CO-SPY: Combining Semantic and Pixel Features to Detect Synthetic Images by AI
生成式AI快速发展,合成图像质量高、速度快,但存在被用于制造假新闻等滥用风险。所以要开发更通用、更鲁棒的合成图像检测方法,以应对最新模型和各种真实场景下的挑战。:关注图像内容(如手部轮廓)。对,但。:关注像素级纹理伪影(如上采样引入的痕迹)。,但,性能下降显著。为了深入理解其优缺点,研究评估了两种最新的语义检测器(Fusing和UnivFD)以及两种伪影检测器(LNP和NPR),使用DRCT-2M
|
文章名 |
CO-SPY: Combining Semantic and Pixel Features to Detect Synthetic Images by AI |
|
作者 |
Siyuan Cheng˚, Lingjuan Lyu:‹, Zhenting Wang;, Xiangyu Zhang, Vikash Sehwag: Purdue University, :Sony AI, ;Rutgers University |
|
简介 |
这篇文章主要介绍了一个名为Co-SPY的新型合成图像检测框架。 |
1 研究背景与动机
1.1 背景
生成式AI快速发展,合成图像质量高、速度快,但存在被用于制造假新闻等滥用风险 。所以要开发更通用、更鲁棒的合成图像检测方法,以应对最新模型和各种真实场景下的挑战 。
两类主要检测方法:
a) 语义特征检测器:关注图像内容(如手部轮廓)。对有损格式(如JPEG压缩)鲁棒,但难以泛化到未见过的模型和内容 。
b) 伪影特征检测器:关注像素级纹理伪影(如上采样引入的痕迹)。能泛化到不同模型和内容,但对有损格式非常敏感,性能下降显著 。
