Agentic RAG之核心协作类(Agentic RAG with Contextual AI)和基础技术类(包含5种RAG变体)
传统RAG是一次性把文档塞进Prompt就生成答案;
传统RAG的弊端:单向、固定、一次性(检索一次生成一次就结束)
存在的问题是:经过一次检索之后无法得到想要的答案;
大部分情况下想要重新进行一次检索或者换另外一种检索方式、或者利用工具获取更多上下文之后再进行检索,但是传统RAG无法实现此目的,需要Agentic RAG,就是把RAG的过程工具化
Agentic RAG=工具化+循环决策+多步推理
将传统RAG的每个环节(检索、改写、读取文件)封装为可调用的工具,多次循环调用工具的一个过程;
由LLM去自主决策需要做什么,在用户输入问题后就开始利用大模型进行决策:
是否需要调用工具?
调用哪个工具?
是否需要多轮调用?
是一个“思考—行动—观察—再思考”的循环过程,Agentic RAG让大模型扮演一个“决策-执行”的控制器,先制定决策,再调用工具逐步收集证据,最后基于证据作答并给出引用。
代码块执行区别:
传统RAG代码块:用户查询、向量检索、检索结果、生成结果
Agentic RAG代码块:
第一轮检索:工具检索、观察(命中低,证据不足)、决策:尝试改写query
第二轮检索(术语同义转换):推理、工具检索、观察(命中高)
......
1.Key Collaboration(核心协作类)
代表技术:Agentic RAG with Contextual AI
特点:结合智能代理与上下文 AI,让系统能自主规划检索策略、动态优化查询,是当前 RAG 的前沿方向,适合复杂多轮对话和任务型场景。
Agentic RAG with Contextual AI:Agentic RAG 的进阶形态,核心是将上下文感知能力深度嵌入智能代理(让系统能在理解全局语境的基础上,自主完成 “规划 - 检索 - 反思 - 生成” 的闭环,既保留 Agentic RAG 的自主性,又解决了传统 RAG 与普通 Agentic RAG 的语境割裂问题),实现更精准的动态协作,类似一个 “懂上下文的资深侦探”。他不仅会主动查线索,还能记住整个案件的来龙去脉(比如之前问过的问题、用户的背景信息),甚至能理解你的隐含意图。
开发流程示意:
1.1:初始上下文记忆
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
1.2:定义代理工具链
给代理配置检索工具、网页搜索工具等,并让它能根据上下文选择工具。
from langchain.agents import AgentExecutor, create_retrieval_agent
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(retriever, "knowledge_base", "检索产品知识库")
tools = [retriever_tool]
agent = create_retrieval_agent(llm, tools, memory=memory)
1.3:启动代理交互
用户提问时,代理会先读取对话历史,理解上下文,再规划检索步骤。
response = agent.invoke({
"input": "这个产品今年的市场反馈如何?",
"chat_history": memory.load_memory_variables({})
})
1.4:动态优化与反思
代理会检查检索结果的质量,如果信息不足,会自动调整查询词(比如加上 “竞品对比”)再检索一次,直到得到足够的信息
2.Foundational(基础技术类)
包含 Basic RAG、RAG with CSV Files、Reliable RAG 、 Optimizing Chunk Sizes、Proposition Chunking
作用:解决 RAG 的核心落地问题,如文档分块、基础检索流程搭建,是进阶技术的底层支撑。
2.1:Basic RAG 基础检索增强生成
RAG的基础流水线框架,是所有进阶RAG的基础底座,实现任何场景都应先落地 Basic RAG 验证可行性(检索—生成)流水线基础上叠加能力,即:针对痛点叠加 CSV 适配、可靠性增强、分块优化等能力,核心流程为4步流水线:
(1)文档入库:将知识库文本切分为固定长度的小块,通过嵌入模型(如 BERT、Sentence-BERT)转化为向量,存入向量数据库(如 Chroma、Pinecone)。
(2)用户查询处理:将用户提问同样转化为向量。
(3)相似性检索:在向量库中检索与查询向量最相似的 Top-N 文本块。
(4)生成回答:将检索到的文本块作为上下文,拼接成 Prompt 发送给大模型;即上下文拼接大模型生成
解决的 AI 领域问题:
(1)大模型幻觉问题:让大模型基于真实知识库回答,而非凭空生成;
(2)大模型知识时效性问题:无需重新训练大模型,仅更新知识库即可补充新信息;
(3) 大模型私有知识适配问题:可对接企业私有文档 / 知识库,实现专属知识问答。
代码落地:
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import RetrievalQA
# 加载环境变量
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# os.environ["OPENAI_API_BASE"] = os.getenv("OPENAI_API_BASE")
