企业级 AI Agent 的终极王牌:从 0 到 1 带你理解 “本体论” 与 6 块核心“积木”
幻觉风险:由于企业知识的垂直特征,容易超出 LLM 的理解能力,为填补空白,它可能编造看似权威的答案。语义不一致:企业不同系统中同一概念的内涵、表述与形式不一致,导致理解困难或者关联失败。上下文理解缺失:缺少关联知识与业务规则约束,AI 容易跑偏。例如,不知道什么情况下可“承诺加急发货”。逻辑推理能力不足:例如 “组件缺货 → 成品延迟 → 订单违约” 这类传递链条,并非 LLM 的强项。
LLM 本质上是一种基于概率预测的“下一个词”生成系统,它并没有真正“理解”世界。这在通识领域问题不大 — 因为它受过大量训练,可以轻松创作像模像样的文章与代码。但到了垂直甚至封闭的企业领域,由于它对企业内部业务与数据的理解非常有限,就会变得“盲目”与脆弱。
尽管生成式 AI 如火如荼,但一个尴尬的事实是:大部分企业 Agent 项目都以失败告终 — 幻觉、跑偏、不可控。也正因此,智能体工程“学科”开始兴起。其中,基于“本体论”(Ontology)的企业“本体”工程,正越来越被推至关键地位。
“本体论”也被认为是当前最火热的科技独角兽Palantir的核心竞争力。
我们将为大家更新一系列本体论实践 — 用尽可能简洁的方式带你体验本体论,并最终构建你的第一个基于本体的 AI Agent。
本篇为第一篇,内容涵盖:
- 企业AI的困境:拥有数据却依然“盲目”
- 现有工程手段:局部“止痛”,很难治本
- 缺失的一环:用本体补上企业“语义层”
- 如何构建本体:理解 6 块核心“积木”
1.企业AI的困境:拥有数据却依然“盲目”
如你所知,LLM 本质上是一种基于概率预测的“下一个词”生成系统,它并没有真正“理解”世界。这在通识领域问题不大 — 因为它受过大量训练,可以轻松创作像模像样的文章与代码。但到了垂直甚至封闭的企业领域,由于它对企业内部业务与数据的理解非常有限,就会变得“盲目”与脆弱。
从一个 Agent 场景开始
让我们设想一个企业 Agent 的场景:
一家定制工业阀门的制造企业,客户向新上线的客服 Agent 催问:
“订单A1024到哪一步了,能否加急发货?”
假设给Agent 配备了查询工具(Tools),可以查询到下列信息:
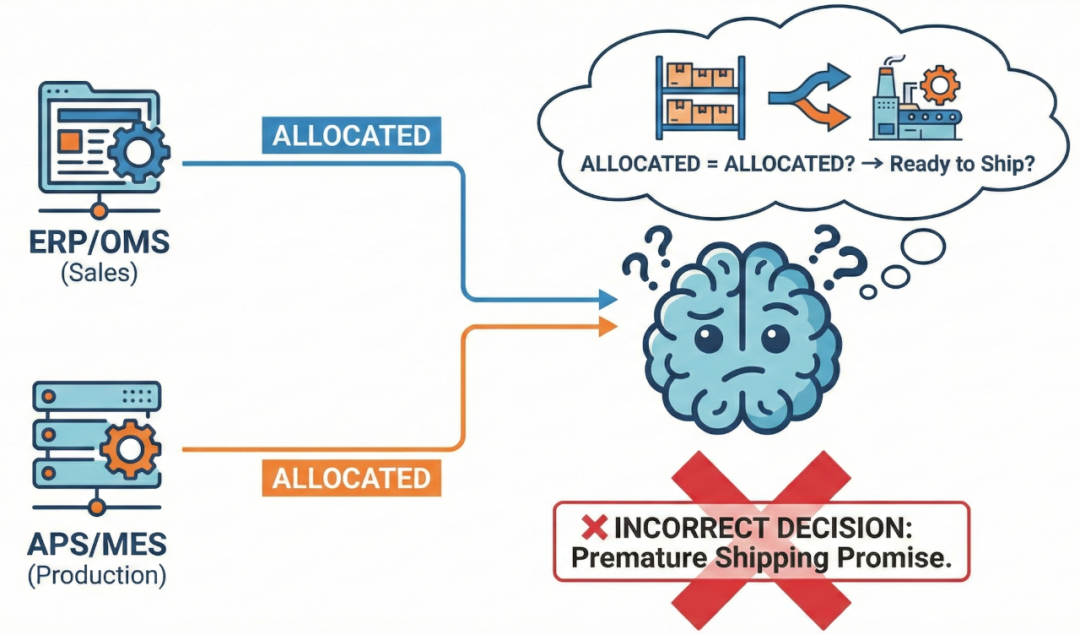
