让大模型像人眼一样“读懂“文档?DeepSeek-OCR 2用因果推理重塑视觉编码!
DeepSeek-OCR 2解决的其实是个很实际的问题:以前模型读文档就像小学生,傻傻地从左上角一个字一个字往右下角扫,碰到复杂排版、公式、表格就懵了。现在它学会了像人一样,看到标题先读标题,看到图表就跳过去看图表,按照文档本身的逻辑来读,自然就更准了。而且它用的token更少、速度更快,在实际使用中重复率从6%降到4%——这意味着你让它识别PDF时,出错和胡说八道的情况明显少了。
研究背景:从扫描顺序到语义理解的范式转变
想象一下,当你阅读一份复杂的学术论文时,你的眼睛是如何移动的?你不会机械地从左上角一行行扫到右下角,而是会根据内容的语义逻辑——标题、摘要、图表、公式——进行有选择性的跳跃式阅读。但现有的视觉语言模型(VLMs)却恰恰相反,它们像扫描仪一样,死板地按照从上到下、从左到右的光栅扫描顺序处理图像,完全忽略了图像中蕴含的语义关系和逻辑结构。
这就是DeepSeek团队想要解决的核心问题。他们提出了一个大胆的假设:能否让视觉编码器像人眼一样,根据图像的语义内容动态地重新排列视觉token的顺序,而不是被固定的空间坐标所束缚? 这个想法在文档OCR场景中尤为关键——想想看,一份包含复杂公式、多栏排版、表格的学术论文,如果机械地按行扫描,根本无法捕捉其内在的阅读逻辑。
DeepSeek-OCR 2的三大核心贡献可以概括为:
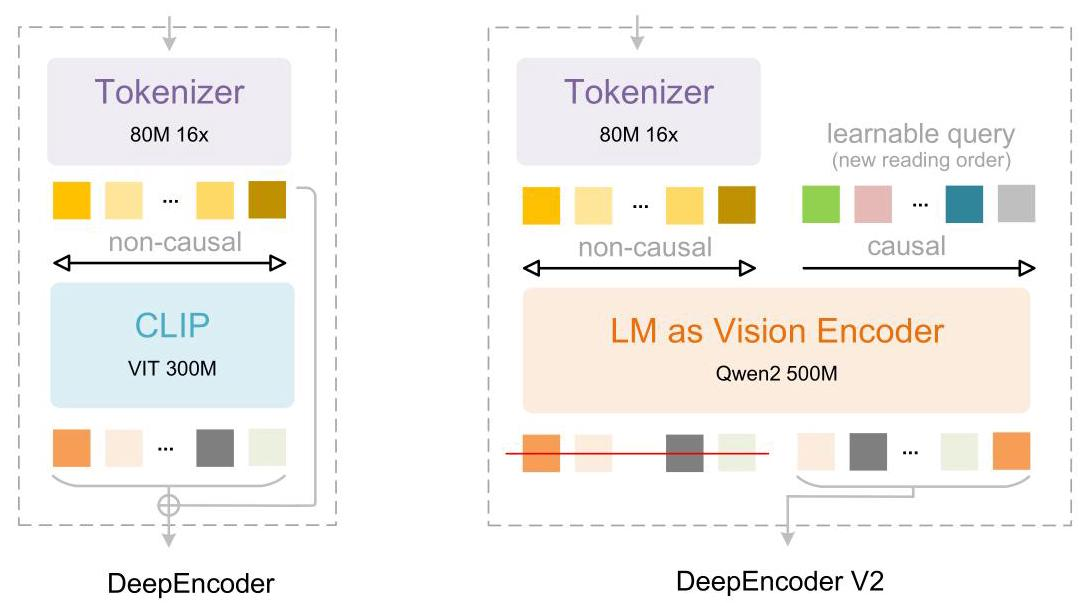
首先,他们设计了DeepEncoder V2这个革命性的编码器。与传统编码器不同,它用一个小型语言模型(LLM)架构替换了CLIP组件,并引入了"因果流查询"(causal flow tokens)机制。这些可学习的查询token能够动态地重新排列视觉信息,就像人眼根据语义进行选择性注意一样。
其次,在保持高效压缩率的同时实现了显著的性能提升。DeepSeek-OCR 2将输入到LLM的视觉token数量控制在256到1120之间——这个上限甚至低于Gemini-3 Pro的最大视觉token预算,但在OmniDocBench v1.5基准测试中却实现了3.73%的性能提升。
最后,这项工作为统一的全模态编码器提供了初步验证。通过使用LLM风格的编码器架构,理论上可以用同一套参数处理文本、图像、音频等多种模态,只需为不同模态配置特定的可学习查询即可。
相关工作:从目标检测到多模态对齐的演进之路
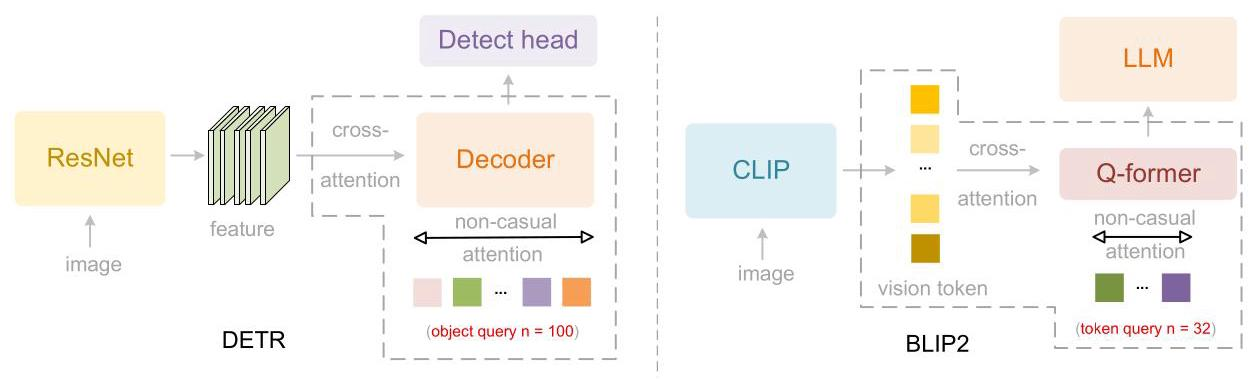
要理解DeepEncoder V2的设计灵感,我们需要回顾两个重要的技术分支:解码器中的并行查询和投影器中的并行查询。
第一个里程碑是DETR(Detection Transformer)。它在2020年将Transformer引入目标检测领域,彻底改变了传统的检测范式。DETR的核心创新是引入了100个"对象查询"(object queries)——这些可学习的查询通过交叉注意力机制与特征图交互,同时通过自注意力机制相互交换信息。这种设计让Transformer能够并行处理多个目标,而不是像传统方法那样串行解码。这个思想后来成为了Transformer检测方法的标准组件。
![]
第二个重要进展是BLIP-2的Q-former。在视觉-语言模型快速发展的浪潮中,研究者们发现需要一个"桥梁"来连接视觉编码器(如CLIP)和大型语言模型。BLIP-2提出的Q-former采用了类似BERT的架构,借鉴DETR的对象查询设计,使用32个可学习查询与数百个CLIP视觉token进行交叉注意力交互。这些压缩后的查询表示随后被输入到LLM中,实现了从视觉到语言空间的有效映射。Q-former的成功证明,并行可学习查询不仅适用于检测任务的特征解码,也同样适用于多模态对齐中的token压缩。
