Kimi K2.5发布:原生多模态 + Agent Swarm,我用它把小红书「复刻」了一遍
Kimi K2.5模型发布,带来原生多模态和Agent Swarm两大突破。该模型通过15T视觉-文本联合训练,实现"看图写代码"的Coding with Vision能力,可基于图片/视频直接生成前端页面并进行视觉调试。Agent Swarm支持最多100个子智能体并行工作,复杂任务处理速度提升4.5倍。实测显示其前端审美显著提升,能高度还原小红书等复杂界面,但存在执行速度慢
Kimi K2.5发布:原生多模态 + Agent Swarm,我用它把小红书「复刻」了一遍
昨天,Kimi 发布了新模型 Kimi K2.5。
我一开始以为这会是一次“常规升级”:更大的参数、更长的上下文、更高的分数……但翻完官方技术报告后,最大的感受反而是——K2.5 更像是在补齐一个方向:
- 不只是“会看图”。而是原生多模态,从训练开始就把视觉和文本当成同一个大脑要处理的信息。
- 不只是“会用工具”。而是能把复杂任务拆成并行子任务,自己拉起一个**Agent Swarm(最多 100 个子智能体)**去跑。
- 不只是“能写代码”。而是强调 Coding with Vision:看着图片/视频写前端、查错、迭代,甚至做审美。
更关键的是:这些能力不是停留在 PPT 上。至少在我最常用的领域——前端设计——K2.5 给了我一波真实的“惊艳”。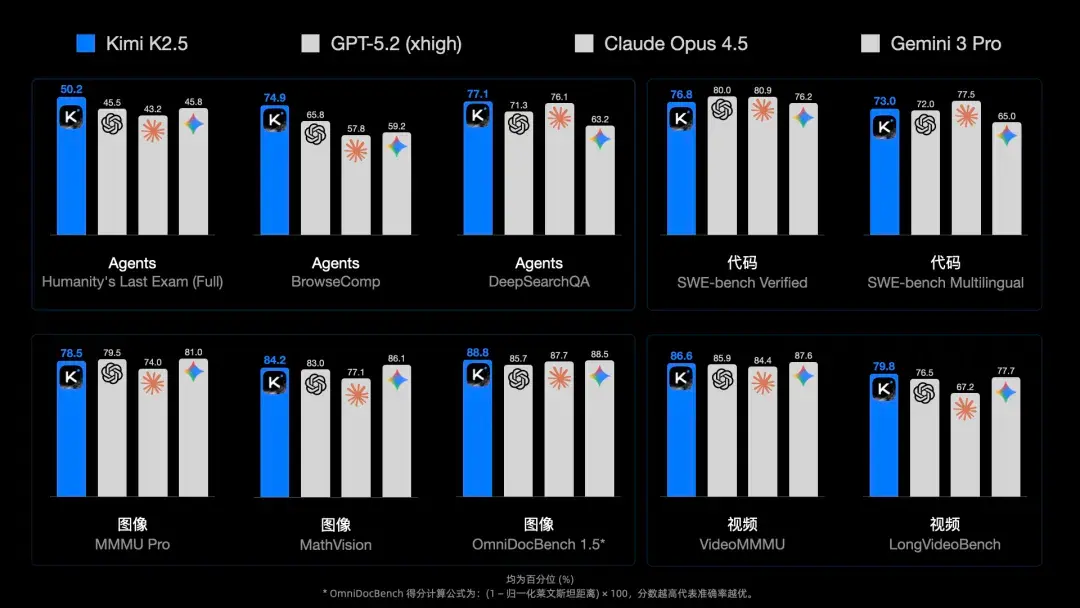
一、先看官方:K2.5 到底升级了什么?
