刚刚,DeepSeek 开源 OCR 2:让 AI 像人一样「阅读」,准确率 91%!
刚刚,DeepSeek 开源 OCR 2:让 AI 像人一样「阅读」,准确率 91%!
最近国产 AI 扎堆更新。
这次轮到 DeepSeek。
昨天,DeepSeek 悄悄发布了 OCR 模型的升级版 DeepSeek-OCR 2,论文标题叫「Visual Causal Flow」,翻译过来是「视觉因果流」。
代码、模型权重、完整论文,全部开源。

DeepSeek-OCR 2 论文,标题「Visual Causal Flow」。
先说结论:
这个模型不再像扫描仪一样机械地从左上角读到右下角,而是根据内容语义动态调整阅读顺序。就像人读报纸会先看标题再看正文,遇到表格会按行或列理解一样。
在 OmniDocBench v1.5 基准测试上,整体得分 91.09%,比前代提升 3.73%。
阅读顺序的编辑距离从 0.085 降到 0.057,意味着新模型真的能更好地理解文档结构。
传统的视觉语言模型在处理图像时,会把图片切成一块块的视觉 token,然后按照固定的顺序投喂给模型。
这个顺序是从左上角开始,一行一行扫到右下角,就像打印机一样。
但人类不是这样阅读的。