![]
此外,近年来的研究还发现,在大规模互联网数据上预训练的LLM可以作为多模态模型的有效初始化。一些研究表明,冻结的LLM Transformer层能够增强视觉判别任务。更激进的是,像Fuyu和Chameleon这样的无编码器或轻量编码器模型,以及语音领域的VALL-E,都进一步验证了LLM预训练权重在多模态初始化中的潜力。这些工作为DeepSeek-OCR 2使用LLM架构作为视觉编码器提供了理论支撑。
核心方法:双流注意力实现视觉因果流
DeepSeek-OCR 2的整体架构延续了DeepSeek-OCR的编码器-解码器设计,但关键创新集中在编码器部分——也就是DeepEncoder V2。让我们深入了解它是如何工作的。
视觉分词器:16倍压缩的第一步
DeepEncoder V2的第一个组件是视觉分词器(vision tokenizer)。它采用了一个8000万参数的SAM-base架构,配合两个卷积层。这个看似简单的设计实际上非常精妙——通过窗口注意力机制实现了16倍的token压缩,将原始图像patch数量大幅减少,从而显著降低后续全局注意力模块的计算成本和激活内存。值得注意的是,最终卷积层的输出维度从DeepEncoder的1024降低到896,以便与后续流程对齐。
这个压缩式分词器并非不可替代——理论上可以用简单的patch embedding取代。但保留它的原因很实际:它的参数量(80M)与LLM中用于文本输入嵌入的典型100M参数相当,在保持压缩效率的同时不会引入过多的计算开销。
LLM作为视觉编码器:双流注意力的奇妙设计
这里是最精彩的部分。在DeepEncoder中,CLIP ViT负责压缩视觉知识。而DeepEncoder V2则大胆地将这个组件重新设计为LLM风格的架构,并引入了一种独特的双流注意力机制。
具体来说,架构中存在两种token:
- 视觉token:使用双向注意力,就像传统ViT一样,每个token可以看到所有其他视觉token,保持了CLIP的全局建模能力
- 因果流查询(causal flow queries):使用因果注意力,每个查询只能看到所有视觉token和它之前的查询token
这个设计有个关键细节:可学习查询的数量与视觉token数量相等。这样做的好处是,在不改变token数量的前提下,对视觉特征进行语义排序和提炼。最终,只有因果查询的输出被送入LLM解码器,而不是原始的视觉token。
为什么要用LLM架构而不是传统的编码器-解码器结构?研究团队实际上尝试过使用交叉注意力的mBART风格编码器-解码器,但发现无法收敛。他们推测失败的原因在于,当视觉token被隔离在单独的编码器中时,视觉信息的交互不足。相比之下,前缀拼接设计(将视觉token作为前缀)让视觉token在所有层中保持活跃,促进了视觉信息与因果查询之间的有效交换。
实现上,他们选择了Qwen2-0.5B(500M参数)——这个规模与CLIP ViT(300M)相当,不会引入过多的计算开销。这个架构实际上建立了两级级联因果推理:编码器通过可学习查询对视觉token进行语义重排,然后LLM解码器对这个排序后的序列进行自回归推理。
因果流查询:多尺度策略
因果查询token的数量计算为 W×H162×16\frac{W \times H}{16^2 \times 16}162×16W×H,其中WWW和HHH是输入编码器的图像宽度和高度。为了避免为不同分辨率维护多组查询,他们采用了多裁剪策略,使用预定义分辨率的固定查询配置。
![]
具体来说:
- 全局视图使用1024×10241024 \times 10241024×1024分辨率,对应256个查询嵌入(记为queryglobal\text{query}_{\text{global}}queryglobal)