官方报告开门见山:Kimi K2.5 是“目前最强的开源模型”。
它基于 K2 继续预训练,使用了约 15T 的混合视觉与文本 tokens,并且强调一句关键点:Built as a native multimodal model(原生多模态)。
另外,Kimi.com 和 App 也同步更新了 4 种模式:
K2.5 InstantK2.5 ThinkingK2.5 AgentK2.5 Agent Swarm (Beta)
如果你只把它当“聊天模型”,可能感知不到它的全部威力;但如果你把它当成“能执行任务的系统”,K2.5 的路线就很清晰了:
- Coding with Vision:看图/视频写代码、做视觉 Debug、把“审美”纳入迭代回路。
- Agent Swarm:不是一个 Agent 走到黑,而是并行拉起多个子 Agent 并行工作。
- Office Productivity:面向真实办公产出(文档、表格、PDF、Slides)的长链路任务。
二、Benchmark 里最扎眼的:Agent 能力和“成本”
我知道很多人看 Benchmark 会疲劳,但 K2.5 这次有两点确实值得扫一眼。
1)Agent 相关榜单:不只是“能调用工具”,而是“能把事做成”
官方拿了几个偏 agentic 的 benchmark 来展示:
- HLE-Full(含工具):K2.5(Thinking)= 50.2,对比 GPT-5.2(xhigh)= 45.5
- BrowseComp:K2.5 = 60.6(有上下文管理策略的版本更高)
- DeepSearchQA:K2.5 = 77.1
这类榜单的意义不在于“谁多 1 分”,而在于它更接近真实工作流:
- 有信息缺口
- 需要多步推理
- 需要工具来验证/检索/执行
- 最终要交付一个可用结果
换句话说,它衡量的是“能不能把任务闭环”。
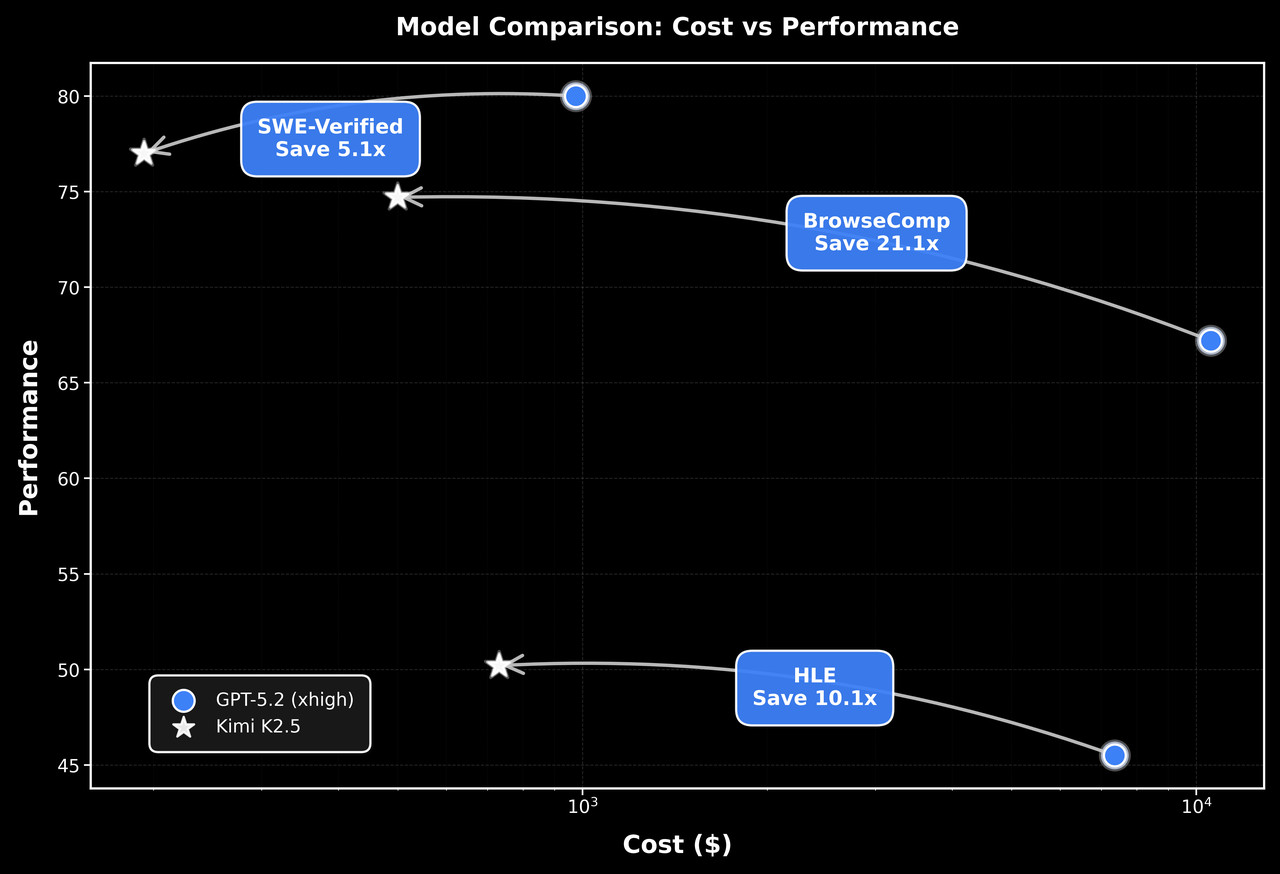
2)成本(token cost)也被单独拿出来讲
报告里专门放了一张图,强调 K2.5 在几个 agent benchmark 上能做到“更强 + 更便宜”。
这一点对普通用户的体感就是:
- 同样一个复杂任务,模型更愿意“动手”(用工具、写脚本、做验证),而不是只给一堆口头建议。
- 如果你是 API 用户,成本结构会影响你能不能把它真的接入到产品/工作流里。
三、我最关心的:它的“前端审美”真的提升了吗?
官方在报告里直接写:K2.5 在 front-end development 上尤其强。
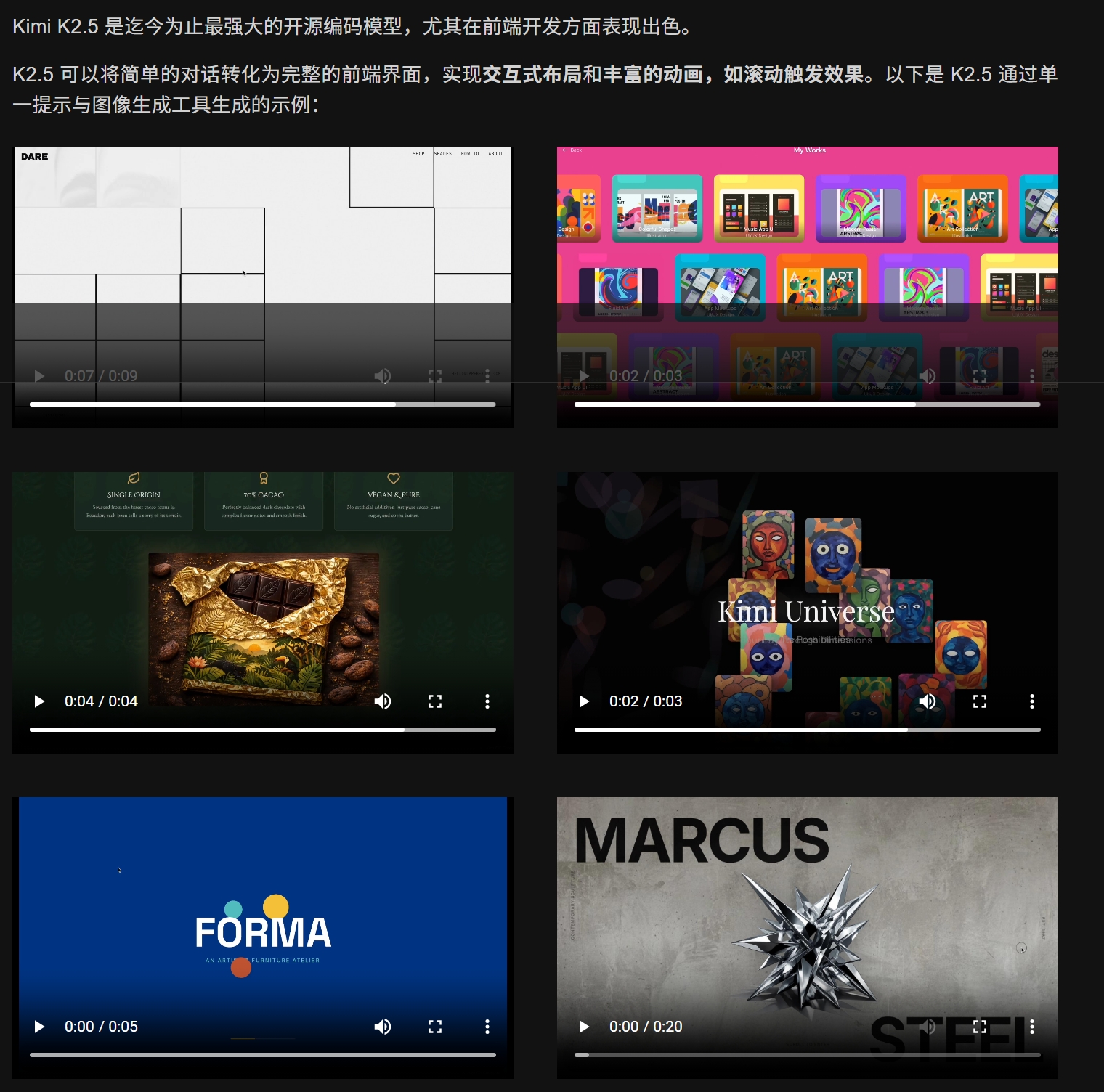
而且它强调的不是“写得出页面”,而是:
- 能做 interactive layouts
- 能做 rich animations(例如滚动触发效果)
- 能把图片/视频当成需求输入,直接走 image/video-to-code
这几句话对前端来说很敏感:
以前很多模型“功能能跑”,但页面带着一股浓浓的 AI 味:
- 间距、字号、配色像默认模板
- 层级关系混乱
- 动效不是没有,就是非常粗糙
所以我做了两个非常“偏私心”的测试:
- 网页审美:同一份祖传 prompt,对比我过去用 Gemini 3 Pro 的体验。
- 图片复刻:拿小红书的三个界面,让它尽量还原(顺便测图像理解+组件拆解能力)。
四、实测 1:网页审美(结论:好看,但慢)
我的测试方法
我用了我一直拿来生成“个人数字网站”的那份提示词(提示词不在这里展开,避免文章太长)。
测试环境:
- 使用 Kimi 网页端
- 选择 Agent 模式
结论先说
- 审美不错:至少我自己挺喜欢的。
- AI 味不重:生成的页面没有那种“模板拼接感”。
- 但速度真的慢:不是思考很久,而是执行链路整体偏慢(尤其是涉及生成资源、组织文件、迭代页面的时候)。
这里我反而觉得它更像“认真做事的团队新人”:
- 思路不拖泥带水
- 但把东西落地、跑流程、出结果,需要时间

五、实测 2:小红书界面复刻(结论:惊艳,但稳定性需要再打磨)
为什么选小红书?