# 1. 初始化模型(大模型+嵌入模型)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) # 生成回答,保证事实准确
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002") # 文本向量化
# 2. 构建基础知识库(可替换为本地文本文档/爬取数据)
knowledge_base = [
"Transformer的自注意力机制能并行计算,提升模型训练效率,分为多头注意力和单头注意力。",
"Basic RAG的核心流程是文档向量化、查询检索、上下文拼接、大模型生成,解决大模型幻觉问题。",
"HyDE是RAG查询侧优化技术,通过生成假设文档扩充查询语义,提升检索精准度。"
]
# 3. 文档预处理:分块(基础分块,按字符数拆分)
text_splitter = CharacterTextSplitter(
chunk_size=200, # 每个分块最大字符数
chunk_overlap=20, # 分块重叠字符数,避免语义割裂
separator="。" # 按中文句号拆分,贴合语义
)
docs = text_splitter.create_documents(knowledge_base)
# 4. 向量化入库:将分块文档存入Chroma本地向量库
vector_db = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory="./basic_rag_chroma" # 向量库本地存储路径
)
retriever = vector_db.as_retriever(search_kwargs={"k": 2}) # 检索相似度最高的2条内容
# 5. 构建Basic RAG链:封装「检索+生成」全流程
basic_rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 简单拼接:将检索结果全部拼入Prompt(适合短检索结果)
retriever=retriever,
return_source_documents=True # 返回检索依据,方便验证
)
# 6. 测试查询
def basic_rag_query(question):
result = basic_rag_chain.invoke({"query": question})
print(f"问题:{question}")
print(f"回答:{result['result']}")
print(f"检索依据:{[doc.page_content for doc in result['source_documents']]}\n")
# 运行测试
if __name__ == "__main__":
basic_rag_query("Basic RAG的核心流程是什么?")
**代码运行效果**:
问题:Basic RAG的核心流程是什么?
回答:Basic RAG的核心流程是文档向量化、查询检索、上下文拼接、大模型生成,该流程能够有效解决大模型的幻觉问题。
检索依据:['Basic RAG的核心流程是文档向量化、查询检索、上下文拼接、大模型生成,解决大模型幻觉问题。']
2.2:RAG with CSV Files(面向 CSV 文件的 RAG)
是针对结构化表格数据的定制化 RAG 方案,核心优化在数据处理和检索环节:
(1)结构化解析:将 CSV 中的每行数据视为一条结构化记录(包含列名和字段值),而非纯文本。
(2) 混合检索策略:
对文本型字段(如产品描述、备注):采用传统向量检索,匹配语义相似性。
对数值型 / 类别型字段(如价格、日期、产品型号):采用关键字检索或过滤检索(如 “价格>1000”“日期 = 2025-01”)。
(3) 精准拼接:将检索到的结构化记录按字段整理成清晰的上下文,传递给大模型生成结构化回答。
解决的 AI 领域问题:
(1)大模型无法直接处理结构化表格数据的问题:大模型擅长自然语言,对 CSV/Excel 等表格的解析能力弱;
(2) 表格数据问答效率低的问题:无需人工整理表格,可直接基于原始 CSV 实现自然语言问答;
(3) 结构化数据与自然语言融合的问题:支持 “表格数据 + 自然语言问题” 的跨模态问答(如 “查询 2024 年产品 A 的销售额”)
代码落地:
先创建测试 CSV 文件sales_data.csv(放在代码同目录),内容如下:
产品名称,年份,销售额(万),销量(件),地区
产品A,2023,500,1000,华北
产品A,2024,650,1300,华北
产品B,2023,300,600,华东
产品B,2024,480,960,华东
产品C,2023,200,400,华南
产品C,2024,350,700,华南
代码实现 CSV 专属 RAG,支持自然语言查询表格数据:
import os
import pandas as pd
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain_core.documents import Document
# 加载环境变量
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 1. 初始化模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# 2. 读取CSV并转换为LangChain Document对象(核心:结构化→自然语言)
def csv_to_documents(csv_path):
df = pd.read_csv(csv_path)
