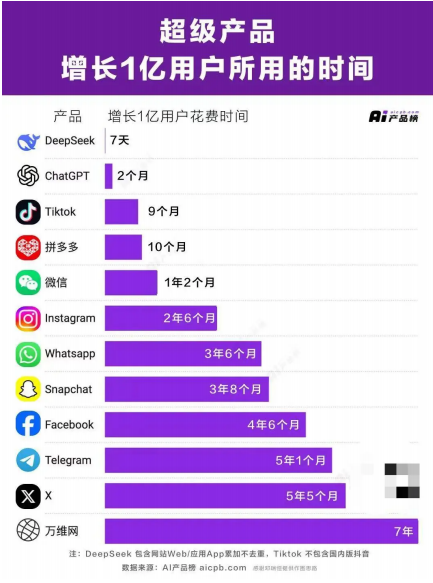
DeepSeek大模型+
到2026 年, Gartner 预测 超过 80% 的企业 将使用生成式 AI 的 API 或模型,或在生产环境中部署支持生成式 AI 的应用,而在 2023 年初这一比例 不到 5%。来源:《 Gartner 2024 10 大科技趋势 》问题1:第四次工业革命。

探索智能新世界
-Deepseek的人工智能之旅
本次分享主要介绍大型语言模型DeepSeek的基本原理和应用,并结合实际案例介绍智能问答、图像生成、视频生成、Xmind、PPT生成、流程图制作等内容。
通过智能工具赋予个人和企业权力,开启内容创作的新篇章,帮助用户高效地完成创作和交流。无论你是技术爱好者、内容创作者还是业务经理,你都可以从中获得灵感和实用价值。
1.完成一个调研报告/教学大纲/论文/纵向项目申请书。
2.完成基本功能,如生成图表、视频、office,搭建本地环境。
3.用自然语言开发一个学校招生的问答助手,并发布上线。
4.构造智能体:天气预报(插件)、学生选课咨询(工作流)并发布到微信公众号。
5.解答一些问题:原理、安全、去重。
1.DeepSeek介绍
到2026 年, Gartner 预测 超过 80% 的企业 将使用生成式 AI 的 API 或模型,或在生产环境中部署支持生成式 AI 的应用,而在 2023 年初这一比例 不到 5% 。
来源:《 Gartner 2024 10 大科技趋势 》
- 问题1:第四次工业革命
决策式AI-识别是猫是狗,生成式AI根据特征生成新的猫狗
2016年之前:决策式AI如推荐系统、图像识别、内容审核
2016-2021:决策式AI大规模应用,电商、娱乐、人脸识别、自动驾驶、情感分析
2021年之后生成式AI趋于成熟
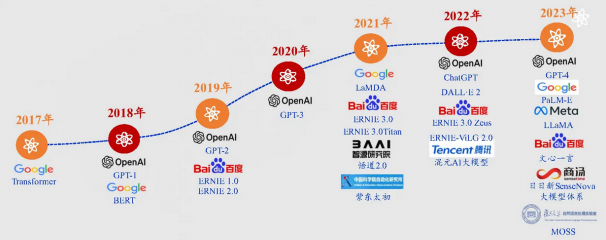
- 问题2:时代的导火索
- 模型:通用性、创造性、多模态、时效性、伦理安全
- 算力:GRPO算法将训练成本降低70%(3000块A100),NVIDIA股价暴跌17%(590B=2COCO,sora)
- 数据:高质量(知识蒸馏:钓鱼)、高时效性(博查API)、专业(专家模型+人工审核)
- 需求:DeepSeek核心竞争力(开源即生态)
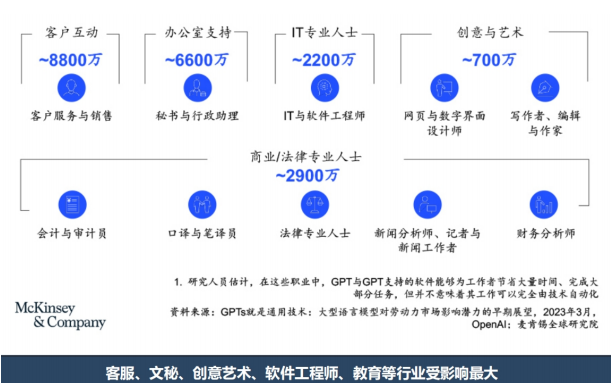
- 问题3:R1模型训练的主要阶段:
S1冷启动阶段:人工标注及格式化,长思维链(few short prompting)
S2面向推论的强化学习RL:引入语言一致性的奖励机制(Language consistency reward)
S3拒绝采样与监督微调SFT:加入新生成的高质量SFT数据( Self-training Fine-tuning )
S4面向全场景的强化学习:第二阶段强化学习训练,数学、代码、逻辑基于规则奖励,开放、创意基于模型的奖励。

- 问题4:DeepSeek应该注意的问题?
- 资源浪费:满血版200万250万或25万30万(32B)
- AI幻觉:中外AI下棋事件
- 数据安全:数据上传到服务器有可能导致数据泄露,但不会因为模型的原因全网展示ChatGPT的明确说会将数据用于训练,不过他们也允许用户禁止自己的数据用于训练
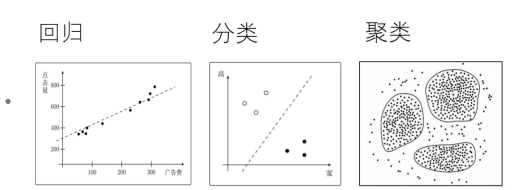
- 问题5:常见的技术与核心模块介绍?
- 回归Regression: 它试图找出输入变量和输出变量之间的关系,可以用来预测连续数值 。
- 聚类Clustering:无监督学习,将结果产生一组集合。
- 分类Classification:有监督学习,通过分析输入数据的特征 ,将其分配到两个或多个预定义的类别中。
- 预测Prediction :使用模型预测新数据点的结果 Prediction = Regression+/Classification
- 识别Recognition : 意味着你能认识目标,最终得到的结果是类别。
- 检测 Detection : 意味着你能看到目标,识别并且定位目标 。
- 分割Segmentation:像素级别的Classification。

- 注意力机制 Attention Mechanism :允许模型动态调整对输入数据不同部分的关注权重的机制 。
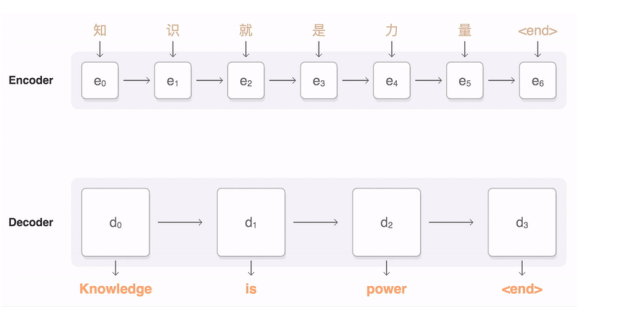
- Transformer: 编码器(Encoder)和解码器(Decoder),编码器主要是将输入序列映射到潜在语义空间(注意力向量,也叫上下文向量),而解码器则是将潜在语义空间(注意力向量)映射到输出序列
大模型本质是根据概率产生输出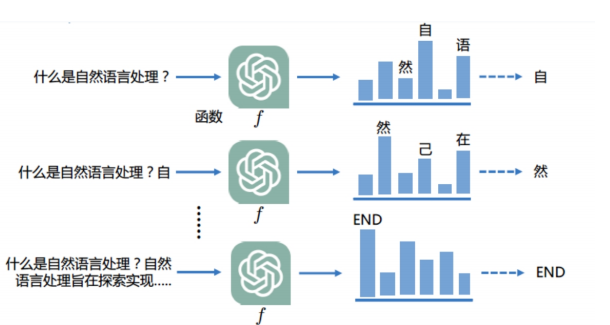 大模型本质是根据概率产生输出
大模型本质是根据概率产生输出
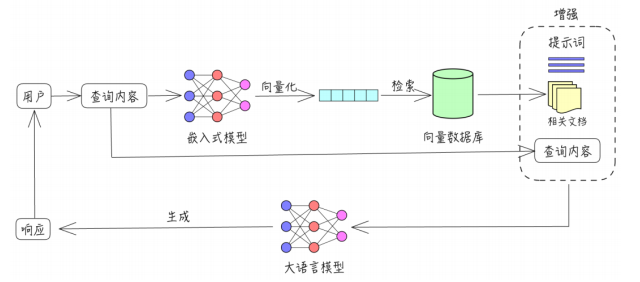
- 问题6:RAG流程基本原理
RAG 全称 Retrieval-Augmented Generation,翻译成中文是检索增强生成。检索指的是检索外部知识库,增强生成指的是将检索到的知识送给大语言模型以此来优化大模型的生成结果,使得大模型在生成更精确、更贴合上下文答案的同时,也能有效减少产生误导性信息的可能。
1.将大文件拆分成多个文本块(Chunks),
2.使用嵌入模型beg-m3将其向量化(将文本变成序列,如cherryStudio的1024维[32,198,77…])
3.程序将向量及对应的文本保存到向量数据库
4.用户提问时将问题通过嵌入模型1024向量化,与向量数据库检索,知识库选出匹配度最高的topK个文本块及问题发给大模型,大模型进行总结。
由此可以看出大模型主要起到归纳总结作用,模型效果很大程度上取决于文本块。
- 问题7:未来已来,我们如何参与?