我们读一份报告,会先看标题,再看摘要,然后跳到感兴趣的章节。遇到表格会按列或按行来理解,遇到公式会先看整体结构再看细节。
这是一种基于语义和逻辑关系的阅读方式,DeepSeek 在论文里把它叫做「因果流」。
下一步看哪里,取决于上一步看到了什么。
传统模型的机械扫描顺序,和人类的因果阅读逻辑,完全是两回事。
这就是 DeepSeek-OCR 2 要解决的核心问题。
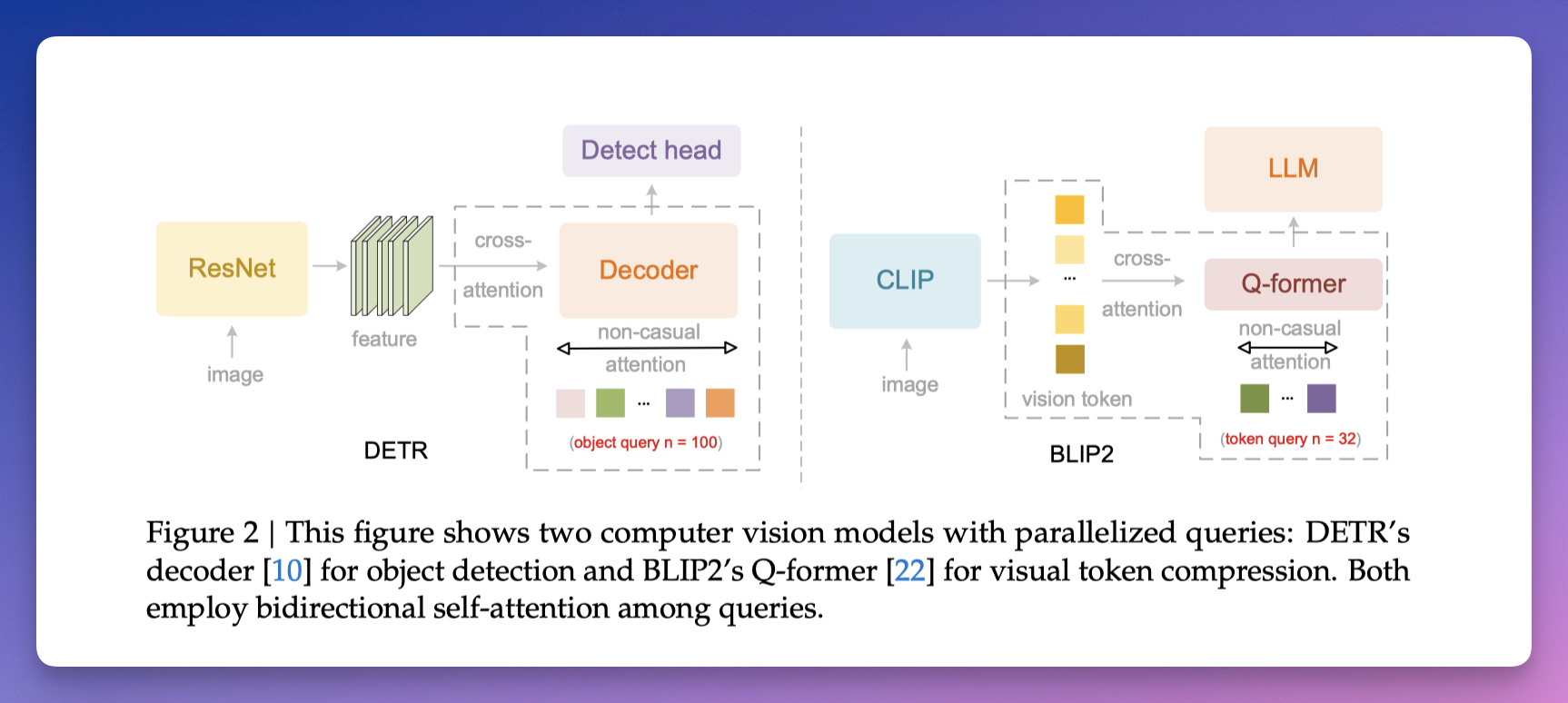
传统视觉模型架构(DETR 和 BLIP2),查询 token 之间使用非因果注意力,没有阅读顺序的概念。
新模型的核心组件叫 DeepEncoder V2。
它有一个关键改动:用一个 5 亿参数的语言模型 Qwen2-0.5B 替换了原来的 CLIP 视觉编码器。
这里引入了一套全新的处理方式。
打个比方。你拿到一份杂乱的文档,会怎么读?
先快速扫一眼,知道大概有哪些内容、在什么位置。
这是「全局感知」。
然后根据内容的逻辑关系,决定先读什么、后读什么。标题、正文、表格、注释,按理解顺序依次处理。
这是「逻辑重排」。
DeepEncoder V2 就是这么干的。
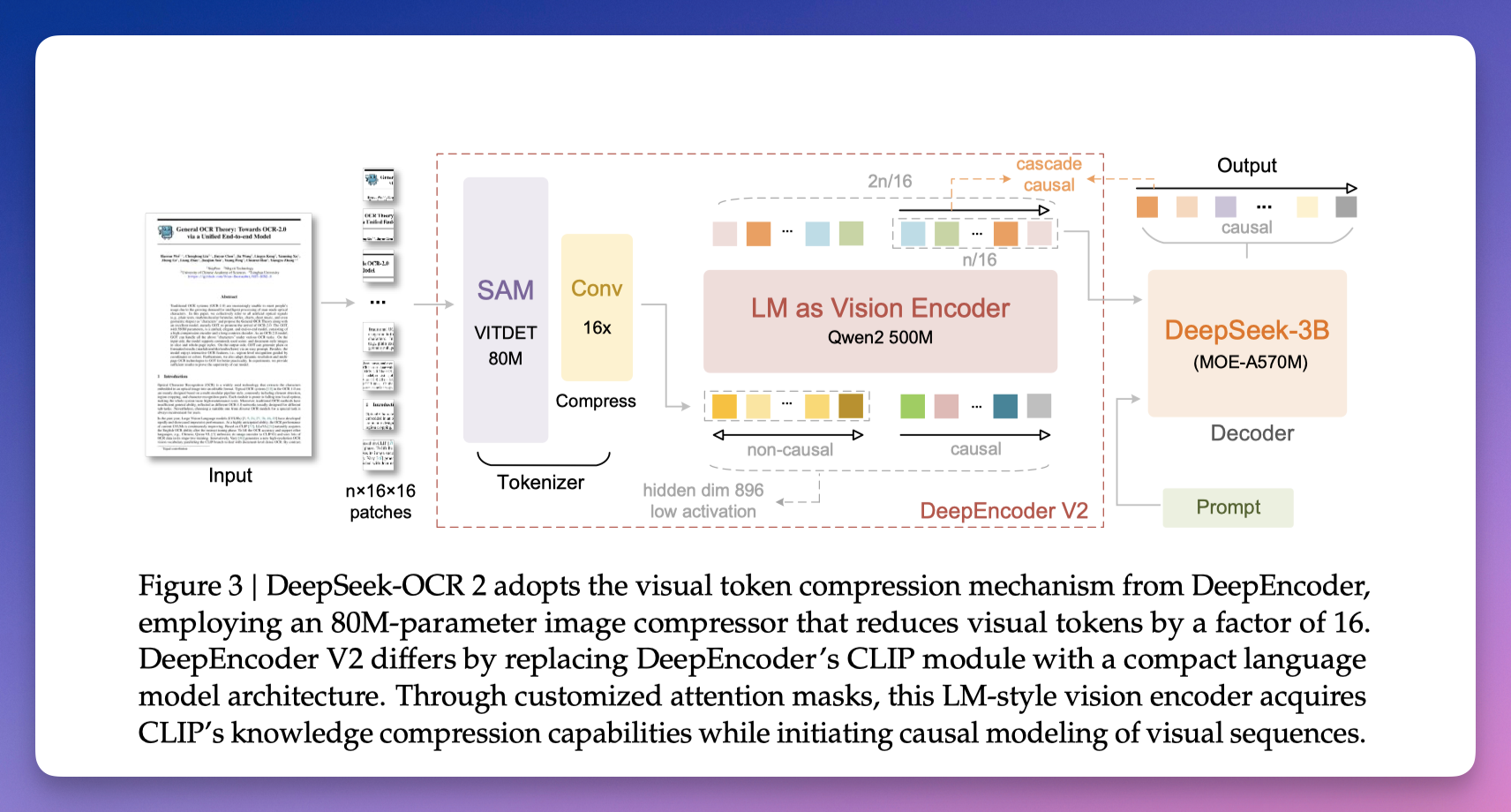