documents = []
# 遍历CSV每行,转换为“键值对自然语言”,保留结构化信息
for idx, row in df.iterrows():
content = f"产品名称:{row['产品名称']},年份:{row['年份']},销售额:{row['销售额(万)']}万元,销量:{row['销量(件)']}件,地区:{row['地区']}"
# 添加元数据(可选,方便后续过滤检索,如按地区/年份检索)
metadata = {"产品名称": row['产品名称'], "年份": row['年份'], "地区": row['地区']}
documents.append(Document(page_content=content, metadata=metadata))
return documents
# 3. 加载CSV数据
csv_docs = csv_to_documents("sales_data.csv")
# 4. 文档分块(表格数据已按行拆分,轻量分块即可)
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=10)
split_docs = text_splitter.split_documents(csv_docs)
# 5. 向量化入库
vector_db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory="./csv_rag_chroma"
)
# 可选:基于元数据过滤检索(如仅检索2024年数据)
retriever = vector_db.as_retriever(
search_kwargs={"k": 3},
# 过滤条件:检索2024年数据
# filter={"年份": 2024}
)
# 6. 构建CSV RAG链
csv_rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
# 7. 测试CSV问答
def csv_rag_query(question):
result = csv_rag_chain.invoke({"query": question})
print(f"问题:{question}")
print(f"回答:{result['result']}")
print(f"检索依据:{[doc.page_content for doc in result['source_documents']]}\n")
# 运行测试
if __name__ == "__main__":
csv_rag_query("对比2023和2024年产品B的销量增长了多少?")
**代码运行效果**:
问题:对比2023和2024年产品B的销量增长了多少?
回答:2023年产品B的销量是600件,2024年是960件,销量增长了360件。
检索依据:['产品名称:产品B,年份:2023,销售额:300万元,销量:600件,地区:华东', '产品名称:产品B, 年份:2024,销售额:480万元,销量:960件,地区:华东']
2.3:Reliable RAG(可靠检索增强生成)
原理:在基础 RAG 流程中加入多层验证与溯源机制,核心逻辑是 “检索 - 验证 - 纠错 - 生成” 闭环;
(1)来源标注:检索时记录每个文本块的原始来源(如文档名称、页码、URL)。
(2)信息验证:
内部验证:检查检索到的多个文本块之间是否存在冲突(如 A 文档说 “功能 X 上线于 2025”,B 文档说 “2024”),自动标记冲突内容。
外部验证:对关键信息(如数据、政策条款),调用工具或权威接口交叉验证。
(3)置信度打分:为每个检索结果赋予置信度分数(如 “高置信度 / 低置信度”),低置信度内容会被标注或排除。
(4)溯源生成:大模型生成回答时,不仅输出结论,还会附上信息来源和置信度,同时拒绝回答无可靠依据的问题。
解决的 AI 领域问题:
(1)RAG 输出可信度低的问题:基础 RAG 无法判断检索内容的准确性和冲突性,可能生成错误回答;Reliable RAG 通过验证和溯源,让回答可追溯、可信任。
(2)高风险场景的合规问题:在金融、法律、医疗等领域,回答需要有明确依据且可追责,Reliable RAG 的来源标注和置信度机制满足合规要求。
(3)检索结果冲突问题:自动识别多源文档的信息矛盾,避免大模型 “混搭” 冲突内容生成错误结论
(4)基础 RAG检索结果冗余的问题:精简有效检索内容,减少大模型 token 浪费。
代码落地:
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_core.documents import Document
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 加载环境变量
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 1. 初始化模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
SIMILARITY_THRESHOLD = 0.7 # 相关性阈值:低于0.7的结果直接过滤
# 2. 构建知识库+预处理(同Basic RAG,新增来源元数据)
knowledge_base = [
{
"content": "Transformer的自注意力机制能并行计算,提升模型训练效率,分为多头注意力和单头注意力。",
"source": "《Transformer论文解读》"
