基于语义增强与规则引导的弱监督视频异常检测方法
本文提出SAGE-VAD视频异常检测框架,通过语义增强与规则引导解决弱监督学习中的关键问题。创新性地设计混合提示集成(HPE)机制,融合人工模板与大模型描述构建鲁棒类别原型;引入帧级规则分数(TeacherScore)作为先验,优化关键帧筛选。在UCF-Crime和XD-Violence数据集上分别取得87.47% AUC和85.08% AP,显著优于基线方法。消融实验验证了各模块协同增强的有效性
导读:
视频异常检测(Video Anomaly Detection, VAD)旨在从长时间监控视频中自动识别异常事件,是智能安防与智能交通等场景中的关键技术。受限于异常事件的稀有性与标注成本,现有方法多采用弱监督学习范式,但仍普遍面临异常语义表达不足、跨模态对齐失效以及标签噪声导致训练不稳定等问题。针对上述挑战,本文提出基于语义增强与规则引导的SAGE-VAD (Semantic-Augmented & Guided Enhancement for VAD)框架。设计混合提示集成(Hybrid Prompt Ensemble, HPE)机制,融合人工模板与大模型描述,构建高覆盖度的类别原型。并引入帧级规则分数(Teacher Score)作为先验,通过一致性约束抑制噪声激活并优化关键帧筛选。实验结果表明,本文方法在UCF-Crime和XD-Violence数据集上均取得了显著性能提升。其中,在UCF-Crime数据集上,本文法的视频级AUC达到87.47%,在XD-Violence数据集上,视频级AP提升至85.08%,验证了语义增强与规则引导机制在弱监督异常检测任务中的有效性。
作者:
王津秋渝, 宋春林:同济大学电子与信息工程学院信息与通信工程系,上海;徐旭辉:同济大学海洋地质国家重点实验室,上海
论文详情
本文提出一种融合语义增强与规则引导的弱监督视频异常检测框架,通过显式建模异常行为的多维语义结构并引入训练与推理阶段的规则一致性约束,在仅依赖视频级监督的条件下提升检测的稳定性与鲁棒性。
基于语义增强与规则引导的视频异常检测框架
图1为SAGE-VAD的网络结构框架示意图。
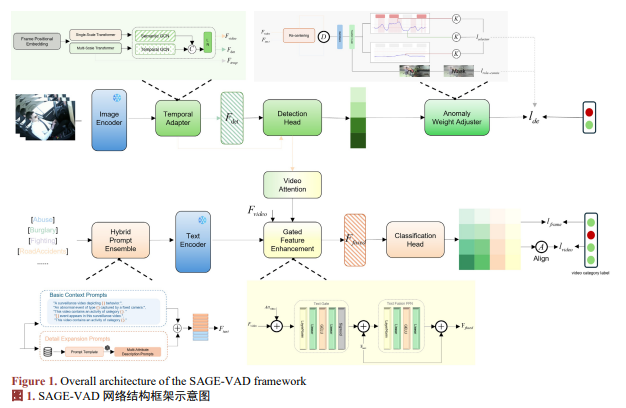
本文通过在文本语义建模、跨模态融合机制以及规则知识引导三个层面进行协同设计,系统性地缓解了CLIP在弱监督场景下面临的语义不足、对齐失效与鲁棒性较差等问题,显著提升了模型在复杂监控场景下的异常识别性能与语义泛化能力。
基于多维异常语义提示的语义增强算法
