LangGraph源码分析 - AI Agent如何智能处理用户输入,从入门到精通
文章详细解析了Open Deep Research项目中用户澄清阶段的实现机制。通过分析clarify_with_user函数,解释了配置检查、模型准备、澄清分析和流程路由四个步骤的工作原理,以及State中messages字段的流转和更新过程。同时介绍了结构化输出模型和提示词设计,帮助读者理解AI Agent如何智能处理用户输入,确保研究方向的准确性。
文章详细解析了Open Deep Research项目中用户澄清阶段的实现机制。通过分析clarify_with_user函数,解释了配置检查、模型准备、澄清分析和流程路由四个步骤的工作原理,以及State中messages字段的流转和更新过程。同时介绍了结构化输出模型和提示词设计,帮助读者理解AI Agent如何智能处理用户输入,确保研究方向的准确性。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
大家好,本期我们继续研究Open Deep Research这个项目的源代码。前面三期我们分别学习了动态模型配置、多Agent架构设计和Graph State的设计思路,从本期开始,我会从数据流转的角度,对项目源代码进行一个从头到尾的梳理。
如前期所述,从数据流转的角度来看,Open Deep Research的整个研究流程从用户输入开始,经过用户澄清、研究计划生成、研究执行、最终报告生成等阶段。其中用户澄清阶段是整个系统的入口,也是数据流转的起点。本期将以这个阶段的相关代码为研究对象。
目前市面上有些Research产品/功能已经有了明显的澄清阶段,比如Qwen网页版的深度研究模式下,就会在用户提出研究主题后要求再补充回答些问题:

本期我们会以State的变化为主线,追踪messages字段从初始状态到最终状态的变化过程,以便理解信息是如何产生、更新和流转的。同时,我们也会分析代码的执行流程,以及相关的提示词设计,理解每个步骤如何影响State的变化,实现代码逻辑与State变化的有机结合。
用户澄清阶段的功能和工作流程
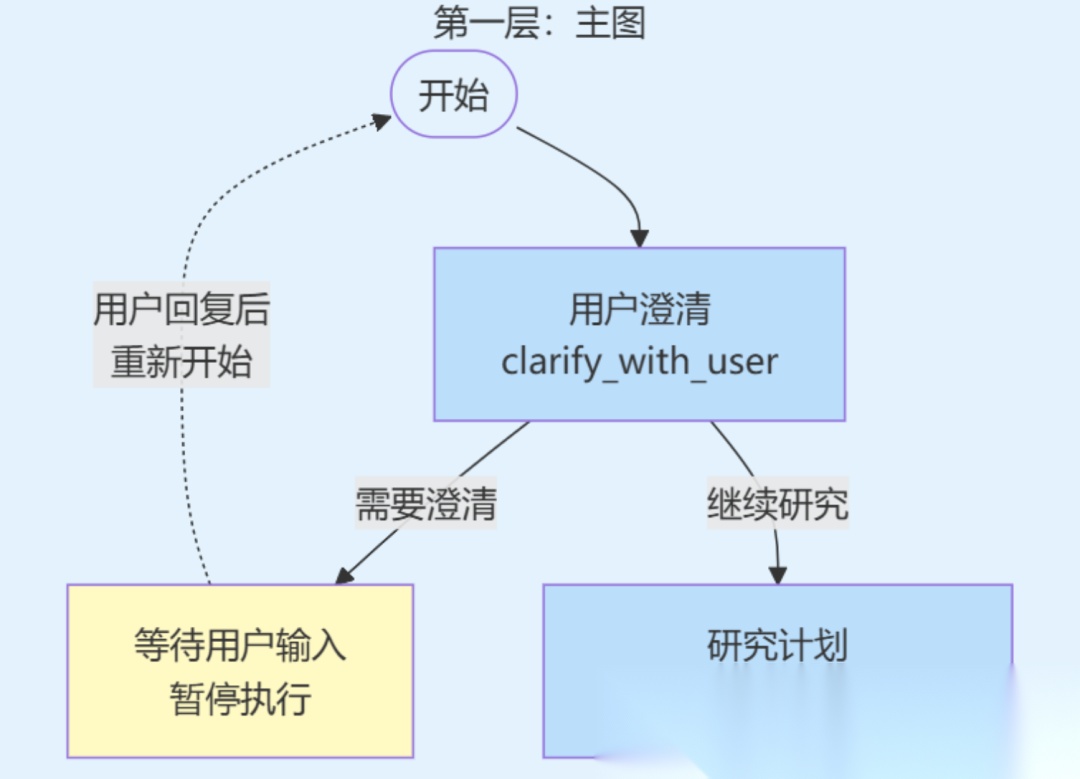
用户澄清阶段主要有两个核心功能
- • 第一:分析用户消息的完整性和清晰度,判断是否需要进一步澄清;
- • 第二:根据分析结果决定流程的走向,要么结束流程并返回澄清问题,要么继续流程并进入研究计划生成阶段。
这种设计使得系统能够在开始研究之前就确保理解用户的真实意图,避免后续研究方向的偏差。
用户澄清阶段的核心代码位于deep_researcher.py文件中的clarify_with_user函数。这个函数是一个异步节点函数,接收AgentState类型的状态和RunnableConfig类型的运行时配置,返回一个Command对象来控制流程的走向。(我们后续会仔细分析它的代码)
从代码的工作流程角度来看,用户澄清阶段可以分为四个主要步骤。
- • 第一步:配置检查,系统首先检查是否启用了澄清功能,如果未启用则直接跳过澄清步骤。
- • 第二步:模型准备,如果启用了澄清功能,系统会从状态中读取用户消息,配置用于澄清分析的模型,这个模型被设置为生成结构化输出。
- • 第三步:澄清分析,系统将用户消息和当前日期构建成提示词,调用模型进行分析,模型会返回一个结构化的结果,包含是否需要澄清、澄清问题或确认消息。
- • 第四步:流程路由,根据模型的分析结果,系统要么结束流程并返回澄清问题,要么继续流程并进入研究计划生成阶段。
用户澄清阶段涉及的State字段回顾
在深入分析代码实现之前,我们先简要回顾一下这个阶段涉及的State字段。关于State的详细设计思路,我们在上一期文章中已经深入讨论过,这里只回顾与用户澄清阶段直接相关的内容。(注意,对state字段内容不熟悉的朋友,一定先看看上一期。)
用户澄清阶段主要涉及messages字段,这个字段承载着用户输入和系统响应的所有消息。回顾上期内容,我们知道:
- •
AgentInputState作为图的输入接口,只包含messages字段;当输入数据进入图后,会被转换为AgentState类型。 - •
AgentState继承自MessagesState,自动继承了messages字段;同时,messages字段使用operator.add作为Reducer函数,这意味着新消息会被追加到现有消息列表的末尾,而不是覆盖。
在用户澄清阶段,messages字段的变化过程是:
- • 初始时包含用户的输入消息;
- • 经过
clarify_with_user节点的处理后,会根据是否需要澄清添加不同的消息。如果需要澄清,会添加包含澄清问题的AIMessage;如果不需要澄清,会添加包含确认消息的AIMessage。
由于使用了operator.add作为Reducer函数,这些新消息会被追加到消息列表的末尾,保证对话历史的完整性。
State变化的完整流程:从输入到输出
现在让我们来详细分析用户澄清阶段的完整流程。
初始状态:AgentInputState的输入