},
{
"content": "Basic RAG的核心流程是文档向量化、查询检索、上下文拼接、大模型生成,解决大模型幻觉问题。",
"source": "《RAG技术实战手册》"
},
{
"content": "HyDE是RAG查询侧优化技术,通过生成假设文档扩充查询语义,提升检索精准度。",
"source": "《Query Enhancement技术指南》"
}
]
# 转换为Document对象,添加来源元数据
docs = [Document(page_content=item["content"], metadata={"source": item["source"]}) for item in knowledge_base]
# 分块
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20, separator="。")
split_docs = text_splitter.split_documents(docs)
# 3. 向量化入库
vector_db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory="./reliable_rag_chroma"
)
# 4. 核心:相关性过滤(过滤低相似度检索结果)
def filter_relevant_docs(question, retriever, threshold):
# 检索候选结果
candidate_docs = retriever.get_relevant_documents(question)
if not candidate_docs:
return []
# 生成问题和候选文档的向量
question_emb = embeddings.embed_query(question)
doc_embs = [embeddings.embed_doc(doc.page_content) for doc in candidate_docs]
# 计算余弦相似度
similarities = cosine_similarity([question_emb], doc_embs)[0]
# 过滤高于阈值的文档
relevant_docs = [doc for doc, sim in zip(candidate_docs, similarities) if sim >= threshold]
return relevant_docs
# 5. 核心:可靠生成提示词(强制依据+来源标注)
RELIABLE_PROMPT = PromptTemplate(
input_variables=["context", "question"],
template="""请严格基于以下上下文内容回答问题,遵循以下规则:
1. 每一句话的回答都必须有上下文的明确支撑,无支撑的内容绝对不生成;
2. 若上下文无相关信息,直接回答“未检索到相关可靠信息”;
3. 回答结束后,标注回答的来源,格式为【来源:xxx】,多个来源用分号分隔;
4. 回答简洁、结构化,分点说明(若需要)。
上下文:{context}
问题:{question}
回答:"""
)
# 6. 构建Reliable RAG链
def reliable_rag_query(question):
# 步骤1:检索并过滤相关文档
retriever = vector_db.as_retriever(search_kwargs={"k": 3})
relevant_docs = filter_relevant_docs(question, retriever, SIMILARITY_THRESHOLD)
if not relevant_docs:
print(f"问题:{question}\n回答:未检索到相关可靠信息\n")
return
# 步骤2:拼接上下文和来源
context = "\n".join([doc.page_content for doc in relevant_docs])
sources = ";".join(list(set([doc.metadata["source"] for doc in relevant_docs]))) # 去重来源
# 步骤3:生成可靠回答
prompt = RELIABLE_PROMPT.format(context=context, question=question)
answer = llm.invoke(prompt).content
# 步骤4:标注来源
final_answer = f"{answer}\n【来源:{sources}】"
# 输出
print(f"问题:{question}")
print(f"回答:{final_answer}\n")
print(f"可靠检索依据:{[doc.page_content for doc in relevant_docs]}\n")
# 运行测试
if __name__ == "__main__":
reliable_rag_query("Basic RAG能解决什么问题?")
reliable_rag_query("LLaMA模型的训练方法是什么?") # 无相关信息,过滤
**代码运行效果**:
问题:Basic RAG能解决什么问题?
回答:Basic RAG能解决大模型的幻觉问题。
【来源:《RAG技术实战手册》】
可靠检索依据:['Basic RAG的核心流程是文档向量化、查询检索、上下文拼接、大模型生成,解决大模型幻觉问题。']
问题:LLaMA模型的训练方法是什么?
