代码的梦魇:基于 AI 的漏洞挖掘(Fuzzing)进化论
因为深度学习框架的 API 约束极强(张量维度必须匹配),传统 Fuzzing 效率极低,而 LLM 能够理解“张量形状推导”的逻辑,生成高通过率的测试代码。在实际工程中(如 Google 的 FuzzBench),这个状态空间会极其巨大,Q-Table 会被深度神经网络(DQN)取代,而奖励函数会包含更细粒度的指标(如分支翻转数、内存消耗等)。它存在严重的**“幻觉”(Hallucination
代码的梦魇:基于 AI 的漏洞挖掘(Fuzzing)进化论
你好,我是陈涉川。这是《硅基之盾》专栏的第 11 篇。这不仅仅是一篇文章,这是一份关于“机器如何猎杀机器”的深度技术档案。
“软件不仅是代码的集合,它是逻辑的迷宫。而今天,我们正在训练一只能够看穿迷宫墙壁的‘米诺陶诺斯’。”
引言:从无限猴子定理到上帝的骰子
1913 年,数学家埃米尔·博雷尔(Émile Borel)提出了著名的“无限猴子定理”:如果让无数只猴子在无数台打字机上随机敲击,只要时间足够长,它们最终能打出一部《莎士比亚全集》。
在网络安全领域,这个定理被奉为圭臬长达三十年。我们把这种技术称为 Fuzzing(模糊测试)。
传统的 Fuzzer(如早期的 zzuf 或基础版的 Peach)就像那些猴子。它们向目标程序疯狂地投喂随机生成的垃圾数据——畸形的字符串、溢出的整数、截断的文件头——以此祈祷程序崩溃(Crash)。一旦崩溃,就意味着内存溢出、空指针引用或逻辑错误,也就意味着发现了一个潜在的 0-day 漏洞。
注:在现代工程实践中,我们不仅仅等待 Crash。我们通常会配合 Sanitizers (如 ASan, UBSan) 编译程序。这些工具能在内存越界发生的瞬间‘踩刹车’并报错,即使该错误原本不会导致程序立即崩溃。AI Fuzzer 的目标函数往往也包含 Sanitizer 的反馈权重。
然而,随着软件复杂度的指数级上升,现代软件不再是简单的文本处理机,而是拥有复杂状态机、加密校验和深度嵌套逻辑的堡垒。“猴子”敲出的随机字符,99.999% 都会在输入校验的第一关(如 if (checksum != crc32(data)) return;)被挡在门外。
对于一个拥有数百万行代码的现代操作系统内核或浏览器引擎,依靠“随机”去触碰深层逻辑,其概率在数学上等同于“热力学第二定律的自发逆转”。其成功率在数学上无限趋近于零,就像期待破碎的杯子自动复原一样。
我们需要进化。
我们需要一种不再盲目乱敲的生物。我们需要一种能够阅读代码、理解逻辑、甚至预判开发者思维谬误的智能体。
这就是 AI-Fuzzing(智能模糊测试) 的诞生背景。这不是简单的工具升级,这是从 “暴力美学” 到 “认知对抗” 的范式转移。
第一章 困兽之斗:传统 Fuzzing 的数学边界与瓶颈
要理解 AI 为何是救世主,首先必须深刻理解传统 Fuzzing 面对的绝望。
1.1 覆盖率导向(CGF)的辉煌与局限
在 AI 入局之前,Fuzzing 领域的“王”是 AFL (American Fuzzy Lop)。
AFL 的核心贡献在于引入了**遗传算法(Genetic Algorithm)**的思想。它通过插桩(Instrumentation)监控代码的执行路径。如果一个变异的输入让程序多执行了一行新代码(即发现了新路径),AFL 就会把这个输入保留下来作为“种子”,继续变异。
用数学语言描述,Fuzzing 是一个在高维离散空间中的搜索问题。
设目标程序为函数 P(x),输入空间为X。Fuzzing 的本质是一个优化问题:寻找输入 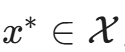 ,使得 P(x^*) 触发异常状态 $E$(如 Crash 或 Sanitizer 报警)。AFL 的策略是通过最大化路径覆盖率C(x)来间接逼近 E。
