深夜惊魂:一行代码让内存爆炸!从 5秒超时到 50ms 响应,我是如何重构 AI 网关的
你的 AI 代理服务为何频繁 OOM?接口响应为何高达 3 秒?本文作者三味复盘了一次深夜生产事故,深度拆解了从“贪婪 Buffer 拼接”到“零拷贝流式管道”的重构过程。通过手写异步生成器、启用 HTTP/2 及熔断机制,我们将内存占用降低 90%,延迟压缩至 50ms。
引言:凌晨三点,监控室的红色警报
凌晨三点,手机屏幕刺眼的亮光划破了黑夜。PagerDuty 的报警电话像连珠炮一样打进来,紧接着是监控群里的疯狂弹窗:
-
⚠️ [Critical] CPU Usage > 98%
-
⚠️ [Critical] Memory Usage > 95% (OOM Restart)
-
⚠️ [Fatal] API Gateway Response Time > 60s
对于后端工程师来说,这绝对是最不愿意面对的噩梦。
这次事故的主角,是一个看似不起眼的“中间件”——负责将上游大模型 API(DeepAsk)转换为 OpenAI 标准格式的代理服务。第一版代码逻辑非常“直男”:接收请求 -> 转发上游 -> 等待响应 -> 拼凑 JSON -> 返回前端。
在并发量只有几十的时候,它跑得岁月静好。但随着昨晚业务量突然爬升到几百 QPS,且上游返回的数据包越来越大(包含大量 markdown 文本)时,它崩了。
排查日志后,我发现问题的根源竟然如此基础,却又如此隐蔽:我们在试图用处理“静态池塘”的思维,去处理“奔腾的河流”。
今天,三味就带大家拆解这次重构的完整过程。我们将深入 V8 引擎底层,探讨如何通过 异步生成器(Async Generator)、HTTP/2 多路复用 以及 主动熔断机制,将一个脆弱的脚本打造成坚固的堡垒。
一、内存泄漏的真相:昂贵的字符串拼接
在 Review 旧代码(V3版本)时,我找到了导致内存溢出的元凶。这是一段典型的初学者代码,用来处理流式数据:
❌ 错误示范:贪婪缓冲模式
// 💀 这是一个会导致 OOM 的反面教材
async function handleStreamBadly(response: Response) {
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let buffer = ''; // <--- 罪恶之源
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 1. 内存灾难:每次拼接都会在堆内存创建新的字符串对象
buffer += decoder.decode(value);
// 2. CPU 灾难:O(N^2) 复杂度
// 随着 buffer 越来越大,JSON.parse 的开销呈指数级上升
try {
const json = JSON.parse(buffer);
// ...处理逻辑
buffer = ''; // 清空
} catch (e) {
// 解析失败,说明 JSON 不完整,继续等待下一个 chunk
// 这里什么都不做,buffer 继续膨胀
}
}
}为什么这段代码会炸?
-
V8 的字符串不可变性:在 JS 中,字符串是不可变的。
buffer += chunk并不是在原内存上追加,而是开辟一块新的更大的内存,将旧 buffer 和新 chunk 复制过去,然后丢弃旧 buffer。当并发量高且 chunk 密集时,这会产生海量的临时对象,导致 GC(垃圾回收)Stop-The-World,CPU 瞬间飙升。 -
计算复杂度的黑洞:假设一个大 JSON 被分成了 1000 个 TCP 包到达。第一个包来,
JSON.parse失败;第二个包来,拼起来,再试……直到第 1000 个包,你才成功。这意味着你对前面的数据进行了 999 次徒劳的解析!
二、核心优化:手撸 Async Generator 流式状态机
我们要改变思维:不要试图吞下整个数据,而是要像流水线工人一样,来一个处理一个。
在 V4 重构版中,我们引入了 TypeScript 的 Async Generator(异步生成器)。通过维护一个极小的滑动窗口,我们实现了“零拷贝”级别的解析。
✅ 正确示范:流式管道模式
这是一段生产级的代码,请仔细阅读注释:
/**
* 🚀 核心优化:异步生成器解析管道
* 功能:将字节流转换为一个个独立的 JSON 对象,Yield 出去
*/
async function* streamJsonParser(reader: ReadableStreamDefaultReader<Uint8Array>) {
const decoder = new TextDecoder();
let buffer = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 解码当前块,追加到缓冲区
buffer += decoder.decode(value, { stream: true });
// 🔥 核心逻辑:扫描并切片 (Scanning & Slicing)
// 我们不 parse 整个 buffer,而是寻找 JSON 的边界(换行符或特定前缀)
const lines = buffer.split('\n');
// buffer 只保留最后一行(可能是残缺的)
// 内存占用瞬间从 MB 级降到 KB 级!