为了深入理解其优缺点,研究评估了两种最新的语义检测器(Fusing和UnivFD)以及两种伪影检测器(LNP和NPR),使用DRCT-2M/SDv1.4数据集进行训练,并使用Co-SPyBENCH进行评估。分析聚焦于三个关键方面:对多样化模型的支持、对有损格式的支持,以及对未见物体的泛化能力。
分析得出了两个核心观察:
- 伪影检测器不支持有损格式:伪影检测器在泛化到未见模型方面表现出色,但其性能在即使轻微的JPEG压缩下也会显著下降。这是因为它们依赖的纹理级伪影对输入变换高度敏感,压缩会扭曲或消除检测所需的细微线索。
- 语义检测器难以泛化到未见模型和未见内容:语义检测器在旧的、相似的模型上表现良好,即使存在有损变换,但其泛化到最新模型和未见内容的能力有限。这是因为它们从特定来源的合成图像中学到的特征,与最新扩散模型产生的特征存在显著差异。
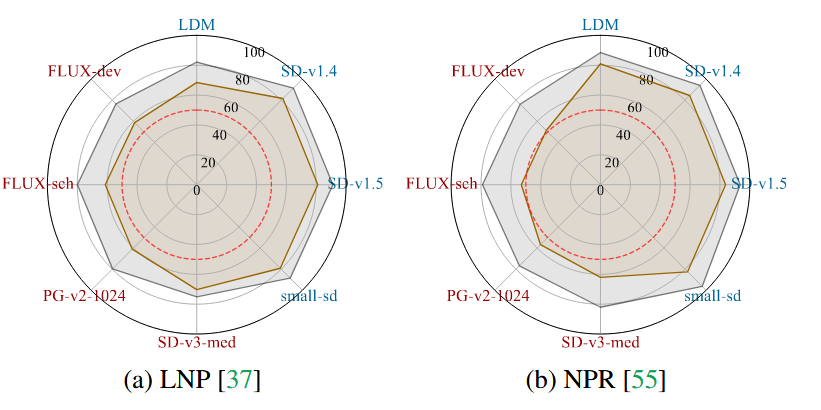
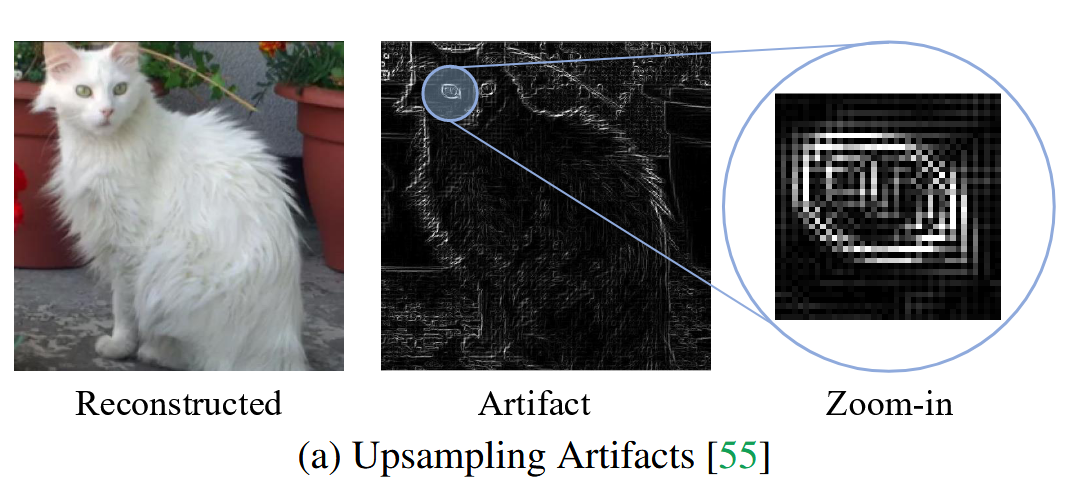
展示LNP和NPR的性能。图中,蓝色模型代表较旧的、生成图像与合成训练样本相似的模型,红色模型代表最近的、能生成更多样化和独特图像的模型。灰色图线表示未应用任何变换的测试结果,棕色图线表示应用了JPEG压缩后的测试结果。该图表明,伪影检测器在所有模型上都实现了很高的泛化能力,平均准确率约为85%。然而,即使轻微的JPEG压缩也会导致其性能大幅下降约17%。这验证了伪影检测器能很好地泛化到不同的模型和未见过的物体,但对有损格式非常脆弱。
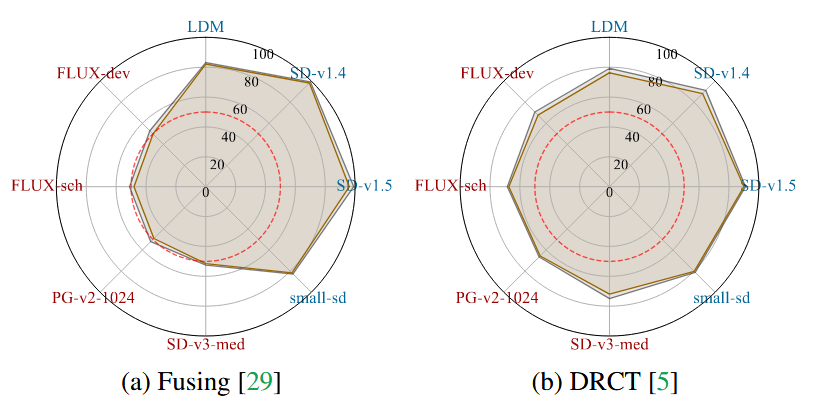
展示了两种语义检测器(Fusing和DRCT)的性能。图中,蓝色模型代表较旧的、生成图像与合成训练样本相似的模型,红色模型代表最近的、能生成更多样化和独特图像的模型。灰色图线表示未应用任何变换的测试结果,棕色图线表示应用了JPEG压缩后的测试结果。该图表明,语义检测器在旧模型上性能很高,但在最新模型上性能大幅下降,准确率仅在50%左右。同时,JPEG压缩导致的准确性下降很小,仅约2%。这说明了语义检测器对有损格式(如JPEG)具有鲁棒性,但难以泛化到未见过的、特别是最新的生成模型。