,使得 P(x^*) 触发异常状态 $E$(如 Crash 或 Sanitizer 报警)。AFL 的策略是通过最大化路径覆盖率C(x)来间接逼近 E。
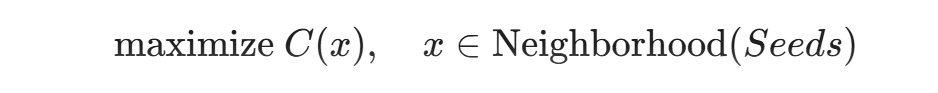
然而,AFL 撞上了三堵墙:
- 魔数与校验和(Magic Numbers & Checksums):
代码中常有 if (input == 0xDEADBEEF) { ... } 这样的检查。对于随机变异的 AFL 来说,在 2^{32} 的空间中正好随机到 0xDEADBEEF 的概率微乎其微。这被称为**“硬比较”**难题。
- 结构化输入的崩塌:
对于 PDF、XML 或 JavaScript 引擎,输入必须符合严格的语法(Grammar)。传统的比特翻转(Bit-flip)策略(例如把 <xml> 变成 <xnl>)会直接导致解析器报错退出,根本无法触及核心业务逻辑。
- 路径爆炸(Path Explosion):
随着程序分支的增加,可能的执行路径呈指数级增长。AFL 维护的 Bitmap(用于记录路径哈希)很快就会饱和,产生大量的哈希冲突,导致它“以为”自己探索了新路径,实际上只是在原地打转。
1.2 符号执行(Symbolic Execution)的算力诅咒
为了解决“硬比较”问题,学术界引入了符号执行(如 KLEE, S2E)。
这种方法不运行程序,而是用数学公式推导程序的逻辑。
例如:if (x * 2 == 10)。符号执行引擎会解方程,得出 x=5。
这听起来很完美,但在工程上是噩梦。
当程序包含加密算法(如 AES)或哈希函数(如 SHA-256)时,符号执行引擎会试图构建极其复杂的约束方程组。这在计算复杂性理论上属于 NP-Hard 问题。面对复杂的哈希函数,求解器SMT Solver(如 Z3)往往无法在有限时间内给出解,导致求解超时(Solver Timeout),这与路径爆炸共同构成了符号执行的阿喀琉斯之踵。
至此,传统手段耗尽了所有弹药。我们需要新的武器。
第二章 降临:AI 介入的三种范式
AI 与 Fuzzing 的结合,并非简单的“1+1”,而是从底层逻辑上的重构。目前主流的融合路径可以归纳为三大范式。
2.1 范式一:预测(Predictive)——“那里有漏洞”
利用深度学习模型(如 BiLSTM, CodeBERT)对源代码进行静态分析,预测哪些函数或文件最可能包含漏洞。
- 角色: 侦察兵。
- 作用: 指导 Fuzzer 将算力集中在“高危区域”,而不是漫无目的地测试所有代码。
2.2 范式二:生成(Generative)——“这是通往深处的钥匙”
利用生成模型(GANs, VAEs, Transformers)学习输入的语法和语义分布,直接生成能够通过格式校验的高质量种子。
- 角色: 伪造者。
- 作用: 解决结构化输入(如 PDF, HTML)的生成难题,绕过解析器,直捣黄龙。
2.3 范式三:决策(Decision-Making)——“下一步该怎么走”
利用强化学习(Reinforcement Learning, RL)动态调整变异策略。
- 角色: 指挥官。
- 作用: 根据当前的反馈(覆盖率、执行速度),决定是应该翻转比特,还是拼接字典,亦或是裁剪输入。
第三章 数据炼金术:训练一只“漏洞嗅探犬”
在深入算法之前,我们必须解决 AI 的核心燃料问题:数据。
对于图像识别,我们有 ImageNet;对于自然语言,我们有 CommonCrawl。
但对于“漏洞挖掘”,我们的数据集在哪里?
