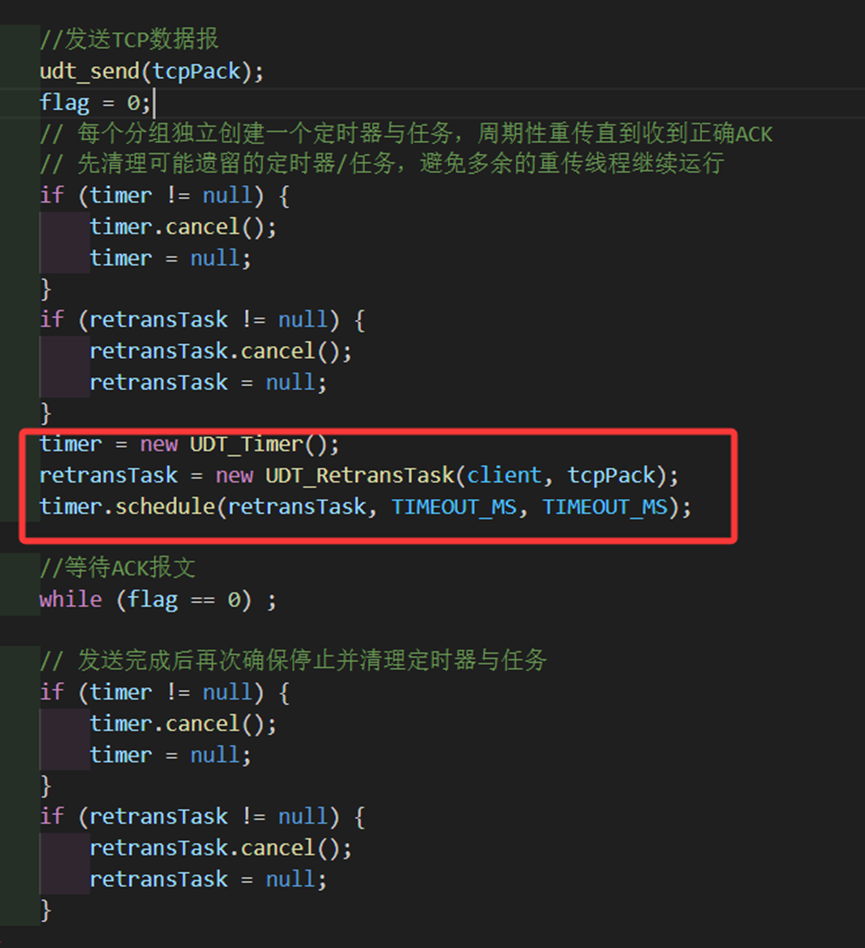
图 20 发送方计时器的设定
有了计时器的设立也要有相应的取消,当我们接收到我们想要的ack时,应当取消掉我们现在的计时器,防止出现即使收到ack仍在重传的错误情况。
需要注意的是,当ack不是我们预期时,我们不再直接重传,而是等待计时器超时以后自动重传,具体说明见下文。
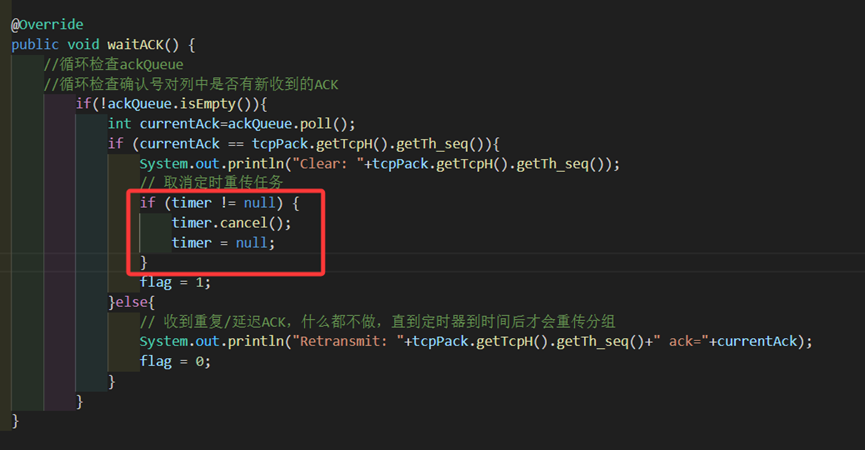
图 21 发送方收到期望ack后计时器的取消
我们会发现,从rdt2.0开始我们就一直在借助flag=1和flag=0来进行“停止等待”协议,在发出一个包以后会令flag=0,并通过while(flag==0)进入等待状态,阻塞应用层的调用;在收到正确的包以后再令flag=1,允许应用层的调用。
超时重传代码的设定部分出现的位置是在发送方rdt_send中发包的代码udt_send之后,等待ack的while循环之前, 是因为计时应该是在发包之后就开始计时;取消计时器的代码在waitACK的正确收到包之后,是因为此时收到了期望的ack以后不应该再进行这个重传任务了,所以取消掉,并将flag=1切换为发送状态。
当发送方收到重复的确认时,和以往直接重传不同,而是等待计时器超时以后自动重传。这是因为如果直接重传的话,可能会和计时器重叠,导致发送多个重传包,会浪费流量、资源,并可能造成不可控的隐式错误。
当接收方收到重复的确认时,依旧保持之前的逻辑,丢弃这个包并进行重传lastAck,确保数据交付不会出现重复,并且可以保证有正确的ack回复。
并且有着上述的逻辑,延迟包和丢失包的处理也很轻松。因为每个数据包都有对应的字节流序号seq确定,ack包的ack字段也拥有和数据包相同或不同的seq值来代表确认或否定。对于接收方,延迟到来的包会比期待序号小导致重传lastAck,而丢失包则不用管,由发送方的超时计时器来进行重传处理;对于发送方,如果收到延迟的ack,因为序号不符合预期所以丢弃,如果是丢失的ack则等待超时计时器进行重传。
至今为止,我们已经可以将发送方和接收方的错误标志位都设置为7(出错/丢包/延迟)来进行测试并观察log了。观察recvData可知包的正确内容包含在输出文件中,并且输出文件中不包含出错的包内容以及重复的包内容(数据为100000行)。
当发送方发出错误包2601时,接收方回复lastAck:2501来代表否认,随后发送方在3s过后,超时重传2601以后被接收方正确接收。
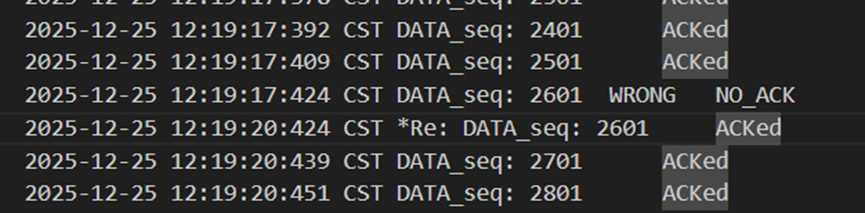
图 22 发送方发出错误包以及3s后超时重传
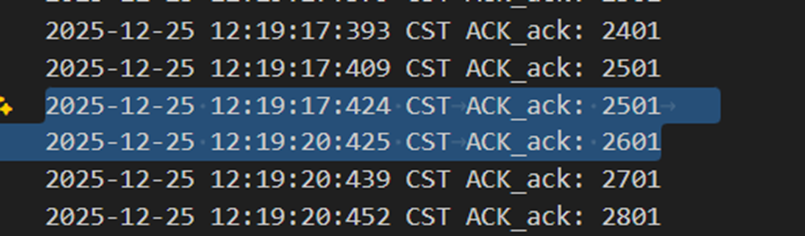
图 23 接收方收到错误包后回复上一个包号
当接收方发确认包15701出错时,发送方忽略掉错误包,并同样在3s之后进行了超时重传,此时接收方再次回复确认包15701,正确到达发送方后发送方得以继续传递后续的包。
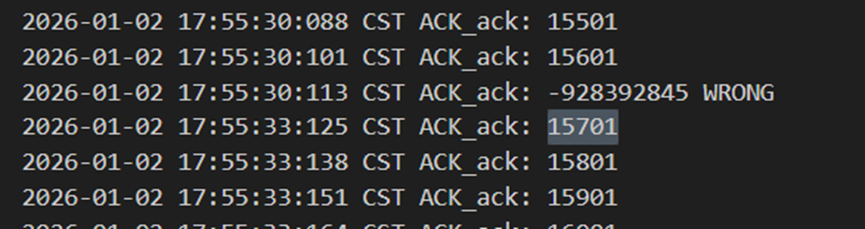
图 24 接收方发出错误确认包
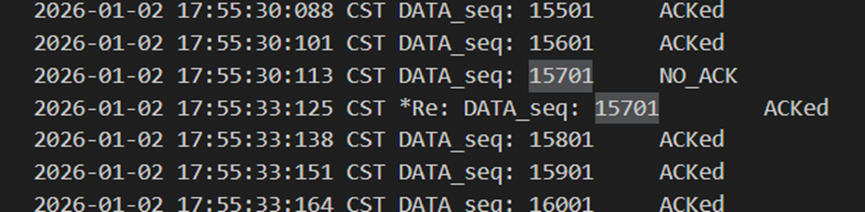
图 25 发送方忽略错误确认包并在发包后3s重传
由于丢失和延迟处理逻辑都一样,都属于丢包,因此这里loss和delay就不重复展示了。当确认包丢包或者数据包丢包时,都会导致发送方过3s之后进行超时重传。
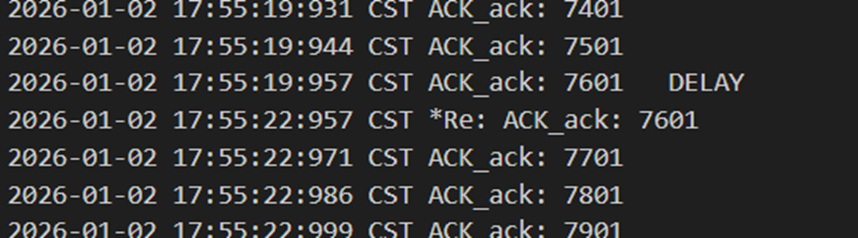
