LangGraph 入门实战:用图结构解锁LLM的复杂工作流
摘要: LangGraph是LangChain生态下的扩展库,采用图结构编排复杂LLM工作流,支持多步骤推理、分支和循环等场景。其核心组件包括节点(执行单元)、边(流向控制)和状态(全局数据)。本文通过构建多步骤问答应用(提问→生成→校验→完善)的代码示例,演示了如何定义节点逻辑、配置条件边及运行工作流。进阶技巧涵盖并行节点(多智能体协作)和持久化调试功能。LangGraph适用于代码生成、智能助
在大语言模型(LLM)应用开发中,简单的“输入-输出”模式早已无法满足复杂场景需求——比如多步骤推理、多智能体协作、条件分支执行、循环校验等。LangGraph 作为 LangChain 生态下的核心扩展库,以“图结构”为核心,将LLM的调用、工具调用、逻辑判断等操作抽象为“节点”和“边”,让复杂工作流的编排、运行和调试变得简洁高效。
本文将从 LangGraph 的核心概念出发,结合具体代码示例,手把手教你搭建第一个 LangGraph 应用,理解其工作原理,并延伸到简单的实战场景,帮助你快速上手这一强大工具。
一、LangGraph 核心概念速览
LangGraph 的核心设计灵感来自“有向图”,所有操作都围绕以下3个核心组件展开,理解它们就能掌握 LangGraph 的本质:
-
节点(Node):图中的最小执行单元,可对应任意操作——LLM 生成、工具调用、数据处理、逻辑判断等。每个节点接收“上下文(State)”作为输入,执行操作后返回新的上下文。
-
边(Edge):定义节点之间的执行流向,分为“确定性边”(固定从A节点到B节点)和“条件边”(根据节点输出的上下文,动态判断流向哪个节点)。
-
状态(State):贯穿整个图运行的“全局数据容器”,存储所有节点的输入、输出和中间结果(如用户问题、LLM 回答、工具返回值等),所有节点通过读写状态实现协作。
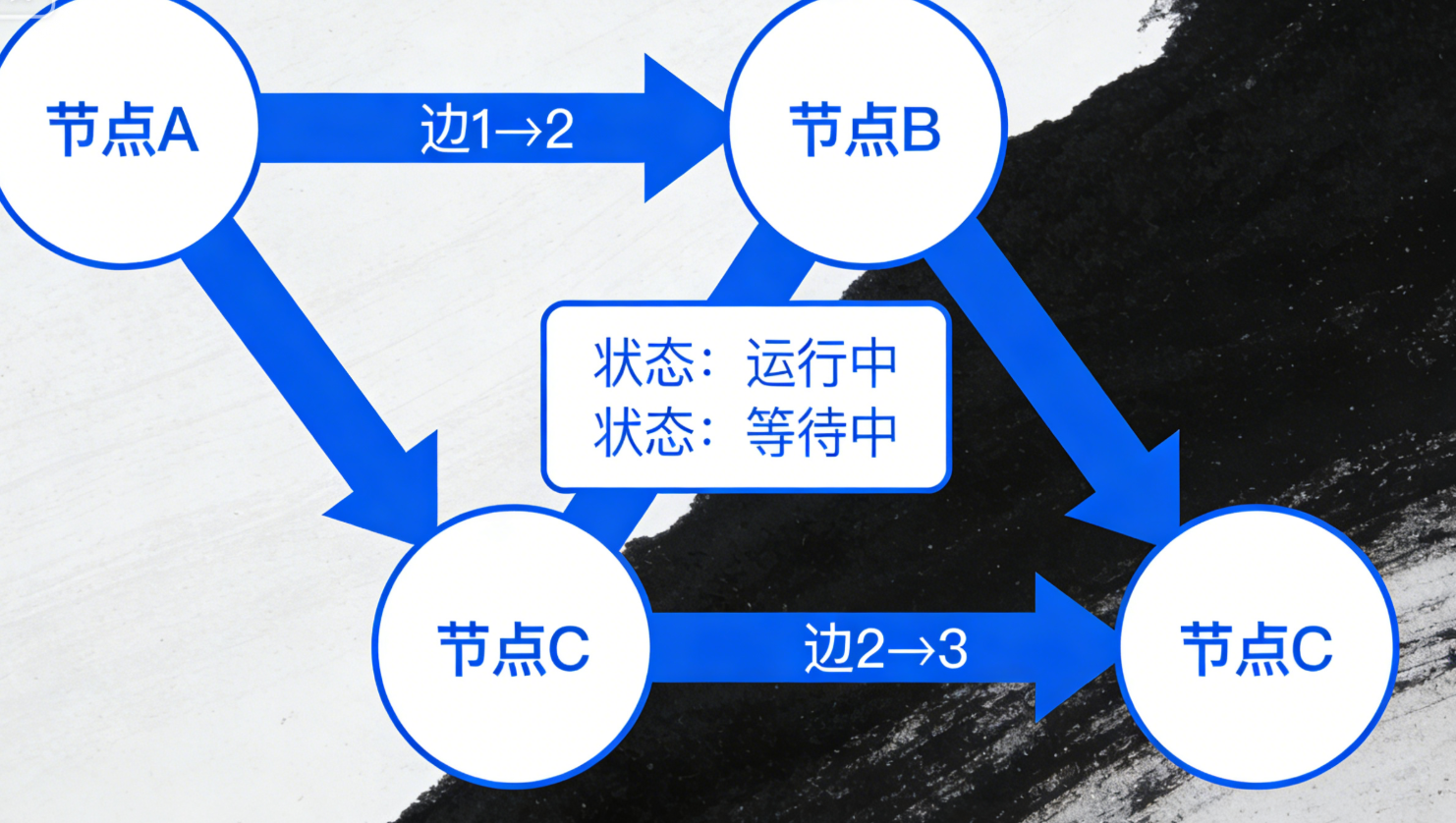
与传统的线性工作流相比,LangGraph 的优势在于:支持循环(如多轮校验)、分支(如根据问题类型切换处理逻辑)、并行(如多智能体同时工作),且可追溯、可调试,非常适合构建复杂的LLM应用(如智能助手、代码生成器、推理引擎等)。
二、环境准备:安装依赖库
在编写代码前,需先安装 LangGraph 及相关依赖(LangChain 用于调用LLM,这里以 OpenAI 模型为例,也可替换为本地模型)。
# 安装核心依赖
pip install langgraph langchain openai python-dotenv
# 可选:若需使用其他工具(如搜索、数据库),安装对应依赖
# pip install langchain-community注意:需要准备 OpenAI API Key(可在 OpenAI 官网申请),并通过 .env 文件管理,避免硬编码。
三、基础实战:搭建第一个 LangGraph(多步骤问答)
我们先搭建一个简单但完整的 LangGraph 应用:实现“用户提问 → LLM 初步回答 → 校验回答完整性 → 完善回答(若不完整)→ 返回最终结果”的工作流。
这个工作流包含4个节点,1条条件边和2条确定性边,清晰体现 LangGraph 的分支和循环能力。
3.1 完整代码实现
from dotenv import load_dotenv
from langgraph.graph import Graph, StateGraph, END
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Dict, Any
# 1. 加载环境变量(读取OpenAI API Key)
load_dotenv()
# 2. 定义全局状态(State):存储所有中间结果
# 用Pydantic模型定义State,结构更清晰,支持类型校验
class QAState(BaseModel):
