Agent & RAG 测试工程05:把 RAG 的检索过程跑清楚:chunk 是什么、怎么来的、怎么被命中的
本文记录了在 RAG 系统中对检索阶段的一次实际验证过程。通过查看 PDF 切分结果与检索输出,梳理了 chunk 的生成方式、chunk_id 与 page 的含义,以及固定问题下检索结果为何命中这些内容。重点在于确认检索行为是否可观察、可解释,为后续的引用与边界控制打基础。
前言:
在 RAG 跑通之后,感觉这三个问题要先搞清楚:
-
文档切出来的这些 chunk,到底代表什么?
-
chunk_id为什么看起来和语义顺序对不上? -
检索命中某个 chunk 时,能不能解释清楚“为什么是它”?
如果这些问题说不清楚,那么所谓的“证据”“引用”,本质上还是黑盒。
这一篇,做这件事:
把 PDF → chunks → retrieval 这条链路,用真实输出跑清楚。
一、Step 1:PDF → chunks
启动项目后,先只看切分结果,不看检索、不看答案。
当前这份 PDF 的切分结果是:
-
第 1 页切出 7 个 chunks
-
第 2 页切出 7 个 chunks
-
总共 14 个 chunks
每个 chunk 都带一个 chunk_id,形如:
p1-c0
p1-c1
p1-c2
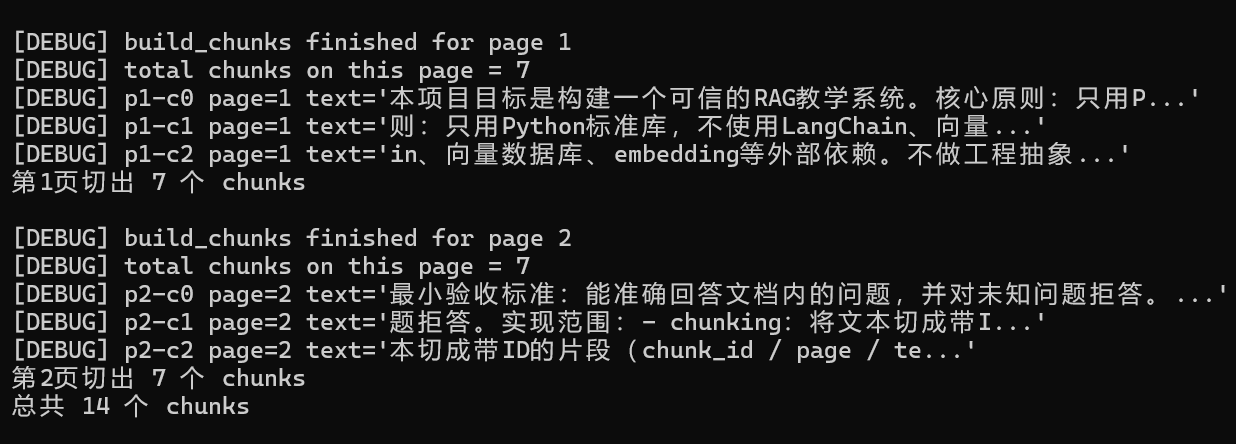
在日志里能直接看到 chunk 的前一小段文本,长度是可以直接阅读理解的,不是关键词碎片,也不是整页全文。
到这里,可以确认一件事:
切分结果本身是“可用”的。
接下来是解决自己的三个疑问:
二、疑问 1:chunk_id 是怎么来的?为什么不像“语义顺序”
一开始很容易产生一个误解:chunk_id 好像应该对应“段落顺序”或“语义顺序”。
但跑完一遍之后,会发现:
p1-c0
p1-c1
p1-c2
...