- 局部裁剪采用768×768768 \times 768768×768分辨率,裁剪数量kkk从0到6(当图像两个维度都小于768时不裁剪)
- 所有局部视图共享一组144个查询嵌入(记为querylocal\text{query}_{\text{local}}querylocal)
因此,输入到LLM的重排序视觉token总数为k×144+256k \times 144 + 256k×144+256,范围在[256, 1120]之间。这个最大token数(1120)比DeepSeek-OCR的1156(Gundam模式)更少,恰好等于Gemini-3 Pro的最大视觉token预算。
注意力掩码:拼接双向与因果
为了更清楚地展示DeepEncoder V2的注意力机制,他们在论文中可视化了注意力掩码。这个掩码由两个不同的区域组成:
![]
- 左侧区域对原始视觉token应用双向注意力(类似ViT),允许完整的token间可见性
- 右侧区域对因果流token采用因果注意力(三角形掩码,与decoder-only LLM相同),每个token只能看到之前的token
这两个组件沿着序列维度拼接,构成DeepEncoder V2的注意力掩码(M):
M=[1m×m0m×n1n×mLowerTri(n)],其中 n=mM = \left[\begin{matrix} \mathbf{1}_{m \times m} & \mathbf{0}_{m \times n} \\ \mathbf{1}_{n \times m} & \text{LowerTri}(n) \end{matrix}\right], \text{其中 } n = mM=[1m×m1n×m0m×nLowerTri(n)],其中 n=m
这里nnn是因果查询token数量,mmm是原始视觉token数量,LowerTri表示下三角矩阵(对角线及以下为1,以上为0)。
解码器与整体前向传播
由于DeepSeek-OCR 2主要关注编码器改进,解码器组件保持不变——仍然使用DeepSeek-OCR的30亿参数MoE结构,约5亿活跃参数。整个DeepSeek-OCR 2的核心前向传播可以形式化为:
O=D(πQ(TL(E(I)⊕Q0;M)))\mathbf{O} = \mathcal{D}\left(\pi_Q\left(\mathcal{T}^L\left(\mathcal{E}(\mathbf{I}) \oplus \mathbf{Q}_0; \mathbf{M}\right)\right)\right)O=D(πQ(TL(E(I)⊕Q0;M)))
其中I∈RH×W×3\mathbf{I} \in \mathbb{R}^{H \times W \times 3}I∈RH×W×3是输入图像,E\mathcal{E}E是视觉分词器,将图像映射为mmm个视觉token,Q0∈Rn×d\mathbf{Q}_0 \in \mathbb{R}^{n \times d}Q0∈Rn×d是可学习因果查询嵌入,⊕\oplus⊕表示序列拼接,TL\mathcal{T}^LTL代表LLL层带掩码注意力的Transformer,M\mathbf{M}M是前面定义的块因果注意力掩码,πQ\pi_QπQ是提取最后nnn个token的投影操作符,D\mathcal{D}D是语言解码器。
实验效果:更少token,更高性能
训练流程:三阶段渐进式优化
DeepSeek-OCR 2的训练分为三个阶段,每个阶段都有明确的目标:
阶段1:编码器预训练 - 这个阶段让视觉分词器和LLM风格编码器获得特征提取、token压缩和token重排序的基本能力。他们使用语言建模目标,将编码器与一个轻量级解码器耦合,通过下一个token预测进行联合优化。在两个分辨率(768×768768 \times 768768×768和1024×10241024 \times 10241024×1024)的数据加载器上训练,使用160个A100 GPU,批量大小640,训练4万次迭代(约1亿图像-文本对样本)。