question: str = Field(description="用户的原始问题")
initial_answer: str = Field(default="", description="LLM的初步回答")
is_complete: bool = Field(default=False, description="回答是否完整的标记")
final_answer: str = Field(default="", description="最终完善后的回答")
# 3. 初始化LLM(这里使用OpenAI的gpt-3.5-turbo,可替换为其他模型)
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.7)
# 4. 定义各个节点(Node)的执行逻辑
# 节点1:接收用户问题(初始化状态)
def init_state(state: QAState) -> Dict[str, Any]:
"""初始化状态,将用户问题存入State"""
return {"question": state.question, "initial_answer": "", "is_complete": False}
# 节点2:LLM生成初步回答
def generate_initial_answer(state: QAState) -> Dict[str, Any]:
"""根据用户问题,生成初步回答"""
prompt = f"请回答用户的问题,简洁明了,无需展开:{state.question}"
response = llm.invoke(prompt)
return {"initial_answer": response.content}
# 节点3:校验回答完整性(条件判断节点)
def check_answer_complete(state: QAState) -> str:
"""校验初步回答是否完整,返回下一步节点的名称"""
# 简单校验逻辑:判断回答长度是否大于50字符,或是否包含关键信息(可自定义复杂逻辑)
prompt = f"""
请判断以下回答是否完整回答了用户的问题,只需返回"完整"或"不完整":
用户问题:{state.question}
初步回答:{state.initial_answer}
"""
check_result = llm.invoke(prompt).content.strip()
if check_result == "完整":
state.is_complete = True
return "complete_node" # 流向“生成最终回答”节点
else:
state.is_complete = False
return "improve_node" # 流向“完善回答”节点
# 节点4:完善回答(循环节点)
def improve_answer(state: QAState) -> Dict[str, Any]:
"""如果回答不完整,基于初步回答进行完善"""
prompt = f"""
你的初步回答不够完整,请结合用户问题,补充关键信息,完善回答:
用户问题:{state.question}
初步回答:{state.initial_answer}
完善要求:逻辑清晰,信息全面,不冗余
"""
improved_response = llm.invoke(prompt)
return {"initial_answer": improved_response.content} # 覆盖初步回答,用于再次校验
# 节点5:生成最终回答
def generate_final_answer(state: QAState) -> Dict[str, Any]:
"""将完整的回答整理为最终格式,存入State"""