- ERP/OMS(销售订单)status = "ALLOCATED":原材料已锁定,具备投产条件
- APS/MES(生产工单)status = "ALLOCATED":产能/工时已分配,排入计划
如果暂不考虑其他上下文工程手段(RAG、Skills、工作流等),我们看看 Agent 可能犯的错误:
错误一:语义谬误
Agent 拉取到两个“ALLOCATED”,LLM 按通用经验推理:
“都 ALLOCATED 了 = 已准备就绪 = 很快能发货/甚至已经在出库流程中。”
这是典型的语义理解错误:同一个词在不同的企业/语境/系统下含义不同。
错误二:动作错误
Agent 可能会产生错误的“客服动作”。比如:
- 直接回复客户:“A1024 已准备就绪,可安排加急”。
- 发起内部流程:把需求错误地路由给仓库“加急出库”,而不是“加急生产”;由于系统校验机制,随后可能会陷入错误与重试的循环。
这里反映出业务规则的缺失。比如“加急交付”规则是:
- 客户必须是VIP → 才可以申请“加急”
- 如果 成品已入库 + 质检放行 → 才可以承诺“加急出库/发货”
- 如果 成品未入库 → 转为“插单排程/加急采购生产”等路径
很显然,AI 无法天然了解这些企业规则。
错误三:难以解释与修复
客户第二天追问“为什么还没发货?”IT 主管回溯时会发现:
- Agent 的依据只是两个 “ALLOCATED”,就认为它等价于“可发货”
- 更麻烦的是,你很难告诉 Agent “下次看到这种情况应该如何如何”
在企业应用中,不可解释有时候比”做错“更头疼,因为这意味着难以定责,也难以修复。
总结:企业 AI Agent 面临的问题
我们对问题做一个系统化的总结:
- 幻觉风险:由于企业知识的垂直特征,容易超出 LLM 的理解能力,为填补空白,它可能编造看似权威的答案。
- 语义不一致:企业不同系统中同一概念的内涵、表述与形式不一致,导致理解困难或者关联失败。
- 上下文理解缺失:缺少关联知识与业务规则约束,AI 容易跑偏。例如,不知道什么情况下可“承诺加急发货”。
- 逻辑推理能力不足:例如 “组件缺货 → 成品延迟 → 订单违约” 这类传递链条,并非 LLM 的强项。
- 决策难以解释:AI 输出的结果或异常很难追溯原因 — 缺乏透明的业务知识结构、可追溯的逻辑、可审计的推理。
- Agent 协作困难:由于缺乏共享的业务知识结构,很容易“鸡同鸭讲”。