图 26 接收方确认包延迟,得到重传包后应答
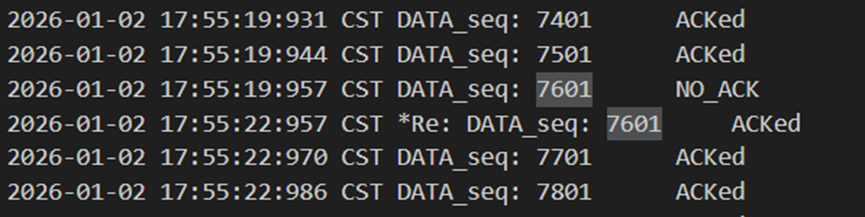
图 27 发送方未收到确认,3s后超时重传
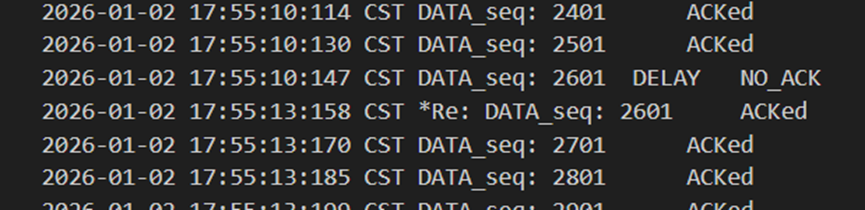
图 28 发送方丢包,并在发包后3s重传
至此,我们已经完成了rdt3.0的设计,并且已经是一个可以实现可靠传输的完善的网络传输协议了。无论是哪方出错、丢失、延迟,我们都可以利用校验和计算以及超时重传来解决问题。
Tcp
虽然在上述说明中rdt3.0完成了可靠传输,但是rdt3.0有一个致命的缺陷,那便是如果用在实际当中将会面临极大的延迟和极慢的传输速率。(因为每发一个包就要等待ack,信道的大部分时间是被浪费的)
基于此,人们提出了很多个不同的解决方案,如有go back N算法,还有Select Response算法,两者各有优劣,而汇集了两者优点的TCP协议则是脱颖而出的佼佼者。在此处我直接跳过了GBN和SR的视线,选择了一次性实现TCP,以减少设计冗余并加快设计进度。
需要注意的是,真正的TCP包括了拥塞控制,但此处的TCP是指没有拥塞控制的类GBN的“缩略版”TCP。
核心思想为以下几点:正常情况下发送方保持一个发送的滑动窗口,将发送但未确认的包记录下来,若窗口满了则要阻塞上层调用停止发送数据;接收方采用500ms的累计确认机制,确认所有按序到达的数据,当收到乱序的数据时,若序号比当前预期序号更大,则需要缓存下来称为失序缓存,等待之后数据到齐以后一并交付;发送方收到返回的累计ACK报文后,需要将所有seq<=ack的报文从滑动窗口中移除,并前移滑动窗口。而在数据包重复或错误时,接收方丢弃包以后也仍旧是采用500ms的累计确认进行重传,只不过会发送的是重复ack包告知发送方未能收到期待的数据包。确认包重复或错误或丢失、数据包出错时,统一由发送方超时重传进行处理。
归纳总结可知我们需要在rdt3.0基础上额外增加或更改的功能:
1.增加发送方的滑动窗口和相关处理;
2.更改计时器的使用,改为记录窗口后延发送的包,并改正超时后的发包逻辑;
3.为接收方增加失序缓存和相关处理;
4.为接收方增加为期500ms的累积确认(需要定时器)。
需要注意的是:此时我们不再是停等模型了,也不是传一个包再接收一个包,而是多个包一起发送,共用同一个发送窗口数据结构,需要注意线程之间的处理。
因此首先要做的是就是去掉先前框架中在类中定义的成员变量数据包,改为函数内局部变量packet,防止不同线程之间发生混淆。
此后也有许多代码地方需要注意线程之间的作用,包括用volatile字段声明变量达到线程之间一致,以及使用synchronized字段实现同步,之后便不再赘述。
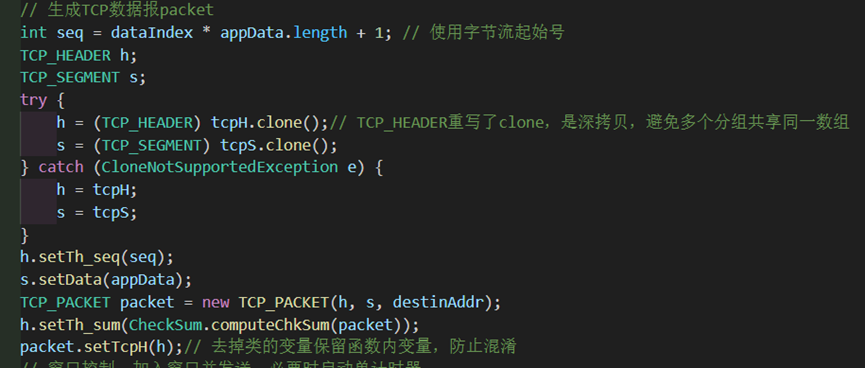
图 29 数据包的逻辑改为局部变量packet
接下来来看第一点和第二点,我们需要增加发送方的滑动窗口和相关变量。对窗口大小和滑动窗口以及辅助用的锁的定义如下:
private static final int WINDOW_SIZE = 20;// 滑动窗口大小(按分组计)
// 发送窗口未确认分组:按序号(th_seq)排序,缓存包内容
private final java.util.LinkedHashMap<Integer, TCP_PACKET> unacked = new java.util.LinkedHashMap<>();