DeepSeek-OCR 2 完整架构:左侧压缩,中间 DeepEncoder V2 实现全局感知 + 逻辑重排,右侧解码器生成输出。
第一组 token 负责「全局感知」,它们之间可以互相看到,确保不漏掉任何信息。
第二组 token 负责「逻辑重排」,它们按严格的先后顺序工作。每一步只能基于前面已经处理过的内容来决定下一步该关注什么。
最终送入解码器的是第二组 token。
它们已经按语义逻辑排好了队,而不是原来那种从左上到右下的机械顺序。
DeepSeek 把这叫做「两级级联因果推理」。
先用第一级理解全局,再用第二级重排顺序。
之前说了,在 OmniDocBench v1.5 基准测试上,DeepSeek-OCR 2 整体得分 91.09%,比前代提升 3.73%。
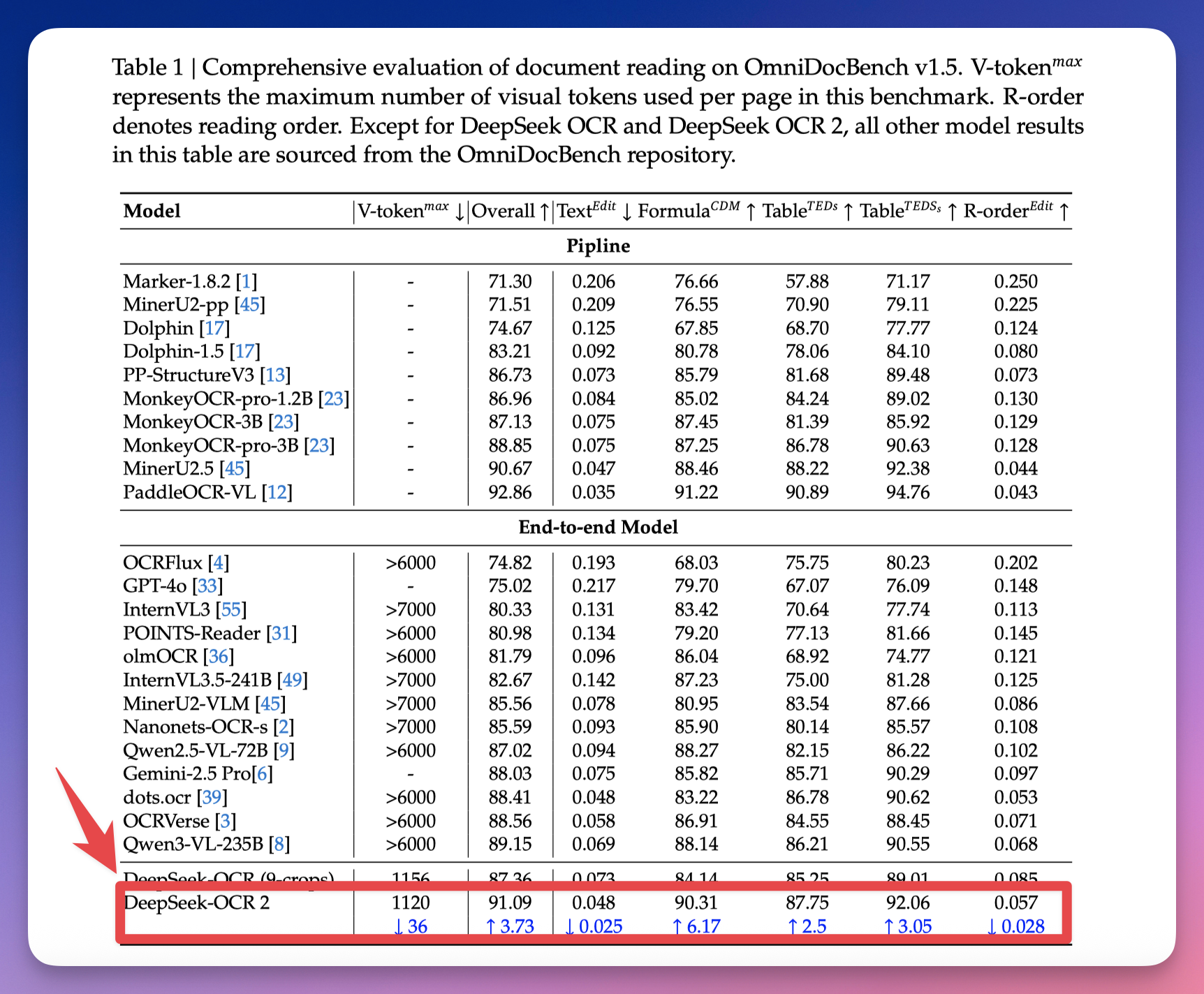
OmniDocBench v1.5 完整评测,DeepSeek-OCR 2 以 1120 个 token 达到 91.09% 准确率,超过需要 6000+ token 的竞品。
更有意思的是阅读顺序这个指标。
编辑距离从 0.085 降到 0.057。这个数字代表模型输出的内容顺序和标准顺序之间的差异,越低越好。