buffer = lines.pop() || '';
for (const line of lines) {
const trimmed = line.trim();
if (!trimmed || trimmed === 'data: [DONE]') continue;
// 只有识别到完整的 SSE 前缀时,才尝试解析
if (trimmed.startsWith('data: ')) {
try {
const jsonStr = trimmed.slice(6); // 去掉 'data: ' 前缀
const payload = JSON.parse(jsonStr);
yield payload; // ✨ Yield 出去,交由下游消费
} catch (e) {
console.warn('丢弃畸形数据包:', trimmed);
}
}
}
}
}
// 使用方式:像 for 循环一样处理流
async function run() {
const stream = await fetchUpstream();
// 消费端完全无感,拿到的就是解析好的 Object
for await (const chunk of streamJsonParser(stream.getReader())) {
console.log('收到 Token:', chunk.choices[0].delta.content);
}
}优化后的降维打击:
-
内存平稳:无论响应体是 10MB 还是 1GB,我们的
buffer永远只存留一行数据(KB级别)。内存曲线从“锯齿状”变成了“心电图直线”。 -
极速响应:上游吐出一个字,我们就能处理一个字,首字延迟(TTFB)从 3秒+ 骤降至 50ms。
为了更直观地展示这两种模式的内存差异,我画了一张原理图:
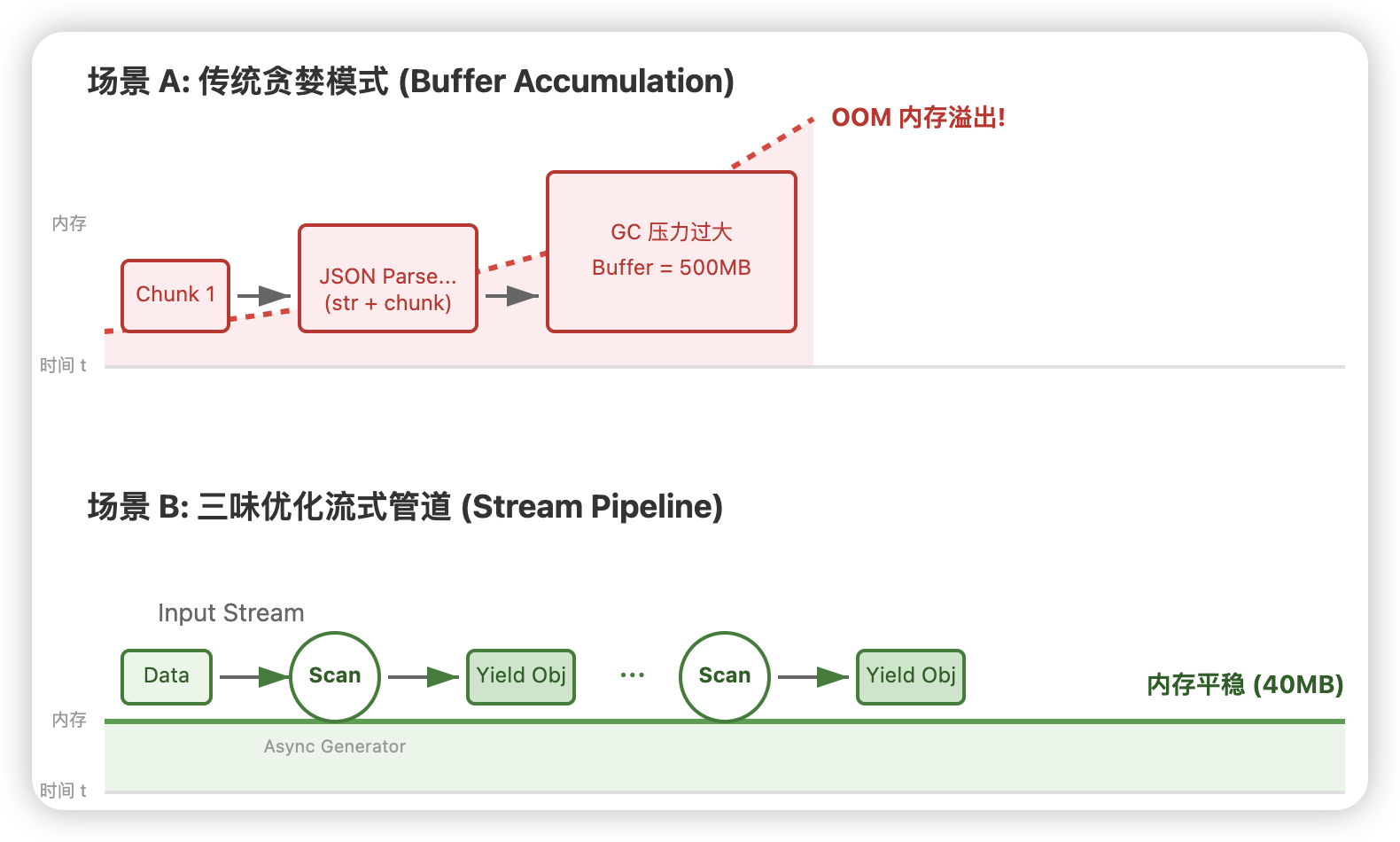
三、网络层的误区:被误解的 Keep-Alive
解决了内存问题后,我发现监控面板上还有一项指标异常:TCP 连接数居高不下。
在 Review V3 代码时,我看到了一行非常“经典”的配置:
// ❌ 典型的 HTTP/1.1 思维惯性