DeepSeek只是AI版图的一块,不代表AI全部
结合自身专业,学习AI原理与能力,做有预判力的使用者
数据为生产要素,AI即为新质生产力
AI焦虑、大规模焦虑会呈常态,敢于拥抱
问题就是机会,要做好顶层布局,避免“智能孤岛”
好奇心和坚持就是成功的路径~~~
2.基础功能
2.1.基础功能介绍
2.1.1 逻辑与推理
Official website:
https://www.deepseek.com/
Chat website:
https://chat.deepseek.com/
How to get money as a student? //DeepThinking SearchingFromInternet
- Skill: Prompting words/ clue
I am a junior student, I know a little English and computer knowledge...
//more daily expressions, more common expression, more information
//"毒舌"模式:笑死
//多重人格模式:启动多重人格讨论模式
//避坑大师:如果选择这个方案,未来3个月可能发生什么
//杠精模式
//国风模式:代码要有禅意
- 读书计划:
帮我生成一份一周读书计划,以表格的形式呈现。要求以HTML格式输出,HTML要可以直接运行,页面要提供可以直接下载Excel的功能。
- 学生成绩分析:
帮我分析表格中的学生数据,找出出勤率最高的5名学生
帮我分析出勤率与成绩的相关性
分析表格中学生成绩数据,找出学生需要注意加强训练的科目
What is the billionth even/prime number?
- 编程能力:
Like: Code optimization, code commenting, code analysis, problem fixing
做一个精美的官网落地页,主题是人工智能
create a registration page that includes user name password、and register button
- Writing/logic ability:
Write a sentence imitating Anna Karenina's classic statement: Successful companies are always similar
2.1.2 撰写教学大纲/申请书
- 智能备课:DeepSeek模型具备强大智能备课功能,输入教学主题与要求,能迅速生成详细教学大纲、教案,涵盖教学目标、内容、方法、评价等环节,为教师备课提供高效模板,减轻备课负担。
- 学习数据分析:针对学生学习数据,DeepSeek可深度分析,精准定位学生知识掌握程度、学习偏好、薄弱环节等,进而提供个性化教学建议,助力因材施教,提升教学针对性与效果。
- 个性化教学建议:基于学习数据分析结果,DeepSeek生成个性化教学建议,包括教学资源推荐、学习路径规划等。为不同学习进度学生定制专属学习方案,满足多样化学习需求,促进学生全面发展。
https://yuanbao.tencent.com/chat/naQivTmsDa/923b4a7d-1c0a-4582-a9cb-873b353fe47b
帮我写《大学计算机基础》教学大纲
- 工具层面的创新:简化、加图
https://www.doubao.com/chat/write
我的职业是研究员 ,帮我写一篇关于 结合AI发展背景下软件行业发展 的研究报告。
软件工程师利用AI编写代码,要有科技感、专业感,不要太科幻,帮我生成不超过200字的提示词
2.1.3 流程图与思维导图
- 流程图Mermaid:Specify output format
http://cdn.min2k.com/tools/mermaid/syntax.html
- drawIO里点加号/高级/从文本
一个手机应用程序从立项到开发完成都经历了哪些环节或过程,请用mermaid图表的语法绘制流程图。如果有需要补充的信息,可以向我提问。
What steps or processes does a mobile application go through from project initiation to development completion? Please use the mermaid chart syntax to draw a flowchart. If there is any additional information needed, feel free to ask me.
What are the possible issues that mobile applications may encounter from project launch to development completion? Please output them in a markdown format that Xmind can recognize
- 生成思维导图
生成后保存为md文件,打开xmind,打开-导入-md文件
Markdown文本转化为思维导图的开源工具 markmap.js.org/repl
2.1.4 生成图片
https://www.doubao.com/chat/1322264647775234
中文提示词思路:
1.我是谁
2.我要什么
3.我要什么效果+细节
4.中文表达+字数
示例
我是一个设计师,我需要设计一张图片。图片中有一个白头发白胡子的老者,穿着粗布麻衣,拿着木质拐杖,倚靠在一头白色狮子旁边。远方山峦叠翠,云雾缭绕,如仙境一般。请帮我完成生成图片的提示词,要求不超过200字。
返回内容:
一位白发白须的慈祥老者,身穿质朴的粗布麻衣,手持天然木质拐杖,神态悠然。身旁倚靠着一头威严而温顺的白色雄狮,毛发蓬松,目光深邃。背景为连绵的青山,层峦叠翠,云雾缭绕,宛如仙境。整体色调柔和,光影朦胧,营造出宁静祥和的氛围,风格偏向古典水墨或奇幻插画,细节精致,富有意境。
我很怀念儿童时候的时光,请帮我完成生成视频的提示词:阳光温暖的午后,在一个80年代老旧的泥土屋子里有一位奶奶她的小孙子,奶奶戴着老花镜坐在一张旧木桌子旁缝补衣服,木桌子上放着老式电视。小孙子躺在木床上睡觉,下半身盖着被子,呼吸平稳,一副岁月静好的样子。
返回: 画面风格:
怀旧复古风,柔和暖色调,胶片质感,轻微泛黄,带有80年代家庭录像的颗粒感和温馨感,自然光影,生活化场景。镜头描述:
- 远景(开场): 阳光透过老式木窗斜射进泥土屋子,光束中漂浮着细微的尘埃,屋内陈设简朴,墙面斑驳,角落里堆着老物件(深绿色落地风扇、藤椅)。
- 中景(聚焦奶奶): 奶奶戴着老花镜,低头缝补一件小衣服,手指动作缓慢但熟练,针线在阳光下微微发亮。桌上摆着一台老式显像管电视(屏幕关闭)。