并不保证内容是“从重要到次要”,甚至不保证是“完整语义段落”。
这里需要明确一个工程层面的原则:chunk_id 只保证“切分顺序”,不保证“语义顺序”。
在当前实现里:
-
文本是按固定窗口大小切分的(例如 200 个字符)
-
每切出一段,就分配一个递增的 index
-
chunk_id = p{page}-c{index}
它表达的是:在 page=1 这一页上,第 0 / 1 / 2 次切分得到的片段
而不表达:
-
章节结构
-
段落语义完整性
-
内容的重要程度
原则(后面非常有用):
chunk_id 是“切分坐标”,不是“内容目录”。
工程里这么设计的目的很现实:
坐标必须稳定,否则回归、定位和复现都会出问题。
三、疑问 2:一个 chunk 到底有多长,overlap 在干嘛
从结果看,一个 chunk 的长度大概在 200 个字符左右。
严谨的说法是:
-
最大长度 ≈ 200
-
实际长度可能略小
-
比如最后一个 chunk
-
或受换行、空白符影响
-
chunk 之间保留了一定长度的 overlap,本质上是一个滑窗切分模型。
可以用一个非常直观的方式理解它的作用:
p1-c1 的前一小段文本,来自 p1-c0 的结尾部分。
这样做的目的只有一个:
降低一句话刚好被切断、关键信息落在边界上的概率。
在有些复杂的文本场景中,需要进一步讨论 overlap 百分比、窗口步长等参数,但在当前这个文档规模下,这一层先不展开。
这里关注的不是“参数调优”,而是:
切分出来的结果,是否有利于后续检索被解释清楚。
chunking.py
def build_chunks(text, page_num, max_len=200, overlap=40):
"""
把一页文本切成 chunks,每个 chunk 有唯一 ID
在 RAG 里的作用:
- 把大文档拆成可检索的小单元
- 每个 chunk 有唯一 ID,方便追溯答案来源
参数:
text: 一页的文本内容
page_num: 页码(用于生成 chunk_id)
max_len: 每个 chunk 最多多少个字符(支持中文)
overlap: 相邻 chunk 之间重复的字符数(避免语义截断)
返回:
[{"id": "p1-c0", "page": 1, "text": "..."}, ...]
"""四、疑问 3:page 是怎么和 chunk 绑在一起的
这个点如果只从结果看,很容易说成:
“切完之后,这些 chunk 属于哪一页。”
但从工程实现角度,更准确的描述是:
page 是 chunk 的“出生地”,chunk 不跨页。
也就是说:
-
page 在切分之前就已经确定
-
每一页的文本单独进行 chunking
-
chunk 在创建时就被打上 page 标签
后续所有事情:
-
检索结果展示
-
引用回溯
-
人工定位原文
都依赖这个 page 字段。
可以说:
page 是人类定位信息,chunk_id 是系统定位信息,两者缺一不可。
五、用一条固定问题来盯检索行为
把切分这层跑清楚之后,才开始看检索。
为了避免引入干扰,只用一条固定问题:
这个项目的最小验收标准是什么?
这条问题对应的检索输出是:
[RETRIEVAL]
p2-c0 score=5
p1-c0 score=1
p1-c1 score=1
这里有几个直观的现象:
-
Top1 的 score 明显高于其他 chunk
-
Top1 对应的 chunk 内容里,能直接看到“最小验收标准”的原文描述
-
其他 chunk 虽然被命中,但分数明显偏低
这一步不需要理解具体的打分算法,只确认:
问题 → 命中的 chunk → 原文内容,是能一一对上的。
六、到这里,确认了什么
通过把“切分 + 检索”这两步拆开观察,确认了三件事:
-
文档切分后的 chunk 是可读、可定位的
-
检索命中的结果不是随机的,而是有明显排序差异
-
为什么命中某个 chunk,是可以被解释清楚的
至少在“找到合适证据”这一层,RAG 的行为已经不是黑盒。
当然,这一步也暴露出另一个问题:
命中相关内容,并不等于就一定能正确回答问题。
但这已经属于下一层了,这里先不展开。下一篇继续梳理这块内容。
小结:
把 RAG 的检索过程跑清楚,看清楚它到底在用哪段文档。
当检索这一层是可观察、可解释的,后面的引用、边界判断和风险控制,才有讨论的基础。
代码说明
本篇涉及的完整可运行代码已放在 GitHub 仓库中,对应本文阶段的代码已打 tag 标记,便于复现与回溯。tag:rag-note-05
GitHub:https://github.com/test202005/mini-rag-core
本文主要关注检索阶段的行为验证,核心逻辑集中在以下文件:
main.py:程序入口,交互式 RAG Demo
chunking.py:文本切分与 chunk_id 生成
retrieval.py:基于 chunk 的检索逻辑

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)