这是一个极其棘手的问题,因为公开的漏洞代码(Vulnerable Code)相对于正常代码来说,是极其稀疏的。
3.1 数据集的构建:从 CVE 到合成数据
专业人士构建 AISec 数据集的策略通常包含三个维度:
- SARD & NVD (The Gold Standard):
NIST 维护的软件保障参考数据集(SARD)和国家漏洞数据库(NVD)是基础。
-
- 提取策略: 爬取 CVE 对应的 Patch Commit。
- 差异分析(Diffing): 补丁前的代码是 V_{vuln},补丁后的代码是 V_{clean}。这两者的差异(Diff)是训练模型识别“漏洞模式”的关键特征。
- 野外挖掘(In-the-Wild Mining):
利用 GitHub API,扫描数百万个开源项目的 Commit Message。寻找包含 "Fix buffer overflow", "Prevent SQL injection" 等关键词的提交。
-
- 清洗挑战: 开发者提交代码很不规范,很多 "Fix bug" 可能只是修复了逻辑错误而非安全漏洞。这里通常需要使用 NLP 技术进行二次清洗。
- 合成数据(Synthetic Data Injection):
鉴于真实样本的稀缺,我们使用“代码变异技术”人工生成漏洞。
-
- 方法: 编写脚本,在正常的 C/C++ 代码中随机插入常见的漏洞模式。
- Example: 找到一个 strcpy(dest, src),将其替换为 memcpy 但故意计算错误的长度,人为制造缓冲区溢出。
- 价值: 这种方法可以生成数以亿计的标注数据,用于预训练模型的“热身”。
3.2 代码的表征学习:如何让 AI “读懂”代码?
你不能直接把 C++ 代码像写小说一样喂给神经网络。代码是结构化的逻辑,通过纯文本处理会丢失大量信息。
初学者误区: 把代码当成自然语言处理(NLP)。
专家路径: 利用代码的结构特征构建多模态表征。
我们需要提取代码的三种视图:
- 词法视图(Lexical View): 源代码的 Token 序列。
- 处理方式: 使用 Transformer (如 BERT) 进行 Embedding。
- 句法视图(Syntactic View): 抽象语法树(AST)。
- 处理方式: 树神经网络 (Tree-LSTM) 或图神经网络 (GNN)。AST 告诉模型“这是一个 if 语句,嵌套了一个 while 循环”。
- 语义视图(Semantic View): 控制流图(CFG)和 数据流图(DFG)。
- 处理方式: 这是最关键的。DFG 告诉模型“变量 x 在第 5 行被定义,在第 10 行被用户输入污染,在第 20 行被用作数组下标”。
GraphCodeBERT 是该领域的集大成者。它不仅仅看代码文本,还利用数据流图(Data Flow Graph)来理解变量之间的依赖关系。
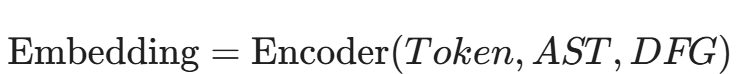
通过这种高维表征,AI 不再是看字符,而是在看逻辑的流动。它能“感觉”到数据流在一个没有任何边界检查的 strcpy 前突然中断的危险气息。
第四章 种子生成的革命:打破格式的枷锁
Fuzzing 的第一步是提供“种子”(Seed)。
传统 Fuzzer 依赖用户提供初始文件。如果目标是一个 PDF 阅读器,你需要给它 100 个合法的 PDF。
但如果要测试一个全新的私有协议,或者极度复杂的复合格式,传统方法就失效了。
4.1 生成式 AI 的介入:GANs 与 VAEs
对于高度结构化的输入(如图片、复杂的配置文件),生成对抗网络(GAN)表现出了惊人的潜力。
案例:IDSFuzz (基于 GAN 的协议 Fuzzing)
假设我们要 Fuzz 一个工业控制协议(如 Modbus 变种),没有文档,只有流量包。
- 生成器(Generator): 试图构造假的协议数据包。
- 判别器(Discriminator): 试图区分“真实捕获的流量”和“生成器生成的流量”。
- 目标函数: 当判别器无法区分时,说明生成器已经学会了协议的隐式语法(Implicit Grammar)。
通过这种博弈,AI 自动学会了协议的结构(头部、长度、校验位)。然后,我们在生成器中引入扰动向量(Perturbation Vector),让它生成“只有一点点坏”的数据包——既能通过协议解析,又能触发边界条件。
4.2 LLM-Fuzzing:大语言模型的降维打击
这是目前最前沿的领域(2024-2025年趋势)。
LLM(如 GPT-4, CodeLlama)不仅懂自然语言,更懂形式语言。
场景:Fuzzing 一个 SQL 数据库引擎。
传统 Fuzzer (如 SQLsmith) 只能基于硬编码的语法树生成 SQL 语句。它很难生成像“使用 CTE 递归查询并在窗口函数中嵌套 JSON 解析”这样复杂的语义合法语句。
LLM 的做法:
Prompt:
"你是一个数据库 QA 专家。请生成 10 条极其复杂的 SQL 查询语句,要求涵盖:递归 CTE、窗口函数、JSON 字段操作以及非常规的 Unicode 字符。目标是测试数据库解析器的极限。"
