AI新风口!多代理混合RAG系统架构大揭秘,零基础也能轻松搭建,附完整源码!
本文介绍了一个基于LangGraph的多代理混合RAG系统,采用"分工协作+多源融合"架构,包含Supervisor调度中枢和5个专业子代理,整合MySQL、Neo4j和Milvus三大数据库,实现结构化数据查询、图知识检索和向量语义检索的统一处理。文章详细解析了系统架构、组件分工、工作流程,并提供Docker部署方案和测试验证,为复杂场景下的智能应用提供可落地的架构方案。
前言
在大模型驱动的智能应用开发中,单一知识库或单代理架构常面临“结构化数据处理弱”“非结构化知识检索不精准”“复杂任务分工模糊”等痛点。而混合RAG(检索增强生成)+多代理架构,通过“结构化数据库+图知识库+向量知识库”的多源存储,搭配分工明确的代理节点与智能调度中枢,能高效应对复杂场景下的问答、数据分析、知识检索等需求。
本文作为系列博客的开篇,将带大家全面拆解一套基于LangGraph的多代理混合RAG系统,从架构设计、核心组件、工作流程到环境部署,手把手带你搭建系统基础框架,为后续深入各个模块做好铺垫。
1 系统核心架构总览
1.1 架构设计理念
本系统的核心设计思路是“分工协作+多源融合”:
- 多代理分工:将复杂任务拆解为“自然语言交互、代码执行、数据查询、图知识检索、向量语义检索”五大场景,每个场景由专属代理负责,提升专业度;
- 混合RAG支撑:整合“MySQL结构化数据库+Neo4j图知识库+Milvus向量知识库”,覆盖结构化数据、关系型知识、非结构化文本的全场景检索需求;
- 智能调度中枢:通过Supervisor(主管代理)实现任务路由与代理协作,避免重复工作,形成闭环流程。
1.2 系统架构全景图
通过项目中的draw_graph.py生成系统架构图(含代理内部逻辑展开),直观呈现各组件的关联关系:
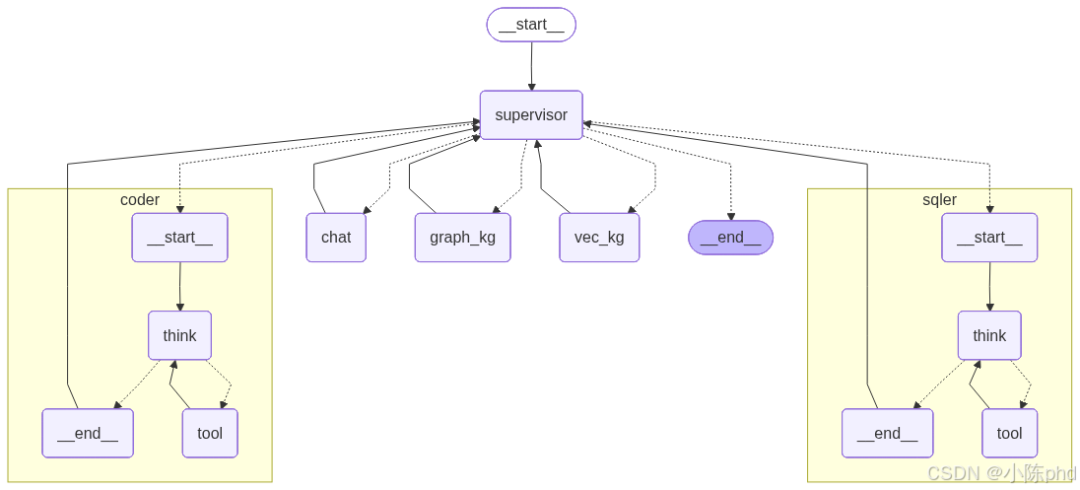
1.3 核心组件拆解
系统由“调度层、代理层、知识库层、数据存储层”四层构成,每层组件各司其职、协同工作:
| 层级 | 核心组件 | 功能定位 |
|---|---|---|
| 调度层 | Supervisor(主管代理) | 系统“大脑”,负责任务分发、代理状态管理、循环保护、结果判断与终止决策 |
| 代理层 | 5个子代理(chat/coder/sqler/graph_kg/vec_kg) | 具体任务执行者,覆盖自然语言交互、代码执行、数据查询、图检索、向量检索场景 |
| 知识库层 | Neo4j图知识库+Milvus向量库 | 非结构化知识存储与检索,图库侧重关系型知识,向量库侧重语义匹配检索 |
| 数据存储层 | MySQL结构化数据库 | 存储结构化业务数据(销售记录、客户信息、产品信息、竞争对手数据) |
2 核心组件详细解析
2.1 调度层:Supervisor主管代理
Supervisor是系统的核心调度中枢,相当于“项目管理者”,核心职责包括:
- 任务识别:解析用户需求,判断需要调用哪个/哪些代理;
- 状态追踪:记录已调用的代理、上一次执行的代理,避免重复调用;
- 规则执行:遵循6大核心规则(如“市场份额相关问题优先调用sqler”“不连续调用同一代理”);
- 循环保护:检测潜在的代理循环调用,强制切换或终止流程;
- 结果判断:评估代理执行结果是否满足用户需求,决定继续调度或终止流程。
其核心价值是让多代理从“无序竞争”变为“有序协作”,确保任务高效推进。
2.2 代理层:5个子代理的角色分工
代理层是系统的“执行团队”,每个代理都有明确的职责边界和技术栈,避免功能重叠:
2.2.1 chat代理(自然语言交互)
- • 定位:“客服专员”,负责直接响应用户的自然语言需求;
- • 核心能力:基于大模型生成流畅、易懂的中文回复,无需调用工具;
- • 适用场景:用户需求简单、无需数据查询或代码执行的场景(如“介绍系统功能”)。
2.2.2 coder代理(代码执行)
- • 定位:“数据分析师”,负责通过Python代码实现数据计算、图表生成;