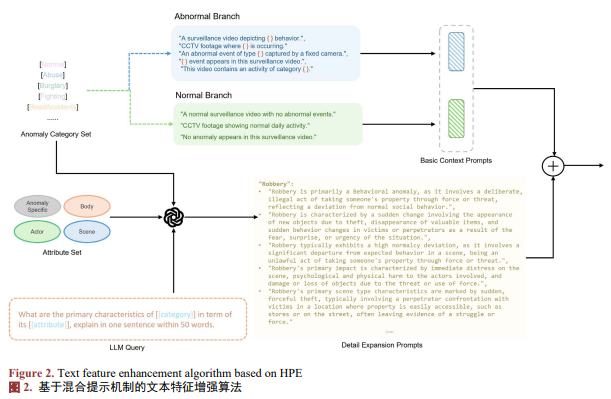
本文提出Hybrid Prompt Ensemble (HPE),如图2,通过结合人工设计模板与大语言模型生成的多样化语义描述,构建更鲁棒的类别文本。
基于规则引导的异常帧选择算法
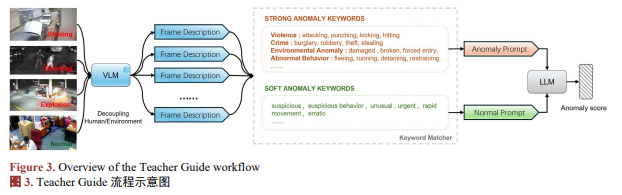
本文中新提出的Anomaly Weight Adjuster首先引入了Teacher Score引导,通过对每一帧的Teacher Score进行调整,来加权和选择最相关的帧。Teacher Score由规则系统生成,如图3所示。
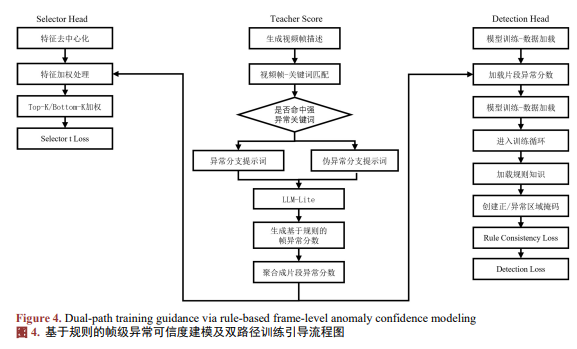
与直接使用规则结果进行硬判决不同,Teacher Score仅作为软可信信号,用于引导模型的帧级语义选择过程,详见图4。
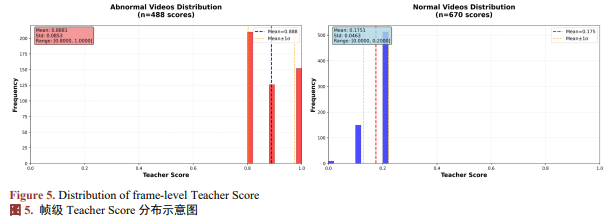
本文对正常视频与异常视频中生成的Teacher Score进行了分析。如图5所示,在正常视频中,大多数帧的Teacher Score集中分布于较低区间,表明规则系统倾向于对正常行为给出较低的异常可信度;而在异常视频中,Teacher Score则显著集中于高分区间,呈现出良好的分布可分性。这一现象表明,基于规则与语义提示构建的分数能够在统计层面有效刻画帧级异常可信度,为模型提供稳定且可靠的先验信息。
规则一致性引导的帧级检测约束、帧级可信度与关键帧选择优化算法等详见原文链接。
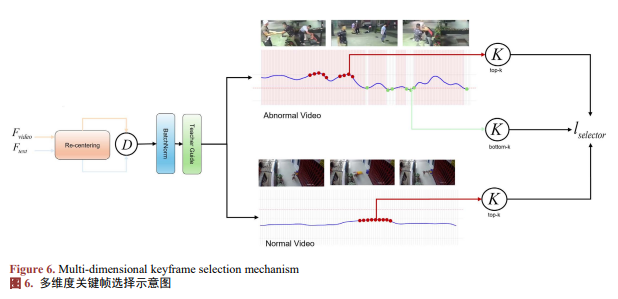
与其他研究仅依赖异常帧的Top-K选择不同,Anomaly Weight Adjuster提出了更精细的Top-K/Bottom-K选择,具体流程见图6。其核心是在帧级语义空间中显式建模异常相关性与样本可信度,并据此进行分层筛选。
实验与分析
用于验证本文方法有效性的实验均在公开视频异常检测数据集上进行,主要包括UCF-Crime与XD-Violence两个具有代表性的真实世界监控视频数据集。所有实验均在统一的训练配置与评测流程下完成,以确保结果的公平性与可复现性。
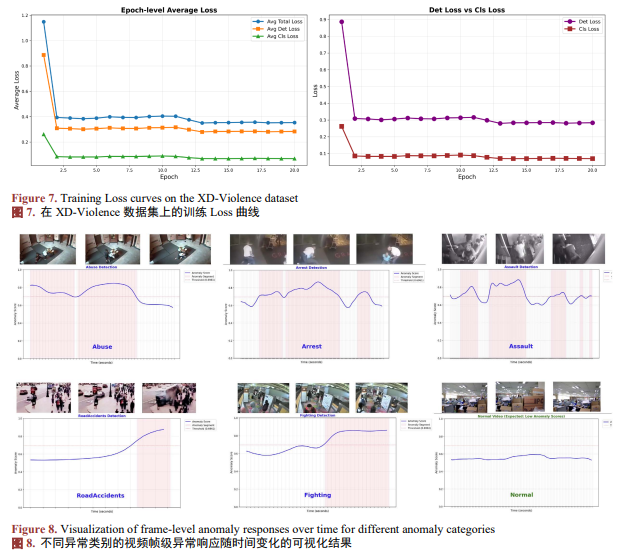