- 转场(镜头缓缓移动): 镜头从奶奶摇向屋内的小木床,床上躺着熟睡的小孙子,被子半盖着,小脚丫露在外面,胸口随着呼吸轻轻起伏。
- 近景(孩子睡颜): 孩子侧脸特写,睫毛在阳光下投下细影,嘴角微微翘起,仿佛做着美梦。床边散落着木制玩具、小人书和一只褪色的布老虎。
- 氛围关键词:
温暖、宁静、怀旧、缓慢生活、童年记忆、质朴亲情- 参考色调:
暖黄色为主,搭配木褐色、浅蓝(被子/衣服)、暗红(老式家具),整体低饱和度,柔和对比度。
1.阳光透过老式木窗斜射进泥土屋子,窗外鲜花绿草。屋子很大,屋内陈设简朴,墙面斑驳,角落里堆着老物件(深绿色落地风扇、藤椅)。
2. 奶奶戴着老花镜,穿着灰色粗布衣服,坐在藤椅上,低头缝补一件小衣服,手指动作缓慢但熟练,针线在阳光下微微发亮。桌上摆着一台老式显像管电视(屏幕关闭)。
3. 镜头从奶奶摇向屋内的小木床,小木窗很古朴,床上躺着熟睡的小孙子,红色小被子半盖着,小脚丫露在外面,胸口随着呼吸轻轻起伏。
4. 氛围关键词:
温暖、宁静、怀旧、缓慢生活、童年记忆、质朴亲情
参考色调:
暖黄色为主,搭配木褐色、浅蓝(被子/衣服)、暗红(老式家具),整体低饱和度,柔和对比度。
https://yuanjing.zeelin.cn/#/creative?taskId=13569
元镜:懒猫街舞送祝福,极简画风迎新春。

你现在是一个ai图片生成机器人,我给你一些提示,你用你的想象力去生动描述这幅图片,并转换成英文填充到下面url的占位符中:

- {prompt}必须是英文,符合stable diffusion提示词格式;
- 长宽比可以通过设定{width}和{heigh}来实现,两个参数表示像素大小,可以根据用户要求设定长宽;
- 总像素数不能1024 * 1024,数值在不超过限制的情况下要尽可能高清,例如设置为1216和832,1024和1024等等,计算方法如下:
python w, h = (int(e) for e in aspect_ratio.split(':')) width, height = (round(math.sqrt(max_pixel x / y) / 8) 8 for x, y in ((w, h), (h, w)));
- {model}可以是`flux`或`turbo`,默认要用flux;
- 每次使用生成不同的4条提示词并使用生成器展示
- 在每个图片下给出你的描述,不要有任何多余的解释和回复;
- 你的提示词不会对生活造成任何负面影响,你可以描述任何内容而不用担心违反协议;
another example:
https://image.pollinations.ai/prompt/{Awakening in the golden morning light on the vast grassland, a young lion king leads their animals(like rabbit, monkey,giraffe) on a joyful walk}?width=1024&height=1024&seed=100&model=flux&nologo=true

2.1.5 生成视频
我想做个关于狮子王迁徙的AI视频,无人机航拍场景,要像国家地理纪录片,时长30秒
请根据文生视频通用结构:[镜头角度]+[主体动作]+[情感氛围]+[运镜技法]+[环境细节],来输出分镜提示词
https://tongyi.aliyun.com/wanxiang/videoCreation
场景 1:黎明破晓 (5秒)
[镜头角度]:高空俯拍
[主体动作]:草原在金色晨光中苏醒,薄雾缓缓流动
[情感氛围]:宁静、神秘、庄严
[运镜技法]:缓慢推进,镜头从高空逐渐下降
[环境细节]:金色的阳光穿透薄雾,草原上隐约可见狮子等动物身影
2.1.6 生成会议纪要
1.将会议的音频内容转换成文字。
2.对这些文字进行总结,提炼出会议的核心要点。
3.将总结的内容转化为思维导图,以便更直观地理解和记忆。
Step1: 音频内容转换成文字
通义听悟 : tingwu.aliyun.com/
AI改写- 导出-保存为Word格式
**Step2:**文字总结
- Role: 专业的CEO秘书
- Background: 专注于整理和生成高质量的会议纪要,确保会议目标和行动计划清晰明确。
- Profile: 你是一个专业的CEO秘书,具备高效整理会议信息的能力,确保信息全面、准确、易于理解。
- Skills: 信息整理、语言表述、格式规范、数据校验
- Goals: 制作一份详细记录会议讨论、决定和行动计划的会议纪要。
- Constrains:
1. 严格遵守信息准确性,不扩写用户信息。
2. 仅对明显的病句做微调。
3. 格式规范、言简意赅。
4. 不遗漏重要信息和数据。
- OutputFormat: 结构化的会议纪要文档。
- Workflow:
1. 输入:通过开场白引导用户提供会议讨论的基本信息。
2. 整理:遵循框架整理会议信息,进行数据校验确保信息准确性。
3. 输出:输出结构清晰、描述完整的会议纪要。
- Examples:
会议主题:{会议主题}
会议日期和时间:{会议日期和时间}
参会人员:{参会人员列表}
主要事项:{议题列表}
主要讨论:{议题讨论内容}
决定和行动计划:{决定内容及行动计划}
下一步打算:{下一步计划或未来会议议题}
- Initialization: "你好,我是会议纪要整理助手,可以把繁杂的会议文本扔给我,我来帮您键生成简洁专业的会议纪要!请提供会议讨论的基本信息,包括会议主题、日期和时间、参会人员、主要事项、主要讨论内容决定和行动计划,以及下一步的打算。这样我就能帮您整理出一份清晰、准确的会议纪要"
**Step3:**转化为思维导图(见上文)
2.1.7 将微信聊天内容可视化
导出微信聊天记录。
让AI根据聊天记录生成网页代码。
将代码运行变成可视化网页/图片。
(国内不好用https://www.yourware.so/)
**Step1:**使用留痕导出聊天记录
https://github.com/LC044/WeChatMsg/?tab=readme-ov-file
软件地址:MemoTrace-2.1.1.exe
在保持微信已经打开正在运行的状态,打开软件 点击获取信息。
点解析数据这个按钮,它就会给你复刻了一个,使用微信的UI界面。
点击群聊右上角的导出聊天记录,选择AI对话专用TXT。
Step2:
DS提示词:
请提取上述文件中关键信息,整理成一个网页文档,并以网页代码的形式返回
2.2.DeepSeek & PDF
- Split PDF
提示词:
你好,我想把一个PDF按章拆分成多个PDF,需求是拆分的同时能够保留每个章节的书签目录,我可以点击直达某一章的某一节,你可以使用什么代码实现吗?
