大模型检索技术大揭秘!这3种损失函数哪个最强?小白也能秒懂的AI开发必看指南!
文章介绍了检索模型的三大学习方式:成对余弦嵌入损失、三元组边距损失和InfoNCE损失。无论Agent技术如何进步,底层检索模型的准确性依然关键,直接影响系统效率和成本。实验表明,InfoNCE覆盖面最广,但通过充分实验和调参,余弦嵌入损失也能达到类似效果,而三元组边距损失可能是两者的折中方案。
Agent 系统发展得这么快那么检索模型还重要吗?RAG 本身都已经衍生出 Agentic RAG和 Self-RAG 这些更复杂的变体了。
答案是肯定的,无论 Agent 方法在效率和推理上做了多少改进,底层还是离不开检索。检索模型越准,需要的迭代调用就越少,时间和成本都能省下来,所以训练好的检索模型依然关键。讨论 RAG 怎么用的文章铺天盖地,但真正比较检索模型学习方式的内容却不多见。
检索系统包含多个组件:检索嵌入模型、索引算法(HNSW 之类)、向量搜索机制(余弦相似度等)以及重排序模型。这篇文章只聚焦检索嵌入模型的学习方式。
本文将介绍我实验过的三种方法:Pairwise cosine embedding loss(成对余弦嵌入损失)、Triplet margin loss(三元组边距损失)、InfoNCE loss。
成对余弦嵌入损失
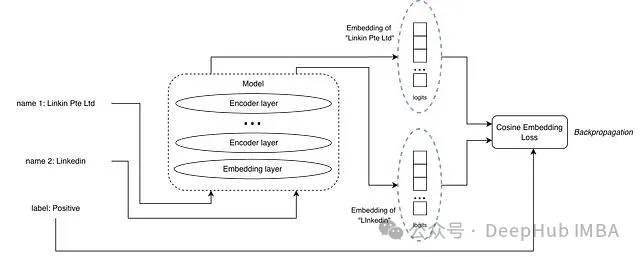
正样本对示例
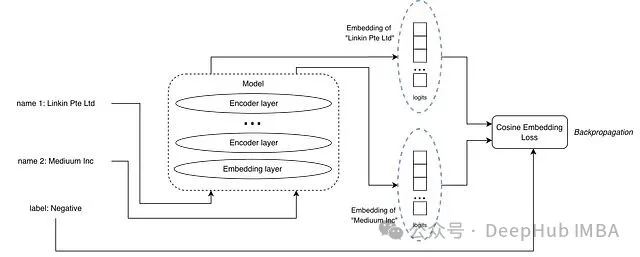
负样本对示例
输入是一对文本加一个标签,标签标明这对文本是正匹配还是负匹配。和 MNLI 数据集里的蕴含、矛盾关系类似。
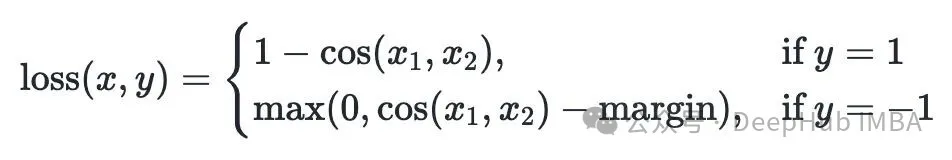
损失函数用的是余弦嵌入损失,x 和 y 分别是文本对的嵌入向量。
三元组边距损失
输入变成三个文本:一个锚文本、一个正匹配、一个负匹配。
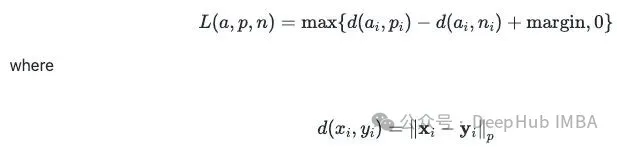
损失函数是 Triplet Margin Loss。公式里 a 代表锚文本嵌入,p 代表正样本嵌入,n 代表负样本嵌入。
InfoNCE 损失
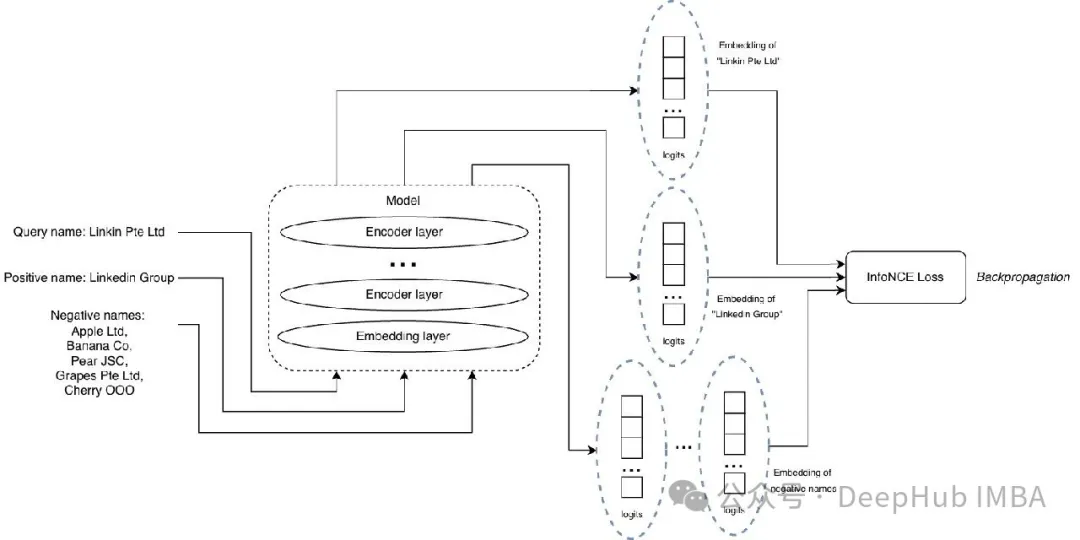
输入包括一个查询、一个正匹配、一组负样本列表。
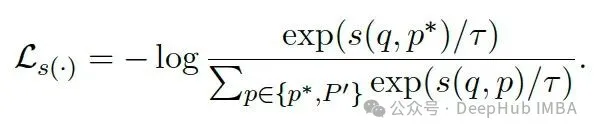
损失函数采用 InfoNCE,灵感来自 M3-Embedding 论文(arxiv:2402.03216)。公式中 p* 是正样本嵌入,P’ 是负样本嵌入列表,q 是查询嵌入,s(.) 表示相似度函数,比如余弦相似度。
比较
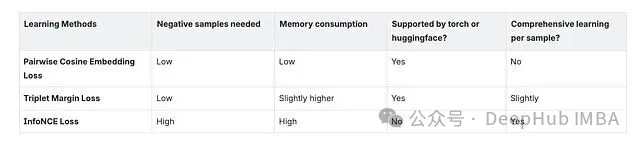
哪种方法最好?要看具体场景、数据量和算力。从我的实验来看,InfoNCE 覆盖面最广。但只要实验做得够充分、训练数据比例调得够细,余弦嵌入损失也能达到差不多的效果。三元组边距损失我没有深入探索,不过它可能是介于另外两者之间的一个折中选项。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献625条内容
已为社区贡献625条内容

所有评论(0)