回答:未检索到相关可靠信息
2.4:Optimizing Chunk Sizes(分块尺寸优化)
核心:摒弃 “固定长度分块” 的弊端,根据文档类型、问题类型、模型上下文窗口动态调整分块大小,核心分块优化原则:
(1)短文档 / 简单事实文档(如 FAQ):小分块(100-300 字符),提升检索精准度;
(2)长文档 / 逻辑连贯文档(如论文、技术手册):大分块(500-1000 字符),避免语义割裂;
(3)结构化文档(如 CSV、代码):按结构分块(如 CSV 按行、代码按函数),而非按字符数;
(4) 模糊查询 / 概念查询:大分块,保留更多上下文;
(5)精准查询 / 细节查询:小分块,精准匹配细节。
解决的 AI 领域问题:
(1)基础 RAG固定分块语义割裂的问题:长文档按小分块拆分后,单个分块无完整逻辑,导致检索结果无效;
(2)基础 RAG分块过大检索精准度低的问题:大分块包含冗余信息,查询与分块的相似度计算偏差大;
(3)基础 RAG分块过小信息缺失的问题:小分块无法保留完整的概念 / 逻辑,导致大模型生成回答不完整;
(4)不同类型文档适配性差的问题:一套分块策略无法适配文本文档、论文、CSV、代码等多种文档。
代码落地:
实现文档类型自动识别 + 动态分块,适配「短 FAQ 文档」和「长技术论文文档」两种场景:
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain_core.documents import Document
# 加载环境变量
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 1. 初始化模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# 2. 定义不同类型文档的动态分块函数(核心:按文档类型适配分块大小)
def dynamic_chunking(docs, doc_type):
"""
动态分块函数
:param docs: LangChain Document列表
:param doc_type: 文档类型,可选:faq(短FAQ)、thesis(长论文)、csv(CSV表格)、code(代码)
:return: 分块后的Document列表
"""
if doc_type == "faq":
# FAQ文档:小分块,高精准
text_splitter = CharacterTextSplitter(
chunk_size=150,
chunk_overlap=15,---相邻两个文本块之间重叠的字符数(或token数,具体取决于实现)为15。该参数用于缓解因硬性切分导致上下文断裂的问题,使每个块保留前一块末尾的一部分内容,从而提升后续处理(如嵌入、检索或生成)时对局部上下文的理解连贯性
separator="。"
)
elif doc_type == "thesis":
# 论文文档:大分块,保语义(用RecursiveCharacterTextSplitter,按多分隔符智能拆分)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=80,
separators=["\n\n", "\n", "。", ",", " "] # 按优先级拆分,先按空行,再按换行,最后按标点
)
elif doc_type == "csv":
# CSV文档:按行分块(已在RAG with CSV Files实现)
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=10)
elif doc_type == "code":
# 代码文档:按函数/类拆分(简单实现,按{}拆分)
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50, separator="{}")
else:
# 默认:中等分块
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=30)
return text_splitter.split_documents(docs)
# 3. 加载不同类型的测试文档
# 3.1 FAQ短文档(小分块场景)
faq_docs = [
Document(page_content="Q:Basic RAG的核心流程是什么?A:文档向量化、查询检索、上下文拼接、大模型生成。"),
Document(page_content="Q:HyDE的作用是什么?A:扩充查询语义,提升RAG检索精准度。"),
Document(page_content="Q:RAG能解决什么问题?A:大模型幻觉问题、知识时效性问题。")
]
# 3.2 论文长文档(大分块场景,模拟Transformer技术论文片段)
thesis_docs = [
Document(page_content="Transformer模型由编码器和解码器两部分组成,编码器负责提取输入序列的特征,由多层多头自注意力机制和前馈神经网络构成,多头自注意力机制能捕捉输入序列的不同维度语义信息,前馈神经网络则对每个位置的特征做独立变换。解码器负责生成输出序列,在编码器的基础上增加了掩码多头自注意力机制,避免生成过程中看到未来的位置信息,同时通过编码器-解码器注意力机制融合编码器的特征。Transformer模型采用并行计算方式,相比RNN模型,训练效率大幅提升,成为自然语言处理领域的基础模型,后续的BERT、GPT等模型均基于Transformer架构改进而来。")
]
# 4. 动态分块处理
faq_split_docs = dynamic_chunking(faq_docs, doc_type="faq")
thesis_split_docs = dynamic_chunking(thesis_docs, doc_type="thesis")
# 5. 分别构建向量库和RAG链(FAQ-小分块;论文-大分块)
# 5.1 FAQ-RAG(小分块,精准检索)
faq_vector_db = Chroma.from_documents(faq_split_docs, embeddings, persist_directory="./faq_chunk_chroma")
faq_rag_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=faq_vector_db.as_retriever(k=1))
# 5.2 论文-RAG(大分块,保语义)
thesis_vector_db = Chroma.from_documents(thesis_split_docs, embeddings, persist_directory="./thesis_chunk_chroma")
thesis_rag_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=thesis_vector_db.as_retriever(k=1))
# 6. 测试不同分块的效果
def test_dynamic_chunking():
# FAQ小分块:精准查询细节
faq_question = "Basic RAG的核心流程是什么?"
faq_answer = faq_rag_chain.invoke({"query": faq_question})["result"]
print(f"【FAQ小分块】问题:{faq_question}\n回答:{faq_answer}\n")
# 论文大分块:查询逻辑连贯的问题
thesis_question = "Transformer的编码器由哪些部分组成?它的训练效率为什么比RNN高?"
thesis_answer = thesis_rag_chain.invoke({"query": thesis_question})["result"]
print(f"【论文大分块】问题:{thesis_question}\n回答:{thesis_answer}\n")
# 运行测试
if __name__ == "__main__":
test_dynamic_chunking()
**代码运行效果:**
【FAQ小分块】问题:Basic RAG的核心流程是什么?