private final Object lock = new Object();其中发送窗口固定为20,发送窗口unacked数据结构为LinkedHashMap。在发包调用之前需要判断窗口是否已满,若unacked.size() >= WINDOW_SIZE则说明窗口已满,需要通过lock.wait()进行等待并阻塞发送线程。每当要发送一个包的时候就通过unacked.put(seq, packet)来将包的数据“暂存”至发送窗口。若当前是窗口的第一个包,则为该包添加计时器,这样就可以实现记录窗口后延发送的包的目的了。
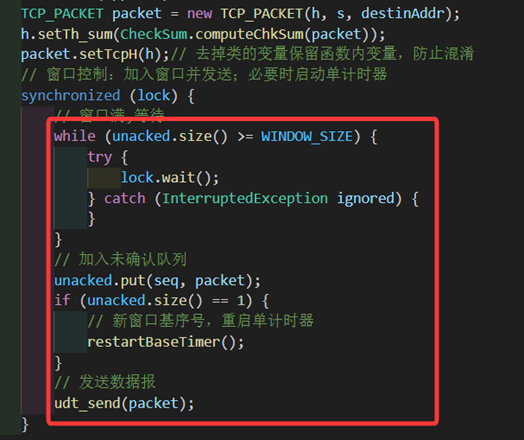
图 30 发送方发送时窗口和计时器的逻辑
与此同时,我们需要完成窗口前移操作。当我们接收到一个包时,若为错误包则直接丢掉不进入ackQueue;若unacked为空则说明该ack是对之前的包的确认,直接跳过;若ack符合期待,则将unacked中所有seq<=ack的分组用remove移除掉,为了防止出现这是对先前的包的ack(即ack<unacked中任意的seq)而错误地唤醒发送线程和重设计时器,因此需要有个窗口移动的标志位baseAdvanced,若移动了则唤醒,并重设计时器。
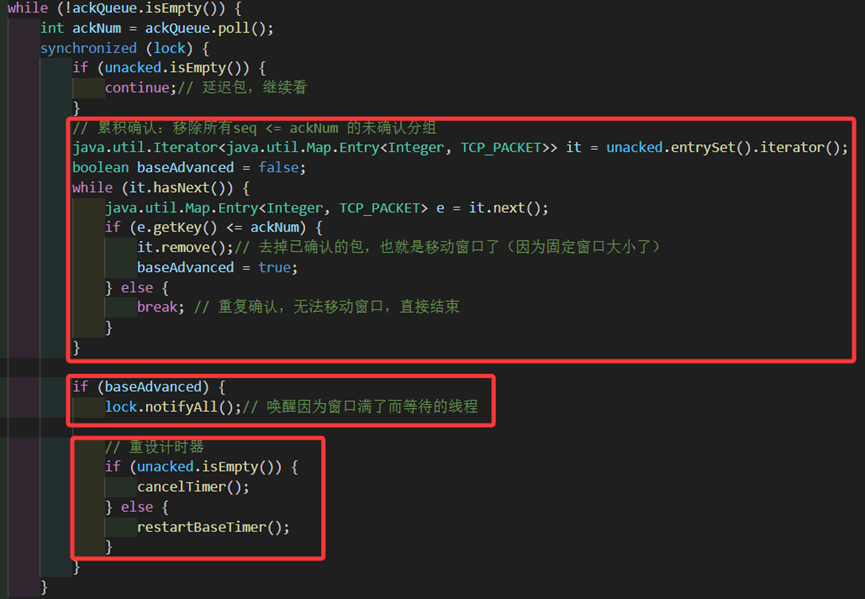
图 31 发送方收包时窗口和计时器的逻辑
而对于计时器,为了方便起见我写了两个函数,一个函数是取消计时器,一个函数是重启计时器。值得注意的是:当触发超时重传时,需要发送窗口内所有的包而不是只传一个包。(这也是为何本章开头提到这是类GBN的TCP)
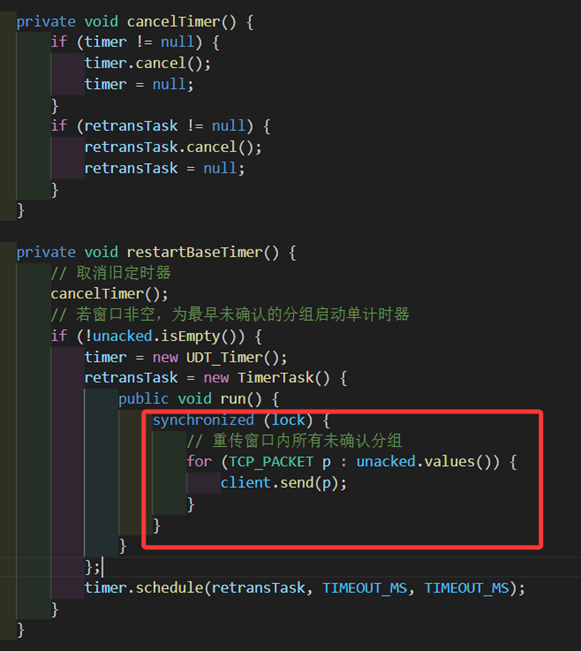
图 32 发送方超时重传内部逻辑
再然后我们来完成第三点和第四点。为接收方增加失序缓存和相关处理,并且需要增加为期500ms的累积确认。对于失序缓存、定时器相关的变量声明如下:(此时之前用到的lastAck被pendingAck替代掉)
private static final int DELAYED_ACK_MS = 500; // 累计确认延迟时间
private Timer ackTimer; // 延迟ACK定时器
private TimerTask ackTask; // 延迟ACK任务
private volatile int pendingAck=0; // 累计ACK值500ms的累积确认比较容易实现。我只需要有一个计时器,当我想要启动时,过个500ms发送ack= pendingAck的确认包即可。需要注意的是可能有多处需要调用累计确认的发包函数scheduleDelayedAck,因此需要对是否已有计时任务进行判断,若有则不更新计时,防止不断调用导致ack一直延迟的错误。
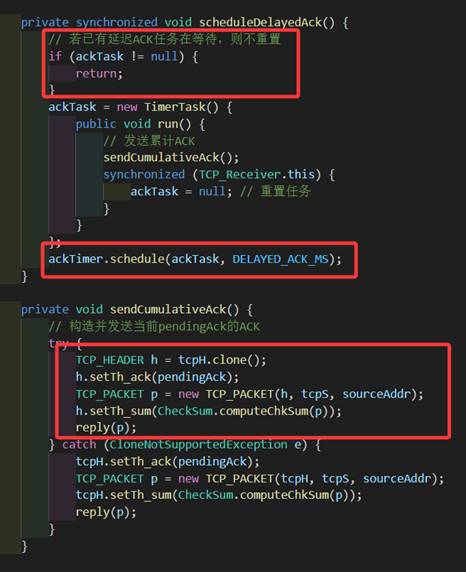
图 33 接收方累积确认发包函数的内部逻辑
当接收方收到错误包时仍旧直接抛弃不管。
若不是则判断收到的包是否符合预期,若是则收下包,更新pendingAck和expectedAck,再在失序缓存里寻找是否有下一个符合预期的包,若有则一并交付,发挥了失序缓存应有的功能。
若收到的包是比expectedAck大的,则说明发生乱序,需要将乱序的包在失序缓存中进行缓存。(需要去重,若失序缓存中已有了则不缓存,防止数据包重复交付)
若收到的包更小,则要么是延迟/重复包,要么是发给发送方的ack没有收到导致发送方进行了重传,所以此时依旧要进行重传确认包,也就是再次累计确认一下。(由于上述的三种情况最终都是要调用scheduleDelayedAck进行累积确认的发包重传,因此统一写在了判断条件外部)