流程的起点是外部调用者传入的输入数据。根据主图的定义,输入数据必须符合AgentInputState的结构,也就是只包含messages字段。假设用户输入了一条消息"帮我研究一下人工智能的发展历史",那么初始的输入数据如下:
{ "messages": [ HumanMessage(content="帮我研究一下人工智能的发展历史") ]}
当这个输入数据进入图后,LangGraph会根据主图定义中的input=AgentInputState和AgentState来处理数据。
AgentInputState定义了输入接口,指定调用者需要提供哪些数据;AgentState定义了图的内部状态,指定图内部使用哪些字段。由于AgentInputState只包含messages字段,而AgentState也包含messages字段(继承自MessagesState),所以LangGraph会将输入数据中的messages字段值映射到AgentState的messages字段中。
注意,AgentState中的其他字段(如supervisor_messages、research_brief等)在初始时会被自动初始化为默认值,这些字段会在后续的节点执行过程中逐步填充。
这个过程完成后,AgentState中的messages字段包含了用户的原始输入消息,并且这个字段使用operator.add作为Reducer函数,这意味着后续添加的新消息会被追加到消息列表的末尾。
节点执行:clarify_with_user函数的四个步骤
当clarify_with_user节点被调用时,它接收当前的AgentState作为输入。这个函数的执行过程对应开篇提到的四个步骤,每个步骤都涉及代码逻辑的执行和State的变化,下面我们来逐步分析。
第一步:配置检查
首先,节点函数会检查用户是否启用了澄清功能。这一步中无论澄清是否开启,State都不会变化。
async def clarify_with_user(state: AgentState, config: RunnableConfig) -> Command[Literal["write_research_brief", "__end__"]]: # Step 1: Check if clarification is enabled in configuration configurable = Configuration.from_runnable_config(config) if not configurable.allow_clarification: # Skip clarification step and proceed directly to research return Command(goto="write_research_brief")
1.函数签名概览
先来看下函数签名,其中async关键字表示这是一个异步函数。由于这个函数中会调用异步的模型API(具体在第三步中会详细讲解),这样可以提高系统的并发性能。
该函数接收两个参数:state参数是当前的AgentState,包含了messages字段等状态信息,函数会从中读取用户消息并更新状态;config参数是RunnableConfig类型的运行时配置,包含了模型配置、API密钥等运行时信息,函数会从中读取配置来决定行为(比如是否启用澄清功能、使用哪个模型等)。
函数返回类型Command[Literal["write_research_brief", "__end__"]]表示这个函数会返回一个Command对象,并且这个Command的goto参数只能是"write_research_brief"或"__end__"这两个值之一,限定了数据流转的下游渠道。这个我们在第四步中会详细讲解。
2.判断澄清功能是否开启
从代码逻辑来看,Configuration.from_runnable_config(config)从运行时配置中提取配置信息,我们在第一期文章讲模型配置的动态读取时中已经详细学习过这个机制,不熟悉的同学请复习。
然后,代码使用if not来检查allow_clarification配置项。当用户关闭澄清功能时(即用户配置False),not会让表达式结果变为True,这样就会直接通过Command跳转到write_research_brief节点进入研究计划生成阶段。这时,messages字段内容不会发生变化,只包含[HumanMessage(content="帮我研究一下人工智能的发展历史")]。因为Command只跳转了流程,没有更新State。
如果澄清功能已启用,则不会触发跳转,代码会继续执行后续步骤。
第二步:模型准备
这一步中,节点函数从State中读取用户消息,配置用于澄清分析的模型;从State变化来看,这一步只是读取State中的数据,State本身不发生变化。
