AI-大语言模型LLM-模型微调1-基础理论
微调让知识内化到模型中,RAG让知识独立于模型存在知识库中微调后的模型,可以让用户使用更少的提示词,RAG需要更多提示词(系统提示词或用户提示词)微调后的模型,使用时步骤更少,性能更高模型微调和RAG往往结合使用。
·
目的
为避免一学就会、一用就废,这里做下笔记
微调和部署
术语
| 概念 | 说明 |
|---|---|
| PEFT | Parameter-Efficient Fine-Tuning,参数高效微调。它是大语言模型微调的一种方法,只训练模型中的一小部分参数(通常少于1%),就能达到接近全参数微调的效果 |
| SFT | Supervised Fine-Tuning,监督微调,属于监督学习。用于为通用模型注入专业知识 |
| RLHF | Reinforcement Learning from Human Feedback,基于人类反馈的强化学习。它是一种让大语言模型(LLM)的输出与人类价值观和偏好对齐(preference alignment)的具体技术框架 |
微调须知123
1、微调在大模型优化中的位置
如图所示,大模型优化方式分四种,从复杂度和计算量上讲,微调难度比从零训练低,比做RAG高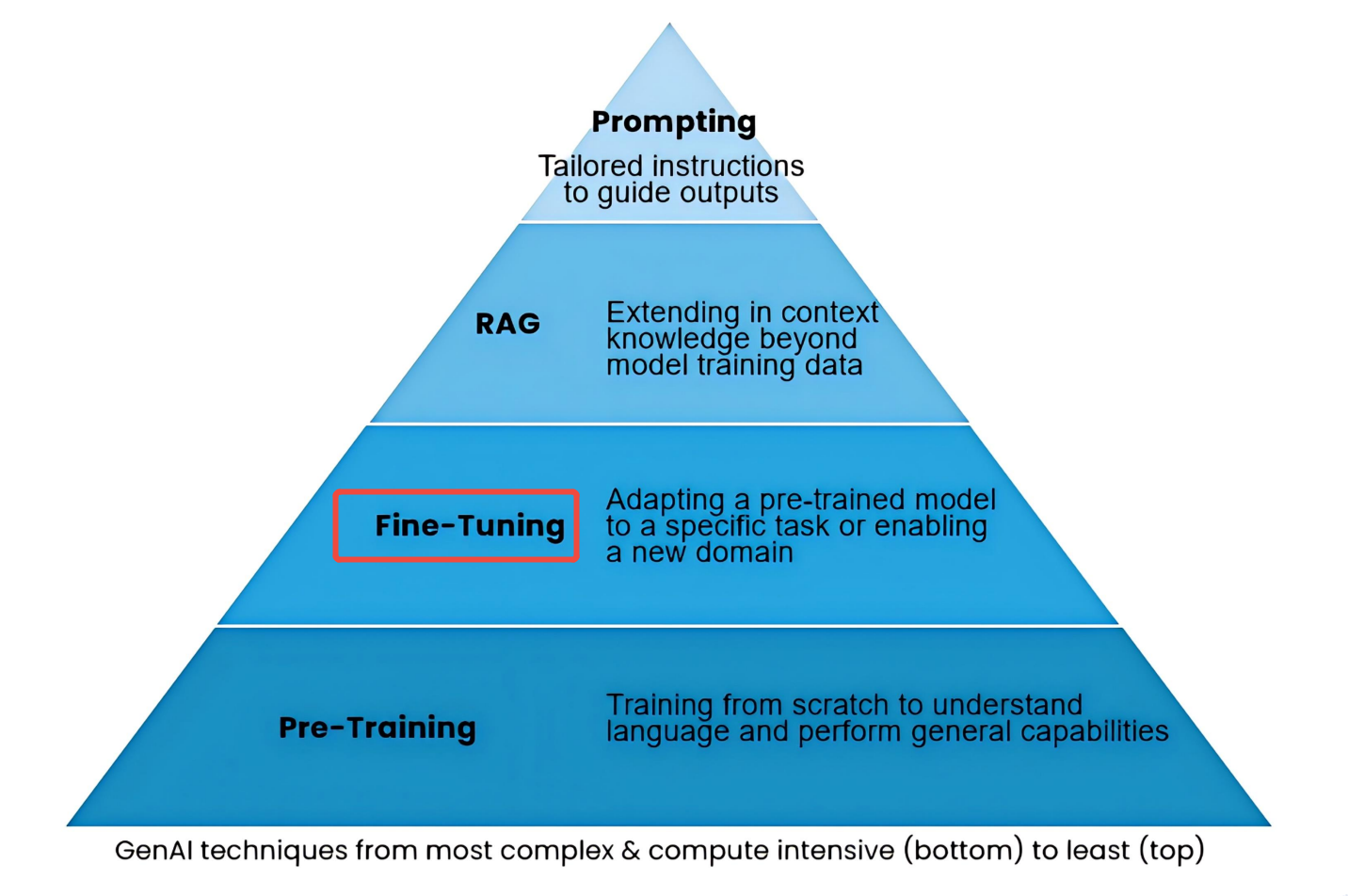
2、微调的性价比
如图所示,越难的东西越值钱/费钱,这很符合直觉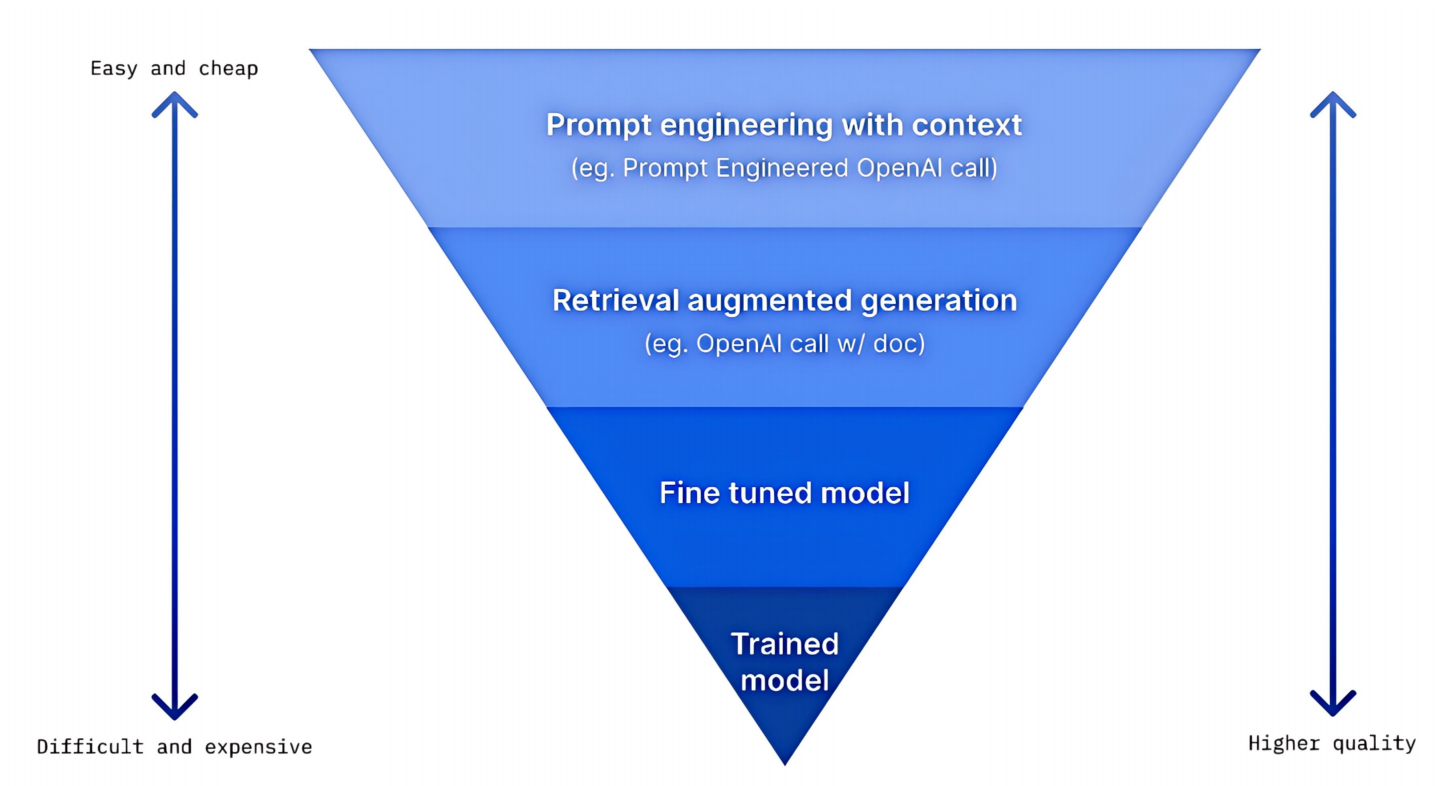
3、什么情况下需要微调
- 经费充足(基础入门级效果:50万 - 200万元;产品商用级:300万 - 1000万元;行业标杆级:1000万 - 2000万)
- 已确认提示词工程和RAG无法达到目标效果
- 行业知识和通用知识内涵或格式差异较大,如医学领域
- 能找到足够高质量、结构化的微调数据