需要注意的是,在先前的代码中我们交付数据时写的判断条件是dataQueue.size()==20,来达到每20个数据进行一次交付的目的。在之前是正确的因为数据永远是一个一个到来,但在这里可能通过失序缓存的累积确认以及其他情况,导致一下子来很多数据,不能确定dataQueue的具体大小情况会如何变化,因此判定条件要改为dataQueue.size() > 0。
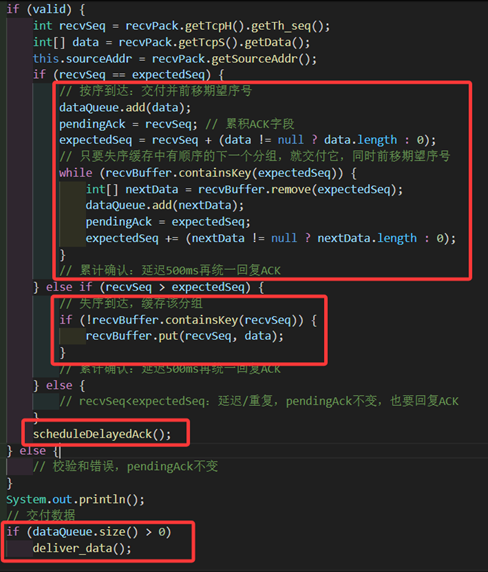
图 34 接收方乱序缓存的实现、发送确认包的逻辑和交付数据条件更改
接下来我们结合log文件具体分析每种情况。
当发送方发送的包出现了错误/延迟/丢包时,对于接收方都相当于是有一个包没有收到,所以是同样的处理逻辑。当发送方接收到15301的确认包以后打算发送接下来20个包,但其中16301出错了,接收方只能失序缓存其余的包并回复16201,此时发送方确认了16201及之前的包,将窗口前移并把多出来的窗口部分再次发满,重设计时器。发满之后线程阻塞,直到重设的计时器超时,重发了窗口内所有的包。接收方收到16301以后累计确认到18201回复给发送方。(此外接收方保证失序缓存中没有重复的包,也丢弃了延迟到来的数据包,数据不会重复提交)
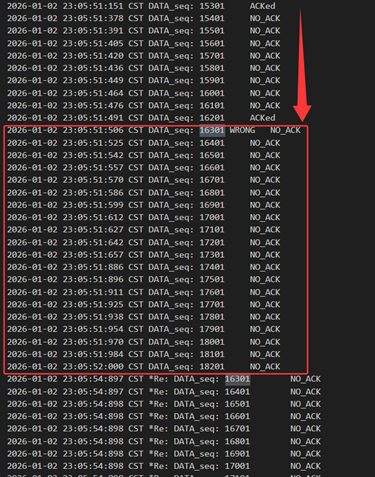
图 35 数据包出错、窗口滑动和整体重传
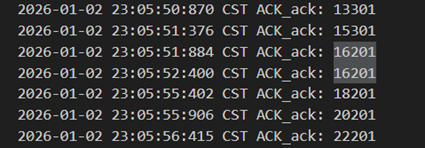
图 36 收到包后500ms的累计确认
当接收方发送的包出现了错误/延迟/丢包时,对于发送方都相当于是没有收到ack,并对重复的ack不做反应,所以是同样的处理逻辑。当接收方正确收到数据包并发送80801的ack时出现了错误,发送方只好等超时以后重发窗口内78901~80801所有的包,此时接收方收到重复的包以后重启500ms的累计确认,再次发送80801完成确认。
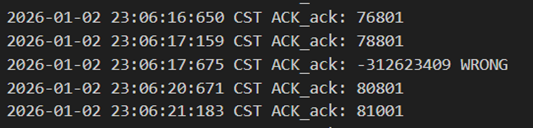
图 37 确认包出错、收到包后500ms的累计确认
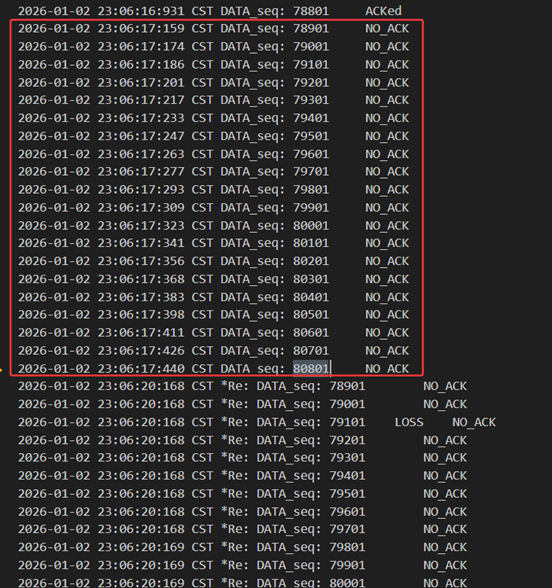
图 38 超时之后重传窗口内所有的包
由此可见已经实现了该TCP阶段所要实现的任务了。在发送端使用LinkedHashMap和WINDOW_SIZE实现了滑动窗口,用put和remove操作实现了滑动窗口的管理,超时后重发窗口内所有的包。在接收端通过对pendingAck和expectedAck的判断和处理、用recvBuffer实现了失序缓存,并通过计时器来实现收到包以后的500ms累积确认。
针对错误、丢失、延迟,都用了多种判断条件和超时重传来满足了可靠传输。
Tahoe
Tahoe是上述“缩略版”TCP的进阶版。主要是为了拥塞控制提出了新的要求:发送窗口的大小要按照慢开始、拥塞避免,超时重发时降到1后再次慢开始。计时器超时时只重传窗口左沿的数据包。(其实也是重传窗口内所有的包,但此时窗口大小cwnd=1)
此版本不需要更改接收方的代码,只需要对发送方进行改动。
要求看似简短,实则实现起来非常困难,尤其是重传导致窗口缩小后该如何处理原先发送窗口中缓存的包。
对于动态窗口,我仍然使用的是之前数据结构类型为LinkedHashMap的unacked,因为这个数据结构我不需要自己去手动调整他的大小,而是只要专注于cwnd和ssthresh两个变量的变化就行了,只需要在各种操作时检测其大小与我真实发送窗口的大小就可以完成很多控制。而且可以轻易地用迭代器的remove来清除已经正确接收的数据包,窗口也能实现自动移动,是个比较简易的“动态结构”。
