《Attention Is All You Need》:Transformer 架构的开山之作
《Attention Is All You Need》:Transformer 架构的开山之作
在深度学习自然语言处理领域,2017 年发表的《Attention Is All You Need》无疑是一篇里程碑式的论文。它提出的 Transformer 架构彻底抛弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),完全基于注意力机制(Attention Mechanism)构建,不仅在机器翻译任务上取得了突破性的性能,更奠定了后续 BERT、GPT 等一系列大语言模型的基础。本文将带大家精读这篇经典论文,剖析其核心思想、技术细节与实践价值。
一、论文核心贡献
在 Transformer 出现之前,序列 transduction 任务(如机器翻译)的主流模型依赖 RNN 及其变体(LSTM、GRU)或 CNN,但它们存在固有缺陷:
- RNN 类模型:计算具有时序依赖性,无法并行化,训练效率低,且长距离依赖建模困难;
- CNN 类模型:建模长距离依赖需堆叠多层,计算复杂度随距离增长(线性或对数增长)。
论文的核心贡献在于:
- 提出Transformer 架构:首个完全基于注意力机制的序列 transduction 模型,彻底摒弃递归和卷积;
- 引入多头注意力(Multi-Head Attention):增强模型对不同子空间特征的捕捉能力;
- 设计位置编码(Positional Encoding):解决注意力机制缺乏序列顺序信息的问题;
- 实验验证:在 WMT 2014 英德、英法翻译任务中刷新 SOTA,且训练效率远超传统模型(8 块 GPU 训练 12 小时即可达到优异效果)。
二、核心技术原理
2.1 整体架构
Transformer 沿用了经典的编码器 - 解码器(Encoder-Decoder)结构,但内部层完全由注意力机制和全连接网络构成。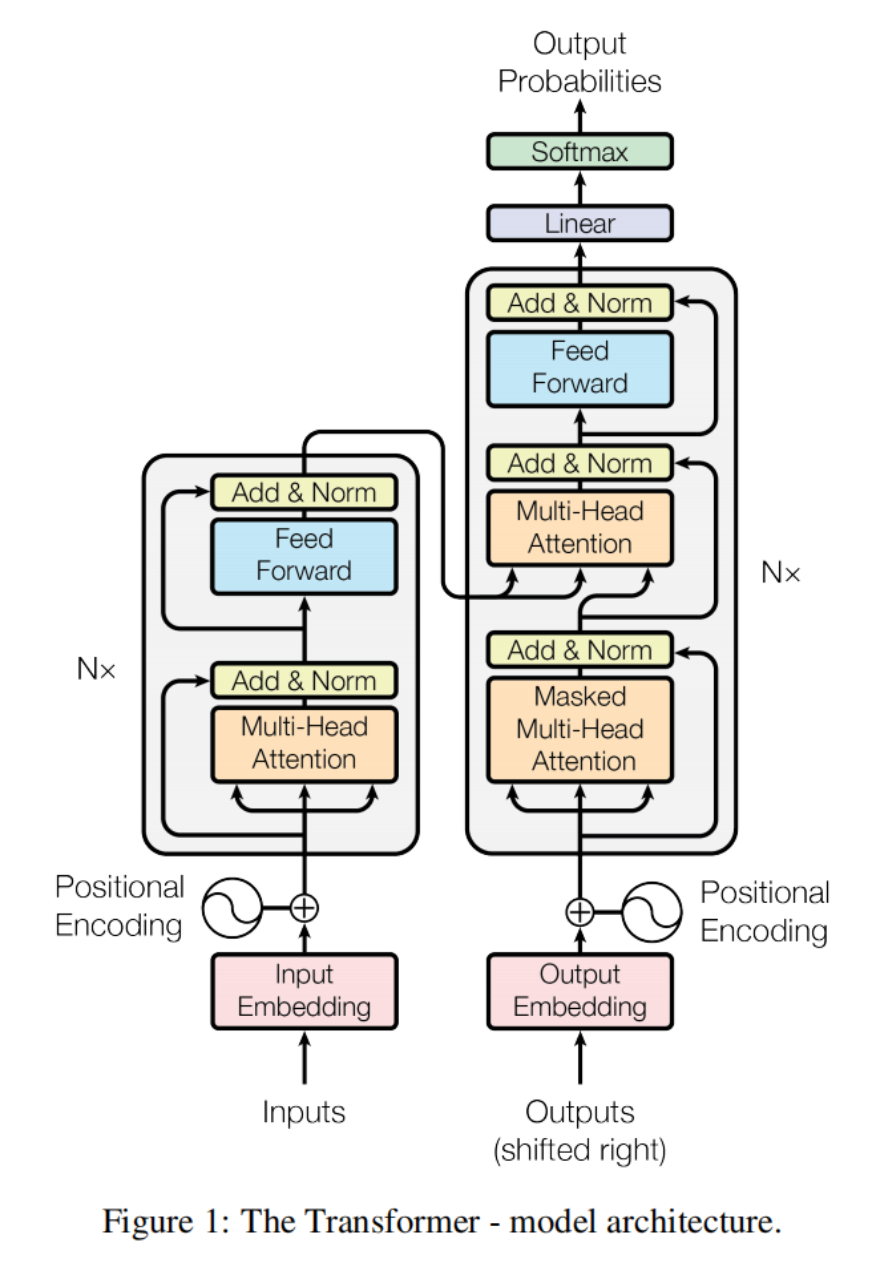
编码器(Encoder)
- 由 6 个相同的层堆叠而成,每层包含两个子层:
- 多头自注意力(Multi-Head Self-Attention):捕捉输入序列内部的依赖关系;
- 位置 - wise 全连接前馈网络(Position-wise Feed-Forward Network):对每个位置的特征独立进行非线性变换。
- 每个子层均采用 “残差连接(Residual Connection)+ 层归一化(Layer Normalization)” 结构,公式表示为: LayerNorm(x+Sublayer(x))\text{LayerNorm}(x + \text{Sublayer}(x))LayerNorm(x+Sublayer(x))
其中Sublayer(x)\text{Sublayer}(x)Sublayer(x)是子层(注意力层或前馈网络)的输出。为适配残差连接,所有子层和嵌入层的输出维度均为dmodel=512d_{model} = 512dmodel=512。
解码器(Decoder)
- 同样由 6 个相同的层堆叠而成,在编码器两层的基础上新增第三个子层:
- 掩码多头自注意力(Masked Multi-Head Self-Attention):防止预测当前位置时依赖未来位置的信息(保持自回归特性);
- 多头编码器 - 解码器注意力(Multi-Head Encoder-Decoder Attention): queries 来自前一层解码器,keys/values 来自编码器输出,实现 “对齐输入与输出”;
- 位置 - wise 全连接前馈网络。
- 掩码机制:通过将 softmax 输入中 “非法连接”(未来位置)设为−∞−∞−∞,确保预测位置iii仅依赖于iii之前的位置。
2.2 注意力机制
注意力机制的核心是将 “查询(Query)” 与 “键(Key)- 值(Value)” 对映射为输出,输出是值的加权和,权重由查询与键的兼容性计算得出。
2.2.1 缩放点积注意力(Scaled Dot-Product Attention)
论文提出的基础注意力模块,计算公式为:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