final_prompt = f"""
请将以下回答整理为最终版本,语气友好,格式规范:
用户问题:{state.question}
完整回答:{state.initial_answer}
"""
final_response = llm.invoke(final_prompt)
return {"final_answer": final_response.content}
# 5. 构建LangGraph(StateGraph)
# 初始化图,指定State类型
graph_builder = StateGraph(QAState)
# 向图中添加所有节点(参数:节点名称,节点执行函数)
graph_builder.add_node("init", init_state)
graph_builder.add_node("generate_initial", generate_initial_answer)
graph_builder.add_node("check_complete", check_answer_complete)
graph_builder.add_node("improve", improve_answer)
graph_builder.add_node("complete", generate_final_answer)
# 6. 定义节点之间的边(流向)
# 确定性边:从init节点 → generate_initial节点(固定流向)
graph_builder.add_edge("init", "generate_initial")
# 确定性边:从generate_initial节点 → check_complete节点(固定流向)
graph_builder.add_edge("generate_initial", "check_complete")
# 条件边:从check_complete节点出发,根据返回值流向不同节点
graph_builder.add_conditional_edges(
source="check_complete", # 源节点
# 条件函数:接收源节点的输出(这里是check_answer_complete的返回值),返回目标节点名称
path_selector=lambda x: x,
# 映射关系:源节点输出 → 目标节点
path_map={
"improve_node": "improve", # 输出"improve_node" → 流向improve节点
"complete_node": "complete" # 输出"complete_node" → 流向complete节点
}
)
# 确定性边:improve节点 → check_complete节点(循环校验,直到回答完整)
graph_builder.add_edge("improve", "check_complete")
# 确定性边:complete节点 → 结束节点(END是LangGraph内置的结束标记)
graph_builder.add_edge("complete", END)
# 7. 设置图的入口节点(起始点)
graph_builder.set_entry_point("init")
# 8. 编译图(生成可运行的图实例)
graph = graph_builder.compile()
# 9. 运行图,传入初始状态(用户问题)
if __name__ == "__main__":
# 初始状态:仅传入用户问题
initial_state = QAState(question="请详细说明LangGraph和LangChain的区别与联系")
# 运行图(stream_mode="values"表示返回每一步的状态,便于调试)
for step, state in enumerate(graph.stream(initial_state, stream_mode="values")):
