线性回归简介
导包:from sklearn.linear_model import LinearRegression实例化模型: estimator = LinearRegression()训练模型: estimator.fit(x_train, y_train)模型预测: estimator.predict(x_test)
超参数选择方法
交叉验证
交叉验证:是一种数据集的分割方法,将训练集划分为 n 份,拿一份做验证集(测试集)、其他n-1份做训练集
交叉验证法原理:将数据集划分为 cv=4 份
第一次:把第一份数据做验证集,其他数据做训练 第二次:把第二份数据做验证集,其他数据做训练 ... 以此类推,总共训练4次,评估4次。 使用训练集+验证集多次评估模型,取平均值做交叉验证为模型得分 若k=5模型得分最好,再使用全部训练集(训练集+验证集) 对k=5模型再训练一边,再使用测试集对k=5模型做评估
交叉验证法,是划分数据集的一种方法,目的就是为了得到更加准确可信的模型评分。
###
网格搜索
为什么需要网格搜索:模型有很多超参数,其能力也存在很大的差异。需要手动产生很多超参数组合,来训练模型 每组超参数都采用交叉验证评估,最后选出最优参数组合建立模型。
网格搜索是模型调参的有力工具。寻找最优超参数的工具!
只需要将若干参数传递给网格搜索对象,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优的超参数。
<u>网格搜索 + 交叉验证的强力组合 (调优和模型选择)</u>
<u>交叉验证解决模型的数据输入问题(数据集划分)得到更可靠的模型 网格搜索解决超参数的组合 <u>两个组合再一起形成一个模型参数调优的解决方案</u>

线性回归
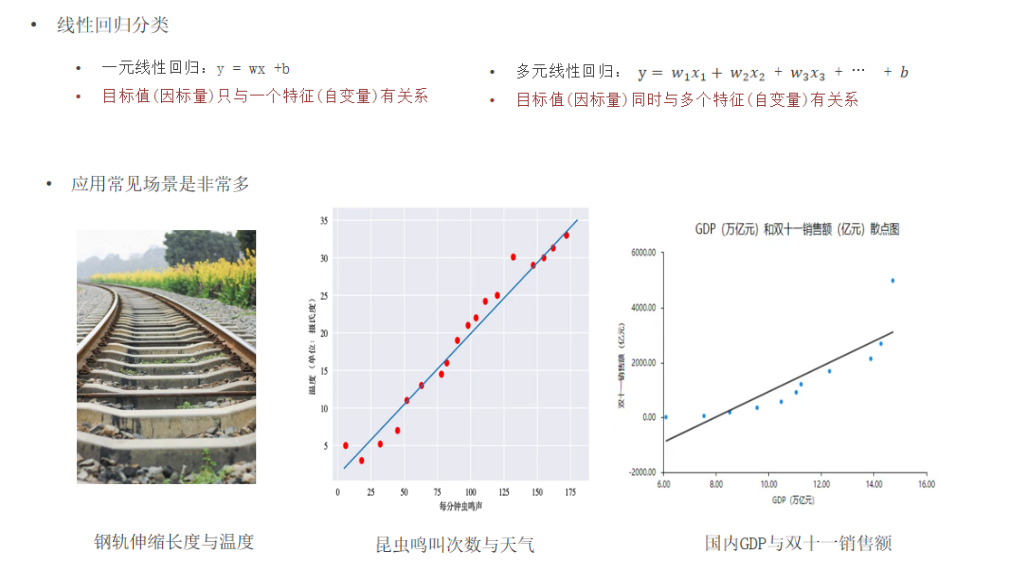
线性回归以及应用场景
线性回归的定义:利用回归方程(函数) 对 一个或多个自变量(特征值)和因变量(目标值)之间 关系进行建模的一种分析方式。
知道线性回归的API
导包:from sklearn.linear_model import LinearRegression
实例化模型: estimator = LinearRegression()
训练模型: estimator.fit(x_train, y_train)
模型预测: estimator.predict(x_test)
损失函数是什么及其作用
1. 损失函数是什么?
误差:预测值 - 真实值的差值
损失函数,也称为代价函数或目标函数,衡量预测值和真实值效果的函数,是机器学习模型在单次训练样本上表现好坏的“度量尺”。
用更直观的方式来说:
-
模型预测:你有一个模型(比如一个预测房价的程序),它根据输入数据(比如房屋面积、位置)给出一个预测值(预测的房价)。
-
真实值:这个预测值对应的实际结果(房屋的真实售价)。
-
差距:损失函数就是一个数学公式,用来量化这个“预测值”和“真实值”之间的差距(误差)。
核心思想:差距越大,损失值越大,说明模型这次预测得越“糟糕”;差距越小,损失值越小,说明预测得越“准确”。
| 核心作用 | 为模型优化提供方向和动力。通过最小化损失函数,驱动模型参数更新,使其预测越来越准。 |
|---|---|
| 主要作用 | 衡量模型性能,
所有样本损失的平均值(即训练损失或测试损失)则反映了模型在整体数据集上的性能。 |

####
梯度下降法
定义:顾名思义:沿着梯度下降的方向求解极小值 举个例子:坡度最陡下山法
什么是梯度 gradient grad:
单变量函数中,梯度就是某一点切线斜率(某一点的导数);有方向为函数增长最快的方向 多变量函数中,梯度就是某一个点的偏导数;有方向:偏导数分量的向量方向
步骤:
输入:初始化位置S;每步距离为a 。输出:从位置S到达山底 步骤1:令初始化位置为山的任意位置S 步骤2:在当前位置环顾四周,如果四周都比S高返回S;否则执行步骤3 步骤3: 在当前位置环顾四周,寻找坡度最陡的方向,令其为x方向 步骤4:沿着x方向往下走,长度为a,到达新的位置S^‘ 步骤5:在S^‘位置环顾四周,如果四周都比S^‘高,则返回S^‘。否则转到步骤3
梯度下降公式:
α: 学习率(步长) 不能太大, 也不能太小. 机器学习中:0.001 ~ 0.01 梯度是上升最快的方向, 我们需要是下降最快的方向, 所以需要加负号

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)