- • 核心工具:Python REPL环境,支持执行任意Python代码(如数据分析、可视化);
- • 适用场景:需要复杂计算、数据统计、图表展示的需求(如“分析库存水平是否健康”)。
2.2.3 sqler代理(结构化数据查询)
- • 定位:“数据库管理员”,负责操作MySQL中的结构化业务数据;
- • 核心工具:封装增删改查(add_sale/delete_sale/update_sale/query_sales)和通用SQL执行(execute_sql)工具;
- • 适用场景:查询销售记录、客户信息、产品数据、竞争对手市场份额等结构化数据需求。
2.2.4 graph_kg代理(图知识库检索)
- • 定位:“关系挖掘专家”,负责从Neo4j图知识库中检索关系型知识;
- • 核心技术:Cypher查询语言,通过图遍历挖掘实体间关系(如“小米的合作品牌”);
- • 适用场景:需要探索实体关系、全局知识关联的需求(如“华为的技术创新突破”)。
2.2.5 vec_kg代理(向量知识库检索)
- • 定位:“细节检索专员”,负责从Milvus向量库中检索细粒度文本知识;
- • 核心技术:语义嵌入(DashScope Embeddings)+ 相似性检索,精准匹配文本语义;
- • 适用场景:需要获取具体细节、文本片段的需求(如“苹果公司的环保目标”)。
2.3 知识库层:混合RAG的双引擎
知识库层是系统的“知识储备库”,采用“图库+向量库”的混合模式,兼顾关系型知识与语义型知识:
2.3.1 Neo4j图知识库
- 存储内容:实体(如公司、产品、技术)与实体间关系(如“小米-合作-某品牌”“华为-开发-鸿蒙系统”);
- 核心优势:擅长处理“谁和谁有关系”“某实体的关联资源”等关系型查询,查询效率高于传统数据库;
- 技术亮点:通过LLMGraphTransformer自动将文本转换为图结构,无需手动建模。
2.3.2 Milvus向量知识库
- 存储内容:非结构化文本的向量表示(如公司介绍、产品详情等);
- 核心优势:基于语义相似性检索,能精准匹配用户需求与文本细节,无需依赖关键词;
- 技术亮点:支持本地Docker部署,通过DashScope Embeddings生成高维度向量,检索精度高。
2.4 数据存储层:MySQL结构化数据库
- • 存储内容:业务核心结构化数据,包含4张核心表:
sales_data:销售记录(销售ID、产品ID、客户ID、销量、金额等);customer_information:客户信息(客户ID、名称、地区、类型等);product_information:产品信息(产品ID、名称、类别、单价、库存等);competitor_analysis:竞争对手分析(竞争对手ID、名称、地区、市场份额等);
- 核心价值:为sqler代理提供数据支撑,确保结构化数据的高效查询与修改。
3 系统工作流程详解
3.1 核心工作流时序图
系统的完整工作流程遵循“用户提问→Supervisor调度→代理执行→结果反馈→终止/继续”的闭环,时序如下:
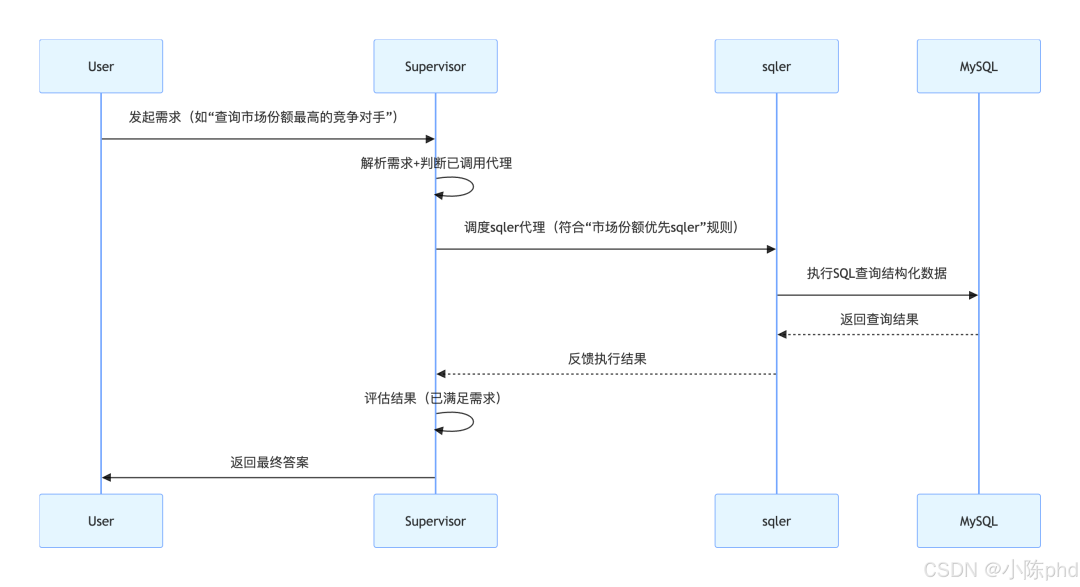
3.2 关键流程说明
- 需求接入:用户通过自然语言发起需求,所有请求先进入Supervisor;
- 调度决策:Supervisor根据需求类型和历史执行记录,选择合适的代理;
- 代理执行:被选中的代理调用对应的工具(数据库、知识库、代码环境)完成任务;
- 结果反馈:代理将执行结果返回给Supervisor,而非直接反馈给用户;
- 终止判断:Supervisor评估结果是否满足需求,满足则返回用户,否则继续调度其他代理。
4 环境准备:Docker部署三大核心服务
系统依赖Neo4j、Milvus、MySQL三大服务,推荐使用Docker Compose一键部署,避免环境冲突。
4.1 前提条件
- 安装Docker和Docker Compose(版本要求:Docker ≥ 20.10,Docker Compose ≥ 2.12);
- 确保本地端口7687(Neo4j)、19530(Milvus)、3307(MySQL)未被占用。
