2026年1月,我实操后最推荐的6个AI开源项目(下)
这篇继续聊上下文工程方向的开源项目:MarkItDown把PDF/PPT/表格等一键转干净Markdown;Instructor用Pydantic让LLM稳定输出结构化数据并自动校验重试;Semantic Router用embedding 10ms级意图路由,快省可控
2026年1月,我实操后最推荐的6个AI开源项目(下)
同合集的上一篇讲了Browser-Use、Mem0、PageIndex。
这一篇我们继续讲后3个,依然聚焦"上下文工程":MarkItDown、Instructor、Semantic Router。

第四个:MarkItDown(把一切文档变成LLM能读的格式)
场景:我需要让LLM分析一份PPT、一个Excel表格、一段PDF。但这些文件格式LLM读不了,得先转成文本。
手动复制粘贴?太蠢了。用现成的解析库?格式全乱了。
MarkItDown解决的问题很直接:
把各种文档转成干净的Markdown,保留结构,方便LLM理解。
这是微软AutoGen团队出品的工具。支持的格式多到离谱:PDF、PPT、Word、Excel、图片(OCR+EXIF)、音频(语音转文字)、HTML、CSV、JSON、ZIP、YouTube视频字幕、EPub……
我试了一份带表格的PDF财报,转出来的Markdown表格结构完好、数字准确。直接丢给Claude分析,效果比复制粘贴好太多。
为什么它比其他方案好?
比textract更专注于"保留结构"
