多模态医疗大模型(二)—— 使用LLamaFactory装载Qwen2-VL-2B-Instruct训练MedTrinity-25M
解决冲突(后续遇到不少冲突问题,这个语句还比较有用,后补于此处运行可以省去很多麻烦)安装后报错如下,仔细核对了一下requirements貌似没有多少相干,先略过出现安装成功提示信息启动UI: llamafactory-cli webuiUI页面出现error修改端口号为7433后再尝试再次运行webui成功。
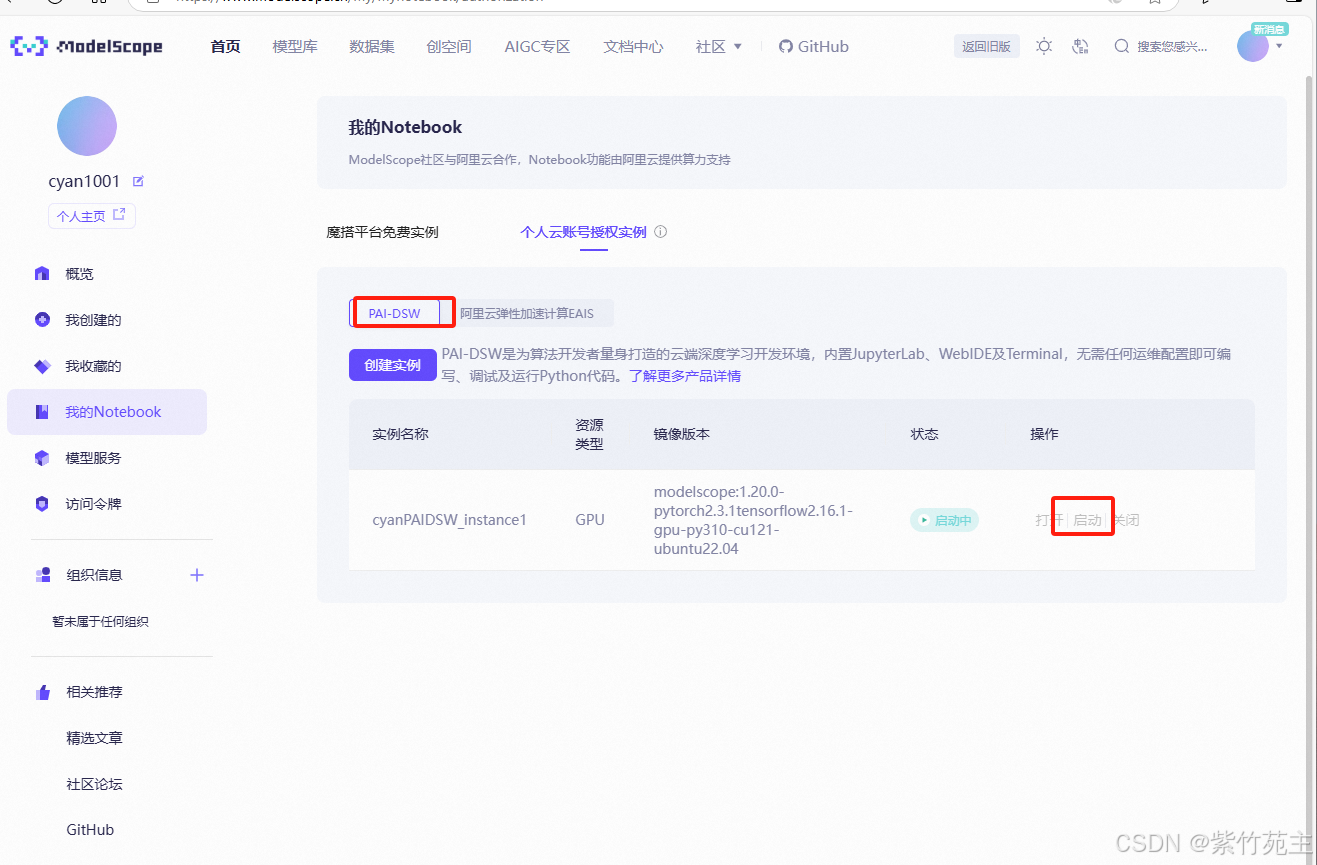
阿里云上启动个人实例
在云实例环境上装载训练框架 LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e “.[torch,metrics]”
解决冲突(后续遇到不少冲突问题,这个语句还比较有用,后补于此处运行可以省去很多麻烦)
pip install --no-deps -e .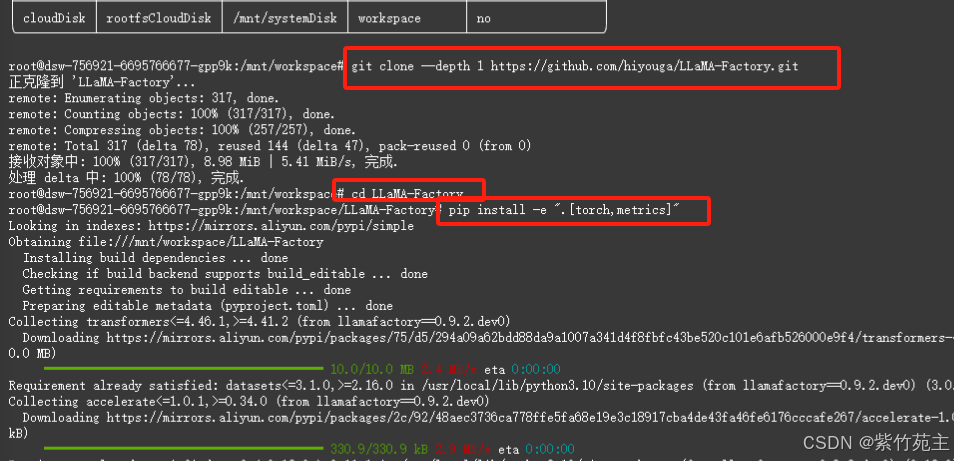
安装后报错如下,仔细核对了一下requirements貌似没有多少相干,先略过
出现安装成功提示信息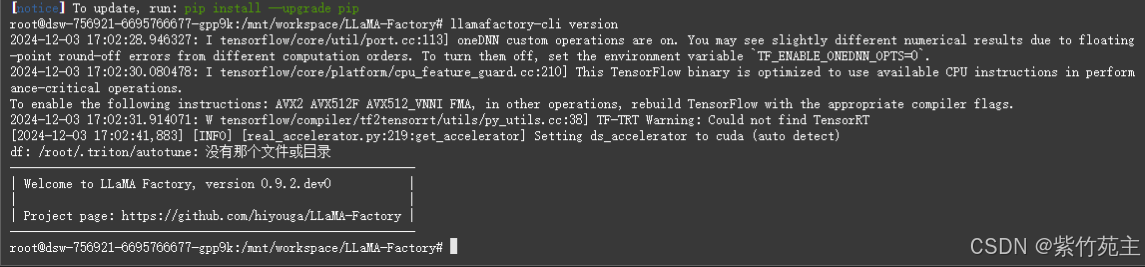
启动UI: llamafactory-cli webui
UI页面出现error
修改端口号为7433后再尝试
export GRADIO_SERVER_PORT=7433 GRADIO_ROOT_PATH=/${JUPYTER_NAME}/proxy/7433/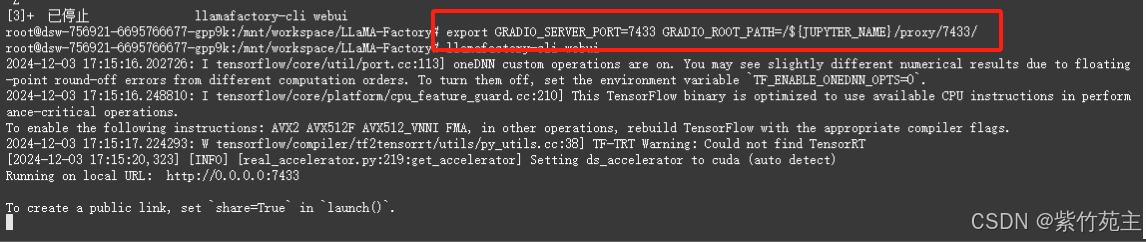
再次运行webui成功
下载视觉多模态预训练模型
通义千问2-VL-2B-Instruct
为什么选择这个模型,详见官网说明。
下载方法: 在LLaMA-Factory下创建models目录,命令行 cd models进入目录,执行git clone下载千问模型:
#git lfs install # 已经安装 lfs可以不需要