# Step 2: Prepare the model for structured clarification analysis messages = state["messages"] model_config = { "model": configurable.research_model, "max_tokens": configurable.research_model_max_tokens, "api_key": get_api_key_for_model(configurable.research_model, config), "tags": ["langsmith:nostream"] } # Configure model with structured output and retry logic clarification_model = ( configurable_model .with_structured_output(ClarifyWithUser) .with_retry(stop_after_attempt=configurable.max_structured_output_retries) .with_config(model_config) )
首先,state["messages"]这行代码从State中提取messages字段的值,这是一个消息列表,包含了用户输入的所有消息。此时,messages变量包含了用户的原始输入,例如[HumanMessage(content="帮我研究一下人工智能的发展历史")]。
接着,函数构建模型配置字典model_config,这个字典包含了模型名称、最大token数、API密钥等配置信息。get_api_key_for_model函数根据模型名称的前缀(如"openai:"、"anthropic:")从环境变量或配置中获取对应的API密钥。
然后,函数在全局的configurable_model模板基础上,通过链式调用构建专门的澄清模型。with_structured_output(ClarifyWithUser)这个方法告诉模型需要生成结构化的输出,输出格式必须符合ClarifyWithUser这个Pydantic模型的定义。with_retry方法添加了重试逻辑,即如果结构化输出失败,会重试最多max_structured_output_retries次。而with_config方法会将前面构建的model_config应用到模型上。这样,我们就得到了一个专门用于澄清分析的模型实例clarification_model。
关于model_config的构建、get_api_key_for_model函数的作用,以及with_structured_output、with_retry、with_config这些链式调用的详细原理,我们在第一期文章"多Agent系统的动态模型配置思路"中已经详细讲解过,这里不再赘述。不熟悉的同学可以回顾第一期文章的"第三步:为不同的节点创建配置字典模板"和"第四步:将配置应用到模型"部分。
从State变化来看,在这个步骤中,State本身没有发生变化。我们只是从State中读取了messages字段的值,用于后续的处理。State仍然是原来的状态,messages字段仍然只包含[HumanMessage(content="帮我研究一下人工智能的发展历史")]。
第三步:澄清分析
第三步,节点函数调用模型来分析用户消息,生成结构化的分析结果;从State变化来看,这一步生成了新的消息内容,但还没有更新到State中。
# Step 3: Analyze whether clarification is needed prompt_content = clarify_with_user_instructions.format( messages=get_buffer_string(messages), date=get_today_str() ) response = await clarification_model.ainvoke([HumanMessage(content=prompt_content)])
这一步是实际执行澄清分析的地方:
1.构造澄清提示词
首先,我们需要把用户输入的内容(已存储在message中)与我们事先设定好的澄清指令模板(clarify_with_user_instructions)结合起来,形成一个完整的澄清提示词。这个过程又可以分为两步:
- • 首先,准备需要填入提示词模板的数据。
get_buffer_string(messages)函数将用户输入的消息列表转换为模型能够理解的文本字符串格式。get_today_str()函数返回当前日期的字符串表示,为模型提供时间上下文信息。 - • 然后,使用
clarify_with_user_instructions.format()方法,将这两个数据填入提示词模板。clarify_with_user_instructions是一个提示词模板字符串,包含了如何分析用户消息的指令,其中包含{messages}和{date}两个占位符。format()方法会将这两个占位符替换为实际的值,生成完整的提示词内容。
接着,把构建好的格式化提示词包装成一个HumanMessage对象(HumanMessage(content=prompt_content)),就可以传递给模型进行分析了。
2.传入模型执行澄清分析
然后,我们调用clarification_model.ainvoke()方法,传入包含HumanMessage对象的消息列表,异步执行模型调用。