LLM 能够生成:
WITH RECURSIVE bomb(n, s) AS (
SELECT 1, '{"a": [1,2,3]}'
UNION ALL
SELECT n+1, JSON_SET(s, '.a', JSON_ARRAY_APPEND(JSON_EXTRACT(s, '.a'), '', n))
FROM bomb WHERE n < 1000
)
SELECT * FROM bomb WHERE HEX(s) LIKE '%00%';这种语句在语法上完全正确(可以通过 Parser),但在语义上极度复杂(递归深度、内存消耗大)。这是传统随机变异器几乎不可能生成的。
TitanFuzz 是这一领域的代表作。它利用大模型直接生成深度学习框架(如 PyTorch/TensorFlow)的 Python API 调用序列。因为深度学习框架的 API 约束极强(张量维度必须匹配),传统 Fuzzing 效率极低,而 LLM 能够理解“张量形状推导”的逻辑,生成高通过率的测试代码。
阴影与对策:幻觉消除与差分模糊测试(Diff-Fuzzing)
然而,LLM 并非全知全能。它存在严重的**“幻觉”(Hallucination)**问题——它可能会捏造不存在的 SQL 函数,或者臆造 PyTorch 中错误的张量维度。
为了驾驭这匹烈马,现代架构引入了两道防线:
- 语义过滤器(Semantic Sanitizer):利用编译器反馈循环(Compiler-Feedback Loop)。如果 LLM 生成的代码编译报错,系统会将报错信息(Error Log)喂回给 LLM,让其进行“自我反思”并修正代码。
- 差分模糊测试(Diff-Fuzzing):这是目前浏览器与解释器挖掘的皇冠明珠。
- 原理:利用 LLM 强大的语义重写能力,生成两段语法不同但语义相同的代码(例如:一段用 for 循环,一段用 map 函数,但逻辑一致)。
- 判决:将这两段代码同时喂给不同的引擎(如 Chrome 的 V8 和 Safari 的 JavaScriptCore)。
- 捕获:如果两者的执行结果(Output)不一致,那么必定有一个引擎存在逻辑 Bug。这种方法能发现那些不会导致 Crash、但在计算逻辑上出错的隐蔽漏洞。
第五章 神经网络平滑(Neural Program Smoothing):数学上的降维打击
本章内容涉及较深的数学原理,是区分“脚本小子”与“安全科学家”的分水岭。
传统 Fuzzing 的最大痛点在于:程序的执行流是离散的(Discrete)。
一个 if (x > 0) 语句,输入 0.0001 和 100 走的是同一条路,但 -0.0001 就走了另一条路。这种“阶跃”使得我们无法使用**梯度下降(Gradient Descent)**来优化输入。
梯度下降是 AI 训练的核心,效率极高。如果能用梯度下降来指导 Fuzzing,速度将提升千倍。
5.1 关键突破:NEUZZ
NEUZZ 提出了一种革命性的思想:利用神经网络拟合程序的分支行为,将离散的程序平滑化。
- 数据收集: 先用传统 Fuzzer 跑一段时间,收集输入 x 和对应的分支覆盖图(Bitmap)y。
- 代理模型训练(Surrogate Model): 训练一个全连接神经网络 F(x) ≈ P(x)。
- 输入:测试用例字节流。
- 输出:预测的边缘覆盖率(Edge Coverage)。
- 梯度计算:
神经网络是可微的!我们可以计算输出针对输入的梯度:
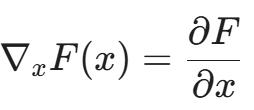
这个梯度告诉我们:“如果你把输入字节流的第 5 个字节增加 1,覆盖率会增加最快。”
- 梯度制导变异:
利用计算出的梯度方向,对输入进行修改。
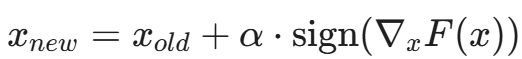
这就像是在漆黑的迷宫中,传统 Fuzzer 是在乱撞,而 NEUZZ 打开了“热成像仪”,通过梯度的指引,直接走向未探索区域的边界。
实验数据表明: 在处理像 readelf 或 objdump 这样复杂的二进制程序时,基于梯度的 Fuzzer 比传统 AFL 快 10 倍以上。
第六章 实战演练:搭建你的第一个 AI 种子生成器
为了让初学者能够落地,我们在这里构建一个简单的、基于 N-gram 语言模型的种子生成器。虽然它比不上 GPT-4,但它展示了“基于统计生成”的核心逻辑。
6.1 场景定义
目标:Fuzz 一个 XML 解析器。
痛点:随机生成的字符串几乎无法通过 XML 语法检查。
6.2 代码实现 (Python)
import random
from collections import defaultdict
class AIPayloadGenerator:
def __init__(self, n=3):
self.n = n
self.memory = defaultdict(list)
def train(self, corpus_files):
"""
从正常的 XML 文件中学习字符的概率分布
"""
print("[-] 开始学习 XML 语法结构...")