- 输入:Q∈Rn×dkQ \in \mathbb{R}^{n \times d_k}Q∈Rn×dk(查询矩阵,nnn为序列长度)、K∈Rm×dkK \in \mathbb{R}^{m \times d_k}K∈Rm×dk(键矩阵)、V∈Rm×dvV \in \mathbb{R}^{m \times d_v}V∈Rm×dv(值矩阵)
- 缩放因子 1dk\frac{1}{\sqrt{d_k}}dk1:当 dkd_kdk 较大时,QKTQK^TQKT 的元素值会过大,导致 softmax 函数进入梯度极小的饱和区,缩放可缓解此问题;
- 优势:相比加法注意力(Additive Attention),计算效率更高(可通过矩阵乘法优化)。
2.2.2 多头注意力(Multi-Head Attention)
为了让模型同时关注不同子空间的特征,将注意力机制并行执行 hhh 次(即 hhh 个 “头”),再将结果拼接并线性投影,公式为:
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_h) W^O MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
其中每个头的计算为:
headi=Attention(QWiQ,KWiK,VWiV) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
- 参数:WiQ∈Rdmodel×dkW_i^Q \in \mathbb{R}^{d_{model} \times d_k}WiQ∈Rdmodel×dk、WiK∈Rdmodel×dkW_i^K \in \mathbb{R}^{d_{model} \times d_k}WiK∈Rdmodel×dk、WiV∈Rdmodel×dvW_i^V \in \mathbb{R}^{d_{model} \times d_v}WiV∈Rdmodel×dv、WO∈Rhdv×dmodelW^O \in \mathbb{R}^{h d_v \times d_{model}}WO∈Rhdv×dmodel。
- 论文设置:h=8h = 8h=8,dk=dv=dmodelh=64d_k = d_v = \frac{d_{model}}{h} = 64dk=dv=hdmodel=64,确保总计算量与单头注意力相当。
2.2.3 注意力的三种应用场景
- 编码器自注意力:Q,K,VQ,K,VQ,K,V均来自前一层编码器输出,捕捉输入序列内部依赖;
- 解码器自注意力:Q,K,VQ,K,VQ,K,V均来自前一层解码器输出,且带掩码,确保自回归;
- 编码器 - 解码器注意力:QQQ来自解码器,K,VK,VK,V
来自编码器,实现输入与输出的对齐(类似传统 Seq2Seq 的注意力)。
2.3 位置编码(Positional Encoding)
由于 Transformer 无递归和卷积,无法天然捕捉序列的顺序信息,因此需要手动注入位置信息。论文采用正弦余弦位置编码:
PE(pos,2i)=sin(pos100002i/dmodel)PE_{(pos, 2i)} = \sin\left( \frac{pos}{10000^{2i/d_{model}}} \right)PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(pos100002i/dmodel)PE_{(pos, 2i+1)} = \cos\left( \frac{pos}{10000^{2i/d_{model}}} \right)PE(pos,2i+1)=cos(100002i/dmodelpos)
参数说明
| 符号 | 含义 | 取值范围 |
|---|---|---|
| pospospos | 序列中 token 的位置 | 0,1,…,L−10, 1, \ldots, L-10,1,…,L−1 |
| iii | 编码维度的索引 | 0,1,…,dmodel2−10, 1, \ldots, \frac{d_{model}}{2}-10,1,…,2dmodel−1 |
| dmodeld_{model}dmodel | 模型维度 | 通常为 512 |
设计原理
- 多频率编码
每个维度 iii 对应一个频率 ωi\omega_iωi:
ωi=1100002i/dmodel=10000−2i/dmodel \omega_i = \frac{1}{10000^{2i/d_{model}}} = 10000^{-2i/d_{model}} ωi=100002i/dmodel1=10000−2i/dmodel
- 当 i=0i=0i=0:ω0=1\omega_0 = 1ω0=1,高频,编码短距离关系
- 当 i=dmodel2−1i=\frac{d_{model}}{2}-1i=2dmodel−1:ωmax≈0.00001\omega_{max} \approx 0.00001ωmax≈0.00001,低频,编码长距离关系
-
相对位置编码
对于任意固定偏移 kkk,PEpos+kPE_{pos+k}PEpos+k 可以表示为 PEposPE_{pos}PEpos 的线性变换:
PEpos+k=Tk⋅PEpos PE_{pos+k} = T_k \cdot PE_{pos} PEpos+k=Tk⋅PEpos
其中 TkT_kTk 是由 cos(ωik)\cos(\omega_i k)cos(ωik) 和 sin(ωik)\sin(\omega_i k)sin(ωik) 组成的块对角矩阵。 -
泛化能力
由于正弦余弦函数定义在整个实数域,该编码可以:
- 处理任意长度的序列
- 包括训练时未见过的超长序列
与学习型位置编码的对比
| 特性 | 正弦余弦编码 | 学习型编码 |
|---|---|---|
| 参数数量 | 0 | Lmax×dmodelL_{max} \times d_{model}Lmax×dmodel |
| 泛化性 | 无限长度 | 最大长度 LmaxL_{max}Lmax |
| 训练稳定性 | 确定性强 | 依赖初始化 |
| 计算复杂度 | O(1)O(1)O(1) | O(Lmax)O(L_{max})O(Lmax) |
| 效果 | 与学习型相当 | 需要更多训练数据 |
结论:正弦余弦编码在保持性能的同时,具有更好的泛化性和零参数优势。
2.4 其他关键组件
位置 - wise 全连接前馈网络
对每个位置的特征独立进行两次线性变换和 ReLU 激活,公式为:
FFN(x)=max(0,xW1+b1)W2+b2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
- 维度:输入输出维度dmodel=512d_{model}=512dmodel=512,中间层维度dffd_{ff}dff =2048;
- 等价于 1x1 卷积:不同位置共享参数,但层与层之间参数不同。
嵌入层与 Softmax
- 输入 token 和输出 token 通过学习型嵌入层(Embedding Layer)映射到dmodeld_{model}dmodel维度;
- 嵌入层权重与解码器输出后的预 Softmax 线性变换权重共享,减少参数数量;
- 嵌入层输出需乘以dmodel\sqrt{d_{model}}dmodel,与位置编码相加后作为编码器 / 解码器的输入。
三、训练细节
3.1 数据集与批处理
- 英德翻译:WMT 2014 数据集(450 万句对),字节对编码(BPE),词汇量 37k;
- 英法翻译:WMT 2014 数据集(3600 万句对),词片编码(WordPiece),词汇量 32k;
- 批处理:按序列长度分组,每个批次包含约 25k 个源 token 和 25k 个目标 token。
3.2 优化器与学习率调度
- 优化器:Adam 优化器,参数 β1=0.9\beta_1=0.9β1=0.9,β2=0.98\beta_2=0.98β2=0.98,ϵ=10−9\epsilon=10^{-9}ϵ=10−9;
- 学习率调度:
lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5) \text{lrate} = d_{\text{model}}^{-0.5} \cdot \min\left( \text{step\_num}^{-0.5}, \text{step\_num} \cdot \text{warmup\_steps}^{-1.5} \right) lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)- 前 4000 步(warmup_steps=4000)线性增长;
- 之后按步数的平方根倒数衰减。
3.3 正则化