因为它是典型的“高审美 + 高工程复杂度”的结合体:
- 信息密度高
- UI 细节多(卡片、标签、头像、间距)
- 组件复用强
- 状态复杂(推荐流、详情、评论、收藏/点赞)
我给了它 3 个界面让它复刻。
过程中发生了什么
- K2.5 生成了非常多的图片资源
- 中途莫名中断了一次,没有完成代码撰写和部署
- 过一会又恢复了(我猜可能是当时用的人太多)
最终效果
尽管过程磕磕绊绊,但最终出来的界面让我有点惊到:
- 真的有“小红书那味道”
- 组件层级、留白、字体大小的选择比较像“人做的”
我把复刻效果放在这里,你可以直接点开看(目前只做了电脑端适配):
https://tjb4cuoijc2wu.ok.kimi.link/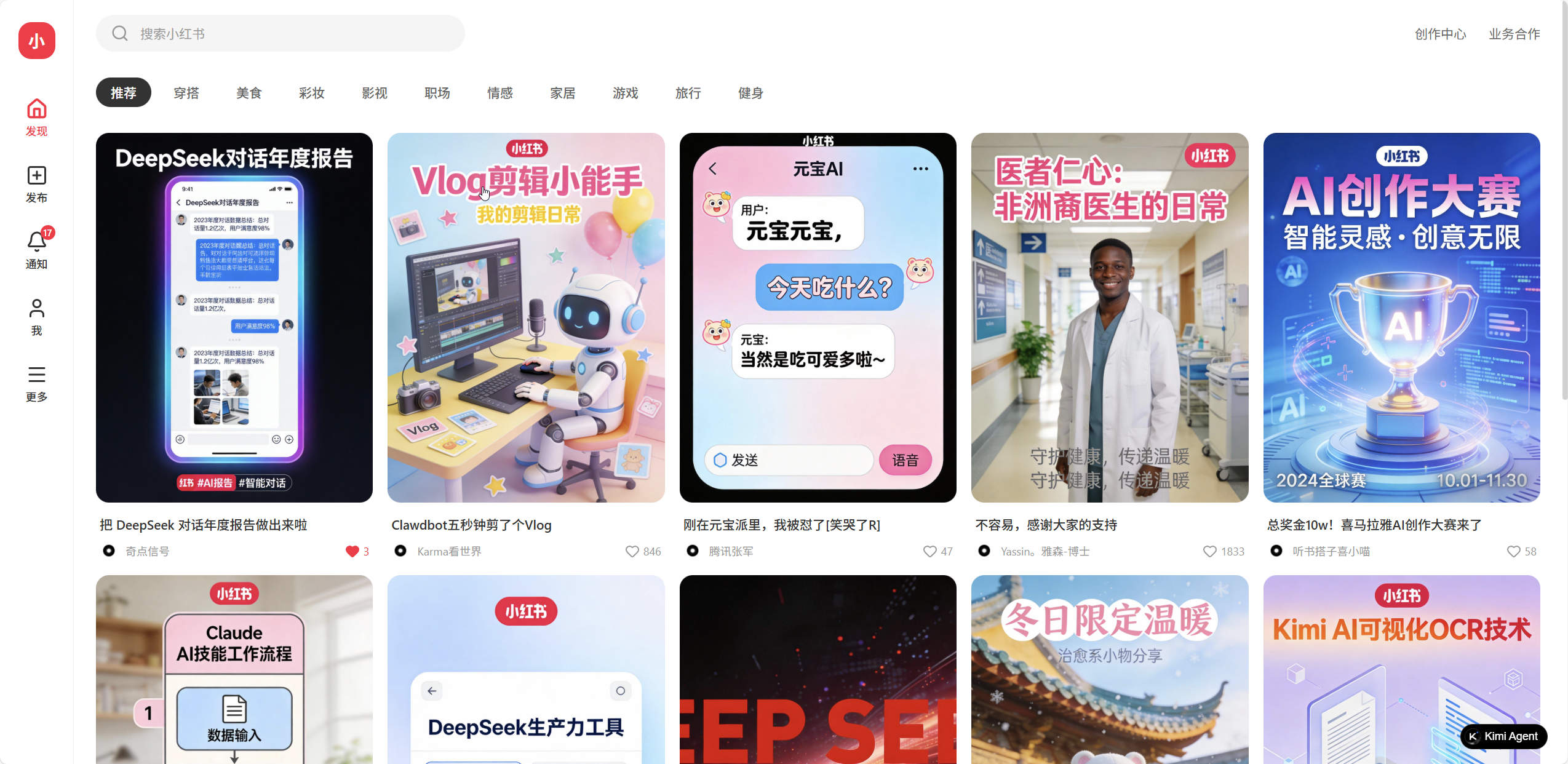
六、为什么它能做到“看着图/视频写前端”?