4.2 Docker Compose配置文件
创建docker-compose-rag.yml文件,内容如下:
version: '3.8'services: # MySQL服务(结构化数据存储) mysql: image: mysql:8.0 container_name: rag-mysql ports: - "3307:3306" environment: MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: langgraph MYSQL_CHARSET: utf8mb4 MYSQL_COLLATION: utf8mb4_unicode_ci volumes: - mysql-data:/var/lib/mysql restart: always # Neo4j图数据库服务 neo4j: image: neo4j:5.15.0 container_name: rag-neo4j ports: - "7474:7474" # Web管理界面 - "7687:7687" # Bolt协议端口(核心连接端口) environment: NEO4J_AUTH: neo4j/password NEO4J_dbms_default__database: neo4j volumes: - neo4j-data:/data restart: always # Milvus向量数据库服务 milvus: image: milvusdb/milvus:v2.4.5 container_name: rag-milvus ports: - "19530:19530" # GRPC连接端口 - "9091:9091" # HTTP连接端口 environment: MILVUS_ETCD_ENDPOINTS: etcd:2379 MILVUS_MINIO_ENDPOINT: minio:9000 MILVUS_MINIO_ACCESS_KEY: minioadmin MILVUS_MINIO_SECRET_KEY: minioadmin depends_on: - etcd - minio restart: always etcd: image: quay.io/coreos/etcd:v3.5.5 container_name: rag-etcd environment: ETCD_LISTEN_CLIENT_URLS: http://0.0.0.0:2379 ETCD_ADVERTISE_CLIENT_URLS: http://etcd:2379 volumes: - etcd-data:/etcd-data restart: always minio: image: minio/minio:RELEASE.2023-03-20T20-16-18Z container_name: rag-minio ports: - "9000:9000" - "9001:9001" environment: MINIO_ROOT_USER: minioadmin MINIO_ROOT_PASSWORD: minioadmin command: server /data --console-address ":9001" volumes: - minio-data:/data restart: alwaysvolumes: mysql-data: neo4j-data: etcd-data: minio-data:
4.3 启动服务
在docker-compose-rag.yml所在目录执行以下命令,启动所有服务:
docker-compose -f docker-compose-rag.yml up -d
4.4 服务验证
启动后,通过以下方式验证服务是否正常运行:
- MySQL:使用Navicat等工具连接
localhost:3307,用户名root,密码root,能看到langgraph数据库即正常; - Neo4j:浏览器访问