git clone https://www.modelscope.cn/Qwen/Qwen2-VL-2B-Instruct.git
为了防止下载不全,可以进入仓库目录运行命令:git fetch --all
在LLamaFactory中装载Qwen2-VL-2B-Instruct模型
模型下载成功后,返回LLaMA-Factory webui页面装载模型

在input 内输入闲聊句子,简单测试装载效果,chatbot给出回答,模型加载测试成功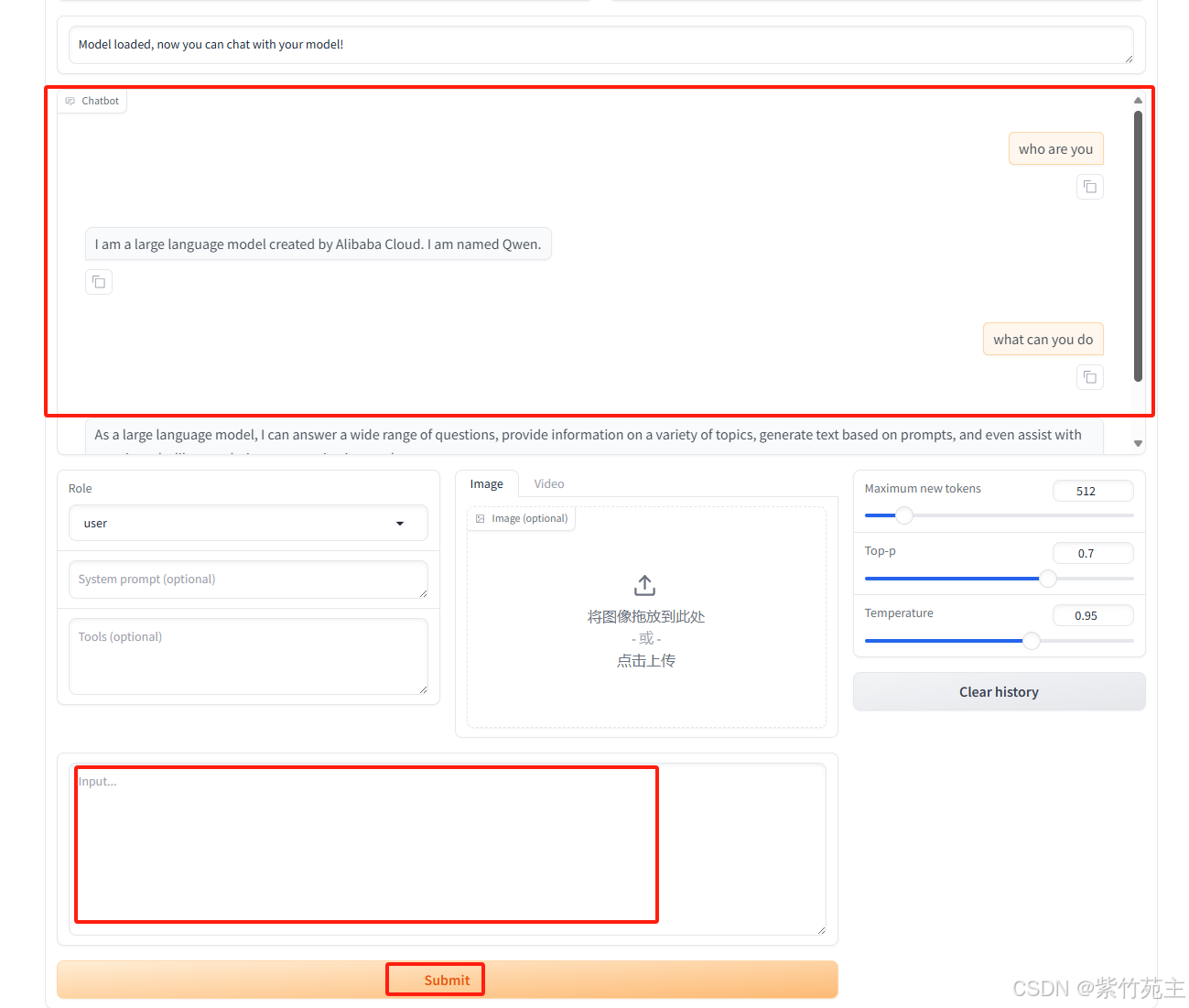
加载图像,测试一下模型对图像的读取能力
加载一个头颅CT,测试读取CT报告的能力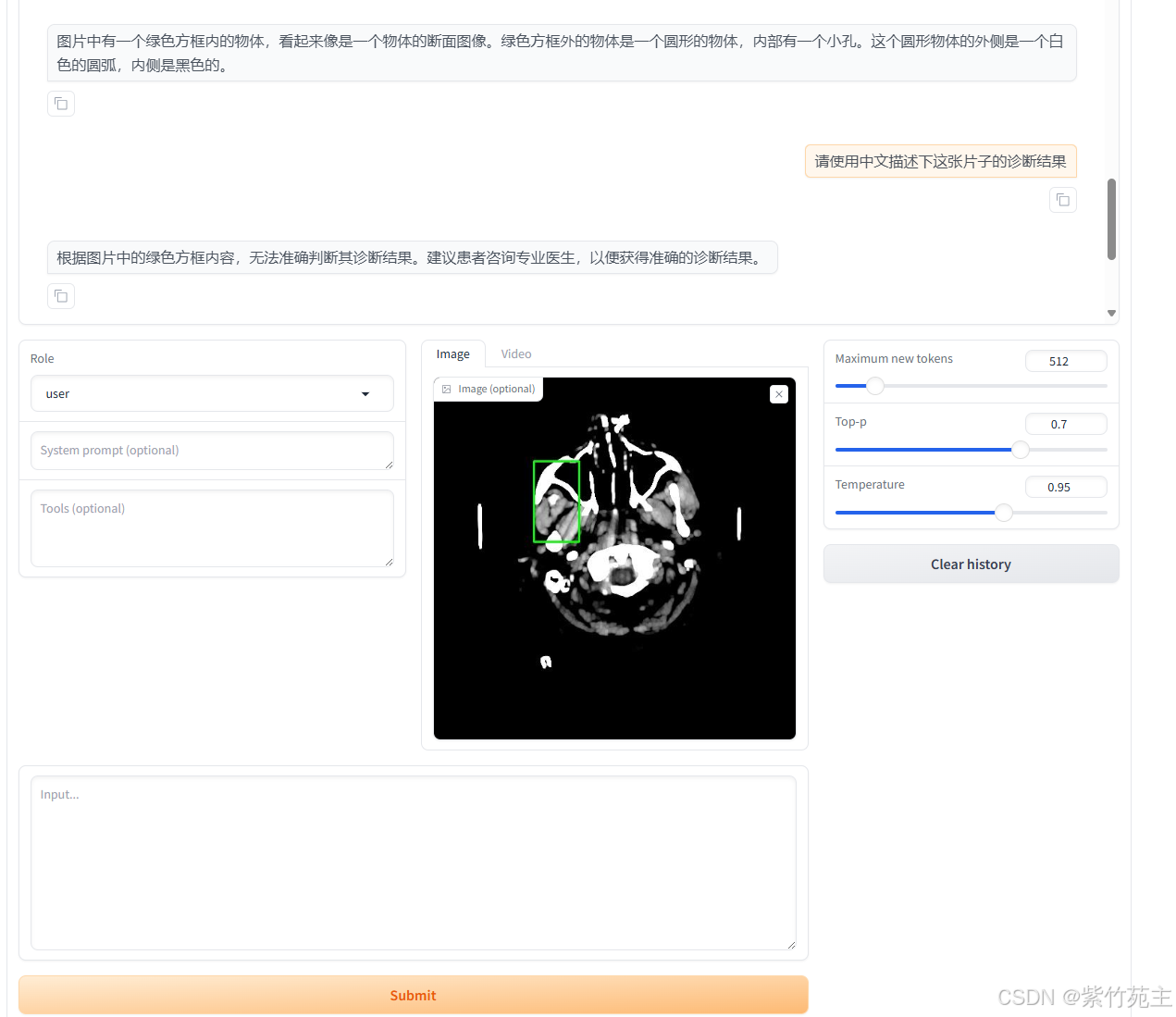
测试结果不难看出,模型把CT报告当成了普通的图片看待,不具有CT报告诊断能力。
预训练
1. 训练数据的格式要求
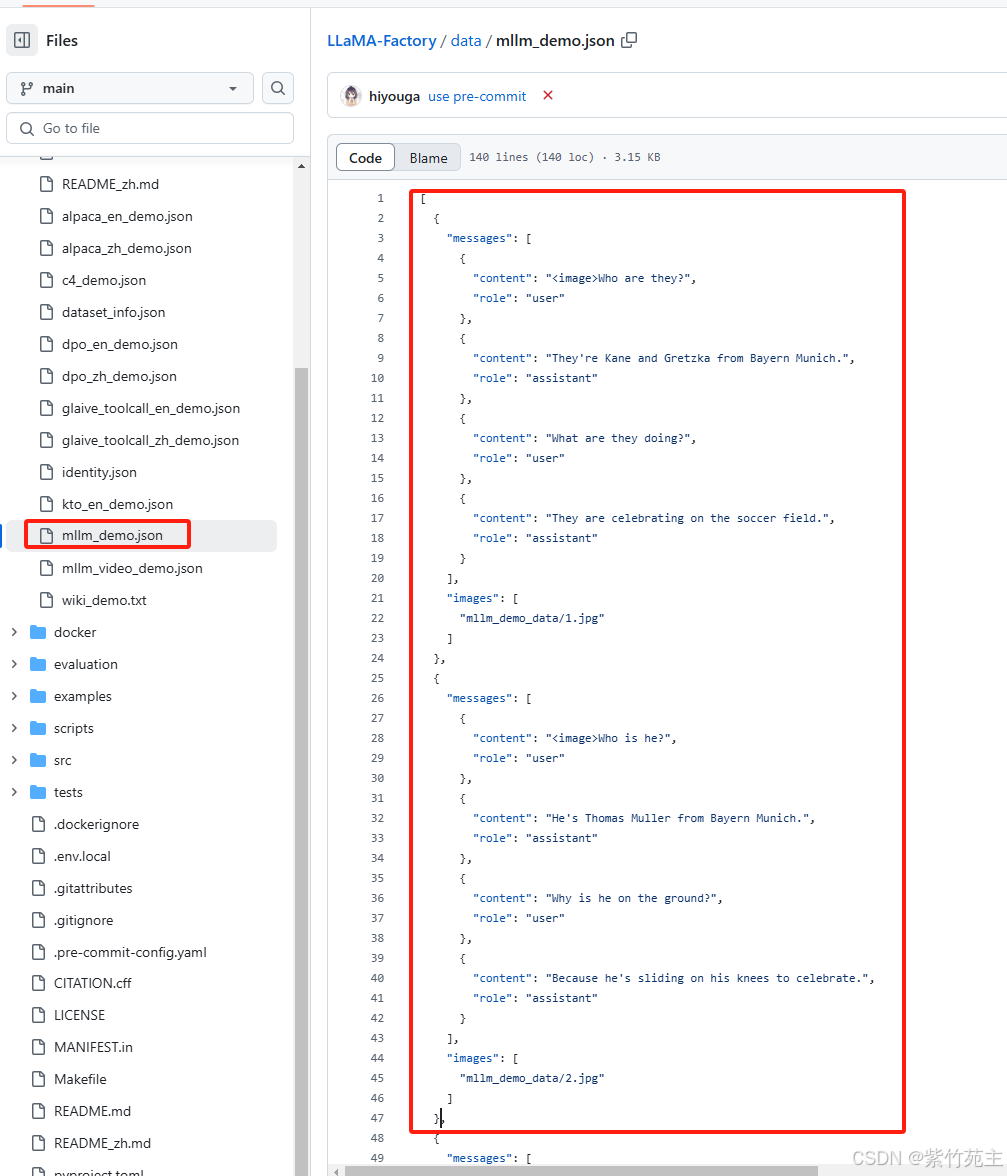
2. 按照格式要求对数据进行格式转换
转换脚本:
from datasets import load_dataset
import os
import json
from PIL import Image
def save_images_and_json(ds, output_dir="mllm_data"):
"""
将数据集中的图像和对应的 JSON 信息保存到指定目录。
参数:
ds: 数据集对象,包含图像和标题。
output_dir: 输出目录,默认为 "mllm_data"。
"""
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 创建一个列表来存储所有的消息和图像信息
all_data = []
# 遍历数据集中的每个项目
for item in ds:
img_path = f"{output_dir}/{item['id']}.jpg" # 图像保存路径
image = item["image"] # 假设这里是一个 PIL 图像对象
# 将图像对象保存为文件
image.save(img_path) # 使用 PIL 的 save 方法