由于我们之前配置澄清模型使用了with_structured_output(ClarifyWithUser),模型会返回一个ClarifyWithUser类型的对象,而不是普通的文本,保存到变量response中。这个ClarifyWithUser对象包含了三个字段:need_clarification、question、verification。
3.关于结构化输出
这里需要补充说明一下,with_structured_output(ClarifyWithUser)这个方法的核心作用是约束模型的输出格式,确保模型返回的数据符合ClarifyWithUser这个Pydantic模型的定义。它的工作原理是这样的:
首先,with_structured_output会将ClarifyWithUser这个Pydantic模型的字段定义(包括字段名、类型、描述等)转换为模型可以理解的格式,并自动添加到我们提供的提示词后面,告诉模型需要生成什么格式的数据。也就是说,with_structured_output和提示词模板clarify_with_user_instructions是共同起作用的:
- •
clarify_with_user_instructions告诉模型"做什么"(分析用户消息,判断是否需要澄清,如何提问等) - •
with_structured_output告诉模型"以什么格式输出"(JSON格式,包含need_clarification、question、verification三个字段)
当模型收到完整的提示词时,它既知道要执行什么任务(来自clarify_with_user_instructions),也知道要以什么格式输出(来自with_structured_output添加的结构化输出要求)。当模型生成响应时,它会尝试生成符合这个结构的JSON数据。
然后,with_structured_output会解析模型的原始输出(通常是文本格式的JSON字符串),并使用Pydantic进行验证和转换。如果模型输出的JSON数据符合ClarifyWithUser的定义,Pydantic会将其转换为ClarifyWithUser类型的Python对象;如果不符合(比如缺少字段、类型错误等),Pydantic会抛出验证错误。
回到主题,从State变化来看,在这个步骤中,State仍然没有发生变化。我们只是生成了新的消息内容(澄清问题或确认消息),但还没有将这些内容添加到State中。State的messages字段仍然只包含[HumanMessage(content="帮我研究一下人工智能的发展历史")]。这一步是分析阶段,生成了用于更新State的数据,但State的更新发生在下一步。
第四步:流程路由
第四步中,函数会根据澄清模型的分析结果决定流程走向;从State变化来看,这一步通过Command的update参数更新State,这是State发生变化的唯一步骤。
# Step 4: Route based on clarification analysis if response.need_clarification: # End with clarifying question for user return Command( goto=END, update={"messages": [AIMessage(content=response.question)]} ) else: # Proceed to research with verification message return Command( goto="write_research_brief", update={"messages": [AIMessage(content=response.verification)]} )
从代码逻辑来看,这一步根据response.need_clarification的值进行条件判断。如果为True,返回一个Command,goto=END表示结束当前流程,update参数包含澄清问题;如果为False,返回一个Command,goto="write_research_brief"表示跳转到研究计划生成阶段,update参数包含确认消息。
这里需要说明一下END的含义。END是LangGraph定义的特殊节点,表示图的执行流程结束。当Command的goto参数为END时,整个图的执行会终止,不再执行后续节点。这不是函数终止,而是整个图的执行流程终止。
从State变化来看,这是澄清阶段State发生变化的唯一情景,我们来具体分析:
1.如果需要用户澄清
首先,如果response.need_clarification为True,说明需要向用户询问澄清问题。
此时,在messages字段的Reducer函数的作用下,澄清问题AIMessage(content=response.question)会被追加到消息列表的末尾,也就是说messages字段的值会从[HumanMessage(content="帮我研究一下人工智能的发展历史")]变成[HumanMessage(content="帮我研究一下人工智能的发展历史"), AIMessage(content=response.question)],完成State的更新。