阶段2:查询增强 - 在编码器预训练后,将其与DeepSeek-3B-A500M集成为最终流程。冻结视觉分词器(SAM-conv结构),同时优化LLM编码器和LLM解码器以增强查询表示。在这个阶段,通过多裁剪策略统一两个分辨率到单一数据加载器。使用4阶段流水线并行,全局批量大小1280,训练1.5万次迭代。
阶段3:LLM持续训练 - 为了快速消耗训练数据,这个阶段冻结所有DeepEncoder V2参数,只更新DeepSeek-LLM参数。这个策略将训练速度提高了一倍以上(相同全局批量大小下),同时帮助LLM更好地理解DeepEncoder V2重排序后的视觉token。从阶段2继续,再训练2万次迭代。
主要结果:全面领先
他们选择OmniDocBench v1.5作为主要评测基准——这是一个包含1,355个文档页面的数据集,涵盖9大类别(杂志、学术论文、研究报告等)的中英文文档。结果如表所示:
DeepSeek-OCR 2在使用最少视觉token上限(1120)的情况下,达到了91.09%的先进性能。与DeepSeek-OCR基线相比,在相似训练数据下实现了3.73%的提升,验证了新架构的有效性。
更值得注意的是,阅读顺序(R-order)的编辑距离显著降低,从0.085降至0.057。这说明新的DeepEncoder V2能够根据图像信息有效地选择和排列初始视觉token。与Gemini-3 Pro(0.115)相比,DeepSeek-OCR 2(0.100)在相似视觉token预算(1120)下实现了更低的编辑距离,进一步证明新模型在保持高压缩率的同时确保了卓越性能。
细粒度分析:仍有提升空间
团队对9种文档类型进行了详细的性能对比,发现DeepSeek-OCR 2仍有相当大的改进空间。例如,在文本识别编辑距离方面,DeepSeek-OCR 2在大多数情况下优于DeepSeek-OCR,但在报纸类别上表现较弱(>0.13 ED)。
他们分析认为主要有两个原因:
- 较低的视觉token上限可能影响文本超密集报纸的识别——未来可以通过增加局部裁剪数量简单解决
- 报纸数据不足——训练数据仅包含25万相关样本,不足以充分训练DeepEncoder V2处理这一类别
但在阅读顺序指标上,DeepSeek-OCR 2在所有类别上全面优于DeepSeek-OCR,再次验证了视觉因果流编码器设计的有效性。
生产就绪度:实战表现出色
DeepSeek-OCR在生产中有两个主要用例:为DeepSeek-LLM提供在线OCR服务,以及执行批量PDF处理的预训练数据流水线。他们比较了两个版本的生产性能。
由于生产环境中无法获得真实标签,主要关注重复率作为关键指标。结果显示,DeepSeek-OCR 2相比前身表现出明显改善的实用性:在线用户日志图像的重复率从6.25%降至4.17%,PDF数据生产的重复率从3.69%降至2.88%。这些结果进一步验证了DeepSeek-OCR 2架构的有效性,特别是其逻辑视觉理解能力。
论文总结:从1D到2D推理的探索之路
DeepSeek-OCR 2解决的其实是个很实际的问题:以前模型读文档就像小学生,傻傻地从左上角一个字一个字往右下角扫,碰到复杂排版、公式、表格就懵了。现在它学会了像人一样,看到标题先读标题,看到图表就跳过去看图表,按照文档本身的逻辑来读,自然就更准了。而且它用的token更少、速度更快,在实际使用中重复率从6%降到4%——这意味着你让它识别PDF时,出错和胡说八道的情况明显少了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)