# 添加消息和图像信息到列表中
all_data.append(
{
"messages": [
{
"content": "<image>图片中的诊断结果是怎样?",
"role": "user",
},
{
"content": item["caption"], # 从数据集中获取的标题
"role": "assistant",
},
],
"images": [img_path], # 图像文件路径
}
)
# 创建 JSON 文件
json_file_path = f"{output_dir}/mllm_data.json"
with open(json_file_path, "w", encoding='utf-8') as f:
json.dump(all_data, f, ensure_ascii=False) # 确保中文字符正常显示
if __name__ == "__main__":
# 加载数据集
ds = load_dataset("UCSC-VLAA/MedTrinity-25M", "25M_demo", cache_dir="cache")
# 保存数据集中的图像和 JSON 信息
save_images_and_json(ds['train'])
转换后生成如下json文件和图片文件夹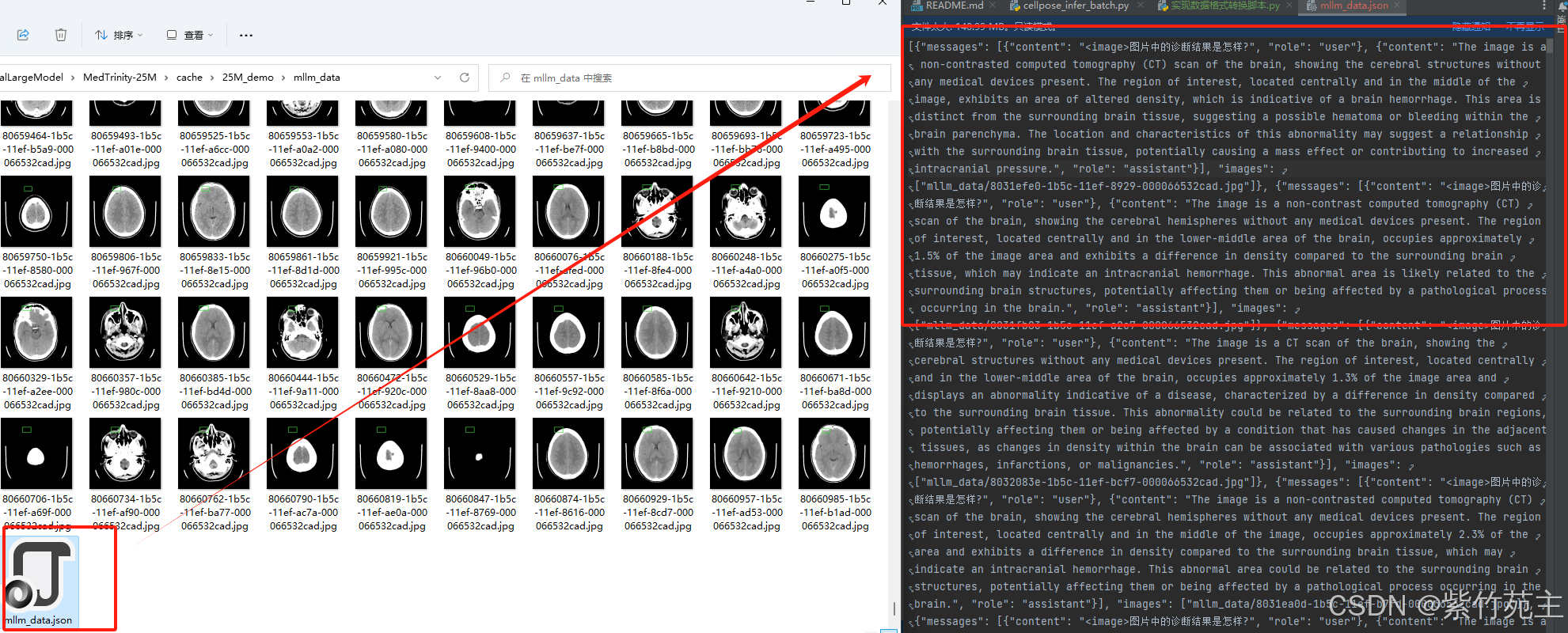
3. 用LLamaFactory训练数据
1. 上传数据到阿里云服务器
将生成的mllm_data文件上传到阿里云个人实例文件夹LLaMaFactory的data目录下
遇到阿里文件中转站限制问题,看来不能直接上传了,试试能不能先上传到git hub或者模搭社区个人数据集中,再从个人数据集上拉取到云服务器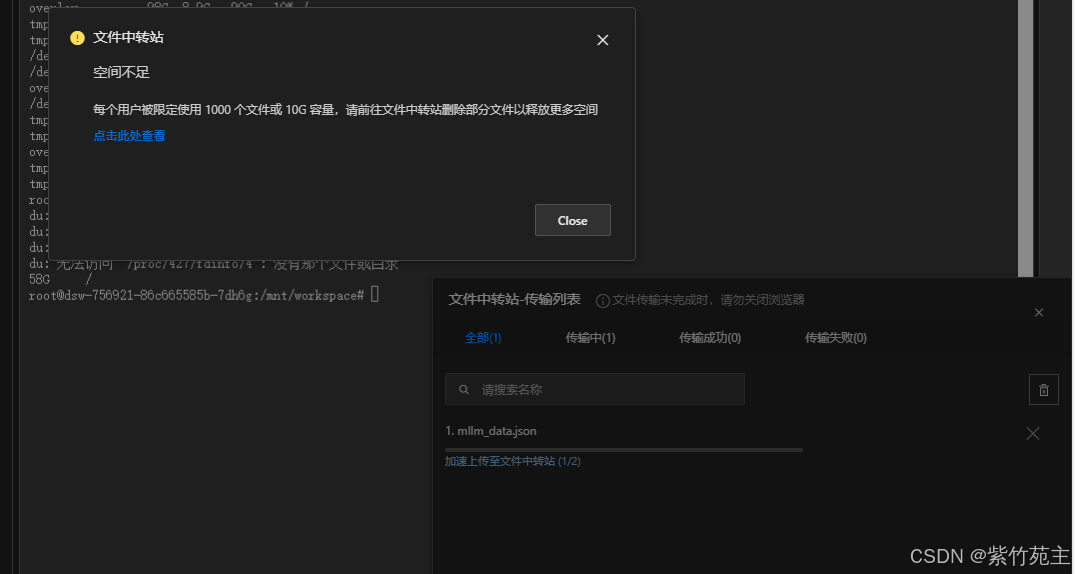
模搭社区上传个人数据的步骤:先创建个人数据仓库——把数据仓库拉取到本地——放入要上传的数据文件——推送到仓库
上传命令:
git clone <您的数据集仓库链接>
进入到本地仓库内,把需要上传的数据压缩文件拷贝进来
git add .