for filepath in corpus_files:
with open(filepath, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
# 简单的 N-gram 建模
for i in range(len(content) - self.n):
state = content[i:i+self.n]
next_char = content[i+self.n]
self.memory[state].append(next_char)
print(f"[-] 模型训练完成,记忆库大小: {len(self.memory)}")
def generate(self, length=100, prompt="<root>"):
"""
基于学习到的概率分布生成新的 XML 内容
"""
current_state = prompt[-self.n:]
output = prompt
for _ in range(length):
if current_state in self.memory:
# 按照统计概率选择下一个字符
next_char = random.choice(self.memory[current_state])
output += next_char
current_state = output[-self.n:]
else:
# 遇到未见过的状态,随机回退或终止
break
# 此时的 output 极大可能符合 XML 语法,但内容是新的
return output
# --- 使用示例 ---
# 假设我们有一堆正常的 xml 文件在 ./corpus 目录
# generator = AIPayloadGenerator(n=4)
# generator.train(['./corpus/1.xml', './corpus/2.xml'])
# payload = generator.generate(length=500, prompt="<user name=")
# print(payload)6.3 代码解读
这段代码虽然只有几十行,但它体现了 Learn & Fuzz 的雏形。
- 传统 Fuzzer 可能会生成 <user name=%%%>(语法错误)。
- 这个简单的 AI 模型会学到,在 <user name= 后面,通常跟着引号 ",然后是字母。
- 生成的 Payload 可能是 <user name="admin" role="superuser">...</root>。
- 进阶: 将 N-gram 替换为 LSTM 或 Transformer,你就能生成嵌套深度极深、逻辑连贯的 XML 结构。
“但这只是暴风雨前的宁静。 我们有了数据和生成器,但这还不够。真正的 Fuzzing 核心在于反馈循环(Feedback Loop)。当程序跑起来后,如何根据覆盖率反馈,实时调整 AI 的策略?这需要一个‘指挥官’。接下来,我们将进入更具攻击性的领域——强化学习与自动化漏洞利用。”
“在数字的荒原上,随机是弱者的墓志铭,策略才是猎食者的罗盘。”
第七章 变异的大脑:强化学习(RL)与马尔可夫决策过程
传统 Fuzzer(如 AFL)之所以被称为“盲目的”,是因为它对变异算子(Mutation Operators)的选择是硬编码的。
AFL 有一套固定的连招:翻转 1 bit -> 翻转 2 bits -> 加减小整数 -> 拼接字典。这就好比一个拳击手,无论对手是谁,永远只按顺序打出“左勾拳、右勾拳、上勾拳”。
面对复杂的软件,这种策略极低效。对于某些文件格式,翻转比特毫无意义(破坏了 checksum),只有拼接大块数据(Block Splicing)才有效。
我们需要一个能够“根据对手反应调整拳法”的拳击手。这就是强化学习(Reinforcement Learning, RL)的用武之地。
7.1 将 Fuzzing 建模为 MDP(马尔可夫决策过程)
要让 AI 控制 Fuzzing,首先要建立数学模型。我们将 Fuzzing 过程映射为强化学习的标准四元组 (S, A, R, \pi):
- 状态(State, S): 当前的种子(Seed)及其属性。
- 特征: 种子的大小、执行路径的哈希(Bitmap hash)、执行时间、已经经过的变异次数。
- 动作(Action, A): 变异算子。
- 集合:{BitFlip, ByteFlip, ArithmeticAdd, DictionaryInsert, BlockDelete, ...}
- 奖励(Reward, R): 变异后的反馈。
- 如果发现了新路径(New Coverage),R = +10。
- 如果触发了 Crash,R = +1000。
- 如果执行超时或无新路径,R = -1(时间惩罚)。
- 策略(Policy, \pi): 核心算法。
- \pi(s) \rightarrow a:根据当前种子的状态,决定下一步使用哪个变异算子。
7.2 多臂老虎机(MAB)与 Q-Learning 的博弈
在早期研究中,最常用的模型是多臂老虎机(Multi-Armed Bandit, MAB)。
假设我们有 10 个变异算子(10 台老虎机)。我们不知道哪个算子最容易产出新路径(中奖)。
算法需要在**探索(Exploration)和利用(Exploitation)**之间平衡:
- 探索: 尝试那些冷门的变异算子,万一有奇效呢?
