【AI神器】RAG-Anything:一键搞定PDF/Word/Excel/PPT/图片,小白程序员也能构建企业级知识库!
RAG-Anything是解决多模态RAG系统数据清洗痛点的开源项目,支持全格式文档处理、高保真解析、专业内容分析、多模态知识图谱和混合检索。基于asyncio设计,安装简单,但需一定资源支持。对处理复杂文档的企业级知识库开发,是全面且值得考虑的技术选型。
简介
做过知识库的朋友都知道,最头疼的永远不是向量数据库选哪个,也不是大模型用哪家,而是数据清洗。
尤其是当你面对一堆 PDF、Word、Excel、PPT,里面还夹杂着复杂的表格、公式、甚至是截图的时候,那种绝望感,谁做谁知道。大多数现有的 RAG 方案,遇到纯文本还好,一旦涉及多模态内容,基本都在“盲人摸象”。
RAG-Anything 就是为了解决这个痛点而生的。这货最牛的地方在于,它构建了一套端到端的多模态管道,不管你丢给它什么——PDF、Office 文档、图片、甚至是包含复杂公式的科研论文,它都能给你“吃干榨净”,然后通过智能检索,回答你的各种刁钻问题。
它的架构非常清晰,主打一个“全能”:
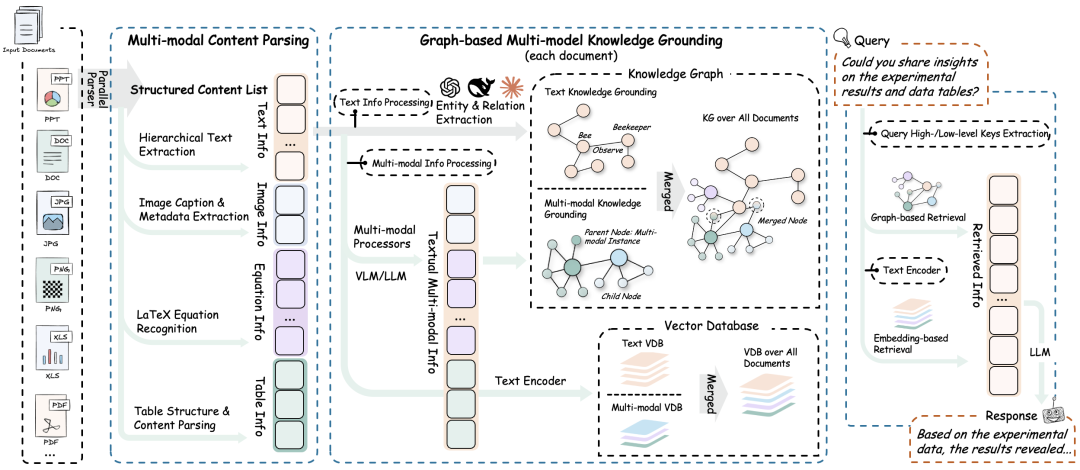
RAG-Anything Framework
核心功能与特点:
- 全格式通吃:PDF、Word、PPT、Excel、图片,统统不在话下。这一点对企业级应用太重要了。
- 高保真解析:集成了 MinerU(这可是个好东西),能够精准还原文档结构,不会把好端端的表格解析成乱码。
- 专业级内容分析:这就很硬核了,它有专门的处理器来对付图片、表格和数学公式。以后问它“图 3 中的趋势说明了什么”,它真能看懂图回答你。
- 多模态知识图谱:自动把文本和图片里的实体提取出来,建立关系。这比单纯的向量检索要聪明得多。
- 混合智能检索:结合了文本和多模态内容的检索能力,不再是“看图说话”那么简单,而是真正的理解。
安装
安装非常简单,官方提供了 PyPI 包,直接 pip 一把梭。
# 基础安装pip install raganything# 如果你想火力全开,支持所有格式(强烈推荐)pip install 'raganything[all]'
注意:如果你要处理 Office 文档(.doc, .docx 等),系统里得有 LibreOffice。
- Mac 用户:
brew install --cask libreoffice - Ubuntu 用户:
sudo apt-get install libreoffice
使用
RAG-Anything 的代码风格非常简洁,基于 asyncio,一看就是为了高性能服务设计的。
下面是一个端到端的完整示例,展示了如何配置和运行:
import asynciofrom raganything import RAGAnything, RAGAnythingConfigfrom lightrag.llm.openai import openai_complete_if_cache, openai_embedfrom lightrag.utils import EmbeddingFuncasyncdef main(): # 你的 API Key api_key = "sk-xxxxxxxx" # 1. 初始化配置,这就叫“既要又要”:图片、表格、公式全都要 config = RAGAnythingConfig( working_dir="./rag_storage", parser="mineru", # 使用强大的 MinerU 解析器 enable_image_processing=True, # 开启图片处理 enable_table_processing=True, # 开启表格处理 enable_equation_processing=True# 开启公式处理 ) # 2. 这里省略了 LLM 和 Embedding 函数的定义, # 实际上就是配置 OpenAI 兼容的接口,支持 DeepSeek、GPT-4o 等 # ... (代码省略,保持文章简洁) # 3. 初始化 RAG 引擎 rag = RAGAnything( config=config, llm_model_func=llm_model_func, vision_model_func=vision_model_func, # 多模态需要视觉模型 embedding_func=embedding_func, ) # 4. 一键处理文档 # 不管你是 PDF 还是 PPT,往里丢就行 await rag.process_document_complete( file_path="./my_complex_paper.pdf", output_dir="./output", parse_method="auto" ) # 5. 见证奇迹的时刻:混合检索 # 它可以同时结合文本和图片内容来回答 result = await rag.aquery( "图 2 展示的实验结果说明了什么?结合表格数据分析一下。", mode="hybrid" ) print("回答:", result)if __name__ == "__main__": asyncio.run(main())
异构数据处理设计机制
我简单翻阅了一下它的源码和技术报告,RAG-Anything 在处理异构数据上的策略是:
- 分而治之:专门的管道处理图片,专门的管道处理文本。
- 多模态对齐:它不仅仅是“读”图,而是把图里的信息转化成向量,和文本向量在同一个空间里对齐。
- 知识图谱增强:这一点很有前瞻性,它试图理清“图”和“文”之间的逻辑关系,而不是割裂地看。
不过,也要提个醒(避坑指南):
- 资源消耗:因为引入了 MinerU 和多模态模型(如 GPT-4o 或开源的 VLM),这货跑起来对显存或者 API 额度是有一定要求的
- 依赖环境:安装
LibreOffice和一堆 Python 依赖(尤其是由MinerU引入的一大堆视觉库)可能会让你的环境配置稍微折腾一下。建议用 Docker 或者 Conda 起个干净环境。
总结
RAG-Anything 是一个非常有野心的项目,它试图解决 RAG 领域最难啃的大一统问题 —— 多模态异构数据的统一处理。
如果你正在开发企业级知识库,或者需要处理大量包含图表、公式的专业文档,RAG-Anything 绝对值得你加入技术选型列表。它可能不是最轻量的,但绝对是目前开源界处理复杂文档最“全面”的方案之一。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献689条内容
已为社区贡献689条内容

所有评论(0)