git commit -m “添加数据文件”
git push
等候上传完成即可(git clone时要带上身份认证)
通过模搭社区的数据集成功转移数据到了服务器(注意上传数据集时,一定要压缩文件,MedTrinity-25M数据文件比较多,超出模搭100000数量限制)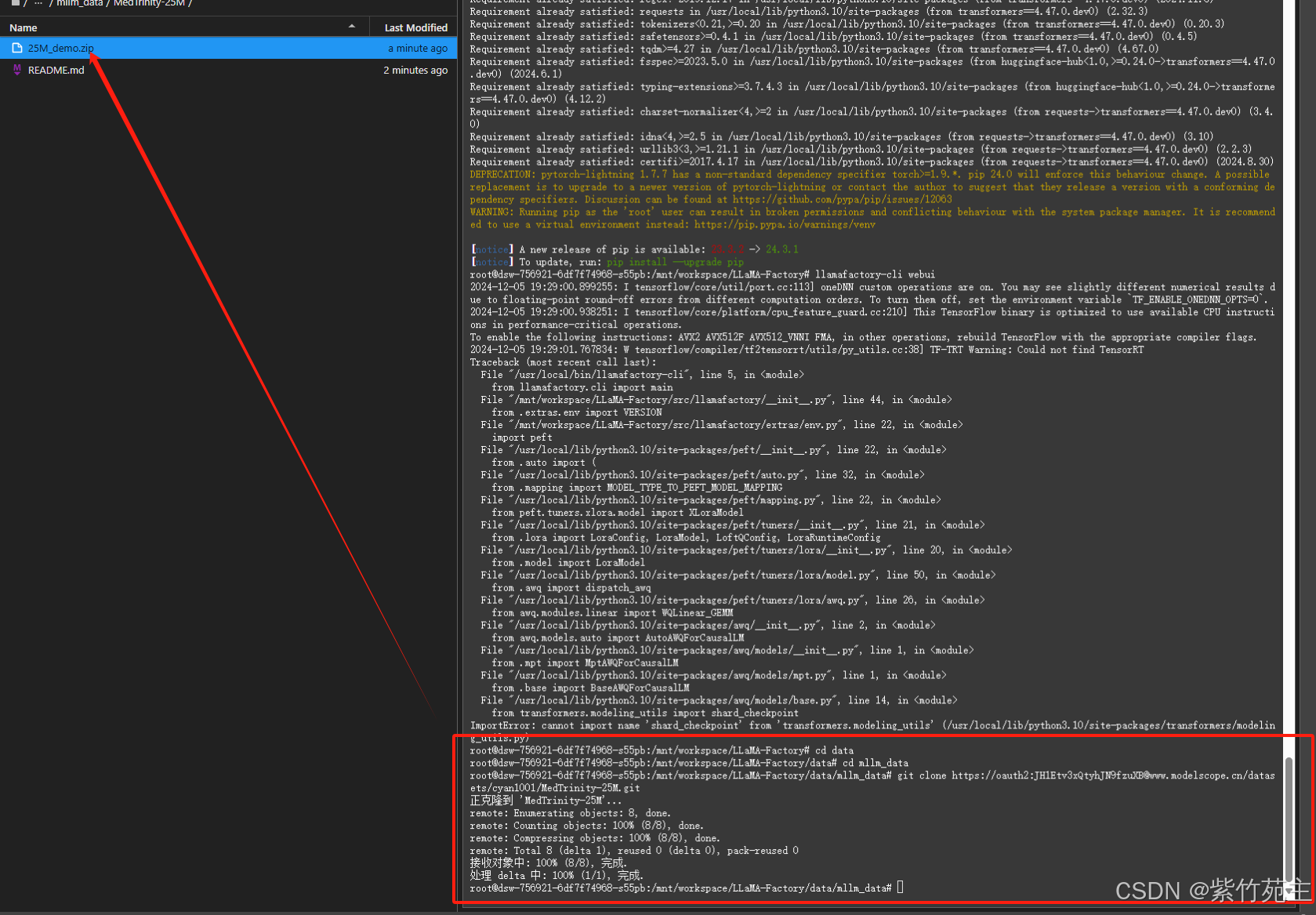
解压压缩文件 命令:unzip filename.zip
把解压后的文件放入data文件夹下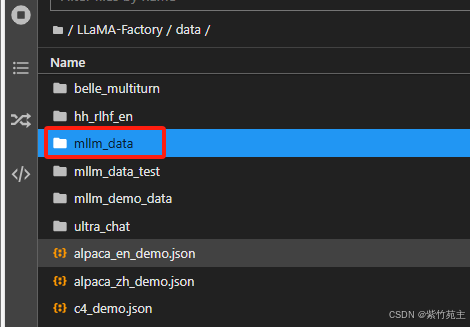
终于搞定了数据集上传问题
2. 修改数据文件
修改 LLaMaFactory data目录下的dataset_info.json,增加自定义数据集
"mllm_med": {
"file_name": "mllm_data/mllm_data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