1.2 动机
当前的两类主流检测器,基于语义特征的检测器和基于纹理层面伪影的检测器,在泛化能力上存在互补的短板。语义检测器对有损格式(如JPEG压缩)鲁棒,但难以泛化到未见过的模型和内容。而伪影检测器能很好地泛化到不同的模型和未见过的物体,但对有损格式非常脆弱,性能会因压缩而显著下降。必须先分别增强这两类检测器本身的能力,使它们在原本不擅长的领域(如伪影检测器应对有损格式,语义检测器应对新模型)得到改善,然后再通过一种智能的自适应机制将它们融合起来。
1.3 贡献
a) 提出了Co-SPyBENCH,这是一个新颖、高质量且多样化的合成图像检测基准。它包含超过一百万张图像,包括来自五个已建立数据库的真实图像,以及使用相应真实图像标题在各种配置下生成的合成图像。合成图像由22种最先进的文本到图像扩散模型生成,包括最近发布的FLUX等最新模型。为了增强多样性,Co-SPyBENCH包括使用不同标题、分辨率和配置(例如不同的扩散步骤和引导尺度)生成的合成图像。该基准在全面性和多样性方面都超过了现有数据集,为评估未来的检测方法提供了坚实的基础。此外,我们还从5个知名网站收集了合成图像,以模拟真实世界的野外测试场景。
b) 对现有检测器进行了全面且深入的分析。概述了它们的优缺点,并解释了每个发现背后的原因。
c) 提出了一种新颖的合成图像检测框架Co-SPY(“结合语义和像素特征以检测AI生成的合成图像”),它增强了现有的语义和伪影提取方法,并战略性地整合了两种特征的优点。这个综合性框架显著提高了检测性能,优于最先进的方法。
d) 进行全面评估,以证明我们的框架优于现有的最先进方法。如第4节所述,在相同数据集上训练并评估了5个数据集和各种压缩条件下22个模型生成的合成图像后,我们的方法在准确率上比最先进的语义检测器DRCT高出11%,比最新的伪影检测器NPR高出21%