比直接用PyPDF2/pdfplumber更省心(一行代码搞定)
支持MCP协议,能直接接入各个Agent
数据:85.5k stars,74位贡献者,微软出品,2.1k项目在用。
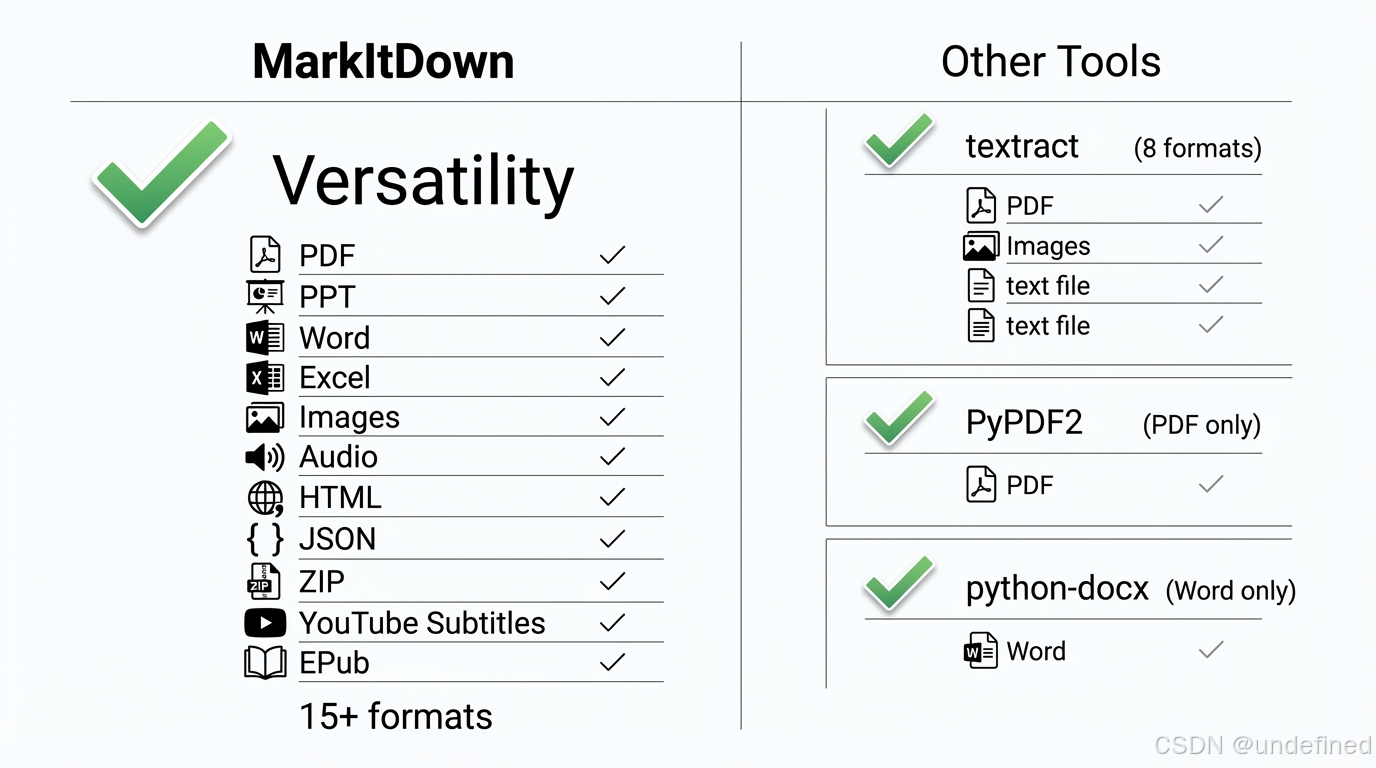
适用场景:
文档问答系统的预处理
多格式文档的统一解析
RAG系统的文档入库
局限:OCR和语音转文字依赖外服务,极复杂排版的PDF可能丢失部分格式(社区反映,我没遇到过)。

场景:我让LLM提取一段文本里的信息,比如"把这段话里的人名、年龄、地址提取出来"。LLM返回了一段自然语言,我还得写正则去解析——又慢又容易出错。
Instructor解决的问题是:让LLM直接返回结构化对象,定义好schema,自动验证、自动重试。
你用Pydantic定义一个数据模型,Instructor让LLM直接输出符合这个模型的对象。
不需要手动写JSON schema,不需要解析字符串,不需要处理格式错误。
|
Python |
核心价值:
自动验证:输出不符合schema?自动重试
流式支持:边生成边返回部分对象
多provider:OpenAI、Anthropic、Google、Ollama一套代码
数据:12.2k stars,254位贡献者,每月300万+下载量,OpenAI/Google/Microsoft团队都在用。
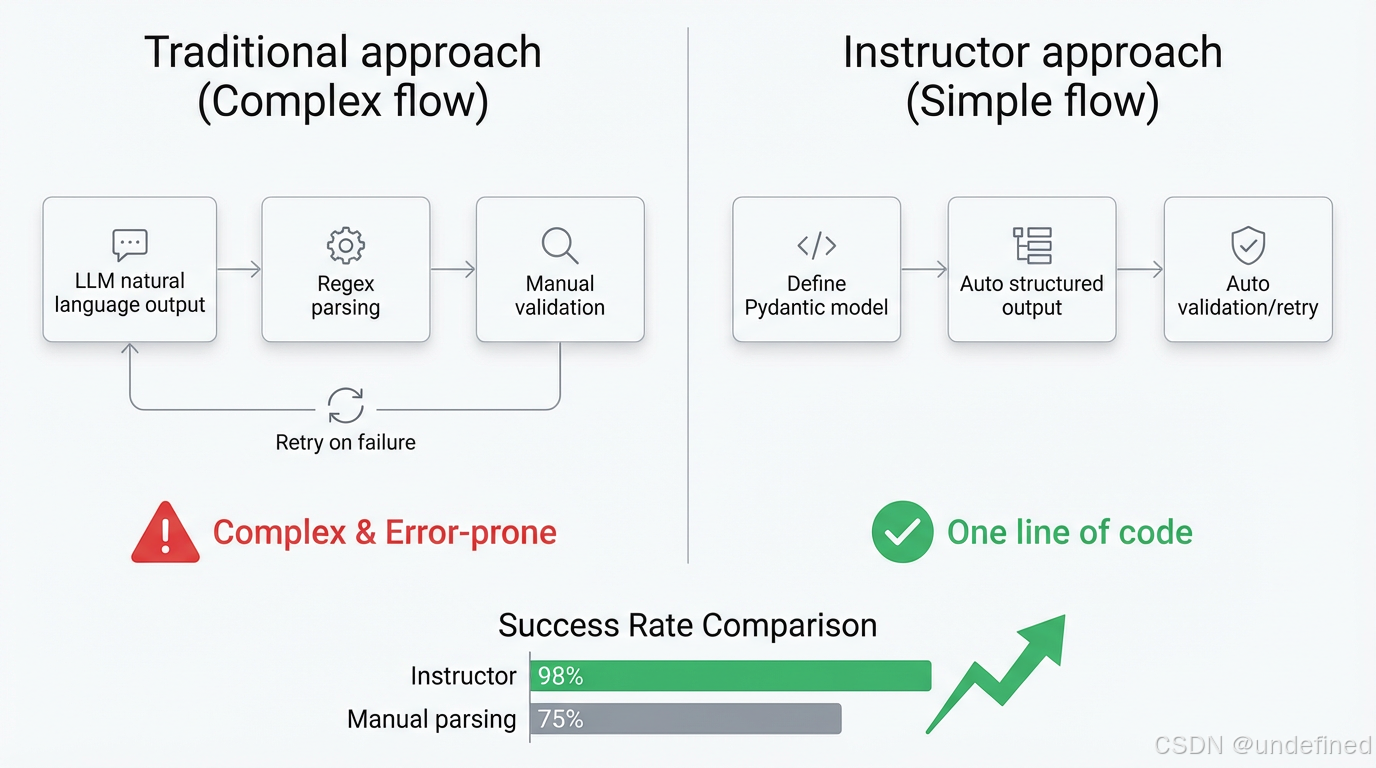
适用场景:
信息提取(NER、关系抽取)
表单解析