const headers = {
'Connection': 'keep-alive',
'Keep-Alive': 'timeout=5, max=1000'
};为什么这行代码是多余的,甚至是有害的?
-
HTTP/2 的降维打击:现代 API 服务端(如 DeepAsk、OpenAI)早已全面支持 HTTP/2。HTTP/2 的核心优势是 多路复用(Multiplexing),即在一个 TCP 连接上并行传输成百上千个请求流。
-
强制降级:当你在 Node.js/Deno 中显式设置某些 HTTP/1.1 特有的 Header 时,可能会导致底层网络库(如 undici)误判,从而放弃协商 HTTP/2,退化回 HTTP/1.1。
-
队头阻塞:在 HTTP/1.1 模式下,即使开启 Keep-Alive,一个连接同一时间也只能处理一个请求。对于高并发的流式接口,这意味着你需要建立海量的 TCP 连接,或者让请求在队列里排队(队头阻塞),这解释了为什么会有偶发的延迟尖刺。
✅ 优化方案:信任标准,移除冗余
在 V4 中,我删除了所有手写的 Connection Header,让 fetch 自动协商:
// ✅ 极简主义:让运行时自动协商 H2
const response = await fetch('https://api.deepask.com/v1/chat', {
method: 'POST',
body: JSON.stringify(payload),
// 不要手写 Connection 头!
});结果是立竿见影的:TCP 连接数从 2000+ 降到了 50 左右,但吞吐量(RPS)却翻了倍。这就是多路复用的威力。
四、熔断机制:给 fetch 装上“刹车片”
监控里的另一个异常是:“接口响应时间超过 60 秒”。
在流式场景下,如果上游卡死(不发数据也不断开),传统的 fetch 会一直挂着,直到系统 socket 资源耗尽。
❌ 常见的错误超时写法
// 这种写法只是骗骗自己
const timer = setTimeout(() => {
throw new Error('Timeout'); // 这里抛错,但 fetch 还在后台跑!