同时,由于goto=END,图的执行会结束,系统会将包含澄清问题的State返回给用户。用户看到澄清问题后,需要再次调用图,并传入包含澄清回答的新消息,系统会重新从clarify_with_user节点开始执行,此时messages字段中已经包含了之前的对话历史(包括用户的原始消息和系统的澄清问题),系统会基于完整的对话历史继续处理。由此实现一种异步交互模式。
这里可能会有读者疑问:为什么不使用LangGraph的interrupt()功能来实现暂停和等待用户输入呢?
interrupt()确实是一个很适合澄清场景的方案,不过正如我们前期所学习的,interrupt()功能依赖于Checkpoints(检查点)机制,需要在编译图时配置checkpointer,并且需要在config中设置thread_id来管理状态的持久化,这会增加系统的复杂度和依赖。同时,Open Deep Research的设计理念是面向API调用场景的异步交互模式。在这种模式下,每次API调用都是一个独立的请求-响应周期,图执行完成后返回结果,用户根据结果决定是否继续调用。这种设计更适合RESTful API或类似的异步交互场景,不需要维护长时间的执行上下文。
当然,如果项目需要更强大的状态管理和更优雅的暂停-恢复机制,使用interrupt()配合checkpointer会是一个更好的选择。
2.如果不需要用户澄清
如果response.need_clarification为False,说明用户消息已经足够清晰,可以直接开始研究。
此时State的变化过程是:原来的messages字段包含[HumanMessage(content="帮我研究一下人工智能的发展历史")],经过Reducer函数的处理,新的State中的messages字段变成了[HumanMessage(content="帮我研究一下人工智能的发展历史"), AIMessage(content=response.verification)]。确认消息被追加到了消息列表的末尾,State更新完成,流程继续到研究计划生成阶段。
结构化输出模型:State更新的数据源
通过阅读源代码可以看出,澄清机制的核心其实是ClarifyWithUser这个结构化输出模板。这个模板的作用是确保模型输出的数据格式符合预期,因为这些数据最终会被用来更新State,同时决定下游的路由。让我们看看它的定义:
class ClarifyWithUser(BaseModel): """Model for user clarification requests.""" need_clarification: bool = Field( description="Whether the user needs to be asked a clarifying question.", ) question: str = Field( description="A question to ask the user to clarify the report scope", ) verification: str = Field( description="Verify message that we will start research after the user has provided the necessary information.", )
这个类继承自Pydantic的BaseModel,定义了三个字段。
- •
need_clarification是一个布尔值字段,用于表示是否需要澄清,这个字段决定了State更新的方向:如果需要澄清,State会被更新为包含澄清问题并结束流程;如果不需要澄清,State会被更新为包含确认消息并继续流程。 - •
question是一个字符串字段,当需要澄清时,这里存储要问用户的问题,这个问题的内容会被用来创建AIMessage并追加到State的messages字段中。 - •
verification也是一个字符串字段,当不需要澄清时,这里存储确认消息,这个确认消息的内容也会被用来创建AIMessage并追加到State的messages字段中。
每个字段都使用了Field来添加描述信息,这些描述信息会被传递给模型,帮助模型理解每个字段的含义和用途。Pydantic会自动验证模型输出的数据是否符合这个结构,如果不符合会抛出验证错误,这保证了数据的类型安全,也确保了State更新的可靠性。
提示词设计:引导模型生成State更新所需的数据
澄清机制的另一个关键组件是提示词模板clarify_with_user_instructions。这个提示词的作用是引导模型分析State中的messages字段,生成用于更新State的数据。我们分拆了下它,逐一分析各部分内容:
1.提供问题澄清的上下文
clarify_with_user_instructions="""These are the messages that have been exchanged so far from the user asking for the report:<Messages>{messages}</Messages>Today's date is {date}.