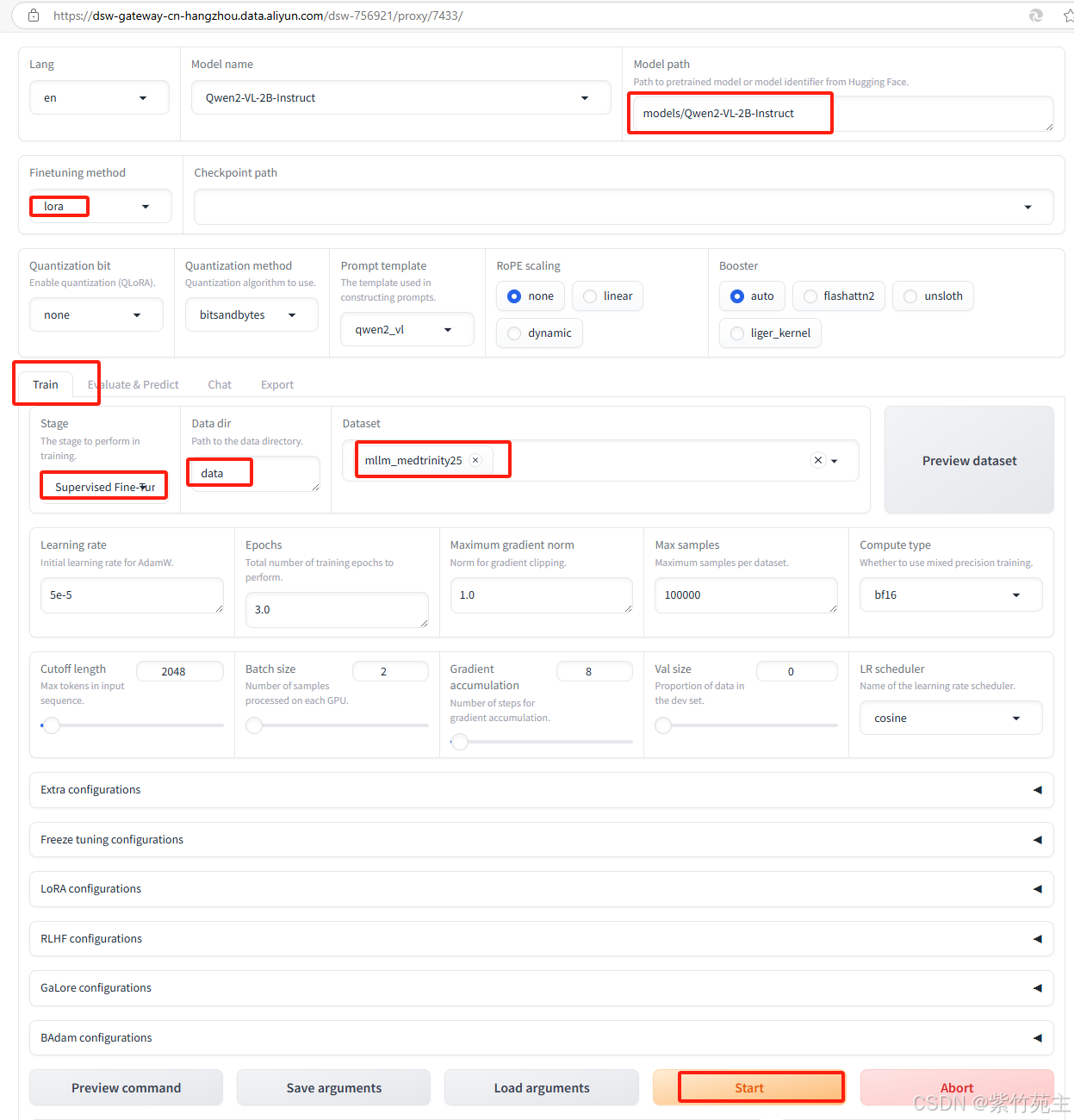
3. 开始微调训练
资源使用率不够,需要重新调整参数。。。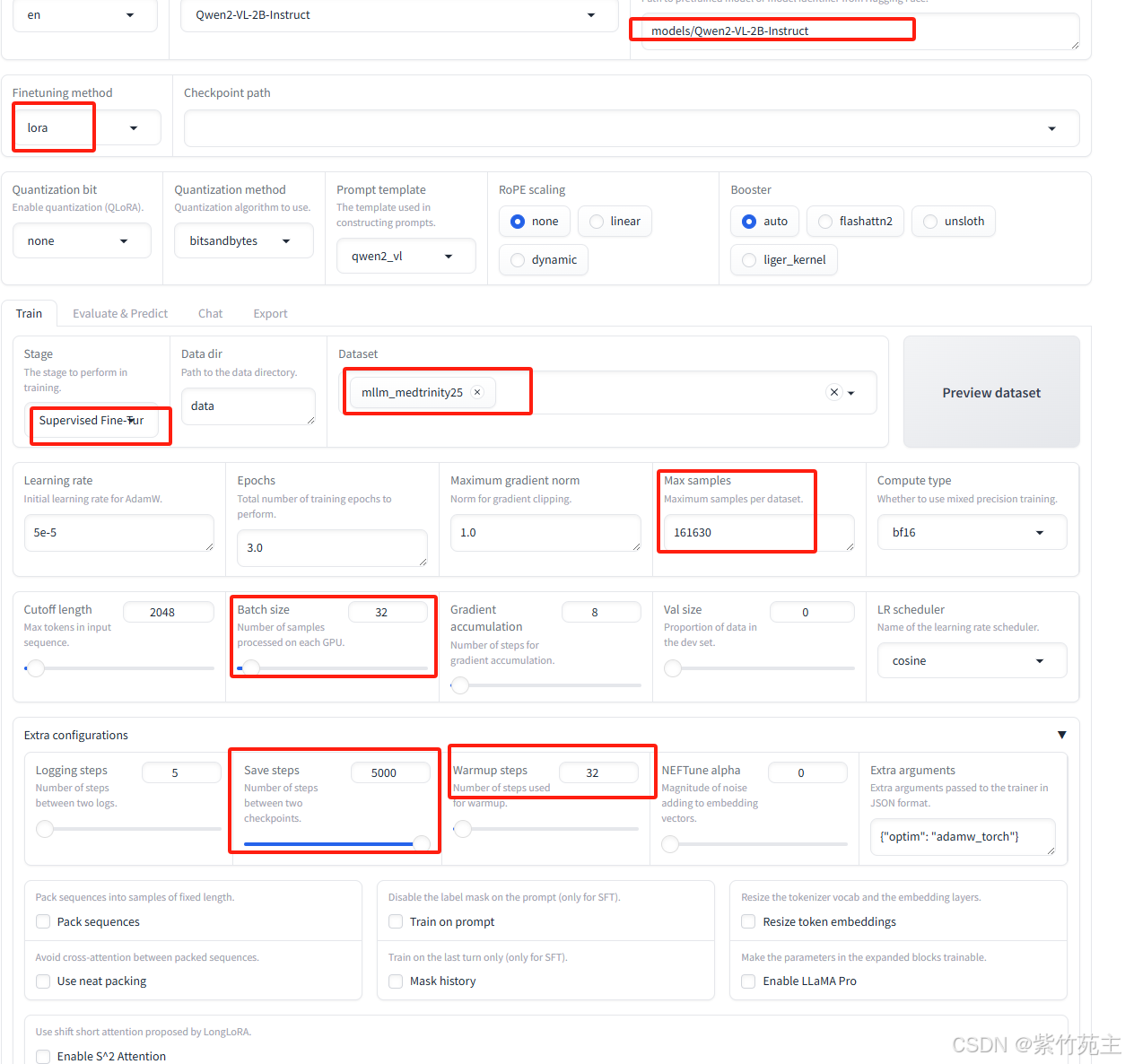


结果挂了,好吧,老实点吧
重新修改参数后执行。。。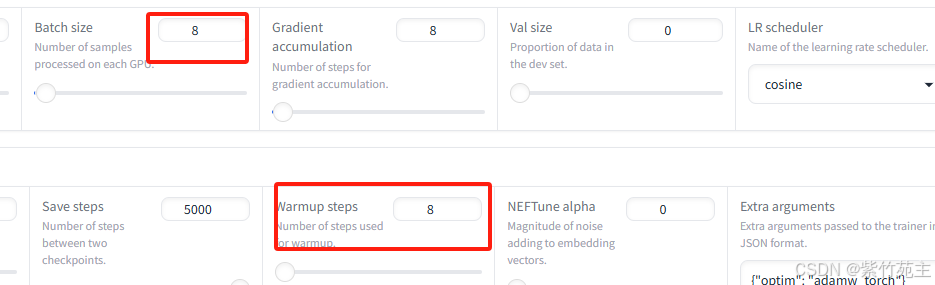
训练前可以通过nvidia-smi命令查看资源初始消耗情况
过程中可以通过watch -n 1 nvidia-smi命令查看资源实时消耗情况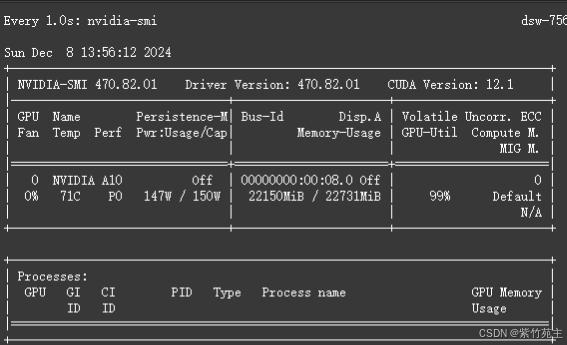
这个资源利用率还是蛮高的,没让我挂掉已属不易
来看看页面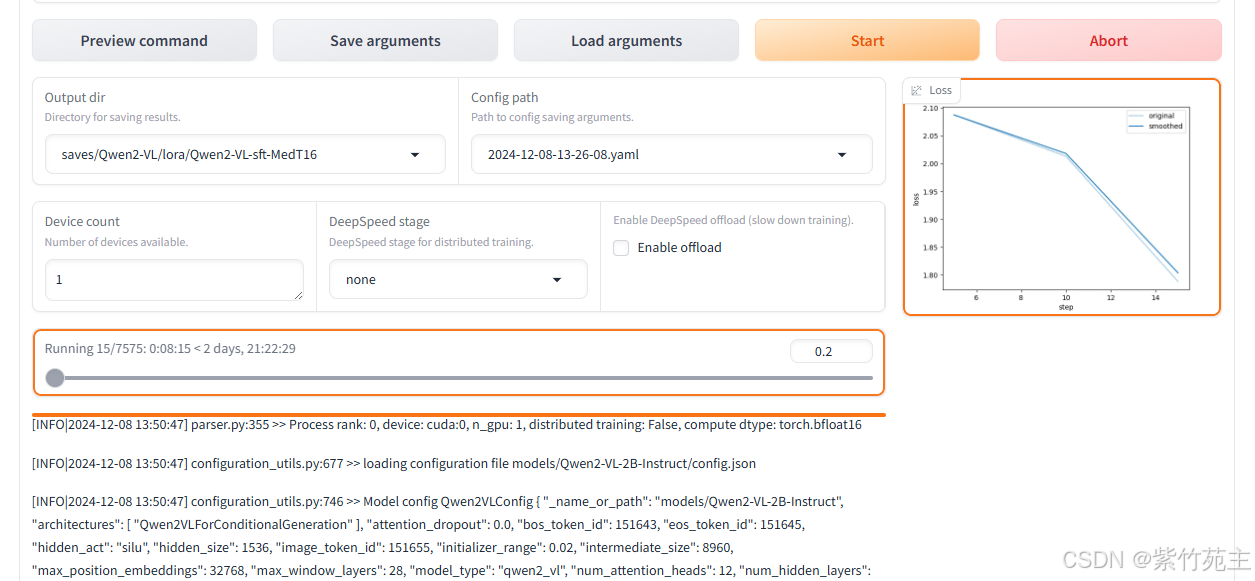
再看看运行明细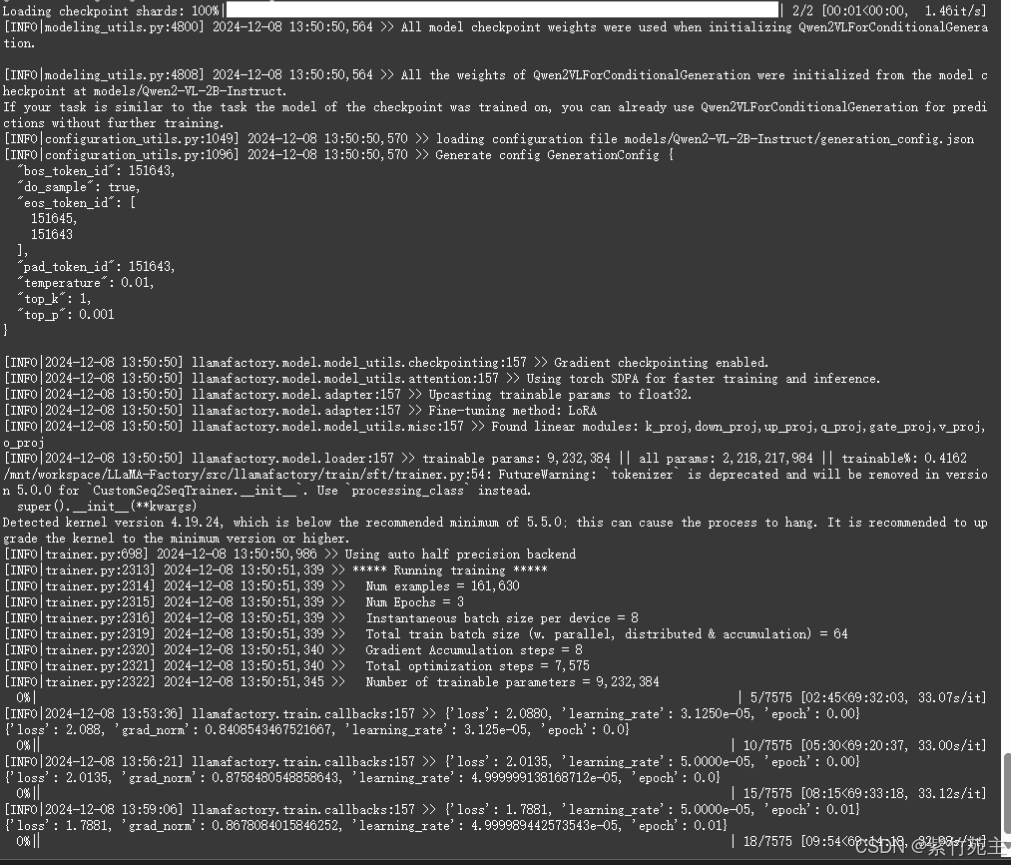