表1展示了SAGE-VAD与现有代表性方法在UCF-Crime和XD-Violence数据集上的性能对比,图7,图8分别是模型在训练以及测试过程中的可视化结果。通过表1可以发现传统的半监督方法(如GODS、GCL)由于依赖额外标注或特征,其整体性能明显受限。零样本方法在一定程度上受益于视觉语言模型的语义泛化能力,但在复杂场景下仍存在性能瓶颈。在弱监督的设置下,基于CLIP的方法整体优于传统3D CNN特征方法,验证了跨模态语义建模在视频异常检测中的有效性。在此基础上,SAGE-VAD在UCF-Crime上取得了87.75% ± 0.04%的AUC,在XD-Violence上达到了85.08% ± 0.11%的AP,相比于大多数弱监督方法有较为客观的增益,展示出语义增强与规则引导的优势。
从表2中可以看到,仅使用人工模板时,模型在AUC上能够取得86.07%,但在mAP@IoU指标上整体表现较弱,平均值仅为4.38%。这表明人工模板虽然能够提供稳定、结构化的类别语义,但是特征表达方式比较单一,难以覆盖异常行为在时序演化和细粒度表现上的多样性,因而对异常片段的精确定位能力有限。
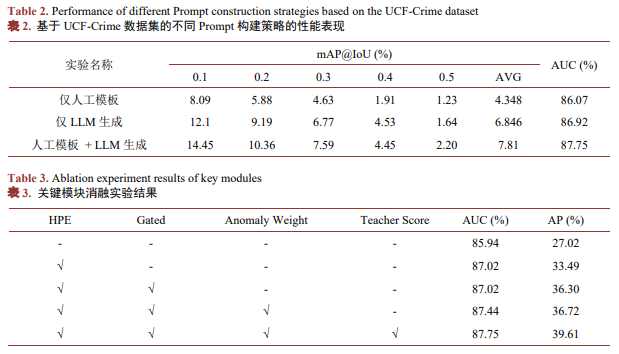
为了系统性地验证本文所提出的所有关键模块的有效性,本文在UCF-Crime数据集上展开了消融实验,实验结果如表3所示。
表3给出了在逐步引入不同模块配置下模型性能的变化情况,其中包括Hybrid Prompt Ensemble、Anomaly Weight Adjuster以及Teacher Score引导机制。首先在未引入任何增强模块的设置上,模型依赖基于CLIP特征提取的弱监督视频级标签进行训练其AUC为85.94%,而AP仅为27.02%。这一结果表明,传统MIL框架在帧级异常定位于排序方面的优势有限,容易受到噪声标签的影响。
结论
综合上述实验结果可以看出,SAGE-VAD在整体性能、文本语义建模、关键帧选择以及规则引导稳定性等多个维度均展现出一致优势。大量实验结果也可以进一步表明SAGE-VAD在AUC、AP及mAP@IoU等指标上皆取得了较大幅度的增长,验证了本文方法在复杂监控场景下的有效性与泛化能力。模型在UCF-Crime与XD-Violence等公开基准数据集上分别取得了AUC为87.75%以及AP为85.08%,相比Baseline模型性能有了显著的优化。后续的消融实验分析可以进一步表明,各模块并非简单叠加,而是在语义建模、跨模态对齐与弱监督约束层面形成了协同增强关系,从而有效提升了模型在复杂监控场景下的异常检测与定位能力。
基金项目:
上海市科委2024创新行动计划项目资助,项目编号:24511103302。
原文链接:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)