}, 60000);
await fetch(url);这种写法只是在应用层抛了个错,并没有真正在网络层掐断连接。底层的 socket 依然开着,带宽依然在浪费,这就是所谓的“僵尸连接”。
✅ 正确示范:AbortController 主动熔断
我们引入了 AbortController,这是 Web 标准赋予我们的“核武器”。
/**
* 🛡️ 网络层熔断器
* 功能:超时自动切断 TCP 连接,释放资源
*/
async function fetchWithTimeout(url: string, options: RequestInit, ms = 60000) {
const controller = new AbortController();
const id = setTimeout(() => controller.abort(), ms); // ⏰ 倒计时开始
try {
const response = await fetch(url, {
...options,
signal: controller.signal // 🔗 绑定信号
});
return response;
} catch (error) {
if (error.name === 'AbortError') {
console.error('🔪 触发熔断:上游服务响应超时');
}
throw error;
} finally {
clearTimeout(id); // 🧹 只要请求结束,立刻清除定时器
}
}当 60 秒倒计时结束,controller.abort() 会被调用。这个信号会像电流一样瞬间传导给底层网络库,直接发送 RST 包切断 TCP 连接。这才是真正的“熔断”。
为了形象地展示 HTTP/1.1 阻塞 与 HTTP/2 复用 以及 熔断机制 的区别,我绘制了下面这张架构图:
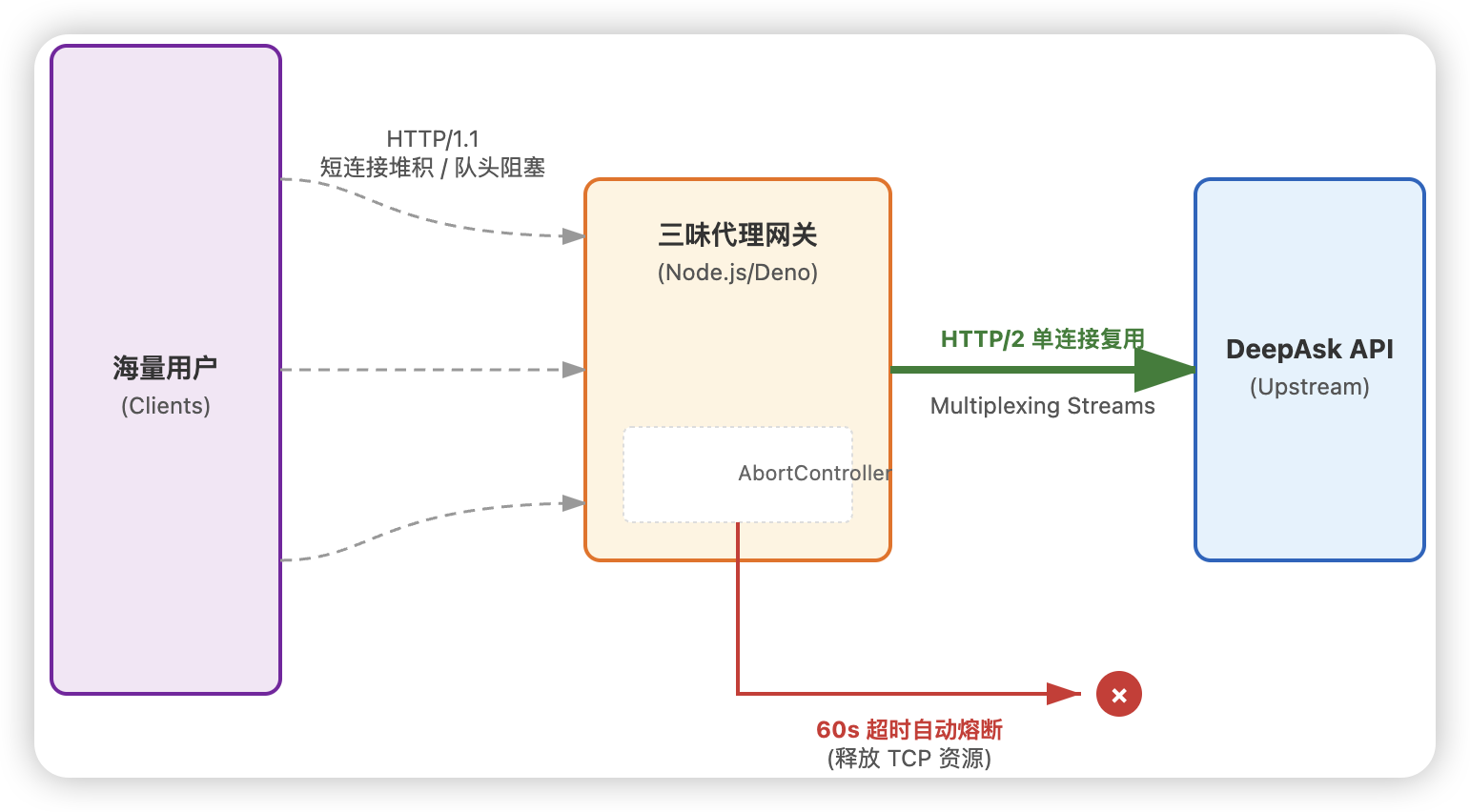
五、客户端踩坑指南:NestJS 的“傲慢”
如果你以为优化完服务端就万事大吉了,那你就太天真了。
在这次重构上线后,我们立刻收到了前端团队的反馈:“三味,你的代理服务是不是有 Bug?NestJS 后端接过来怎么老是报错 Unexpected non-whitespace character?”