通过书本所学,为了方便后续实现,我们先新定义以下一些变量:(cwnd设置为double是为了方便后续拥塞窗口的增长,retransFlag用来方便逻辑处理)
private volatile double cwnd = 1.0;// 拥塞窗口
private volatile int ssthresh = 8;
private volatile boolean retransFlag = false;// 超时重传标志并且依据实际以及规定,实际的拥塞窗口大小应为max(1,cwnd),为方便起见写了如下函数简化书写:
private int allowedWindow() {
return Math.max(1, (int) Math.floor(cwnd));
}由于引入了一个超时重传标志retransFlag,并且窗口大小不再是固定的了,所以在发包函数中用来阻塞发送线程的条件需要更改。若窗口满或者在超时状态,就阻塞发送线程并进行等待。
// 窗口满或者在超时状态,等待
while (unacked.size() >= allowedWindow() || retransFlag) {
try {
lock.wait();
} catch (InterruptedException ignored) {
}
}接下来是要新实现增窗口的慢开始、拥塞避免的函数。其参数ackedCount是在waitACK中记录下的本次移除了多少未确认分组的数量。
在正常情况下逻辑为上半段。依据课本上的逻辑,tcp协议在慢开始阶段是每确认一个包窗口就加一,从而出现的“乘法增加”现象。而在拥塞避免阶段则是收到当前窗口数量的包以后窗口才加一,分散到每一个包的时候就是一个分式,也就是说cwnd要增加 (ackedCount) / (1.0*cwnd),而处于慢开始和拥塞避免的交界处,则是同时考虑到两者,先让cwnd慢开始增长到ssthresh,再加上拥塞避免阶段的分式。这也是我们将cwnd设置为double类型的原因。
而在超时重传状态下情况会有所改变,代码为下半段。我们直接不关注ackedCount的数值,而是如果是慢开始则直接乘2,如果是拥塞避免就+1,交界情况就同时考虑两者。
之所以要分两个不同的逻辑原因如下:
假如现在没有超时,处在慢开始阶段,窗口为4,而我收到了前两个包的确认我就乘二,收到后两个包的确认我又乘二,那么实际上窗口应该变成8,但现在却变成了16,所以应该是确认了几个包窗口就加几。(符合书上所描述的慢开始增长)
假如现在处在超时状态,仍然是在慢开始,我发出去了64个包但是第一个包没有到达,接收方缓存了后63个包后回复0,此时超时重传了1,接收方收到以后累积确认发来64,此时ackedCount=64,但是窗口不应该变大到64而只应该变大到2才对。
这样子将两者的逻辑分开能够更好地处理正常情况和超时情况下窗口的增长。
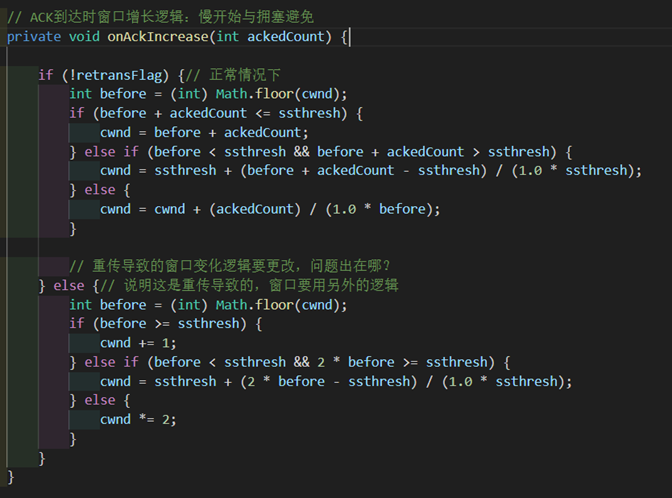
图 39 窗口增长逻辑
针对waitAck函数的改动很大。我们先对延迟包跳过的条件加强,防止对后续逻辑产生影响。(先前即使ackNum比窗口后延的未确认包序号小,也不会对后续逻辑产生影响,但这里有可能会有影响,所以需要加强)对于有位错的确认包依旧是直接抛弃不管。
if (unacked.isEmpty() || ackNum < unacked.keySet().iterator().next()) {