这就是企业 AI Agent 的困境:
它们拥有足够的数据访问权与工具,却缺乏足够的业务语义、规则与约束,就像一个缺乏导航的驾驶员来到陌生城市 — 很容易迷失与犯错。
2.现有工程手段:局部“止痛”,很难治本
当然,随着技术的发展,我们有了一些“看起来不错”的解决方案。它们确实能在一定程度上缓解问题,但也都有各自的边界。让我们来分析下。
Skills(技能)+ RAG(检索增强生成)
给企业 Agent 增加业务知识最直觉的方法是:增加知识“外挂”。比如:
- 对于静态知识内容,用 RAG 来提供动态上下文,给 Agent 参考
- 另一种给 Agent 注入新能力的方法,就是当下火热的Skills(技能)
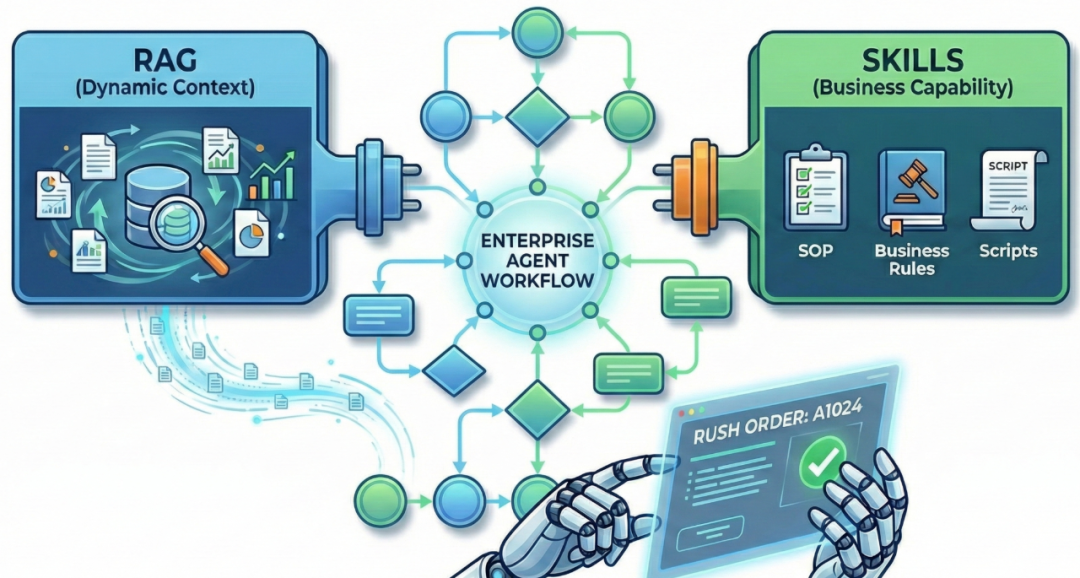
延续第一节的例子,我们进行“修缮”:
给 Agent 注入“订单加急交付”的技能 — 包含 SOP(标准操作流程)、状态解释、业务规则甚至脚本等。
这确实能在很大程度上避免低级错误,但需要注意:
- Skills 本质仍是“提示”,而不是语义与约束。 当上下文足够复杂、对话足够长、或技能定义本身存在歧义时,Agent 仍可能理解错、推理错。
- 规模化后容易带来“碎片化”维护问题。 应用到企业领域,你会有海量 Skills,每个都会有相关的业务概念及规则,后期维护是一大挑战。
所以,Skills 的问题可以概括为:
Skills/RAG 的确能教 Agent “你应该怎么做”;
但一是“教的太累”;二是记住了不代表“不会做错”。
Agentic Workflow(工作流)
Agentic Workflow 是企业场景下提高可控性的常见方法:把关键步骤固定下来,在局部让 LLM 发挥,降低模型“自由发挥”的空间。
但这里的问题是:
只要存在LLM推理,就仍然存在“语义谬误”的空间。
比如上面的例子,如果你设计流程:
Step 1:获取订单/工单状态(系统调用)
Step 2:LLM 判断是否可以“加急发货”
Step 3:若可以 → 回复客户并创建加急工单;否则 → 转人工或改走“加急排产/生产催办”在这里,LLM 在 Step 2 仍然要回答:当前状态是否满足“可承诺发货/可加急”的条件?于是又回到了同一个根问题。
当然,你也可以把部分语义和条件硬编码进流程里,把关键规则判断从 LLM 手里“拿”回来(伪代码):