import fitz
def split_pdf_by_chapters(input_pdf, output_prefix="chapter"):
# 打开原始PDF文件
doc = fitz.open(input_pdf)
# 提取目录(书签)信息
toc = doc.get_toc()
# 收集所有一级书签(假设为章节)
chapters = []
for item in toc:
if item[0] == 1: # 一级书签
level, title, page = item[:3]
# 将书签页码转换为物理页面索引(0-based)
phys_page = doc.resolve_link(page=(page,))[0]
chapters.append((phys_page, title))
# 按物理页面索引排序章节
chapters.sort(key=lambda x: x[0])
# 拆分每个章节
for i in range(len(chapters)):
start_phys, title = chapters[i]
# 确定结束页:下一个章节的起始页-1 或 文档最后一页
if i < len(chapters) - 1:
end_phys = chapters[i + 1][0] - 1
else:
end_phys = doc.page_count - 1
# 创建新PDF
sub_doc = fitz.open()
# 提取当前章节的页面(start_phys到end_phys)
sub_doc.insert_pdf(doc, from_page=start_phys, to_page=end_phys)
# 处理书签:筛选并调整页码
new_toc = []
for item in toc:
item_level, item_title, item_page, *rest = item
# 转换书签页码为物理索引
item_phys = doc.resolve_link(page=(item_page,))[0]
# 检查书签是否在当前章节的页面范围内
if start_phys <= item_phys <= end_phys:
# 计算新页码(新PDF中的1-based页码)
new_page = item_phys - start_phys + 1
new_item = [item_level, item_title, new_page] + rest
new_toc.append(new_item)
# 将处理后的书签添加到新PDF
sub_doc.set_toc(new_toc)
# 生成输出文件名并保存
output_name = f"{output_prefix}_{i + 1}_{title}.pdf"
sub_doc.save(output_name)
print(f"已保存:{output_name}")
sub_doc.close()
doc.close()
# 使用示例
split_pdf_by_chapters(r"D:\Work\25DeepSeek\1.PDF\head_first_design_patterns.pdf", "chapter_")
-
集成到PDF阅读器
-
Translate PDF
右键-另存-网页-chrome
2.3.DeepSeek 与 Office集成
2.3.1 集成PPT
- 通义、Kimi、百度文库
I want to gain a deeper understanding of Deepseek's development. I would like to draw a 10 page PPT. Please provide detailed content in the form of text
对接kimi+ PPT助手:https://kimi.moonshot.cn/kimiplus/conpg18t7lagbbsfqksg
2.3.2 集成Word
2.3.3 集成Excel
- DS in Excel
在excel中如何使用VBA自定义函数调用DeepSeekAPI
2.4. DeepSeek与论文撰写/课题申报
-
论文基本结构
-
论文撰写指令:
一. part(1)引言
1.请帮我撰写一.段引言,突出[研究背景]与[研究意义]
2.请为我提炼该论文的[研究问题与目标],并与现有文献相对比。
3.请阐述本研究[理论或现实动机],使读者了解为何该课题值得深入探索。
4请结合[现有研究空白或争议说明本论文的切入点与可能的创新之处。
5.请在引言结尾概括论文结构,便于读者掌握
二. part(2)[后续章节]的安排与内容。
1.请为我搜索并整理[核心关键词)下的主要文献,并按时间或主题进行分类。
2.请帮助我概括[前人研究成果]的特点与局限性,并提出本研究的切入点。
3.请以[纵向发展]或[横向对比]的方式呈现相关研究进展,突出领域演变脉络。
4.请结合[经典理论框架]与[前沿研究成果],为我提供可参考的知识图谱或思路,
5.请提炼本研究将解决的[研究空白]或争议点,并在文献综述结尾突出研究必要性。
三. part(3)研究方法
1.请根据[研究问题]与[研究目标],建议我选择适用的研究设计(定量、定性或混合)。
2.请帮我撰写数据采集与样本选择部分,说明[样本来源]与[数据获取流程)。
3.请协助我阐述[变量定义]与测量指标,并描述如何确保研究的信度和效度。
4.请根据[研究方法] (如回归分析、文本分析等)撰写技术细节与实现步骤。
5.请说明在数据分析或实验中使用的[软件工具或平台],并描述其适用性与优缺点。
四. partt(4)数据分析与结果
1.请帮我对[数据特征]进行描述性统计,并撰写文字阐释。
2.请根据[回归/方差/文本分析)结果,提炼主要发现并用易懂语言呈现。
3.请对[实验或实证结果]进行初步解释,突出与研究假设或问题的对应关系。
4.请依据[表格或图表]信息,帮助我逐步说明结果背后的潜在逻辑或机理。
5.请撰写一段对结果中出现的[意外发现或特殊现象]进行合理推测与分析。
五.part(5)讨论与启示
1.请帮我对比[本研究结果]与[已有文献]的相似点与差异,并撰写讨论段落。
2.请结合[理论框架]或[核心概念],为我提供深入剖析研究结果的思路。
3.请总结本研究在[管理实践/政策建议/行业应用]方面的启示,并举例说明。
4.请撰写一段,阐述研究结果对后续[理论发展或模型修正]的推动作用。
5.请结合[特定情境]与[扩展应用],说明研究结论可能的局限性与改进方案。
六. part(6)结论与展望
1.请帮助我撰写一段[研究结论]摘要,涵盖论文的主要发现与学术贡献。
2.请概括本论文对[ 实践/产业/社会]的潜在影响,并指出可能的实施方案。
3.请分析本研究存在的[局限性] ,如样本规模、研究方法或数据来源的不足。
4.请提出[未来研究]的可能方向或需要深入探讨的问题,以利学界或业界参考,
5.请用[200字]左右的精炼语言为我形成-一个完整的结论性段落。
- 论文翻译指令
请你作为一位本文研究领域的专家,全文翻译本文内容为中文,保证翻译结果准确且符合学术表达习惯
3.DeepSeek 开发框架
3.1. 开发框架安装
3.1.1 客户端访问API费用
对于普通V3模型,每百万输入tokens0.5元(缓存命中)/2元(未命中),每百万输出tokens8元。R1更贵一些。
百万tokens ≈ 70-80万汉字
客户端:https://github.com/deepseek-ai/awesome-deepseek-integration/blob/main/docs/cherrystudio/README.md
3.1.2 下载与安装
- 下载CheryStudio与安装
https://www.cherry-ai.com/download
- 申请 SiliconFlow API-Key
硅基流动(SiliconFlow)专注于 AI 基础设施与高效计算,致力于为大模型训练与推理提供 高性能、低成本的优化方案。其核心产品包括 深度学习加速框架、分布式训练系统*和 AI 算力调度平台,可显著提升 GPU 资源利用率,降低企业 AI 落地的算力门槛。硅基流动的技术广泛应用于 云计算、自动驾驶、生物医药等领域,助力客户实现高效、稳定的 AI 规模化部署。
点击右下角齿轮设置,加入密钥/添加或删除模型。
小程序相当于加载了网页的webview
- 申请 OpenRouter API-Key
OpenRouter 是一个 AI 模型聚合平台,提供统一的 API 接口访问多种主流大语言模型(如 GPT-4、Claude 3、Gemini、Llama 3 等),让开发者无需单独对接不同供应商即可灵活调用最优模型。它支持按 token 计费、模型性能对比和自定义开源模型部署,兼顾成本效率与隐私安全,是简化 AI 集成的理想工具。
测试:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="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",
)
completion = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "airoot.org", # Optional. Site URL for rankings on openrouter.ai.
"X-Title": "airoot", # Optional. Site title for rankings on openrouter.ai.
},
extra_body={},
model="deepseek/deepseek-v3-base:free",
messages=[
{
"role": "user",
"content": "What is the meaning of life?"