这里就要回到报告里一句话:
K2.5 excels at coding with vision.
它的核心不是“接了个视觉模型”,而是通过大规模的视觉-文本联合预训练,让模型具备一种更接近人类的表达方式:
- 你可以用图片/视频表达需求
- 模型能把视觉信息映射到可执行的工程结构(组件、布局、样式、资源)
- 还能在迭代里做 visual debugging(看着自己的输出改)
官方举的例子里包括:
- 从视频重建网站
- 看着一个迷宫图,用 Python 找最短路径并可视化
这种能力一旦成立,意味着“需求表达”的门槛会下降:
- 以前要描述 UI:你要写一大段文字
- 现在你可以说:就照这个图来(甚至是照这个视频的交互来)
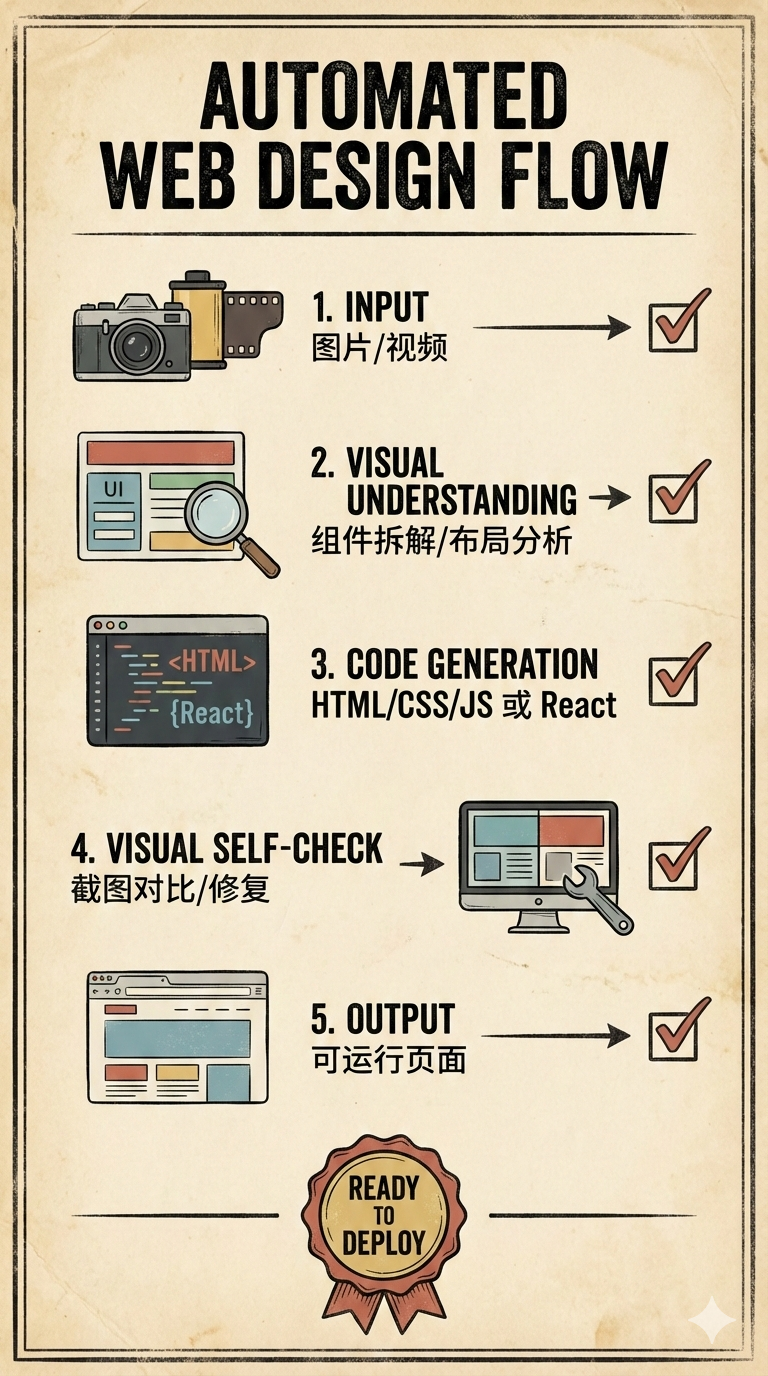
七、另一个大招:Agent Swarm(不是一个人做项目,是 100 个同事一起做)
如果说“看图写代码”解决的是表达与落地,那 Agent Swarm 解决的是另一件事:
- 复杂任务里,最大的敌人往往不是智商,而是 时间(以及串行的步骤依赖)。
官方给的数据很激进:
- 最多 100 个子智能体
- 最多 1,500 次工具调用
- 相比单 Agent,最多能快 4.5x
并且它强调:
- 子 Agent 不是预先手工定义的
- 工作流也不是写死的