任何需要LLM返回结构化数据的场景
局限:主要面向提取任务,不适合开放式生成;对token消耗比纯文本输出稍高。
规避动作:先评估任务是否真的需要结构化输出,简单场景用Prompt指令即可。

场景:一个AI客服demo,用户可能问产品问题、投诉、闲聊、敏感话题……每种需要走不同的处理流程。
让LLM判断意图又太慢了,而且每次都要调用API。
Semantic Router解决的问题是:用向量相似度做"超快决策层",10毫秒级别判断用户意图。
原理很简单:你预定义几条"意图路由",每条路由有几个示例utterance。用户输入进来,算embedding相似度,瞬间匹配到对应路由。比调LLM快100倍以上。
|
Python |
为什么它比LLM判断好?
速度:10ms vs 1000ms
成本:embedding调用比LLM便宜几十倍
可控:明确的规则,出错的概率更低。
数据:3.2k stars,45位贡献者,支持Cohere/OpenAI/HuggingFace/本地模型。
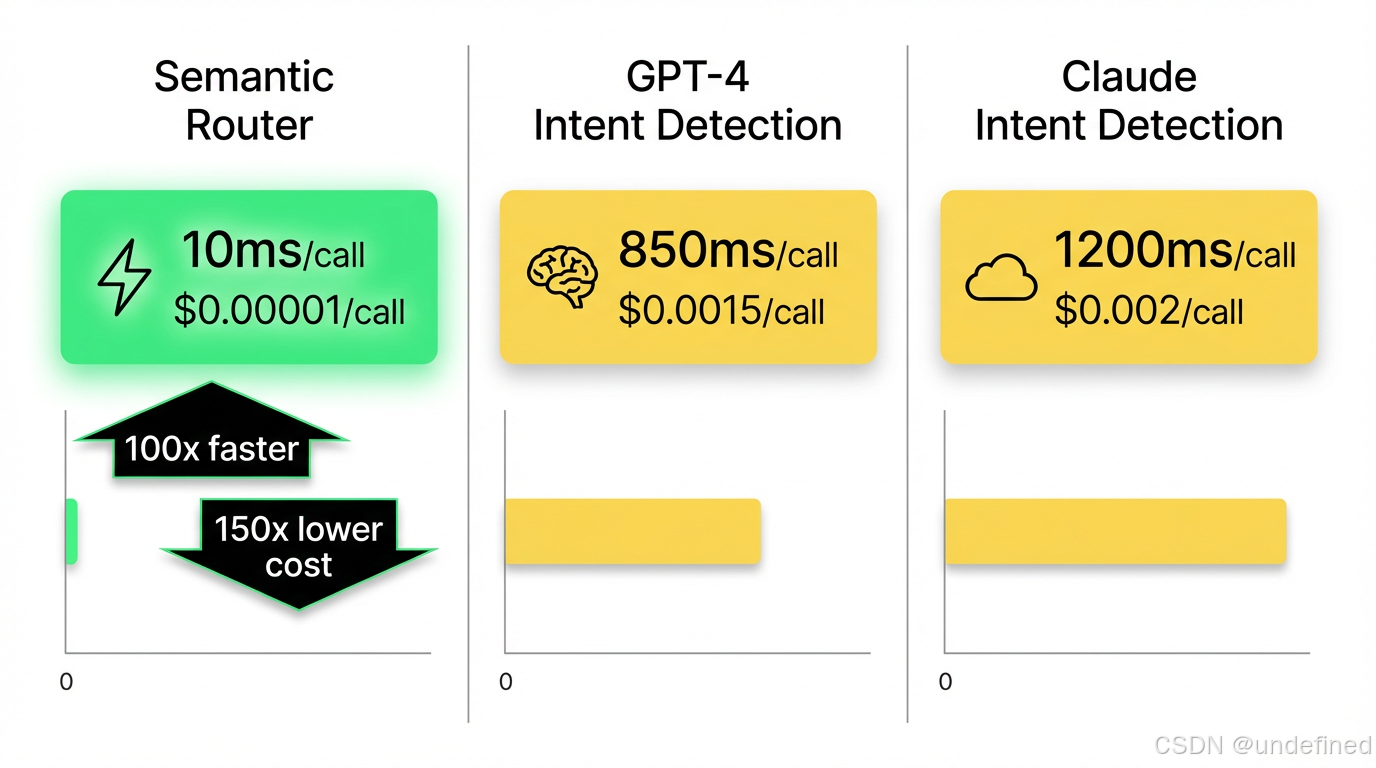
适用场景:
多轮对话的意图分类
敏感话题过滤
Agent的工具选择
局限:需要预定义意图,无法处理完全开放的问题;对utterance质量敏感,示例不好会影响准确率。
规避动作:每条路由至少5-10个高质量示例;定期根据真实用户输入优化utterance。
回头看这6个项目,它们能留下来,不是因为"功能最全"或"生态最大",而是:
1. 解决一个明确的痛点