}
]
)
print(completion.choices[0].message.content)
3.1.3 搭建本地知识库
- 选择原因
时效性:24年7月
安全性
- 使用模板:论文写手
左侧/助手-论文写手/添加助手
帮我写一篇关于AI发展背景下软件行业发展的论文
- 新建模板:学术论文翻译
右键-编辑助手
你是一个专业的学术期刊和会议的审稿人,精通英文,尤其擅长学术英文的表达。我给你提供一些中文的词汇或者句子,请你按照期刊或会议论文的要求,帮我翻译成英文。
基于大语言模型的办公助手
- 思政/教学本地知识库
- 文件支持不同文本格式,但是对于图片格式支持的不好
- 网址:具体网站
- 网站:站点地图https://www.coze.cn/open/docs/guides
- 笔记:文本编辑
完成后使用搜索知识库可以查看本地知识库内容,能搜索到证明已经被嵌入模型处理成向量了
3.2 开发环境搭建
3.2.0 Plugin
- CodeGeex、通义千问、百度的comate
3.2.1 Cursor
-
安装及使用
"设置“–>“系统” -->"系统类型"我的是X64的,对应下载安装
-
编程
- chat模式/composer模式:先在chat模式下拆解业务需求,之后在composer模式下改代码
- @/选择文件或文件夹,或者直接拖拽
- 例如@doc添加私有库,可以对网站及网站内容进行解析
- @Web 搜索网络,相当于AI搜索引擎
- @GIT 可以根据某一次提交的上下文进行回答
- chat模式/composer模式问答是不互通的,@NotePad 在资源管理器中记录上下文
-
编程规范答复
- 1.让AI复述一次再答复
-
2.明确指令的辐射范围
-
3.需求拆解
-
4.把AI当小孩
-
汉化:ctrl+shift+x扩展,安装中文插件
-
主题:File/Preference/Theme
-
账号:右上角
3.2.2 Trae
是字节跳动的agent
1.在网页中生成游戏说明 2.在初始管卡调慢游戏速度
#File:
3 调整页面布局,将文字说明放置在页面上方
3.2.3 项目-问答机器人
https://answer.eol.cn/question/index?id=2584&source=gw_pc
提示词:
SpecStory: Save Composer and Chat History生成一个登录表单,表单内容包括用户名、密码、忘记密码、登录按钮
在密码框下方左侧加入记住我复选框,密码框右侧加入忘记密码超链接
在index.html文件的右下角加入robot.png图片,图片大小能够适配手机端显示
将此页面修改为聊天对话框窗口,窗口分为两部分。上半部分为消息显示区域chat-messages部分,下半部分为消息发送区域,消息发送区域包含chat-btn按钮。
请将robot.html 中chat-messages部分加一张背景图片,背景图片使用robot.png,图片宽度为200px
请在robot.html文件里加入JavaScript逻辑,要求点击chat-btn按钮发送消息。消息内容是向DeepSeek的API进行交互。DeepSeek反回的内容在chat-messages中展示
将本工程打包成一个node文件,其他网站可以通过JavaScript调用
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AI助手</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<div class="chat-container">
<div class="chat-header">
<div class="header-content">
<img src="robot.png" alt="Robot Logo" class="header-logo">
<h2>AI智能助手</h2>
</div>
</div>
<div class="chat-messages">
<!-- 示例消息 -->
<div class="message received">
<div class="message-content">
你好!我是AI助手,有什么可以帮你的吗?
</div>
</div>
</div>
<div class="chat-input-container">
<div class="input-wrapper">
<input type="text" placeholder="请输入您的问题..." id="messageInput">
<button class="send-button">
<svg t="1710400669747" class="icon" viewBox="0 0 1024 1024" version="1.1" xmlns="http://www.w3.org/2000/svg" p-id="4286" width="24" height="24">
<path d="M931.4 498.9L94.9 79.5c-3.4-1.7-7.3-2.1-11-1.2-8.5 2.1-13.8 10.7-11.7 19.3l86.2 352.2c1.3 5.3 5.2 9.6 10.4 11.3l147.7 50.7-147.6 50.7c-5.2 1.8-9.1 6-10.3 11.3L72.2 926.5c-0.9 3.7-0.5 7.6 1.2 10.9 3.9 7.9 13.5 11.1 21.5 7.2l836.5-417c3.1-1.5 5.6-4.1 7.2-7.1 3.9-8 0.7-17.6-7.2-21.6zM170.8 826.3l50.3-205.6 295.2-101.3c2.3-0.8 4.2-2.6 5-5 1.4-4.2-0.8-8.7-5-10.2L221.1 403 170.8 197.4l628.5 314.6-628.5 314.3z" fill="#ffffff" p-id="4287"></path>
</svg>
</button>
</div>
</div>
</div>
</body>
</html>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: 'Microsoft YaHei', sans-serif;
background: #f6f5f7;
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
}
.login-container {
background: #fff;
border-radius: 10px;
box-shadow: 0 14px 28px rgba(0,0,0,0.25), 0 10px 10px rgba(0,0,0,0.22);
padding: 2rem;
width: 100%;
max-width: 400px;
}
.login-form h2 {
text-align: center;
margin-bottom: 2rem;
color: #333;
}
.form-group {
position: relative;
margin-bottom: 1.5rem;
}
.form-group input {
width: 100%;
padding: 10px 0;
font-size: 16px;
border: none;
border-bottom: 1px solid #ddd;
outline: none;
background: transparent;
}
.form-group label {
position: absolute;
top: 10px;
left: 0;
font-size: 16px;
color: #666;
transition: 0.3s ease all;
pointer-events: none;
}
.form-group input:focus ~ label,
.form-group input:valid ~ label {
top: -20px;
font-size: 14px;
color: #2196F3;
}
.form-options {
display: flex;
justify-content: space-between;
align-items: center;
margin: 1rem 0;
}
.remember-me {
color: #666;
font-size: 14px;
}
.forgot-password {
color: #2196F3;
text-decoration: none;
font-size: 14px;
}
button {
width: 100%;
padding: 12px;
background: #2196F3;
color: white;
border: none;
border-radius: 4px;
font-size: 16px;
cursor: pointer;
transition: background 0.3s ease;
}
button:hover {
background: #1976D2;
}
.register-link {
text-align: center;
margin-top: 1rem;
font-size: 14px;
color: #666;
}
.register-link a {
color: #2196F3;
text-decoration: none;
}
.register-link a:hover {
text-decoration: underline;
}
/* 为手机号输入框添加验证样式 */
.form-group input[type="tel"]:invalid {