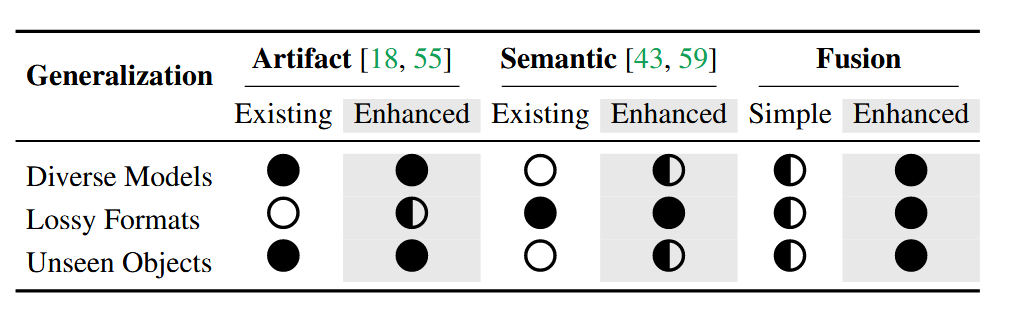
表一通过符号化的方式,对比了不同类型检测器在三个关键泛化场景下的能力表现。
-
第一列(Artifacts Detectors (Existing)):展示了现有伪影检测器在三个场景下的表现。它在支持多样化模型和泛化到未见物体方面表现良好,但在支持有损格式方面能力很弱。
-
第二列(Artifacts Detectors (Enhanced)):展示了本文增强后的伪影检测器的表现。经过增强后,它在支持有损格式方面的能力得到了提升。
-
第三列(Semantic Detectors (Existing)):展示了现有语义检测器在三个场景下的表现。它对有损格式具有鲁棒性,但在支持多样化模型和泛化到未见物体方面表现不佳。
-
第四列(Semantic Detectors (Enhanced)):展示了本文增强后的语义检测器的表现。经过增强后,它在支持多样化模型和泛化到未见物体方面的能力得到了改善。
-
第五列(Simple Combine (Existing)):展示了简单结合现有两类检测器后的表现。这种结合并未实现协同增效,其能力只是两类检测器现有能力的简单叠加。
-
第六列(Our Fusion (Co-SPY)):展示了本文提出的自适应融合框架(Co-SPY)的表现。它在所有三个泛化场景下都表现出强大的支持能力。
2 实现方法
2.1 伪影检测器的提升
纹理层面的伪影可以泛化到未见过的模型和物体,但在有损变换(如JPEG压缩)下无法保持,因为这些伪影是低级的且易受压缩影响。一种流行的方法利用生成模型中存在大量下采样和上采样操作的观察结果。
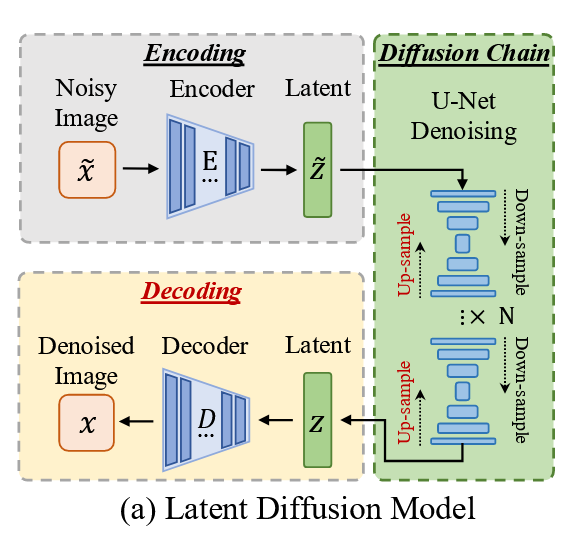
上图展示了一个典型的扩散流程,其中每个扩散步骤都涉及下采样和上采样。因此,当一张合成图像经过一对下采样和上采样操作时,其结果图像与原始图像的差异,比一张从未经历过此类操作的真实图像要小。因此,可以从这种差异中提取伪影并用于分类。然而,这些伪影是非常低级的,例如以颗粒状纹理的形式呈现,如下图所示。