回答:Basic RAG的核心流程是文档向量化、查询检索、上下文拼接、大模型生成。
【论文大分块】问题:Transformer的编码器由哪些部分组成?它的训练效率为什么比RNN高?
回答:Transformer的编码器由多层多头自注意力机制和前馈神经网络构成;Transformer模型采用并行计算方式,相比RNN模型,训练效率大幅提升。
2.5:Proposition Chunking(命题式分块)
一种语义级的高级分块策略,区别于基础 RAG 的「按字符数 / 分隔符」的表层分块,命题分块是「按语义命题」的深层分块—— 将文档拆分为独立的、完整的语义命题(即一个独立的事实 / 观点 / 结论),每个分块是一个 “最小完整语义单元”,而非简单的字符片段。
核心特征:
(1)每个命题分块独立成义:单独看一个分块,能理解完整的事实 / 观点;
(2) 分块间无语义重叠:避免不同分块包含相同的核心信息;
(3)分块粒度可控:可拆分为 “基础命题”(如 “自注意力机制分为多头和单头”)或 “复合命题”(如 “自注意力机制通过并行计算提升效率,分为多头和单头”)
解决的 AI 领域问题:
(1)基础表层分块语义不完整的问题:按字符数拆分后,分块无独立语义,导致检索结果无效;
(2) 基础分块语义重叠的问题:多个分块包含相同信息,导致检索结果冗余,大模型生成重复内容;
(3)复杂文档检索精准度低的问题:命题分块是 “最小语义单元”,查询与分块的相似度计算更精准,能匹配到具体的事实 / 观点;
(4)大模型回答碎片化的问题:命题分块的独立语义,让大模型能基于完整的事实生成连贯回答
代码落地:
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain_core.documents import Document
from langchain.prompts import PromptTemplate
# 加载环境变量
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 1. 初始化模型(大模型用于命题分块+生成回答;嵌入模型用于向量化)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# 2. 核心:命题分块提示词(让大模型将文档拆分为独立的语义命题)
PROPOSITION_CHUNK_PROMPT = PromptTemplate(
input_variables=["document"],
template="""请将以下文档拆分为**独立的、完整的语义命题**,遵循以下规则:
1. 每个命题是一个独立的事实/观点/结论,单独看能理解完整语义;
2. 命题分块粒度适中,每个命题不超过50字,避免过细或过粗;
3. 分块间无语义重叠,不重复表达相同的事实/观点;
4. 仅输出命题分块,每行一个命题,无需额外解释;
5. 保留文档中的核心技术术语,不做简化。
文档:{document}
命题分块:"""
)
# 3. 命题分块函数(核心:大模型语义解析→命题分块)
def proposition_chunking(document_content):
# 大模型生成命题分块
prompt = PROPOSITION_CHUNK_PROMPT.format(document=document_content)
chunk_result = llm.invoke(prompt).content
# 将结果转换为LangChain Document对象
proposition_docs = []
for idx, proposition in enumerate(chunk_result.split("\n")):
if proposition.strip(): # 过滤空行
proposition_docs.append(Document(page_content=proposition.strip(), metadata={"命题编号": idx+1}))
return proposition_docs
# 4. 加载测试文档(复杂技术文档,模拟RAG技术手册片段)
original_document = """
RAG 即检索增强生成,是解决大模型幻觉问题的核心技术,其核心流程包括文档预处理、向量库存储、查询检索、上下文拼接、大模型生成五大步骤。文档预处理是RAG的基础,包括文档分块和向量化,分块策略直接影响检索精准度,常见的分块方式有基础字符分块、动态分块和命题分块。HyDE是RAG的查询侧优化技术,属于Query Enhancement体系,通过生成假设文档扩充查询语义,能有效提升短查询和抽象查询的检索精准度,可直接叠加在Basic RAG上使用,无需重构基础架构。
# 5. 执行命题分块(替代传统的表层分块)
proposition_docs = proposition_chunking(original_document)
print("===== 命题分块结果 =====")
for doc in proposition_docs:
print(f"命题{doc.metadata['命题编号']}:{doc.page_content}")
print("-"*80 + "\n")
# 6. 向量化入库(命题分块→向量化)
vector_db = Chroma.from_documents(
documents=proposition_docs,
embedding=embeddings,
persist_directory="./proposition_rag_chroma"
)
retriever = vector_db.as_retriever(search_kwargs={"k": 3}) # 检索相关命题
# 7. 构建命题分块RAG链
proposition_rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
# 8. 测试命题分块RAG(精准查询具体命题)
def proposition_rag_query(question):
result = proposition_rag_chain.invoke({"query": question})
print(f"问题:{question}")
print(f"回答:{result['result']}\n")
print(f"匹配的命题分块:{[doc.page_content for doc in result['source_documents']]}\n")
# 运行测试
if __name__ == "__main__":
proposition_rag_query("RAG的核心流程有哪些?")