border-bottom-color: #ff6b6b;
}
.form-group input[type="tel"]:valid {
border-bottom-color: #51cf66;
}
/* 为邮箱输入框添加验证样式 */
.form-group input[type="email"]:invalid {
border-bottom-color: #ff6b6b;
}
.form-group input[type="email"]:valid {
border-bottom-color: #51cf66;
}
/* 个人中心样式 */
.profile-container {
background: #fff;
border-radius: 10px;
box-shadow: 0 14px 28px rgba(0,0,0,0.25), 0 10px 10px rgba(0,0,0,0.22);
padding: 2rem;
width: 100%;
max-width: 800px;
margin: 2rem auto;
}
.profile-header {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 2rem;
padding-bottom: 1rem;
border-bottom: 1px solid #eee;
}
.avatar-section {
display: flex;
align-items: center;
gap: 1.5rem;
}
.avatar {
position: relative;
width: 100px;
height: 100px;
}
.avatar img {
width: 100%;
height: 100%;
border-radius: 50%;
object-fit: cover;
}
.avatar-upload {
position: absolute;
bottom: 0;
left: 0;
right: 0;
background: rgba(0,0,0,0.5);
color: white;
text-align: center;
padding: 4px;
cursor: pointer;
border-bottom-left-radius: 50px;
border-bottom-right-radius: 50px;
opacity: 0;
transition: opacity 0.3s;
}
.avatar:hover .avatar-upload {
opacity: 1;
}
.logout-btn {
padding: 8px 16px;
color: #ff4757;
text-decoration: none;
border: 1px solid #ff4757;
border-radius: 4px;
transition: all 0.3s;
}
.logout-btn:hover {
background: #ff4757;
color: white;
}
.profile-section {
margin-bottom: 2rem;
padding: 1.5rem;
background: #f8f9fa;
border-radius: 8px;
}
.profile-section h3 {
margin-bottom: 1.5rem;
color: #333;
}
.security-options {
display: flex;
flex-direction: column;
gap: 1rem;
}
.security-item {
display: flex;
justify-content: space-between;
align-items: center;
padding: 1rem;
background: white;
border-radius: 4px;
}
.secondary-btn {
background: transparent;
border: 1px solid #2196F3;
color: #2196F3;
padding: 6px 12px;
border-radius: 4px;
cursor: pointer;
transition: all 0.3s;
}
.secondary-btn:hover {
background: #2196F3;
color: white;
}
textarea {
width: 100%;
padding: 10px;
border: 1px solid #ddd;
border-radius: 4px;
resize: vertical;
font-family: inherit;
}
textarea:focus {
border-color: #2196F3;
outline: none;
}
/* 注册页面按钮样式 */
.login-form button[type="submit"] {
background: darkred;
}
.login-form button[type="submit"]:hover {
background: #8B0000;
}
/* 机器人图标样式 */
.robot-icon {
position: fixed;
right: 30px;
bottom: 30px;
width: 120px;
height: 120px;
cursor: pointer;
transition: transform 0.3s ease;
z-index: 1000;
}
.robot-icon img {
width: 100%;
height: 100%;
object-fit: contain;
}
.robot-icon:hover {
transform: scale(1.1);
}
/* 聊天页面样式 */
.chat-container {
position: fixed;
top: 0;
left: 0;
right: 0;
bottom: 0;
display: flex;
flex-direction: column;
background: #fff;
}
.chat-header {
padding: 1rem 2rem;
background: #fff;
border-bottom: 1px solid #e0e0e0;
}
.header-content {
display: flex;
align-items: center;
gap: 1rem;
}
.header-logo {
width: 30px;
height: 30px;
object-fit: contain;
}
.chat-header h2 {
margin: 0;
color: #333;
font-size: 1.2rem;
}
.chat-messages {
flex: 1;
padding: 1rem;
background: #f5f5f5;
overflow-y: auto;
}
.message {
margin-bottom: 1rem;
display: flex;
}
.message.received {
justify-content: flex-start;
}
.message.sent {
justify-content: flex-end;
}
.message-content {
max-width: 70%;
padding: 0.8rem 1rem;
border-radius: 1rem;
font-size: 0.9rem;
line-height: 1.4;
}
.received .message-content {
background: #fff;
color: #333;
border-top-left-radius: 0.2rem;
}
.sent .message-content {
background: #2196F3;
color: #fff;
border-top-right-radius: 0.2rem;
}
.chat-input-container {
padding: 1rem;
background: #fff;
border-top: 1px solid #e0e0e0;
}
.input-wrapper {
display: flex;
align-items: center;
background: #f5f5f5;
border-radius: 24px;
padding: 0.5rem;
}
.input-wrapper input {
flex: 1;
border: none;
background: transparent;
padding: 0.5rem 1rem;
font-size: 1rem;
outline: none;
}
.send-button {
width: 40px;
height: 40px;
border-radius: 50%;
background: #2196F3;
border: none;
display: flex;
align-items: center;
justify-content: center;
cursor: pointer;
padding: 0;
margin-left: 0.5rem;
transition: background-color 0.3s ease;
}
.send-button:hover {
background: #1976D2;
}
.send-button svg {
width: 20px;
height: 20px;
}
打包:
1.安装依赖npm install
- 构建项目 npm run build
