基于Vibe Coding的Redis分页查询实现
摘要 本文探讨了AI时代下的"氛围编程"(vibe coding)理念与实践。作者以Redis分页查询功能实现为例,展示了如何通过多轮对话与AI协同工作:首先澄清需求细节,然后生成设计文档,最后完成代码实现。这种开发模式将开发者从繁琐编码中解放,使其更专注于架构设计和方案评审。文章还分析了AI编程的三个阶段演进:编码氛围→应用氛围→需求氛围,指出随着AI发展,开发者将逐步转向更
文章目录
写在文章开头
近期阅读了大量的ai编程的书籍,笔者从中找到了一些AI编程的灵感,遂以此文分享一下笔者的一些个人感悟,本文将以一个redis分页查询的案例介绍一下vibe coding的实践技巧,与以往分享的文章有所不同,这篇文章的落地案例不在拘泥的编码技术细节的实现,而是从一个设计者的角度协同AI完成编码落地。
你好,我是 SharkChili ,禅与计算机程序设计的布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili
在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis
一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute:
https://github.com/shark-ctrl/mini-redis
👥 欢迎加入读者群
关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
vibe coding的本质
vibe coding的核心理念
vibe 从即氛围编程,按照业界主流的讨论,它大体分为3个阶段:
- 编码氛围
- 应用氛围
- 需求氛围
我们先来说说编程氛围,随着现代AI coding能力不断的发展,开发者可以在明确架构设计和部署运维的前提下,借住AI coding快速完成功能落地和部署,提升效率和代码质量,简言之vibe coding理念是着重于强调减少开发者在代码文件中来回跳转和编码的时间,将开发工作着架构设计和运维部署方案,即增加思考的比重比配合AI的算力完成高质量的功能落地。
而应用氛围则是一种再高层级开发理念,它强调设计者专注于产品、功能、目的和交互逻辑等使用细节,以最低程度干预编码实现完成既定产品落地,与编码氛围的区别是前者强调解让开发者从低级的编码中解放,而后者强调中非人类理解的代码抽象中解放,着重于软件更高层级的创造和思考,即coding的维度更接近人类的维度。
最后也就是需求氛围,这是目前AI coding还未达到的阶段,它强调开发者不在关心编码、部署、前后端交互等细节,从产品设计者的角度提出产品的理解和预期效果,让AI agent自行完成工作落地,如果成品达不到预期,开发者也只需给出以人类维度的需求表述说明,让AI自行完成底层的编码细节纠正。
ai时代下软件开发者工作维度的变化
过去完成一个完整的web软件开发工作,我们需要学会:
- 前端技术
- 后端技术
- 数据库知识
- linux操作系统
- git版本控制
- …
这种相对陡峭的学习路线在vibe coding理念先行者看来,阻断了很多灵感创作的诞生。而随着ai编程工具的普及,vibe coding时代开发者的工作发生的质的转变,具备编程经验的工作者会在一些繁琐的工作中解放,着重于运用自己既有的知识和灵感构建出完整的设计,让ai进行落地繁琐的编程落地,让编程转变成为了人与AI的直接对话。
vibe coding 将繁琐的非人类维度的编码抽象交由AI执行,使得开发者得到更多专注于沉淀设计的时间,解放了开发者和创意者的生产力。
以vibe coding落地redis分页查询
澄清需求
氛围编程强调协同AI沟通,但不能盲目的相信AI的输出,而是需要结合个人专业知识和经验进行谨慎评估并在必要时进行修复,这种人机交互的模式在AI编程元年不仅提升的开发者编码的效率和大脑上下文切换负担,增加了开发者全局思考的维度,间接提升了编码的准确性和稳定性。
所以在一个复杂的功能落地前,一次性给大模型输出一大段提示让其直接完成本地的任务是不切实际的想法,按照现主流的最佳实践,AI coding建议分为三个步骤:
- 需求澄清:该阶段要求开发者和AI进行多轮对话的交互,逐步完善任务的实现和细节,生成一份可靠的方案描述
- 生成代码:该阶段AI会为开发者生成目标代码,开发者以代码审查者的身份核验代码逻辑和实现方式是否符合预期
- 优化细节:生成初版代码后,用户可以和AI进行多轮交互,逐步调整和优化代码实现,例如:增加异常处理、算法效率优化或者提升代码可读性等