- 利用: 疯狂使用那个刚才产出了新路径的算子。
进阶:深度 Q 网络(DQN)
MAB 假设状态是静态的,但实际上 Fuzzing 是动态的。
Deep Q-Network (DQN)通过神经网络来拟合 Q 函数:
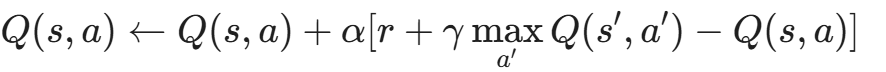
BODE (Bayesian Optimization) 是另一个流派。它利用贝叶斯优化来预测:如果我把输入文件第 100 字节的 0x00 改为 0xFF,获得新覆盖率的概率分布是多少?这使得 Fuzzer 能够极其精准地进行“外科手术式”变异。
7.3 案例:AFLFast 与 EcoFuzz
虽然它们不算纯 AI,但引入了基于马尔可夫链的能量分配机制。
- AFLFast:它观察到 Fuzzer 大部分时间浪费在‘高频路径’(High-frequency path)上。它引入了马尔可夫链模型来估算路径概率,设计了特殊的能量调度策略(Power Schedule),刻意对执行次数过多的路径进行“惩罚“(减少变异机会),从而迫使 Fuzzer 将算力转移到那些难以触及的“低频路径“上。
- EcoFuzz: 利用一种对抗性的多臂老虎机算法,动态判断一个种子是否已经“枯竭”。如果预测该种子产生新路径的概率低于阈值,直接丢弃,不再浪费算力。
第八章 收割时刻:从 Crash 到 Exploit 的自动化跃迁
Fuzzing 的终点通常是 Crash。
但在黑客眼中,Crash 只是半成品。一个 Segmentation Fault 毫无价值,除非你能证明它可以被转化为 EIP/RIP Control(指令指针劫持)。
这是网络安全中门槛最高的一环:漏洞利用开发(Exploit Development)。
以前,这是人类专家的禁脔。现在,大语言模型(LLM)正在跨越这道鸿沟。
8.1 自动分类与去重(Triage)
Fuzzer 跑一晚上可能产生 10 万个 Crash。其中 99% 都是同一个 bug 触发的。
传统工具(如 GDB exploitable 插件)基于简单的哈希去重,经常误判。
AI 方案:基于图的根本原因分析(RCA)
- 执行流录制: 记录 Crash 发生前的最后 1000 条汇编指令。
- 图构建: 将其转化为执行流图。
- 图匹配: 利用图神经网络(GNN)计算两个 Crash 的相似度。
- AI 判断: “虽然这两个 Crash 的报错地址不同,但它们的数据流污染源头都是 process_packet 函数中的第 3 个 memcpy,所以它们是同一个漏洞。”
8.2 堆风水(Heap Feng Shui)的 AI 编排
堆溢出(Heap Overflow)利用极难,因为你需要精确控制堆块(Chunk)的布局。这通常涉及对 glibc malloc/free 分配算法(如 fastbin, tcache)的深度理解和操纵。
你需要精心构造一系列的 malloc 和 free 操作,使得被溢出的对象刚好紧邻着包含函数指针的对象。
强化学习的堆布局生成:
这本质上是一个俄罗斯方块游戏。
- 环境: 堆内存管理器(如 ptmalloc, jemalloc)。
- 动作: malloc(size), free(ptr), write(ptr, content)。
- 目标: 让 Target Chunk 和 Vulnerable Chunk 相邻。
通过训练一个 RL Agent,它能学会极其反直觉的堆操作序列(例如:先分配 10 个,释放奇数位的 5 个,再分配一个大的),从而实现完美的利用布局。
8.3 LLM 作为 Exploit 编写者
这是最令人战栗的前沿。
场景:栈溢出(Stack Overflow)利用生成
Prompt to LLM:
"我有一个程序,在处理 USER 命令时发生了 Crash。
附件是 GDB 的上下文:RIP 覆盖为 0x41414141。RSP 指向 0x7fffffffe400。
目标系统中开启了 NX(不可执行位),但关闭了 ASLR(地址随机化)。
请利用 libc 中的 system 函数和 /bin/sh 字符串,构造一个 ROP (Return-Oriented Programming) 链。
请输出 Python 攻击脚本,使用 pwntools 库。"
LLM 的思维链(Chain of Thought):
- 识别现状: 这是一个标准的 Ret2Libc 攻击。
- 寻找 Gadgets: 我需要 pop rdi; ret 来传递参数。
- 计算偏移: 根据 RIP 覆盖情况,计算 Padding 长度。
- 生成代码:
from pwn import *
# LLM 自动生成的 Payload 逻辑
p = process('./vuln_app')
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