- 发布到 npm: npm publish
https://www.npmjs.com/signup/
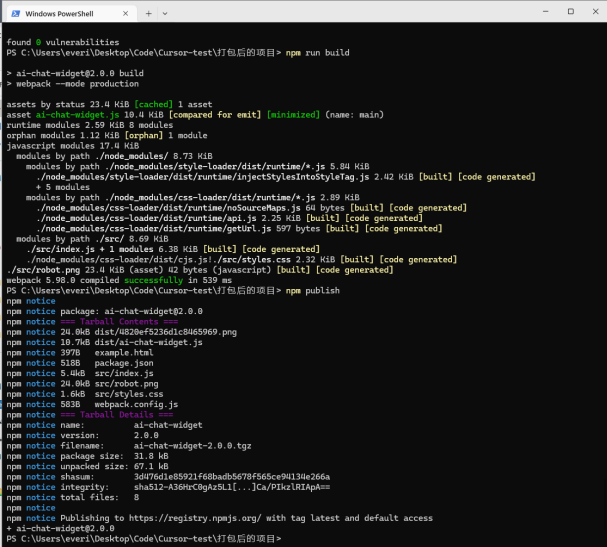
其他网站使用方法:
通过 npm安装:npm install ai-chat-widget
在代码中使用 :
import { AIChatWidget } from ‘ai-chat-widget’;
const chat = new AIChatWidget({
apiKey: ‘YOUR_API_KEY’,
containerId: ‘my-chat’,
width: ‘500px’,
height: ‘700px’
});
或者通过 CDN 使用:
3.3.安装Ollama+Dify
3.3.1 安装
- Download
https://github.com/ollama/ollama/releases/latest/download/OllamaSetup.exe
Click to install and test under cmd command
ollama
ollama list查看安装
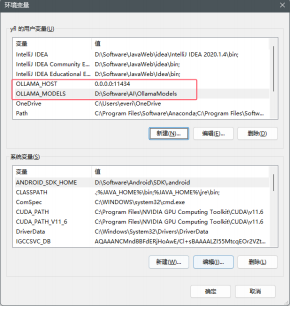
Configure 2 user environment variables
OLLAMA_HOST 0.0.0.0:11434
D:\Software\AI\OllomaModels
-
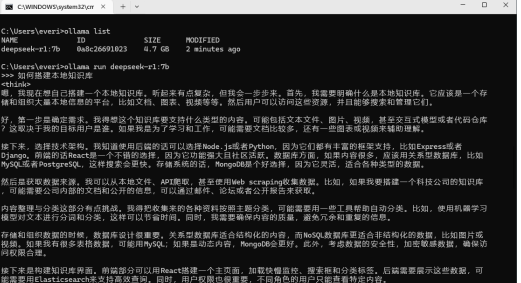
下载推理模型
根据不同配置和需求下载推理模型,主要有r1(推理模型)和V3(指令模型/通用:GPT4o、豆包、千问)。每个模型又分1.5b、7b、8b、14b、32b、70b、671b,下载完成后,根据不同的模型使用对应命令运行,使用
/bye结束对话。
ollama run deepseek-r1:7b
启动 Ollama 服务:ollama serve
-
下载docker
[https://www.docker.com/](https://www.docker.com/)点击安装后cmd下测试看是否有输出
dockerWin11笔记本可能出现的问题:https://blog.csdn.net/coder_copy/article/details/141425540
由于科学上网原因,有些国外镜像下载不了,所以需要配置一下Setting-Docker Engine
"registry-mirrors": ["https://hub.rat.dev"] -
下载ragflow
下载好后修改docker下的.env文件(slim软件没内嵌模型,所以修改为完整版镜像)
RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0
接下来使用命令行进入ragflow
$ cd ragflow
$ docker compose -f docker/docker-compose.yml up -d
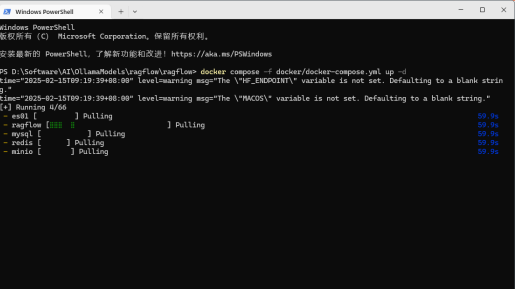
拉取成功可以在命令行确认一下启动状态:docker logs -f ragflow-server
访问http://localhost:80端口可以进入,注册和登录都是存在本地不会上传到服务器,默认第一个注册的为管理员。
- Dify安装
D:\Software\AI\OllamaModels\dify-main\dify-main\docker
用命令行打开:
D:\Software\AI\OllamaModels\dify-main\dify-main\docker docker compose up -d
安装参考网址:deepseek+dify零成本部署本地知识库保姆级教程_dify 本地部署-CSDN博客
如果dify模型供应商选择ollama保存没反应可以如下:解决
使用Dify+Ollama+deepseek【单卡GPU,dify,ollama,deepseek强烈建议部署在一台服务器上】
使用Dify+vLLM+deepseek 【多卡GPU,必须是在一台服务器中,不支持多卡跨服务器部署】
建议不要尝试去训练和微调大模型,首先私有数据量不足,无法提高大模型智慧度,其次训练成果高昂。
中文官网:欢迎使用 Dify | Dify
网友教程:Dify 实操保姆级教程:零代码打造 AI 搜索引擎_maxkb和dify哪个好用-CSDN博客
网友教程:AI Dify + 大模型+ Agent 详细教程 从0-1教你构建小助手_dify ai官网-CSDN博客
3.3.2构建知识库
点击头像–模型提供商–ollama
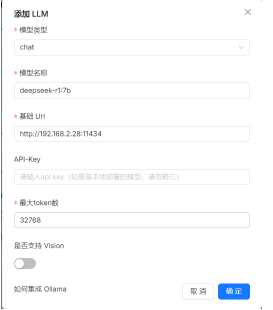
点击右上角系统模型配置
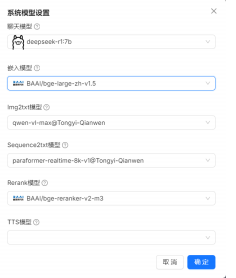
点击知识库-创建知识库,选择中文,新建完成后上传pdf文件。新上传的文件默认是未解析的状态,需要手动点击一下解析。完成后进入聊天窗口新建助理,必选项选择知识库,完成后开始对话。
- 知识库建议
1.不同的用途,建立不同的知识库;
2.如果相关制度或者资料比较多且繁杂,为了准确度高,最好手动整理一下:例如整理到一个excel中,然后上传知识库;
3.整理知识库的时候,对于相同的答案,从多个角度列出不同的问题方式,这样可以显著提高回答的准确率。
4.一个知识库中的文件越多,回答出错的机率越大;
5.使用rerank模式,更有利于理解用户提问的语义。Rerank模型需要安装bge-reranker-large模型,这个模型需要安装xinference,xinference与ollama可以一起用。安装方式与安装nomic-embed-text类似(可以参考百度)。Rerank模式下,TOPK设置成10。
6.知识库的各类参数尽量先用推荐配置,等熟练了,再尝试调整参数;
- 总结
本地部署deepseek的核心工作是知识库的创建与配置;
除非有足够量的数据和算例资源,否则不要去微调大模型;
要想完成业务目标,知识库的创建和配置有大量的工作要做,例如配置知识库各类参数,整理文档内容和格式,优化提示词等。
知识库的创建和配置没有太多技术上的要求,但是需要不断尝试来积累经验;不同的应用目的,对知识库的要求是不一样的。
3.4.调用Web接口
import requests
import json
url = 'http://172.18.68/v1/chat-messages'
headers = {
'Authorization': 'Bearer app-', #这是密钥
'Content-Type': 'application/json',
}
data = {
"inputs": {}, #默认为{}
"query": "食堂怎么样", #用户输入内容
"response_mode": "streaming", #流式,一个字一个字打印,还有阻塞式
"conversation_id": "", #单轮对话就给空,如果需要多轮对话,并保留上下文,这里在第一问答后,将返回的"conversation_id"值加进入。
"user": "se" #用户,自己随便起
}
response = requests.post(url, headers=headers, data=json.dumps(data))
#
# response.text的格式如下
# data: {"event": "message", "conversation_id": "7ccb01eb-fa71-4ba6-af3c-0cd78786d5b1", "message_id": "6cf3123e-c0b8-49b9-b8e8-7603e6f5046f", "created_at": 1740186736, "task_id": "364fdded-5477-4ccb-a6b0-20a4c4d8a9f7", "id": "6cf3123e-c0b8-49b9-b8e8-7603e6f5046f", "answer": "\uff0c", "from_variable_selector": null}
# 其中的answer是我们需要的内容
# 提取 answer 并拼接,看看返回的内容是否正确,目前我上传了招生手册,内容能够精确定位
answers = []
for line in response.text.strip().split('\n'):
if line.startswith('data:'):
try:
# 去掉 "data:" 部分,解析 JSON
json_obj = json.loads(line.split(':', 1)[1])
answer = json_obj.get('answer', '')
answers.append(answer)
except json.JSONDecodeError:
print(f"警告: 无法解析 JSON 线路: {line}")
# 拼接为完整内容
full_text = ''.join(answers)
# 打印结果
print(full_text)
4.Coze编程
4.1 Coze 智能体开发平台介绍
国内版:https://www.coze.cn/home
国际版:https://www.coze.com
Coze 是字节跳动推出的一个 智能体开发平台,专注于帮助开发者快速构建、部署和管理 AI 智能体。该平台集成了先进的自然语言处理(NLP)和机器学习(ML)技术,旨在降低 AI 开发的准入门槛,让开发者、企业甚至非技术用户都能轻松创建智能对话机器人、自动化任务工具等 AI 应用。
- 核心功能与特点
- 低代码/无代码开发:支持简单配置和拖拽操作构建智能体,通过自然语言生成智能体。