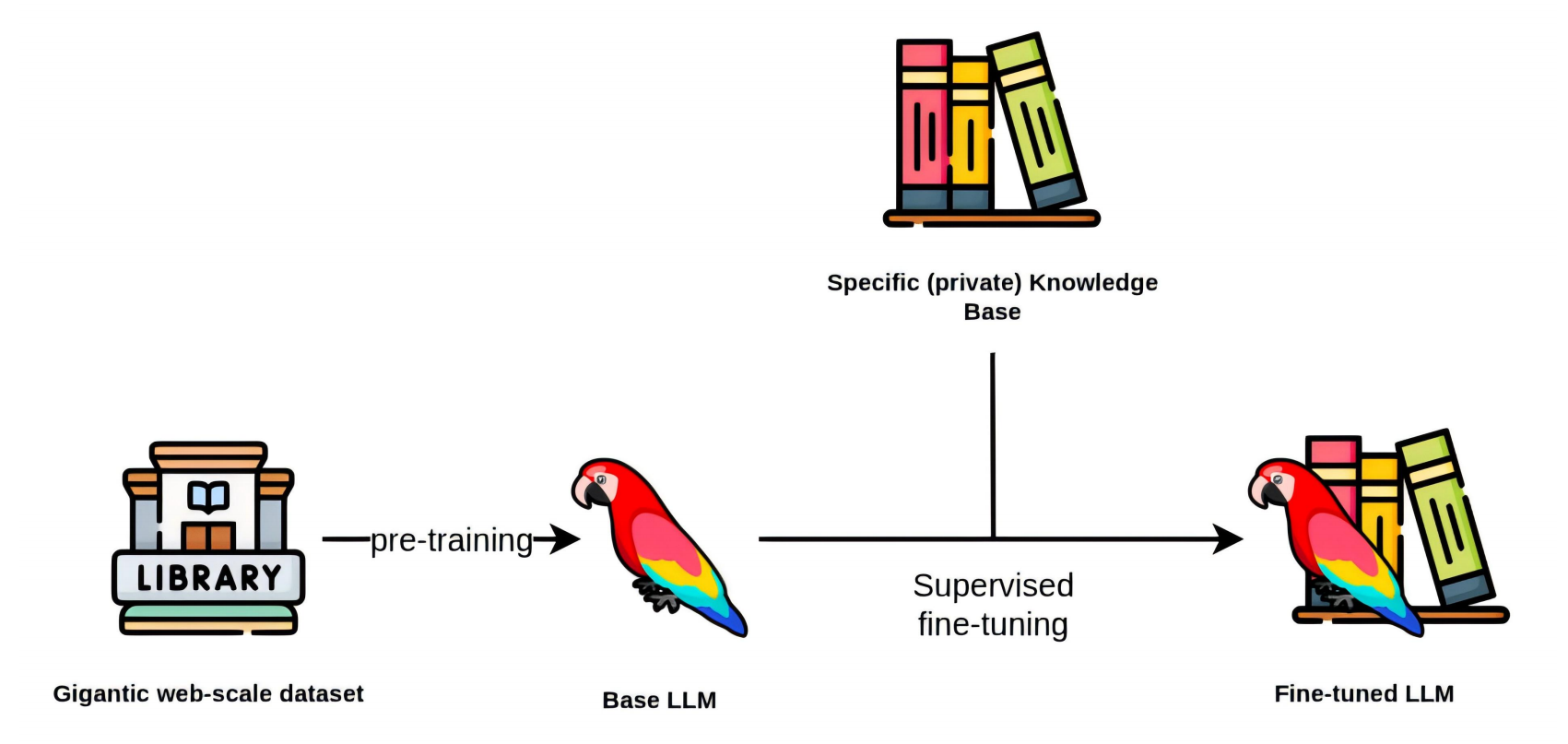
传统大模型训练流程
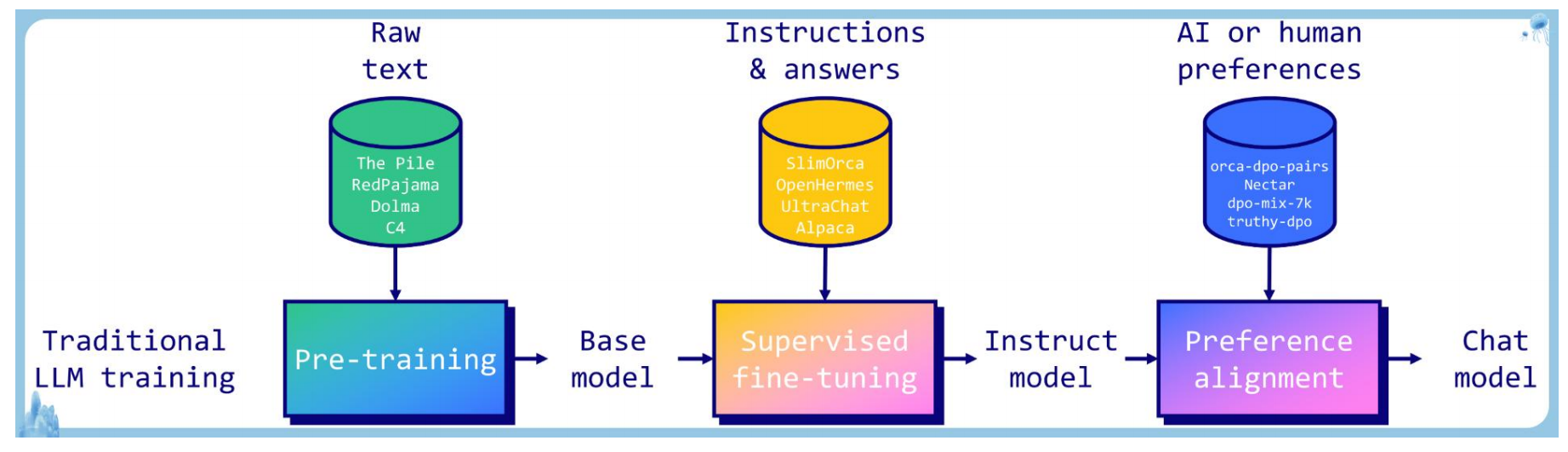
- 先使用海量数据对模型做预训练(Pre-Training),生成基础模型(Base Model)
- 再使用标注数据,对基础模型进行监督微调(SFT),生成指令微调模型(Instruct Model)
- 结合人类偏好,对微调指令进行偏好对齐(Preference Alignment),确保模型的输出符合人类偏好(政治正确、三观正确、符合法律、温和礼貌等),最终作为对外的聊天模型
偏好对齐非必须流程,指令微调模型像野马,强大但不可控,偏好对齐像驯马,使之温顺
微调 VSVSVS RAG
RAG流程示意
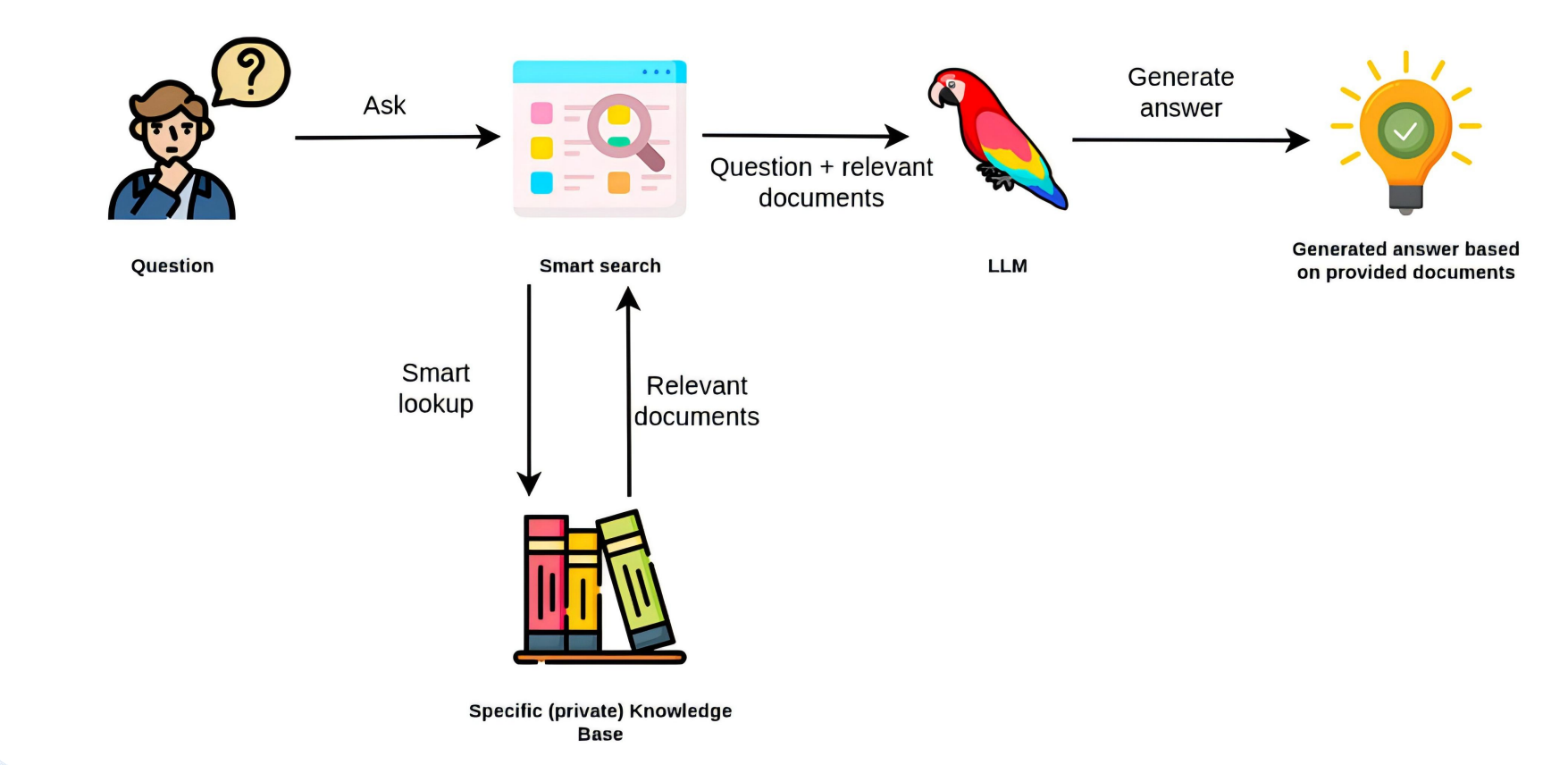
微调训练过程示意
总结