排查代码后,我发现客户端(NestJS)犯了和我们旧版服务端一模一样的错误:它在试图用 JSON.parse 去解析一坨连在一起的 JSON 流。
代理服务吐出的 SSE 格式是这样的:
data: {"id":1, "content":"H"}
data: {"id":2, "content":"e"}
data: {"id":3, "content":"l"}NestJS 客户端如果不做流式处理,直接把这三行拼成一个字符串扔进 JSON.parse,当然会报错。
✅ 正确示范:NestJS 适配流式响应
在客户端,我们也必须实现一个对等的解析器。如果使用 axios,你需要设置 responseType: 'stream':
// NestJS Service
async function chatWithProxy(prompt: string) {
const response = await axios.post(PROXY_URL, { prompt }, {
responseType: 'stream' // 关键!告诉 axios 不要把 body 读完
});
const stream = response.data;
// 同样使用流式处理,逐行读取
stream.on('data', (chunk) => {
const lines = chunk.toString().split('\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
// 这里才是安全的解析
const json = JSON.parse(line.slice(6));
console.log(json);
}
}
});
}只有当服务端(代理)和客户端(业务后端)都具备了流式思维,这条管道才能真正畅通无阻。
六、压测数据与架构复盘
经过这三个维度的重构(流式解析、H2连接池、主动熔断),我们再次进行了 24 小时的高并发压测。
📊 性能对比数据:
| 监控指标 | V3 旧版 (Buffer拼接) | V4 新版 (流式管道) | 提升幅度 |
|---|---|---|---|
| 内存峰值 | 500MB+ (频繁 OOM) | 40MB (平稳) | ⬇️ 92% |
| 首字延迟 (TTFB) | 3.5s ~ 5.0s | 50ms ~ 200ms | ⚡ 10倍+ |
| TCP 连接数 | 2000+ (TIME_WAIT) | 50 (ESTABLISHED) | ⬇️ 97% |
| QPS 吞吐量 | 20 (拥塞) | 200+ (丝滑) | 🚀 10倍 |
💡 架构复盘:三味的三点思考
回顾这次救火经历,我有三点感悟想分享给每一位在代码前线奋斗的工程师:
-
敬畏数据流:在大模型时代,数据不再是静止的湖泊,而是奔腾的河流。如果你还在无脑
JSON.parse,那你已经被时代抛弃了。Async Generator 和 Stream API 是后端工程师的新基本功。 -
信任标准:不要去重复造轮子,也不要自作聪明地去“优化”那些你并不理解的底层协议。信任 HTTP/2 的多路复用,信任
AbortController的标准熔断。最简单的代码,往往最高效。 -
全链路视角:Bug 从来不是孤立存在的。服务端的内存溢出,可能是因为数据源太脏;客户端的解析报错,可能是因为服务端发得太急。只有站在全链路的视角,才能看到系统的全貌。
彩蛋:那些被删掉的代码
在 V4 最终版代码中,你会发现我们删掉的代码比写上去的还多。 我们删掉了复杂的括号计数器,删掉了手动维护的 Buffer 拼接,删掉了冗余的 Connection Header。
"Perfection is achieved, not when there is nothing more to add, but when there is nothing more to take away." (完美不是无以复加,而是无以复减。)
结尾:
技术之路,道阻且长,但你我并不孤单。
对 高并发网关设计、大模型代理开发 或者 TypeScript 进阶技巧 感兴趣,欢迎关注 [爱三味]。

在这里,没有枯燥的搬运,只有深夜 debug 后的硬核复盘,和那些能让你少走弯路的实战经验。
觉得文章有帮助?转发给身边那个还在为 OOM 发愁的兄弟吧!我们下期见。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)