- 而是模型自动创建并编排
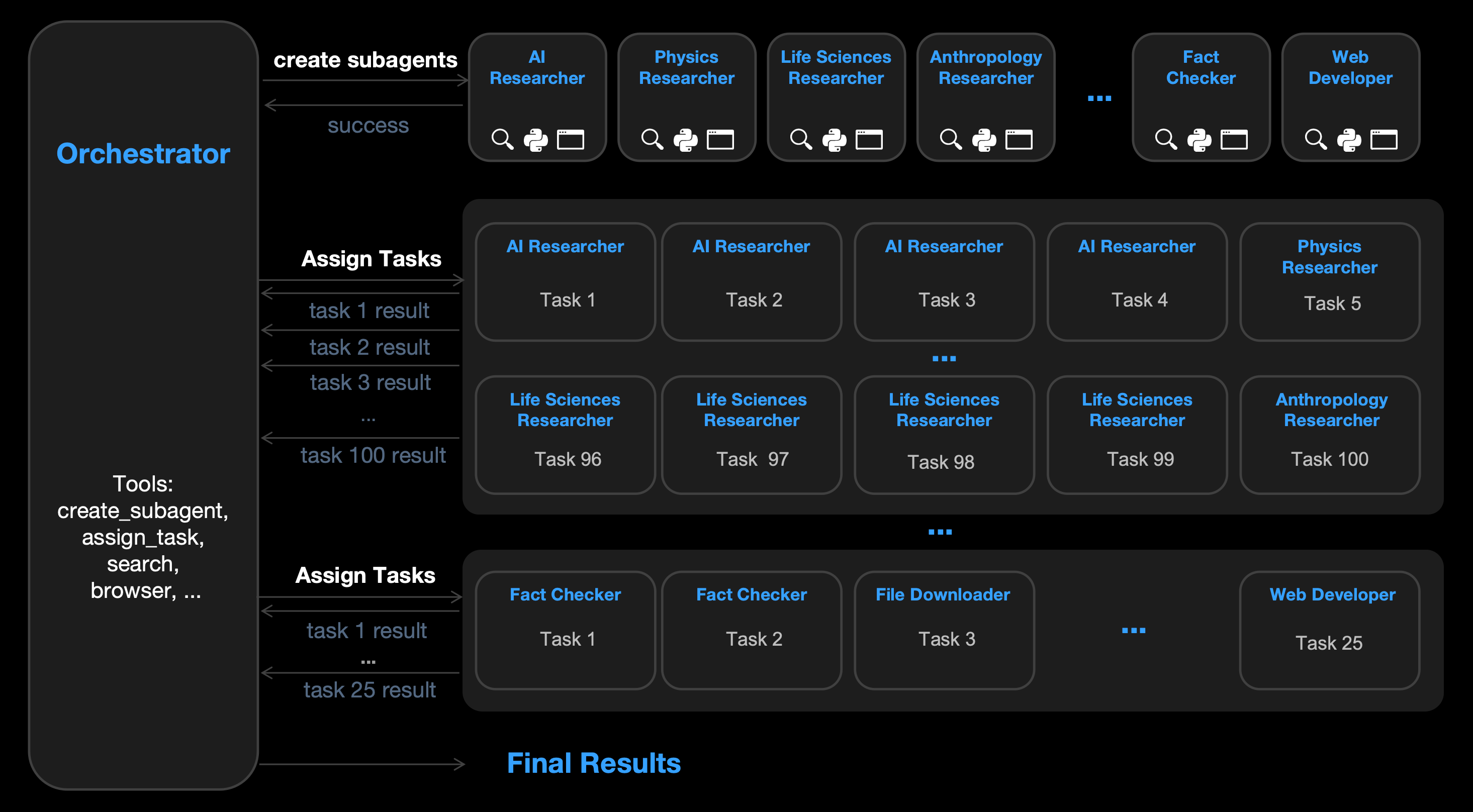
报告里提到他们用 **Parallel-Agent Reinforcement Learning(PARL)**训练一个“可学习的编排器(orchestrator)”,去避免常见失败模式:
- serial collapse(串行塌缩):明明可以并行,但 orchestrator 懒得拆,最后还是一个 agent 从头干到尾
以及他们用一个更贴近并行计算的指标:Critical Steps,去逼迫系统真的用并行缩短关键路径。
八、写代码这件事:K2.5 的定位可能更像“能落地的工程队”
官方也给了不少 coding benchmark:
- SWE-Bench Verified:76.8
- SWE-Bench Multilingual:73.0
- LiveCodeBench v6:85.0
这些分数当然重要,但对我来说更重要的是它在产品层的配套:
- Kimi Code:在终端里用,也能接入 VSCode / Cursor / Zed 等
- 支持图片和视频输入
- 能发现并迁移 MCP/技能到环境
这类“生态接入”的完善程度,会直接决定它是不是能成为你每天都用的生产力工具。
九、我的真实感受(优点很明确,短板也很真实)
我认为它最强的地方