http://localhost:7474,输入用户名neo4j,密码password,能登录管理界面即正常; - Milvus:执行
docker logs rag-milvus,无报错且显示“Milvus is ready”即正常。
5 系统初始化:种子数据与知识库构建
5.1 种子数据插入
系统启动后,需向MySQL插入初始业务数据(客户、产品、销售、竞争对手信息),项目代码中已内置init_seed_data()函数,执行以下步骤自动插入:
- 确保
hybrid_rag_supervisor.py中MySQL连接配置正确:```plaintext
DATABASE_URI = ‘mysql+pymysql://root:root@localhost:3307/langgraph?charset=utf8mb4’ - 运行
hybrid_rag_supervisor.py,程序会自动检测数据库是否有数据,无数据则插入3个客户、3个产品、3个竞争对手、3条销售记录,控制台输出“✅ 种子数据初始化完成”即成功。
5.2 知识库初始化
- 图知识库(Neo4j):程序会加载
doc/company.txt中的文本内容,通过LLMGraphTransformer自动转换为图结构并插入Neo4j,控制台输出“图文档数量: X”即成功; - 向量知识库(Milvus):程序会将
company.txt文本分块(chunk_size=250,chunk_overlap=30),通过DashScope Embeddings生成向量并插入Milvus,控制台输出“向量索引构建完成”即成功。
6 系统测试:快速验证功能
6.1 测试流程
-
确保所有Docker服务正常运行;
-
配置环境变量:在
.env文件中添加DashScope API密钥和Base URL:```plaintext
DASHSCOPE_API_KEY=你的DashScope API密钥DASHSCOPE_API_BASE=你的DashScope API Base URL -
运行
hybrid_rag_supervisor.py,程序会自动执行6个测试查询,示例如下:
- 对比小米和华为在技术创新方面的不同侧重点;
- 查询市场份额最高的竞争对手及其总部位置;
- 分析所有产品的平均单价和库存健康状态。
6.2 预期结果
程序会输出每个测试查询的执行过程,包括Supervisor的调度决策、代理的执行结果,最终返回清晰的中文答案,例如:
[Supervisor] 决策:调度代理 [sqler] 执行任务[sqler]: [{'competitor_name': '三星电子', 'region': '韩国', 'market_share': 22.5}][Supervisor] 决策:调度代理 [FINISH][chatbot]: 目前市场份额最高的竞争对手是三星电子,其市场份额为22.5%,总部位于韩国。
7 总结与后续预告
本文作为系列博客的开篇,带大家完成了多代理混合RAG系统的“从0到1”搭建:明确了系统架构设计、核心组件分工、工作流程,完成了Docker环境部署、种子数据插入和知识库初始化,并通过测试验证了系统的基本功能。
这套系统的核心优势在于“分工明确、多源融合、智能调度”,既能处理结构化数据查询,又能挖掘关系型知识和检索文本细节,为复杂场景下的智能应用提供了可落地的架构方案。
后续博客预告
- 主题2:《多代理实战:5个子代理的角色分工与ReAct架构实现》—— 拆解ReAct Agent的底层原理和代码实现;
- 主题3:《混合知识库搭建:本地Docker部署Neo4j图数据库与Milvus向量库》—— 深入讲解双知识库的建模、优化与协同逻辑;
- 主题4:《Supervisor核心:多代理调度逻辑与路由规则设计》—— 揭秘系统“大脑”的决策机制;
- 主题5:《系统测试与落地优化:问题案例、性能调优与扩展方向》—— 解决落地痛点,提升系统性能。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献634条内容
已为社区贡献634条内容

所有评论(0)