Browser-Use:AI不能操作浏览器
Mem0:AI没有长期记忆
PageIndex:RAG检索不准
MarkItDown:文档格式LLM读不了
Instructor:LLM输出难解析
Semantic Router:意图判断太慢
每个都是一句话能说清楚的问题。
2. 上手门槛极低
六个项目都是pip install就能跑,不需要复杂的环境配置,不需要读100页文档才能入门。
3. 社区活跃
issues有人回复,PR有人审,每周都有更新。这意味着遇到问题有人帮,版本迭代有保障。
如果你看完想试试,这是我的建议:
1. 从场景倒推选项
不要因为"这个项目很火"就去用。先想清楚你要解决什么问题,再看哪个项目最匹配。
2. 小规模验证再投入
每个项目基本都有免费的demo或Colab笔记本。先跑通一个最小案例,确认适合你的场景,再考虑生产部署。
3. 关注社区活跃度
开源项目最怕的是"弃坑"。选之前看看:最近一次commit是什么时候?issues有人回复吗?贡献者还在活跃吗?
死项目尽可能不要碰,即使功能看起来完美。
这6个项目不是"最好的",而是"我用过觉得好的"。
你的场景、你的需求、你的技术栈可能不一样。但如果你也在找"不烂大街但真正好用"的AI开源项目,希望这两篇能给你一些参考。
既然看到这了,如果觉得不错,随手点个赞、收藏、转发三连吧~
有问题欢迎留言,我是Carl,更多AI趋势与实战,关注我,我们下期见!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)