print(f"\n=== 步骤 {step + 1} ===")
print(f"当前节点:{graph.get_current_node()}")
print(f"用户问题:{state.question}")
print(f"初步回答:{state.initial_answer}")
print(f"回答是否完整:{state.is_complete}")
print(f"最终回答:{state.final_answer}")
# 输出最终结果
final_result = graph.invoke(initial_state)
print("\n=== 最终结果 ===")
print(f"用户问题:{final_result.question}")
print(f"最终回答:{final_result.final_answer}")3.2 代码解析
以上代码实现了一个完整的“提问-生成-校验-完善”闭环工作流,关键细节解析如下:
-
State 定义:用 Pydantic 模型 QAState 定义全局状态,明确存储用户问题、初步回答、完整性标记、最终回答,确保数据结构清晰,便于节点之间的读写。
-
节点逻辑:每个节点都是一个函数,接收 State 作为输入,返回修改后的 State 片段(字典格式),LangGraph 会自动合并这些片段,更新全局状态。
-
边的配置:
-
确定性边(add_edge):固定流向,比如“初始化 → 生成初步回答”“完善回答 → 重新校验”。
-
条件边(add_conditional_edges):动态流向,由校验节点的输出决定,实现“完整则结束,不完整则完善”的分支逻辑。
-
-
运行方式:
-
stream 方法:流式返回每一步的状态,便于调试,查看每个节点的执行结果。
-
invoke 方法:直接返回最终状态,适合实际部署时使用。
-
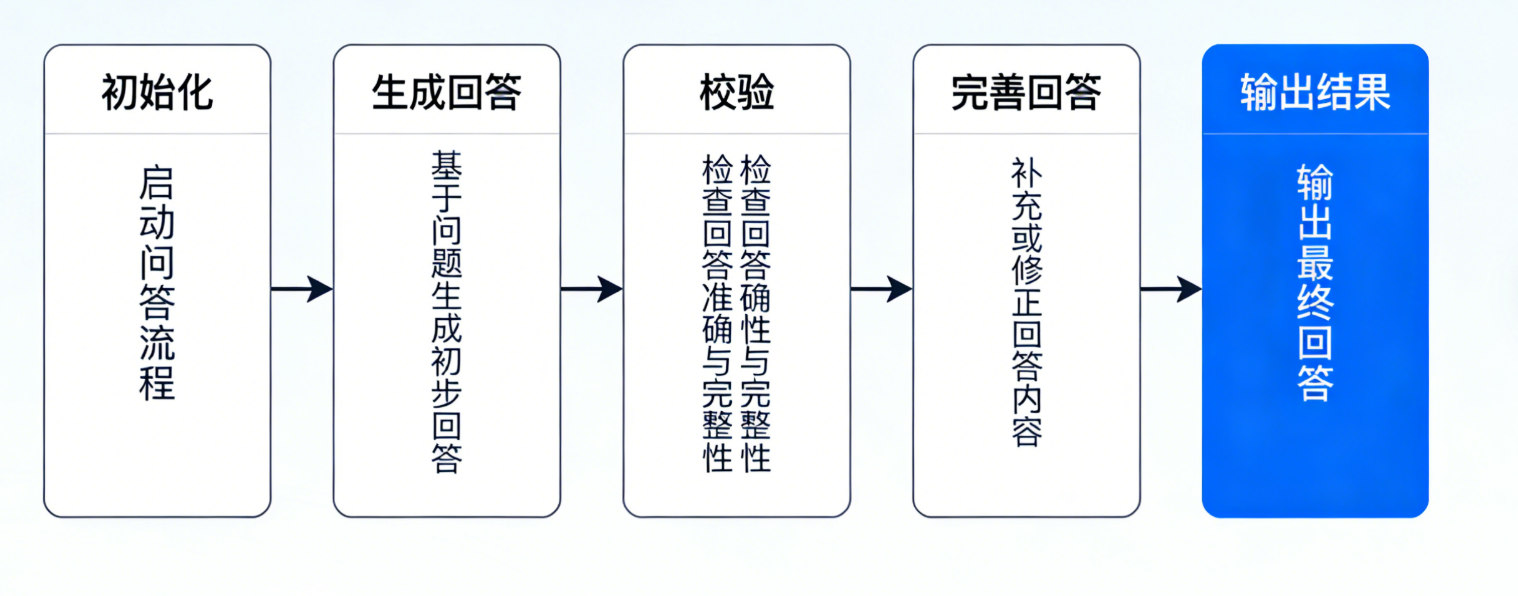
3.3 运行效果示例
当传入用户问题“请详细说明LangGraph和LangChain的区别与联系”时,运行流程如下:
-
步骤1:init节点初始化状态,存入用户问题。
-
步骤2:generate_initial节点生成初步回答(可能较为简洁,不够全面)。
-
步骤3:check_complete节点校验,判断初步回答不完整,流向improve节点。
-
步骤4:improve节点完善回答,补充更多细节。
-
步骤5:check_complete节点再次校验,判断回答完整,流向complete节点。
-
步骤6:complete节点整理最终回答,流向END,运行结束。
最终会输出整理后的完整回答,实现“自动校验、循环完善”的效果,无需人工干预。
四、进阶技巧:LangGraph 的核心特性扩展
除了基础的分支和循环,LangGraph 还有很多实用特性,结合代码片段简单介绍,帮助你应对更复杂的场景。
4.1 并行节点(多智能体协作)
LangGraph 支持多个节点并行执行(如多智能体同时处理不同任务),只需使用 add_parallel_edges 方法,示例如下:
from langgraph.graph import StateGraph
# 定义两个并行执行的节点(比如两个不同的智能体)
def agent1(state: QAState) -> Dict[str, Any]:
"""智能体1:补充理论相关内容"""
prompt = f"补充LangGraph的理论基础:{state.initial_answer}"
return {"initial_answer": state.initial_answer + "\n" + llm.invoke(prompt).content}
def agent2(state: QAState) -> Dict[str, Any]:
"""智能体2:补充实战相关内容"""
prompt = f"补充LangGraph的实战案例:{state.initial_answer}"
return {"initial_answer": state.initial_answer + "\n" + llm.invoke(prompt).content}
# 构建图时,添加并行边
graph_builder.add_parallel_edges(
source="generate_initial", # 源节点
destinations=["agent1", "agent2"], # 并行的目标节点
then="check_complete" # 并行节点执行完毕后,统一流向的节点
)上述代码中,agent1 和 agent2 会并行执行,分别补充理论和实战内容,执行完毕后共同流向 check_complete 节点,提升效率。
4.2 持久化与调试
LangGraph 支持将图的结构和运行状态持久化,同时提供可视化调试工具,便于排查问题:
# 1. 可视化图结构(生成PNG文件)
graph.draw("qa_graph.png") # 需要安装graphviz:pip install graphviz
# 2. 持久化图的运行状态(使用LangChain的持久化工具)
from langchain.storage import LocalFileStore
from langgraph.checkpoint.memory import MemorySaver
# 初始化内存持久化器(可替换为本地文件、数据库等)
memory = MemorySaver()
# 编译图时指定持久化器
graph = graph_builder.compile(checkpointer=memory)
# 运行图时,指定会话ID,可恢复会话状态
session_id = "user_123"
final_state = graph.invoke(initial_state, config={"configurable": {"session_id": session_id}})
# 恢复会话状态(比如用户中断后,继续之前的工作流)
restored_state = graph.get_state(config={"configurable": {"session_id": session_id}})五、实战场景延伸
LangGraph 的应用场景非常广泛,除了上述的多步骤问答,还可用于:
-
代码生成与调试:节点1(生成代码)→ 节点2(运行代码校验)→ 节点3(调试错误)→ 节点4(生成最终代码),循环直至代码可运行。
-
智能助手:节点1(意图识别)→ 节点2(根据意图选择工具:搜索/数据库/LLM)→ 节点3(执行工具)→ 节点4(整理回复)。
-
多文档总结:节点1(拆分文档)→ 节点2(并行总结单篇文档)→ 节点3(合并总结)→ 节点4(校验完整性)。
六、总结
LangGraph 以“图结构”为核心,打破了LLM应用的线性限制,让复杂工作流的编排变得直观、灵活。其核心价值在于:将分散的操作(LLM调用、工具调用、逻辑判断)抽象为节点,通过边定义流向,实现分支、循环、并行等复杂逻辑,同时借助 State 管理全局数据,让多节点协作变得简单。

本文通过基础实战代码,帮助你掌握了 LangGraph 的核心用法,后续可结合具体场景,扩展节点逻辑、优化状态管理,解锁更多复杂LLM应用的可能性。建议多尝试修改代码(如替换LLM模型、调整校验逻辑、添加并行节点),快速熟悉其特性,将其应用到实际开发中。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 34
34 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)