proposition_rag_query("HyDE属于哪种技术体系?它的作用是什么?")
proposition_rag_query("文档预处理对RAG有什么影响?")
===== 命题分块结果 =====
命题1:RAG即检索增强生成,是解决大模型幻觉问题的核心技术。
命题2:RAG的核心流程包括文档预处理、向量库存储、查询检索、上下文拼接、大模型生成五大步骤。
命题3:文档预处理是RAG的基础,包括文档分块和向量化。
命题4:分块策略直接影响RAG的检索精准度。
命题5:常见的分块方式有基础字符分块、动态分块和命题分块。
命题6:HyDE是RAG的查询侧优化技术,属于Query Enhancement体系。
命题7:HyDE通过生成假设文档扩充查询语义,提升短查询和抽象查询的检索精准度。
命题8:HyDE可直接叠加在Basic RAG上使用,无需重构基础架构。
问题:RAG的核心流程有哪些?
回答:RAG的核心流程包括文档预处理、向量库存储、查询检索、上下文拼接、大模型生成五大步骤。
匹配的命题分块:['RAG的核心流程包括文档预处理、向量库存储、查询检索、上下文拼接、大模型生成五大步骤。']
问题:HyDE属于哪种技术体系?它的作用是什么?
回答:HyDE属于Query Enhancement体系,是RAG的查询侧优化技术,其作用是通过生成假设文档扩充查询语义,有效提升短查询和抽象查询的检索精准度。
匹配的命题分块:['HyDE通过生成假设文档扩充查询语义,提升短查询和抽象查询的检索精准度。', 'HyDE是RAG的查询侧优化技术,属于Query Enhancement体系。']
问题:文档预处理对RAG有什么影响?
回答:文档预处理是RAG的基础,其包含的分块策略会直接影响RAG的检索精准度。
匹配的命题分块:['分块策略直接影响RAG的检索精准度。', '文档预处理是RAG的基础,包括文档分块和向量化。']
选型原则: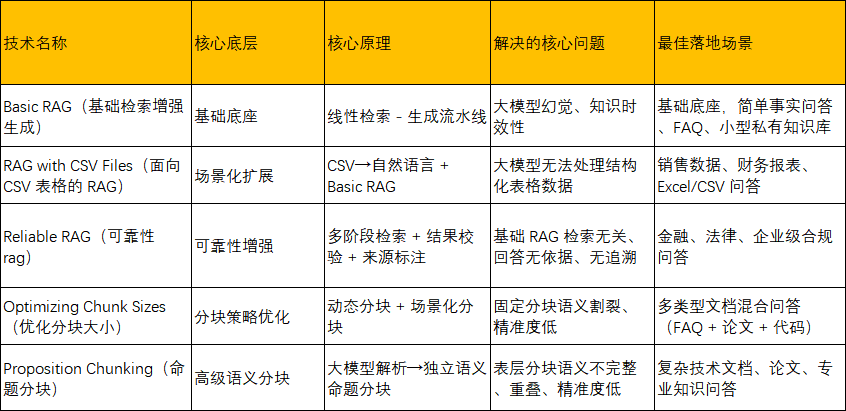
(1)基础必选:Basic RAG 是所有场景的底座,先落地再优化;
(2)表格数据:叠加 RAG with CSV Files,仅修改文档预处理;
(3)企业合规:升级为 Reliable RAG,强化过滤 + 校验 + 标注;
(4)分块优化:优先用 Optimizing Chunk Sizes(动态分块),复杂技术文档再用 Proposition Chunking(命题分块);
(5)全场景混合:搭建「基础底座 + 能力插件 + 路由分发」架构,按需调用,平衡效果与成本

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)