IF Order.hasValidInventoryAllocation = TRUE
AND Order.hasPassedQualityCheck = TRUE
THEN urgent_allowed = TRUE
ELSE urgent_allowed = FALSE这里的 “hasValidInventoryAllocation” 、“hasPassedQualityCheck”不是某个固定字段,而是自定义的业务规则:判断是否满足加急发货条件。
这样 LLM 只负责生成话术(如何解释)、或生成建议(下一步怎么做),关键决策不再让它完成。
但问题很明显:
尽管限制了 LLM 的发挥,但它也承担过多“语义解释与规则”的责任,工程复杂度会指数级的膨胀 — 你无法穷举所有业务条件(比如 VIP 客户可以跨仓调拨、某条合同允许跳过部分校验、不同地区截单时间不同等)。最后变成:系统是“正确可控”了,但也越来越“没人敢动”。
所以Workflow的问题是:
它只是让任务路径更可控;
但要么仍然依赖 LLM 对业务的理解,
要么容易陷入难以维护的硬编码“规则爆炸”。
3.缺失的一环:用本体补上企业“语义层”
要缓解上述企业 AI Agent 的困境,除了上面的工程手段(提示、RAG、工作流等)。一种正在被推到更重要位置的思路是:引入一个能够解释业务、数据与规则的中间语义层 — 本体(Ontology)。
本体是什么?你可以先用一句话理解:
本体就是对现实业务世界的数字化建模(“数字孪生”)。
它不是把文档塞给 AI,而是把企业里“什么是什么、如何关联、什么条件成立”等,用结构化方式表达出来,形成统一的语义视图,让 Agent 有了统一的“业务知识理解”,从而减少误解与幻觉。
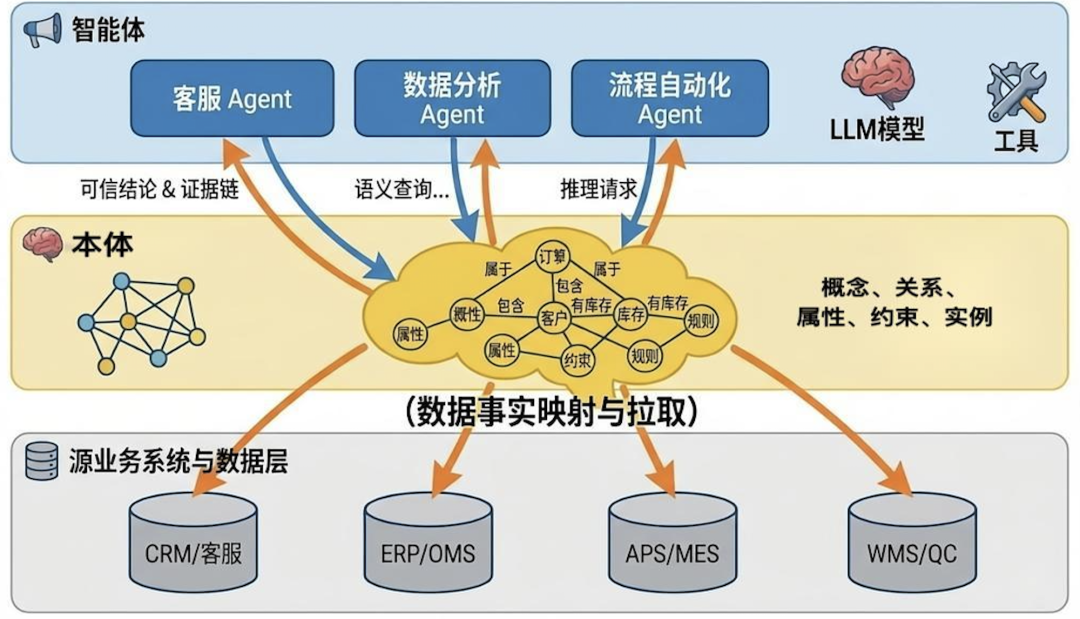
注:本体的来历与复兴
本体(Ontology)最早来自哲学中的“存在之学”,在计算机领域则在 2000 年代语义网浪潮中被标准化(W3C 的 RDF/OWL 等)。语义网当年因成本高、工程化难等不足而未普及。近几年本体在企业里重新走红,很大程度源于 Palantir 等公司的实践:把本体当作企业的共享“语义底座”,并在此基础上构建AI应用。
用一个最小的本体来理解
现在围绕前面的场景,但只关注一个基础问题:
“一个订单,什么时候才可以发货?”