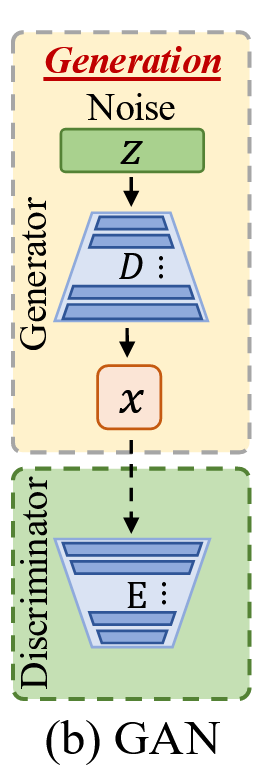
除了下采样和上采样,大多数生成模型还共享另一个共同/相似的操作——解码。图4(a-b)展示了两种流行的生成模型,即潜在扩散模型和生成对抗网络。LDM将噪声输入编码到潜在空间,通过多个扩散步骤进行处理,最后解码回像素空间。GAN采用更简单的方法,直接将噪声向量映射到输出图像。它同样使用判别器来指导生成过程。两者都有一个解码器组件D。与下采样和上采样类似,解码也会引入其自身的伪影。
因此,本文采用一个预训练的变分自编码器(即一对编码器和解码器)来捕获伪影,方法是将图像输入VAE,并将结果图像与原始图像进行差分。随后,训练一个下游分类器来区分来自合成图像的差异和来自真实图像的差异。与下采样和上采样引入的伪影相比,解码伪影处于更高层次,因此在存在变换时更具鲁棒性。图3(b)展示了此类伪影的一个例子。观察到,与图3(a)中下采样和上采样操作产生的伪影相比,它们更平滑且编码了更多的物体信息。
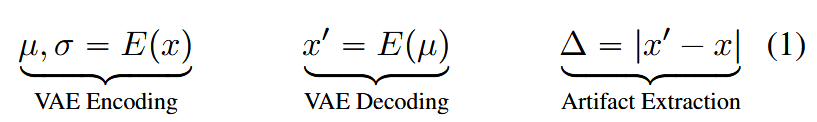
将输入图像x通过VAE编码器E编码为潜在空间的均值μ和方差σ,然后仅使用均值μ通过解码器D重建得到图像x',最后通过计算x'与x的绝对差值来提取伪影Δ。这些提取出的伪影随后被送入一个ResNet-50分类器,以区分图像是真实的还是AI生成的。
2.2 语义检测器的提升
(1) 为了缓解对训练数据过拟合问题,我们采用了最新的CLIP模型作为特征提取器。其核心思想是利用CLIP在数十亿图像上预先训练所获得的大量知识。具体来说,我们使用CLIP的视觉编码器为真实和虚假图像生成嵌入,然后利用这些嵌入来训练一个下游分类器。
(2) 仅使用“硬标签”样本(即非真即假,标记为0或1的样本)进行训练,无法达到最佳效果。模型只记住了训练集中特定AI模型的“画风”或特征,而无法灵活应对新的、未见过的AI生成内容。
