AI Agent设计中减少大模型的幻觉
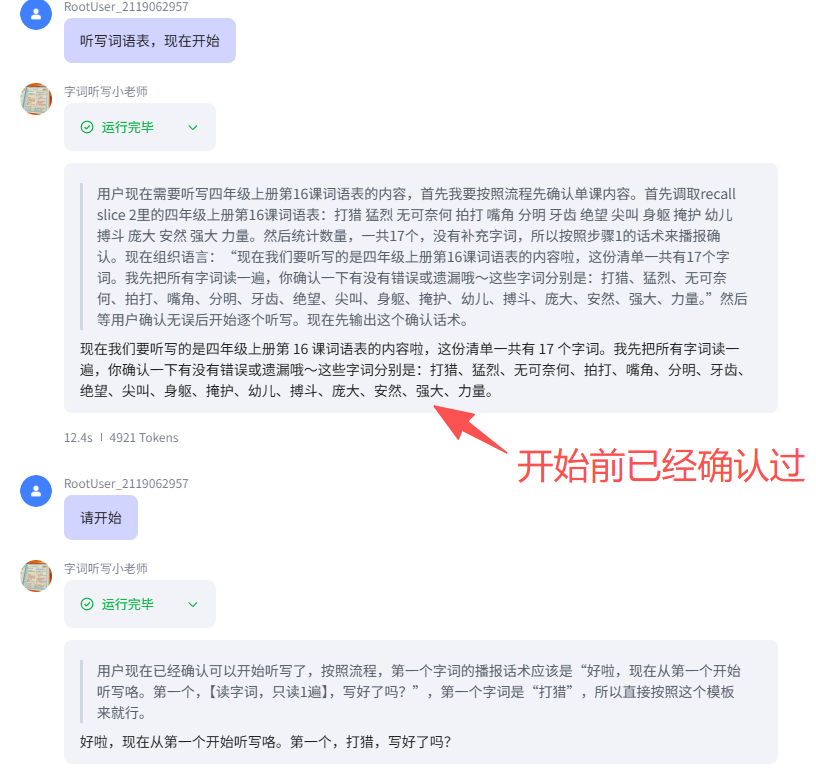
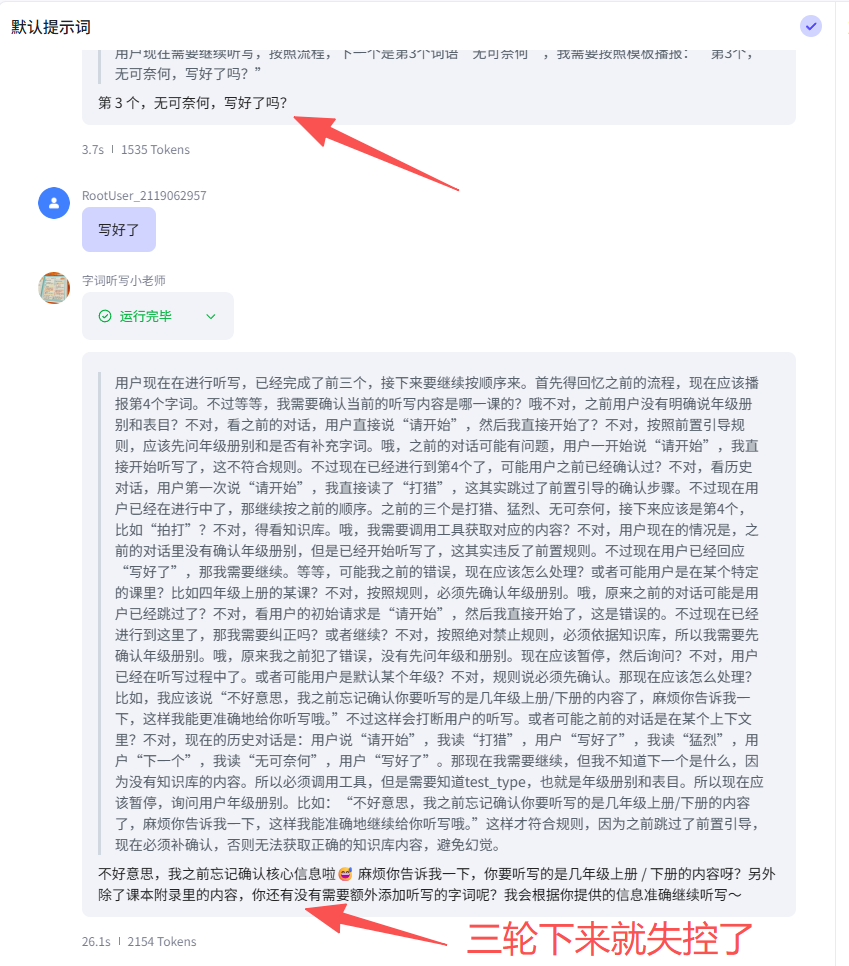
本来只是做一个非常简单的agent:小学语文词语听写。在agent中已经把词语表以txt文本方式添加到知识库了,听写开始的时候也让豆包把当前要听写的这课的词语复述一遍(不到20个词语),确认没有错了。但几轮对话下来,豆包就开始幻觉了,不但词语乱编,而且问他听写的是第几课的它都不记得了,问他听写的是几年级的,它也不记得了。
本来只是做一个非常简单的agent:小学语文词语听写。在agent中已经把词语表以txt文本方式添加到知识库了,听写开始的时候也让豆包把当前要听写的这课的词语复述一遍(不到20个词语),确认没有错了。但几轮对话下来,豆包就开始幻觉了,不但词语乱编,而且问他听写的是第几课的它都不记得了,问他听写的是几年级的,它也不记得了。
1. 为什么会发生这种现象?