- 视觉 + 代码的结合很实用:尤其是前端、产品、设计协作场景
- Agent 能力更像“能把事做成”:不是聊天式建议,而是能执行、能闭环
- 审美显著进步:至少在我测的前端页面生成/复刻里,明显更像“人做的”
你可能会踩的坑
- 速度/稳定性:任务复杂时,链路长、资源多,容易慢或中断
- 高峰期体验波动:我这次复刻小红书时就遇到过中断
- 不要只看一个分数:K2.5 在不同任务类型的表现有强弱分布,适配场景更重要

十、怎么上手最划算?(给不同人群的建议)
- 如果你是普通用户:
- 先在 Kimi.com 用
K2.5 Agent做一次完整任务(比如“把这个页面复刻出来并部署”),你会最快理解它的优势。
- 先在 Kimi.com 用
- 如果你是前端/设计/产品:
- 直接用“图片/视频 + 需求”驱动它做页面,你会明显感到表达成本下降。
- 如果你是开发者/API 用户:
- 建议先把“工具链”配齐(IDE、终端、浏览器、截图对比),再评估它的吞吐与成本。
最后还是那句话:
判断一个模型到底行不行,最好的方式不是读任何解读(包括这篇),而是自己真的去亲手试一次。
如果你也测了 K2.5,欢迎留言告诉我:
- 你在哪个场景觉得它“离谱地好用”?
- 又在哪个场景觉得它“还差点意思”?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)