为了解决上述问题,作者提出了“特征插值”的方法。
操作:在由预训练CLIP模型提取出的“图像特征向量”(即嵌入)空间中进行操作。具体是在真实图像的特征向量(x_R)和合成图像的特征向量(x_S)之间进行线性插值。
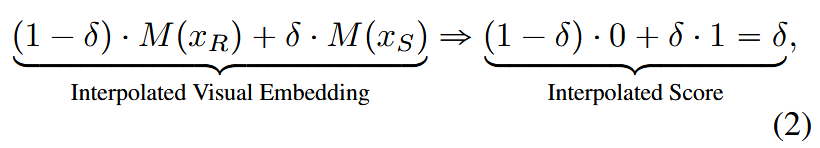
在每次训练的一批数据中,会随机选择其中50%的样本,对它们应用上述特征插值操作(使用一个随机的δ值),而剩下的50%则保持不变。这种混合训练策略确保了模型既能学习硬边界,也能学习连续的过渡状态。
2.3 Co-SPY架构
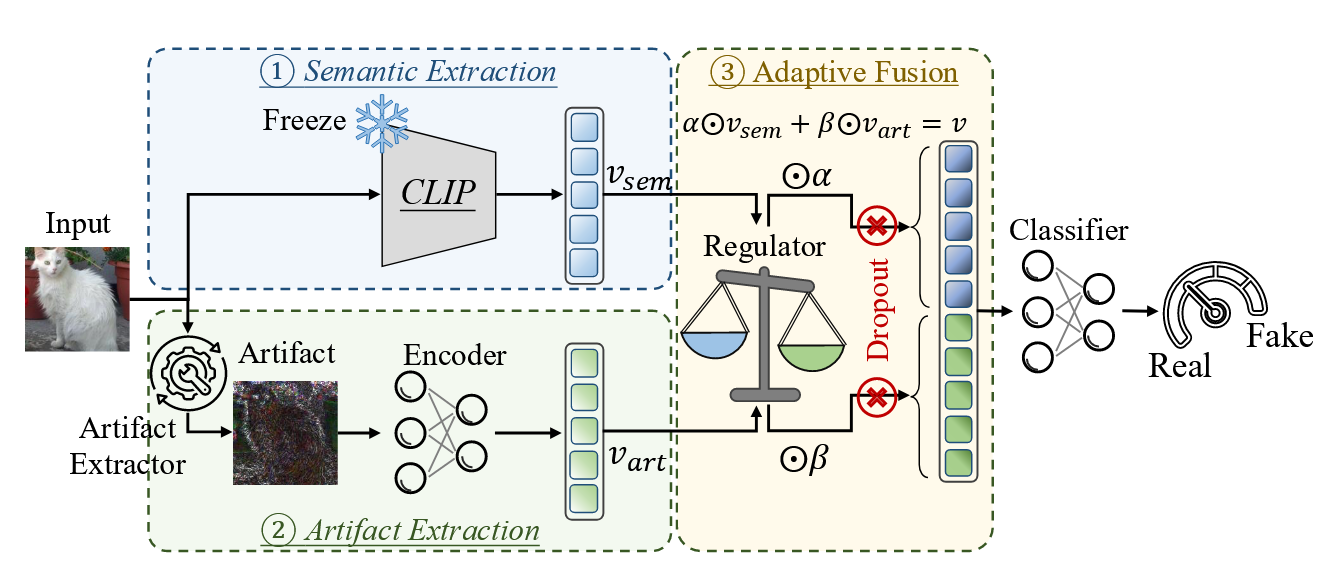
该框架包含三个主要模块:语义特征提取、伪影提取和自适应融合。
① 语义提取:使用CLIP ViT-SO400M-14-384作为语义特征提取器,并在训练期间保持其冻结。此外,我们应用公式2中定义的特征插值作为数据增强技术。得到的语义特征记为v_sem。
② 伪影提取:伪影是使用SD-v1.5的VAE并遵循公式1来提取的。采用ResNet-50编码器从导出的伪影中提取特征,得到v_art。
③ 自适应融合:为了动态地结合语义和伪影特征,我们设计了一个调节器模块,该模块在拼接之前将每个特征映射到一个缩放系数。具体来说,用于调节语义特征,
用于调节伪影特征,然后通过
进行自适应融合。其中R_sem和R_art分别是语义和伪影特征的调节器。系数α和β对各自的特征进行缩放,加权后的语义和伪影特征被拼接起来得到聚合特征v。此外,我们在聚合前对特征应用随机丢弃,在训练期间随机将α或β设置为0,以防止对任一特征的过拟合。两个系数永远不会同时设置为0,以避免v成为零向量。最后,一个分类层将聚合特征v映射到一个输出分数,代表输入是合成图像的概率。
3 实验以及结果
3.1 实验设置
(1) 训练集部分