padding = b'A' * 72 # LLM 根据上下文推断的偏移
pop_rdi = 0x00000000004011d3 # 假设的 Gadget 地址
# 构造 ROP 链
rop = padding
rop += p64(pop_rdi)
rop += p64(next(libc.search(b'/bin/sh')))
rop += p64(libc.symbols['system'])
p.sendline(rop)
p.interactive()现实案例: 在 2024 年的 DARPA AI Cyber Challenge (AIxCC) 中,参赛的 AI 系统已经展示了自动修复漏洞并自动生成 PoC(概念验证)的能力。虽然对于复杂的内核级漏洞利用(需要 Race Condition + UAF 组合)AI 尚显吃力,但对于标准漏洞,它的速度是人类的百倍。
第九章 终极形态:自主网络捕食者系统架构
如果我们将全文的所有组件拼装在一起,我们就得到了 AISec 的圣杯:一个全自动、端到端的网络捕食者。
9.1 宏观架构设计
这个系统不是一个单一的程序,而是一个多智能体系统(Multi-Agent System)。
- 侦察 Agent (Scout):
- 负责《硅基之盾》前几篇提到的资产发现。
- 将目标二进制文件下载到沙箱。
- 逆向 Agent (Reverser):
- 利用 LLM 和 IDA Pro 插件,分析二进制,提取控制流图,识别潜在攻击面(Attack Surface)。
- 输出:“目标使用了自定义的 TLV 协议,解析函数在 0x401000。”
- Fuzzing 编排器 (Orchestrator):
- 启动 AFL++ 或 Honggfuzz 实例。
- 种子生成模型(GAN/LLM)源源不断地输送高质量结构化种子。
- RL 变异模型 实时监控覆盖率,动态调整变异策略。
- NEUZZ 梯度模型 指引 Fuzzer 突破复杂的 Magic Number。
- 利用开发 Agent (Exploiter):
- 一旦 Fuzzer 抛出 Crash,Exploiter 接管。
- 分析 Dump 文件,尝试生成 ROP 链。
- 如果利用成功,回传 Flag 或 Shell 访问权限。
9.2 自我进化的循环
这个系统最可怕之处在于在线学习(Online Learning)。
每一次失败的 Fuzzing 尝试,都成为了 RL 模型的负样本;每一次成功的 Crash,都强化了种子的生成策略。它跑得越久,就越聪明。它不需要休息,不需要喝咖啡,甚至不需要薪水。
第十章 工程落地:用 Python 实现一个强化学习变异器
为了让读者能够触摸到 AI Fuzzing 的脉搏,我们来实现一个最简化的 Q-Learning 变异调度器。
10.1 场景
我们有一个简单的 Fuzzing 循环。我们有 3 个变异算子:翻转、加法、拼接。我们要训练 AI 自动选择当下最好的那个。
10.2 代码实现
import numpy as np
import random
class QLearningFuzzer:
def __init__(self, actions, alpha=0.1, gamma=0.9, epsilon=0.1):
self.actions = actions # 变异算子列表
self.q_table = {} # Q表: 映射 (state) -> [action_values]
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # 探索率
def get_state_key(self, seed_coverage, seed_len):
"""
将连续的状态离散化。
例如:将覆盖率分桶,将种子长度分桶。
"""
cov_bucket = int(seed_coverage / 10) # 假设覆盖率是 0-100
len_bucket = int(seed_len / 100) # 每100字节一个桶
return (cov_bucket, len_bucket)
def choose_action(self, state):
"""
Epsilon-Greedy 策略
"""
self._init_state(state)
# 探索:随机选择
if random.uniform(0, 1) < self.epsilon:
return random.choice(self.actions)
# 利用:选择 Q 值最大的动作
state_actions = self.q_table[state]
max_idx = np.argmax(state_actions)
return self.actions[max_idx]