- 微调让知识内化到模型中,RAG让知识独立于模型存在知识库中
- 微调后的模型,可以让用户使用更少的提示词,RAG需要更多提示词(系统提示词或用户提示词)
- 微调后的模型,使用时步骤更少,性能更高
- 模型微调和RAG往往结合使用
指令数据集构造方式
微调的核心是SFT,SFT的必要条件就是指令数据集,即有标签的样例数据,因此如何构造指令数据集成为重要步骤。
直接上结论:方法1:人工构造 方法2:用LLM构造。如下图: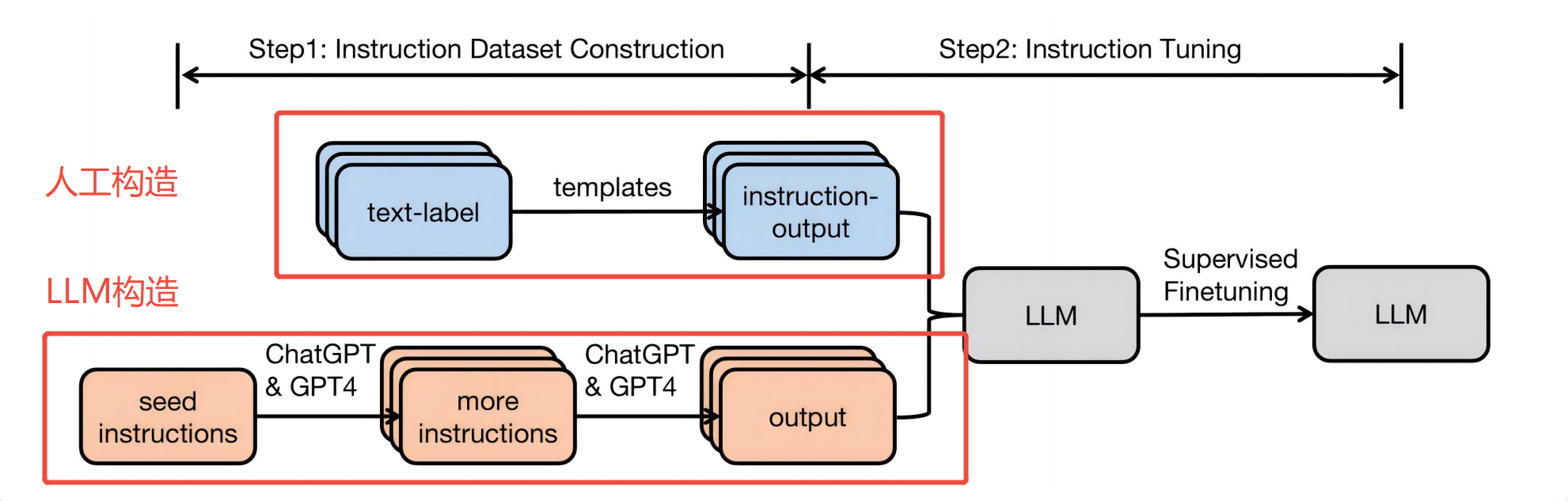
用LLM构造的可行性,业界已实践验证,下图为Alpaca 7B模型的微调流程: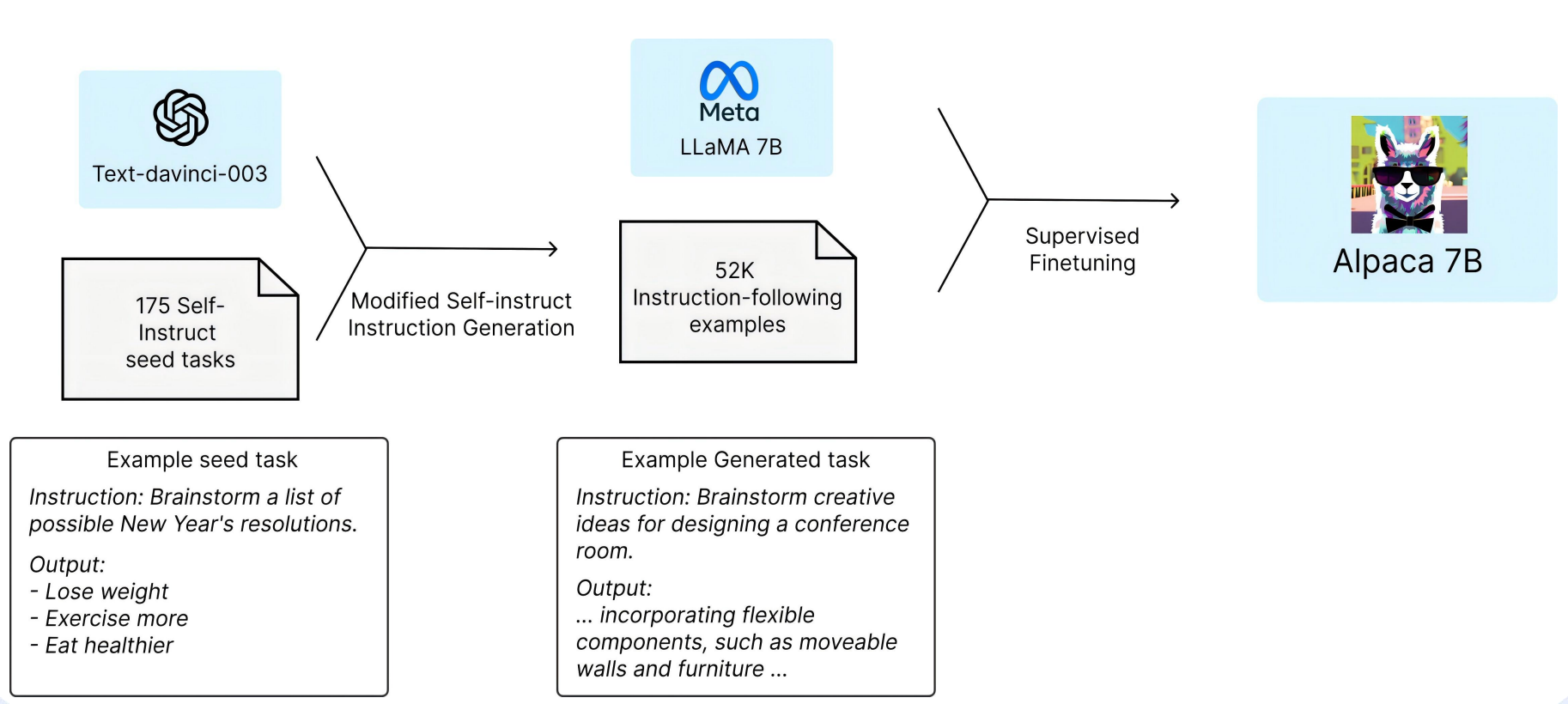
PEFT和传统LLM微调的不同
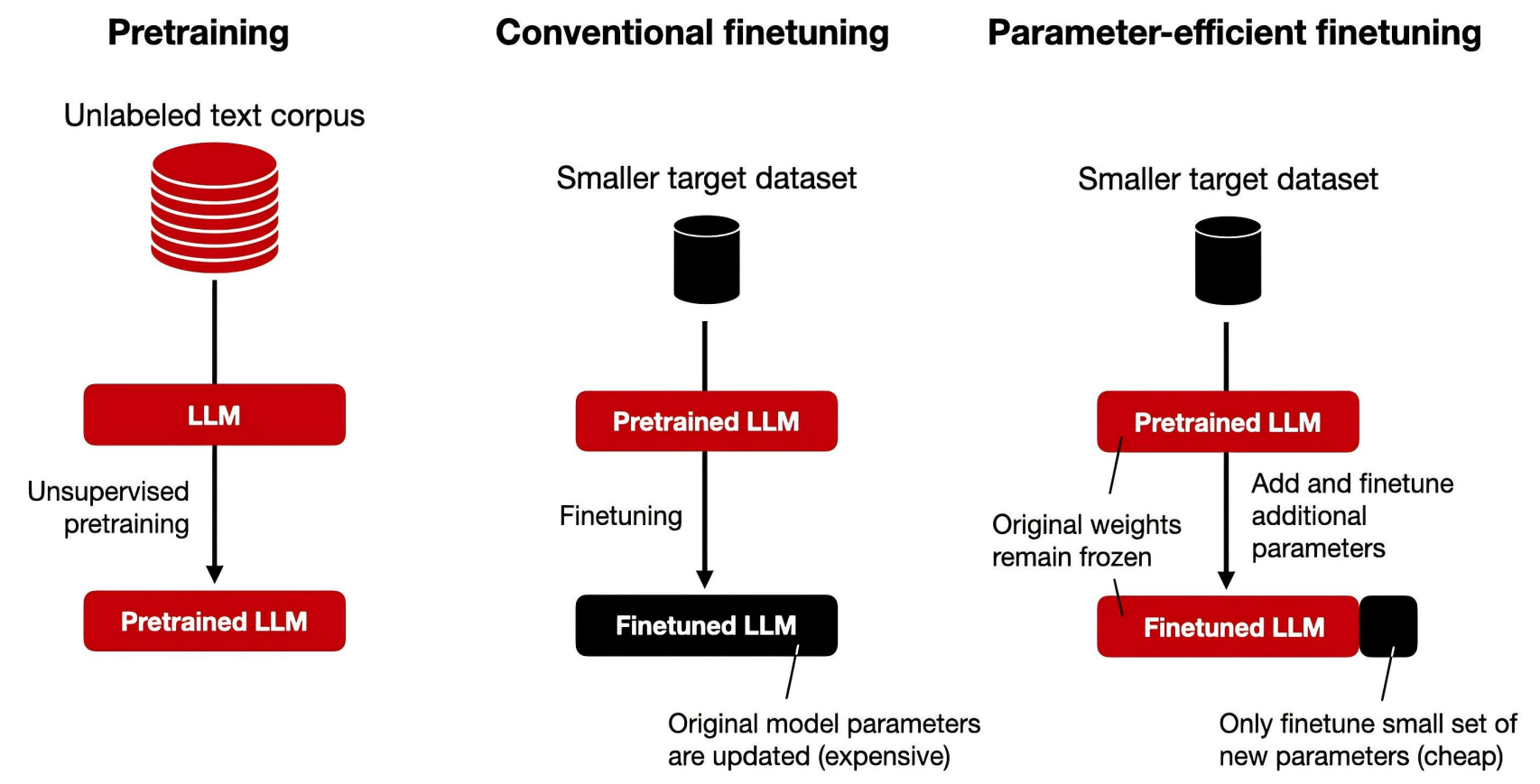
