从浅到深了解线性回归算法
线性回归算法
什么是线性回归呢?
简单来说 y = kx+b 就是一个线性回归方程,当然这只是线性回归的冰山一角.
那么对应AI术语的话 线性回归就是 将一个或者多个特征和标签的线性关系用正规方程去表示.
正规方程
什么是正规方程呢?
简单理解 就是一元n次和多元n次方程.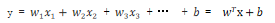
对应sklearn模块中的sklearn.linear_model.LinearRegression
正规方程的优缺点?
优点就是计算是一步到位,若有解,计算是相当准确的.
缺点:
单特征可能好计算,但是多特征数据量多的情况下使用正规方程计算量是相当庞大的,对其求导,求偏导,
最后变换到矩阵运算,而且计算到最后不一定有解,即矩阵不一定有逆矩阵.
多元的最终解: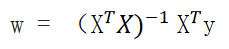
损失函数
损失函数本质是去衡量预测值与真实值误差效果的函数
损失函数有多种,概述几个常见的损失函数:
-
最小二乘法 LS 误差平方和
公式: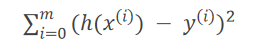
其中sklearn.linear_model.LinearRegression默认使用的损失函数就是最小二乘法. -
均分误差 MSE 平均误差平方和
公式: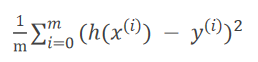
-
平均绝对误差 MAE 平均绝对值误差和
公式: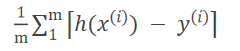
梯度下降法
梯度下降法就是沿着梯度下降的方向求解极小值.
步骤: 设置步长(也叫学习率),移动步长到下一个位置,然后环顾四周,查看是否为最低,
若不是找到最陡的方向,然后移动步长,一直循环直到移动到最低点位置.
梯度: 梯度就是某一点的导数或者偏导数
梯度的方向: 单特征就是函数增长的方向,多特征分量的向量方向
公式: 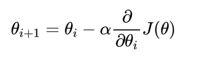
分类
- 全梯度下降法 FGD
顾名思义就是每次迭代使用所有样本的梯度值,训练速度慢,但是准确 - 随机梯度下降法 SGD
每次迭代使用随机的一个样本的梯度值,简单高效但是不稳定,容易被局部最优解迷惑
对应sklearn.linear_model.SGDRegressor - 小批量梯度下降法 MBGD
每次迭代使用小批量样本的梯度值,结合FGD和SGD的优点
正规方程VS梯度下降法
- 正规方程若有解计算是一步到位的,而梯度下降法需要进行迭代
- 正规方程一般适用于特征少的小样本的场景,梯度下降方法适用噪杂,特征多的大数据的场景
- 正规方程是没有学习率,梯度下降法有学习率
线性回归的评估方法
评估方法是在模型测试测试集时使用.
-
MSE 均方误差
公式: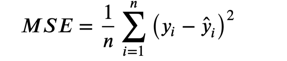
对应sklearn.metrics.mean_squared_error模块 -
RMSE 均方跟误差
公式: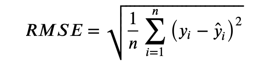
对应sklearn.metrics.root_mean_squared_error模块 -
MAE 平均绝对误差
公式: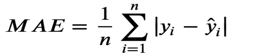
对应sklearn.metrics.mean_absolute_error模块
拟合相关知识
欠拟合
模型欠拟合的表现为在训练集表现差,测试集也差
产生原因: 模型太过简单,特征学少了.
解决方法:
- 增加特征
- 手动添加多项式特征值使用numpy.hstack(tup)去水平增加多项式特征
过拟合
模型过拟合的表现为在训练集表现好,测试集也差
产生原因: 模型太过复杂,特征学多了.
解决方法:
- 减少特征
- 使用正则化去降低特征的权重
正则化
在模型训练时,数据中有些特征影响模型复杂度、或者某个特征的异常值较多,
所以要尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化。
正则化分为两类L1,L2
L1 Lasso回归
对应sklearn.linear_model.Lasso
L1正则化,在损失函数中添加L1正则化项
公式: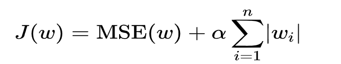
- α 叫做惩罚系数,该值越大则权重调整的幅度就越大,即:表示对特征权重惩罚力度就越大
- L1 正则化会使得权重趋向于0,甚至等于 0,使得某些特征失效,达到特征筛选的目的
L2 岭回归 Ridge
对应sklearn.linear_model.Ridge
计算本质于L1差不多,但是他不能使权重等于0.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)