def learn(self, state, action, reward, next_state):
"""
Q-Learning 核心更新公式
"""
self._init_state(state)
self._init_state(next_state)
action_idx = self.actions.index(action)
predict = self.q_table[state][action_idx]
target = reward + self.gamma * np.max(self.q_table[next_state])
# 更新 Q 值
self.q_table[state][action_idx] += self.alpha * (target - predict)
def _init_state(self, state):
if state not in self.q_table:
self.q_table[state] = np.zeros(len(self.actions))
# --- 模拟 Fuzzing 过程 ---
# 定义算子
operators = ['bit_flip', 'int_add', 'block_splice']
fuzzer_brain = QLearningFuzzer(operators)
# 模拟循环
current_seed_cov = 10
current_seed_len = 50
print("[-] 启动 RL Fuzzing 训练...")
for episode in range(1000):
state = fuzzer_brain.get_state_key(current_seed_cov, current_seed_len)
# 1. AI 选择动作
action = fuzzer_brain.choose_action(state)
# 2. 执行变异 (这里用模拟代替)
# [REAL WORLD NOTE]: 在真实场景中,这里会调用 instrumented_binary (如 afl-fuzz),
# 并通过解析共享内存(Shared Memory)中的 bitmap 来计算真实的 edge coverage 增量。
# 伪代码: execution_result, new_cov = run_target(mutate(seed, action))
reward = 0
next_cov = current_seed_cov
# 模拟环境反馈:假设 'int_add' 在当前状态下击中了边界检查
if action == 'int_add' and current_seed_len < 100:
reward = 10 # 发现新路径!
next_cov += 5
elif action == 'bit_flip':
reward = -1 # 浪费时间/无新路径
# 3. AI 学习
next_state = fuzzer_brain.get_state_key(next_cov, current_seed_len)
fuzzer_brain.learn(state, action, reward, next_state)
current_seed_cov = next_cov # 更新状态
print("[-] 训练结束。查看 Q-Table:")
print(f"在状态 (Cov=0-10, Len=0-100) 下的动作价值: {fuzzer_brain.q_table[(0,0)]}")
# 你会发现 'int_add' 对应的分数变得很高10.3 代码解读
这个微型模型展示了 RL Fuzzing 的灵魂:反馈循环。
在实际工程中(如 Google 的 FuzzBench),这个状态空间会极其巨大,Q-Table 会被深度神经网络(DQN)取代,而奖励函数会包含更细粒度的指标(如分支翻转数、内存消耗等)。
结语:与神角力的凡人
读完这篇文章,你可能会有一种感觉:传统的网络安全已经死了。
(抱歉这种感觉我在2023年就有了,并且陷入职业危机。)
曾经,挖掘漏洞是一个黑客在深夜里对着反汇编窗口抽烟、冥思苦想的浪漫画面。
现在,它变成了一个巨大的、由 GPU 驱动的工业化熔炉。AI 不知疲倦地生成、变异、评估、收割。它不理解什么是“代码的美感”,它只关心“覆盖率”和“崩溃”。
但这并不意味着人的退出。
相反,人的层级提升了。我们从“挖漏洞的人”,变成了“设计挖漏洞机器的人”。
- 你需要懂编译原理,才能做插桩。
- 你需要懂深度学习,才能设计模型。
- 你需要懂博弈论,才能设计奖励函数。
正如《黑客帝国》中的墨菲斯所说:“有些门你必须自己推开。”
AI 给了你一把钛合金的撞门锤,但选择撞哪扇门,依然取决于你。
陈涉川
2026年01月27日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)