1. 残差 Dropout:
应用位置:对每个子层输出、嵌入层与位置编码的和应用Dropout 率:Pdrop=0.1P_{\text{drop}} = 0.1Pdrop=0.1(基础模型)
2. 标签平滑(Label Smoothing):
平滑因子:ϵls=0.1\epsilon_{\text{ls}} = 0.1ϵls=0.1,牺牲困惑度(Perplexity),换取更好的泛化性和 BLEU 分数
四、实验结果
4.1 机器翻译任务
| 模型 | 英德翻译 BLEU | 英法翻译 BLEU | 训练成本(FLOPs) |
|---|---|---|---|
| 传统 SOTA(GNMT+RL Ensemble) | 26.30 | 41.16 | 1.8×10201.8 \times 10^{20}1.8×1020(英德) |
| Transformer(基础模型) | 27.3 | 38.1 | 3.3×10183.3 \times 10^{18}3.3×1018(英德) |
| Transformer(大模型) | 28.4 | 41.8 | 2.3×10192.3 \times 10^{19}2.3×1019(英德) |
- 英德翻译:大模型 BLEU 达 28.4,超此前 SOTA 2 个以上 BLEU;
- 英法翻译:大模型 BLEU 达 41.8,刷新单模型 SOTA,训练成本仅为此前模型的 1/4;
- 训练效率:基础模型 8 块 P100 GPU 训练 12 小时,大模型训练 3.5 天,远快于传统 RNN/CNN 模型。
4.2 模型变体验证
论文通过变体实验验证了关键组件的重要性:
- 多头注意力:单头注意力比最优设置低 0.9 BLEU,头数过多(如 32 头)也会导致性能下降;
- 位置编码:学习型编码与正弦余弦编码效果接近;
- 模型规模:更大的dmodeld_{model}dmodel、dffd_{ff}dff 或更多层可提升性能;
- Dropout:去除 Dropout 会导致过拟合,BLEU 下降 1.2。
4.3 泛化能力:英语 constituency 解析
将 Transformer 应用于英语句法分析任务,无需任务特定调优:
- 仅用 4 万句训练数据(WSJ 数据集):F1 分数 91.3,接近 SOTA(91.7);
- 半监督设置(1700 万句数据):F1 分数 92.7,超越多数传统模型,证明其强泛化性。
五、关键优势与影响
5.1 相比传统模型的优势
- 并行化效率高:无时序依赖,可充分利用 GPU 并行计算,训练速度指数级提升;
- 长距离依赖建模更优:注意力机制直接建模任意位置间的依赖,路径长度为常数(RNN为
O(n)O(n)O(n),CNN 为O(log(n)O(\text{log}(n)O(log(n)); - 可解释性强:注意力权重可可视化,能直观看到模型对输入序列的依赖关系(如句法结构、指代消解)。
5.2 对后续研究的影响
- 奠定大语言模型基础:BERT(双向 Transformer 编码器)、GPT(单向 Transformer 解码器)、T5(Encoder-Decoder Transformer)均基于 Transformer 架构;
- 跨模态扩展:Transformer 已被广泛应用于图像、音频、视频等领域(如 ViT、Whisper);
- 注意力机制普及:多头注意力、自注意力成为深度学习的核心组件。
六、总结与展望
《Attention Is All You Need》的核心创新在于 “用注意力替代递归与卷积”,构建了高效、并行、强表达能力的 Transformer 架构。它不仅解决了传统序列模型的训练效率问题,更开启了注意力驱动的深度学习新时代。
论文的未来研究方向也极具启发性:
- 局部注意力机制:针对超长序列优化(如限制注意力范围);
- 多模态扩展:处理文本以外的输入(图像、音频等);
- 减少生成的时序依赖性:进一步提升解码效率。
如今,Transformer 已成为 AI 领域的 “基础积木”,读懂这篇论文不仅能理解大模型的核心原理,更能把握深度学习的发展脉络。建议结合论文代码(https://github.com/tensorflow/tensor2tensor)动手实践,深入体会注意力机制的魅力!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)