continue;}// 延迟包,继续看接下来则是和之前类似的确认包逻辑。这里需要用ackedCount记录下来确认了多少包,然后通过调用onAckIncrease(ackedCount)来实现窗口增长。随后也和之前一样正常的唤醒发送线程和重启计时器。
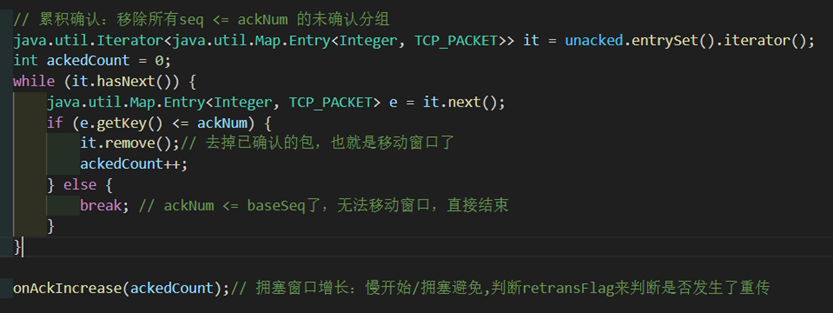
图 40 确认包逻辑和窗口增长
不同的点在于我们要加入对超时状态的处理。先来看超时任务retransTask的改变:调整窗口和门槛大小,令超时状态为1,随后只重发窗口后延的1个包。(这里不再是重传窗口内所有的包了,重传也要慢开始)除此以外和之前一样,依旧是每隔3秒执行一次的计时器。
ssthresh = Math.max((int) Math.floor(cwnd / 2), 1);
cwnd = 1;
retransFlag = true;// 超时重传改数值
java.util.Iterator<java.util.Map.Entry<Integer, TCP_PACKET>> it = unacked.entrySet().iterator();
if (it.hasNext()) {
java.util.Map.Entry<Integer, TCP_PACKET> e = it.next();
udt_send(e.getValue());// 发送cwnd(1)个包
}无论是否超时,waitAck上半段逻辑是一致的,而且我们在窗口增长函数中正确实现了不同阶段应有的增长逻辑,所以无需再考虑上半段。并且每次waitAck的末尾都会重设计时器,所以不用担心计时器的错误计时问题。
现在只需要具体关心在超时情况下还需要加入额外的逻辑。
如果此时unacked为空了,说明我已经重传完毕了,该启用发送线程发新包了。
如果不为空,则说明unacked里依旧有先前传过但未收到确认的,但我没办法用上层调用的发包逻辑去发送我已经发过的包,所以此时我只能在这里继续模拟发包逻辑,发送cwnd个包(若窗口内已经不足cwnd个,则发送窗口内所有包)。而且这里实际上实现了慢开始:第1个包由超时计时器完成,随后调整窗口由固定函数完成,这里发送窗口大小个包。
如果没有发送完窗口内的包,此时依旧要保持重传状态等待ack到来以后再一步处理。
如果发送完了(利用标志位flush),则取消超时状态。
一旦不是超时状态,就立即唤醒发送线程。这样子就不会出现窗口很大,但是发包只发了几个之前发过的包而没有新发的包的现象了。否则继续阻塞发送线程阻止发送新包。
如果Ack正确到来则按正常逻辑处理,否则继续等待超时计时器重发即可。
取消超时状态以后,将不会再进入到这个超时发包逻辑里面继续发包。
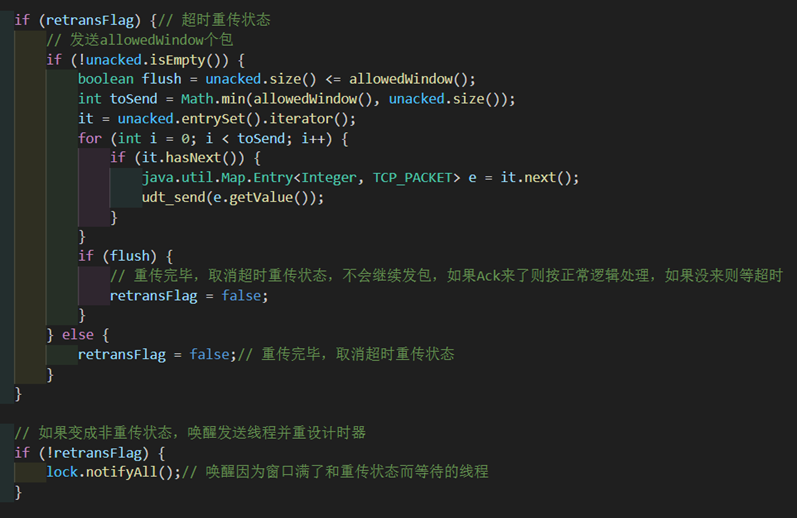
图 41 确认包逻辑和窗口增长
至此一整个慢开始、拥塞避免、超时重传的机制都被实现了。现在结合log文件进行分析。
正常情况下发包窗口会以慢开始、拥塞避免地方式增长。
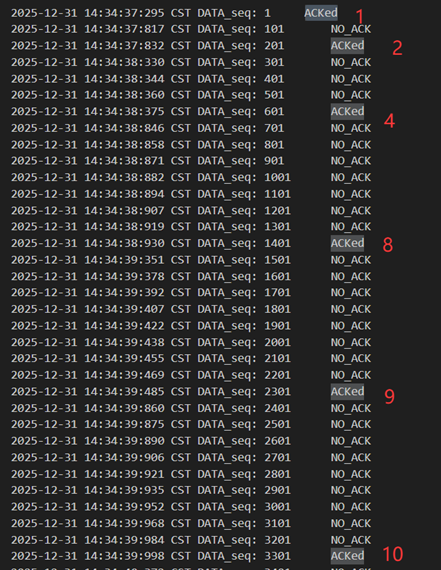
图 42 慢开始与拥塞避免
当发送方发送的包出现了错误/延迟/丢包时,对于接收方都相当于是有一个包没有收到,所以是同样的处理逻辑。这里此时cwnd=15,发包时中途的8801丢失了,发送方返回8701,导致窗口移动继续发包到了10201(但此时窗口还是15)。然后8801触发超时重传,cwnd=1,ssthresh=7,之后接收方返回10201代表确认,之后发送方再次以cwnd=2,4,7,8,9…地形式正确增长并发包。
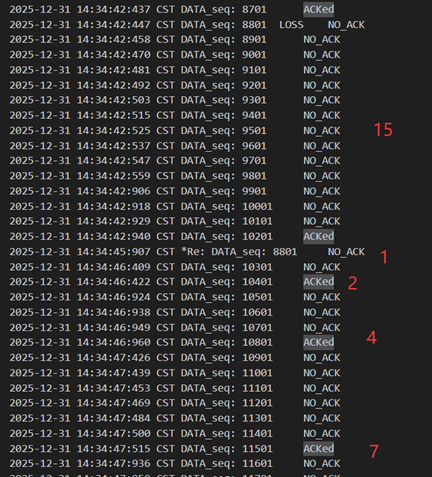