哎,又提示我还需要2个G的GPU,看来得要留出5个G左右的GPU空间用于中途加载任务,把batch size修改为4再次执行(还是老祖宗说的对,没钱就不要那么任性!┭┮﹏┭┮)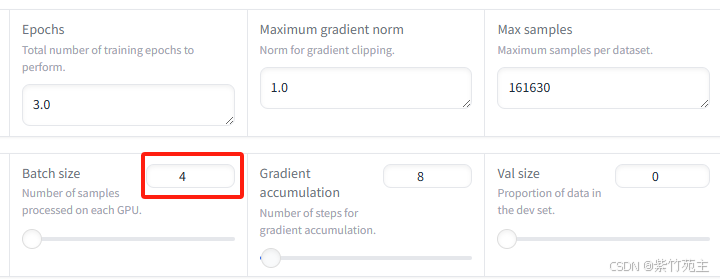
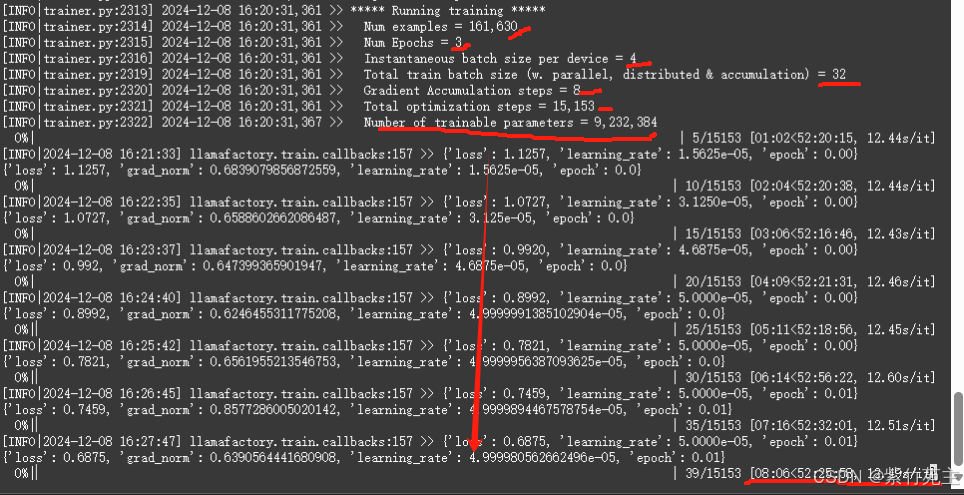
来看看这些参数
Num examples = 161,630 表示样本总数
Num Epochs = 3 总共3个epoch (后悔了,epoch应该改成1,还有那个save step参数应该设置成1000或者800啥的,用不了删掉也比现在总也不save强啊又犯了没钱还想任性的臭毛病┭┮﹏┭┮)
Instantaneous batch size per device = 4 每个设备上的即时批大小为4
Total train batch size (w. parallel, distributed & accumulation) = 32总训练批大小(考虑并行、分布式训练及梯度累积)
Gradient Accumulation steps = 8 梯度累积步数