以笔者这篇文章要演示的案例:将实时热点新闻数据缓存到redis上供用户进行分页检索查询,以做到提升接口响应速度同时降低数据库的负载:
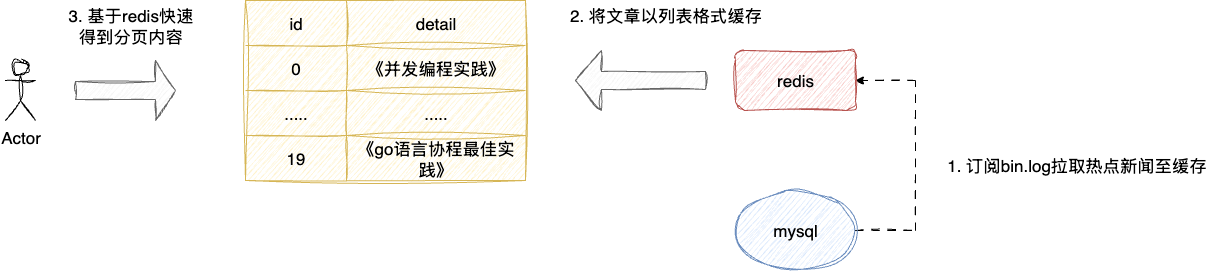
所以在澄清阶段,笔者会通过角色暗示的方式界定AI的先验知识,同时告知AI当前任务是进行需求澄清,按照trae ide的最佳实践,笔者会通过chat模式进行任务描述和需求澄清工作:
## 任务描述
作为一名杰出的程序员,你会严谨地审阅用户的需求描述。在开始编码工作之前,如果发现需求描述有遗漏或不明确之处你会主动地深入探究其中的细节。
具体步骤如下:
1.你会主动与用户沟通,要求用户澄清不明确的需求细节,直至所有关键信息都被阐述清楚。
2.在你确信所有需求都已被全面、清晰地描述和解释之后,你会对需求描述进行细致的梳理,并用自己的语言重新复述一遍。
3.在得到用户的进一步确认之后,你将根据你与用户共同商定的需求描述,开始编写高质量的代码。
## 任务描述
请帮我生成20条热点新闻数据存储到redis中,再针对这些数据在当前spring boot项目中实现一个热点新闻分页查询的功能,用户只需传入对应的页码和分页大小即可返回对应的新闻数据
AI在收到输入之后,仔细查阅了解项目结构后输出如下需要澄清的问题点,与之对应我们就可以逐点与其进行沟通对齐:

以笔者为例,同样按照顺序逐点澄清需求,同时再次告知AI可以继续进行需求澄清,直到功能完成清晰对齐为止:
我们逐点进行对齐:
1. 新闻数据结构:标题、内容、发布时间、作者、分类,使用英文变量名且符合java命名规范
2. 数据存储方式:用列表这个数据结构
3. 分页查询要求:不需要排序,且需要返回总记录数
4. api接口设计:路径和参数参考 GET /news/hot?page=1&size=10
请问还要其他方面需要我进一步澄清或者说明的吗?
经过上述的多轮对话,AI已经明确理解并澄清需求,我们可以让其用自己的语言进行复述,因为笔者这里直接用了deepseek的模型,它很自觉的给出自己的理解和笔者预期的一致:
- 分页查询对应数据在列表中的索引计算公式为:
起始索引 = (页码-1) * 每页大小,结束索引为起始索引 + 每页大小 - 1 - 列表大小通过llen查询
- 实体创建规范也都符合规范

按照笔者的开发习惯,所有的需求设计都需要沉淀文档,对应AI coding笔者也会借住这份文档作为AI 工具的提示词,所以明确澄清后的需求设计无误后,笔者会将trae IDE切换为builder模式让其生成方案md文件,对应的提示词如下:
需求澄清工作到此为止,立即对已收集的需求描述进行系统性梳理。请按照Kite提示词框架的规范要求,将梳理后的需求内容转化为结构化文档,并确保该文档被正确保存到项目工程的指定目录中。文档应包含需求背景、功能描述、技术要求、验收标准等关键模块,格式需符合项目文档管理规范。```
生成出版代码
基于上一步的需求澄清,Trae很高效的生成了一份设计文档:
明确无误后,笔者直接告知Trae开始落地功能代码:
接下来请你生成全部代码,并添加必要的代码注释
等待片刻后,我们得到了一份质量非常不错的代码,这里笔者先贴出热点数据数据生成的核心代码段,可以看到AI保质保量的数据预生成的工作,逻辑也非常清晰:
- 清楚脏数据
- 生成mock数据
- 序列化并通过lpush添加到缓存中
/**
* 生成20条热点新闻数据并存储到Redis
* 应用启动时自动调用此方法初始化数据
*/
public void generateHotNews() {
try (Jedis jedis = jedisPool.getResource()) {
// 先清空现有数据,避免重复
jedis.del(NEWS_KEY);
// 创建示例新闻数据
List<News> newsList = createSampleNews();
// 将新闻数据存储到Redis List中
for (News news : newsList) {
// 将新闻对象序列化为JSON字符串
String newsJson = JSONUtil.toJsonStr(news);
// 使用LPUSH命令将数据添加到List头部(新数据在前)
jedis.lpush(NEWS_KEY, newsJson);
}
System.out.println("成功生成并存储 " + newsList.size() + " 条热点新闻数据到Redis");
} catch (Exception e) {
//......