图 43 超时重传-慢开始与拥塞避免
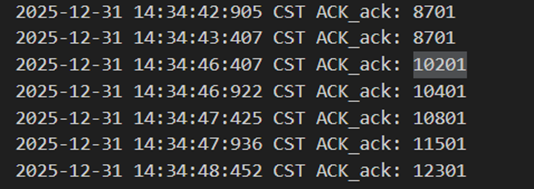
图 44 累计确认
当接收方发送的包出现了错误/延迟/丢包时,对于发送方都相当于是没有收到ack,并对重复的ack不做反应,所以是同样的处理逻辑。此处接收方发送70701延迟了,此时窗口是12,发送方等待超时以后重发69601,cwnd=1,ssthresh=6,接收方返回70701确认包,之后发送方再次以cwnd=2,4,6,7,8…地形式正确增长并发包。
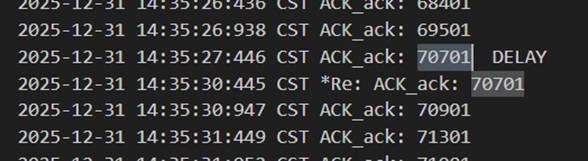
图 45 累积确认和丢失确认包
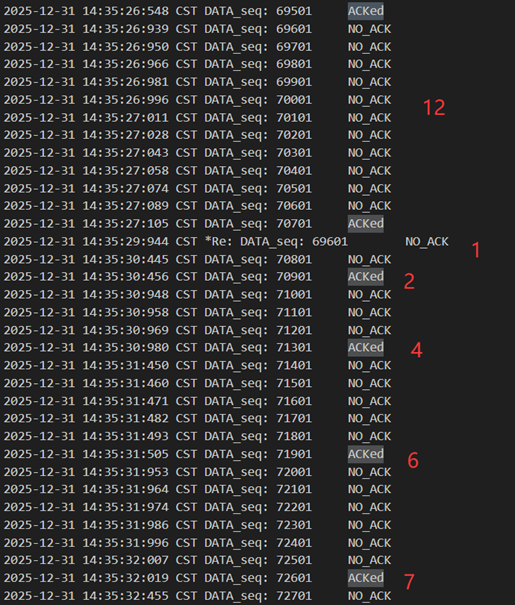
图 46 超时重传-慢开始与拥塞避免
由此可见已经实现了Tahoe阶段所要实现的任务了。在发送端使用LinkedHashMap和cwnd与ssthresh的控制实现了动态增长的滑动窗口,对窗口的增长有着正确的控制逻辑,超时后只重发了窗口后延的第一个包。主要的重难点在于该怎么修改waitAck函数和窗口增长onAckIncrease函数,使得超时状态下窗口按照所要的逻辑增长,并且能够实现正确的重传而没有差错。
针对错误、丢失、延迟,也都用了多种判断条件和超时重传来满足了窗口的动态调整和可靠传输。
Reno
Reno是该TCP实验的最终要求版本。要求在Tahoe的基础上实现快重传、快恢复。这些相对比较容易实现。
按照课本,首先需要对接收方做略微的改动。对于错误包依旧是直接抛弃不管。对于正确包,在之前我们是不管什么包到来都是用延迟500ms的累积确认的,而现在只有在得到期望序号的包才会进行延迟500ms,否则如果收到乱序的包都要立即回复ack字段为当前按序收到的最大包号pendingAck的确认包。
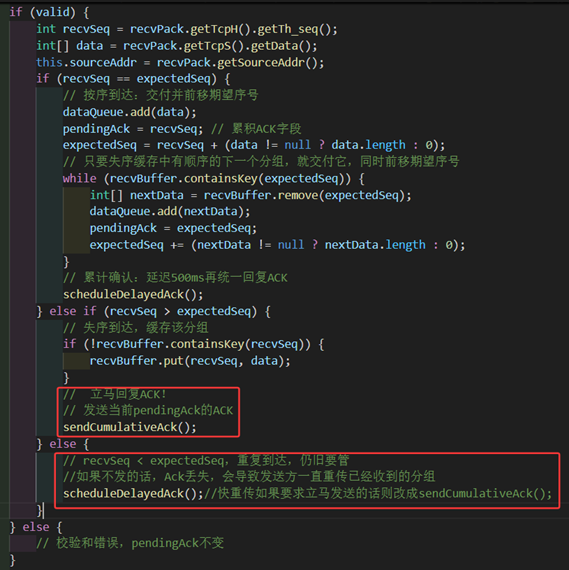
图 47 对乱序包进行立即确认
为了给重复包计数,新定义了变量,分别用来记录上一次的ack和重复的ack数:
private volatile int dupCount = 0;// 重复ack计数
private volatile int lastack = 0;// 上次收到的最大ack序号随后更改waitAck里关于收到的ack比窗口后延第一个包的seq还小的逻辑。其中lastAck是在每次waitAck得到的ack报文能有效移动滑动窗口之后才进行更新的,数值上永远是最后一个被确认的包的序号。
当收到的ack比窗口后延第一个包的seq还小,要判断是否是重复ack,如果是则用dupCount计数。(如果ack是比第一个包的seq大,则dupCount要清零)
当dupCount收到三次时,需要进行快重传和快恢复的算法。调整门槛和cwnd的数值,重置dupCount,并重传未确认的第一个分组。
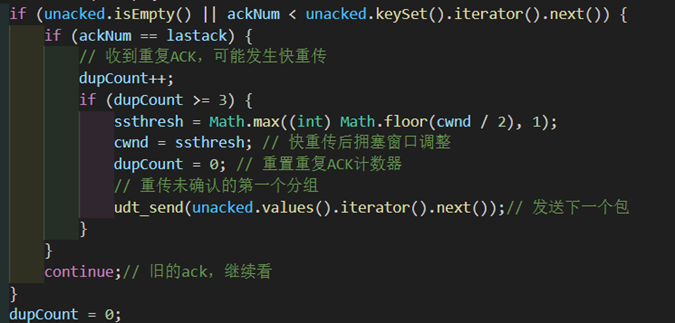
图 48 快重传、快恢复的实现
现在结合log文件进行分析。
正常情况下发包窗口会以慢开始、拥塞避免地方式增长,不再重复展示。
当接收方发送的包出现了错误/延迟/丢包时,对于发送方都相当于是没有收到ack,并对重复的ack不做反应,所以是和Tahoe同样的利用超时重传的处理逻辑,而且因为引入快重传以后该现象很少见,在此不再重复展示。
此处重点关注快重传和快恢复的实现。
当发送方发送的包出现了错误时,接收方直接丢弃。而面对延迟(先是相当于丢包,后相当于重复)、丢包情况发送方会立刻回复ack。乱序情况除了会乱序缓存也会立刻回复ack。