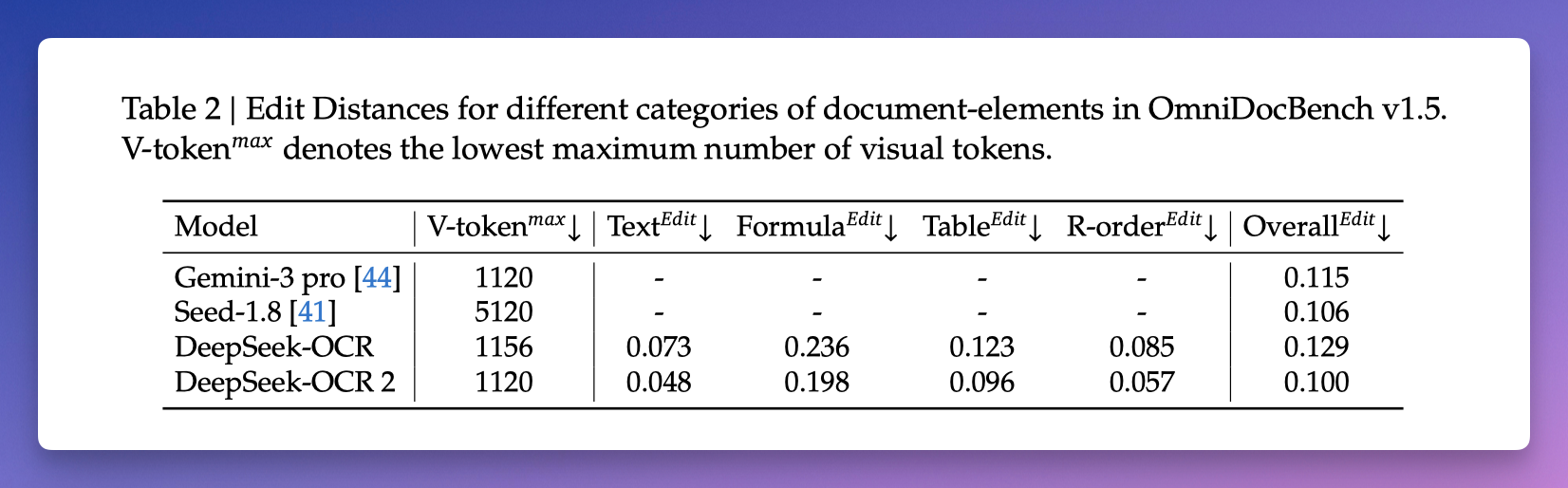
文档解析编辑距离对比,DeepSeek-OCR 2 的 0.100 优于 Gemini 3 Pro 的 0.115。
新模型不仅识别得更准,还能更好地理解文档的逻辑结构。
在相近的视觉 token 数量下,DeepSeek-OCR 2 的文档解析编辑距离是 0.100,Gemini 3 Pro 是 0.115。
DeepSeek 用的视觉 token 上限是 1120,和 Gemini 3 Pro 持平。
但很多其他 OCR 或视觉模型动辄需要 6000 甚至 7000 个 token。
高压缩率 + 高准确率,DeepSeek-OCR 2 同时做到了。
重复输出是 OCR 的常见问题,同一段内容被识别多次。
视觉因果流的引入有效缓解了这个问题。
在生产环境中,用户上传图片的重复输出率从 6.25% 降到 4.17%,批量 PDF 处理的重复率从 3.69% 降到 2.88%。

生产环境重复输出率对比,用户图片从 6.25% 降到 4.17%,PDF 从 3.69% 降到 2.88%。
但 DeepSeek-OCR 2 也不是万能的。
在报纸类文档上,识别准确率甚至略低于前代模型。原因是报纸版面密集、训练数据中报纸样本只有 25 万张。
这是端到端模型的老问题,性能高度依赖训练数据的广度与质量。
DeepEncoder V2 验证了 LLM 架构可以做视觉编码器。
同一套编码器,只需要配置不同的模态查询嵌入,就能处理文本、图像、音频。
一个统一的全模态编码器,是 DeepSeek 的下一步目标。
回看 DeepSeek 2026 开年来的动作,mHC 解决训练稳定性,Engram 实现查-算分离,现在 OCR 2 重构视觉理解。
三篇论文看似各自独立,实则指向同一个方向:
「用更聪明的架构设计,而不是更多的算力。」
参考链接
-
GitHub:https://github.com/deepseek-ai/DeepSeek-OCR-2
-
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
-
论文 PDF:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
我是木易,Top2 + 美国 Top10 CS 硕,现在是 AI 产品经理。
关注「AI信息Gap」,让 AI 成为你的外挂。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)