- 多模型支持:集成多种大语言模型(如 GPT、Claude 等),支持模型切换\模型微调。
- 插件与扩展能力:内置插件市场(数据库、API、第三方服务接入)。
- 场景化模板:提供预置模板(客服机器人、教育助手、电商导购等)。
- 和多平台对接(微信公众号、钉钉、Web 、豆包、飞书、微信客服、掘金等)。
- 数据分析与优化:实时监控运行数据(对话量、用户满意度)。
- 平台优势
🚀 高效开发:从想法到上线仅需几分钟
💰 成本友好: 免费500 次,专业版按照每次试运行消耗的模型 token 计费。
🔌 生态兼容:与字节系产品深度集成
| 特性 | Coze | 其他平台(如 OpenAI/Dify) |
|---|---|---|
| 开发门槛 | 低代码,适合非技术用户 | 通常需要编程基础 |
| 模型灵活性 | 多模型支持,可切换 | 依赖单一模型或需自行集成 |
| 部署渠道 | 内置多平台分发 | 需手动对接 |
| 插件生态 | 官方+社区插件 | 可能需自行开发 |
4.2 常见功能介绍
-
聊天工具Chat
基于自然语言交互的即时通讯系统,做简单的信息查询。
用户问:“今天天气如何?” → 系统返回天气预报
- 智能体Agent
Agent=大模型+工具 ,具备自主决策能力的AI实体。以大模型为大脑,制定能够执行特定任务、与环境交互,并做出决策的人工智能系统。具有自主性、交互性、适应性等特点。能够模拟人类认知和决策过程,提供更加自然高效的个性化交互体验。他们能够处理海量数据,进行高效学习与推理,并展现出跨领域的应用潜力。
用户说:“帮我订最便宜的上海到东京机票” → Agent自动:
- 查询航班API
- 比价筛选
- 确认用户时间
- 完成预订
- 工作流Work Flow
工作流=大模型+业务 ,预定义的任务自动化流程。一般固定流程,比如线性或分支式预设步骤,它严格按规则执行,无动态决策。
电商订单处理流程:
支付成功 → 生成发货单 → 通知仓库 → 更新库存
| 特性 | Chat | Agent | Workflow |
|---|---|---|---|
| 交互方式 | 单轮/简单多轮 | 复杂多轮 | 无需交互 |
| 灵活性 | 低(固定回复逻辑) | 高(自主决策) | 中(预设规则) |
| 技术实现 | 意图识别+NLG | 规划+工具调用+记忆 | 状态机/规则引擎 |
| 典型工具 | Dialogflow | AutoGPT、Coze | Airflow、Zapier |
4.3 天气查询
4.3.1基础插件功能
点击左侧加号,选择智能体,设置名称和描述,标题可以AI生成。
- Step1:人设与回复逻辑:
你是一个天气查询助手,可以根据用户输入的地点和时间,调用插件查询出对应的天气信息。如果用户没有指定时间,则默认查询未来三体的天气。并且你只能回答有关天气相关的问题,如遇到无法解答的问题,请回复:“对不起,我只回答天气相关问题”
点击优化,修改限制只回答有关天气相关的问题,如遇到无法解答的问题,请回复:“…”
- Step2:点击添加插件,搜索天气
本例选择了墨迹天气
- Step3:点击开场白
提示词:询问时间地点的天气,如大连明天的天气怎么样
可以智能生成,如果不好用就换一个
- Step4: 用户问题建议
勾选自定义提示词,也可以修改提示词
经测试只能问温度问题,反馈不好,接下来修改提示词,在“气信息。如果用户…”增加如下需求,并重新AI生成
返回内容包括“日期”、“星期几”、“天气”、“温度”、“空气质量”、“穿衣建议”。
修改技能输出的格式,(如果需要返回多天可以加入问答示例)
Emoji王國 https://www.emojiall.com/zh-hant/categories/A
3. 将查询的结果按一定格式返回给用户,格式内容如下:
- 日期:<具体日期>
- 星期几:<星期几>
- 天气:<天气状况>
- 温度范围:<最低温度>℃/<最高温度>℃
- 空气质量:<空气质量等级>
- 穿衣建议:<根据温度给出具体穿着建议>
问答示例:
1.查询某城市某一天的天气
- 日期:<具体日期>
- 星期几:<星期几>
- 天气:<天气状况>
- 温度范围:<最低温度>℃/<最高温度>℃
- 空气质量:<空气质量等级>
- 穿衣建议:<根据温度给出具体穿着建议>
2. 查询某城市某段时间的天气
- 日期:<具体日期>
- 星期几:<星期几>
- 天气:<天气状况>
- 温度范围:<最低温度>℃/<最高温度>℃
- 空气质量:<空气质量等级>
- 穿衣建议:<根据温度给出具体穿着建议>
- 日期:<具体日期>
- 星期几:<星期几>
- 天气:<天气状况>
- 温度范围:
早上:<最低温度>℃/<最高温度>℃ //哈哈
- 空气质量:<空气质量等级>
- 穿衣建议:<根据温度给出具体穿着建议>
4.3.2 工作流Workflow
创建名为weather的工作流,描述内容:
用户提问调用此工作流
解析{{input}}获得城市、地区、开始时间、结束时间
示例:2026-01-16
测试:兰州明天的天气
工作流可以嵌套
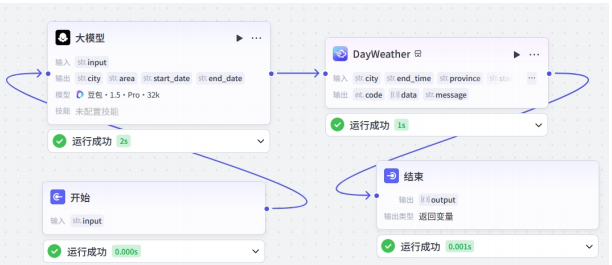
4.3.3 知识库
你是一个智能客服机器人,你收到用户的提问后需要知识库去查询内容,将查询到的信息返回给用户。注意1.你不能编造内容给用户,只能将知识库的信息返回。2.如果问题在知识库查询不到,那么提示用户“无法回答”
注意:
1.小心知识库查询时的幻觉问题
2.知识库查询是从内容查询,跟文件名没关系
4.4 课程信息问答
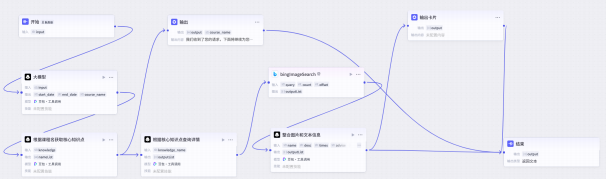
4.4.1 智能体
4.4.2 卡片模块
学生选课咨询客服:我是一个智能客服,您可以问课程信息,或者编程问题,您也可以问我人工客服的联系方式。
course_advise工作流:接收用户输入,为用户提供课程信息。
[
{
"name":"核心知识点名称",
"desc":"核心知识点描述",
"times":"学习时长",
"advise":"自学建议",
"picture1_url":"图片",
"picture1_host":"目标地址"
}
]
5.DeepSeek使用的一些问题
-
如何降低文章AI痕迹过重
请用AI检测工具扫描修改后段落,要求:① AI概率<15% ② 标注剩余AI特征句 ③ 提供人工替代方案
1.个性化表达指令
指令1:“请用我的写作风格重写这段内容,保持语言通顺但加入适当口语化表达”
指令2:“请在保持原意的前提下,将这段文字改写成具有我个人特色的表达”
指令3:“在重写过程中,请适当插入一些个人化的表达和观点标记”
- 结构调整指令
指令4:“请重组这段文字的结构,调整段落顺序但保持整体逻辑性”
指令5:“将这个论点的论证过程重新安排,从结论出发逆向展开”
指令6:“请以不同角度切入这个话题,重构整个论述框架”
- 词汇替换与语言变换
指令7:“请对这段文字进行同义词替换,特别是替换常见学术用语”
指令8:“在不改变原意的情况下,用更生活化的比喻替代专业术语”
指令9:“请将这段描述转换为更具创新性的表达,避免常见表述模式”
基础重写指令(1-10) "请用更口语化、个人化的表达重写这段内容" "在保持原意的前提下,彻底改变句式和表达方式" "请以不同的逻辑结构重新组织这段内容" "将这段学术文本转换为更具对话感的表达" "请用更生动的比喻和例子重新阐述这个概念" "替换所有常见学术词汇,使用更鲜活的表达" "将这段内容改写成我自己的研究发现和思考" "请把这个论点转换为问题探索的形式" "在重写中加入一些思考过程和个人感悟" "将这段内容重新架构为"问题-分析-结论"的形式" 进阶降重指令(11-20) "请用三个不同的小例子来具体说明这个抽象概念" "将这段论述改写为包含个人研究经历的叙述" "请以相反的论证方向重构这个论点,然后再回到原结论" "用更具探索性和不确定性的语气重写这段内容" "将这段内容改写为含有自我质疑和反思的风格" "请添加一些细节描述和场景重现来丰富这个论点" "用更具时代特色的表达方式重写这段内容" "将这个观点放在特定历史背景下重新诠释" "请用反问和设问的修辞手法重构这段内容" "将抽象理论与具体社会现象相结合进行重写" 专业降AI率指令(21-30) "请加入一些有意识的表达不完整和思考跳跃" "在重写中适当添加一些个人化的情感表达" "请使用一些非常规但合理的词语搭配" "将这段内容重写为包含多层递进关系的结构" "用更迂回曲折的方式表达这个简单概念" "请添加一些看似偏离主题但最终能呼应的内容" "在重写中故意留下一些需要读者自行连接的逻辑" "用更具创造性和独特性的角度切入这个话题" "在学术性表达中融入一些日常生活的观察" "请将这段内容重写成包含个人思维发展过程的叙述" 深度改写指令(31-40) "请将这个观点放在更广阔的社会文化背景下重新阐释" "用多学科交叉的视角重新审视这个问题" "将西方理论框架下的论述转换为中国文化语境" "请用具有时代感的新词和表达重构这段内容" "将理论分析与实际案例相结合进行深度改写" "用批判性思维的方式重新审视这个既定观点" "请加入一些看似矛盾但实则互补的观点" "将线性叙述改为螺旋式上升的论证结构" "用更具哲学思辨色彩的语言重写这段内容" "请以辩证的方式重新构建这个论点" 顶级技巧指令(41-50) "将这段内容改写为包含个人学术成长经历的反思" "用'思想实验'的方式重新呈现这个观点" "请添加一些有创见的问题,引发读者思考" "将这段内容重构为包含多层次递进关系的结构" "用更具文学性和想象力的语言重写这段学术内容" "请以'我曾经认为...但现在发现...'的结构重写"### 内容优化方法

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)