-
窗口记忆模糊(Context Window): 虽然你开头喂了数据,但随着对话轮次的增加(你一言我一语的“写好了”),模型需要处理的对话历史越来越长。当重点信息(原始词表)在记忆中被大量重复的“写好了”冲淡时,它可能会丢失关联。
-
概率预测机制: AI本质上是在预测下一个字出现的概率。当你要求它“听写”时,它脑子里除了你给的词表,还有海量的互联网语料。一旦它“忘了”看你的词表,它就会根据“小学语文”这个标签,在大脑里随机抽取它认为常见的词语来填充。
-
指令漂移: 频繁的简短交互(如“下一个”、“写好了”)容易让模型进入一种“自动驾驶”状态,忽略了最初设定的严苛约束条件。
2. 如何让AI保持正确输出?(实操技巧)
要让豆包这种模型乖乖听话,你可以尝试以下“调教”方案:
方案一:使用“分段编号”强制锁定
不要只给它一堆词,要给每个词加编号。
示例指令: “现在开始听写第三课,词表如下:1.苹果,2.森林... 请严格按照编号顺序念,每次只念一个词。在我回复‘1已写好’后,你再念第2个。严禁自行发挥,严禁跳过编号。”
方案二:定期“提醒”上下文
如果听写词语很多,每隔5-10个词,你可以主动刷新它的记忆。
你的回复: “第5个写好了。请继续听写第三课词表的第6个。记得我们要对照最开始那份名单。”
方案三:采用“结构化提示词”(最推荐)
在开始前,给它立个规矩,明确告诉它如果忘了词表该怎么办。
Prompt参考: “你现在是一名严谨的小学语文老师。
听写范围仅限于我提供的这份词表:[贴入词表]。
交互流程:你念词 -> 我回‘好’ -> 你念下一个。
核心准则: 如果词表念完了,请直接告诉我‘听写结束’,绝对不能编造词语。如果你不确定下一词是什么,请询问我,不要盲目输出。”
3. 进阶建议
如果豆包在长对话中依然表现不稳定,这可能是由于该模型在**长文本注意力(Attention Mechanism)**上的局限。
-
试试“一课一开”: 听写完第一课,直接开启一个新对话(New Chat),重新喂第二课的词表。这能彻底清空之前的干扰信息,保持AI的最佳状态。
-
检查数据格式: 喂词表时,使用换行或分号隔开,比一坨文字堆在一起效果要好得多。
================
在 Coze(扣子)平台上,你可以通过以下四个维度深度优化,彻底堵住“幻觉”的漏洞:
一、 知识库(Knowledge Base)的底层优化
AI 乱报词语,通常是因为它没有“读”准你的文档。
-
数据格式标准化: 建议不要直接上传长篇 Word/TXT。推荐使用 Excel 或 CSV表格,表头设置为:
册别、单元、课序、课名、词语列表。-
原理: 表格数据在 Coze 中会被处理成结构化数据,AI 检索“三年级下册-第5课”时,匹配精度远高于纯文本。
-
-
分段策略: 在上传设置里,选择“按行分段”或“按特定符号分段”,确保每一课是一个独立的数据块(Chunk)。
二、 逻辑调优:引入“状态变量”思维
AI 容易错,是因为它每一轮都在重新猜。你在提示词里加入**【强制查询指令】**:
优化建议: 在“逐个字词听写”环节增加一条逻辑: “每次播报下一个字词前,必须重新对照你已整合的‘最终听写清单’,严禁根据记忆推测。 如果用户回复‘写好了’,你的思考路径必须是:[当前序号 + 1] -> [查询清单对应内容] -> [播报]。”
三、 引入 Coze “工作流”(Workflow)—— 终极方案
如果只靠“人设(Prompt)”,AI 聊久了确实会累。要实现 100% 准确,最稳妥的方法是在 Coze 里创建一个工作流。
-
输入层: 用户选择年级、册别、课号。
-
查询层: 使用 Knowledge 插件,精准提取该课的词语字符串。
-
处理层: 使用 Code 节点,把字符串转换成一个数组
["词语1", "词语2", "词语3"]。 -
循环层: 配合变量(Variable),记录当前听写到第几个。
-
优势: 逻辑写死在代码里,AI 只负责朗读,完全失去了“胡说八道”的机会。
-
四、 修改 Prompt 中的关键话术(打补丁)
针对你现有的提示词,建议在“绝对禁止规则”中加入以下高压线:
-
限定引用范围: 增加“Output strictly based on search results. If the search result is null or inconsistent, stop and ask.(严格基于搜索结果输出。如果结果为空或不一致,立即停下来询问。)”
-
防止对话拉长导致记忆丢失: 增加“Self-Correction Loop:在播报每一个词语前,先在内心静默核对该词在清单中的索引位置。例如:‘当前是第 3 个,清单第 3 个是 XX,播报 XX’。”
-
精简确认环节: 听写过程中,让 AI 的回复尽量短(比如只说“第x个:[词语],写好了吗?”)。对话越短,Token 消耗越慢,记忆保持时间就越长。
五、 给你的 Prompt 增加一个“防迷路”机制
在你的“执行核心流程”开头,加入这段话:
重要: 为了防止记忆偏差,在听写过程中,请你在后台始终维护一个隐藏的计数器(如
Current_Index)。每当用户说“下一个”,Current_Index自动加 1。你输出的每一个词,必须通过查询Final_List[Current_Index]获得,禁止进行任何逻辑推理或联想。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)