比如此时cwnd=19,发包时发现16501错掉了,接收方在收到后面四个乱序包的时候会连发四次确认。发送方认为第一个确认是普通的确认接受下来并移动窗口,收到后面三个确认时会触发快重传,重传窗口后延的包,并快恢复让cwnd= ssthresh=9,之后cwnd=10,11…,符合正确的窗口变化和增长逻辑。
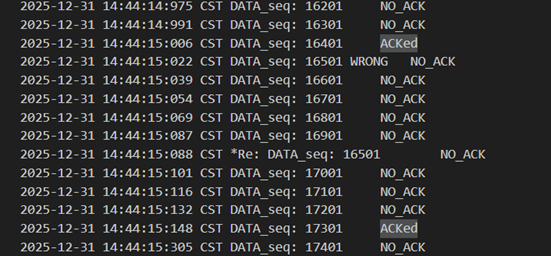
图 49 快重传、快恢复
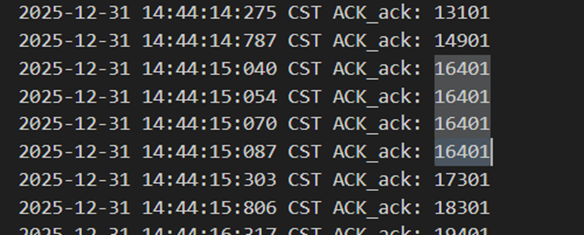
图 50 收到乱序包以后立刻重传
遇到的困难
本次实验所有项目全部完成。
主要遇到的困难就是tahoe那里,思维定式错误地认为重传任务一定要写在超时任务里面完成。苦思冥想三天也想不出来该怎么用慢开始的方式重传包,尤其是本身unacked里面就有东西了,也无法通过rdt_send来重传已经发过的包,超时任务发一次之后还不能方便再用第二次,甚至一度怀疑实验框架有问题,以为应该让我在高层通过回溯的方式用rdt_send来重传,还为此打扰了好几遍助教。
后来想通了,我可以不局限在超时任务里面完成,只要在waitAck里面也写上重传的一部分逻辑就行了。
迭代开发的优点或问题
迭代开发的优点就在于我能够每次都基于前一个阶段的正确的代码,独立地重新开始我另一段逻辑。能够不断改进自身的代码,还方便切换分支来回对比。而且对于复杂项目比如这个tcp任务,如果直接写reno的话可能会一头雾水,但是一步步精进的话就会逐渐有思路并写下去。
缺点就是开发过程有些地方会缓慢拖沓。比如为了加快开发速度我是直接跳过了GBN和SR的实现,其实可以的话我想直接从rdt1.0跳到rdt3.0,但奈何评分机制不得不中间多个过程进行额外书写。
总结已经解决的主要问题和采取的相应解决方法
问题1:想不出来该怎么用慢开始的方式重传包。
解决1:不要局限在超时重传任务,再在waitAck里面也写上重传的后续部分逻辑。
问题2:完成后半部分实验时有时发现recvdata会是空的或者少数据。
解决2:在接收方把交付数据的判断条件改成dataQueue.size() >= 0。(之前的判断条件都是dataQueue.size() ==20,对于一次发一个包的是正确的,但对于后面一次性发多个包还有失序缓存的情况下就不对了)
问题3:错误地认为快重传的时候是和超时重传一样重传改变后的cwnd个包。
解决3:把问题想复杂了,直接改成发送一个包就行了。
对于实验系统的问题或建议
- 实验报告要求每个地方都得说明位错是如何处理的,还有各种细枝末节的琐事,但实际上我们这本身就是个迭代开发的项目,我认为前面做了而后面没有改动的地方应该不要再次说明才对。
- 实验框架拿到手以后没有任何指点和说明,初期无法了解该如何调用以及各种接口的含义。既然要求我们写解决复杂工程问题的整个过程的所有关键点的实现和评估,那为何实验框架本身却没有给我们相应的书面技术交流文档呢?即使有着导入的包的源码,但没有说明还是很难理解的。
- 实验报告要求不应该太过繁琐,该写的我其实都已经在“实验内容”部分写过了,不应该让我在实验内容里也写,在别的章节也写。除此之外还有多种冗余的部分,实验报告应该只是做完了以后轻松写出来证明学生顺利完成了的才对,而不是繁琐地需要写好几天好几遍的超大型文档,否则会出现七天写代码十天写报告的情况,复习也复习不了,为了实验报告一直在写,学生的期末压力也苦不堪言,这不是捡了芝麻丢了西瓜吗?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)