研究使用了两个成熟的训练集:CNNDet/ProGAN训练集和DRCT-2M/SD-v1.4训练集。CNNDet/ProGAN训练集包含来自LSUN的真实图像和由ProGAN生成的合成图像,总计72万张图像。DRCT-2M/SD-v1.4训练集则利用SD-v1.4模型和MSCOCO-2017的标题生成合成图像,并包含同等数量的MSCOCO真实图像,总计23.6万张图像。
(2) 测试集部分
评估使用了四个测试集以全面衡量检测性能:AIGCDetectBenchmark、GenImage、Co-SPYBENCH以及Co-SPYBENCH/in-the-wild。所有图像在训练和测试阶段均被调整为224x224像素以确保公平比较。
在输入图像上以50%的概率随机应用质量在75至95之间的JPEG压缩,以模拟用户上传图片前的典型压缩场景,并防止检测器过度拟合于格式差异。
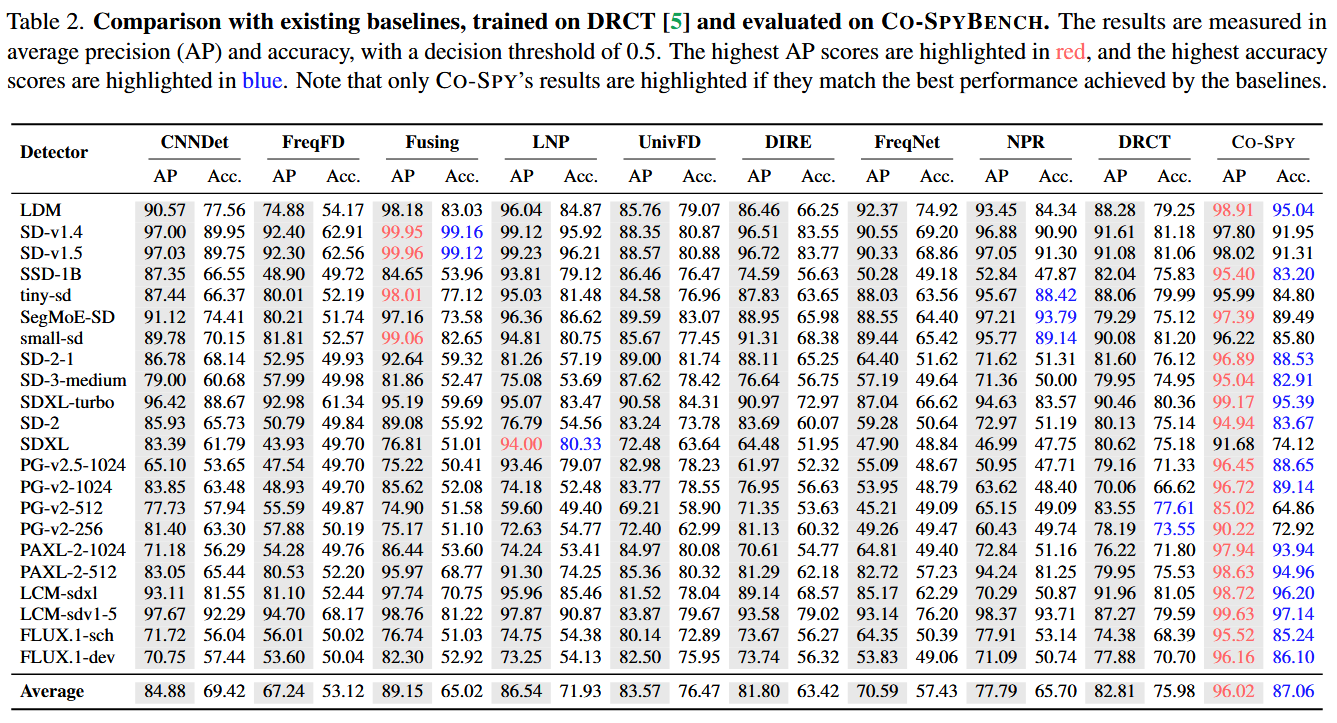
表二展示的是在Co-SPYBENCH测试集上的评估结果。该测试集由研究团队精心构建,包含了22种最先进的生成模型在多种配置下生成的合成图像,旨在全面评估检测器在多样化、受控的生成内容上的性能。
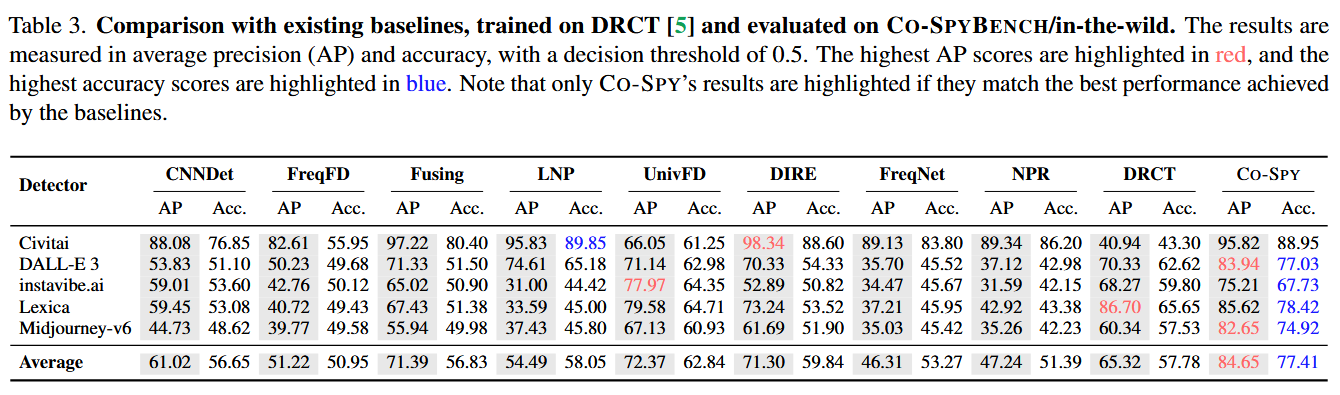
表三展示的是在Co-SPYBENCH/in-the-wild测试集上的评估结果。该测试集由从互联网上收集的真实世界合成图像构成,模拟了检测器在实际部署中可能遇到的、经过用户后处理且来源多样的“野外”图像。
表二侧重于在标准化的、广泛的生成模型上进行评估,而表三侧重于在真实世界的、来自互联网的复杂场景下进行评估。
3.2 鲁棒性
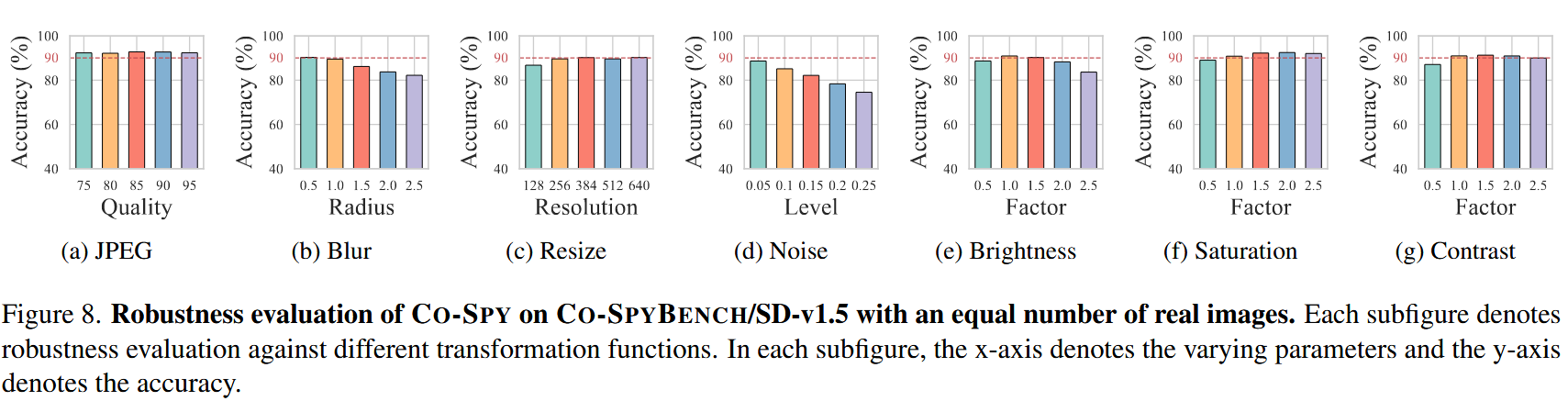
图中包含七个子图,分别对应七种不同的变换函数:JPEG压缩、模糊、调整大小、噪声、亮度、饱和度和对比度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)