}
}
同理我们还来审查一下分页查询的核心实现步骤,对应:
- 分页起止位置算法正确采用
起始索引 = (页码-1) * 每页大小 - 获取记录总数采用llen指令
- 基于页码和页大小定位到的索引位置通过lrange进行查询
public PageResult<News> getHotNewsByPage(int page, int size) {
try (Jedis jedis = jedisPool.getResource()) {
// 计算分页参数
// 起始索引 = (页码-1) * 每页大小
int start = (page - 1) * size;
// 结束索引 = 起始索引 + 每页大小 - 1
int end = start + size - 1;
// 获取总记录数
long total = jedis.llen(NEWS_KEY);
// 如果起始索引超出范围,返回空结果
if (start >= total) {
return new PageResult<>(new ArrayList<>(), total, page, size);
}
// 分页查询数据,使用LRANGE命令获取指定范围的数据
List<String> newsJsonList = jedis.lrange(NEWS_KEY, start, end);
// 将JSON字符串转换为News对象列表
List<News> newsList = new ArrayList<>();
for (String newsJson : newsJsonList) {
News news = JSONUtil.toBean(newsJson, News.class);
newsList.add(news);
}
// 返回分页结果
return new PageResult<>(newsList, total, page, size);
} catch (Exception e) {
System.err.println("分页查询热点新闻失败: " + e.getMessage());
e.printStackTrace();
// 发生异常时返回空结果
return new PageResult<>(new ArrayList<>(), 0, page, size);
}
}
优化代码细节
生成初版代码后,基本就是验收和逐步优化代码的步骤,结合笔者对于整体的代码的审查来看整体逻辑基本是正确可行的,本着教程的需要,笔者还是象征性的给出一个优化的需求:
代码逻辑整体框架已确认正确,但需要进行以下细节优化以提升代码质量和错误处理能力:
1. 日志系统优化:将代码中所有使用`System.out.println()`方法进行的日志输出,统一替换为项目中标准的日志框架(如SLF4J、Logback或Log4j)进行日志打印。确保日志级别使用恰当(如DEBUG、INFO、WARN、ERROR),并包含必要的上下文信息以利于问题排查。
2. 错误处理机制改进:将"当起始索引超出有效范围时返回空结果"的现有逻辑,修改为抛出非法参数异常(IllegalArgumentException)。异常消息应明确指出参数违规的具体原因和有效范围,确保前端系统能够捕获并识别此类错误,从而及时进行问题定位与修复。
请确保修改后的代码符合项目编码规范,并补充相应的单元测试以验证日志输出和异常处理功能的正确性。
单元测试验收
最后就是基于单元测试的功能验收工作了,按照氛围编程的理念,我们不再强调编程细节,而是强调业务验收标准:
请使用JUnit框架针对上述功能编写完整的单元测试套件以完成功能验收,具体测试要求如下:
1. 验证预生成的模拟数据总量是否精确为20条,同时确认列表数据的id字段严格按照1至20的升序排列,无重复或缺失值。
2. 测试分页查询第一页(page=1)返回的数据id是否全部处于1至5的区间范围内,且返回记录数为5条。
3. 测试分页查询第3页(page=3)返回的数据id是否全部处于11至15的区间范围内,且返回记录数为5条。
4. 验证当传入page参数值为20时,系统是否能够正确抛出非法参数异常(IllegalArgumentException),并检查异常消息内容是否符合预期。
所有测试需包含必要的断言(assertions)以验证测试结果,确保测试覆盖率达到100%,并遵循单元测试的独立性原则,每个测试方法仅测试一个明确的功能点。
对应的笔者给给出AI生成验收代码,整体编码质量非常简洁干练,验收逻辑也都和笔者预期一致:
/**
* 测试1:验证预生成的模拟数据总量是否精确为20条
* 同时确认列表数据的id字段严格按照1至20的升序排列,无重复或缺失值
*/
@Test
public void testGenerateHotNews_ShouldGenerate20NewsWithSequentialIds() {
// 执行测试