在本体中,我们不急着想到“数据库字段”,而是先梳理现实世界涉及哪些概念,以及它们之间的关系:
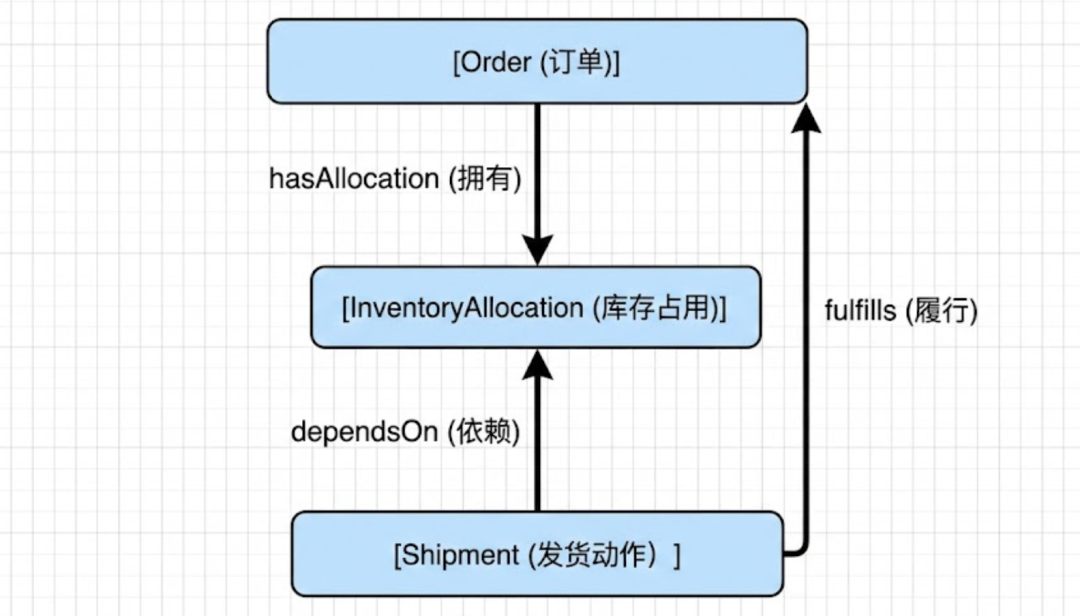
用文字来描述这个本体:
业务概念
- Order(订单):代表客户需求的业务对象
- InventoryAllocation(库存占用):为订单“确认可交付”的业务事实
- Shipment(发货/交付动作):订单进入交付流程的事件
关系
- Order — hasAllocation — InventoryAllocation(订单拥有库存占用)
- Shipment — dependsOn — InventoryAllocation(发货依赖库存占用)
- Shipment — fulfills — Order(发货履行订单)
约束
- 订单拥有“库存占用” —> 才可以发货
这就是一个很小但完整的语义框架。它表达了和“发货”相关的业务概念和规则(这里用最简单的规则演示,实际应用当然要复杂的多)。
本体的价值1:复杂业务推理
有了这层最小语义,Agent 在遇到“加急发货 A1024”时,就可以结合本体与事实进行推理。举个简单的例子:
- 语义(本体规则):发货 → 依赖 → 库存占用
- 事实(系统数据):订单 A1024 → 拥有 → 库存占用
- 推理结论:A1024 可发货(从而可进一步判断是否可加急/可承诺)
当然,基于本体的推理可以再复杂。比如规则变为:
- 加急发货 -> 需要 -> 可发货
- 可发货 -> 需要 -> 库存占用
- 库存占用 -> 要求 -> 数量匹配 / 状态可用
- 加急发货 -> 需要 -> 质检已放行
- 加急发货 -> 需要 -> VIP客户订单
如果订单 A1204 同时满足必要的事实,那么 Agent 就能给出结论与理由链:
订单 A1204 可以加急:因为具备发货条件、客户为 VIP、质检已放行。
本体的价值2:把“规则”从代码里解放
企业里,“加急发货”往往还牵涉 合规、信用、合同条款、截单时间、是否定制等。如果这些规则散落在代码/流程/文档里,系统会越来越难以维护与解释。
而本体的另一个重要意义是:
把业务规则当成数据放在语义层上。
比如我们需要修改规则:
“VIP 允许跨仓调拨的截单时间从 16:00 改为 18:00“
你无需在代码里改一堆 if-else,也不必反复重写 Prompt 或工作流,而是更新本体的一处规则定义,让所有基于语义层的流程与 Agent 行为同步生效。
更重要的是,AI 行为会变得可解释、可追溯。比如 Agent 判定不能加急发货时,它可以给出更可信的解释:
“订单 A1024 无法加急发货,因为可出库成品库存不足(可用 10 / 需求 20)。加急发货必须满足‘有效库存占用’与‘质检放行’两个前置条件。当前已为您转为加急排产。”
所以,本体对 Agent 的意义可以总结为:
把企业业务的“语义 + 规则 + 推理”补齐。
带来的直接收益是:减少误解与幻觉:统一概念与关系、支撑复杂推理与多跳查询、提升协作与治理(可解释可审计)能力。
4.如何构建本体:理解 6 块核心积木
既然本体如此有用,那么下一个问题就是:我们应该如何来构建与使用本体?