首先,它从State中读取messages字段的内容,通过{messages}占位符将消息历史传递给模型,同时{date}占位符传递当前日期,从而明确告诉模型需要分析的消息内容和当前日期,为模型提供必要的上下文。
2.判断是否需要澄清
Assess whether you need to ask a clarifying question, or if the user has already provided enough information for you to start research.IMPORTANT: If you can see in the messages history that you have already asked a clarifying question, you almost always do not need to ask another one. Only ask another question if ABSOLUTELY NECESSARY.
然后,它给出了判断是否需要澄清的指导原则,特别强调如果已经问过澄清问题,通常不需要再问一次,这避免了重复询问的尴尬。这个设计考虑了State中可能已经包含澄清问题的场景。
3.如何提问以实现高质量澄清
If there are acronyms, abbreviations, or unknown terms, ask the user to clarify.If you need to ask a question, follow these guidelines:- Be concise while gathering all necessary information- Make sure to gather all the information needed to carry out the research task in a concise, well-structured manner.- Use bullet points or numbered lists if appropriate for clarity. Make sure that this uses markdown formatting and will be rendered correctly if the string output is passed to a markdown renderer.- Don't ask for unnecessary information, or information that the user has already provided. If you can see that the user has already provided the information, do not ask for it again.
接着,提示词详细说明了如果需要澄清,应该如何提问。它要求问题要简洁但全面,可以使用列表格式提高可读性,并且要避免询问用户已经提供的信息。这些指导原则确保了澄清问题的质量,也确保了添加到State中的消息是有价值的。
4.明确问题澄清的结构化输出要求
Respond in valid JSON format with these exact keys:"need_clarification": boolean,"question": "<question to ask the user to clarify the report scope>","verification": "<verification message that we will start research>"If you need to ask a clarifying question, return:"need_clarification": true,"question": "<your clarifying question>","verification": ""If you do not need to ask a clarifying question, return:"need_clarification": false,"question": "","verification": "<acknowledgement message that you will now start research based on the provided information>"For the verification message when no clarification is needed:- Acknowledge that you have sufficient information to proceed- Briefly summarize the key aspects of what you understand from their request- Confirm that you will now begin the research process- Keep the message concise and professional"""
最后,提示词明确说明了输出格式,要求模型返回JSON格式,包含三个指定的键。它还分别说明了需要澄清和不需要澄清两种情况下的输出格式,这帮助模型理解如何填充每个字段。这些字段的值最终会被用来创建AIMessage并更新State的messages字段。
总结
用户输入处理与澄清机制是Open Deep Research系统的入口阶段,它负责在开始研究之前分析用户消息的完整性和清晰度,判断是否需要进一步澄清,并根据分析结果决定流程的走向。这个阶段的核心功能有两个:一是分析用户消息是否需要澄清,二是根据分析结果决定是结束流程返回澄清问题,还是继续流程进入研究计划生成阶段。
从实现机制来看,这个阶段采用了配置检查→模型准备→澄清分析→流程路由的四步流程。首先检查是否启用澄清功能,如果未启用则直接跳过;如果启用,则配置用于澄清分析的模型(使用结构化输出),调用模型分析用户消息,最后根据分析结果通过Command决定流程走向。这种设计既提供了灵活性(可以通过配置禁用澄清),又保证了分析的准确性(使用结构化输出确保数据格式正确)。
从State变化的角度来看,这个阶段的核心是messages字段的更新和流转。初始状态是AgentInputState,只包含用户的原始消息;经过clarify_with_user节点的处理,State被更新为AgentState,messages字段通过Reducer函数追加了系统的澄清问题或确认消息。
好了,以上就是本期的全部内容,如果大家觉得对自己有帮助的,还请多多点赞、收藏、转发、关注!祝大家玩得开心,我们下期再见!
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)