Total optimization steps = 15,153 总优化步骤
Number of trainable parameters = 9,232,384 总可训练参数数量
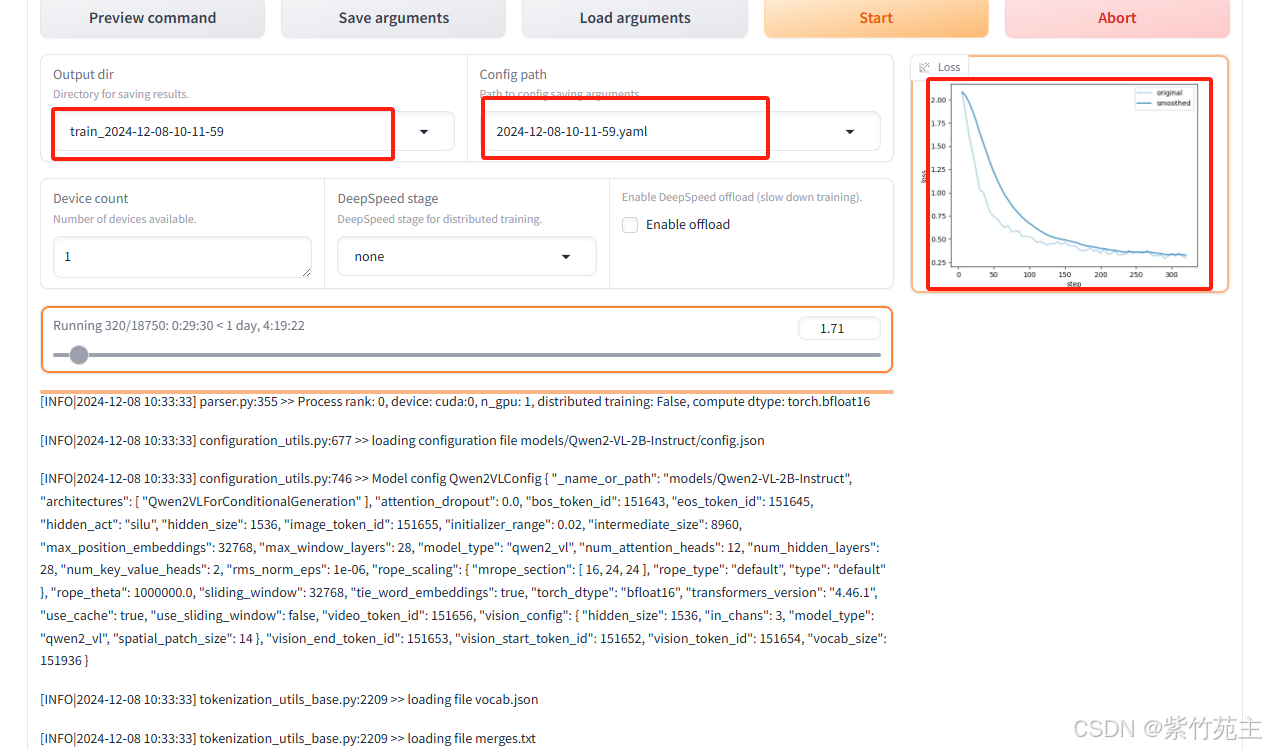
39/15153 [08:06<52:25:58, 12.51 : 15153之第39个优化步骤,耗时08分06秒,总计需要52小时25分钟58秒,每个优化步骤大约花费12.51秒 这是实时计算的结果,大差不差,总训练耗时约52小时(┭┮﹏┭┮)
loss从 1.1257持续降低中,表明在做有效学习,经过一天的训练降到0.10左右出现震荡难以向下
出来第一个保存点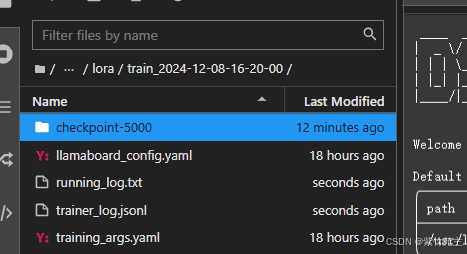
跑到1.2个epoch时,阿里云向我发了算力告急短信,于是手动中断-保存训练参数,生成当前检查点
看看算力还有点时间,打算再跑1000个样本