在准备动手进入 OWL、查询语言、推理引擎这些“标准工具”之前,我们先来理解本体的几大核心概念(积木)—
无论你用什么建模工具、语言还是推理库,本体最终都绕不开这几块“积木”。为了方便理解,我们用数据库、OOP(面向对象编程)来做类比。

类 / 概念(Class)
表示业务世界里稳定存在的业务对象类型。
例子:Order(订单)、InventoryAllocation(库存占用)等。
类比:
- 数据库:类似一张表(比如订单表),注意不是表里的数据
- OOP:一个 class(类),注意不是某个对象实例
实例 / 个体(Individual)
表示真实世界发生的业务事实,如某个具体订单、某次具体占用。
例子:订单_A1024、订单_A102 — 拥有 — 库存占用_01
类比:
- 数据库:表里的某一行具体数据
- OOP:new Order() 创建出来的 object(对象)
个体/事实通常来自业务系统数据。建模时用少量示例用于验证规则;生产中则在运行时把事实(比如某订单)动态注入,再进行查询与推理
关系(Object Property)
关系用来表示概念之间的链接(谁和谁有关、依赖谁)。
例子:hasAllocation(订单 → 库存占用)、fulfills(发货 → 订单)。
类比:
- 数据库:外键(FK)/ 关联表,表达了表与表关系
- OOP:类定义中对其他类型对象的引用,例如 Order.allocation(所以本体里的关系就叫Object Property)
属性(Data Property)
表示业务对象自身携带的业务特征,比如数量、时间、等级、状态等。
例子:requiredQty(订单需求数量)、customerLevel(客户等级)。
类比:
- 数据库:表里的列字段,例如订单表的“状态”列
- OOP:类定义中的简单成员变量,例如 Order.create_time
约束 / 公理(Axiom)
表示基于概念、关系及属性之上定义的规则与约束。这是本体与传统建模拉开差距的关键 — 它把“业务规则”提升为语义层的可判定规则。
例子:只有当订单拥有“库存占用”时,才允许发货。
类比:
- 数据库:近似于 CHECK 约束 + 业务层校验
- OOP:近似于类层面的不变式(Invariant)/ 断言(Assert)。
推理(Reasoning)
简单说就是:基于业务语义(概念、关系、约束等)与事实(实例/个体等),能得出什么新的结论,并能解释为什么。
例子:
- 事实:订单 A1024 有一个库存占用
- 规则:库存占用 -> 允许发货
- 结论:A1024 可发货
类比:
- 数据库:有点像视图/派生字段/规则引擎输出(或业务层校验结果)
- OOP:类似在不变式约束下做推导的判定逻辑。比如执行 canShip(order)
推理本身是一种“动作”,主要用在运行阶段用它产出结论与解释。
最后:如何区分本体与知识图谱
本体对业务的定义(对象、关系、属性等)很容易让人联想到知识图谱,它们也都会涉及“三元组”。但并不相同:
- 本体(Ontology)定义业务知识的结构框架(有哪些概念、如何关联、怎么约束),通常相对稳定。
- 知识图谱(Knowledge Graph)则是“事实数据的集合”:它是业务知识的实例填充(发生了什么、这单是什么状态),通常规模更大且持续增长。
简单说:本体是“语义与规则”,知识图谱是“事实与数据”。比如:
- 本体定义:Order 可以 hasAllocation 一个 InventoryAllocation
- 知识图谱:Order_A1024 — hasAllocation — Alloc_01

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献160条内容
已为社区贡献160条内容

所有评论(0)