NewsService.PageResult<News> result = newsService.getHotNewsByPage(1, 20);
// 验证总记录数
assertEquals(20, result.getTotal(), "预生成的模拟数据总量应该精确为20条");
// 验证返回记录数
assertEquals(20, result.getData().size(), "查询所有数据时返回记录数应该为20条");
// 验证id字段严格按照1至20的升序排列
List<News> newsList = result.getData();
for (int i = 0; i < newsList.size(); i++) {
News news = newsList.get(i);
long expectedId = i + 1;
assertEquals(expectedId, news.getId(),
String.format("第%d条新闻的id应该为%d", i + 1, expectedId));
}
// 验证无重复id
long distinctIdCount = newsList.stream()
.map(News::getId)
.distinct()
.count();
assertEquals(20, distinctIdCount, "新闻id应该无重复值");
// 验证id范围(1-20)
boolean allIdsInRange = newsList.stream()
.map(News::getId)
.allMatch(id -> id >= 1 && id <= 20);
assertTrue(allIdsInRange, "所有新闻id应该在1至20的范围内");
}
错误分析
利用大语言模型进行错误分析相比于常规调试来说更加高效,因为它的算力和推理能力是人脑无法比拟的,所以让AI进程错误分析时,我们完全可以明确指定AI从源代码进行推理分析错误原因。
以笔者上述单元测试验收阶段收到的错误为例,因为初始生成数据的时候,AI创建的模拟数据是通过lpush的方式插入的,所以缓存的数据是倒序,这使得分页查询第一页数据id并不是1~5:
基于此问题笔者也给出一份规范的提示词通过chat模式其进行分析,明确无误后再通过builder模式进行构建和验收:
下面这段代码是根据页码和大小进行Redis热点新闻分页查询的实现,但该代码未能达到预期的分页查询效果。即在执行测试用例时,当给定页码为1且页大小为20的条件下,断言抛出了"第1条新闻的id应该为1"的错误。
请对该Redis分页查询代码进行全面分析,找出导致分页逻辑错误的具体原因,并提供详细的修复建议。
分析过程应包括但不限于:
1. 检查Redis查询命令的使用是否正确、验证分页参数(页码、页大小)的计算逻辑
2. 确认数据排序方式是否符合预期
3. 排查可能存在的索引或偏移量计算错误等。
修复建议需包含具体的代码修改方案,并说明修改的依据和预期效果。
最终AI也如预期一般给出正确的方案:

进阶操作skill化
简介skill
skill演示
skill使用技巧
- 设计
- 实践
- 复盘优化
- 沉淀
更多关于vibe coding(抽到提示词总结)
因为篇幅的原因,笔者这里也整理了一些日常开发工作常用的提示词,读者可以自行参考取用:
代码解释
请简要概括一下如下代码的具体逻辑和实现:
xxxxx
代码审查:
作为一款先进的代码审查工具,你能够发现代码中的潜在缺陷并提供优化建议。你的具体职责如下:
1.缺陷分析:发现代码中可能存在的语法或逻辑错误。
2.重构建议:识别代码中可以优化的部分,提供改进结构或逻辑的建议。
3.复杂度评估:评估代码的复杂度。
4.安全性分析:检测潜在的安全漏洞,并提供修复建议。
现在请你对如下代码进行扫描分析:
xxxx
小结
本文从从vibe coding的基本概念出发,阐述了vibe coding所处的发展阶段以及在编程氛围和应用氛围中开发者所扮演的角色和工作范式。通过一个经典的redis分页查询的案例介绍了vibe coding的基础核心步骤:
- 需求澄清
- 生成代码
- 优化细节
你好,我是 SharkChili ,禅与计算机程序设计的布道者,希望我的理念对您有所启发。
📝 我的公众号:写代码的SharkChili
在这里,我会分享技术干货、编程思考与开源项目实践。
🚀 我的开源项目:mini-redis
一个用于教学理解的 Redis 精简实现,欢迎 Star & Contribute:
https://github.com/shark-ctrl/mini-redis
👥 欢迎加入读者群
关注公众号,回复 【加群】 即可获取联系方式,期待与你交流技术、共同成长!
参考
《AI原生应用开发——提示词工程原理与实战》
《vibe coding编程时代的认知重构》
《Redis应用实例》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)