于是重新载入刚才生成的检查点,设置好训练参数,继续启动训练

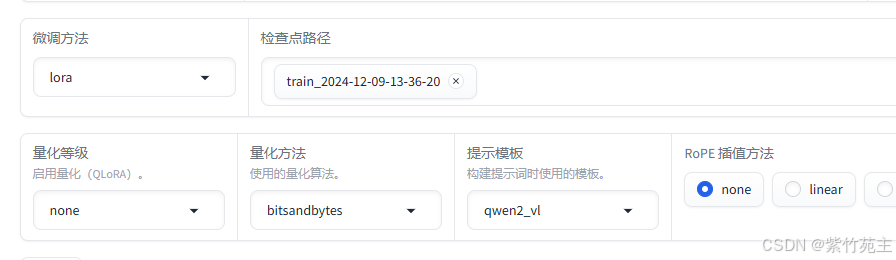
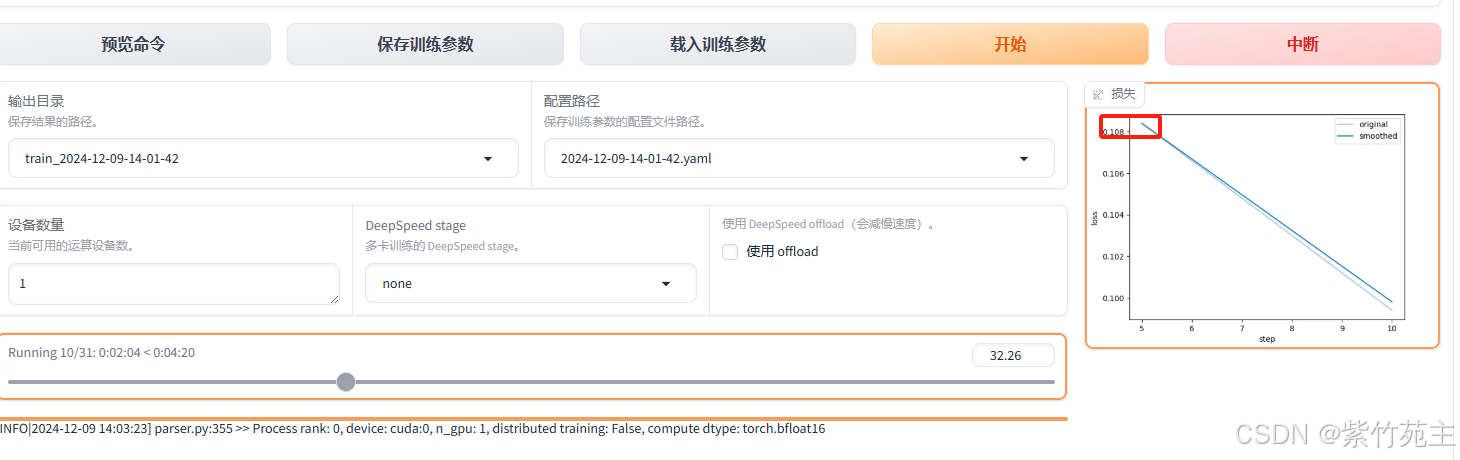
loss会接着中断点保存的参数继续往下再训练1000个数据结束。
忘记截取前面1.2个epoch时候的loss曲线图了,总体看起来还是平滑下降的
最后1000个数据也训练完了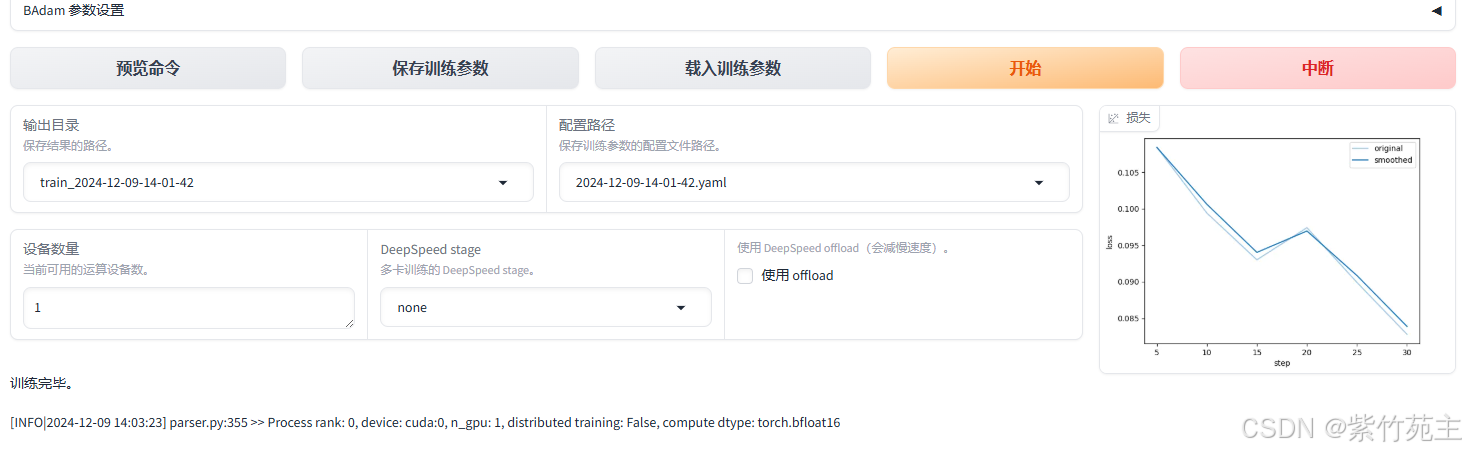
4. 合并导出模型
导出方法参考我另外一篇文章wsl乌班图环境使用LLamaFactory装载千问多模态大模型流程演练 导出模型部分。
5. 测试导出效果
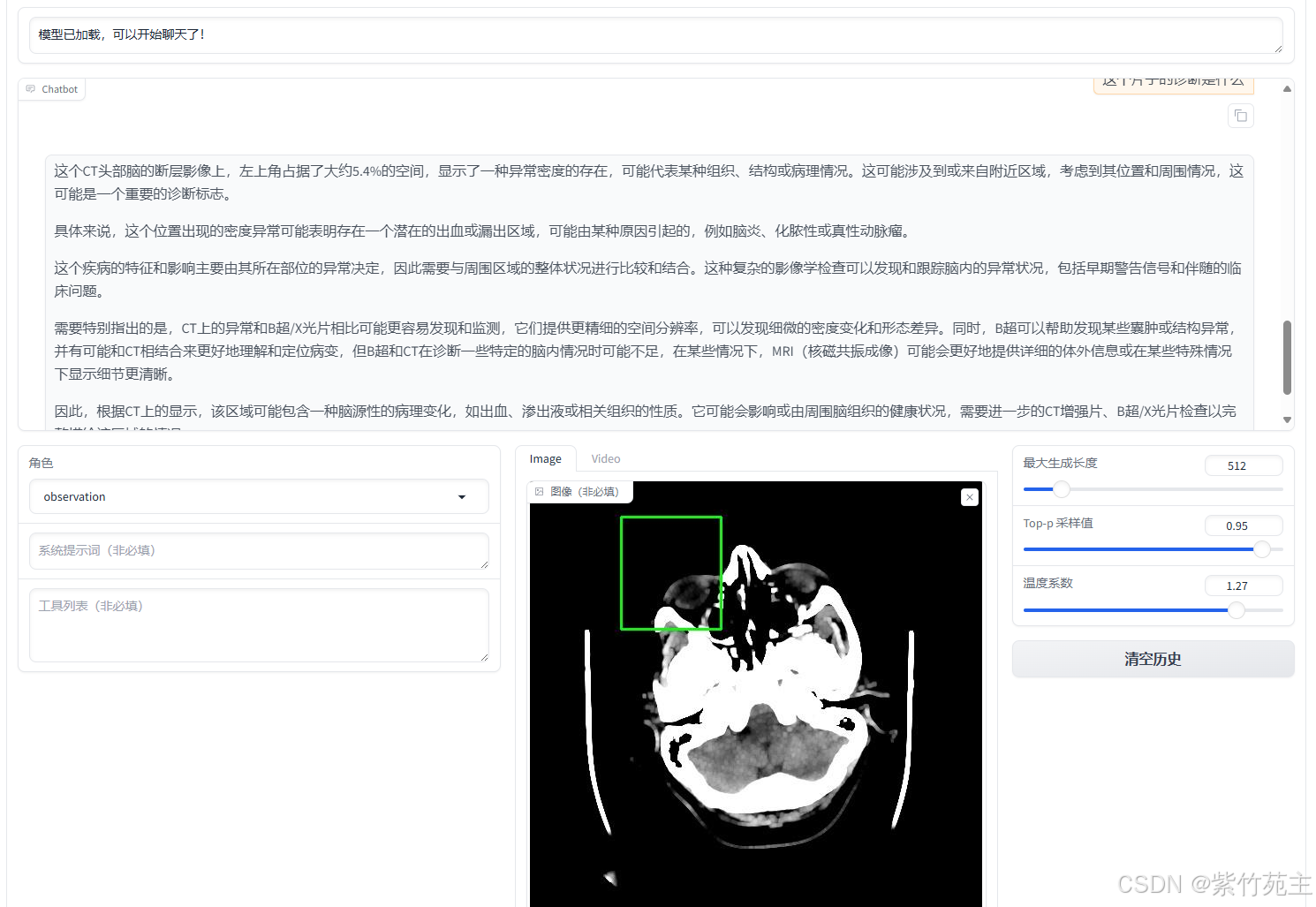
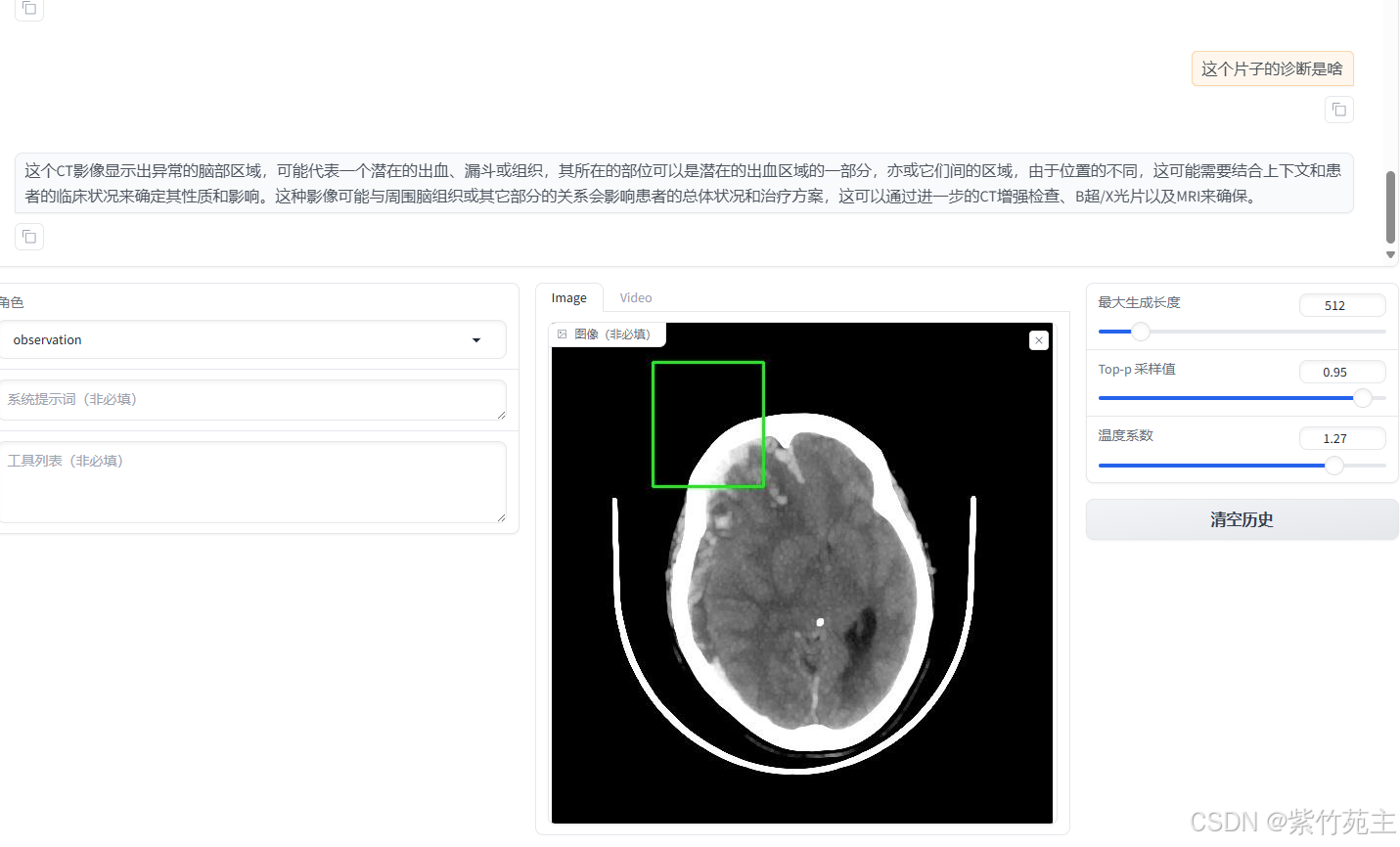

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)