- 传统大模型微调,需要调整原模型的海量参数,耗费巨大
- PEFT不改变基础模型参数,而是在原模型的基础上增加额外的少量参数并微调(或者仅改变原模型少量参数,约1%-10%),耗费小很多
- PEFT几乎可以避免把原模型训练更差的灾难性遗忘问题
一句话总结:PEFT是传统微调的“轻量化改造”,它像给大模型“加插件”,而非重装整个系统,在保证效果接近的同时实现了高效、低成本和多任务管理。
PEFT的各种实现方法
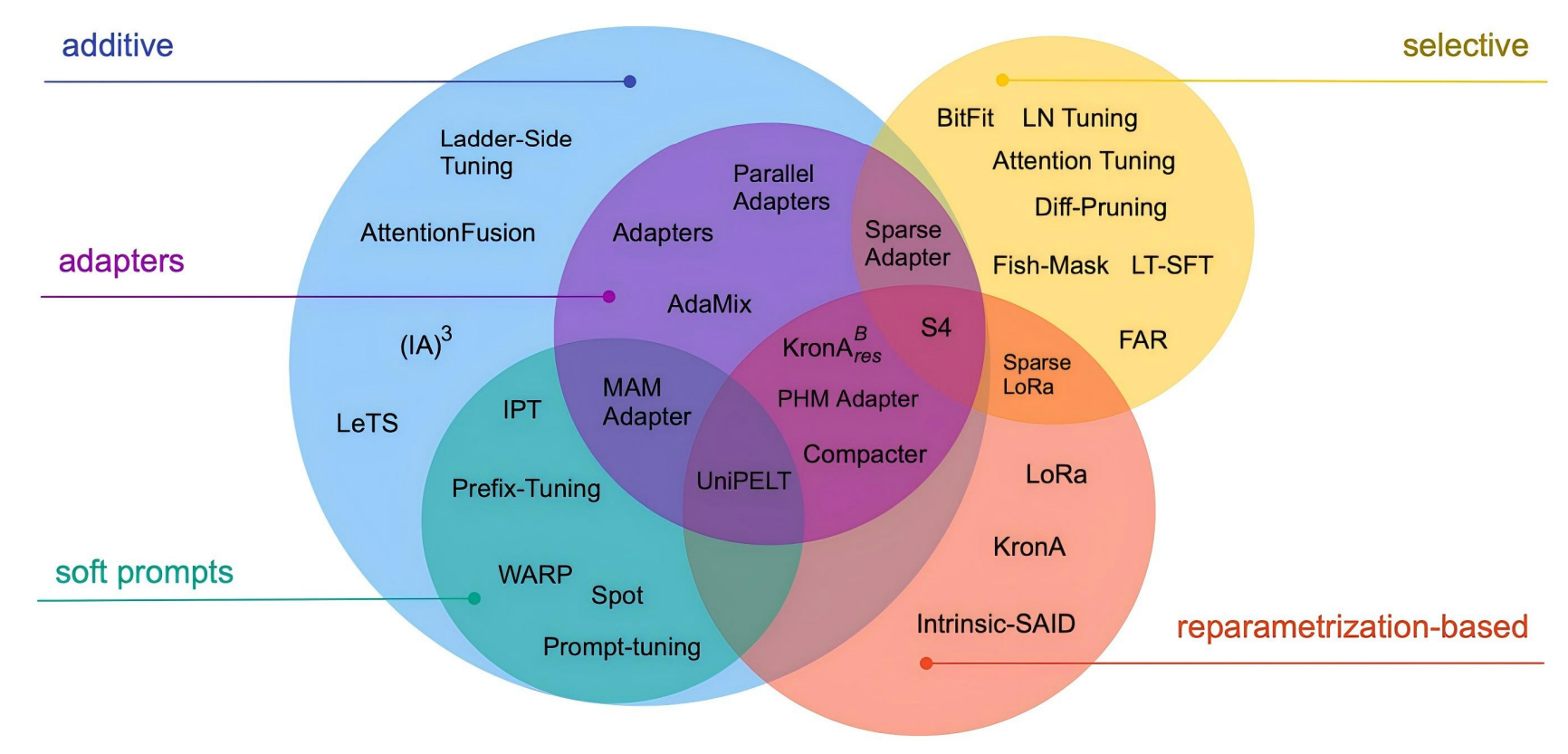
1. Selective(选择性微调)
- 含义:只选择性地微调原始模型中的一部分参数,而冻结其余大部分参数。
- 核心思想:不是所有参数对下游任务都同等重要。通过识别并只更新最关键的部分(如注意力层的偏置项、特定层的权重),实现高效微调。
- 图中例子:
Diff-Pruning,Fish-Mask,BitFit(仅微调偏置项)。 - 类比:给一台复杂机器做保养时,只调整几个最重要的旋钮,而不是拆开整个机器重装。
2. Additive(附加式微调)
- 含义:在原始模型结构之外,额外添加新的、可训练的参数模块,同时冻结原始模型的所有参数。
- 核心思想:通过引入少量外部参数来学习任务特定知识,完全不改变原始模型,避免灾难性遗忘。
- 这是图中最大的一类,包含了
Adapters和Soft Prompts两个重要子类。 - 类比:给智能手机外接一个便携镜头或键盘来增强特定功能,而不改动手机内部芯片。
3. Adapters(适配器)
- 含义:
Additive方法的一个主要子类。指在Transformer层的内部(通常是前馈网络FFN之后或注意力模块之后)插入小型、参数化的瓶颈层模块。 - 典型结构:降维 → 非线性激活 → 升维。
- 特点:模块化程度高,但会在前向传播中引入少量额外计算,可能略微增加推理延迟。
- 图中位置:在
Additive分支下,如Parallel Adapters、MAM Adapter、Compacter等。 - 类比:在工厂的主流水线上插入一个微型工作站,对产品进行特定加工,流水线主体不变。
4. Soft Prompts(软提示 / 连续提示)
- 含义:
Additive方法的另一个主要子类。指在模型的输入层(词嵌入空间)添加一组可训练的连续向量作为提示。 - 核心思想:通过优化这些向量来“引导”或“激活”模型内部知识,使其适配下游任务,不修改模型内部任何结构。
- 特点:参数效率极高,推理时几乎无额外开销。
- 图中位置:在
Additive分支下,如Prefix-Tuning、Prompt-Tuning。 - 类比:给一个经验丰富的向导一张精心设计的地图或指令卡,他就能带你找到特定地点,而不需要改变向导本身的知识。
5. Reparameterization-based(基于重参数化的微调)
- 含义:通过对原始模型的权重矩阵进行低秩分解、乘积或其他数学变换来间接引入新的可训练参数,而不是直接添加新模块。
- 核心思想:用一种数学上等价但参数更少的表示形式来模拟全参数微调的效果。
- 代表方法:LoRA 是其最著名的代表。
- LoRA将权重更新
ΔW分解为两个低秩矩阵的乘积(ΔW = BA),只训练小矩阵A和B。
- LoRA将权重更新
- 特点:训练后,新增参数可以合并回原始权重,实现零推理延迟。
- 图中位置:最右侧的独立分支,包含
LoRA及其变体(如Sparse LoRA)。 - 类比:不是给车子加挂车,而是用一套微型齿轮组调整发动机的输出特性,调完后齿轮组可以拆掉,不影响车子原有结构。
引用说明
图片截取自“马士兵教育”课件

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)